Introduction
Machine learning has become increasingly prevalent in our modern world, influencing various aspects of our lives, from the personalized recommendations we receive on streaming platforms to the autonomous vehicles that navigate our roads. Though the term “machine learning” may seem complex and intimidating, it refers to a field of study that enables computers to learn and make predictions or decisions without being explicitly programmed.
At its core, machine learning leverages algorithms and statistical models to enable computers to learn from data, identify patterns, and make informed decisions or predictions. This remarkable capability allows machines to continuously improve their performance as they gather more data and refine their algorithms.
The concept of machine learning is not entirely new. Over the past few decades, researchers have been developing and refining machine learning techniques to create intelligent systems that can mimic human cognitive processes. These advancements have paved the way for significant breakthroughs in numerous industries.
In this article, we will explore the fascinating world of machine learning, including its definition, origins, working principles, key terminology, types of algorithms, and applications. We will also examine the benefits and limitations of machine learning and how it has become an integral part of Google’s operations.
Through this exploration, we hope to shed light on the transformative power of machine learning and its potential to shape the future. Whether you are a novice curious about this field or a seasoned professional seeking deeper insights, this article will serve as a comprehensive guide to understanding the fundamentals of machine learning and its impact on our world.
Definition of Machine Learning
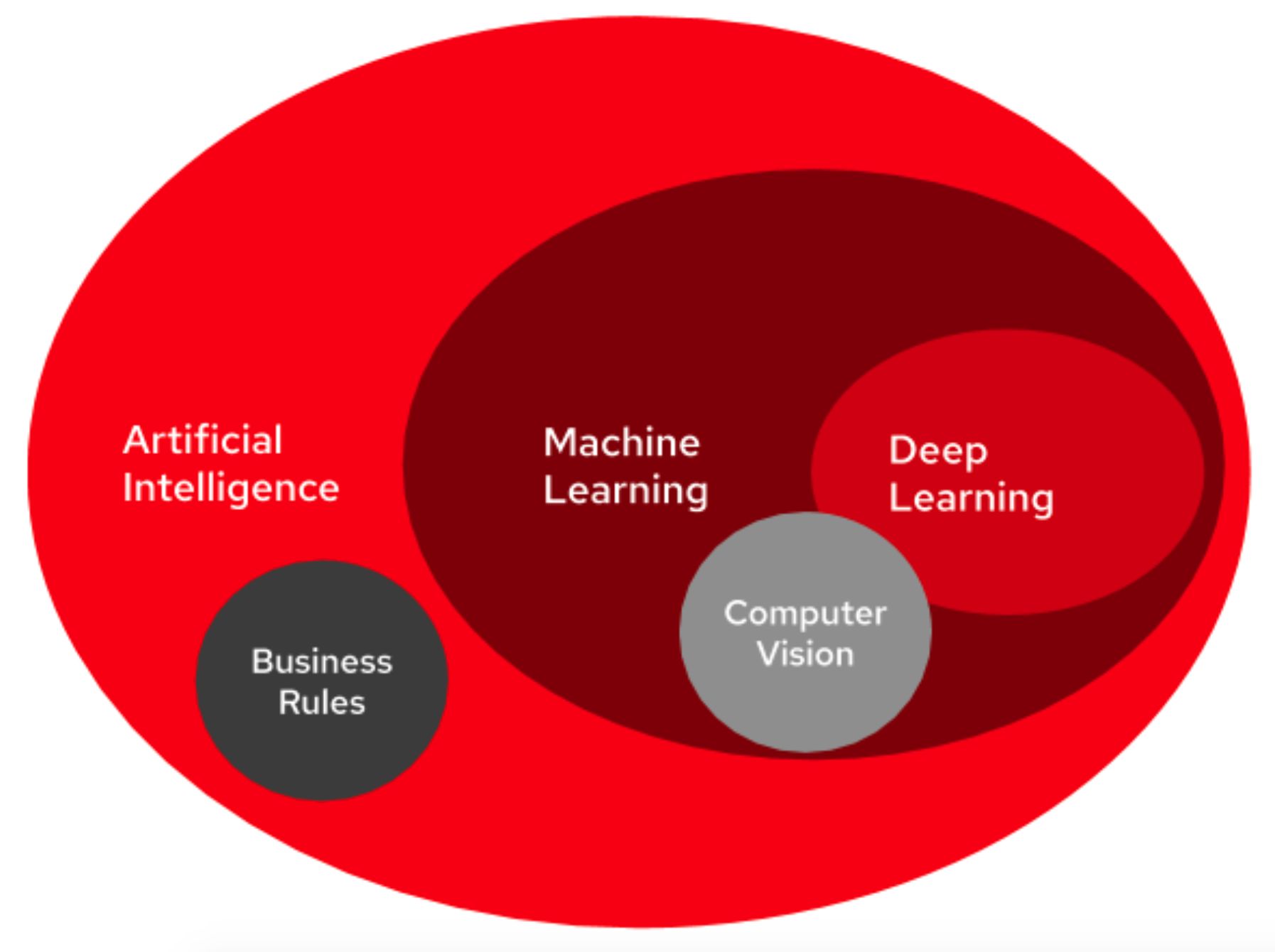
Machine learning is a subfield of artificial intelligence (AI) that focuses on developing algorithms and models that allow computers to learn from and analyze data, without explicitly being programmed for specific tasks. It involves the development of statistical models and algorithms that enable machines to automatically improve their performance or make predictions based on patterns and insights gained from data.
Machine learning algorithms can be trained to identify and recognize patterns, make predictions or decisions, and automatically adjust their behaviors as they gather more data. This ability to learn from experience distinguishes machine learning from traditional programming, where rules and instructions are explicitly defined.
One of the key elements of machine learning is the use of training data. This data is typically labeled, meaning it has been pre-labeled with the correct outcomes or classifications. The machine learning algorithm is then trained on this data, which allows it to learn patterns and relationships between the input data and the corresponding output or outcome.
