Introduction
Machine learning is a powerful field of study that involves training computers to learn from data and make predictions or decisions without being explicitly programmed. One popular technique used in machine learning is bagging, which stands for bootstrap aggregating. Bagging is a method of combining multiple machine learning models to achieve better accuracy and reliability in predictions.
Bagging is widely used in various domains, such as finance, healthcare, and marketing, to solve complex problems and make informed decisions. It is particularly useful when dealing with high-dimensional data, noisy data, or when the underlying relationship between input and output variables is complex and non-linear. By leveraging the power of ensemble learning, bagging can help improve the performance and generalization of machine learning models.
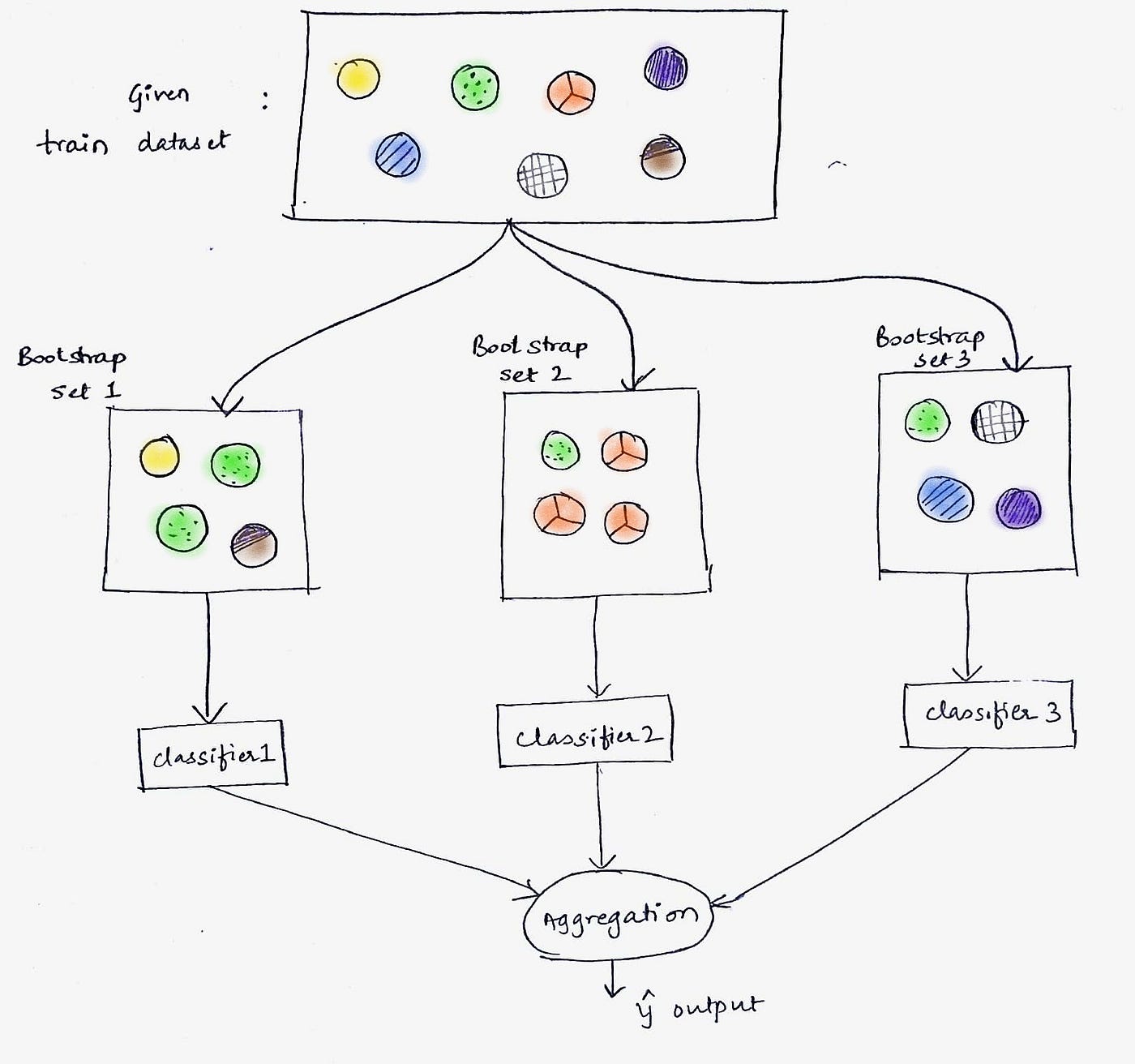
The main idea behind bagging is to create multiple subsets of the original training data, called bootstrap samples, by randomly sampling with replacement. Each bootstrap sample is then used to train a separate model, often referred to as a base or weak learner. The predictions from all the base learners are then combined using a voting or averaging mechanism to make the final prediction.
