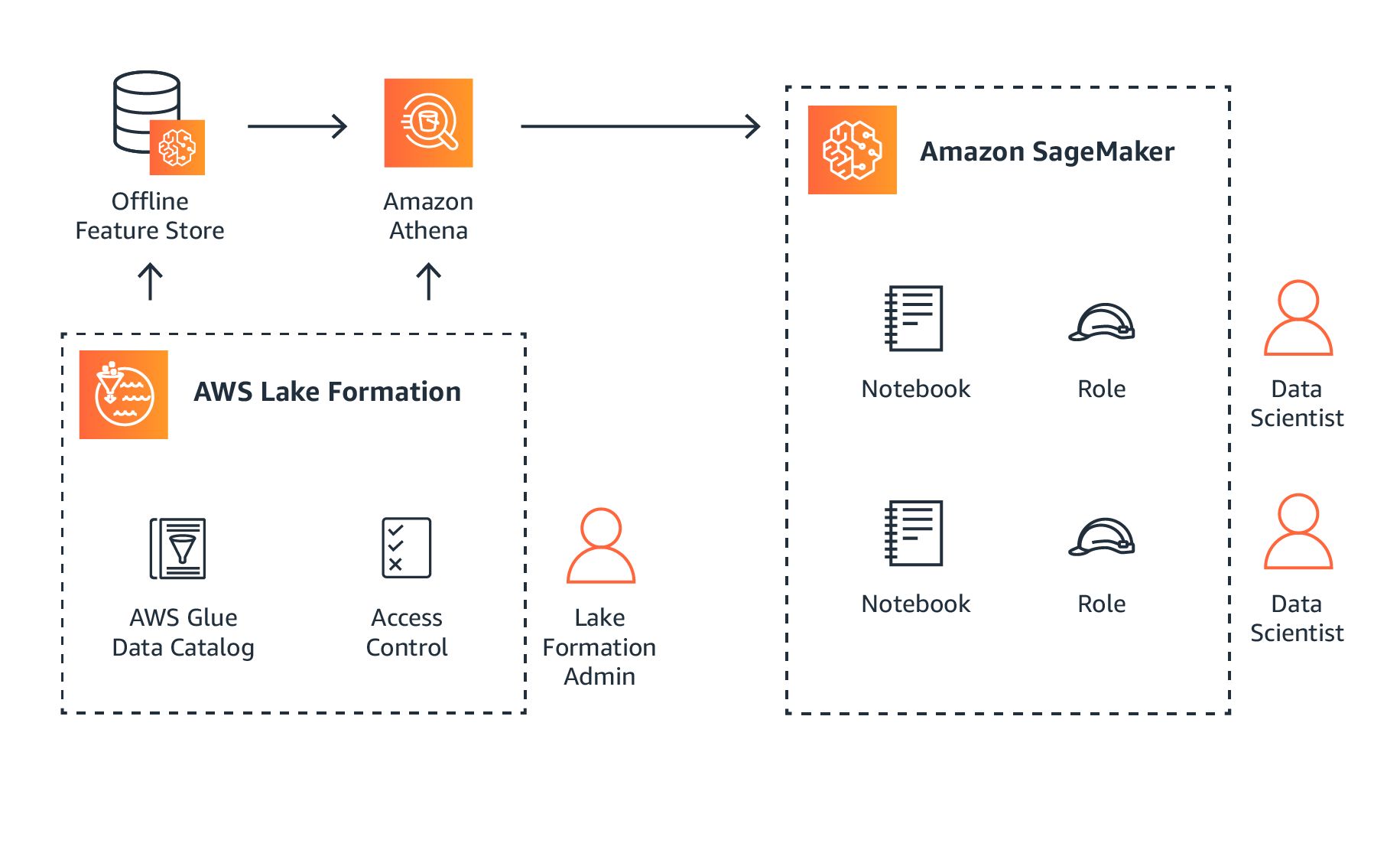
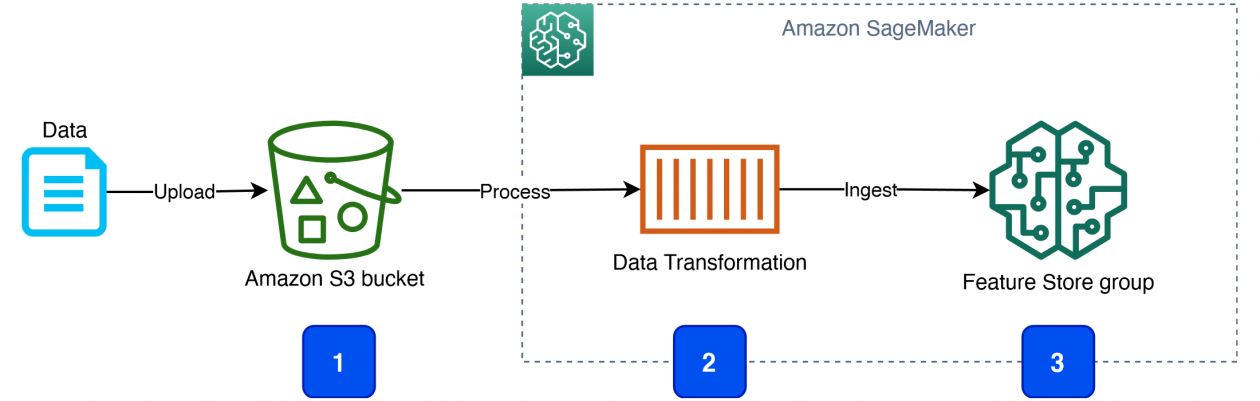
Introduction
Amazon Machine Learning (Amazon ML) is a powerful tool that allows you to build and deploy machine learning models without the need for extensive knowledge in data science or programming. With Amazon ML, you can leverage the vast amounts of data available on Amazon Web Services (AWS) to make accurate predictions and improve decision-making processes.
Machine learning has emerged as a crucial component of various industries, from e-commerce and finance to healthcare and marketing. By utilizing algorithms and statistical models, machine learning enables systems to learn from data, identify patterns, and make predictions or take actions based on that learning. Amazon ML simplifies this process by providing a user-friendly interface and automated features, making it accessible to users of all backgrounds and skill levels.
Getting started with Amazon ML is easy. You only need to have an AWS account and a dataset that contains the historical data on which you want to train your model. Whether it’s customer behavior data, product information, or sales data, you can use this data to extract meaningful insights and improve your business strategies.
In this guide, we will walk you through the process of using Amazon ML. We will cover everything from creating a machine learning model to training it, evaluating its performance, and making predictions. Additionally, we will explore the different ways you can use Amazon ML, such as batch prediction and real-time prediction. By the end of this guide, you will have a solid foundation to leverage the power of Amazon ML for your business needs.
Please note that while Amazon ML removes some of the complexities associated with machine learning, it is still important to have a basic understanding of the underlying concepts. Familiarizing yourself with key terms such as datasets, variables, and models will help you make the most of Amazon ML and achieve accurate predictions and valuable insights.
Getting Started
Before diving into the world of Amazon Machine Learning (Amazon ML), there are a few prerequisites you need to fulfill. Firstly, you will need an Amazon Web Services (AWS) account. If you don’t have one yet, you can easily create it on the AWS website.
