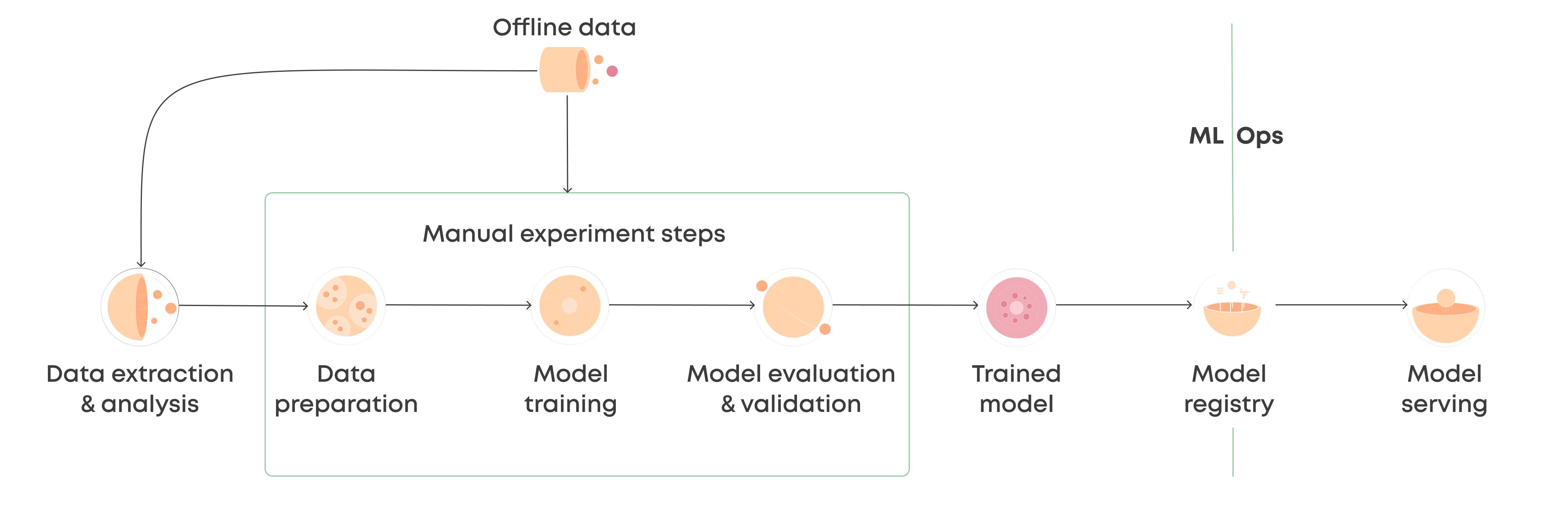
Assess the Existing System
Before adding a machine learning component to an existing system, it is crucial to thoroughly assess the current system and its performance. This initial step helps identify the areas where machine learning can make a significant impact and determine the feasibility of integration.
To begin, analyze the functionality and structure of the existing system. Understand how it operates, the inputs it requires, and the outputs it produces. This evaluation will provide insights into the system’s strengths, weaknesses, and potential areas for improvement.
Consider the performance metrics of the system, such as accuracy, efficiency, and scalability. Identify any pain points or bottlenecks that may hinder its performance. This assessment helps determine whether a machine learning component can address these limitations and enhance the overall system.
Another crucial aspect is evaluating the available data. Examine the quality, volume, and variety of the data that the system currently utilizes. Machine learning algorithms require high-quality and relevant data to generate accurate predictions or insights. If the existing system lacks sufficient data or has data quality issues, data collection or preparation may be necessary before proceeding with machine learning integration.
Furthermore, consider the hardware and software infrastructure that supports the existing system. Ensure it can accommodate the computational requirements of machine learning algorithms. If necessary, assess if any upgrades or modifications are needed to handle the increased computational demands.
A comprehensive understanding of the existing system will help define the scope and objectives of the machine learning component. It will also aid in identifying the specific problem or challenge that the machine learning component aims to address.
In summary, assessing the existing system involves analyzing its structure, performance metrics, data availability, and infrastructure. This assessment lays the foundation for incorporating a machine learning component by identifying areas for improvement and defining the problem that needs to be solved. By evaluating the existing system, you can make informed decisions about the integration of machine learning technologies.
Define the Problem
Once the existing system has been thoroughly assessed, the next step in adding a machine learning component is to clearly define the problem that needs to be solved. This step is crucial as it sets the direction for the machine learning solution and ensures that it aligns with the system’s goals and objectives.
Start by identifying the specific challenge or issue that the machine learning component will address. Pinpoint the areas where the existing system falls short or where improvements can be made. Is it a classification problem, regression problem, anomaly detection, or recommendation engine? Defining the problem will shape the selection of machine learning algorithms and the subsequent steps of model development.