One of the key advantages of bagging is that it reduces the variance of the model by averaging the predictions of multiple models. This can help mitigate the problem of overfitting and improve the model’s robustness. Additionally, bagging allows for parallelization, as the base learners can be trained independently, making it suitable for large-scale machine learning tasks.
However, like any technique, bagging also has its disadvantages. The main drawback is the increased computational cost, as multiple models need to be trained and predictions need to be combined. Moreover, bagging may not be effective if the base learners are highly correlated or if the underlying algorithm is sensitive to noisy data.
Despite these limitations, bagging has proven to be an effective and widely adopted technique in machine learning. Its applications range from classification and regression to outlier detection and feature selection. In the next sections, we will delve deeper into how bagging works, its advantages and disadvantages, and explore some real-world applications.
Definition of Bagging
Bagging, short for bootstrap aggregating, is a machine learning ensemble technique that aims to improve the accuracy and stability of predictions by combining multiple models. It involves creating multiple subsets, known as bootstrap samples, from the original training data and training a separate model on each of these samples. The predictions from these models are then combined to make the final prediction.
The name “bootstrap” in bagging comes from the bootstrap resampling method, which involves randomly sampling the training data with replacement. This means that each bootstrap sample can contain duplicate instances from the original dataset. By generating multiple bootstrap samples, bagging creates diverse training sets that capture different aspects of the data distribution.
The idea behind bagging is to reduce the variance of the model by averaging the predictions of multiple models trained on different subsets of the data. This can help mitigate the problem of overfitting and improve the generalization ability of the model. While bagging is commonly used with decision trees as the base or weak learner, it can also be applied to other machine learning algorithms.
To combine the predictions of the base learners, bagging employs either voting or averaging. In classification problems, voting is used, where each base learner makes a prediction, and the class with the majority votes is selected as the final prediction. In regression problems, the predictions of the base learners are averaged to obtain the final prediction. The aggregation of predictions helps to reduce the impact of individual model errors and provide a more accurate result.
Bagging can be seen as a parallelization technique, as the base learners can be trained independently and in parallel. This makes bagging suitable for distributed computing environments and large-scale machine learning tasks. Moreover, bagging is robust to noise and outliers, as the aggregation of predictions helps to smooth out the impact of individual erroneous predictions.
Overall, bagging is a powerful technique that leverages ensemble learning to enhance the accuracy and stability of machine learning models. By harnessing the diversity of bootstrapped samples and combining the predictions of multiple models, bagging offers a practical solution for improving the performance of various machine learning algorithms.
How Bagging Works
Bagging, or bootstrap aggregating, is a technique that combines the predictions of multiple models to improve the accuracy and stability of machine learning algorithms. The key steps involved in bagging are as follows:
- Bootstrap Sampling: Bagging starts by creating multiple subsets, called bootstrap samples, from the original training data. Each bootstrap sample is created by randomly sampling the data with replacement, which means that some instances may be repeated while others may be left out. These bootstrap samples have the same size as the original dataset.
- Model Training: Once the bootstrap samples are created, a separate model is trained on each sample. The models can be based on any machine learning algorithm, although decision trees are commonly used as base learners in bagging. Each base learner is trained independently on its respective bootstrap sample.
- Prediction Aggregation: After training the base learners, their predictions are aggregated to make the final prediction. The aggregation method depends on the problem type. In classification tasks, the predictions are combined using majority voting, where the class with the highest number of votes across the base learners is selected. In regression tasks, the predictions are averaged to obtain the final numerical value.
The main idea behind bagging is to exploit the diversity among the base learners. The use of bootstrap sampling ensures that each base learner is trained on a slightly different subset of the data, introducing randomness and diversity into the models. This helps to capture different aspects and patterns of the data, reducing the variance and potential overfitting of the individual models.
Another advantage of bagging is that it allows for parallelization. Since each base learner is trained independently on its bootstrap sample, the training process can be distributed across multiple processors or machines, speeding up the training time for large datasets.
It’s important to note that bagging can be applied to any machine learning algorithm, not just decision trees. In practice, different base learners can be combined to form an ensemble, such as random forests, where bagging is applied to decision trees with additional features like feature randomness.
