The Definition of Bootstrapping in Machine Learning
Bootstrapping is a powerful technique in machine learning that involves generating multiple training datasets through resampling with replacement. It is commonly used to estimate the stability and uncertainty of a model’s predictions. The term “bootstrapping” originates from the phrase “to pull oneself up by one’s bootstraps,” illustrating the idea of self-sufficiency and leveraging available resources.
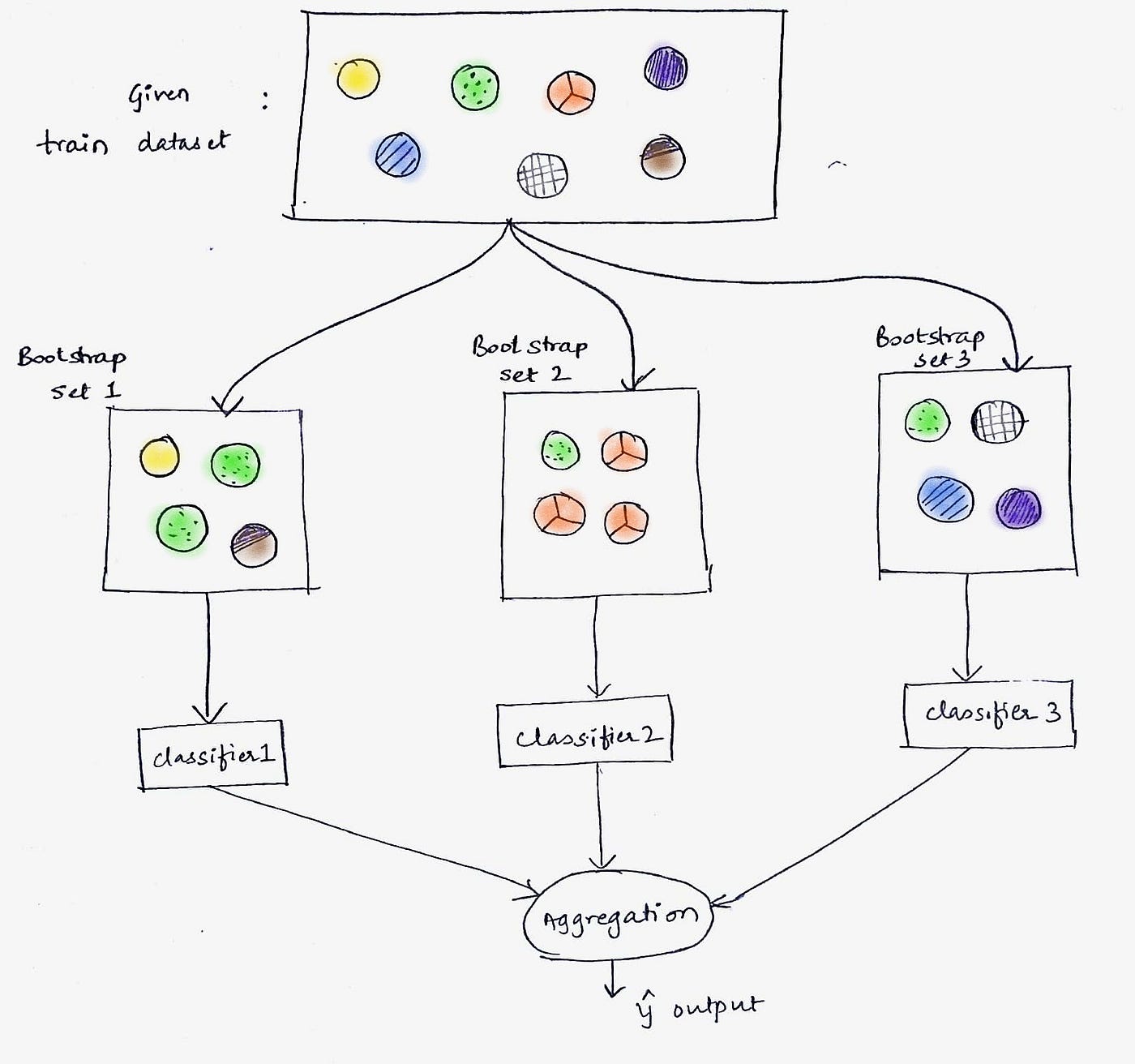
