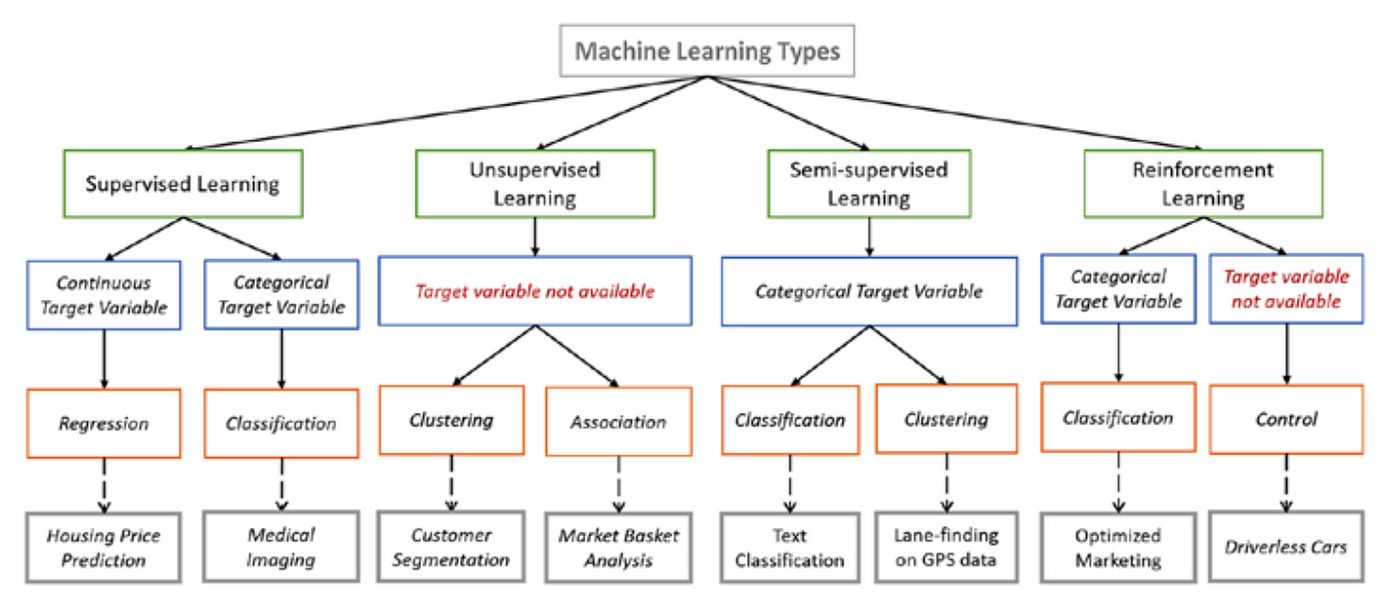
Supervised Learning
Supervised learning is one of the most common and widely used types of machine learning techniques. It involves training a model on a labeled dataset, where the input data is paired with the corresponding output or target variable. The goal of supervised learning is to build a model that can accurately predict the output variable given new input data.
The process of supervised learning can be best understood through an example. Let’s say we have a dataset of housing prices, where the input data consists of features like the area, number of bedrooms, and location, and the output variable is the predicted price of the house. The supervised learning algorithm will analyze the labeled data, find patterns, and establish a relationship between the input variables and the output variable.
There are various algorithms used in supervised learning, such as linear regression, logistic regression, support vector machines (SVM), decision trees, and random forests. Each algorithm has its own strengths and weaknesses, depending on the nature of the problem and the type of data.
Supervised learning is widely applied in many fields, including finance, healthcare, marketing, and natural language processing. It can be used for tasks like credit scoring, image classification, spam detection, sentiment analysis, and recommendation systems. The success of supervised learning depends on the availability of a high-quality labeled dataset, as this is what enables the model to learn and make accurate predictions.
One of the advantages of supervised learning is that it provides a clear evaluation metric to measure the performance of the model. The accuracy of predictions can be measured using metrics like precision, recall, F1 score, or mean squared error, depending on the nature of the problem. This allows for iterative improvements and fine-tuning of the model.
However, supervised learning also has its limitations. It heavily relies on labeled data, which can be time-consuming and expensive to obtain. Additionally, the model’s predictions are limited to the range of the labeled data it was trained on, making it less reliable for extrapolation or predicting unseen data points outside the training set.
