Introduction
Welcome to the fascinating world of machine learning algorithms! In this digital era, with the exponential growth of data, businesses and researchers are constantly seeking ways to harness the power of artificial intelligence and automation. Machine learning algorithms are at the forefront of this technological revolution, playing a pivotal role in extracting meaningful insights from vast datasets and making intelligent predictions.
At its core, machine learning is a subset of artificial intelligence that focuses on creating algorithms capable of learning and improving from data without explicit programming. These algorithms mimic human learning, identifying patterns, and relationships within the data to make predictions or decisions.
Machine learning algorithms are the building blocks of this dynamic field. They enable computers to learn patterns and make predictions or decisions with minimal human intervention. These algorithms vary in complexity and purpose, each designed to handle specific types of data and solve particular problems.
This article aims to provide an overview of machine learning algorithms, their components, functionality, and limitations. We will explore various types of machine learning algorithms, such as supervised learning, unsupervised learning, and reinforcement learning. Additionally, we will touch upon popular algorithms within each category and examine how these algorithms work to process and analyze data.
We will also delve into the evaluation of machine learning algorithms, discussing metrics used to assess their performance and accuracy. Lastly, we will highlight the challenges and limitations faced when working with machine learning algorithms, offering insight into the potential pitfalls and considerations when implementing them.
By the end of this article, you will have a solid understanding of machine learning algorithms, their significance in the field of artificial intelligence, and the factors to consider when choosing and evaluating these algorithms for various applications.
Definition of a Machine Learning Algorithm
A machine learning algorithm is a set of mathematical instructions or rules that enables a computer system to learn from data, identify patterns, and make intelligent predictions or decisions without being explicitly programmed. It is the cornerstone of machine learning, providing the framework for training models and extracting insights from complex datasets.
Unlike traditional programming where explicit rules are defined, machine learning algorithms utilize statistical techniques to automatically learn and adapt from data. These algorithms are designed to find patterns, correlations, or relationships within the input data to make informed predictions or decisions.
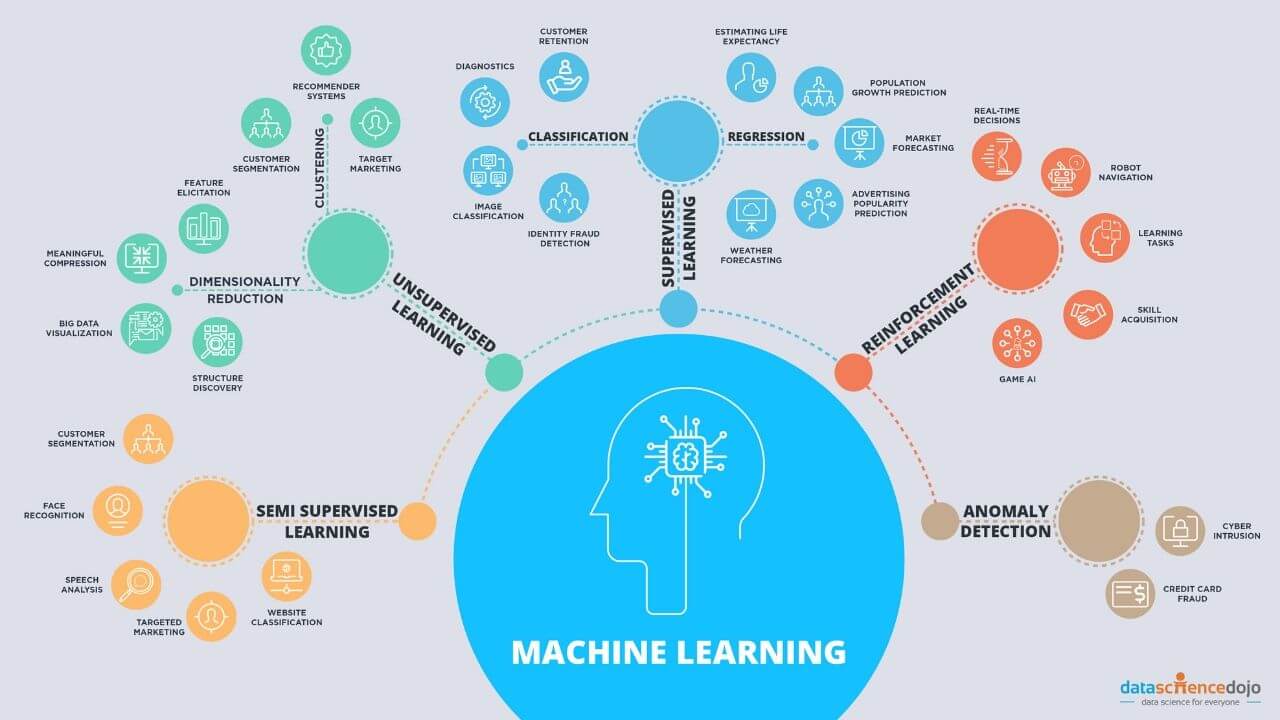
Machine learning algorithms can be classified into three main categories: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, the algorithm learns from labeled training data, where each data point is associated with a known output or label. The algorithm analyzes the relationship between the input features and the corresponding output labels to create a model that can predict the output for new and unseen data. Examples of supervised learning algorithms include linear regression, decision trees, and support vector machines.