Once the algorithm is trained, it can be applied to new, unseen data to make predictions or decisions. This capability is what makes machine learning incredibly powerful and applicable to a wide range of domains and industries.
There are different types of machine learning techniques, including supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Supervised learning involves using labeled training data to train the model, while unsupervised learning focuses on finding patterns and relationships in unlabeled data. Semi-supervised learning combines elements of both supervised and unsupervised learning, while reinforcement learning involves learning through a reward-based system.
Overall, machine learning is a dynamic field that continues to evolve, with new algorithms and techniques being developed regularly. Its applications are vast and extend across industries like healthcare, finance, marketing, and more. Understanding the definition and principles of machine learning is essential to grasp its potential and harness its power to drive innovation and solve complex problems.
Origins of Machine Learning
The origins of machine learning trace back to the beginnings of computer science and artificial intelligence. While the term “machine learning” gained popularity in recent years, the concept and techniques behind it have been in development for decades.
One of the earliest pioneers in the field of artificial intelligence and machine learning was Arthur Samuel. In 1956, Samuel developed the first computer program capable of learning, known as the Samuel Checkers-Playing Program. This program used a technique called reinforcement learning to improve its performance in playing checkers through trial and error.
In the 1960s and 1970s, machine learning saw significant advancements with the emergence of new techniques and algorithms. The field began to focus more on statistical approaches and pattern recognition, such as the development of the nearest-neighbor algorithm by IBM researcher Evelyn Boyd Granville.
Another milestone in the history of machine learning was the development of decision tree algorithms, which allowed machines to make decisions based on a hierarchical structure of rules and conditions. This breakthrough led to the foundation of the field known as symbolic machine learning.
During the 1980s and 1990s, the field of machine learning experienced a surge in popularity and research. Researchers developed more sophisticated algorithms, such as neural networks, which are inspired by the structure and function of the human brain. Neural networks enabled machines to learn complex patterns and relationships from data.
