Introduction
In the ever-evolving field of machine learning, ensemble learning has emerged as a powerful technique for improving predictive accuracy and robustness. As the name suggests, ensemble learning involves combining multiple models, often referred to as “base learners,” to make more accurate predictions collectively than any single model could achieve alone.
Ensemble learning has gained significant attention and popularity due to its ability to tackle complex problems and provide more reliable results. By harnessing the wisdom of crowds, it leverages the collective intelligence of diverse models to overcome individual model biases and errors. This approach has been successfully applied in various domains, including image recognition, natural language processing, and financial forecasting.
One of the key advantages of ensemble learning is its ability to reduce the risk of overfitting, a common problem when a single model is trained on limited data. By aggregating the predictions of multiple models, ensemble learning can find a balance between bias and variance, resulting in more robust and accurate predictions. Additionally, ensemble learning can handle noisy or incomplete data more effectively as the ensemble models can learn from different subsets of the data.
Another benefit of ensemble learning is its ability to combine different algorithms or variations of the same algorithm to exploit their strengths and compensate for their weaknesses. This diversity in models brings complementary information and viewpoints, leading to improved decision-making. Ensemble methods can outperform individual models when faced with complex, ambiguous, or uncertain problems that may have multiple plausible solutions.
Ensemble learning operates on the principle that a committee of diverse and independent models can collectively make better predictions than any individual model. This concept draws parallels from various fields, such as wisdom of crowds in social psychology and ensemble methods in statistics and machine learning. By pooling the opinions and expertise of multiple models, ensemble learning can unlock hidden patterns and relationships, thus achieving superior prediction accuracy.
In the following sections, we’ll delve deeper into the inner workings of ensemble learning, explore different types of ensemble methods, and discuss their advantages and disadvantages. By the end of this article, you’ll have a comprehensive understanding of ensemble learning and its potential applications in solving complex machine learning problems.
Definition of Ensemble Learning
Ensemble learning, in the context of machine learning, refers to the process of combining multiple individual models to create a stronger, more accurate predictive model. The underlying principle is that a group of diverse models, collectively known as an ensemble, can outperform any single model by leveraging their complementary strengths and reducing individual model biases and errors.
The term “ensemble” in this context refers to a group or a committee of models, each of which is trained on a subset of the training data. Each individual model in the ensemble is known as a “base learner” or a “weak learner,” as it is typically not as accurate as the final ensemble model. However, when these individual models are combined through an ensemble method, they work together synergistically to produce more accurate and robust predictions.
Ensemble learning can be applied to both classification and regression problems. In classification tasks, the ensemble model combines the predictions of its constituent models to determine the class or category of a given input. In regression tasks, the ensemble model combines the outputs of the base learners to estimate a continuous numerical value.
There are different ensemble learning algorithms and techniques that dictate how the individual models in the ensemble are trained and combined. Some common ensemble methods include bagging, boosting, and stacking. While each method has its own characteristics and advantages, they all aim to enhance the performance and reliability of the final ensemble model.
Ensemble learning has gained widespread popularity in the field of machine learning due to its ability to improve prediction accuracy and generalization. By harnessing the collective intelligence of diverse models, ensemble learning can overcome the limitations of individual models, such as overfitting, bias, or noise in the data. It exploits the concept of “wisdom of crowds,” where multiple opinions can collectively provide more accurate decisions than a single opinion.
In the next sections, we will explore how ensemble learning works, the different types of ensemble methods, and the advantages and disadvantages of employing ensemble learning techniques. By understanding the fundamentals of ensemble learning, you will be able to utilize this powerful technique to enhance the performance of your machine learning models.
How Ensemble Learning Works
Ensemble learning works by combining the predictions of multiple individual models to create a final prediction that is more accurate and reliable than any single model. Although the ensemble model may seem like a black box, the underlying process can be broken down into three main steps: training individual models, combining their predictions, and making a final prediction.
The first step in ensemble learning is to train individual models, also known as base learners or weak learners. Each base learner is trained on a different subset of the training data or may use different algorithms. This ensures diversity in the ensemble, as each model learns from a different perspective. The base learners should have sufficient variation in terms of bias and modeling technique to capture different aspects of the problem at hand.