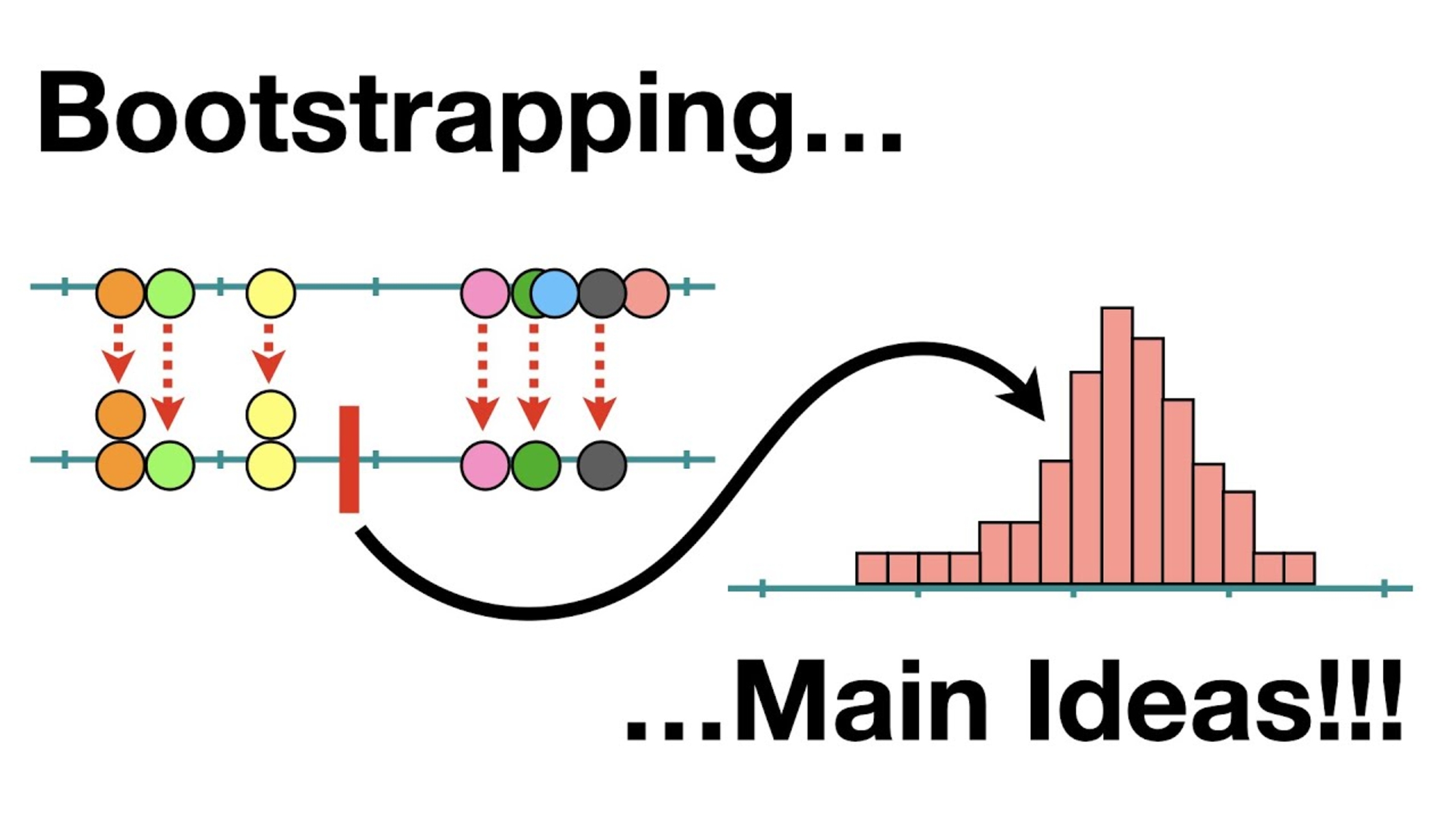
In the context of machine learning, bootstrapping refers to the process of iteratively creating new training datasets by randomly sampling observations from the original dataset. Each new dataset is of the same size as the original, but some observations may be repeated, while others may be left out. This resampling technique allows for the generation of multiple datasets that simulate the complexity and variability present in the real-world data.