Overall, supervised learning is a powerful approach in machine learning that enables the development of accurate prediction models. It is widely used and has a diverse range of applications across various industries. With the right dataset and algorithm, supervised learning can provide valuable insights and solutions to complex problems.
Unsupervised Learning
Unsupervised learning is another important branch of machine learning that deals with unlabeled data. Unlike supervised learning, unsupervised learning algorithms work with datasets where there are no predefined labels or target variables. Instead, the algorithms aim to discover meaningful patterns, structures, and relationships within the data on their own.
One of the main goals of unsupervised learning is to find groups or clusters of similar data points. This process, known as clustering, helps in understanding the underlying structure of the data and identifying patterns or segments within it. The algorithm analyzes the input data and automatically categorizes it into different groups based on similarities in features or attributes.
Another technique used in unsupervised learning is dimensionality reduction. This involves reducing the number of features or variables in the dataset while preserving the essential information. Dimensionality reduction methods like principal component analysis (PCA) or t-distributed stochastic neighbor embedding (t-SNE) help to visualize and represent complex data in a lower-dimensional space, aiding in better understanding and analysis.
Unsupervised learning has various applications in fields like image recognition, anomaly detection, market segmentation, and recommendation systems. For example, in customer segmentation, unsupervised learning can group similar customers together based on their purchasing behavior or preferences. This information can then be utilized for targeted marketing campaigns or personalized recommendations.
One of the advantages of unsupervised learning is that it can uncover hidden patterns or anomalies in the data that might have gone unnoticed. It can discover novel insights and reveal underlying structures that can be valuable for decision-making. Additionally, unsupervised learning algorithms can be applied to large-scale datasets without the need for manual labeling, reducing time and cost.
However, unsupervised learning also faces certain challenges. The lack of labeled data makes it difficult to evaluate the performance of the algorithm objectively. It requires domain expertise and manual interpretation to understand the clusters or patterns discovered by the algorithm. Additionally, unsupervised learning algorithms can be sensitive to outliers or noise in the data, which can impact the accuracy of the results.
In summary, unsupervised learning plays a crucial role in understanding and discovering hidden patterns in unlabeled data. It helps in gaining insights, identifying clusters, and reducing the dimensionality of complex datasets. By utilizing unsupervised learning algorithms, businesses and researchers can unlock valuable information and make data-driven decisions for various applications.
Semi-supervised Learning
Semi-supervised learning is a hybrid approach that combines elements of both supervised and unsupervised learning. It comes into play when a dataset contains a small amount of labeled data and a larger amount of unlabeled data. The goal of semi-supervised learning is to leverage the unlabeled data to improve the performance of the model trained on the labeled data.
In semi-supervised learning, the small labeled dataset is used to train a model initially, similar to supervised learning. However, instead of relying solely on the limited labeled data, the algorithm incorporates the unlabeled data to capture the underlying structure or patterns present in the complete dataset.
The algorithm achieves this by encouraging consistency or similarity between the predictions made on the labeled and unlabeled data. It does so by either propagating the labels from labeled examples to the unlabeled examples or by enforcing smoothness in the decision boundaries between the different classes.
Semi-supervised learning is especially useful in scenarios where obtaining labeled data is expensive, time-consuming, or requires expert annotation. It allows for leveraging the abundance of unlabeled data available in many real-world applications.
One advantage of semi-supervised learning is that it can improve the classification accuracy of the model compared to using only the limited labeled data. By incorporating additional information from the unlabeled data, the algorithm can discover more subtle patterns and better generalize to new, unseen instances.
However, semi-supervised learning also has its challenges. The effectiveness of leveraging the unlabeled data depends on the quality and representativeness of the unlabeled samples. In some cases, unlabeled data may introduce noise or conflicting information that could degrade the performance of the model. Additionally, semi-supervised learning algorithms can be computationally more demanding than traditional supervised learning algorithms.
In summary, semi-supervised learning is a valuable approach when labeled data is scarce, and unlabeled data is plentiful. By combining both labeled and unlabeled data, the algorithm can improve its comprehension of the underlying data structure and enhance the performance of the model. With its ability to leverage unlabeled data, semi-supervised learning opens up new opportunities for learning from large, unlabeled datasets in various domains.