The availability of large datasets and advancements in computational power in the 2000s revolutionized machine learning. This era witnessed the rise of deep learning, a subfield of machine learning that focuses on using deep neural networks to learn from vast amounts of data. Deep learning algorithms have achieved remarkable breakthroughs in various domains, including image recognition, speech processing, and natural language processing.
Today, machine learning continues to evolve and expand, aided by advancements in technology and the proliferation of data. Researchers and practitioners are exploring new techniques, such as reinforcement learning, generative adversarial networks (GANs), and transfer learning, to push the boundaries of what machines can learn and achieve.
The origins of machine learning lay the foundation for the impressive capabilities we see today, from self-driving cars to virtual assistants. Understanding this rich history allows us to appreciate the progress made in this field and inspires us to explore new possibilities for the future.
How Does Machine Learning Work?
Machine learning works by utilizing algorithms and statistical models to enable computers to learn from data and make predictions or decisions. The process typically involves several steps, including data collection, preprocessing, model training, and evaluation.
The first step in machine learning is data collection. This involves gathering relevant data that will be used to train the machine learning model. The data can come from various sources, such as databases, sensors, or online platforms. It is crucial to ensure that the data is representative and diverse enough to capture the patterns and relationships of the problem at hand.
Once the data is collected, it needs to be preprocessed to prepare it for analysis. This step involves tasks such as cleaning the data, handling missing values, and transforming the data into a format suitable for the machine learning algorithm. Data preprocessing is essential to ensure the quality and consistency of the data, which directly impacts the performance and accuracy of the model.
After preprocessing the data, the next step is model training. This involves selecting an appropriate machine learning algorithm and training it on the labeled or unlabeled data. During the training process, the algorithm learns from the data and identifies patterns and relationships between the input variables and the target variable. The specifics of model training can vary depending on the algorithm being used, but the general objective is to optimize the algorithm’s parameters to minimize errors or maximize predictive accuracy.
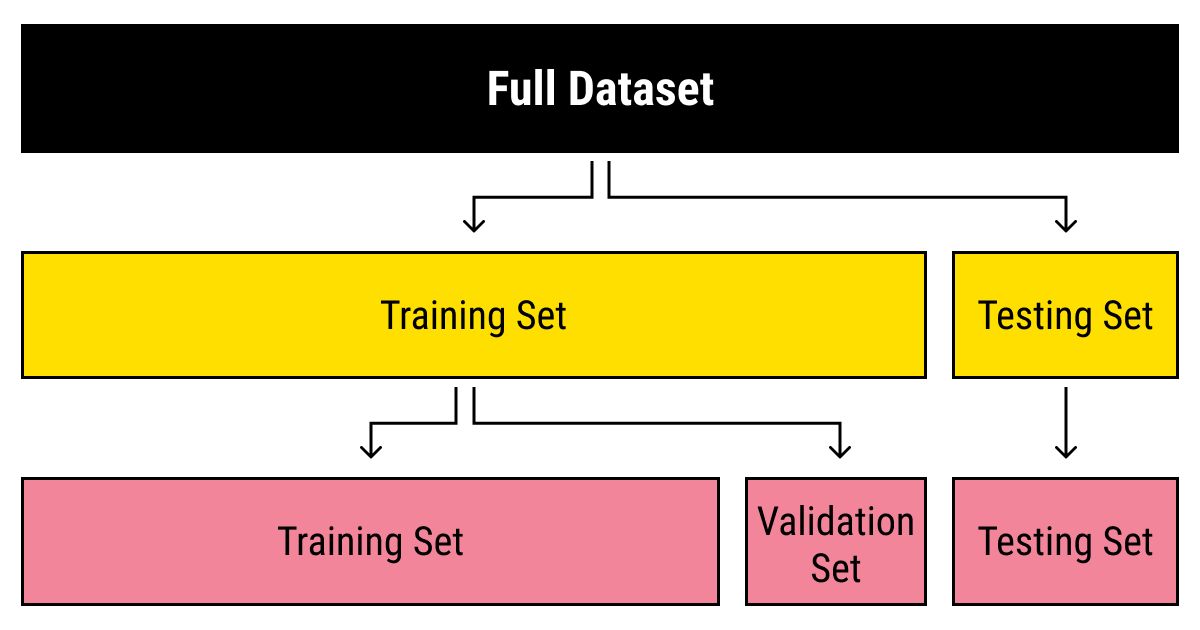
Once the model is trained, it needs to be evaluated to assess its performance. This evaluation is typically done on a separate set of data called the test set or validation set. The model’s predictions on the test set are compared to the actual values to measure its accuracy and generalization ability. If the model performs well on the test set, it can be considered successful, and it can be deployed to make predictions or decisions on new, unseen data.