Once you have your AWS account set up, you can navigate to the Amazon ML console. Here, you will be able to create and manage your machine learning models. The console provides a user-friendly interface that allows you to perform various tasks, such as importing datasets, training models, and making predictions.
To start using Amazon ML, you will need to have a dataset on which to train your machine learning model. This dataset should contain relevant historical data that captures the patterns and trends you want to analyze. For example, if you are building a model to predict customer churn, your dataset might include information such as customer demographics, purchase history, and customer satisfaction ratings.
Amazon ML accepts datasets in CSV (Comma Separated Values) format, which is a common file format for storing tabular data. If your data is stored in a different format, you can easily convert it to CSV before uploading it to Amazon ML. It’s important to ensure that your dataset is well-structured and contains all the necessary fields for training the model.
Once you have your dataset ready, you can import it into Amazon ML. The console provides a simple, step-by-step process to guide you through the data import process. You can either upload your dataset directly or provide an Amazon Simple Storage Service (S3) path where the dataset is located.
After importing your dataset, Amazon ML automatically performs some basic data analysis to identify the types of variables in the dataset. It detects numerical, categorical, and text variables, which helps in the subsequent steps of model creation and training. You can review and modify the variable types if necessary.
Now that you have your dataset imported and analyzed, you are ready to start building your machine learning model. In the next section, we will explore the process of creating a machine learning model using Amazon ML. By leveraging the power of machine learning algorithms and the extensive computing resources provided by AWS, you can unlock valuable insights from your data and make accurate predictions to drive business growth.