Reinforcement Learning
Reinforcement learning is a type of machine learning that focuses on an agent learning to make decisions through trial and error. Unlike supervised and unsupervised learning, reinforcement learning does not rely on labeled or unlabeled data. Instead, the agent interacts with an environment and learns by receiving feedback in the form of rewards or punishments based on its actions.
The goal of reinforcement learning is to find the optimal policy or set of actions that maximizes the cumulative reward over time. The agent takes actions in the environment, and based on the outcome, it receives a positive or negative reward. The agent then updates its strategy to maximize the rewards it receives in future interactions.
The concept of reinforcement learning can be understood through the example of training an autonomous robot to navigate a maze. The robot starts with no prior knowledge of the maze and explores by taking random actions. When it reaches the goal, it receives a positive reward, and if it hits a wall, it gets a negative reward. Through repeated iterations, the robot learns which actions lead to positive outcomes and adjusts its strategy to navigate the maze efficiently.
Reinforcement learning algorithms use different techniques to balance exploration and exploitation. Initially, the agent explores various actions to understand the environment. Over time, it learns through trial and error, and as it gains more knowledge, it focuses on exploiting the actions that have brought the most rewards in the past.
Reinforcement learning has been successfully applied in various domains, including robotics, game playing, recommendation systems, and optimization problems. Examples include training robots to perform complex tasks, teaching autonomous vehicles to navigate city streets, and creating artificial intelligence agents that can play games like chess or Go at a superhuman level.
One advantage of reinforcement learning is its ability to handle complex, dynamic environments where the optimal decision-making policy may evolve over time. It can adapt to changing conditions and learn from real-time feedback. Additionally, reinforcement learning can discover innovative solutions and strategies that may not have been explicitly programmed.
However, reinforcement learning also faces challenges. The training process can be time-consuming and computationally expensive, especially in complex environments. Designing appropriate reward structures and defining the state space can be difficult, and incorrect rewards or sparse feedback can lead to suboptimal learning. Furthermore, reinforcement learning models are sensitive to the exploration-exploitation trade-off and can get stuck in local optima.
In summary, reinforcement learning is a powerful approach that allows agents to learn from interactions with their environment through rewards and punishments. By optimizing their decision-making policy based on trial and error, agents can gradually improve their performance in complex tasks. Reinforcement learning has the potential for solving real-world challenges and creating intelligent systems that can adapt and learn in dynamic environments.
Deep Learning
Deep learning is a subset of machine learning that focuses on using artificial neural networks with multiple layers (hence the term “deep”) to solve complex problems. It is inspired by the structure and function of the human brain, with each layer of the network processing and transforming the data in a hierarchical manner.
The key advantage of deep learning is its ability to automatically learn hierarchical representations of the input data. This is achieved through a process called training, where the neural network iteratively adjusts the weights and biases of the connections between neurons to minimize the difference between its predicted outputs and the actual outputs.
One of the main applications of deep learning is in computer vision, where convolutional neural networks (CNNs) have achieved remarkable success in image classification, object detection, and image generation tasks. Deep learning has also been applied to natural language processing (NLP), with recurrent neural networks (RNNs) and transformer models proving effective in tasks like language translation, sentiment analysis, and text generation.
The success of deep learning can be attributed to several factors. Deep neural networks have a high capacity to learn intricate patterns and extract meaningful features from raw data. They can handle data with high dimensionality and large amounts of noise. Additionally, advancements in hardware, such as graphical processing units (GPUs) and specialized processors, have enabled the efficient training and deployment of deep learning models.
However, deep learning also poses challenges. Training deep neural networks requires large labeled datasets, which may not always be available. Deep learning models are computationally intensive, requiring significant resources and time for training. They are also prone to overfitting, where the model memorizes the training data, leading to poor generalization on unseen data.
Despite these challenges, deep learning continues to make significant advancements in various fields. It has revolutionized areas such as computer vision, speech recognition, and natural language processing, achieving state-of-the-art performance in many benchmarks. Deep learning models are powering technologies like autonomous vehicles, virtual assistants, and recommendation systems, and they continue to push the boundaries of what is possible in artificial intelligence.
