





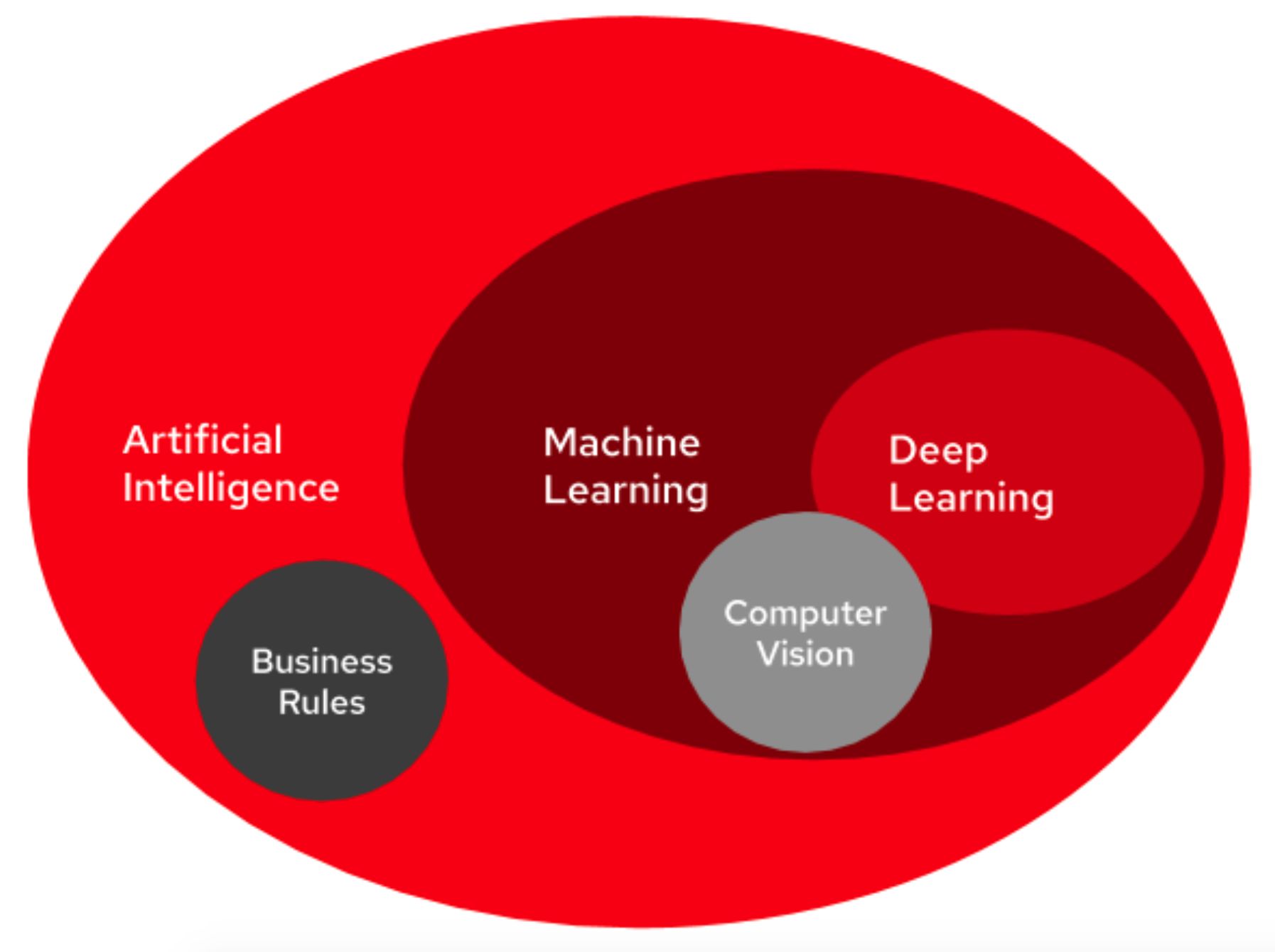
Introduction
Machine learning is a rapidly evolving field of computer science that utilizes algorithms to enable computers to learn and make predictions or decisions without being explicitly programmed. It is a subset of artificial intelligence that focuses on the development of systems that can learn and improve from experience.