It is essential to consider the impact that solving this problem can have on the overall system. Will it improve efficiency, accuracy, or user experience? Understanding the potential benefits will help prioritize resources and efforts towards problem-solving.
Additionally, defining the problem involves setting clear and measurable objectives. Specify what success looks like for the machine learning component. This could be achieving a certain level of accuracy, reducing errors, or increasing the system’s performance. Well-defined objectives provide a benchmark for evaluating the effectiveness of the machine learning solution.
Consider the constraints and limitations surrounding the problem. Are there any resource constraints, time restrictions, or privacy concerns that need to be taken into account? Understanding these constraints will help determine the feasibility and practicality of the machine learning solution.
Moreover, it is essential to involve stakeholders and gather their input during the problem definition phase. Engage with individuals who interact with the existing system and understand their pain points and expectations. This collaboration will ensure that the defined problem reflects the real needs of the users and stakeholders.
In summary, defining the problem is a critical step in adding a machine learning component to an existing system. It involves identifying the specific challenge, setting clear objectives, considering constraints, and involving stakeholders. This process ensures that the machine learning solution is focused, goal-oriented, and aligned with the needs of the system and its users.
Determine the Data Requirements
Once the problem has been clearly defined, the next step in adding a machine learning component to an existing system is to determine the data requirements. Machine learning algorithms rely on high-quality and relevant data to make accurate predictions or provide meaningful insights. Understanding the data needs is crucial for the success of the machine learning integration.
Start by identifying the types of data that are necessary for solving the defined problem. This could include structured data such as numerical values or categorical variables, or unstructured data such as text, images, or audio. Understanding the data types will help determine the appropriate data collection and preparation methods.
Next, assess the quality of the existing data. Analyze its completeness, consistency, and correctness. Is the data clean and free from errors or anomalies? If the quality of the existing data is inadequate, it may be necessary to clean or preprocess it before training the machine learning model. This can involve removing duplicates, filling missing values, or resolving inconsistencies.
Consider the volume of data required. Machine learning algorithms often perform better with larger datasets. Determine if the existing system has sufficient data, or if additional data needs to be collected. This may involve acquiring data from external sources, setting up data collection mechanisms, or leveraging existing data repositories.
Furthermore, analyze the relevance of the data to the defined problem. The data used by the machine learning component should be representative of the scenarios or instances the system encounters. It should capture the patterns, relationships, or behaviors that are relevant to solving the problem. Assessing the relevance of the data will help improve the accuracy and effectiveness of the machine learning model.
Data security and privacy considerations are also important. Identify any sensitive or confidential data that needs to be protected. Ensure that data handling practices comply with relevant regulations and guidelines. Implement appropriate measures to anonymize or encrypt data if necessary.
Finally, consider the scalability of the data. Determine if the existing data infrastructure can handle large volumes of data in terms of storage, processing, and access. If not, evaluate the need for upgrades or modifications to accommodate the data requirements of the machine learning component.
In summary, determining the data requirements involves identifying the types of data needed, assessing the data quality, analyzing the volume and relevance of the data, considering data security and privacy, and evaluating data scalability. This step ensures that the machine learning component has access to the necessary data to produce accurate and meaningful results.
Collect and Prepare the Data
After determining the data requirements, the next step in adding a machine learning component to an existing system is to collect and prepare the data. This stage focuses on gathering the necessary data and transforming it into a suitable format for training the machine learning model.
Data collection involves obtaining the required data from various sources. If the existing system already captures the relevant data, it can be extracted and used for the machine learning component. However, in some cases, additional data collection methods may be necessary. This can involve setting up data collection mechanisms such as sensors, APIs, or web scraping tools. It’s important to ensure that the collected data is representative and relevant to the problem at hand.
Once the data has been collected, the next step is to prepare it for the machine learning model. This stage involves data preprocessing, which includes cleaning, transforming, and formatting the data in a way that allows the machine learning algorithm to effectively learn from it.
Data cleaning involves handling missing values, outliers, and inconsistencies in the data. Missing values can be imputed or removed depending on the data characteristics and the impact on the machine learning model. Outliers, if significant, can be adjusted or removed to improve the robustness of the model. Inconsistencies in the data, such as conflicting values or errors, must be resolved to ensure data integrity.
Feature engineering is another essential aspect of data preparation. This involves selecting, creating, or transforming features in the data that can potentially improve the performance of the machine learning model. Feature selection methods, such as statistical techniques or domain knowledge, can help identify the most relevant features. Feature transformation techniques, such as normalization or scaling, can be applied to ensure that the data is in a suitable range for the machine learning algorithm.