The key principle behind bootstrapping is that by creating multiple datasets, we can better understand the stability and uncertainty of our models. By training our models on different variations of the data, we can observe how they perform and make more reliable predictions by taking into account the potential variations that exist in the underlying data.
Bootstrapping has various applications in machine learning, including estimating model parameters, measuring predictive performance, and building ensemble models. It is particularly useful when the available dataset is limited, and we want to make the most of the available information.
Overall, bootstrapping provides a robust and elegant solution for understanding the variability and stability of machine learning models. By creating multiple training datasets and leveraging resampling techniques, we can gain insights into the uncertainty and reliability of our models’ predictions, leading to more informed decision-making in various domains.
How Does Bootstrapping Work in Machine Learning?
Bootstrapping in machine learning revolves around the concept of resampling, where new training datasets are generated by sampling the original dataset with replacement. The process involves the following steps:
- Step 1: Random Sampling
- Step 2: Training and Predicting
- Step 3: Repeat and Average
During bootstrapping, a new training dataset is created by randomly selecting observations from the original dataset. Each observation has an equal probability of being selected, and once chosen, it is placed back into the original dataset, allowing for potential duplicates and exclusions.
The newly generated dataset is then used to train a machine learning model. This could be any algorithm such as decision trees, random forests, or support vector machines. The model learns from the variability present in the bootstrapped dataset and generates predictions for unseen data based on this training.
The process of random sampling and training is repeated multiple times, generating different bootstrapped datasets and corresponding models. Each model independently generates predictions for unseen data. Finally, the predictions from all the models are averaged to obtain a more robust and stable estimate.
Bootstrapping is commonly used in machine learning for several reasons:
- Estimating Model Parameters: Bootstrapping helps estimate the statistical properties of the model’s parameters, such as the mean, variance, and confidence intervals.