The beauty of machine learning lies in its ability to analyze large amounts of data, identify patterns, and make accurate predictions or classifications. This enhances decision-making processes, empowers businesses to gain insights, and enables predictive analytics.
Machine learning algorithms are designed to perform specific tasks by processing and analyzing vast amounts of data. These algorithms are categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, the algorithm is given a labeled dataset, where it learns from the input-output pairs to make predictions or decisions. On the other hand, unsupervised learning involves analyzing unlabeled data to discover patterns or hidden structures. Lastly, reinforcement learning employs a reward system to train algorithms by allowing them to make decisions based on trial and error.
Machine learning has found applications in numerous fields, revolutionizing how we interact with technology. From recommendation systems and natural language processing to image recognition and fraud detection, the impact of machine learning is pervasive.
In the following sections, we delve into the various applications of machine learning and explore how it is transforming industries and shaping the future.
Understanding Machine Learning
Machine learning is a branch of artificial intelligence that focuses on creating algorithms and models that enable computers to learn and make predictions or decisions without being explicitly programmed. The foundation of machine learning lies in the ability of computers to analyze large amounts of data, identify patterns, and use that knowledge to improve their performance over time.
At its core, machine learning is all about training algorithms to recognize patterns and make accurate predictions or decisions. These algorithms are designed to improve their performance through iterative learning, where they continuously refine their models based on new data. The more data the algorithm is exposed to, the better it becomes at making predictions or decisions.
One key concept in machine learning is the training dataset. This dataset consists of labeled examples where the desired output is known. The algorithm uses this dataset to learn the relationship between the input features and the desired output, enabling it to generalize its learning to unseen examples.
Another important concept in machine learning is the model or hypothesis. The model represents the learned relationship between the input features and the output. It serves as the basis for making predictions or decisions on new, unseen data. The model is typically represented by a set of parameters that are adjusted during the learning process to minimize the prediction error.
Machine learning algorithms can be broadly classified into two categories: supervised learning and unsupervised learning. In supervised learning, the algorithm is provided with a labeled dataset, where each example is associated with a known output. The goal is to learn a function that maps the input features to the desired output. This can be used for tasks such as classification, regression, and prediction.
Unsupervised learning, on the other hand, works with unlabeled data, where the algorithm’s objective is to discover hidden patterns or structures within the data. The algorithm learns to group similar examples together or to find interesting dependencies among the data points. Unsupervised learning is commonly used for tasks such as clustering, dimensionality reduction, and anomaly detection.
Overall, understanding the fundamentals of machine learning is crucial for harnessing its power and applying it to real-world problems. By leveraging the capabilities of machine learning algorithms, businesses and organizations can gain valuable insights from their data, automate processes, and make more informed decisions.
Machine Learning Algorithms
Machine learning algorithms are the backbone of machine learning systems. They are designed to process and analyze data, identify patterns, and make accurate predictions or decisions. These algorithms play a crucial role in various machine learning tasks, including classification, regression, clustering, and anomaly detection. Let’s explore some commonly used machine learning algorithms:
1. Decision Trees: Decision trees are versatile algorithms that make decisions by creating a tree-like model of decisions and their possible consequences. They are easy to understand and interpret, and can handle both categorical and numerical data.
2. Random Forest: Random forests are collections of decision trees that work together to make predictions. They are known for their robustness and ability to handle high-dimensional data, making them popular for classification and regression tasks.
3. Support Vector Machines (SVM): SVM is a powerful algorithm used for both classification and regression tasks. It works by finding an optimal hyperplane that separates the data into different classes or predicts a continuous output.
4. Naive Bayes: Naive Bayes is a probabilistic algorithm based on Bayes’ theorem. It assumes that the features are independent of each other, which simplifies the calculations. Naive Bayes is commonly used for text classification and spam filtering.
5. K-Nearest Neighbors (KNN): KNN is a simple but effective algorithm that makes predictions based on the k-nearest neighbors in the training dataset. It is widely used for pattern recognition, recommendation systems, and anomaly detection.