Creating a Machine Learning Model
Creating a machine learning model in Amazon Machine Learning (Amazon ML) is a straightforward process that involves defining the target variable, selecting an algorithm, and specifying the training and evaluation data. Let’s explore the steps involved in creating a machine learning model using Amazon ML:
1. Define the Target Variable:
The target variable is the variable you want to predict or make predictions about. It is also known as the dependent variable. For example, if you want to predict customer churn, the target variable would be whether a customer churned or not. In Amazon ML, you need to specify the target variable in your dataset.
2. Select an Algorithm:
Amazon ML provides three built-in algorithms for classification and regression tasks: binary logistic regression, multiclass logistic regression, and linear regression. These algorithms are optimized for accuracy and performance. You can select the appropriate algorithm based on the type of task and the nature of your data.
3. Specify the Training and Evaluation Data:
To train your machine learning model, you need to specify the training data, which includes a subset of your dataset. Amazon ML automatically splits your dataset into a training set and an evaluation set. The training set is used to train the model, while the evaluation set is used to assess the model’s performance.
4. Customize Model Settings:
Amazon ML provides default settings for training your model, but you can customize certain parameters to improve performance. For example, you can specify the regularization parameter to control the trade-off between model complexity and overfitting. You can also set the hyperparameters for the algorithms, such as the learning rate for logistic regression.
5. Create the Model:
Once you have defined the target variable, selected an algorithm, specified the training and evaluation data, and customized the model settings, you are ready to create the model. Amazon ML takes care of the heavy lifting, including feature engineering, model training, and parameter tuning. The model creation process may take some time, depending on the size of your dataset and the complexity of the task.
After creating the model, you can monitor its progress and evaluate its performance. Amazon ML provides metrics such as accuracy, precision, recall, and F1 score to assess the model’s performance. You can also visualize the performance metrics using the built-in charts and graphs.
In the next section, we will delve into the process of preparing data for training the model. This involves defining variables, specifying the data schema, and ensuring the quality and accuracy of the data. By following these steps, you can create an effective machine learning model in Amazon ML and harness the power of data-driven insights for your business.
Preparing Data for Training
Before you can start training your machine learning model in Amazon Machine Learning (Amazon ML), it is crucial to prepare your data. Properly preparing the data ensures that it is accurate, relevant, and in the format required for successful training and prediction. Let’s discuss the steps involved in preparing your data:
1. Define Variables:
Start by defining the variables (also known as attributes or features) present in your dataset. Variables can be categorical, numerical, or text-based. Categorical variables represent discrete categories, such as gender or product type. Numerical variables, like age or price, represent continuous values. Text-based variables include free-form text, such as customer reviews or product descriptions.
2. Specify the Data Schema:
To train your model effectively, it is important to define the data schema. The data schema provides a description of each variable, including its name, data type, and role (target, categorical, numerical, or text). By specifying the data schema, you allow Amazon ML to understand the structure and characteristics of the data.
3. Clean and Preprocess the Data:
Cleaning the data involves handling missing values, outliers, and other data inconsistencies. Amazon ML provides tools to clean and preprocess your data, such as filling missing values or removing outliers. By ensuring data cleanliness, you improve the accuracy and performance of your model.
4. Normalize Numerical Variables:
Normalization is the process of scaling numerical variables to a common range. This step ensures that variables with different scales do not disproportionately influence the model’s training process. Amazon ML provides automated normalization options, or you can apply custom scaling methods if necessary.
5. Encode Categorical Variables:
Categorical variables need to be encoded into numerical representations for effective training. Amazon ML supports automatic encoding of categorical variables, such as one-hot encoding or binary encoding. These encoding techniques represent each category as a separate feature, allowing the model to understand and learn from categorical information.
6. Split the Data Set:
To evaluate the performance of your machine learning model, it is essential to split your dataset into training and evaluation sets. The training set is used to train the model, while the evaluation set is used to assess its performance. Amazon ML provides built-in mechanisms to handle the data splitting process.
7. Ensure Data Quality:
Lastly, ensure that your dataset is of high quality and free from any biases or inconsistencies. Validate the data for completeness, accuracy, and relevance to the problem you are trying to solve. It is crucial to have a reliable and representative dataset to achieve reliable and accurate predictions.
By following these steps, you can prepare your data effectively for machine learning with Amazon ML. This ensures that your model is trained on clean, relevant, and accurate data, resulting in high-quality predictions. In the next section, we will explore the process of defining variables and the data schema in Amazon ML.