Data splitting is also important during data preparation. The collected data should be divided into training, validation, and testing sets. The training set is used to train the machine learning model, the validation set is used to fine-tune the model and optimize its hyperparameters, and the testing set is used to evaluate the performance of the final model.
Lastly, ensure that the data is in a format that the machine learning algorithm can process. This might involve encoding categorical variables, scaling numerical variables, or converting text or image data into numerical representations.
In summary, collecting and preparing the data involves gathering the necessary data from various sources, cleaning the data, performing feature engineering, splitting the data into appropriate sets, and formatting the data in a suitable format for the machine learning algorithm. This stage ensures that the data is ready to be used for training and evaluating the machine learning model.
Choose the Appropriate Machine Learning Algorithm
Once the data has been collected and prepared, the next step in adding a machine learning component to an existing system is to choose the appropriate machine learning algorithm. The selection of the algorithm depends on the nature of the problem, the characteristics of the data, and the desired outcomes.
There are various types of machine learning algorithms, each designed to address specific types of problems. For instance, classification algorithms are suitable for problems where the goal is to assign data points to predefined categories or classes. Regression algorithms, on the other hand, are used when predicting continuous values. Clustering algorithms help identify hidden patterns or groupings in data, while recommendation algorithms provide personalized recommendations based on user preferences.
Consider the characteristics of the data when selecting the algorithm. Determine if the data is labeled or unlabeled, and if it is linearly separable or non-linearly separable. This information will guide the selection of supervised or unsupervised learning algorithms and the appropriate algorithm specific to the problem.
Evaluate the complexity and interpretability of the algorithm. Some algorithms are more complex and require more computational resources, while others, like decision trees or logistic regression, offer simplicity and interpretability. Choosing an algorithm that aligns with the system’s resources and interpretability requirements is crucial.
Furthermore, assess the scalability of the algorithm. Consider the volume of data expected to be processed and the computational requirements of the algorithm. If the existing system deals with large-scale data, it may be necessary to choose algorithms that are capable of handling such volumes.
Consistently refer back to the defined problem and objectives during the algorithm selection process. Ensure that the chosen algorithm aligns with the desired outcomes and can address the specific challenges identified in the existing system.
Considering the algorithm’s performance, evaluate its accuracy, precision, recall, and F1-score on similar datasets or benchmarks. Assess if the algorithm can handle noise or outliers in the data and if it provides reliable predictions or insights. Consulting existing research, case studies, or domain experts can provide valuable insights into the performance of different algorithms for similar problems.
Ultimately, it may be beneficial to experiment with multiple algorithms and compare their performance on the problem at hand. This exploration can help determine the most suitable algorithm for integration into the existing system.
In summary, choosing the appropriate machine learning algorithm involves considering the problem type, data characteristics, interpretability, scalability, and performance. Selecting the right algorithm is crucial for achieving accurate and meaningful results from the machine learning component.
Train the Model
After selecting the appropriate machine learning algorithm, the next step in adding a machine learning component to an existing system is to train the model. Training the model involves using the prepared data to teach the algorithm to make accurate predictions or provide meaningful insights.
The first step in training the model is to split the prepared data into two subsets: the training set and the validation set. The training set is used to teach the model, while the validation set is used to fine-tune the model and evaluate its performance during the training process.
During training, the algorithm learns the underlying patterns and relationships in the data by adjusting its internal parameters. This process involves an iterative optimization algorithm that minimizes the error or cost function. The goal is to find the set of parameter values that best fit the training data and generalize well to unseen data.
The training process typically involves defining hyperparameters, which are parameters that control the learning process itself. These include the learning rate, batch size, regularization techniques, and the number of training iterations. Tuning these hyperparameters appropriately can greatly impact the model’s performance.
It is essential to monitor the training process to ensure the model is converging to an optimal solution. Evaluate the performance metrics, such as accuracy, loss function value, or other relevant metrics, during each training iteration. Analyze the trends and make adjustments to the hyperparameters if necessary, to improve the model’s performance.
In some cases, feature selection or dimensionality reduction techniques can be applied during the training process. This helps reduce the complexity of the model and improve its efficiency. Additionally, ensemble techniques, such as bagging or boosting, can be used to combine multiple models and improve overall predictive performance.
Once the training process is completed, it is important to evaluate the model’s performance on the validation set. Assess the accuracy, precision, recall, or other suitable metrics to determine how well the model generalizes to unseen data. This evaluation helps identify any overfitting or underfitting issues and guides further refinement of the model.
After model training and evaluation, the final step is to save the trained model parameters, weights, or coefficients. These can be used for future predictions or for integration into the existing system.