Unsupervised learning algorithms, on the other hand, learn from unlabeled data, where there are no predefined output labels. Instead, these algorithms aim to discover inherent patterns, structures, or clusters within the data. Unsupervised learning algorithms are commonly used for tasks such as clustering, anomaly detection, and dimensionality reduction. Some popular unsupervised learning algorithms include k-means clustering, hierarchical clustering, and principal component analysis (PCA).
Reinforcement learning algorithms are designed to learn through interaction with an environment. In this scenario, the algorithm learns from feedback in the form of rewards or penalties based on its actions. The goal is to maximize the cumulative reward over time by learning the optimal strategy or policy. Reinforcement learning algorithms are widely used in robotics, gaming, and autonomous systems.
It is important to note that machine learning algorithms are not static but continue to learn and adapt as new data becomes available. This process, known as model training, involves iteratively adjusting the algorithm’s parameters or weights to minimize errors and improve performance.
In summary, a machine learning algorithm is a mathematical framework that enables computers to learn from data and make intelligent predictions or decisions without explicit programming. These algorithms play a crucial role in various applications, including predictive analytics, image and speech recognition, natural language processing, and recommendation systems, driving advancements in the field of artificial intelligence.
Components of a Machine Learning Algorithm
A machine learning algorithm is composed of several key components that work together to enable the learning and prediction process. Understanding these components is essential for building and deploying effective machine learning models. Let’s explore the main components of a machine learning algorithm:
1. Data: Data serves as the foundation for any machine learning algorithm. It consists of a collection of input features and corresponding output labels (in supervised learning) or unlabeled observations (in unsupervised learning). The quality, size, and diversity of the data greatly impact the performance and accuracy of the algorithm.
2. Feature Selection/Extraction: Feature selection or extraction involves identifying the most relevant features from the input data. This process helps reduce dimensionality and extract meaningful information that contributes to the algorithm’s learning and prediction capabilities. Various techniques, such as principal component analysis (PCA) and information gain, can be used for feature selection and extraction.
3. Model: The model represents the mathematical representation or hypothesis learned by the algorithm. It is created based on the input data and is used to make predictions or decisions on new, unseen data. The model can take different forms, such as decision trees, logistic regression, neural networks, or support vector machines, depending on the chosen algorithm.
4. Training: Training is the process of fitting the model to the training data. During training, the algorithm adjusts the model’s parameters or weights to minimize the difference between its predictions and the actual output labels in supervised learning or to optimize a specific objective in unsupervised learning. The training process aims to make the model generalize well to unseen data.
5. Evaluation: Evaluation measures the performance and accuracy of the algorithm. Common evaluation metrics include accuracy, precision, recall, and F1 score in classification problems, mean squared error (MSE) in regression problems, and the silhouette coefficient or cohesion/separation measures in clustering problems. Evaluation helps assess the algorithm’s ability to generalize beyond the training data.
6. Prediction/Inference: Once the algorithm is trained and evaluated, it can be used for prediction or inference on new, unseen data. The input features are fed into the trained model, which produces output predictions or decisions based on its learned parameters. The predictions made by the model allow it to solve real-world problems, such as classifying emails as spam or non-spam, recommending products to users, or diagnosing diseases based on medical imaging.