Defining Variables and Data Schema
Defining variables and data schema is a crucial step in utilizing Amazon Machine Learning (Amazon ML) effectively. By understanding and specifying the variables and their properties, you provide valuable information to the model for accurate training and prediction. Let’s explore the process of defining variables and data schema in Amazon ML:
1. Identify Variables:
Start by identifying the variables present in your dataset. These variables capture the information that is relevant to the problem you are trying to solve. Variables can be categorical, numerical, or text-based, depending on the nature of the data.
2. Define Variable Types:
Once you have identified the variables, categorize them according to their data types. Specify which variables are categorical, numerical, or text. Categorical variables have a finite number of categories, numerical variables represent numeric values, and text variables contain free-form text.
3. Assign Roles to Variables:
In addition to defining the variable types, assign roles to the variables to indicate their significance in the modeling process. The roles can be target, categorical, numerical, or text. The target variable is the variable you want to predict or make predictions about. Categorical, numerical, and text variables provide additional context for training and prediction.
4. Specify Data Schema:
The data schema provides a formal definition of the variables and their characteristics. In Amazon ML, you specify the data schema using the JSON (JavaScript Object Notation) format. The schema includes the variable name, data type, and role. For example, a data schema for a customer churn model might include variables like “age” (numerical), “gender” (categorical), and “review” (text).
5. Handle Missing Values:
Missing values can affect the performance of your machine learning model. You need to decide how to handle missing values in each variable. Amazon ML provides options for automatically handling missing values, such as replacing them with the mean or most frequent value, or you can apply custom techniques based on your domain knowledge.
6. Validate and Verify the Schema:
Before proceeding with training your model, ensure that the data schema accurately represents the variables in your dataset. Validate the schema to ensure that it is correct and complete. Verifying the schema helps to avoid errors and ensures that the model is trained on the right variables.
Defining variables and data schema is a crucial step in Amazon ML as it provides a clear understanding of the data structure and its relevant characteristics. By accurately defining the variables and data schema, you lay the foundation for successful model training and prediction.
In the next section, we will explore the process of splitting the dataset into training and evaluation sets. This step is crucial for assessing the performance of your machine learning model.
Splitting the Data Set
Splitting the dataset into training and evaluation sets is a critical step in the machine learning process. By dividing the data appropriately, you can ensure that your model is trained on a subset of the data and evaluated on a separate subset. This allows you to assess the performance and generalization ability of the model. In Amazon Machine Learning (Amazon ML), you can easily split your dataset using the provided functionalities. Let’s explore the process of splitting the dataset:
1. Training Set:
The training set is used to train the machine learning model. It comprises a subset of the dataset, typically the majority portion, on which the model learns patterns and relationships. The training set should be representative of the overall dataset and provide sufficient information to the model for accurate learning.
2. Evaluation Set:
The evaluation set is used to evaluate the performance of the trained model. It provides an unbiased assessment of the model’s ability to generalize to new, unseen data. The evaluation set is crucial for understanding how well the model performs on data it hasn’t seen during training. It helps in identifying any overfitting or underfitting issues.
3. Data Splitting Techniques:
Amazon ML provides different techniques for splitting the dataset. By default, Amazon ML randomly splits the dataset into training and evaluation sets. However, you can also specify a specific percentage of data to allocate for training and evaluation. It is recommended to allocate around 70-80% of the data for training and the remaining 20-30% for evaluation, but this can vary based on the size and nature of your dataset.
4. Handling Unbalanced Datasets:
In some cases, the dataset may be unbalanced, meaning there is a significant difference in the number of instances across different classes or categories. In such scenarios, it is important to ensure that both the training and evaluation sets contain a proportional representation of the different classes to avoid biased model performance.
5. Revisiting the Split:
As you iterate and make improvements to your model, it is essential to revisit the data split. Repeating the data splitting process, especially if you make significant changes to your model or dataset, ensures that your evaluation results are reliable and consistent. This helps in accurately assessing the impact of the changes on the model’s performance.
By splitting the dataset into training and evaluation sets, you can train your model on a representative subset and evaluate its performance on unseen data. This step is crucial for setting realistic expectations and effectively assessing the accuracy and robustness of your model. In the next section, we will delve into the process of training the model using Amazon ML.
