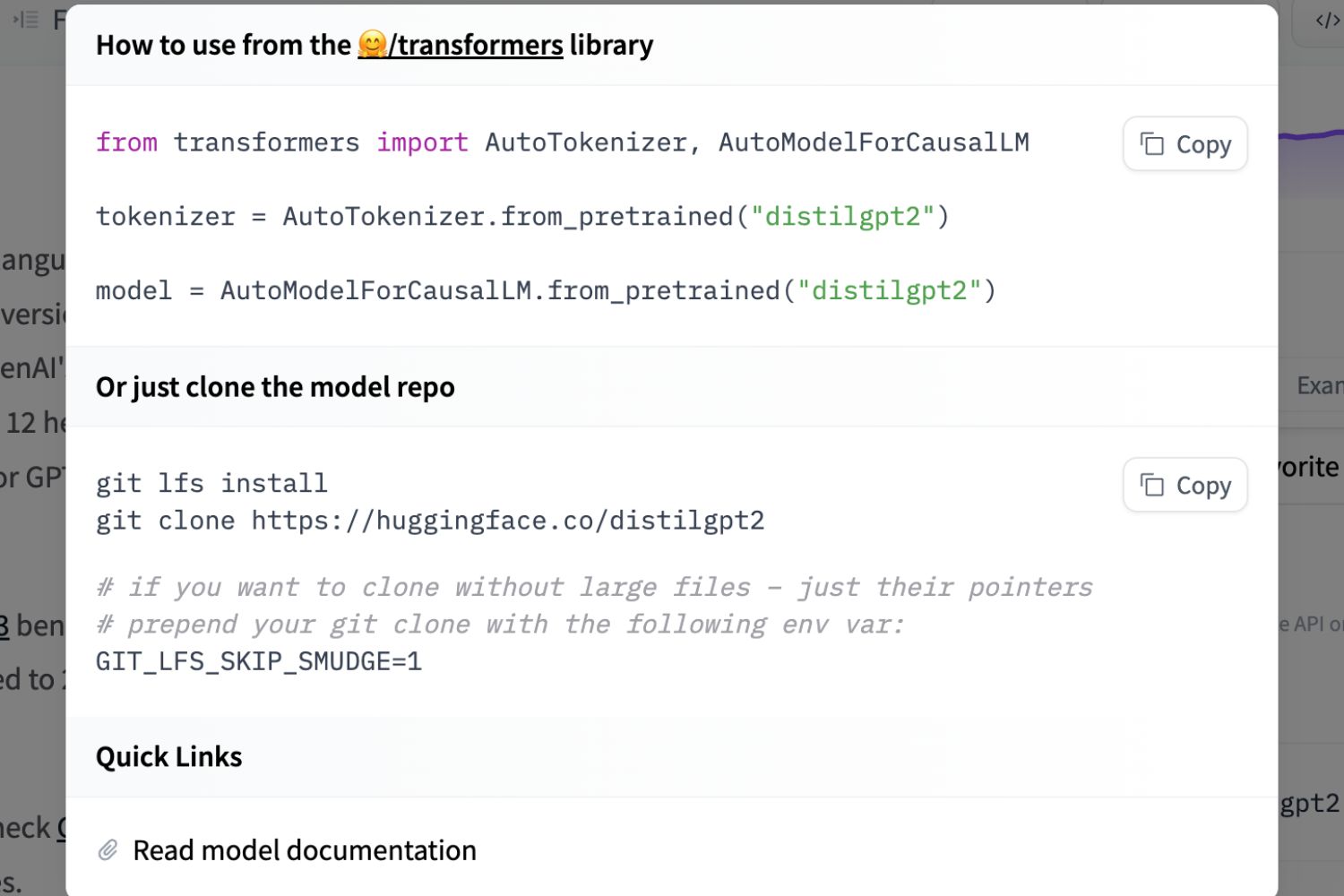
Introduction
When it comes to machine learning, having relevant and high-quality datasets is crucial for training and testing algorithms. However, finding suitable datasets can sometimes be a daunting task. Fortunately, there are several resources available that offer a wide range of public datasets for machine learning purposes.
In this article, we will explore different platforms and repositories where you can find datasets to fuel your machine learning projects. Whether you are a beginner or an experienced practitioner, these resources will provide you with a diverse set of data that you can use to develop and improve your machine learning models.
By using public datasets, you not only save time and effort on data collection and cleaning but also benefit from the collaborative nature of the machine learning community. These datasets have been meticulously curated and made available for others to use, enabling researchers and developers to build upon existing knowledge and explore new possibilities.
It is important to note that the choice of dataset will largely depend on the specific problem you are trying to solve and the type of machine learning algorithm you are using. Keep in mind the characteristics and size of the dataset, as well as its relevance to your project, to ensure that you are working with the most suitable data.
In the following sections, we will explore some of the popular platforms and repositories where you can find datasets for machine learning purposes. From well-known sources like Kaggle and Google Dataset Search to government-sponsored initiatives like Data.gov and data.world, we will cover a wide range of options for acquiring datasets that cater to different domains and objectives.
So, without further ado, let’s dive into the world of public datasets for machine learning and discover where you can find the perfect data to fuel your next project.
Public Datasets
Public datasets are widely available resources that cover a variety of topics and domains. These datasets are typically made freely accessible to the public and are suitable for a wide range of machine learning tasks. Let’s explore some of the popular platforms and repositories where you can find public datasets:
Kaggle
Kaggle is a well-known platform that hosts a vast collection of datasets contributed by the data science community. It offers datasets on diverse topics, including image classification, natural language processing, and time series analysis. Kaggle also organizes machine learning competitions where participants can apply their skills to real-world problems.