It is important to note that machine learning models are not set in stone. The models can be further refined and improved by iterating through the training and evaluation process with new data. This process is known as model tuning or optimization.
Machine learning also relies on continuous learning and adaptation to changing circumstances. As new data becomes available, the models can be updated to incorporate this information and improve their predictions or decisions. This iterative process of learning, evaluating, and updating is what makes machine learning a powerful tool for solving complex problems and making data-driven decisions.
Overall, machine learning works by harnessing the power of data and algorithms to enable computers to learn from experience, make predictions, and continuously improve their performance. Understanding the inner workings of machine learning allows us to appreciate its capabilities and explore its vast potential in various domains.
Key Terminology in Machine Learning
Machine learning, like any specialized field, has its own set of key terminologies and concepts. Understanding these terms is crucial for grasping the fundamental principles of machine learning and effectively communicating within the field. Here are some of the key terminologies commonly used in machine learning:
- Algorithm: An algorithm in machine learning refers to a set of instructions or rules that a computer program follows to solve a specific problem or perform a task. Machine learning algorithms are designed to learn and make predictions from data.
- Training Data: Training data refers to the labeled or unlabeled dataset used to train a machine learning model. Labeled data includes both the input data and the corresponding output or target variable. Unlabeled data does not have the corresponding target variable and is used in unsupervised learning.
- Feature: Features are the individual measurable properties or characteristics of the data that are used as input variables in a machine learning model. The choice and selection of relevant features play a critical role in the model’s performance and accuracy.
- Model: A model in machine learning represents the learned pattern or relationship between the input variables (features) and the output variable (target variable). The model is created based on the training data and is used for making predictions or decisions on new, unseen data.
- Supervised Learning: Supervised learning is a type of machine learning where the training data is labeled, meaning it has both the input data and the corresponding output variable. The goal of supervised learning is to learn the mapping between the input and output variables to make predictions on new data.
- Unsupervised Learning: Unsupervised learning is a type of machine learning where the training data is unlabeled, meaning it only consists of the input data. The goal of unsupervised learning is to discover patterns, structures, or relationships within the data without specific output or target variables.
- Overfitting: Overfitting is a phenomenon in machine learning where a model performs well on the training data but fails to generalize to new, unseen data. It occurs when the model becomes too complex and learns noise or irrelevant patterns instead of the true underlying patterns.
- Underfitting: Underfitting is the opposite of overfitting. It occurs when a model is too simple to capture the underlying patterns in the training data, resulting in poor performance on both the training data and new data.
- Evaluation Metrics: Evaluation metrics are used to assess the performance of a machine learning model. Common evaluation metrics include accuracy, precision, recall, F1 score, and mean squared error, depending on the nature of the problem and the type of the model.
- Bias-Variance Tradeoff: The bias-variance tradeoff refers to the balance between a model’s ability to capture the true underlying patterns in the data (low bias) and its sensitivity to noise or fluctuations in the data (high variance). Finding the right balance is crucial for achieving optimal model performance.
These are just a few key terms used in machine learning. Familiarizing yourself with this terminology will help you navigate the field, understand research papers and articles, and engage in meaningful discussions about machine learning concepts and techniques.