Training the Model
Once you have prepared the data and defined the variables in Amazon Machine Learning (Amazon ML), it’s time to train your machine learning model. Training the model involves utilizing the dataset to create a model that can make accurate predictions on new, unseen data. Let’s explore the process of training the model in Amazon ML:
1. Select the Machine Learning Algorithm:
Before training the model, you need to choose the appropriate machine learning algorithm. Amazon ML offers three built-in algorithms: binary logistic regression, multiclass logistic regression, and linear regression. The choice of algorithm depends on the nature of your problem – classification or regression – and the type of data you have.
2. Configure the Training Options:
Amazon ML provides various training options for fine-tuning your model. You can specify the number of passes the algorithm makes over the data, set the regularization parameter to control overfitting, and adjust other hyperparameters based on your knowledge of the problem domain. Experimentation with different settings can help improve the model’s performance.
3. Start the Training Process:
Once you have selected the algorithm and configured the training options, you can start the training process. Amazon ML automatically handles the complex tasks involved in training the model, such as feature engineering, selecting appropriate variables, and optimizing the algorithm’s parameters. The training time depends on the size and complexity of your dataset, as well as the chosen algorithm.
4. Monitor the Training Progress:
While the model is being trained, you can monitor the training progress. Amazon ML provides feedback on the model’s status, including the number of passes completed, the training time, and any warnings or errors encountered during training. Monitoring the progress helps ensure that the model is being trained successfully.
5. Evaluate the Model’s Performance:
After the training is complete, it’s essential to assess the performance of the model. Amazon ML provides various evaluation metrics, such as accuracy, precision, recall, and F1 score, to measure how well the model predicts the target variable. Evaluating the model’s performance helps you understand its strengths and weaknesses and identify areas for improvement.
6. Iteratively Refine the Model:
Machine learning is an iterative process. Based on the evaluation results, you can refine the model by adjusting parameters, modifying the dataset, or exploring different algorithms. Iteratively refining the model can lead to improved accuracy and better predictions.
Training your model is a crucial step in leveraging the power of Amazon ML. By selecting the appropriate algorithm, configuring training options, monitoring progress, and evaluating performance, you can create a model that accurately predicts outcomes and provides valuable insights.
In the next section, we will explore the process of evaluating the performance of the trained model in more detail.
Evaluating Model Performance
Evaluating the performance of a machine learning model is crucial to assess its accuracy and effectiveness in making predictions. In Amazon Machine Learning (Amazon ML), evaluating model performance involves analyzing various metrics and understanding how well the model performs on new, unseen data. Let’s explore the process of evaluating model performance in Amazon ML:
1. Confusion Matrix:
A confusion matrix provides a detailed breakdown of the model’s predictions and actual outcomes. It shows the number of true positives, true negatives, false positives, and false negatives. This matrix helps in understanding how well the model performs in different scenarios and evaluating its ability to correctly classify instances.
2. Accuracy:
Accuracy measures the proportion of correct predictions made by the model. It is calculated as the ratio of the correct predictions to the total number of instances. A higher accuracy indicates better performance, but it should be interpreted in conjunction with other metrics, especially in cases of imbalanced datasets.
3. Precision and Recall:
Precision and recall are essential evaluation metrics, especially for classification tasks. Precision measures the proportion of correctly predicted positive instances out of all instances predicted as positive. Recall measures the proportion of correctly predicted positive instances out of all actual positive instances. Balancing precision and recall is crucial, depending on the specific problem domain.
4. F1 Score:
The F1 score combines precision and recall into a single metric, providing a balance between the two. It is the harmonic mean of precision and recall. The F1 score considers both false positives and false negatives, making it a useful measure when there is an imbalance between classes or varying costs associated with different types of errors.
5. Area Under the Curve (AUC-ROC):
For binary classification tasks, the AUC-ROC (Area Under the Curve – Receiver Operating Characteristic) curve is a popular metric that assesses the model’s predictive ability across different thresholds. The AUC-ROC curve represents the trade-off between true positive rate (sensitivity) and false positive rate (1-specificity). A higher AUC value indicates better performance.
6. Interpretation and Contextualization:
While evaluating the model’s performance, it is essential to interpret the metrics in the context of the specific problem and domain. Understanding the significance of the metrics and considering the costs and consequences of different types of errors is crucial for practical decision-making based on the model’s predictions.
By evaluating the performance of your model in Amazon ML, you gain insights into its strengths and weaknesses. This evaluation helps you make informed decisions about model improvements, feature engineering, and choosing the best model for your use case. In the next section, we will explore the process of making predictions with the trained model.