UCI Machine Learning Repository
The UCI Machine Learning Repository is a popular resource for finding datasets for educational and research purposes. It offers a wide range of datasets covering various domains such as finance, healthcare, and social sciences. The repository provides detailed information about each dataset, including attribute descriptions and citation guidelines.
Google Dataset Search
Google Dataset Search is a search engine specifically designed to help users discover datasets. It indexes millions of publicly available datasets from various sources, making it easier to find relevant data for machine learning projects. The search results provide information about the dataset, including its description, size, and licensing.
AWS Open Data Registry
The AWS Open Data Registry is a curated collection of publicly available datasets hosted on the Amazon Web Services (AWS) platform. It provides access to a wide range of datasets, including genomics data, satellite imagery, and social media data. AWS offers various tools and services to analyze and process these datasets easily.
Data.gov
Data.gov is a U.S. government initiative that provides access to thousands of datasets from federal agencies. The datasets cover a wide range of topics, including climate, education, and health. Data.gov promotes transparency and encourages collaboration by making government data available to the public for research and development purposes.
These are just a few examples of platforms and repositories that offer public datasets for machine learning projects. It is important to explore and evaluate different sources to find the most suitable data for your specific needs. Remember to properly cite the datasets you use and comply with any licensing or usage restrictions to respect the data providers’ terms and conditions.
Kaggle
Kaggle is a renowned platform that serves as a hub for data science and machine learning enthusiasts. It not only offers a vast collection of datasets but also provides a collaborative environment for users to participate in machine learning competitions, share code, and engage in discussions.
Kaggle hosts a diverse range of datasets contributed by the data science community. These datasets cover various domains, including image classification, natural language processing, and tabular data analysis. Many of these datasets come with well-defined problem statements, making them ideal for training and evaluating machine learning models.
One of the key features of Kaggle is its active community. Users can collaborate with others, ask questions, and share insights. The platform encourages knowledge sharing through notebook-style submissions, enabling users to showcase their analysis and models in a structured and accessible manner.
In addition to datasets, Kaggle hosts machine learning competitions. These competitions allow users to apply their skills to solve real-world problems while competing with other data scientists. Participating in competitions not only hones your skills but also provides an opportunity to learn from other participants’ approaches and gain valuable experience.
Kaggle provides a user-friendly interface that makes it easy to browse and search for datasets. Each dataset is accompanied by a detailed description, including information on data sources, features, and any preprocessing that has been performed. This information helps users understand the dataset and determine its suitability for their specific machine learning task.
Furthermore, Kaggle offers a platform for users to submit and share their machine learning models and solutions. Users can explore and learn from the models submitted by others, making it a valuable resource for both beginners and experienced practitioners.
To access Kaggle’s datasets and participate in competitions, users need to create an account, which is free. The platform also provides options for paid features and services, such as Kaggle Kernels, which allow users to run code and analyze datasets in the cloud.
Overall, Kaggle is an excellent platform for finding datasets and engaging in the data science community. Whether you are a beginner looking to explore machine learning or an experienced practitioner seeking interesting datasets and competitions, Kaggle offers a wealth of resources to fuel your machine learning journey.
UCI Machine Learning Repository
The UCI Machine Learning Repository is a well-established resource that provides a vast collection of datasets for educational and research purposes. It is a go-to platform for many data scientists and researchers looking for high-quality datasets to use in their machine learning projects.
The repository hosts a diverse range of datasets covering various domains, including finance, healthcare, social sciences, and more. These datasets have been carefully curated and are accompanied by detailed descriptions, making it easier for users to understand their content and relevance.
One of the notable features of the UCI Machine Learning Repository is the extensive documentation provided for each dataset. Documentation includes attribute descriptions, data source information, and citation guidelines. This level of detail allows users to fully understand the dataset’s structure and make informed decisions when selecting it for their machine learning tasks.
The repository offers datasets in different formats, including CSV, ARFF (Attribute-Relation File Format), and others, allowing users to choose the file format that suits their preferences and requirements. The variety of data types and formats ensures that users can find datasets suitable for their specific machine learning algorithms and applications.
Furthermore, the UCI Machine Learning Repository encourages users to contribute their own datasets, thereby expanding the collection of available datasets. Community contributions add to the diversity and richness of the repository, making it a collaborative platform where users can both access and contribute to the collective knowledge of the machine learning community.
The UCI Machine Learning Repository’s website provides a user-friendly interface for browsing and searching datasets. Users can filter datasets based on various criteria, such as the number of instances, number of attributes, and data type. This filtering functionality helps users narrow down their search and find the most relevant datasets for their projects.
Whether you are a student, a researcher, or a data scientist, the UCI Machine Learning Repository serves as a valuable resource for finding datasets that span different domains and cater to various machine learning tasks. Its commitment to providing detailed documentation and encouraging community contributions makes it a trusted platform in the machine learning community.
Google Dataset Search
Google Dataset Search is a specialized search engine designed to help users discover publicly available datasets. It indexes millions of datasets from various sources, making it easier to find relevant data for machine learning projects.
The search results on Google Dataset Search provide detailed information about each dataset, including its description, size, format, and licensing. This information helps users quickly assess the suitability of the dataset for their specific needs. Additionally, users can access the dataset directly from the search results or visit the hosting repository website.