- Measuring Predictive Performance: By generating multiple bootstrapped datasets, the predictive performance of the model can be evaluated with improved accuracy, allowing for a more accurate assessment of its effectiveness.
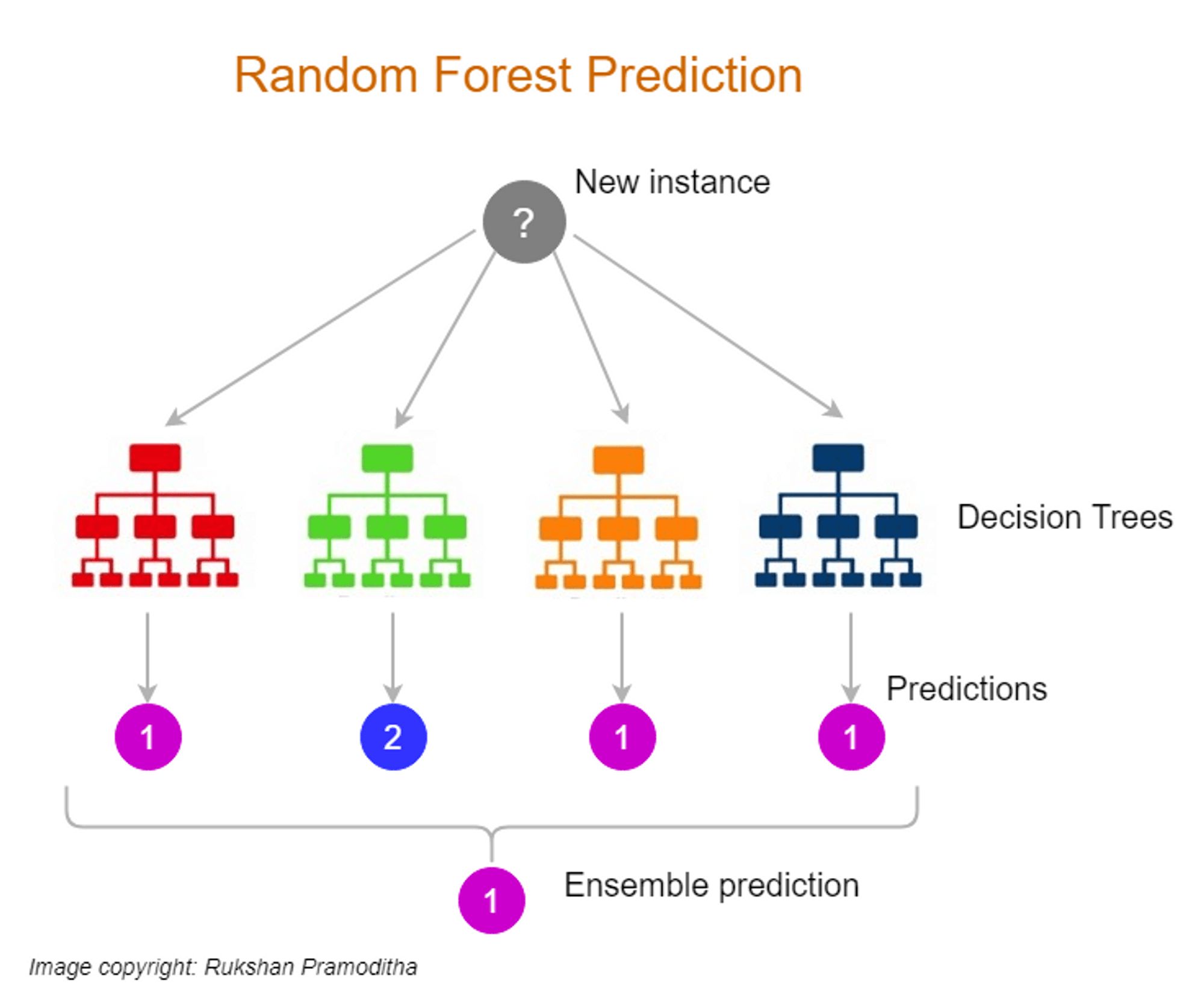
- Building Ensemble Models: Bootstrapping is used in the creation of ensemble models, such as bagging and random forests, where multiple models are combined to make predictions and improve overall performance.
However, it is essential to note that bootstrapping introduces some uncertainty and potential biases due to the resampling process. The availability of a more extensive dataset can help reduce these issues, making the results more reliable and accurate.
Overall, bootstrapping is a powerful technique in machine learning that allows for better estimation of model parameters, improved predictive performance evaluation, and the creation of ensemble models. By leveraging resampling techniques, bootstrapping provides a valuable tool for dealing with limited data and understanding the stability and variability of machine learning models.
Advantages of Bootstrapping in Machine Learning
Bootstrapping is a widely used technique in machine learning due to its numerous advantages. Let’s explore some of the key benefits of bootstrapping:
- Estimating Model Performance:
- Handling Limited Data:
- Building Ensemble Models:
- Handling Variability and Uncertainty:
Bootstrapping allows for a reliable estimation of a model’s performance. By creating multiple bootstrapped datasets and training models on each of them, we can obtain a more accurate assessment of the model’s predictive capabilities. This helps in understanding the model’s strengths and weaknesses and provides valuable insights for model refinement.
Bootstrapping is particularly useful when the available dataset is small or limited. Instead of relying solely on a small number of observations, bootstrapping generates multiple datasets by resampling the existing data. This enhances the training process by providing a larger and more diverse training sample, leading to more robust and generalizable models.
Bootstrapping plays a crucial role in the creation of ensemble models. Ensemble models combine the predictions of multiple models to improve overall performance and reduce the risk of overfitting. By generating different bootstrapped datasets and training models on each, bootstrapping enables the aggregation of diverse model outputs, resulting in more accurate and reliable predictions.