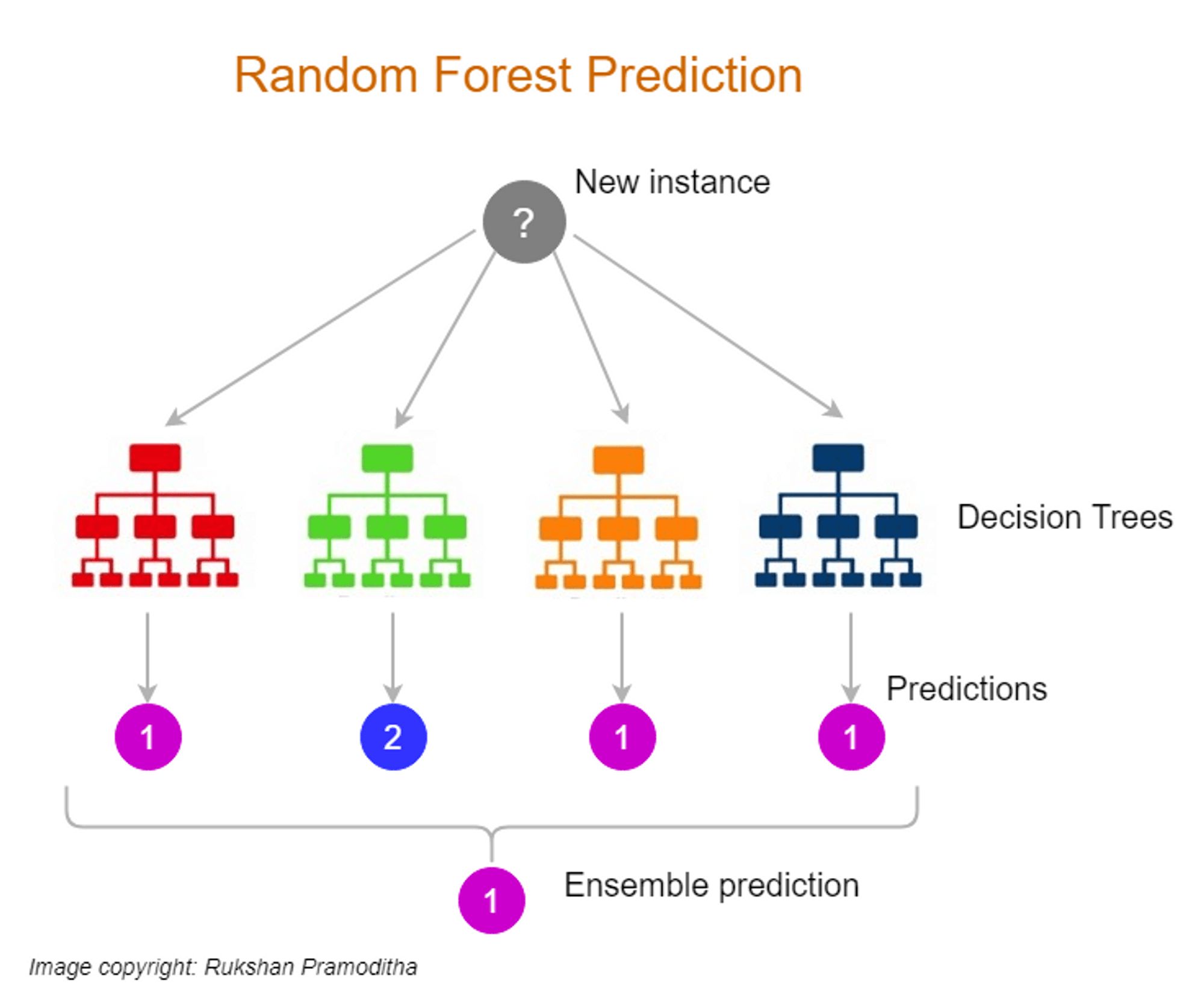
Once the base learners are trained, the next step is to combine their predictions. There are various methods to accomplish this, depending on the ensemble algorithm being used. One common approach is majority voting, where each base learner votes for a class or category, and the class with the most votes is selected as the final prediction. This approach works well for classification problems.