Making Predictions
Once you have trained and evaluated your machine learning model in Amazon Machine Learning (Amazon ML), you can leverage it to make predictions on new, unseen data. Predictions allow you to derive insights, make informed decisions, and optimize business processes. Here’s how you can make predictions using your trained model in Amazon ML:
1. Prepare the Input Data:
Before making predictions, you need to ensure that the input data is in the correct format and matches the data used during training. The input data should have the same structure, variable types, and data schema as the training dataset. Preprocessing steps, such as cleaning missing values or encoding categorical variables, may be required based on the model’s requirements.
2. Batch Prediction:
Amazon ML provides a batch prediction feature that allows you to make predictions on a large batch of data. You can upload your input dataset and request predictions for the entire dataset in one go. The predictions are typically returned as a separate file or stored in an Amazon S3 bucket for further analysis.
3. Real-time Prediction:
Amazon ML also supports real-time prediction, where you can make individual predictions in real-time as new data points arrive. This feature is useful for scenarios where immediate predictions are required, such as recommending products to customers or detecting anomalies in real-time data streams. Real-time prediction is achieved by deploying the trained model as a real-time endpoint.
4. Specify Predictive Attributes:
When making predictions, you can specify which attributes or variables you want the model to predict. For example, if you have trained a model to predict customer churn, you can provide the necessary attributes like customer ID, purchase history, and customer activity, and ask the model to predict the likelihood of churn for each customer.
5. Monitor Prediction Quality:
After making predictions, it’s important to monitor the quality and accuracy of the predictions. Compare the predicted outcomes with the actual outcomes to determine the model’s performance. Continuously monitoring the prediction quality helps identify any discrepancies or changes in the model’s effectiveness.
6. Iterate and Improve:
Machine learning is an iterative process, and making predictions is an ongoing task. Based on the feedback and results, you can refine your model by retraining it with new data or adjusting the model parameters. This iterative approach allows your model to adapt and improve over time.
By making predictions using your trained model in Amazon ML, you can harness the power of data-driven insights to drive business decisions and improve operational efficiency. Whether it’s predicting customer behavior, optimizing marketing campaigns, or detecting anomalies, the ability to make accurate predictions is invaluable. In the next section, we will explore the batch prediction feature in more detail.
Using Batch Prediction
In Amazon Machine Learning (Amazon ML), batch prediction allows you to make predictions on a large amount of data in a single request. This feature is particularly useful when you want to process a significant number of data points and obtain predictions for all of them efficiently. Here’s how you can utilize the batch prediction feature in Amazon ML:
1. Prepare the Input Data:
To perform batch prediction, you need to organize your input data in a format that matches the structure and data schema used during model training. Ensure that the input data has the same variables and variable types as the dataset used for training. Any necessary preprocessing steps, such as cleaning missing values or encoding categorical variables, should also be applied to the input data.
2. Upload the Input Data:
Once the input data is prepared, you can upload it to Amazon ML. You have the option to upload the data directly through the Amazon ML console, or you can specify the location of the data in an Amazon S3 bucket. Amazon ML accepts data in various formats, including CSV (Comma Separated Values), JSON (JavaScript Object Notation), and more.
3. Start Batch Prediction Job:
Next, you initiate a batch prediction job in Amazon ML. You define the source of the input data, specify the model you want to use for prediction, and specify the desired output location for the predictions. Amazon ML processes the input data using the trained model and generates predictions for each data point in the input dataset.
4. Retrieve the Predictions:
Once the batch prediction job is complete, you can retrieve the predictions. Amazon ML provides the predictions as a separate file, or you can choose to store them in an Amazon S3 bucket for further analysis. The predictions align with the structure of the input data, allowing you to easily associate each prediction with its corresponding data point.
5. Analyze and Utilize the Predictions:
With the predictions in hand, you can analyze and utilize them to gain valuable insights or drive decision-making processes. Depending on the specific use case, you may perform further analysis, visualize the predictions, or integrate them into other systems or applications. The predictions can be used for various purposes, such as identifying potential target customers, recommending personalized content, or optimizing business operations.
6. Monitor and Refine:
As with any machine learning process, it’s important to monitor the quality and accuracy of the predictions. Continuously evaluate the predictions against the ground truth or actual outcomes to assess the model’s performance. If necessary, iterate and refine the model by retraining it with new data or adjusting the model parameters to improve prediction accuracy.