Bootstrapping provides a mechanism for understanding the variability and uncertainty in machine learning models. By generating multiple bootstrapped datasets, we can observe how the models perform under different training conditions. This helps quantify the uncertainty associated with the predictions and facilitates better decision-making by considering the range of potential outcomes.
Overall, bootstrapping is a versatile technique that offers several advantages in machine learning. It allows for accurate estimation of model performance, handles limited data effectively, facilitates the creation of ensemble models, and enables the handling of variability and uncertainty. By leveraging bootstrapping, we can enhance the robustness and reliability of our machine learning models and make more informed predictions and decisions.
Disadvantages of Bootstrapping in Machine Learning
While bootstrapping is a powerful technique in machine learning, it is not without its limitations and disadvantages. Here are some drawbacks to consider when using bootstrapping:
- Potential Bias:
- Computational Intensity:
- Overfitting:
- Small Sample Size:
Bootstrapping relies on resampling from the original dataset, which means that some observations may be repeatedly selected while others may never be included. This inherent sampling bias can introduce a skewed representation of the underlying data and potentially impact the generalizability of the model.
Bootstrapping involves repeatedly generating new datasets, training models, and evaluating their performance. This iterative process can be computationally intensive and time-consuming, particularly when dealing with large datasets or complex models. It requires sufficient computational resources and may not be feasible in situations with limited computational power.
Bootstrapping can potentially lead to overfitting if not carefully managed. As each bootstrapped dataset contains variations of the original data, models trained on these datasets may become overly tuned to the idiosyncrasies and noise present in the training sets. This can result in models that perform well on training data but struggle with generalization to unseen data.
Bootstrapping may not be effective when working with small sample sizes. In such cases, the resampling process may not generate enough variability to accurately represent the underlying data distribution. This can limit the usefulness of bootstrapping for estimating model performance or building reliable ensemble models.
Despite these disadvantages, it is important to note that the limitations of bootstrapping can often be mitigated by careful implementation and consideration of the specific problem at hand. Understanding and addressing these drawbacks can help make the most of the benefits provided by bootstrapping and enable more robust and reliable machine learning models.
Common Applications of Bootstrapping in Machine Learning
Bootstrapping is a versatile technique that finds applications across various domains in machine learning. Some of the common use cases of bootstrapping include:
- Estimating Model Parameters:
- Predictive Performance Assessment:
- Building Ensemble Models:
- Missing Data Imputation:
- Model Validation and Selection:
- Model Robustness Assessment:
Bootstrapping is often used to estimate the statistical properties of model parameters. By generating multiple bootstrapped samples and training models on each sample, we can obtain robust estimates of parameters such as mean, variance, and confidence intervals. This allows for a more accurate understanding of the underlying data distribution and the model’s reliability.
Bootstrapping is useful for evaluating and comparing the predictive performance of different machine learning models. By generating multiple bootstrapped datasets, models can be trained and validated on each dataset independently. This enables a more reliable assessment of the models’ performance, including metrics like accuracy, precision, recall, and area under the curve (AUC).
Bootstrapping plays a critical role in the creation of ensemble models. Ensemble models combine the predictions of multiple models to improve overall performance and generalization. Bootstrapping provides the necessary foundation for generating diverse models through resampling, resulting in a more robust ensemble that can handle a wide range of data patterns.
Bootstrapping can be employed to address missing data issues in machine learning. By generating bootstrapped samples, missing values are imputed using various techniques such as mean imputation, regression imputation, or hot deck imputation. Multiple imputed datasets can then be created, and models are trained on each dataset to handle missing data effectively.
Bootstrapping is valuable for validating and selecting the best model among a set of candidates. By generating multiple bootstrapped samples, trained models can be evaluated on each sample independently, providing insights into performance variation and identifying models that consistently perform well. This aids in choosing the most suitable model for the task at hand.
Bootstrapping allows for assessing the robustness of machine learning models to different perturbations in the training data. By generating bootstrapped samples, models can be trained on each sample and evaluated on the original dataset. This helps identify models that are more resilient to noise, outliers, or variations in the data.