One of the strengths of Google Dataset Search is its integration with popular data repositories and platforms, such as Kaggle, UCI Machine Learning Repository, and many others. This integration allows users to discover datasets from a wide range of sources, all in one convenient place.
The search functionality of Google Dataset Search is intuitive and user-friendly. Users can enter specific keywords related to their desired dataset or filter results based on various criteria, such as data type, location, or category. This filtering capability helps users narrow down their search and find the most relevant datasets for their machine learning projects.
Google Dataset Search also supports advanced search features, including the ability to search by schema.org properties. This allows users to specify search criteria based on key attributes of the dataset, such as the number of instances or the date of update. These advanced search options provide more targeted and refined results.
Furthermore, Google Dataset Search encourages dataset owners and providers to mark up their datasets using schema.org’s Dataset markup. By doing so, dataset creators help ensure that their datasets are discoverable through the search engine and that the relevant information is properly structured and indexed.
As a machine learning professional or researcher, Google Dataset Search can save you time and effort by providing a centralized platform to search for publicly available datasets. Its wide coverage, detailed metadata, and advanced search features make it a valuable tool for finding the right datasets to fuel your machine learning projects.
Note that while Google Dataset Search is a powerful resource, it is important to carefully evaluate the datasets you find to ensure they meet your specific requirements in terms of quality, relevance, and licensing.
AWS Open Data Registry
The AWS Open Data Registry is a curated collection of publicly available datasets hosted on the Amazon Web Services (AWS) platform. It serves as a valuable resource for data scientists, researchers, and developers looking for diverse datasets to fuel their machine learning projects.
The AWS Open Data Registry offers a wide range of datasets covering various domains, including genomics, satellite imagery, geospatial data, social media data, and more. These datasets are contributed by both public and private organizations, and they are made available to the public for free or at a minimal cost.
One of the advantages of using the AWS Open Data Registry is the seamless integration with AWS services and tools. Users can easily access and analyze the datasets using AWS services such as Amazon S3 for storage, Amazon Athena for querying, and Amazon EMR for big data processing. This integration simplifies the process of working with large-scale datasets and enables users to leverage the power of the AWS cloud infrastructure.
The AWS Open Data Registry also provides detailed documentation for each dataset, including information about its source, structure, and potential use cases. This documentation helps users understand the content and format of the dataset and facilitates its integration into their machine learning workflows.
Furthermore, the AWS Open Data Registry offers a data lake architecture, which allows users to combine multiple datasets and perform complex analyses. By leveraging the data lake architecture, users can gain deeper insights and unlock the full potential of the datasets they are working with.
One notable aspect of the AWS Open Data Registry is its commitment to data quality. The platform ensures that the datasets listed in the registry meet certain standards in terms of accuracy, completeness, and relevance. This quality assurance process gives users confidence in the datasets they use for their machine learning projects.
As the AWS Open Data Registry continues to grow and evolve, it represents a valuable resource for machine learning practitioners who are looking for high-quality datasets. The platform’s integration with AWS services, extensive documentation, and focus on data quality make it a trusted and reliable source for finding and working with diverse datasets.
It is worth mentioning that while many datasets hosted on the AWS Open Data Registry are available for free, there may be some datasets that require payment or have specific usage restrictions. Users should carefully review the terms and conditions of each dataset before utilizing it in their projects.
Data.gov
Data.gov is an initiative by the U.S. government to promote transparency and open data. It serves as a comprehensive platform that provides access to a vast collection of datasets from federal agencies, making it a valuable resource for researchers, policymakers, and data scientists.
Data.gov offers datasets covering a wide range of domains, including agriculture, climate, education, finance, health, transportation, and more. These datasets are contributed by various government agencies, providing a rich and diverse collection of data for different purposes.
One of the advantages of using Data.gov is the high quality and reliability of the datasets. The U.S. government ensures that the datasets made available through Data.gov meet certain standards in terms of accuracy, completeness, and timeliness. This reliability is crucial for machine learning projects that require trustworthy and up-to-date data.
The platform provides a user-friendly interface for searching and exploring datasets. Users can browse datasets by topic, agency, or data format, making it easier to find relevant data for their specific needs. Each dataset comes with a detailed description, metadata, and information on how to access and utilize the data effectively.
Data.gov also encourages data collaboration and engagement with the community. Users can provide feedback on datasets, suggest improvements, and even contribute their own data to the platform. This collaborative approach fosters knowledge exchange and enhances the quality and diversity of the available datasets.
In addition to the datasets, Data.gov offers tools and resources to facilitate data exploration and analysis. These resources include data visualization tools, APIs for programmatic access to data, and tutorials on how to work with the datasets effectively. These resources further empower users to extract meaningful insights from the data and drive impactful decisions.
Furthermore, Data.gov supports the use of open data standards such as schema.org and the Data Catalog Vocabulary (DCAT). This ensures that the datasets are properly documented, structured, and interoperable, making it easier for users to integrate the data into their machine learning workflows.
Whether you are an academic researcher, a policymaker, or a data scientist, Data.gov offers a wealth of high-quality and diverse datasets that can fuel your machine learning projects. The platform’s commitment to transparency, collaboration, and open data principles makes it a trusted source for accessing and analyzing government data.
It is important to note that while Data.gov primarily focuses on U.S. government datasets, it also includes international and state-level datasets. Users should carefully review the licensing and usage restrictions of each dataset to ensure compliance with the respective data providers’ terms and conditions.