By using batch prediction in Amazon ML, you can efficiently process large volumes of data and obtain predictions for each data point in a single request. This enables you to gain insights and make informed decisions based on the predictions. In the next section, we will explore the real-time prediction feature in Amazon ML.
Using Real-time Predictions
In addition to batch prediction, Amazon Machine Learning (Amazon ML) also supports real-time predictions. This feature enables you to make predictions on individual data points in real-time as they arrive, allowing you to quickly respond to dynamic changes and make time-sensitive decisions. Here’s how you can leverage the real-time prediction feature in Amazon ML:
1. Deploy the Trained Model:
Before you can make real-time predictions, you need to deploy the trained model as a real-time endpoint in Amazon ML. This endpoint serves as an interface for making predictions on new, individual data points. Deploying the model is a straightforward process that can be done through the Amazon ML console or programmatically via API calls.
2. Send Data for Real-time Prediction:
Once the model is deployed as a real-time endpoint, you can send new data points to the endpoint for prediction. This data can be in the form of a single data record or a batch of records, depending on your application’s requirements. The data should match the variable types and data schema used during training.
3. Receive Real-time Predictions:
When you send data for real-time prediction, Amazon ML processes the data using the deployed model and returns the predictions in real-time. The predictions can be sent back as a response to your API call or as an event pushed to an Amazon Simple Notification Service (SNS) topic. You can extract the predicted outcomes and use them immediately for making decisions or taking appropriate actions.
4. Scale and Performance Considerations:
Real-time predictions in Amazon ML are designed to handle high volumes of requests and provide low-latency responses. You can scale the real-time endpoint to handle concurrent requests, ensuring responsiveness even under heavy load. However, it’s important to monitor the endpoint’s performance and consider the associated costs, especially if you anticipate significant utilization.
5. Continuous Model Improvement:
Real-time predictions offer the advantage of immediate feedback, enabling you to continuously improve the model’s performance. By collecting prediction results and comparing them with the actual outcomes, you can identify areas for model enhancement. You can leverage this feedback loop to retrain the model with new data or adjust the model parameters for better accuracy.
6. Real-time Prediction Applications:
Real-time predictions are valuable in various applications. For example, in e-commerce, you can use real-time predictions to personalize product recommendations for customers as they browse your website. In fraud detection, real-time predictions can help identify suspicious transactions in real-time, allowing for prompt action. Real-time predictions can enhance customer experience, optimize operations, and drive real-time decision-making across multiple industries.
By utilizing real-time predictions in Amazon ML, you can harness the power of machine learning in real-time applications and gain valuable insights for immediate action. Whether it’s personalization, fraud detection, or instant decision-making, real-time predictions enable agility and responsiveness to dynamic changes. In the next section, we will discuss monitoring and managing the trained model in Amazon ML.
Monitoring and Managing the Model
Monitoring and managing your machine learning model in Amazon Machine Learning (Amazon ML) is crucial to ensure its performance, reliability, and accuracy over time. By effectively monitoring and managing the model, you can make informed decisions, identify issues, and maintain the model’s effectiveness. Let’s explore the key aspects of monitoring and managing your model in Amazon ML:
1. Performance Monitoring:
It is important to continuously monitor the performance of your model to ensure its accuracy and reliability. Monitor key metrics such as precision, recall, accuracy, or F1 score to assess the model’s performance over time. If you observe a decline in performance, you may need to retrain the model with additional data or fine-tune the model’s parameters.
2. Data Drift Detection:
Detecting data drift is crucial to maintaining model accuracy. Data drift occurs when the characteristics of the input data change over time, leading to degraded model performance. Use techniques such as monitoring statistical measures or comparing predictions against ground truth to identify instances of data drift. When data drift is detected, consider updating your model or retraining it with fresh data.
3. Versioning and Retraining:
As your model evolves, it is essential to have a versioning system in place to track changes and maintain a history of model iterations. Versioning allows you to keep track of different iterations, compare performance, and revert to previous versions if necessary. Retraining the model periodically with new data and improved techniques ensures that your model remains relevant and accurate.
4. Model Deployment:
When deploying your trained model, ensure that it is appropriately integrated into your production environment. Monitor the deployed model for any issues such as errors, latency, or unexpected behavior. Regularly validate the model’s predictions against actual outcomes to measure its effectiveness in a real-world context.