6. Neural Networks: Neural networks are inspired by the human brain and are composed of interconnected nodes (neurons) arranged in layers. They are capable of learning complex patterns and are used in various tasks such as image recognition, natural language processing, and speech recognition.
7. Clustering Algorithms: Clustering algorithms, such as K-means and hierarchical clustering, group similar data points together based on their similarity. These algorithms are commonly used for customer segmentation, image segmentation, and data analysis.
8. Dimensionality Reduction Algorithms: Dimensionality reduction algorithms, such as Principal Component Analysis (PCA) and t-SNE, reduce the dimensionality of the dataset while preserving its important features. These algorithms are useful for visualizing high-dimensional data and improving the performance of machine learning models.
These are just a few examples of the wide range of machine learning algorithms available. Choosing the right algorithm depends on the nature of the problem, the characteristics of the data, and the desired outcome. By understanding the strengths and weaknesses of different algorithms, machine learning practitioners can select the most appropriate algorithm for their specific task, leading to more accurate predictions and better results.
Supervised Learning
Supervised learning is a fundamental category of machine learning where the algorithm learns from labeled training data to make predictions or decisions. In supervised learning, the dataset consists of input features and their corresponding output values. The goal is to learn a mapping function that can accurately predict the output for new, unseen instances.
There are two main types of supervised learning tasks: classification and regression. In classification tasks, the algorithm learns to classify input instances into predefined classes or categories. For example, a supervised learning algorithm can be trained to classify emails as spam or non-spam based on their features. Classification algorithms such as Support Vector Machines (SVM), Decision Trees, and Naive Bayes are commonly used for this task.
In regression tasks, the supervised learning algorithm learns to predict a continuous output value based on the input features. For instance, a regression algorithm can be trained to predict the price of a house based on its attributes such as location, size, and number of rooms. Regression algorithms like Linear Regression, Random Forests, and Neural Networks are often used in these scenarios.
The supervised learning process involves several steps:
- Data Collection: Collecting a labeled dataset with input features and their corresponding output values. This step may involve manual labeling or the use of existing labeled datasets.
- Data Preprocessing: Preprocessing the data by handling any missing values, normalizing the features, and splitting the dataset into training and testing sets.
- Model Selection: Choosing an appropriate model or algorithm for the supervised learning task based on the characteristics of the data and the desired outcome.
- Model Training: Training the selected model on the labeled training data to learn the underlying patterns and relationships between the input features and the output values.
- Model Evaluation: Assessing the performance of the trained model using evaluation metrics such as accuracy, precision, recall, and mean squared error.
- Prediction: Using the trained model to make predictions on new, unseen data instances.
Supervised learning is widely used in various domains and applications. It is employed in spam filtering, sentiment analysis, fraud detection, recommendation systems, medical diagnosis, and many other areas. The availability of labeled training data and the ability to make accurate predictions make supervised learning a powerful tool for solving a wide range of real-world problems.
Unsupervised Learning
Unsupervised learning is a branch of machine learning that deals with unlabeled data and aims to uncover hidden patterns, structures, or relationships within the data. Unlike supervised learning, there is no predefined output to guide the learning process. Instead, the algorithm explores the data on its own to discover meaningful insights.
In unsupervised learning, the algorithm seeks to group similar data points together or find interesting dependencies among the data. This process is known as clustering. The algorithm looks for commonalities, differences, or anomalies in the data without any prior knowledge of the expected outcomes.
There are different types of unsupervised learning algorithms, each with its own approach to uncovering patterns:
- Clustering: Clustering algorithms group similar data points based on their proximity or similarity. The algorithm automatically learns the clusters in the data without any prior information about the groups. K-means clustering and hierarchical clustering are popular examples of unsupervised clustering algorithms.
- Dimensionality Reduction: Dimensionality reduction algorithms aim to reduce the number of variables or features in the dataset while preserving the most important information. This is particularly useful in visualizing high-dimensional data and eliminating redundant or irrelevant features. Principal Component Analysis (PCA) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are widely used dimensionality reduction techniques.