In summary, deep learning is a powerful subset of machine learning that uses artificial neural networks with multiple layers to automatically learn hierarchical representations from data. It has proven to be highly effective in solving complex problems in computer vision, natural language processing, and other domains. With ongoing research and advancements, deep learning holds great potential for driving transformative innovations and creating intelligent systems that can perceive, understand, and interact with the world.
Transfer Learning
Transfer learning is a machine learning technique that aims to leverage knowledge and information learned from one task to improve the performance of a related but different task. It is based on the idea that the knowledge gained from solving one problem can be applied to another problem with some similarities or shared characteristics.
Traditionally, machine learning models were trained from scratch for each new task, requiring a large amount of labeled data and computational resources. Transfer learning, on the other hand, allows models to learn from previous experiences and pre-trained models, reducing the need for extensive training on new datasets.
The process of transfer learning involves taking a pre-trained model, typically trained on a large dataset, and utilizing its learned representations or features for a new task. The pre-trained model’s knowledge is transferred by freezing some or all of its layers and building new layers on top of it to adapt it to the new problem. This process allows the model to extract relevant features from the data in a more efficient and effective manner.
Transfer learning has proven to be highly beneficial, especially in scenarios where there is limited labeled data for the target task. By leveraging the pre-trained model’s knowledge, it can mitigate the need for large amounts of labeled data and significantly reduce the training time and resources required for achieving good performance.
One example of transfer learning is in computer vision tasks. Models pre-trained on large-scale image classification datasets, such as ImageNet, have been found to learn general features and representations that are transferrable to various visual recognition tasks. These pre-trained models can be fine-tuned on smaller, domain-specific datasets to achieve high accuracy with fewer training samples.
Transfer learning is also widely used in natural language processing (NLP). Models pre-trained on a large corpus of text, such as the Transformer model in NLP, can be fine-tuned for specific language understanding or text generation tasks. This approach saves computational resources and time while still achieving state-of-the-art results.
However, transfer learning is not always straightforward. The success of transfer learning depends on the similarity between the tasks and the availability of relevant pre-trained models or datasets. A misalignment between the source and target tasks can result in ineffective transfer and may require additional adaptations or domain-specific training.
In summary, transfer learning is a powerful technique in machine learning that allows models to leverage existing knowledge and pre-trained models to improve performance on new tasks. By transferring learned representations, it can reduce the need for extensive training and labeled data for the target task. Transfer learning has found success in various domains and has become an essential tool for accelerating and enhancing the performance of machine learning models.
Online Learning
Online learning, also known as incremental learning or lifelong learning, is a machine learning approach that involves training models on data that arrives sequentially, rather than in a batch. It is particularly useful in scenarios where new data becomes available over time and the model needs to adapt and update its predictions continuously.
In online learning, the model learns from individual instances or small batches of data as they arrive, making predictions and updating its parameters in real-time. This process allows the model to adapt to changes in the data distribution and make predictions on new, unseen instances without retraining the entire model.
One of the main advantages of online learning is its ability to handle dynamic environments and evolving data. It is well-suited for applications where the data distribution changes over time or when there is a need for quick adaptation to new trends or patterns. Online learning allows for faster model deployment and can save computational resources compared to traditional batch learning approaches.
Online learning is commonly used in various domains, including online advertising, fraud detection, recommendation systems, and sensor data analysis. For example, in online advertising, models need to continuously update their understanding of user preferences and behavior to deliver relevant ad recommendations. Online learning enables them to learn from user interactions and optimize ad delivery in real-time.
However, online learning also poses challenges. Handling noisy or biased data can lead to incorrect updates and impact the model’s performance. The selection of appropriate learning rate and regularization parameters becomes crucial to prevent overfitting or underfitting. Moreover, monitoring and detecting concept drift, which is the change in the underlying data distribution, is necessary to ensure model accuracy over time.
Another challenge in online learning is the trade-off between exploration and exploitation. The model needs to strike a balance between trying out new actions or decisions to gather more information and exploiting the current knowledge to maximize immediate rewards. Selecting the right exploration-exploitation strategy is crucial in achieving optimal results in dynamic environments.
In summary, online learning is a powerful machine learning approach that enables models to learn from sequentially arriving data and update their predictions in real-time. It is well-suited for dynamic environments and applications that require continuous adaptation and quick response to changing data patterns. While online learning brings numerous advantages, careful consideration of challenges such as noisy data, concept drift, and exploration-exploitation trade-offs is essential for successful implementation and accurate model predictions.