In regression problems, the predictions of the base learners can be combined by averaging their outputs. This can be a simple average or a weighted average, where certain base learners have more influence on the final prediction based on their performance or expertise.
The final step is to make a prediction using the combined predictions of the base learners. This can be done by taking the majority vote in classification problems or averaging the outputs in regression tasks. The ensemble model’s prediction is typically more accurate and robust than that of any individual base learner, as it benefits from the collective knowledge and perspectives of the ensemble.
To ensure the effectiveness of ensemble learning, it is crucial to maintain the diversity and independence of the base learners. If the base learners are too similar or correlated, the ensemble may not yield significant improvements in performance. Techniques like bagging and boosting are employed to introduce diversity in the ensemble models by using different training data subsets or applying weightings to the training examples, respectively.
Overall, ensemble learning leverages the wisdom of crowds by combining multiple models to improve prediction accuracy and generalization. By carefully selecting and training diverse base learners and implementing suitable combination techniques, ensemble learning can overcome individual model limitations and achieve superior performance.
Types of Ensemble Learning
Ensemble learning offers a variety of techniques to combine multiple models, each with its own strengths and characteristics. Here are three commonly used types of ensemble learning: bagging, boosting, and stacking.
1. Bagging
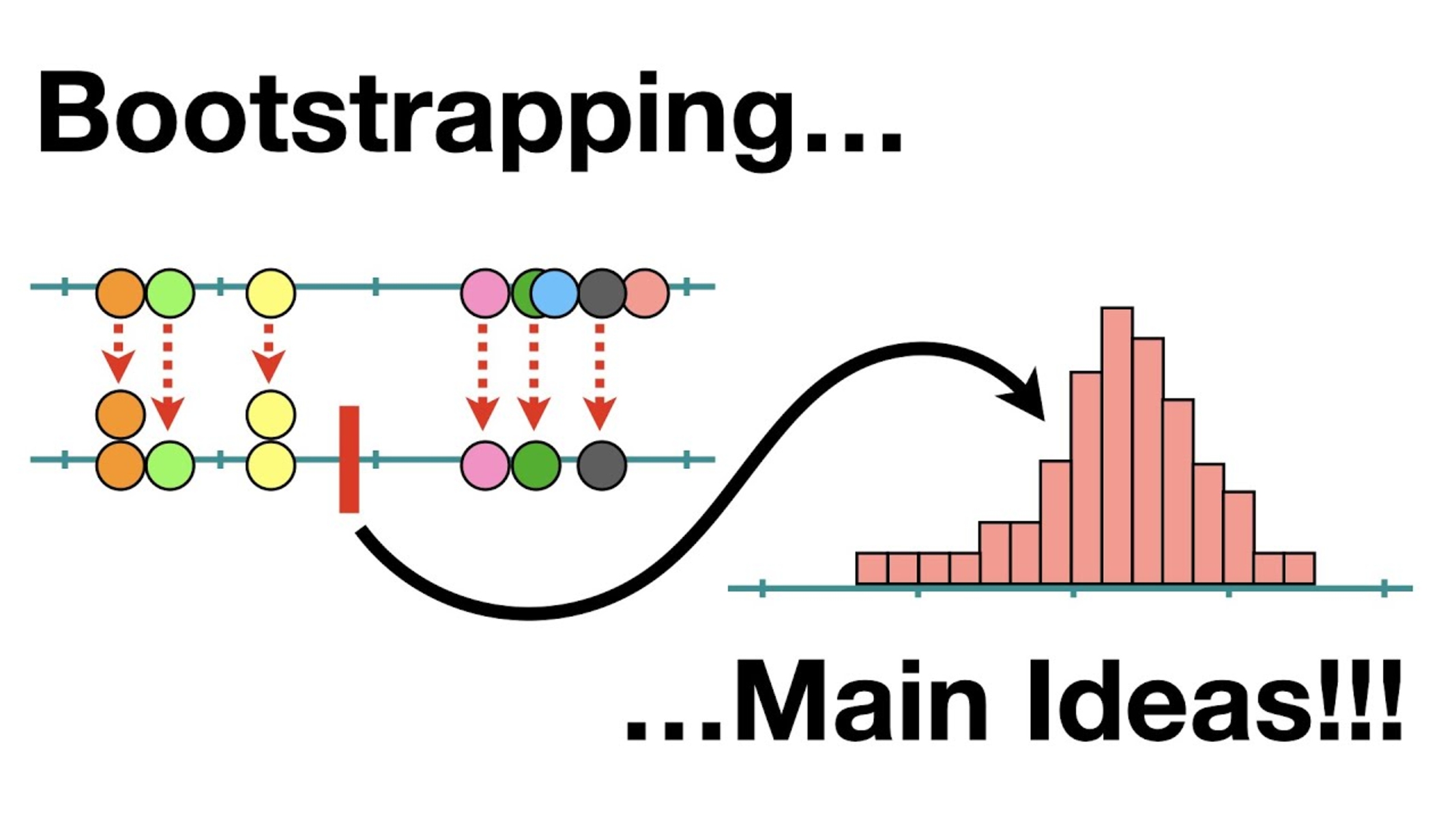
Bagging, short for bootstrap aggregating, is an ensemble learning technique that involves training multiple base learners on different bootstrap samples of the training data. Each base learner is trained independently and has an equal weight in the final ensemble. In bagging, the predictions of the base learners are combined through averaging or majority voting to reach the final prediction. Bagging helps to reduce the variance of the ensemble model and can be used with different base learning algorithms, such as decision trees (Random Forest), neural networks (Bagging Neural Networks), or support vector machines (Bagging SVM).
2. Boosting
Boosting is another popular ensemble learning technique that focuses on iteratively improving the performance of weak learners. Unlike bagging, boosting assigns different weights to each training example based on how well the base learner performs on them. Initially, all training examples have equal weights, but as the weak learners are trained, the weights are adjusted to give more influence to the misclassified examples. This process allows subsequent weak learners to focus on the hard-to-classify examples and improve the overall ensemble performance. Common boosting algorithms include AdaBoost (Adaptive Boosting), Gradient Boosting, and XGBoost (Extreme Gradient Boosting).