- Association Rule Learning: Association rule learning algorithms identify relationships or dependencies among different items in a dataset. They are commonly used in market basket analysis, where the algorithm determines which items are frequently purchased together. Apriori and FP-Growth are well-known association rule learning algorithms.
- Anomaly Detection: Anomaly detection algorithms identify unusual or outlying data points that deviate significantly from the norm. This can be vital in detecting fraudulent transactions, network intrusions, or medical anomalies in healthcare. Popular unsupervised anomaly detection algorithms include Isolation Forest and Local Outlier Factor.
Unsupervised learning has various applications in real-world scenarios. It aids in customer segmentation, pattern recognition, anomaly detection, data exploration, and finding hidden structures in data. By uncovering valuable insights from unlabeled data, unsupervised learning can provide a deeper understanding of complex systems and help drive decision-making processes in an informed manner.
Reinforcement Learning
Reinforcement learning is a type of machine learning that enables an agent to learn how to make decisions in an environment through trial and error. Unlike supervised and unsupervised learning, reinforcement learning does not require labeled data or predefined behaviors. Instead, the agent learns by interacting with the environment and receiving feedback in the form of rewards or penalties.
In reinforcement learning, the agent’s goal is to maximize the cumulative reward it receives over time by taking actions in the environment. The agent explores different actions, learns from the consequences, and adjusts its behavior accordingly. The learning process involves building a policy that maps states to actions, optimizing the policy to maximize the expected rewards.
Key components of reinforcement learning include:
- Agent: The entity that learns and takes actions in the environment based on its past experiences.
- Environment: The external system with which the agent interacts.
- State: The current configuration or snapshot of the environment at a particular time.
- Action: The decision made by the agent in response to the state of the environment.
- Reward: The feedback signal that the agent receives as a result of its actions. The reward can be positive, negative, or zero, depending on the outcome.
- Policy: The strategy or set of rules that the agent follows to select actions based on the observed states.
Reinforcement learning can be implemented using various algorithms, including Q-learning, Monte Carlo methods, and Deep Q-Networks (DQNs). These algorithms aim to find an optimal policy that maximizes the expected long-term reward from the environment.
The applications of reinforcement learning are diverse and include autonomous robotics, game playing (such as AlphaGo), recommendation systems, resource management, and autonomous driving. Reinforcement learning enables agents to learn from experience and adapt their decision-making strategies to achieve optimal outcomes in complex and dynamic environments.
Applications of Machine Learning
Machine learning is being applied to a wide range of industries and sectors, revolutionizing how we interact with technology and solving complex problems. Its ability to analyze large quantities of data, identify patterns, and make accurate predictions or decisions has led to numerous applications that have the potential to transform various domains. Let’s explore some key applications of machine learning:
- Recommendation Systems: Machine learning powers recommendation systems that provide personalized recommendations to users. These systems analyze user preferences, historical data, and behavior patterns to suggest relevant products, movies, music, or articles. Popular examples include Netflix’s recommendation algorithm and Amazon’s personalized product recommendations.
- Natural Language Processing (NLP): NLP is a branch of artificial intelligence that deals with the interaction between computers and human language. Machine learning algorithms are used in NLP tasks such as sentiment analysis, text classification, entity recognition, and machine translation. Applications of NLP can be found in virtual assistants, chatbots, voice recognition systems, and language understanding platforms like Google Assistant and Siri.
- Image Recognition: Machine learning has revolutionized image recognition, enabling computers to understand and interpret visual data. Image recognition algorithms are used in facial recognition systems, object detection, image classification, and autonomous vehicles. Companies like Google, Facebook, and Tesla utilize machine learning algorithms in their image recognition technologies.
- Fraud Detection: Machine learning algorithms are instrumental in identifying fraudulent activities in various domains, including finance, insurance, and e-commerce. These algorithms analyze large volumes of data, detect patterns, and flag suspicious transactions or behaviors, helping organizations combat fraud effectively.
- Predictive Analytics: Machine learning enables businesses to leverage historical and real-time data to make accurate predictions and forecasts. Predictive analytics algorithms are applied in sales forecasting, demand planning, financial market analysis, and risk management. These algorithms help companies optimize their operations, make informed decisions, and improve overall performance.