Types of Machine Learning Algorithms
Machine learning algorithms are the building blocks of machine learning models. They are designed to learn patterns, make predictions, and make decisions based on the data they are given. There are various types of machine learning algorithms, each suited for different types of data and problem domains. Here are some of the most common types:
- Supervised Learning: Supervised learning algorithms are trained on labeled data, where the input data is accompanied by the corresponding output or target variable. These algorithms learn the mapping between the input and output variables and can then make predictions on new, unseen data. Popular algorithms in supervised learning include linear regression, logistic regression, decision trees, random forests, support vector machines (SVM), and artificial neural networks (ANN).
- Unsupervised Learning: Unsupervised learning algorithms operate on unlabeled data, where the input data does not have corresponding output variables. These algorithms aim to discover patterns, structures, or relationships within the data without prior knowledge of the desired output. Common unsupervised learning algorithms include clustering algorithms such as k-means clustering, hierarchical clustering, and density-based spatial clustering of applications with noise (DBSCAN). Dimensionality reduction algorithms like principal component analysis (PCA) and independent component analysis (ICA) are also commonly used.
- Semi-Supervised Learning: Semi-supervised learning algorithms leverage both labeled and unlabeled data for training. They are useful when acquiring labeled data is expensive or time-consuming. These algorithms combine elements of supervised and unsupervised learning to learn from both labeled and unlabeled data and make predictions on new data. Generative models, such as Gaussian mixture models (GMM), and co-training algorithms are popular techniques in semi-supervised learning.
- Reinforcement Learning: Reinforcement learning algorithms learn through an interactive process of trial and error. They operate in an environment where an agent learns to take actions to maximize rewards or minimize penalties. The agent learns from feedback received in the form of positive or negative reinforcement, allowing it to optimize its decision-making policy. Q-learning, policy gradient methods, and deep reinforcement learning algorithms, such as Deep Q-Networks (DQN) and Proximal Policy Optimization (PPO), are commonly used in reinforcement learning.
- Deep Learning: Deep learning algorithms are a subset of machine learning algorithms inspired by the structure and function of the human brain. They leverage deep neural networks with multiple layers to learn hierarchical representations from data. Deep learning algorithms excel in tasks such as image and speech recognition, natural language processing, and recommendation systems. Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Generative Adversarial Networks (GAN) are some of the popular deep learning algorithms.
These are just a few types of machine learning algorithms, and the field continues to evolve with new algorithms being developed regularly. Understanding the different types of algorithms allows data scientists and practitioners to choose the most suitable approach for a given problem and data set. It is important to keep in mind that the choice of algorithm depends on the characteristics of the data, the problem at hand, and the desired outcome.
Applications of Machine Learning
Machine learning has found applications in a wide range of industries and domains, revolutionizing the way we work, live, and interact with technology. The ability of machine learning algorithms to analyze vast amounts of data and make intelligent predictions or decisions has led to significant advancements and innovation. Here are some of the key applications of machine learning:
- Image and Speech Recognition: Machine learning algorithms have made remarkable advancements in image and speech recognition. They have enabled the development of accurate facial recognition systems, automatic speech recognition, and object detection technologies. These applications find use in fields such as security, healthcare, entertainment, and customer service.
- Natural Language Processing (NLP): NLP encompasses tasks such as language translation, sentiment analysis, text summarization, and chatbot development. Machine learning algorithms have improved automated language processing, enabling accurate translation systems, sentiment analysis of online reviews, and intelligent chatbots that mimic human-like conversations.
- Healthcare: Machine learning plays a vital role in healthcare applications, including disease diagnosis, drug discovery, patient monitoring, and personalized medicine. Algorithms can analyze patient data to identify patterns, aid in diagnosing diseases, and predict patient outcomes. This has led to more accurate diagnoses, efficient drug development, and improved patient care.