5. Model Governance and Compliance:
Adhere to data governance and compliance standards when handling sensitive or regulated data in your machine learning models. Ensure that all data usage is in compliance with relevant regulations, and implement necessary measures such as data anonymization or encryption to protect sensitive data.
6. Security and Access Control:
Implement robust security measures to protect your models and data. Define appropriate access control policies to ensure that only authorized personnel can access and manage the model. Regularly audit and monitor access logs to detect any unauthorized activity or potential security breaches.
7. Scalability and Resource Management:
Monitor the resource utilization of your model to ensure optimal performance and cost-effectiveness. Configure scalability options to handle increased traffic or computation requirements. Efficient resource management helps in maximizing the utilization of computing resources and minimizing costs.
By effectively monitoring and managing your machine learning model in Amazon ML, you can ensure its performance, stability, and accuracy over time. Continuous monitoring, versioning, data drift detection, and adherence to governance and security practices contribute to maintaining a reliable and effective model.
In the final section, we will discuss the process of deleting a model in Amazon ML.
Deleting a Model
In Amazon Machine Learning (Amazon ML), if you no longer need a model or want to free up resources, you can delete it. Deleting a model removes it from your account and stops any associated billing. Here’s how you can delete a model in Amazon ML:
1. Access the Amazon ML Console:
To delete a model, log in to the Amazon ML console using your AWS account credentials. Navigate to the section where your models are listed.
2. Select the Model:
Identify the specific model you want to delete from the list of available models. Ensure that you choose the correct model to avoid accidentally deleting an important model.
3. Initiate the Deletion Process:
Select the model you want to delete and click on the appropriate button or option to initiate the deletion process. Amazon ML will prompt you to confirm the deletion, as this action cannot be undone.
4. Confirm the Deletion:
Carefully review the confirmation prompt and ensure that you have selected the correct model. Once you confirm the deletion, the model and all related settings, configurations, and runtime artifacts will be permanently removed.
5. Verify the Deletion:
After the deletion is complete, verify that the model has been successfully removed from the Amazon ML console. Confirm that the model is no longer listed among your available models.
6. Review Billing Impact:
Deleting a model in Amazon ML also stops any associated billing for that model. After the model is deleted, review your AWS billing statements to ensure that the charges for that model are no longer appearing.
It’s important to note that once a model is deleted, all associated data, including batch predictions and real-time predictions, are permanently removed and cannot be recovered. Therefore, it is crucial to perform a thorough review and confirmation before initiating the deletion process.
Deleting models that are no longer needed helps in optimizing resources and reducing costs. By keeping your account tidy and removing unnecessary models, you can effectively manage your Amazon ML environment and focus on the models that are actively contributing value to your business.
With the knowledge of how to delete a model in Amazon ML, you have the ability to remove obsolete models and streamline your machine learning workflow. In the next section, we will provide a brief summary of the key points covered in this guide.
Conclusion
Amazon Machine Learning (Amazon ML) provides a powerful platform for building and deploying machine learning models without the need for extensive data science expertise. With Amazon ML, you can leverage the vast amounts of data available on Amazon Web Services (AWS) to extract insights and make accurate predictions that drive informed decision-making.
In this guide, we explored the process of using Amazon ML, from getting started with an AWS account to creating a machine learning model, preparing data for training, and evaluating model performance. We also discussed how to make predictions using batch prediction and real-time prediction features, as well as monitoring and managing the trained model.
By following the steps outlined in this guide, you can successfully leverage Amazon ML to build models that provide valuable insights and drive business growth. Remember to define variables and data schema accurately, split the dataset for training and evaluation, and continually monitor and evaluate the model’s performance for ongoing improvement.
Real-time prediction and batch prediction options offer flexibility in making predictions based on your specific needs, allowing you to respond to dynamic changes or process a large volume of data efficiently.
Additionally, we discussed the importance of monitoring and managing the model, including performance monitoring, data drift detection, versioning, and compliance with governance and security practices. Lastly, we covered the process of deleting a model when it is no longer needed.
Amazon ML empowers businesses of all sizes to harness the power of machine learning. By leveraging the platform’s intuitive interface and automated features, you can unlock valuable insights, make accurate predictions, and optimize business processes.
Remember that while Amazon ML simplifies the machine learning process, it is important to have a basic understanding of machine learning concepts and best practices. Continuously expand your knowledge in this ever-evolving field to make the most of Amazon ML and stay ahead in the competitive landscape.
Start your journey with Amazon ML today and unlock the potential of your data to drive innovation and achieve impactful results.