Overall, bootstrapping is a versatile technique that finds diverse applications in machine learning. It supports estimation of model parameters, assessment of predictive performance, building ensemble models, handling missing data, model validation and selection, and assessing model robustness. By leveraging bootstrapping, machine learning practitioners can enhance their analysis and build more reliable and accurate models for various tasks and domains.
Steps to Implement Bootstrapping in Machine Learning
Implementing bootstrapping in machine learning involves several steps to generate bootstrapped datasets and train models on each iteration. Here is a general outline of the steps:
- Data Preprocessing:
- Bootstrapping Iterations:
- Model Training:
- Prediction and Model Aggregation:
- Evaluation and Analysis:
- Iterate and Refine:
Start by preparing and preprocessing your original dataset. This includes cleaning the data, handling missing values, normalizing or scaling features, and any other necessary preprocessing steps specific to your dataset and problem.
Decide on the number of bootstrapped datasets you want to generate. For each iteration, randomly resample observations from the original dataset with replacement to create a new bootstrapped dataset. The size of each bootstrapped dataset should be equal to the size of the original dataset.
Train a machine learning model on each bootstrapped dataset. The choice of the model depends on your specific problem, and it can be any algorithm ranging from decision trees to neural networks.
After training, use each model to make predictions on your original dataset. If the goal is to create an ensemble model, aggregate the predictions of all the models. This can be done by taking the average for regression problems or using voting methods for classification problems.
Evaluate the performance of the bootstrapped models by assessing their predictive accuracy, precision, recall, or any other relevant performance metrics. Compare the performance of the models and analyze their variability to gain insights into model stability and uncertainties.
Iterate through steps 2 to 5 by generating new bootstrapped datasets, training models, making predictions, and evaluating their performance. Consider adjusting the number of bootstrapped datasets, model parameters, or other factors based on the analysis and insights gained from previous iterations.
By following these steps, you can effectively implement bootstrapping in machine learning. Repeat the process multiple times to generate a sufficient number of bootstrapped datasets and capture the variability in the data. This approach helps improve model estimation, assess model stability, and build more reliable machine learning models.
Evaluating the Performance of Bootstrapped Models
Evaluating the performance of bootstrapped models is essential to assess their reliability and make informed decisions based on their predictions. Here are some key considerations for evaluating the performance of bootstrapped models:
- Accuracy Metrics:
- Variability Analysis:
- Comparison to Baseline:
- Bias-Variance Trade-off:
- Model Selection:
- Statistical Significance:
Calculate standard performance metrics to assess the accuracy of the bootstrapped models. These may include metrics such as accuracy, precision, recall, F1-score, or area under the receiver operating characteristic (ROC) curve. Evaluate these metrics on the original dataset to gain insights into how well the models are performing.
Examine the variability in performance across the bootstrapped models. Analyze the range, mean, and standard deviation of performance metrics obtained from the models. This variability analysis helps understand the stability and robustness of the models by quantifying how prediction performance varies across different bootstrapped datasets.
Compare the performance of the bootstrapped models to a baseline model or other non-bootstrapped models trained on the original dataset. This provides a point of reference to assess the improvement or lack thereof achieved through bootstrapping. It helps determine whether the bootstrapped models have enhanced predictive accuracy compared to standard models.
Consider the bias-variance trade-off in the bootstrapped models. High bias indicates underfitting, where the models are not capturing the underlying patterns, while high variance indicates overfitting, where the models are too sensitive to noise. Use techniques like learning curves, validation curves, or bias-variance plots to evaluate the bias-variance trade-off and identify the optimal level of model complexity.
If using bootstrapping for model selection, assess the performance of the different models generated from the bootstrapped datasets. Compare their performance and variability to select the most reliable and stable model. Consider factors such as prediction accuracy, stability, and generalization ability to make an informed choice about which model to use.
Assess the statistical significance of the performance differences observed among the bootstrapped models. Conduct hypothesis testing or build confidence intervals to determine whether the observed differences are statistically significant or simply due to random chance.
By evaluating the performance of bootstrapped models using these approaches, you can gain insights into their accuracy, stability, and robustness. This evaluation process helps identify the most reliable model, understand the sources of variability, and make informed decisions based on the predictions of the bootstrapped models.