- Speech Recognition: Speech recognition systems, powered by machine learning algorithms, are transforming the way we interact with devices. These systems convert spoken language into written text and are used in virtual assistants, voice-controlled systems, and speech-to-text applications. Examples include Apple’s Siri, Google Assistant, and Amazon’s Alexa.
These are just a few examples of the diverse applications of machine learning. The potential of this technology is vast, and it continues to impact industries such as healthcare, manufacturing, transportation, marketing, and more. As machine learning advancements continue, we can expect even more innovative applications that will shape the future of various sectors.
Recommendation Systems
Recommendation systems are one of the most widely recognized applications of machine learning. They are designed to provide personalized recommendations to users based on their preferences, historical data, and behavior patterns. These systems play a crucial role in various industries, including e-commerce, streaming services, social media platforms, and online content providers.
There are two main types of recommendation systems:
- Content-based filtering: This approach focuses on analyzing the attributes or characteristics of items in order to recommend similar items to users. Content-based filtering algorithms learn from the user’s past interactions and understand their preferences based on the attributes of the items they have consumed. For example, in a music streaming service, a content-based recommendation system would recommend songs with similar genres or artists to those the user has previously enjoyed.
- Collaborative filtering: Collaborative filtering relies on collecting and analyzing user behavior and preferences across a large user base. This approach identifies patterns and similarities among users with similar tastes and recommends items that have been favored by users with similar preferences. Collaborative filtering can be further divided into two subtypes: user-based filtering and item-based filtering. User-based filtering recommends items based on the preferences of users with similar tastes, while item-based filtering recommends items that are similar to those previously enjoyed by the user.
Recommendation systems utilize machine learning algorithms to analyze vast amounts of data, including user interaction data, item data, and contextual information. The algorithms learn from this data to uncover patterns and make accurate predictions about user preferences, enabling them to generate personalized recommendations.
Personalized recommendations impact various aspects of our digital experiences. They help users discover new products, movies, music, articles, and more, ultimately enhancing customer satisfaction and engagement. Moreover, recommendation systems offer businesses significant benefits, including increased sales, improved customer retention, and enhanced user experience.
Companies such as Netflix, Amazon, Spotify, and YouTube have leveraged the power of recommendation systems to great success. For instance, Netflix’s recommendation system uses machine learning algorithms to analyze user viewing history, ratings, and similar user behaviors to suggest movies and shows tailored to each user’s taste. Amazon’s recommendation system uses collaborative filtering techniques to recommend products based on the purchasing history, ratings, and browsing behavior of similar users.
As machine learning techniques continue to advance, we can expect even more sophisticated recommendation systems that utilize techniques such as deep learning, reinforcement learning, and natural language processing. These systems will continuously improve the accuracy, relevance, and personalization of recommendations, further enhancing the user experience and driving business growth.
Natural Language Processing
Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on the interaction between computers and human language. NLP enables computers to understand, interpret, and generate human language, allowing for more efficient communication and analysis of vast amounts of textual data. Machine learning algorithms play a crucial role in NLP by enabling computers to process and analyze natural language in a meaningful way.
NLP encompasses a wide range of tasks and applications, including:
- Sentiment Analysis: Sentiment analysis involves determining the sentiment or opinion expressed in a piece of text, such as positive, negative, or neutral. Machine learning algorithms can be trained to analyze textual data, such as customer reviews or social media posts, to extract sentiment and understand public opinion.
- Text Classification: Text classification involves categorizing or organizing text documents into predefined classes or categories. Machine learning algorithms can be trained on labeled text data to automatically classify documents into different topics, genres, or types.
- Entity Recognition: Entity recognition, also known as named entity recognition, involves identifying and classifying named entities (such as names, organizations, locations, dates) in text. Machine learning algorithms can learn to recognize and extract entities from unstructured textual data.
- Machine Translation: Machine translation aims to automatically translate text from one language to another. Machine learning algorithms have been instrumental in improving machine translation models, such as neural machine translation, by learning the patterns and semantics of different languages.
- Question Answering: Question answering involves automatically generating or retrieving answers to questions asked in natural language. Machine learning algorithms can be trained to understand the intent of questions and provide accurate answers by analyzing relevant textual data.