3. Stacking
Stacking, also known as stacked generalization, is a more sophisticated ensemble learning technique that combines the predictions of multiple base learners using a meta-learner or a stacking model. In stacking, the base learners are trained on the same training data, and their predictions are used as features for the meta-learner. The meta-learner then takes these base learner predictions as input and learns to make the final prediction. By incorporating the predictions of multiple base learners, stacking can capture higher-level relationships and interactions among the models. Stacking is often used when there is a diverse set of base learners or when the problem domain is complex and requires more advanced modeling techniques.
Each type of ensemble learning has its own advantages and disadvantages. Bagging is effective in reducing variance and improving stability, while boosting focuses on minimizing bias and evolving weak learners into strong ones. Stacking allows for more complex model relationships and interactions. The choice of ensemble learning technique depends on the specific problem and the characteristics of the dataset. Experimentation and analysis are often required to determine the most suitable approach for a given scenario.
Bagging
Bagging, an abbreviation for bootstrap aggregating, is a popular ensemble learning technique that aims to reduce variance and improve the stability of the final model. It involves training multiple base learners on different bootstrap samples of the training data and combining their predictions to make the final prediction.
In bagging, the base learners are trained independently and have equal weightage in the ensemble. Each base learner is trained on a random subset of the training data, created by randomly sampling the original dataset with replacement. This means that some instances may be included multiple times, while others may be left out. By creating these bootstrap samples, bagging introduces variation in the training data and allows each base learner to learn from a different perspective.
Once the base learners are trained, their predictions are combined using either averaging or majority voting. In classification tasks, the ensemble prediction is determined by taking the majority vote of the base learners. For example, if there are three base learners and two of them predict class A while one predicts class B, the ensemble prediction will be class A. In regression tasks, the predictions of the base learners are averaged to obtain the final prediction.