Data.world
Data.world is a collaborative platform that offers a vast collection of datasets from a wide range of domains. It serves as a hub for data enthusiasts, researchers, and organizations to discover, collaborate, and analyze data for various purposes, including machine learning projects.
One of the key features of Data.world is its emphasis on community-driven collaboration. The platform encourages users to share and contribute datasets, fostering a collaborative environment where data scientists can learn from each other and work together on solving complex problems.
Data.world hosts a diverse collection of datasets, covering topics such as social sciences, finance, health, government, and more. Users can search for datasets based on keywords, tags, and categories, making it easy to find relevant data for their specific projects.
Each dataset on Data.world comes with detailed documentation and metadata, including information about the data source, licensing, and data quality. This comprehensive information helps users understand the characteristics and limitations of the dataset, enabling them to make informed decisions when incorporating the data into their machine learning workflows.
The platform offers a user-friendly interface that allows users to explore and analyze datasets within a web-based environment. It provides built-in tools for data visualization, querying, and collaboration, enabling users to gain insights, run analyses, and share their findings with others.
Data.world also supports integration with popular data analysis tools, such as R, Python, and Jupyter notebooks. This integration allows users to seamlessly import datasets into their preferred analysis environment and leverage the rich ecosystem of machine learning libraries and frameworks to build models and derive insights.
Furthermore, Data.world promotes open data standards and interoperability. The platform supports the use of common data formats like CSV and JSON, making it easy to work with the data in any programming language or analytical tool. Additionally, Data.world follows Linked Data principles, allowing for seamless integration and linking of datasets across domains.
The collaborative nature of Data.world sets it apart, as it provides a platform for users to engage in discussions, share insights, and seek help from the community. Users can ask questions, post comments, and collaborate on projects, fostering a sense of shared learning and knowledge exchange.
Whether you are a novice data enthusiast or an experienced machine learning practitioner, Data.world offers a wealth of datasets and a supportive community to help you in your data-driven endeavors. Its collaborative features, diverse collection of datasets, and commitment to open data principles make it an invaluable resource for exploring and analyzing data for machine learning projects.
OpenML
OpenML is an open-source platform that provides a comprehensive collection of datasets and machine learning experiments. It enables data scientists, researchers, and enthusiasts to discover, share, and collaborate on machine learning projects.
One of the main features of OpenML is its extensive library of datasets. It hosts a wide range of datasets across various domains, including image classification, text analysis, and time series forecasting. These datasets are contributed by researchers and organizations and are accompanied by detailed metadata and descriptions.
OpenML is designed to promote reproducibility in machine learning research. Along with the datasets, it also hosts machine learning experiments that showcase the application of algorithms on the datasets. This allows users to not only access the datasets but also explore the models and methods applied by others in a transparent and reproducible manner.
The platform encourages users to contribute their own datasets and experiments, fostering a collaborative and sharing environment. By contributing to OpenML, users can make their work accessible to the community, allowing others to build upon their research and replicate their results.
OpenML provides a range of tools for working with datasets and experiments. Users can explore and search for datasets based on various criteria, such as domain, task type, and dataset size. They can also access APIs and libraries to integrate OpenML with their machine learning workflows, making it easier to download and analyze datasets programmatically.
In addition to datasets and experiments, OpenML offers features for benchmarking machine learning algorithms. Users can compare the performance of different algorithms on specific datasets, facilitating the evaluation and selection of models for specific tasks. This benchmarking functionality provides valuable insights for researchers and practitioners in the machine learning community.
OpenML supports interoperability with other machine learning platforms and frameworks. It integrates with popular machine learning tools such as Weka, scikit-learn, and R, allowing users to seamlessly import datasets and experiments into their preferred environments for analysis and model development.
By providing access to diverse datasets, experiments, and benchmarking capabilities, OpenML serves as a valuable resource for machine learning research and development. Its focus on reproducibility and collaboration strengthens the transparency and reliability of machine learning workflows and fosters continuous learning and improvement in the field.
Whether you are a researcher, a data scientist, or a machine learning enthusiast, OpenML offers a platform to explore, contribute to, and benefit from a vast array of datasets and experiments. Its collaborative nature, rich functionality, and commitment to openness make it an invaluable asset for the machine learning community.
Google Cloud Public Datasets
Google Cloud Public Datasets is a platform that offers a wide range of high-quality datasets hosted on the Google Cloud Platform. With a focus on openness and accessibility, this collection of datasets provides machine learning practitioners, researchers, and developers with valuable and diverse data to power their projects.
Google Cloud Public Datasets encompasses a variety of domains, including genomics, climate, finance, geospatial data, and more. These datasets are contributed by both Google and other organizations, ensuring a rich collection of data for various machine learning applications.
One of the notable advantages of Google Cloud Public Datasets is the seamless integration with Google Cloud Platform services. Users can easily access and analyze the datasets using services like BigQuery for querying large datasets, Google Cloud Storage for data storage, and Google Data Studio for data visualization. This integration simplifies the process of processing, analyzing, and deriving insights from the datasets.
Regarding data quality, Google Cloud Public Datasets ensures that the hosted datasets are of high quality and well-documented. The datasets undergo rigorous approval processes to ensure accuracy, completeness, and reliability, which is crucial for machine learning applications that heavily rely on trustworthy and reliable data.
Furthermore, Google Cloud Public Datasets provides detailed documentation for each dataset, including information such as data source, description, schema, and usage recommendations. This documentation helps users understand the structure of the dataset and its potential applications, facilitating the exploration and utilization of the data effectively.