- Chatbots: Chatbots are intelligent virtual agents that interact with users via natural language. They utilize machine learning algorithms to understand user queries, generate appropriate responses, and provide personalized assistance in various domains, including customer support, information retrieval, and task automation.
NLP has numerous practical applications across industries. In healthcare, it can be used to extract and analyze medical records, generate clinical reports, and assist in diagnosis. In finance, NLP can analyze news articles and social media data to predict market trends and guide investment strategies. In legal domains, NLP can aid in legal research, document analysis, and contract review.
Leading companies such as Google, Microsoft, and IBM have developed sophisticated NLP systems, including Google’s BERT, Microsoft’s Language Understanding Intelligent Service (LUIS), and IBM’s Watson. These systems employ advanced machine learning algorithms to process and understand natural language data, enabling more efficient and accurate analysis of textual information.
As machine learning techniques continue to advance, NLP has the potential to transform various aspects of our daily lives, facilitating seamless communication and providing valuable insights from the vast amount of unstructured textual data available.
Image Recognition
Image recognition, also known as computer vision, is a field of study that focuses on developing algorithms and techniques that enable computers to understand and interpret visual data. Machine learning plays a vital role in image recognition algorithms by enabling computers to learn from large amounts of images and accurately classify or detect objects, scenes, and patterns.
Image recognition algorithms are used in various applications across industries:
- Object Recognition: Object recognition involves identifying and classifying specific objects within an image. Machine learning algorithms can be trained on labeled datasets to recognize and localize objects of interest, such as cars, animals, or household items. Object recognition has applications in autonomous vehicles, surveillance systems, and augmented reality.
- Face Recognition: Face recognition algorithms identify and verify individuals based on their facial features. Machine learning systems can learn to detect and recognize unique facial features, enabling face authentication in security systems, identity verification processes, and social media applications.
- Image Classification: Image classification involves categorizing images into predefined classes or categories. Machine learning algorithms can be trained on labeled image datasets to automatically classify images into classes such as animals, landmarks, or scenes. Image classification is used in areas such as inventory management, agriculture, and medical imaging diagnosis.
- Image Segmentation: Image segmentation algorithms separate an image into multiple regions or segments based on specific characteristics. Machine learning techniques, such as clustering or deep learning, can learn to segment images into meaningful regions, which find applications in medical imaging, object tracking, and autonomous driving.
- Visual Search: Visual search enables users to search for similar images based on a query image. Machine learning algorithms can learn to understand the visual features of images and retrieve relevant images from large databases. Visual search is used in e-commerce to enable users to find products similar to what they have visually queried.
- Image Captioning: Image captioning algorithms generate descriptive captions for images. By combining computer vision and natural language processing, machine learning models can learn to interpret visual content and generate textual descriptions. Image captioning finds applications in image indexing, assistive technologies, and content generation.
Leading technology companies like Google, Microsoft, and Facebook have developed powerful image recognition systems, such as Google’s Cloud Vision API, Microsoft’s Azure Computer Vision, and Facebook’s DeepFace. These systems utilize deep learning algorithms, such as convolutional neural networks (CNNs), to achieve high levels of accuracy in image recognition tasks.
Image recognition has a wide range of applications, including in healthcare for medical imaging analysis, in retail for object recognition and visual search, in manufacturing for quality control and object tracking, and in entertainment for augmented reality and virtual reality experiences. As machine learning and computer vision techniques continue to advance, image recognition technology is expected to make further strides, enabling computers to understand and interpret visual information with increasing accuracy.
Fraud Detection
Fraud detection is a critical application of machine learning that helps detect and prevent fraudulent activities across various domains, including finance, insurance, and e-commerce. Machine learning algorithms are instrumental in analyzing vast amounts of data, identifying patterns, and flagging suspicious transactions or behaviors, enabling proactive measures to combat fraud effectively.
Fraud detection systems utilize machine learning techniques to learn from historical data and detect fraudulent patterns or anomalies. These systems leverage both supervised and unsupervised learning methods to detect known fraud patterns and discover new, previously unseen fraud patterns.