The key advantage of bagging is that it helps reduce the variance of the ensemble model. By training multiple base learners on different subsets of the data, bagging allows each model to capture different aspects and nuances of the problem. The ensemble model can then combine these diverse perspectives to achieve more accurate predictions. Bagging is particularly effective when the base learners are weak learners, meaning they have low individual accuracy but can contribute useful information when combined.
Bagging can be applied with various base learning algorithms, such as decision trees, neural networks, or support vector machines. One popular implementation of bagging is the Random Forest algorithm, which uses an ensemble of decision trees. Each decision tree in the Random Forest is trained on a different bootstrap sample of the data, and the final prediction is obtained by averaging the predictions of all trees. Random Forests have proven to be highly effective in a wide range of classification and regression tasks.
It is important to note that bagging is not suitable when the base learners are highly correlated or when the dataset has no inherent randomness. In such cases, the variation introduced by bagging may not result in improved performance. Therefore, it is essential to assess the independence and diversity of the base learners before applying bagging as an ensemble technique.
In summary, bagging is an ensemble learning technique that combines the predictions of multiple base learners trained on different bootstrap samples of the data. By reducing variance and leveraging the collective knowledge of diverse models, bagging can improve the stability and accuracy of the final ensemble prediction. It is a commonly used method in machine learning, with Random Forests being a notable application of bagging in decision tree-based models.
Boosting
Boosting is a powerful ensemble learning technique that focuses on iteratively improving weak learners to create a strong ensemble model. It aims to reduce bias and improve overall performance by assigning weights to training examples and giving more emphasis to misclassified instances.
The boosting process starts by training a base learner on the original training data. This base learner is typically a simple and weak classifier or regressor that performs slightly better than random guessing. After the training, weights are assigned to each training example based on how well the base learner performed on them. Initially, all training examples have equal weights.
In each subsequent boosting iteration, the weights of the misclassified examples are increased, while the weights of correctly classified examples are decreased. This allows the subsequent weak learners to focus more on the challenging examples and improve their ability to classify them correctly. The weights are updated using a specific boosting algorithm, such as AdaBoost (Adaptive Boosting) or Gradient Boosting.
The process of boosting continues for a predetermined number of iterations or until a predefined performance threshold is met. At the end of the boosting process, the base learners are combined, and their predictions are weighted based on their individual performance. The final ensemble prediction is obtained by summing or averaging the weighted predictions of the base learners.
The strength of boosting lies in its ability to convert multiple weak classifiers into a strong ensemble. By iteratively adjusting the weights and focusing on the misclassified examples, boosting improves the overall performance of the ensemble model and reduces both bias and variance. Boosting is particularly effective when there is a large amount of noisy or ambiguous data, as it can adapt to the complexity of the problem and learn from misclassifications.
AdaBoost, one of the most popular boosting algorithms, assigns weights to the base learners based on their accuracy in the previous iteration. It adjusts the weights of the misclassified examples to make them more influential in the subsequent iterations. Gradient Boosting, on the other hand, uses gradient descent to minimize an error function, such as mean squared error, and updates the base learners based on the negative gradient of the error. XGBoost (Extreme Gradient Boosting) is an optimized implementation of gradient boosting that provides excellent performance and scalability.
Boosting is a widely used ensemble learning technique that has shown great success in various domains, including computer vision, natural language processing, and fraud detection. However, it is important to keep in mind that boosting can be sensitive to outliers and noisy data, which may affect its performance. Additionally, boosting can be computationally expensive and may require careful tuning of hyperparameters to achieve the best results.
In summary, boosting is an ensemble learning technique that iteratively improves weak learners to create a strong ensemble model. By adjusting weights and focusing on misclassified examples, boosting effectively reduces bias and improves performance. Algorithms such as AdaBoost and Gradient Boosting are commonly used to implement boosting and have demonstrated success in a wide range of machine learning tasks.
Stacking
Stacking, also known as stacked generalization, is a sophisticated ensemble learning technique that combines the predictions of multiple base models using a meta-learner. It allows the ensemble model to capture higher-level relationships and interactions among the base models, leading to improved predictive performance.