- Finance: Machine learning has revolutionized the financial industry, enabling automated fraud detection, algorithmic trading, credit scoring, and personalized financial products. Machine learning models can analyze large volumes of financial data in real-time to identify fraudulent transactions, make trading decisions, and provide personalized investment recommendations.
- Marketing and Customer Analytics: Machine learning algorithms are used in marketing to analyze customer behavior, segment customer data, and predict customer preferences. This enables the delivery of personalized marketing campaigns, targeted advertising, and customer churn prediction. Machine learning also facilitates customer sentiment analysis, which helps companies understand customer feedback and improve their products and services.
- Autonomous Vehicles: Machine learning is at the core of autonomous vehicle technology. Self-driving cars rely on complex algorithms and models to perceive their environment, detect obstacles, and make decisions in real-time. Machine learning enables vehicles to learn from vast amounts of sensory data to navigate safely and efficiently on roads.
- Recommendation Systems: Recommendation systems are present in various online platforms, from e-commerce to streaming services. Machine learning algorithms analyze user preferences and past behaviors to recommend products, movies, or music tailored to individual users’ tastes. These systems enhance user experience, drive engagement, and increase customer satisfaction.
These are just a few examples of the wide-ranging applications of machine learning. The field continues to expand, enabling innovative solutions to complex problems in various industries. As technology advances and more data becomes available, machine learning will likely play an increasingly prominent role in shaping our future.
Benefits and Limitations of Machine Learning
Machine learning offers a multitude of benefits and has the potential to revolutionize industries and improve decision-making processes. However, it is not without its limitations. Understanding both the benefits and limitations of machine learning is crucial for effectively utilizing this powerful technology. Here are some of the key benefits and limitations:
Benefits of Machine Learning:
- Automation and Efficiency: Machine learning algorithms automate repetitive tasks, leading to increased efficiency and productivity. They can process vast amounts of data quickly and identify patterns or insights that would be challenging for humans to detect.
- Predictive Analytics: Machine learning enables accurate predictions and forecasts based on historical data. This can aid in making data-driven decisions, anticipating market trends, and optimizing business processes.
- Personalization: Machine learning algorithms can analyze user data and provide personalized recommendations or experiences. This enhances customer satisfaction and engagement by delivering tailored content, products, or services.
- Improved Decision Making: Machine learning provides valuable insights and data-driven recommendations, enabling more informed decision-making. It can help identify factors contributing to a problem or opportunity and suggest the most effective course of action.
- Handling Complex and Large-Scale Data: Machine learning algorithms excel at analyzing complex and large-scale data. They can uncover patterns and relationships in data that may not be apparent to humans, leading to breakthroughs in various domains.
Limitations of Machine Learning:
- Data Dependence: Machine learning models heavily rely on high-quality and relevant data for training and decision-making. When the training data is incomplete, biased, or not representative, it can lead to inaccurate or biased predictions.
- Interpretability: Some machine learning algorithms, such as deep neural networks, are often considered “black boxes” as they lack interpretability. Understanding how and why a model makes a specific decision can be challenging, especially in critical domains like healthcare or finance.
- Ethical Considerations: Machine learning algorithms can inadvertently perpetuate biases present in the training data. This raises ethical concerns, such as discrimination or privacy violations, which need to be carefully addressed in algorithm design and deployment.
- Need for Expertise: Implementing and fine-tuning machine learning algorithms require specialized knowledge and expertise. Skilled data scientists are needed to ensure proper model selection, data preprocessing, and interpretation of results.
- Dependency on Computational Resources: Some machine learning algorithms, especially deep learning models, require significant computational power and resources. This can pose challenges for organizations with limited computing capabilities or financial constraints.
While the benefits of machine learning are substantial, it is essential to recognize and address the limitations to ensure responsible and reliable use of this technology. By leveraging the advantages and overcoming the challenges, machine learning can unlock tremendous opportunities for innovation, automation, and data-driven decision-making.