Each of these components plays a crucial role in the overall function of a machine learning algorithm. By understanding and carefully considering these components, practitioners can develop and fine-tune algorithms that yield accurate, reliable, and practical results.
Supervised Learning Algorithms
Supervised learning is a type of machine learning where the algorithm learns from labeled training data to make predictions or decisions. It involves mapping input features to the corresponding output labels based on the provided examples. Supervised learning algorithms are widely used for tasks such as classification and regression. Let’s explore some popular supervised learning algorithms:
1. Linear Regression: Linear regression is a simple yet powerful algorithm used for predicting continuous numerical values. It establishes a linear relationship between the input features and the target variable, fitting a line that best represents the data. The algorithm estimates the coefficients that minimize the sum of squared differences between the predicted and actual target values.
2. Decision Trees: Decision trees are versatile algorithms that learn hierarchical decision rules based on the input features. They split the data based on different attribute values, creating a tree-like structure that leads to a final decision or prediction. Decision trees are intuitive, easy to interpret, and capable of handling both categorical and numerical data.
3. Random Forests: Random forests are an ensemble learning method that combines multiple decision trees. Each tree is trained on a different subset of the training data and uses a random selection of input features. Random forests provide better generalization and reduce overfitting compared to individual decision trees. They are robust and effective for handling high-dimensional datasets.
4. Support Vector Machines (SVM): SVM is a powerful algorithm for both classification and regression tasks. It aims to find the best decision boundary that separates different classes while maximizing the margin between them. SVM can handle linearly separable as well as non-linearly separable data using techniques like kernel functions.
5. Naive Bayes: Naive Bayes is a probabilistic algorithm based on Bayes’ theorem. It assumes that all input features are independent, hence the “naive” assumption. Naive Bayes is widely used for text classification, spam filtering, and sentiment analysis due to its simplicity, speed, and good performance with high-dimensional datasets.
6. K-Nearest Neighbors (KNN): KNN is a non-parametric algorithm that classifies or predicts based on the neighbors’ majority vote. It assigns the label or value of a data point based on the k nearest neighbors in the feature space. KNN is easy to understand and implement but can be computationally expensive for large datasets.
These are just a few examples of supervised learning algorithms, each with its own strengths, weaknesses, and areas of application. Choosing the right supervised learning algorithm depends on the problem at hand, the nature of the data, and the desired outcome.
Unsupervised Learning Algorithms
Unsupervised learning is a type of machine learning where the algorithm learns from unlabeled data to discover underlying patterns, structures, or relationships. Unlike supervised learning, there are no predefined output labels to guide the learning process. Unsupervised learning algorithms are widely used for tasks such as clustering, dimensionality reduction, and anomaly detection. Let’s delve into some popular unsupervised learning algorithms:
1. K-means Clustering: K-means is one of the most commonly used clustering algorithms. It aims to partition the data into K clusters, where K is predefined. The algorithm iteratively assigns data points to the nearest cluster centroid and updates the centroids until convergence. K-means clustering is effective for finding natural groupings in data.
2. Hierarchical Clustering: Hierarchical clustering builds a hierarchical structure of clusters by iteratively merging or splitting clusters based on their similarity. It can be represented as a tree-like structure called a dendrogram, which provides insights into both individual clusters and the overall cluster hierarchy.
3. Gaussian Mixture Models (GMM): GMM is a probabilistic model that represents the data as a mixture of Gaussian distributions. It assumes that the data points belong to different clusters, each following a Gaussian distribution. GMM is particularly useful for modeling complex data distributions and can also handle incomplete or missing data points.
4. Principal Component Analysis (PCA): PCA is a widely used dimensionality reduction technique. It transforms a high-dimensional dataset into a lower-dimensional representation while preserving the most important information in the data. PCA identifies the principal components that capture the maximum variance in the data and projects the data onto these components.
5. Anomaly Detection: Anomaly detection algorithms aim to identify rare or abnormal data points in a dataset. These algorithms learn the normal behavior of the data and flag instances that deviate significantly from the learned patterns. Anomaly detection is particularly valuable for detecting fraud, network intrusion, or unusual patterns in medical data.