Overall, bagging works by generating diverse subsets of the training data, training individual models on these subsets, and then combining their predictions to improve the accuracy and stability of machine learning models. Its ability to reduce variance, handle noisy data, and parallelize the training process makes bagging a popular and effective technique in the field of machine learning.
Advantages of Bagging
Bagging, or bootstrap aggregating, offers several advantages that make it a powerful technique in machine learning. Here are some of the key advantages of using bagging:
- Reduced Variance: One of the main advantages of bagging is that it reduces the variance of the model. By training multiple models on different subsets of the data, bagging introduces randomness and diversity into the ensemble. The aggregation of predictions from these diverse models helps to reduce the impact of individual model errors, resulting in a more robust and accurate prediction.
- Overfitting Mitigation: Bagging is particularly effective in mitigating the problem of overfitting. Overfitting occurs when a model becomes too complex and starts to memorize the training data instead of learning the underlying patterns. By training base learners on different bootstrap samples, bagging creates diverse models that capture different aspects of the data. The aggregation of these diverse models helps to smooth out any overly specific patterns, reducing the likelihood of overfitting.
- Noise and Outlier Robustness: Bagging is robust to noise and outliers in the data. Since the base learners are trained on different subsets of the data, the impact of noisy or outlier instances is reduced. The aggregation of predictions from multiple models helps to average out the errors introduced by individual models, resulting in more accurate predictions even in the presence of noisy data.
- Parallelization: Bagging allows for parallelization during the training process. Each base learner is trained independently on its respective bootstrap sample, enabling the training process to be distributed across multiple processors or machines. This parallelization capability speeds up the training time, making bagging suitable for large-scale machine learning tasks.
- Generalization: Bagging improves the generalization ability of machine learning models. By aggregating predictions from multiple models, bagging helps to capture diverse patterns and reduce bias in the predictions. This enhances the model’s ability to generalize to unseen data and perform well on test datasets.
Overall, bagging offers significant advantages in terms of variance reduction, overfitting mitigation, noise and outlier robustness, parallelization, and generalization. These advantages make bagging a valuable technique for improving the accuracy, stability, and robustness of machine learning models.
Disadvantages of Bagging
While bagging, or bootstrap aggregating, offers numerous benefits to machine learning models, it also has certain disadvantages and limitations. It’s important to consider these factors when applying bagging to a problem. Here are some of the main disadvantages of bagging:
- Increased Computational Complexity: One of the drawbacks of bagging is the increased computational cost. Since bagging involves training multiple models on different subsets of the data, it requires more computational resources and time compared to training a single model. The predictions of all the base models also need to be combined, adding to the computational overhead.
- Loss of Interpretability: Bagging can lead to a loss of interpretability in the model. When multiple models are combined and their predictions are aggregated, it becomes challenging to interpret the individual contributions of each model. The ensemble model becomes a black box, making it difficult to understand the reasoning behind specific predictions.
- Correlated Base Learners: Bagging relies on the diversity among the base learners to improve predictions. However, if the base learners are highly correlated, for example when using the same machine learning algorithm with the same hyperparameters, the ensemble’s performance may not improve significantly. The base learners should ideally be diverse, capturing different aspects of the data.
- Sensitivity to Noisy Data: While bagging provides some robustness against noisy data, it is not immune to its effects. If the training data contains significant amounts of noise, the base learners may still make erroneous predictions, and the aggregation process may not be able to resolve these errors completely. Preprocessing the data to clean or handle the noise before applying bagging can help mitigate this issue.
- Model Specificity: Bagging may not be suitable for all machine learning algorithms. In some cases, certain algorithms may not benefit significantly from bagging due to their inherent characteristics. For example, some algorithms may already have built-in mechanisms to handle variance and overfitting, making the variance reduction aspect of bagging less impactful.
Despite these limitations, bagging remains a powerful ensemble learning technique that can enhance the stability and accuracy of machine learning models. It is essential to consider these disadvantages while weighing the benefits and deciding whether to apply bagging to a particular problem.
Applications of Bagging
Bagging, or bootstrap aggregating, has found wide-ranging applications in various domains and problem types within the field of machine learning. Its ability to improve prediction accuracy and stability makes it a valuable technique in several scenarios. Here are some common applications of bagging:
- Classification: Bagging is commonly used in classification tasks, where the goal is to predict the categorical class labels of instances. By training multiple base learners on different bootstrap samples, bagging can effectively reduce variance, mitigate overfitting, and improve the overall classification accuracy. It has been successfully applied to various classification problems, including image recognition, sentiment analysis, and medical diagnosis.