Improving Bootstrapping Techniques in Machine Learning
Bootstrapping techniques in machine learning can be enhanced to improve the accuracy, efficiency, and robustness of models. Here are some key ways to improve bootstrapping techniques:
- Advanced Resampling Strategies:
- Cross-Validation Techniques:
- Feature Selection and Dimensionality Reduction:
- Ensuring Diversity:
- Optimization of Hyperparameters:
- Post-Bootstrap Model Aggregation:
Explore advanced resampling strategies to generate more diverse bootstrapped datasets. Techniques like stratified bootstrapping, cluster-based bootstrapping, or resampling with different weights can help better capture the underlying data distribution and reduce potential biases in the resampled datasets.
Combine bootstrapping with cross-validation techniques to further enhance model performance evaluation. Instead of training and evaluating models on a single bootstrapped dataset, use techniques like k-fold cross-validation on each bootstrapped sample. This provides a more reliable estimate of model performance and reduces the impact of randomness in the bootstrapped datasets.
Incorporate feature selection and dimensionality reduction techniques within the bootstrapping process. By including these steps, you can reduce the number of features and focus on the most informative ones, improving model efficiency and generalization. Techniques like forward selection, backward elimination, or principle component analysis (PCA) can help in this regard.
Pay attention to the diversity of models generated from the bootstrapped datasets. Use techniques like bagging with random feature subsets or random subspaces to promote diversity and reduce the risk of overfitting. Ensuring diversity among the bootstrapped models can lead to better ensemble models and improved generalization.
Optimize the hyperparameters of the models during the bootstrapping process. Perform a hyperparameter search on each bootstrapped dataset to find the optimal settings that maximize performance. This helps improve the accuracy and robustness of the models and can lead to better overall performance.
Consider additional techniques for combining the predictions of the bootstrapped models. Instead of simple averaging or voting, explore more advanced ensemble techniques, such as weighted averaging, stacking, or boosting. These techniques can further improve the performance of the combined models and produce more accurate predictions.
By incorporating these approaches, bootstrapping techniques in machine learning can be improved to enhance the accuracy, efficiency, and reliability of models. These improvements help create more robust models that can handle complex data patterns, improve generalization, and deliver more accurate predictions across various domains and applications.
Conclusion
Bootstrapping is a powerful technique in machine learning that allows for the estimation of model parameters, assessment of performance, and building of robust ensemble models. By generating multiple bootstrapped datasets through resampling with replacement, bootstrapping provides a way to explore the variability and uncertainty in the data, leading to more reliable and accurate predictions.
In this article, we explored the definition of bootstrapping and its workings in machine learning. We discussed the advantages of bootstrapping, including its ability to handle limited data, build ensemble models, and assess model performance. However, bootstrapping also has its disadvantages, such as potential bias and overfitting, which should be carefully considered when implementing this technique.
We also examined common applications of bootstrapping, such as estimating model parameters, measuring predictive performance, and imputing missing data. Bootstrapping can also be used for model selection and assessing model robustness in the face of variability and noise in the dataset.
To implement bootstrapping, we outlined the necessary steps, including data preprocessing, bootstrapping iterations, model training, prediction, evaluation, and refinement. These steps help create multiple bootstrapped datasets, train models on each dataset, and assess their predictive performance.
It is important to evaluate the performance of bootstrapped models by considering factors like accuracy metrics, variability analysis, comparison to baselines, and the bias-variance trade-off. Additionally, techniques like statistical significance testing can provide insights into the reliability and significance of observed performance differences.
To enhance bootstrapping techniques in machine learning, it is recommended to explore advanced resampling strategies, incorporate cross-validation techniques, optimize hyperparameters, and focus on ensuring diversity among the bootstrapped models. These improvements can lead to better model performance, efficiency, and generalization.
In conclusion, bootstrapping is a versatile technique in machine learning that enables better estimation, performance evaluation, and model building by leveraging resampling and variability analysis. By utilizing bootstrapping effectively, machine learning practitioners can enhance their models’ accuracy, reliability, and applicability to real-world problems.