6. Association Rule Mining: Association rule mining discovers meaningful associations or relationships between items in large transactional datasets. It identifies frequently occurring itemsets and generates rules that describe the associations between different items. Association rule mining is commonly used in market basket analysis, where it helps uncover purchasing patterns and support product recommendations.
These unsupervised learning algorithms provide valuable insights into unlabeled data without the need for explicit guidance. They help uncover hidden structures, identify anomalies, and extract meaningful information from complex datasets, enabling further analysis or decision-making processes.
Reinforcement Learning Algorithms
Reinforcement learning is a type of machine learning where an agent learns through trial and error by interacting with an environment. The aim is to maximize cumulative rewards over time by learning the optimal actions or policies. Reinforcement learning algorithms are commonly used in settings where an agent must make sequential decisions in a dynamic environment. Let’s explore some popular reinforcement learning algorithms:
1. Q-Learning: Q-Learning is a model-free algorithm that learns from experience to make decisions. It uses a table called a Q-table to store the expected rewards for each action in each state of the environment. The algorithm selects actions based on the current state and updates the Q-values in the table based on the rewards received. Q-Learning is effective for solving Markov Decision Processes (MDPs).
2. Deep Q-Network (DQN): DQN is an extension of Q-Learning that uses deep neural networks as function approximators. Instead of relying on a Q-table, DQN approximates the Q-values using a deep neural network and updates the network’s weights through backpropagation. DQN is particularly useful for environments with high-dimensional state spaces.
3. Policy Gradient Methods: Policy gradient methods aim to learn the optimal policy directly from interacting with the environment. These algorithms parameterize the policy and use gradient ascent to update the policy parameters based on the expected rewards. Policy gradient methods, such as REINFORCE and Proximal Policy Optimization (PPO), enable the agent to learn complex policies for continuous action spaces.
4. Actor-Critic Methods: Actor-Critic is a hybrid approach that combines the advantages of both policy-based and value-based methods. It consists of two components: an actor that selects actions based on the learned policy and a critic that estimates the value or reward function. Actor-Critic methods, such as Advantage Actor-Critic (A2C) and Asynchronous Advantage Actor-Critic (A3C), provide better stability and convergence in reinforcement learning tasks.
5. Monte Carlo Tree Search (MCTS): MCTS is a planning algorithm commonly used in problems with large state spaces and complex decision trees, such as board games. MCTS builds a search tree by simulating multiple trajectories from the current state, selecting actions based on upper confidence bounds. MCTS algorithms, such as AlphaGo, have achieved remarkable success in games like Go and chess.
6. Deep Deterministic Policy Gradient (DDPG): DDPG is an off-policy algorithm that combines deep neural networks with the actor-critic framework. It is primarily used for continuous action spaces and leverages the power of neural networks to approximate the policy and Q-values. DDPG has been successfully applied to tasks such as robotic control and autonomous driving.
Reinforcement learning algorithms excel in sequential decision-making tasks, where the agent learns to navigate and adapt to complex environments. These algorithms enable AI systems to learn optimal strategies, play games, control robots, and make decisions in dynamic and uncertain scenarios.
Popular Machine Learning Algorithms
Machine learning algorithms are an essential part of today’s data-driven world. They power a wide range of applications and enable computers to analyze and interpret complex data, make predictions, and automate decision-making processes. Here are some of the most popular machine learning algorithms:
1. Logistic Regression: Logistic regression is a popular algorithm used for binary classification tasks. It models the relationship between the input features and the probability of belonging to a particular class. Logistic regression is simple, interpretable, and works well with linearly separable data.
2. RandomForest: RandomForest is an ensemble learning algorithm that combines multiple decision trees to make predictions. It improves the accuracy and robustness by aggregating the predictions of individual trees. RandomForest is versatile, handles high-dimensional data, and provides feature importance rankings.
3. Gradient Boosting: Gradient Boosting is another ensemble learning technique that builds a strong predictive model by sequentially adding weak models. It creates a gradient-based optimization to minimize the loss function in each iteration. Gradient Boosting algorithms, such as XGBoost and LightGBM, are known for their excellent performance on various machine learning tasks.