- Regression: Bagging can also be applied to regression problems, where the goal is to predict continuous numerical values. By combining the predictions of different base learners, bagging can reduce the variance and improve the accuracy of regression models. It has been used in regression tasks, such as stock market forecasting, housing price prediction, and demand forecasting.
- Anomaly Detection: Bagging can be used for anomaly detection, where the goal is to identify and flag instances that deviate significantly from the norm. By training multiple base learners on different subsets of the data, bagging can capture different aspects of normal behavior, making it more robust to variations and outliers. It has been applied in detecting credit card fraud, network intrusions, and medical anomalies.
- Ensemble Methods: Bagging serves as the foundation for other ensemble methods, where multiple base learners are combined to form a more powerful model. Random Forest is a popular example that combines bagging with decision trees. Bagging is also used as a component in boosting algorithms, such as AdaBoost and Gradient Boosting, to further enhance their performance.
- Feature Selection: Bagging can be utilized as a feature selection technique. By training base learners on different subsets of features, bagging can identify the most informative features for prediction. The frequency or importance of features across the base learners can provide insights into the relevance of different features.
The applications of bagging are not limited to the above examples, and it can be employed in various other machine learning scenarios. Its versatility and effectiveness in improving model accuracy, stability, and generalization make it a valuable tool for data scientists and machine learning practitioners across different industries and domains.
Example of Bagging Algorithm
To illustrate how bagging works in practice, let’s consider an example of bagging using decision trees as the base learners.
Suppose we have a dataset consisting of various attributes of different types of flowers, such as petal length, petal width, and sepal length. The task at hand is to classify a new instance of a flower into one of three classes: “setosa,” “versicolor,” or “virginica.”
In a bagging algorithm, we would first create multiple bootstrap samples from our training data. Each bootstrap sample is generated by randomly selecting instances from the original dataset with replacement, resulting in a new dataset of the same size as the original but with potential duplicates.
Next, we train a decision tree model on each of these bootstrap samples. Each decision tree is trained independently on its respective bootstrapped dataset, learning different aspects of the underlying patterns in the data.
During the training process, each decision tree considers a random subset of features at each split, creating further diversity among the base learners. This random feature selection helps to reduce correlation and enhances the overall performance of the ensemble.
Once all the decision trees are trained, we can make predictions using the aggregated knowledge of the ensemble. For classification tasks, we can use majority voting to determine the final predicted class. Each decision tree makes its own prediction, and the class that receives the majority of votes across the trees is selected as the final prediction.
Similarly, for regression tasks, we can take the average of the predictions made by each decision tree to obtain the final prediction.
The predictive power of the ensemble is often superior to that of any individual decision tree due to the reduction of overfitting and the capturing of diverse patterns in the data. The aggregation process helps to smooth out biases and errors in individual predictions.
In this example, bagging with decision trees can improve the accuracy and robustness of flower classification by combining the knowledge of multiple decision trees trained on different bootstrap samples. This ensemble approach reduces the variance of the predictions and allows for more reliable and accurate classifications.
Overall, this example illustrates how bagging can be used with decision trees as base learners to improve the performance of machine learning models in classification tasks.
Conclusion
Bagging, or bootstrap aggregating, is a powerful technique in machine learning that combines the predictions of multiple models to improve accuracy and stability. By creating diverse subsets of the training data and training separate models on these subsets, bagging reduces variance, mitigates overfitting, and enhances the generalization ability of machine learning models.
We explored the definition and working of bagging, highlighting its advantages and disadvantages. Bagging reduces the variance of models, making them more robust and accurate. It also offers noise and outlier robustness and allows for parallelization of the training process. However, bagging comes with increased computational complexity and the potential loss of interpretability.
Bagging finds applications in various domains, including classification, regression, anomaly detection, ensemble methods, and feature selection. Its ability to improve prediction accuracy and stability makes it a valuable tool in numerous machine learning scenarios.
We also discussed an example of how bagging can be applied using decision trees as the base learners. By generating bootstrap samples and training decision trees independently, we can combine their predictions to make accurate classifications or regression predictions.
In conclusion, bagging is a versatile and effective technique in machine learning that can enhance the performance and robustness of models. Its ability to reduce variance, handle noisy data, and improve generalization makes it a valuable tool for data scientists and machine learning practitioners.