In stacking, the base models, also known as level-0 models, are first trained on the original training data. Each base model may use a different algorithm or have variations in hyperparameters to introduce diversity. The base models make predictions on the validation set, which is a subset of the training data that was not used for training. These predictions then become the input features for the meta-learner.
The meta-learner, also known as the level-1 model, combines the predictions of the base models to make the final prediction. It is trained on the validation set, where the true class labels or target values are known. The meta-learner learns to determine the optimal weights or relationships between the base model predictions to maximize the predictive accuracy on this validation set.
After training the meta-learner using the validation set, the stacked ensemble model is ready for making predictions on new, unseen data. The base models generate predictions on the test set, and these predictions are then used as input features for the meta-learner. The meta-learner combines the predictions of the base models to make the final prediction.
Stacking allows the ensemble model to learn from the diverse predictions of the base models and exploit interdependencies between them. By incorporating higher-level information and capturing nonlinear relationships, stacking can achieve better predictive performance compared to individual base models.
One challenge with stacking is avoiding overfitting. To mitigate this, it is common to use cross-validation during the training phase. Cross-validation involves splitting the training data into multiple folds, training the base models on some folds, and making predictions on the remaining fold. These predictions from different folds are then combined to create the stacked ensemble. This technique helps to ensure the generalizability of the meta-learner and prevent it from memorizing the training data.
Stacking can be used with various types of models and algorithms, ranging from simple ones like decision trees and logistic regression to more complex ones like support vector machines and neural networks. The flexibility in model selection and architecture makes stacking a versatile technique in ensemble learning.
However, it is important to note that stacking can be computationally expensive and requires a substantial amount of training data to effectively learn the relationships between the base models. Additionally, the performance of stacking heavily depends on the quality and diversity of the base models. Selecting a diverse set of strong base models is crucial in improving the effectiveness of the stacked ensemble.
In summary, stacking is an innovative ensemble learning technique that combines the predictions of multiple base models using a meta-learner. It leverages the diverse predictions of the base models to capture higher-level relationships and achieve improved predictive performance. Through careful model selection and training, stacking can be a powerful tool in machine learning and help solve complex prediction problems.
Advantages of Ensemble Learning
Ensemble learning offers several advantages over individual models, making it a popular and effective approach in machine learning. Here are some key advantages of ensemble learning:
1. Improved Prediction Accuracy:
One of the primary advantages of ensemble learning is its ability to improve prediction accuracy. By combining the predictions of multiple diverse models, ensemble learning can overcome individual model biases and errors. The ensemble model can capture hidden patterns and make more accurate predictions by leveraging the collective knowledge of the base learners.
2. Robustness and Generalization:
Ensemble learning enhances the robustness and generalization of the model. The aggregation of predictions from multiple base learners helps to reduce the risk of overfitting and improves the model’s ability to handle noisy or incomplete data. This can result in a more reliable model that performs well on unseen data.
3. Handling Complexity:
Ensemble learning is particularly effective in handling complex problems. By combining the strengths of different base models, ensemble learning can address different aspects of the problem and capture diverse perspectives. This is especially useful in situations where there is high variation, ambiguity, or uncertainty in the data.
4. Error Detection and Correction:
Ensemble learning can help identify and correct errors in the predictions of individual models. If a base learner consistently makes incorrect predictions, the ensemble model can determine that the particular learner is unreliable and assign less weight to its predictions. This error detection and correction mechanism further improves the overall accuracy and reliability of the ensemble model.
5. Versatility in Model Selection:
Ensemble learning allows for the combination of different types of models and algorithms. This flexibility enables the use of diverse base learners, which can capture different types of relationships and characteristics in the data. By employing a variety of models, ensemble learning maximizes the potential for finding the best possible solution to a given problem.
6. Adaptability to Changing Data:
Ensemble learning is adaptable to changing data environments. If the characteristics of the data change over time, such as a concept drift, the ensemble model can adjust by adding or removing base learners or adjusting their weights. This ability to adapt makes ensemble learning suitable for dynamic and evolving data scenarios.