Active Learning
Active learning is a machine learning approach that involves an iterative process of selecting the most informative instances from a large pool of unlabeled data and acquiring their labels through human annotation. It aims to optimize the learning process by actively selecting the “right” data points to label, reducing the need for extensive labeling of the entire dataset.
In active learning, the initial labeled data is used to train a model. The model then analyzes the unlabeled data and selects a subset of samples that it considers the most uncertain or informative. These selected samples are sent to human annotators for labeling. The newly labeled data is then added to the training set, and the model is retrained. This iterative process continues until the desired performance is achieved.
The key advantage of active learning is that it allows models to learn from a small labeled dataset while achieving performance equivalent to or even better than models trained on larger datasets. By selectively choosing the most informative instances to label, active learning significantly reduces the need for extensive manual annotation, which can be time-consuming and costly.
Active learning has applications in various domains, including text classification, image recognition, and sentiment analysis. For example, in text classification tasks, active learning can help prioritize the labeling of ambiguous or challenging examples, improving the model’s understanding of complex linguistic structures and nuances.
There are several active learning strategies used to select the most informative samples for labeling. Some common strategies include uncertainty sampling, query-by-committee, and diversity-based sampling. Uncertainty sampling selects instances with the highest uncertainty or disagreement among the model’s predictions. Query-by-committee considers multiple models and selects instances where there is disagreement among the models. Diversity-based sampling aims to cover as many diverse regions of the input space as possible, ensuring a representative and diverse set of labeled instances.
However, active learning also faces challenges. The success of active learning relies on the quality of the selected samples for labeling. If the selected samples are not truly informative or representative, the model’s performance may not improve significantly. Selecting the appropriate active learning strategy and balancing the exploration of diverse instances with exploiting informative instances is critical for achieving optimal results.
In summary, active learning is a powerful approach that enables models to select the most informative instances to label, reducing the need for extensive manual annotation. By actively choosing the right samples for labeling, active learning optimizes the learning process and allows models to achieve high performance with limited labeled data. Careful consideration of active learning strategies and the quality of selected samples is essential for successful implementation and improved model performance.
Ensemble Learning
Ensemble learning is a machine learning technique that combines the predictions of multiple individual models (known as base learners) to make more accurate and robust predictions. It leverages the diversity and collective wisdom of multiple models to improve overall performance and reduce the risk of overfitting.
The fundamental idea behind ensemble learning is that combining multiple models that have different strengths and weaknesses can lead to better results than relying on a single model. Each base learner in an ensemble is trained on a subset of the data or using a different algorithm, allowing them to capture different aspects of the problem or dataset.
There are various approaches to ensemble learning, with two common types being bagging and boosting. Bagging, short for bootstrap aggregating, involves training multiple models on different subsets of the training data and combining their predictions through voting or averaging. RandomForest is an example where an ensemble of decision trees is used. Boosting, on the other hand, involves training models sequentially, with each subsequent model focusing on the examples that the previous models find most challenging. Gradient Boosting is a popular boosting algorithm.
Ensemble learning offers several advantages over a single model. It can improve predictive accuracy by reducing the variance and bias inherent in individual models. It is often more robust and less sensitive to noise in the data. Ensemble models are also more resistant to overfitting, as the combination of different models helps to generalize better to unseen data.
Ensemble learning has been successfully applied in various domains, including pattern recognition, image classification, and regression tasks. For example, in Kaggle competitions, ensemble models are frequently used by top-performing participants to achieve the highest accuracy.
However, ensemble learning also has its challenges. Building and training multiple models can be computationally expensive and time-consuming, especially with large datasets or complex models. Ensuring diversity among the base learners is crucial to avoid correlation and obtain the full benefits of ensemble learning. Ensemble models can also be difficult to interpret and explain compared to individual models.
In summary, ensemble learning is a powerful technique that combines the predictions of multiple models, improving accuracy and robustness. By leveraging the diversity and collective intelligence of individual models, ensemble learning offers higher accuracy, reduced overfitting, and improved generalization. While ensemble learning has challenges, its effectiveness in various domains makes it a valuable tool in machine learning.