In summary, training the model involves splitting the data into training and validation sets, adjusting the internal parameters of the algorithm to learn from the data, monitoring the training process for performance, and evaluating the model’s performance on the validation set. This step ensures that the model is trained effectively to make accurate predictions or provide meaningful insights within the existing system.
Evaluate and Refine the Model
After training the machine learning model, the next step in adding a machine learning component to an existing system is to evaluate and refine the model. Evaluating the model helps assess its performance and identify areas for improvement, while refining the model aims to enhance its accuracy and effectiveness.
Start by evaluating the model’s performance on a separate test dataset that was not used during the training or validation phase. Measure metrics such as accuracy, precision, recall, or F1-score to assess how well the model generalizes to new, unseen data. This evaluation provides an objective measure of the model’s predictive capabilities and guides further refinement.
Identify any performance gaps or issues observed during evaluation, such as low accuracy or high false-positive rates. These issues can indicate potential areas for refinement. Analyze the misclassified samples or predictions to gain insights into the model’s weaknesses and make informed decisions on refining the model.
There are several strategies for refining the model. One approach is to experiment with different hyperparameter values. This can involve adjusting the learning rate, batch size, regularization techniques, or the number of training iterations. Fine-tuning these hyperparameters can lead to better model performance and improved generalization.
Consider incorporating additional data or augmenting the existing dataset. This can help diversify the training data and capture more variations in the problem domain. Augmentation techniques such as data synthesis or oversampling can be employed to balance imbalanced classes or enrich the training data.
Feature engineering can also play a role in refining the model. Analyze the importance of individual features and assess if any additional features can be derived or extracted from the existing data. Feature selection techniques, such as forward selection or backward elimination, can help identify the most relevant features and eliminate noise or redundant information.
Ensemble methods can be employed to refine the model’s performance. Techniques such as bagging, where multiple models are trained on different subsets of the data and their predictions are combined, or boosting, where weak models are sequentially trained to handle misclassified samples, can improve overall predictive performance.
Regularly evaluate and refine the model as new data becomes available or when system requirements change. Continuous monitoring and refinement ensure that the model adapts to evolving conditions and remains effective and reliable over time.
In summary, evaluating and refining the model involves assessing its performance on a separate test dataset, identifying performance gaps, and making adjustments to improve accuracy and effectiveness. Strategies for refinement include adjusting hyperparameters, incorporating additional data, performing feature engineering, and utilizing ensemble methods. Regular evaluation and refinement ensure that the model remains robust and aligned with the objectives of the existing system.
Integrate the Machine Learning Component into the Existing System
After the model has been evaluated and refined, the final step in adding a machine learning component to an existing system is to integrate it seamlessly into the system’s architecture. This step ensures that the machine learning component works harmoniously with the existing system and provides the desired functionalities and improvements.
The integration process begins by determining the specific points within the existing system where the machine learning component will be integrated. This could be at the input stage, where the component processes incoming data, or at the output stage, where the component generates predictions or insights. Understanding the integration points is crucial for establishing the necessary flow of data and interactions between the existing system and the machine learning component.
Next, consider the technical requirements for integration. This includes ensuring that the system’s infrastructure can support the computational requirements of the machine learning component. Determine if any hardware or software upgrades are necessary to effectively utilize the machine learning model.
Develop appropriate APIs or interfaces that facilitate communication between the existing system and the machine learning component. This can involve defining the input and output formats, handling data preprocessing and transformation, and establishing secure data transfer protocols.
Test the integration thoroughly to ensure that the machine learning component functions as intended within the existing system. Validate the inputs, verify the outputs, and assess the performance and reliability of the integrated system. Conducting comprehensive testing helps identify and resolve any issues or inconsistencies in the integration process.
Document the integration process and provide clear instructions for maintenance and future updates. This documentation should include details about the system’s architecture, the machine learning component’s role and configuration, and any potential troubleshooting steps or considerations.
Furthermore, consider the ongoing monitoring and maintenance of the integrated system. Set up mechanisms to track the performance of the machine learning component in real-time and collect feedback from users or stakeholders. This monitoring allows for timely updates and refinements as needed to ensure the continued effectiveness of the machine learning component.
Lastly, prioritize the security and privacy aspects of the integrated system. Implement measures to protect sensitive data and ensure compliance with relevant regulations or policies. Incorporate techniques such as data anonymization, encryption, or access controls to safeguard the integrity and confidentiality of the data.
In summary, integrating the machine learning component into the existing system involves identifying integration points, establishing technical requirements, developing APIs or interfaces, conducting thorough testing, documenting the integration process, and ensuring ongoing monitoring and maintenance. By successfully integrating the machine learning component, the existing system can benefit from enhanced capabilities, improved performance, and valuable insights derived from the machine learning model.