Overall, ensemble learning provides several advantages that make it a powerful tool in machine learning. By incorporating the strengths of multiple models, ensemble learning achieves improved prediction accuracy, robustness, and adaptability. It is a versatile approach that can handle complex problems and leverage different types of models and algorithms. These advantages make ensemble learning a valuable technique in various domains and applications of machine learning.
Disadvantages of Ensemble Learning
While ensemble learning offers numerous advantages, it is essential to be aware of the potential limitations and disadvantages associated with this approach. Here are some key drawbacks of ensemble learning:
1. Increased Complexity:
Ensemble learning can introduce additional complexity, both in terms of implementation and understanding. The process of training and combining multiple models requires additional resources and computational power. Moreover, the ensemble model’s increased complexity might make it challenging to interpret and explain the underlying prediction rationale.
2. Time-consuming Training:
Ensemble learning often requires training multiple base learners, which can be time-consuming, especially for computationally expensive models or large datasets. The training time increases linearly with the number of base learners, making the ensemble learning process inefficient in situations where training time is a critical factor.
3. Overfitting:
Although ensemble learning aims to reduce overfitting, it is still possible for the ensemble model to overfit the training data, especially if the base learners are excessively complex or if there is a lack of diversity among them. Overfitting occurs when the ensemble model becomes too specialized in the training data, leading to poor generalization on new, unseen data.
4. Sensitivity to Noisy Data:
Ensemble learning can be sensitive to noisy or misleading data. If the training set contains outliers or incorrect labels, some base learners may overly rely on these noisy samples, leading to degraded overall performance. Preprocessing techniques, such as outlier removal or data cleaning, may be necessary to minimize the negative impact of noisy data.
5. Increased Model Complexity:
Ensemble learning often results in a more complex model architecture, which can lead to challenges in deployment and maintenance. The increased complexity might require more computational resources for making predictions and storing the model parameters. Consequently, the deployment and scalability of ensemble models may be more demanding compared to individual models.
6. Skill and Expertise Requirements:
Effectively implementing ensemble learning techniques requires in-depth knowledge and understanding of various algorithms and their interactions. Selecting appropriate ensemble methods, determining the optimal number of base learners, and tuning hyperparameters require expertise and experimentation. The skill level required to master ensemble learning can be higher compared to traditional machine learning approaches.
It is important to consider these limitations and challenges when deciding whether to use ensemble learning. The complexity, training time, increased sensitivity to noisy data, and potential overfitting should be carefully evaluated before choosing ensemble learning as an approach. Additionally, sufficient resources and expertise are necessary to deal with the added complexity and to ensure effective implementation and deployment of ensemble models.
Conclusion
Ensemble learning is a powerful technique in machine learning that combines the predictions of multiple individual models to create a stronger and more accurate predictive model. By leveraging the diversity and collective intelligence of the ensemble, ensemble learning can overcome the limitations of individual models, improve prediction accuracy, and enhance generalization to unseen data.
Throughout this article, we explored the various aspects of ensemble learning, including its definition, how it works, the different types of ensemble methods like bagging, boosting, and stacking, and examined its advantages and disadvantages. Ensemble learning offers significant benefits, such as improved prediction accuracy, robustness, handling of complexity, error detection and correction, versatility in model selection, and adaptability to changing data.
However, it is important to consider the potential drawbacks of ensemble learning, such as increased complexity, time-consuming training, overfitting, sensitivity to noisy data, increased model complexity, and the skill and expertise requirements associated with implementing and maintaining ensemble models.
Nevertheless, with careful consideration and appropriate use, ensemble learning can be a valuable tool in solving complex machine learning problems and achieving superior predictive performance. It allows for the combination of different models, algorithms, and perspectives to overcome individual model limitations and to make more accurate and reliable predictions.
To successfully apply ensemble learning, it is crucial to select diverse and independent base learners, employ suitable combination techniques, and understand the characteristics and limitations of the data and problem at hand. By doing so, one can harness the full potential of ensemble learning and leverage its advantages in enhancing the accuracy and robustness of machine learning models.