Google Cloud Public Datasets also supports collaboration and community engagement. Users can provide feedback, report issues, and suggest improvements for the datasets, fostering a collaborative environment where users can contribute to enhancing the quality and usability of the hosted datasets.
Another advantage of Google Cloud Public Datasets is the scalability and performance offered by the Google Cloud Platform. Users can leverage the platform’s vast computing resources, distributed computing capabilities, and advanced analytics tools to efficiently process and analyze large-scale datasets, accelerating the development and deployment of machine learning models.
Whether you are a data scientist, a researcher, or a developer, Google Cloud Public Datasets offers a wide variety of high-quality datasets and the infrastructure needed to power your machine learning projects. Its integration with the Google Cloud Platform, stringent data quality standards, and commitment to documentation and community engagement make it an excellent resource for accessing and utilizing diverse datasets.
Microsoft Research Open Data
Microsoft Research Open Data is a platform established by Microsoft that provides access to a diverse range of datasets contributed by the research community. It serves as a valuable resource for data scientists, researchers, and machine learning practitioners who are looking for high-quality datasets to support their projects.
Microsoft Research Open Data hosts datasets from various domains, including computer vision, natural language processing, healthcare, social sciences, and more. These datasets are contributed by researchers and organizations and have been carefully curated to ensure their quality and usefulness.
One of the strengths of Microsoft Research Open Data is its focus on supporting reproducible research. The platform not only provides access to datasets but also encourages the sharing of code and methodologies used in research projects. This commitment to reproducibility enables users to understand and replicate the experiments and models developed by researchers, promoting transparency and collaboration in the scientific community.
The platform offers a user-friendly interface for searching and exploring datasets. Users can filter datasets based on various criteria, such as domain, publication date, and licensing. Each dataset is accompanied by detailed documentation, including information about the data source, data format, and any preprocessing that has been performed. This documentation helps users understand the data and evaluate its suitability for their specific research needs.
Microsoft Research Open Data also supports interoperability by providing datasets in common formats, such as CSV, JSON, and SQLite. This compatibility enables users to easily integrate the datasets into their preferred machine learning frameworks and tools, facilitating seamless data analysis and model development.
Additionally, Microsoft Research Open Data encourages collaboration and knowledge sharing by providing a platform for researchers to publish their findings and insights. Users can explore published papers, datasets, and associated code to gain a deeper understanding of the research conducted within the community. This collaborative environment fosters innovation and allows researchers to build upon each other’s work.
The platform further supports the machine learning community through its partnership with other organizations and initiatives. Microsoft Research Open Data collaborates with academic institutions, government agencies, and industry partners to expand the dataset collection and promote interdisciplinary research collaboration.
Whether you are a researcher, a data scientist, or a machine learning practitioner, Microsoft Research Open Data offers a valuable resource for discovering and accessing high-quality datasets. Its commitment to reproducibility, interoperability, and collaboration makes it an excellent platform for advancing research and fostering knowledge exchange in the machine learning community.
AI2 Datasets
AI2 Datasets is a collection of datasets created and maintained by the Allen Institute for Artificial Intelligence (AI2). It serves as a valuable resource for researchers, data scientists, and machine learning practitioners looking for high-quality datasets to drive advancements in AI and machine learning.
The AI2 Datasets cover a wide range of domains and tasks, including natural language processing, computer vision, and more. These datasets have been carefully curated and annotated to ensure their quality and relevance for machine learning applications.
One of the notable features of AI2 Datasets is the emphasis on large-scale, comprehensive datasets. The institute focuses on creating datasets that capture the complexity and diversity of real-world scenarios, enabling researchers to develop robust and high-performing machine learning models.
The AI2 Datasets provide detailed documentation and guidelines for each dataset, including information about the data collection process, annotation procedures, and task-specific instructions. This documentation helps users understand the dataset’s structure, nuances, and limitations, facilitating its proper utilization in their machine learning workflows.
In addition to the datasets, AI2 offers benchmarking tasks and challenges that allow users to evaluate and compare their machine learning models against state-of-the-art approaches. These benchmarking initiatives provide a standard evaluation framework and encourage healthy competition in the research community, driving advancements in AI and machine learning.
AI2 also promotes transparency and reproducibility by making code and associated resources available for many of its datasets. This enables researchers to study and replicate the results, fostering collaboration and facilitating the sharing of methodologies and insights.
Furthermore, AI2 actively encourages community contributions to the datasets. The institute provides mechanisms for researchers to contribute annotations, additional data samples, and improvements to existing datasets. This collaborative approach enriches the datasets and promotes knowledge sharing within the AI community.
AI2 Datasets are made available for free to the research community, promoting open and accessible resources for advancing AI and machine learning. The datasets can be accessed through the AI2 website or through direct downloads from AI2’s GitHub repository.
Whether you are a researcher, a data scientist, or a machine learning practitioner, AI2 Datasets offer a valuable collection of high-quality and comprehensive datasets for driving advancements in AI and machine learning. By leveraging these datasets, researchers can develop and evaluate state-of-the-art machine learning models, furthering our understanding and capabilities in AI-driven technologies.
Internet Archive
The Internet Archive is a non-profit organization dedicated to preserving and providing access to a vast collection of digital content, including text, images, audio, video, and datasets. It serves as a valuable resource for researchers, historians, and data scientists who are looking for diverse and historical datasets to support their projects.