Machine Learning and Google
Machine learning plays a pivotal role in Google’s operations, enabling the company to deliver personalized and relevant experiences to its users, improve search results, and enhance various product offerings. Google leverages machine learning algorithms and techniques across multiple domains to provide effective solutions and services. Here are some notable applications of machine learning within Google:
Search Engine Algorithms: Google’s search engine, one of the most widely used globally, relies on machine learning algorithms to understand and rank web pages. Algorithms such as RankBrain and BERT (Bidirectional Encoder Representations from Transformers) utilize natural language processing and deep learning techniques to interpret search queries and deliver more accurate search results.
Advertisement Targeting: Google’s online advertising platform utilizes machine learning to target ads to relevant users. By analyzing user behavior, preferences, and demographics, machine learning algorithms can serve personalized ads, maximizing advertisers’ reach and increasing click-through rates.
Google Maps and Navigation: Machine learning algorithms contribute to Google Maps’ traffic estimation, route optimization, and real-time transit updates. These algorithms learn from vast amounts of historical data and current traffic conditions to provide accurate and reliable navigation guidance.
Google Translate: Google Translate employs machine learning to improve language translation accuracy and readability. Through deep learning models, the system can analyze patterns in multilingual text data and generate more fluent and coherent translations.
Google Photos: Machine learning algorithms are utilized extensively in Google Photos for automated image recognition, object detection, and photo organization. The algorithms can recognize and categorize objects, people, and scenes in photos, allowing users to easily search for specific images.
Natural Language Processing: Google employs machine learning-powered language models, like BERT, to enhance language understanding and process natural language queries more effectively. This technology improves voice assistants like Google Assistant, making them more capable of understanding and responding to user commands.
Recommendation Systems: Google utilizes machine learning algorithms to power personalized recommendations in various products, including YouTube, Play Store, and Google News. These algorithms analyze user preferences, browsing history, and engagement patterns to suggest relevant content for a more tailored user experience.
Machine learning is deeply embedded within Google’s infrastructure, and it continues to be a driving force behind many of the company’s technological advancements. By harnessing the power of machine learning, Google exemplifies how this technology can improve user experiences, streamline processes, and deliver intelligent solutions on a massive scale.
As Google continues to invest in machine learning research and development, we can expect even more innovative applications and advancements that will shape the future of technology and how we interact with information online.
Conclusion
Machine learning has emerged as a transformative force in the modern world, allowing computers to learn from data, make predictions, and automate complex tasks. From personalized recommendations to autonomous vehicles, machine learning has found applications in various industries, revolutionizing the way we work and interact with technology.
In this article, we explored the definition of machine learning, its origins, and how it works. We discussed key terminology in machine learning, such as algorithms, models, supervised and unsupervised learning, and the different types of machine learning algorithms. We also delved into the applications of machine learning across industries, including healthcare, finance, marketing, and more, highlighting the wide-ranging impact it has had on various domains.
We discussed the benefits of machine learning, such as automation, predictive analytics, personalization, and improved decision-making. However, we also acknowledged the limitations, such as data dependence, interpretability challenges, ethical considerations, need for expertise, and reliance on computational resources. Understanding these benefits and limitations is essential for responsible and effective use of machine learning.
We also examined the role of machine learning within Google, showcasing its applications in search engine algorithms, advertisement targeting, navigation, translation, and recommendation systems. Google’s integration of machine learning into its products and services demonstrates how this technology can enhance user experiences and bring innovative solutions to a global scale.
As technology continues to advance and more data becomes available, the potential of machine learning will only grow. It is a dynamic field that constantly evolves, with new algorithms and techniques being developed regularly. With the right expertise and careful consideration of ethical implications, machine learning has the power to drive innovation, solve complex problems, and make data-driven decisions in countless domains.
As we move forward, understanding and embracing the opportunities and challenges presented by machine learning will be crucial. By harnessing its potential and leveraging its benefits while addressing its limitations, we can shape a future where machine learning plays a central role in driving positive change, advancing technology, and improving the lives of individuals and communities worldwide.