Supervised learning algorithms can be trained on labeled datasets to learn the characteristics and patterns of fraudulent activities. They learn to recognize specific features or combinations of features associated with fraudulent transactions, allowing for accurate identification of suspicious behavior. These algorithms can help in tasks like credit card fraud detection, insurance claim fraud, and identity theft.
Unsupervised learning algorithms, on the other hand, can detect anomalies or outliers in large datasets without prior knowledge of fraudulent instances. These algorithms identify patterns or data points that deviate significantly from the norm, helping to identify previously unknown fraud patterns. Unsupervised learning is particularly useful in detecting emerging fraud trends or detecting fraud in new environments where historical fraud data is limited.
Fraud detection systems often employ a combination of machine learning algorithms and rules-based systems. The algorithms analyze various factors and variables, such as transaction amount, location, time, or user behavior, to identify suspicious activities. Rules-based systems complement the machine learning algorithms by applying predefined rules and thresholds to trigger alerts or block potentially fraudulent transactions.
As fraudsters evolve their techniques, fraud detection systems must continuously adapt to new approaches and patterns. Machine learning techniques, including deep learning and reinforcement learning, are being increasingly applied to fraud detection, enabling more sophisticated and accurate identification of fraudulent activities.
Leading financial institutions, e-commerce platforms, and insurance companies rely on machine learning algorithms to power their fraud detection systems. These systems help prevent financial losses, protect customers, and ensure a secure environment for transactions.
Overall, fraud detection using machine learning is an ongoing, dynamic process that aims to stay one step ahead of evolving fraudulent activities. By leveraging the power of machine learning algorithms, businesses can effectively detect and combat fraud, safeguarding their operations, and maintaining the trust of their users.
Predictive Analytics
Predictive analytics is a powerful application of machine learning that involves analyzing historical and real-time data to make accurate predictions and forecasts. It leverages advanced machine learning algorithms to identify patterns, relationships, and trends within the data, enabling businesses to make informed decisions and anticipate future outcomes.
Predictive analytics encompasses a wide range of techniques and uses, including:
- Sales Forecasting: Predictive analytics helps businesses forecast future sales or demand based on historical sales data, market trends, and other relevant factors. By accurately predicting sales, businesses can optimize inventory management, production planning, and resource allocation.
- Customer Behavior Analysis: Predictive analytics enables businesses to gain insights into customer behavior by analyzing past interactions, purchase history, browsing patterns, and demographic information. This analysis helps in customer segmentation, personalized marketing campaigns, and customer retention strategies.
- Financial Market Analysis: Predictive analytics algorithms can analyze historical and real-time financial data to identify patterns and trends in the market. This analysis helps investors make informed decisions, predict market movements, and optimize investment strategies.
- Risk Management: Predictive analytics is widely used in the insurance industry to assess risks and determine insurance premium rates based on various factors such as individual health, driving behavior, or property conditions. It helps insurers accurately assess risks, prevent losses, and streamline underwriting processes.
- Supply Chain Optimization: Predictive analytics is crucial in optimizing supply chain operations by analyzing historical and real-time data on inventory levels, production rates, delivery times, and external factors such as weather or transportation disruptions. This analysis helps companies optimize their supply chain, reduce costs, and improve customer satisfaction.
- Quality Control: Predictive analytics can identify potential quality issues or defects in manufacturing processes by analyzing sensor data, historical performance data, and other relevant variables. This helps manufacturers identify and rectify issues early, reduce product recalls, and improve overall product quality.
Predictive analytics models utilize various machine learning algorithms such as linear regression, decision trees, random forests, and neural networks. These algorithms learn from historical data and use it to make predictions or forecasts on new, unseen data instances. The models are typically trained and validated using well-defined metrics, such as accuracy, precision, recall, or mean squared error, to ensure their predictive performance.
Leading companies across industries rely on predictive analytics to optimize business operations, make strategic decisions, and gain a competitive edge. By leveraging predictive analytics, companies can anticipate market trends, mitigate risks, streamline processes, and improve overall business performance.