4. Support Vector Machines (SVM): SVM is a widely used algorithm for both classification and regression tasks. It aims to find an optimal hyperplane that separates data points of different classes while maximizing the margin between them. SVM is effective for handling both linearly separable and non-linearly separable data.
5. K-Nearest Neighbors (KNN): KNN is a simple yet powerful algorithm used for both classification and regression. It assigns labels or predicts values based on the majority vote or average of the k nearest neighbors in the feature space. KNN is easy to understand, but the computational complexity increases with the size of the dataset.
6. Neural Networks: Neural networks are a class of algorithms inspired by the structure and functioning of the human brain. Deep learning, a subfield of neural networks, involves training deep neural networks with multiple layers to learn intricate patterns and relationships in data. Neural networks are highly flexible and excel in tasks such as image recognition, natural language processing, and speech synthesis.
7. Naive Bayes: Naive Bayes is a probabilistic algorithm based on Bayes’ theorem. It assumes that all input features are independent, given the class or output label. Naive Bayes is simple, computationally efficient, and works well with high-dimensional data. It is commonly used for text classification, sentiment analysis, and spam filtering.
8. Clustering Algorithms: Clustering algorithms, such as K-means and hierarchical clustering, are widely used for grouping similar data points together. These algorithms discover inherent patterns or clusters within the data based on similarity measures. Clustering is valuable in various applications, including customer segmentation, anomaly detection, and image compression.
These are just a few examples of popular machine learning algorithms, each with its own strengths, limitations, and areas of application. Choosing the right algorithm depends on the nature of the problem, the available data, and the desired outcome. It is important to experiment and select the algorithm that best fits the specific requirements of the task at hand.
How Machine Learning Algorithms Work
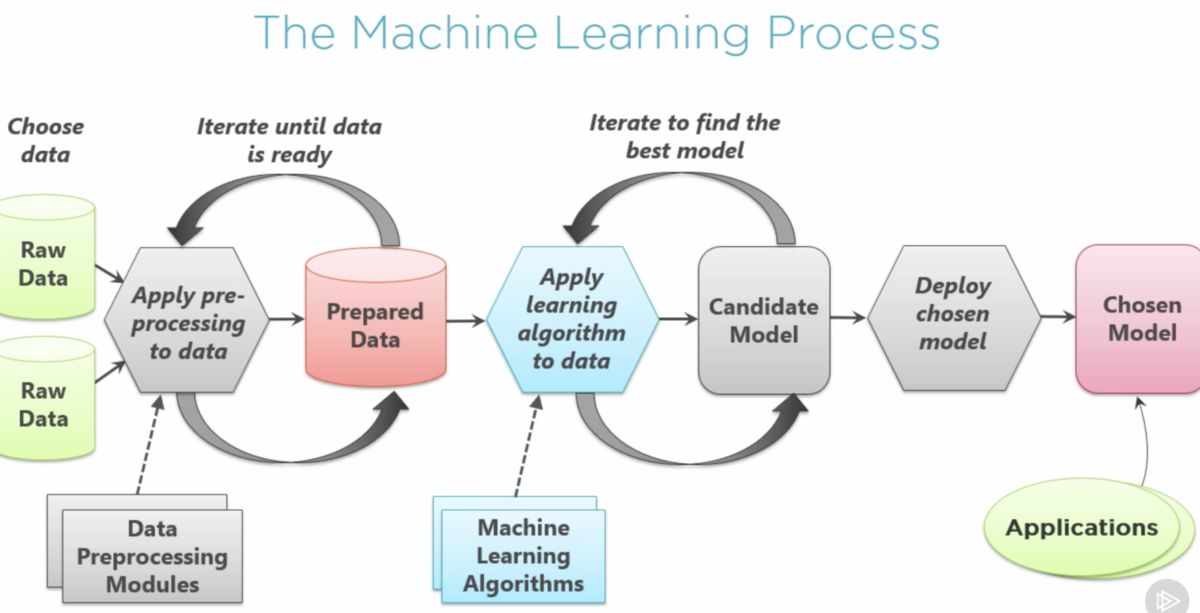
Machine learning algorithms are designed to learn patterns and make predictions using historical or unlabeled data. They follow a systematic process that involves data preprocessing, model training, and inference. Here’s a high-level overview of how machine learning algorithms work:
1. Data Preprocessing: Before training a machine learning algorithm, the data needs to be cleaned, transformed, and prepared for analysis. This step involves handling missing values, dealing with outliers, scaling or normalizing the data, and encoding categorical variables. Data preprocessing ensures that the algorithm can effectively learn from the input features.