The Internet Archive’s dataset collection spans a wide range of domains and topics. It encompasses historical web pages, books, academic papers, government documents, music, movies, and much more. These datasets offer a wealth of information that can be utilized for research, analysis, and innovation.
One of the strengths of the Internet Archive is its massive digital library, containing petabytes of data. The organization continuously captures and archives snapshots of web pages, allowing researchers to examine the evolution of online content over time. This longitudinal perspective provides valuable insights into the ever-changing digital landscape.
In addition to web archives, the Internet Archive hosts a wide variety of other datasets. These include digitized books, recorded audio performances, curated collections of images, and extensive collections of public domain movies. Researchers can explore and analyze these datasets to uncover patterns, explore cultural trends, and gain a deeper understanding of various subjects.
The Internet Archive offers various tools and APIs for accessing, searching, and utilizing the datasets. Researchers can access the Wayback Machine to browse archived web pages, use the Open Library API to retrieve information about books, or explore the Audio Collections API to access historical audio recordings. These tools and APIs facilitate the integration of the datasets into research and analysis workflows.
Another unique aspect of the Internet Archive is its commitment to open access and open data. The organization believes in providing free and open access to its collections, enabling individuals and organizations worldwide to benefit from the wealth of information available. This commitment to openness fosters collaboration, innovation, and the dissemination of knowledge.
Researchers can access the datasets hosted by the Internet Archive directly from its website or download them for offline use. It is crucial to note that the size and format of the datasets may vary, and some datasets may require specialized tools or knowledge for handling and analysis.
Whether you are a historian, a researcher, or a data scientist, the Internet Archive offers a treasure trove of historical and diverse datasets. By leveraging these datasets, researchers can delve into the past, explore cultural milestones, and uncover insights that contribute to our collective knowledge and understanding.
Data.gov.uk
Data.gov.uk is the UK government’s official platform for publishing and sharing open data. It serves as a comprehensive resource for accessing a wide range of datasets related to various aspects of UK governance, society, and the economy. Researchers, policymakers, and data scientists can utilize these datasets to gain valuable insights, drive innovation, and inform evidence-based decision-making.
Data.gov.uk hosts datasets from different government departments, agencies, and public organizations. These datasets cover diverse domains, including health, education, environment, transportation, finance, and more. The platform strives to provide a broad representation of data to cater to various research and analysis needs.
One of the key strengths of Data.gov.uk is its commitment to transparency and accessibility. The platform promotes open data principles and encourages government organizations to release data in a machine-readable format, making it easier for users to access, download, and analyze the datasets. This commitment fosters accountability and empowers users to scrutinize and analyze government information.
The datasets hosted on Data.gov.uk provide valuable information about the UK’s demographics, population trends, public services, infrastructure, and more. Users can access datasets such as demographic statistics, crime rates, educational outcomes, transportation data, and environmental indicators. These datasets enable researchers to gain insights into societal trends, support policy development, and contribute to evidence-based decision-making.
Data.gov.uk provides a user-friendly interface for searching, browsing, and accessing datasets. Users can explore datasets based on various criteria, such as topic, organization, or data format. Each dataset is accompanied by detailed metadata, including descriptions, data sources, and relevant documentation. This information helps users assess the datasets’ suitability for their research needs and understand their structure and context.
The platform encourages collaboration and community engagement through its features for user feedback and data improvement. Users can provide feedback on datasets, offer suggestions for enhancements, or even contribute their own datasets to enhance the capabilities and richness of the platform. This collaborative approach fosters a sense of community and encourages knowledge sharing.
Data.gov.uk also promotes the use of open standards and APIs, facilitating data integration and interoperability. Users can find information about data APIs and access points, enabling them to programmatically access and use the datasets in their applications, research projects, or data analyses.
Whether you are a researcher, policymaker, or a data enthusiast, Data.gov.uk offers a wealth of open data resources that facilitate evidence-based decision-making, research, and innovation. Its commitment to transparency, accessibility, and collaboration makes it a valuable platform for accessing and utilizing a wide variety of datasets related to the UK.
Quandl
Quandl is a platform that provides access to a vast collection of financial, economic, and alternative datasets. It serves as a valuable resource for investors, researchers, and data scientists looking to gather insights and analyze various financial markets and economic indicators.
Quandl offers a wide range of datasets from different sources, including stock prices, economic indicators, commodities, demographics, and more. These datasets are sourced from reputable providers, ensuring high-quality and reliable data for analysis.
One of the strengths of Quandl is its focus on financial and economic data. Users can access historical and real-time market data, allowing them to monitor and analyze trends in the stock market, currency exchange rates, interest rates, and more. This data can be invaluable for investment research, risk analysis, and developing trading strategies.
Quandl provides comprehensive documentation and metadata for each dataset, including details about the data source, methodology, and frequency of updates. This information helps users understand the characteristics and limitations of the data, facilitating its proper utilization in their financial analysis and modeling.
The platform offers a user-friendly interface and powerful search functionality, allowing users to quickly find and access the datasets they need. Users can apply filters based on various criteria, such as asset class, geography, and data type, to narrow down their search and discover the most relevant data for their specific needs.
In addition to accessing individual datasets, Quandl also offers data bundles and premium subscription services. These services provide users with curated collections of datasets tailored to specific industries, asset classes, or investment strategies. Premium subscribers can also access additional features, such as advanced analytics tools and personalized support.