As machine learning techniques continue to advance, predictive analytics is expected to become even more sophisticated and accurate. With the increasing availability of big data and the development of more powerful algorithms, businesses will have access to valuable insights that drive innovation, enhance decision-making, and unlock new opportunities for growth.
Speech Recognition
Speech recognition is a remarkable application of machine learning that enables computers to convert spoken language into written text. It has revolutionized how we interact with technology, allowing for hands-free control, voice assistants, and speech-to-text applications. In speech recognition systems, machine learning algorithms play a crucial role in understanding and interpreting human speech.
Speech recognition technology utilizes a combination of techniques, including acoustic modeling, language modeling, and pattern recognition, to accurately transcribe spoken words. The process involves converting an audio signal into a sequence of linguistic units, such as phonemes or words, using machine learning algorithms.
There are different approaches to speech recognition:
- Hidden Markov Models (HMMs): HMMs are statistical models that can represent the temporal relationships between phonemes or words. They are widely used in speech recognition to capture the sequential nature of speech and learn the probabilistic patterns of different linguistic units.
- Deep Learning: Deep learning techniques, particularly recurrent neural networks (RNNs) and convolutional neural networks (CNNs), have significantly advanced the field of speech recognition. These models can learn to directly map acoustic features to linguistic units, enabling more accurate and robust speech recognition systems.
- Language Modeling: Language modeling plays an important role in speech recognition by helping the system understand the context and structure of spoken language. Language models utilize statistical techniques and machine learning to predict the likelihood of word sequences, improving the accuracy of speech recognition systems.
Speech recognition has numerous applications, including:
- Virtual Assistants: Speech recognition technology enables virtual assistants like Apple’s Siri, Google Assistant, and Amazon’s Alexa to understand and respond to voice commands. These assistants can perform various tasks, from setting reminders and answering questions to controlling smart home devices.
- Speech-to-Text Applications: Speech recognition is used in applications that convert spoken language into written text, such as dictation software, transcription services, and voice typing. This simplifies data entry, facilitates accessibility for individuals with disabilities, and enhances productivity.
- Voice-Controlled Systems: Speech recognition allows for voice-controlled systems in various domains, including automotive systems, smart home devices, and industrial automation. Users can interact with these systems using natural spoken language, providing convenience and seamless control.
- Speech Analytics: Speech recognition technology is used in call centers and customer service applications to analyze and extract insights from recorded phone conversations. By transcribing and analyzing spoken conversations, businesses can gain valuable information about customer sentiment, trends, and feedback.
- Speech Translation: Machine learning-driven speech recognition has also facilitated advancements in speech translation. By transcribing speech in one language and translating it into another, speech translation systems enable cross-language communication and facilitate multilingual interactions.
Continual advances in machine learning and deep learning techniques promise further improvements in speech recognition accuracy and robustness, opening up new possibilities for voice-controlled systems and natural language interactions.
Conclusion
Machine learning is a rapidly advancing field that has revolutionized numerous industries and has the potential to shape the future of technology and data-driven decision-making. Through the power of machine learning algorithms, computers can learn from data, identify patterns, and make predictions or decisions without being explicitly programmed.
From understanding machine learning concepts to exploring various algorithms, such as supervised learning, unsupervised learning, reinforcement learning, and their applications, it is evident that machine learning has vast potential for solving complex problems and improving efficiency across various domains.
Whether it is recommendation systems personalizing user experiences, natural language processing enabling effective communication with computers, image recognition empowering visual understanding, fraud detection safeguarding financial transactions, predictive analytics providing foresight for informed decision-making, or speech recognition enabling hands-free interactions, machine learning is transforming the way we interact with technology and unlocking new possibilities.
As machine learning techniques continue to advance and datasets grow larger and more diverse, the accuracy and capabilities of machine learning algorithms will only improve. This, in turn, will lead to even more innovative applications and solutions in fields such as healthcare, finance, manufacturing, and beyond.
It is essential to stay updated with the latest developments in machine learning and embrace its potential to drive innovation and solve critical challenges. As we navigate an increasingly data-driven world, harnessing the power of machine learning will be key to unlocking valuable insights, making informed decisions, and creating transformative solutions.
