2. Model Training: Once the data is preprocessed, the algorithm can be trained. In supervised learning, this process involves feeding the labeled training data into the algorithm, which learns the underlying patterns and relationships between the input features and the output labels. The algorithm adjusts its internal parameters or weights iteratively to minimize errors and improve prediction accuracy. In unsupervised learning, the algorithm learns patterns, structures, or clusters within the data without using predefined output labels.
3. Model Evaluation: After training, it is essential to evaluate the performance of the machine learning model. This step involves using a separate set of data called the validation set or testing set to measure the model’s accuracy, precision, recall, and other relevant evaluation metrics. The evaluation provides insights into how well the model generalizes to unseen data and helps identify any potential issues or overfitting.
4. Inference: Once the model is trained and evaluated, it can be deployed and used for making predictions or decisions on new, unseen data. The input features are fed into the trained model, and the model produces predictions or outputs based on its learned parameters. The inference stage allows the algorithm to solve real-world problems, such as classifying images, recommending products, or predicting stock prices.
It’s important to note that machine learning algorithms are not limited to a single iteration. They can be fine-tuned and retrained based on new data to continually improve their performance. This iterative process ensures that the algorithm adapts to changes in the data distribution and remains up-to-date.
Machine learning algorithms work by iteratively learning from data, adjusting their internal parameters or weights to improve prediction accuracy. They leverage mathematical and statistical techniques to uncover patterns, relationships, or clusters within the input data. Through the process of training, evaluation, and inference, machine learning algorithms enable computers to make intelligent decisions, automate tasks, and extract valuable insights from complex datasets.
Evaluation of Machine Learning Algorithms
Evaluating the performance of machine learning algorithms is crucial to assess their effectiveness and determine their suitability for a particular task. Proper evaluation helps researchers and practitioners understand how well an algorithm generalizes to unseen data and provides insights into its strengths and limitations. Here are some common techniques used to evaluate machine learning algorithms:
1. Training and Testing Sets: A common practice is to split the available data into two parts: a training set and a testing set. The training set is used to train the algorithm, while the testing set is used to evaluate its performance. This approach ensures that the model is tested on unseen data and provides an estimate of its performance in real-world scenarios.
2. Cross-Validation: Cross-validation is a more robust method for evaluating machine learning algorithms, especially when the dataset is limited. It involves dividing the data into multiple subsets or folds and performing multiple training and testing iterations. This technique provides a better estimate of the algorithm’s performance by reducing the impact of data variability and overfitting.
3. Evaluation Metrics: Evaluation metrics quantify the performance of machine learning algorithms based on their predictions. For classification tasks, common metrics include accuracy, precision, recall, F1 score, and area under the receiver operating characteristic (ROC) curve. For regression tasks, mean squared error (MSE), root mean squared error (RMSE), and R-squared are frequently used.
4. Confusion Matrix: A confusion matrix is a useful visual representation of the performance of a classification algorithm. It shows the number of true positive, true negative, false positive, and false negative predictions, allowing for a detailed analysis of the algorithm’s accuracy and error patterns.
5. Bias-Variance Tradeoff: The bias-variance tradeoff is a fundamental concept in machine learning evaluation. It represents the tradeoff between the model’s ability to fit the training data (low bias) and its ability to generalize to unseen data (low variance). A model with high bias may underestimate the complexity of the data, while a model with high variance may overfit the training data. Achieving the optimal balance between bias and variance leads to a well-performing and robust algorithm.
6. Feature Importance and Interpretability: In addition to performance evaluation, understanding the importance of different features or variables in a machine learning algorithm can provide valuable insights. Techniques such as feature importance scores, partial dependence plots, and SHAP (SHapley Additive exPlanations) values can help quantify the impact of each feature on the algorithm’s predictions.