Quandl supports data integration into various analysis platforms and programming languages, making it easy for users to incorporate the data into their existing workflows. The platform provides APIs and libraries for popular programming languages like Python and R, allowing users to access and analyze the datasets programmatically.
Furthermore, Quandl encourages the sharing and collaboration of data-driven insights through its community platform. Users can create and share their own datasets, analytics, and research findings, fostering a collaborative environment for knowledge exchange and innovation.
Whether you are a financial analyst, researcher, or a data scientist, Quandl offers a wide range of comprehensive and reliable financial and economic datasets. Its user-friendly interface, powerful search functionality, and commitment to data quality and documentation make it an essential platform for accessing and analyzing data for financial analysis and research.
Yelp Dataset
The Yelp Dataset is a popular resource for researchers, data scientists, and developers interested in analyzing and understanding customer reviews, ratings, and other data related to businesses on the Yelp platform. It provides a wealth of information about various businesses, allowing for insights into consumer preferences, sentiment analysis, and more.
The Yelp Dataset captures a wide range of data attributes, including user reviews, ratings, business attributes, geolocation data, and more. It encompasses data from businesses across different industries and geographical locations, making it a comprehensive resource for studying consumer behavior and business trends.
One of the strengths of the Yelp Dataset is its size and diversity. It includes millions of reviews and ratings, covering thousands of businesses. This large-scale dataset provides researchers with a substantial volume of data for analysis, allowing for robust statistical analysis and machine learning applications.
Researchers and data scientists can leverage the Yelp Dataset to study various aspects of consumer behavior. They can analyze customer sentiment, identify popular business categories, extract insights on customer preferences, or explore patterns in business performance across different regions.
The Yelp Dataset is well-documented, providing detailed information about the dataset structure, data types, and available attributes. Users can access the dataset’s documentation to gain a comprehensive understanding of the available data, ensuring proper utilization of the dataset for their research or analysis.
Yelp provides the dataset for research and non-commercial use through their academic dataset program. However, it is important to note that the dataset does not include full business and review text due to privacy and legal considerations.
Accessing and working with the Yelp Dataset typically requires some level of data processing and cleaning due to its size and complexity. Nevertheless, many resources and code examples are available from the research community, making it easier for researchers and data scientists to analyze and extract insights from the Yelp Dataset.
By leveraging the Yelp Dataset, researchers and data scientists can gain valuable insights into consumer behavior, industry trends, and sentiment analysis. The dataset’s size, diversity, and documentation make it a valuable resource for a wide range of research and analysis in areas related to customer satisfaction, business performance, and recommendation systems.
ImageNet
ImageNet is a widely-used and influential dataset in the field of computer vision. It offers a large collection of labeled images covering thousands of object categories, making it a valuable resource for researchers, data scientists, and developers working on image recognition and classification tasks.
The ImageNet dataset includes millions of images, each annotated with multiple object categories. The dataset covers a broad range of objects, from animals and everyday objects to complex scenes and abstract concepts. This diversity makes ImageNet a powerful tool for training and evaluating computer vision models.
One of the key strengths of ImageNet is its hierarchical labeling system. Each image is associated with a WordNet hierarchy, allowing for the exploration of relationships and similarities across different object categories. This hierarchical structure facilitates more nuanced analysis and exploration of object semantics.
ImageNet has played a pivotal role in advancing the field of deep learning, particularly with the development of deep convolutional neural networks (CNNs). The dataset has been used extensively for training and benchmarking state-of-the-art image classification models. The availability of ImageNet has fostered large-scale experiments and facilitated the development of more accurate and robust computer vision algorithms.
ImageNet also hosts the ImageNet Challenge, an annual competition that attracts researchers and practitioners from around the world. The challenge tasks participants with developing models to classify objects within the dataset. The ImageNet Challenge has become a benchmark for evaluating and comparing the performance of computer vision algorithms.
Accessing the ImageNet dataset may require registration and adherence to licensing terms. However, subsets and smaller versions of the dataset are often available, making it more accessible for research and experimentation purposes.
Researchers and data scientists leverage ImageNet for various applications, including object recognition, image segmentation, visual question answering, and image generation. The dataset provides an extensive collection of labeled images that can be utilized to develop and evaluate computer vision algorithms across a wide range of tasks.
While ImageNet has been instrumental in advancing computer vision, it also faces challenges in terms of bias, representation, and scalability. Efforts are being made to address these issues and expand the diversity and inclusivity of the dataset to better represent a wide range of objects, cultures, and contexts.
Overall, ImageNet has had a significant impact on the field of computer vision and has become a foundational resource for training and evaluating image recognition models. Its scale, diversity, and hierarchical structure make it invaluable for advancing the state of the art in computer vision research and development.
CIFAR-10 and CIFAR-100
CIFAR-10 and CIFAR-100 are widely-used benchmark datasets in the field of computer vision and machine learning. They are structured collections of labeled images designed to facilitate the development and evaluation of image classification models.
CIFAR-10 consists of 60,000 images divided into 10 classes, with each image being a low-resolution (32×32 pixels) representation of an object. The dataset covers common objects such as airplanes, cars, birds, cats, and more. CIFAR-100, on the other hand, consists of 100 classes with 600 images each, offering a more fine-grained classification challenge.
These datasets are commonly used for training and benchmarking machine learning models, especially in the field of deep learning. The small image size and diverse object categories present unique challenges compared to larger and more high-resolution datasets, making CIFAR-10 and CIFAR-100 popular choices for developing efficient and accurate image classification algorithms.
CIFAR-10 and CIFAR-100 are useful for researchers, data scientists, and developers who want to experiment with image classification techniques. The datasets provide a standardized basis for comparing different approaches and algorithms, enabling fair and meaningful comparisons.
Due to their popularity, CIFAR-10 and CIFAR-100 have become a common starting point for many researchers and students working on image classification tasks. These datasets offer a relatively low barrier to entry, making it easier for newcomers to explore and experiment with machine learning algorithms.
Accessing CIFAR-10 and CIFAR-100 datasets is straightforward, as they are readily available for download from various sources, including the official CIFAR website and online machine learning repositories. This accessibility enables researchers and practitioners to easily incorporate these datasets into their experiments and projects.
CIFAR-10 and CIFAR-100 have become common benchmarks for evaluating and comparing machine learning models. Researchers often report their results using these datasets, allowing for a direct comparison of model performance across different studies. This standardized evaluation process helps drive progress and advancement in the field of image classification.
While CIFAR-10 and CIFAR-100 have been instrumental in pushing the boundaries of image classification, it is important to note that they have some limitations. The small image size and simplified representations may not fully reflect real-world scenarios or the complexity of visual recognition tasks. Additionally, CIFAR datasets may not be ideal for tasks that require high-resolution or fine-grained object classification.
Nevertheless, CIFAR-10 and CIFAR-100 have proven to be invaluable resources for benchmarking and developing image classification algorithms. They continue to contribute to the advancement of computer vision research and provide a standardized framework for evaluating the performance of machine learning models in image classification tasks.
Reddit Dataset
The Reddit Dataset is a comprehensive collection of data from the popular online community and social media platform, Reddit. It offers a wealth of textual content, discussions, and user interactions, making it a valuable resource for researchers, data scientists, and developers interested in studying online communities, natural language processing, and social media analytics.
The Reddit Dataset consists of posts, comments, user profiles, voting patterns, and other metadata collected from different subreddits. Subreddits are individual communities within the Reddit platform that focus on specific topics, enabling researchers to explore and analyze discussions related to a diverse range of interests, hobbies, and domains.
With millions of posts and comments from Reddit users worldwide, the dataset provides insights into user behavior, sentiment, trends, and community dynamics. It serves as a rich and extensive corpus for studying online conversations, conducting sentiment analysis, predicting user behavior, and exploring linguistic patterns.
Researchers can utilize the Reddit Dataset to analyze user interactions, identify influential users, examine topic trends over time, and investigate the spread of information and misinformation within online communities. The dataset’s size and variety enable large-scale studies and can lead to valuable insights into how people communicate and engage with each other in virtual communities.
Accessing the Reddit Dataset typically involves obtaining the data through web scraping techniques or using publicly available data dumps provided by Reddit or third-party repositories. It is important to adhere to Reddit’s terms of service and respect user privacy and anonymity when working with the dataset.
Given the vastness and complexity of the dataset, preprocessing and cleaning steps are often necessary to handle the unstructured nature of the textual data. Techniques such as text cleaning, tokenization, and sentiment analysis may be applied to make the data suitable for specific research questions or machine learning tasks.
Researchers and data scientists often leverage the Reddit Dataset for a wide range of applications, including social network analysis, natural language processing, text classification, recommender systems, and sentiment analysis. The dataset allows for exploration and experimentation with various algorithms and approaches to gain insights and develop models that can enhance our understanding of online communities.
While the Reddit Dataset provides valuable information for research and analysis, it is important to address the ethical considerations associated with working with user-generated content. Researchers should consider privacy, consent, and guidelines for responsible data usage when handling and analyzing Reddit data.
Overall, the Reddit Dataset offers a valuable resource for studying online communities, analyzing user behavior, and exploring natural language processing techniques. Its vast volume of textual data and diverse community interactions make it an essential asset for understanding the dynamics and patterns of online social platforms.
Conclusion
In conclusion, the availability of public datasets plays a crucial role in advancing machine learning research, enabling data scientists, researchers, and developers to access diverse and high-quality data for training, testing, and evaluating their models. The platforms and repositories discussed in this article offer a wide range of datasets that cater to different domains and objectives.
From platforms like Kaggle and Data.world, which provide access to a vast collection of datasets, to specialized repositories like UCI Machine Learning Repository and ImageNet, researchers have a plethora of options to choose from when searching for datasets. These resources not only save time and effort on data collection but also foster collaboration and knowledge sharing within the machine learning community.
Additionally, platforms like Google Dataset Search, AWS Open Data Registry, and Microsoft Research Open Data provide curated datasets with detailed documentation and support for data integration, making it easier for researchers to find and utilize relevant data in their projects.
The importance of smaller but specialized datasets like CIFAR-10 and CIFAR-100 should not be overlooked, as they serve as valuable benchmarks for image classification tasks and enable researchers to develop efficient and accurate models. Meanwhile, datasets from Yelp, Reddit, and the Internet Archive allow researchers to gain insights into consumer behavior, sentiment analysis, and the dynamics of online communities.
While these datasets offer valuable resources, it is essential to exercise caution in their usage. Researchers should consider ethical considerations, abide by licensing terms, and respect user privacy and consent when collecting, analyzing, and sharing the data.
Overall, the availability of public datasets empowers data scientists and researchers to push the boundaries of machine learning and develop innovative solutions. By leveraging these datasets, we can gain deeper insights, validate algorithms, and contribute to advancements in various domains of machine learning and AI.