Evaluating machine learning algorithms is essential to select the best model for a given task, avoid overfitting or underfitting, and gain insights into the algorithm’s behavior and performance. It is important to consider the specific requirements of the problem, the nature of the data, and the goals of the analysis when choosing evaluation techniques and metrics.
Challenges and Limitations of Machine Learning Algorithms
While machine learning algorithms have made significant advancements and achieved remarkable success in various domains, they also face several challenges and limitations. Understanding these challenges is important to ensure realistic expectations and address potential limitations. Here are some common challenges and limitations of machine learning algorithms:
1. Data Quality and Quantity: Machine learning algorithms heavily rely on the quality and quantity of data. Insufficient or low-quality data can lead to inaccurate predictions or biased models. Data preprocessing and cleaning are crucial to address these issues, but obtaining labeled data can be expensive or time-consuming.
2. Overfitting and Underfitting: Overfitting occurs when a machine learning model learns the training data too well, resulting in poor generalization to new, unseen data. On the other hand, underfitting occurs when the model is too simple to capture the underlying patterns in the data. Balancing the model’s complexity and performance is a key challenge in machine learning.
3. Feature Engineering: Extracting meaningful features from raw data plays a vital role in the performance of machine learning algorithms. The process of feature selection or extraction requires domain expertise and careful consideration. Insufficient or irrelevant features can negatively impact the algorithm’s accuracy and efficiency.
4. Interpretability and Explainability: While machine learning algorithms are highly effective in making predictions, they often lack interpretability. Many algorithms are considered black boxes, making it challenging to understand the reasoning behind their decisions. This lack of interpretability can be problematic, especially in critical domains such as healthcare and finance.
5. Algorithmic Bias and Fairness: Machine learning algorithms can inadvertently capture and reinforce biases present in the data. Biased training data can lead to biased predictions, perpetuating systemic discrimination or unfairness. Ensuring fairness and mitigating algorithmic bias is a significant challenge in the development and deployment of machine learning systems.
6. Computational Resources and Efficiency: Some machine learning algorithms, particularly deep learning algorithms, require significant computational resources and time for training. Large-scale datasets and complex models can strain computer resources and hinder real-time or resource-constrained applications. Efficient implementation and optimization techniques are necessary to address these challenges.
7. Continual Learning and Adaptability: Machine learning algorithms typically require periodic retraining to adapt to changing data distributions. Learning from dynamic or streaming data poses additional challenges, as models need to update continuously without losing previously learned information. Continual learning and adaptability are critical for maintaining the relevance and accuracy of machine learning models.
Understanding and addressing these challenges and limitations is crucial for the responsible and effective deployment of machine learning algorithms. Researchers and practitioners continuously strive to develop techniques and methods that mitigate these limitations and enhance the reliability, interpretability, and fairness of machine learning systems.
Conclusion
Machine learning algorithms have revolutionized the way we approach data analysis and decision-making. They enable computers to learn patterns, extract insights, and make predictions from vast and complex datasets. From supervised learning algorithms like linear regression and random forests to unsupervised learning algorithms like clustering and dimensionality reduction, and reinforcement learning algorithms that allow agents to learn through trial and error, there is a wide range of algorithms to address various problems and domains.
However, it is important to recognize that machine learning algorithms are not perfect and face certain challenges and limitations. Data quality and quantity, overfitting and underfitting, feature engineering, interpretability and explainability, algorithmic bias, computational resources, and continual learning are some of the key challenges that need to be addressed to ensure the effectiveness and reliability of machine learning applications.
Despite these challenges, machine learning algorithms continue to make significant contributions in various fields, including healthcare, finance, e-commerce, and more. They have the potential to drive innovation, improve decision-making processes, and unlock new insights from data. As researchers and practitioners work towards developing techniques to overcome limitations, it is crucial to approach the deployment of machine learning algorithms with careful consideration, ensuring fairness, transparency, and ethical use.
In conclusion, machine learning algorithms serve as powerful tools in harnessing the potential of data. Through their ability to learn from data and generate valuable predictions, these algorithms have the potential to transform industries, drive advancements in technology, and enhance the way we solve complex problems. By addressing the challenges and limitations, we can unlock the full potential of machine learning algorithms and leverage their capabilities to create a better future.