Introduction
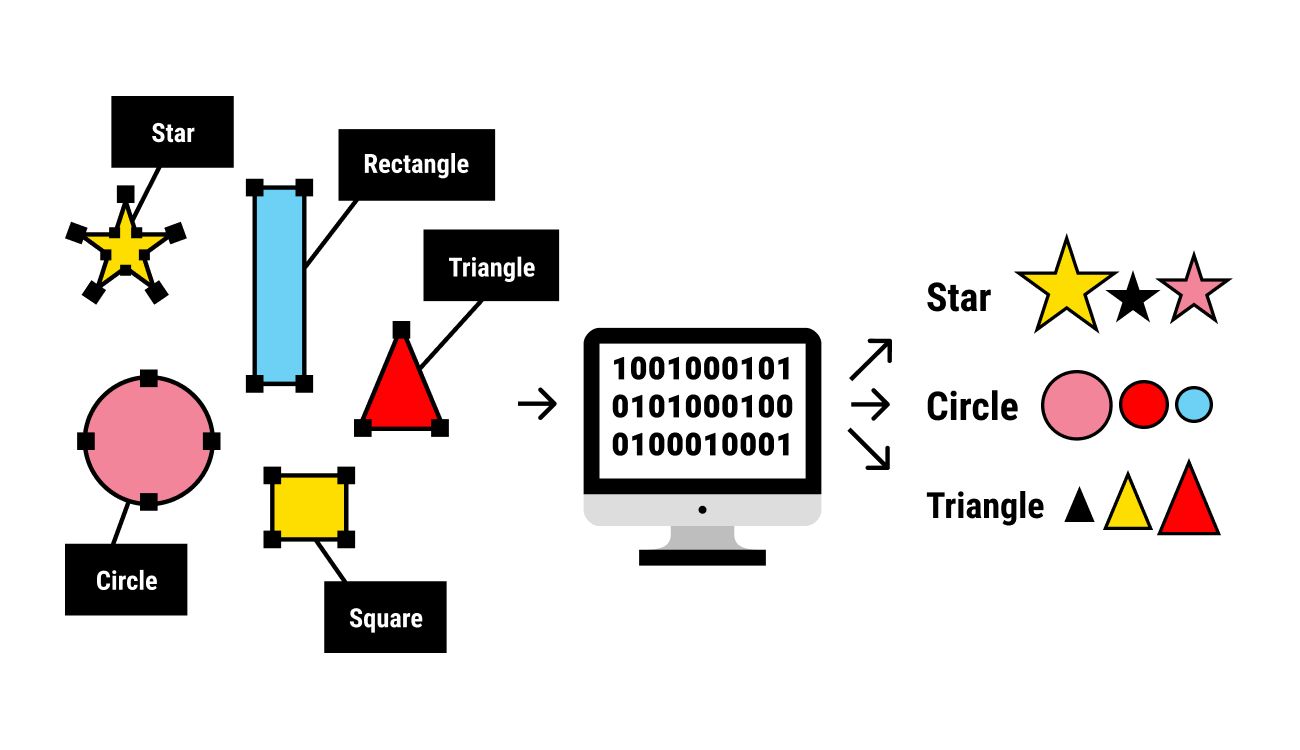
Labeling images accurately and efficiently is a critical step in the field of machine learning. As machines learn to understand and interpret visual data, properly labeled images become the foundation for training algorithms and improving their accuracy. The process of labeling images involves assigning descriptive and relevant tags to images, helping machines recognize and classify objects, scenes, and other visual elements.
With the increasing demand for image recognition and computer vision applications, the importance of proper image labeling cannot be overstated. From autonomous vehicles to facial recognition systems, industries across the board rely on accurately labeled images to develop robust machine learning models.
Image labeling encompasses a wide range of tasks, from object detection and segmentation to facial landmark detection and image categorization. The effectiveness of these tasks depends on the quality and accuracy of the labels assigned to each image. Considering the vast amount of visual data available, labeling images manually can be a time-consuming and tedious process.
In this article, we will explore the significance of image labeling in machine learning and discuss different types of labels to consider. We will also delve into the various methods and tools available for efficient image labeling. Additionally, we will examine best practices for image labeling, addressing common challenges and solutions that arise during the process. Finally, we will touch upon quality control and the importance of data annotation in generating reliable labeled datasets.
Whether you are a seasoned machine learning practitioner or just getting started, understanding the principles and techniques of image labeling is essential. by the end of this article, you will have a solid understanding of how to label images effectively to improve the performance of machine learning models.
Understanding the Importance of Labeling Images
Image labeling plays a crucial role in machine learning, as it directly impacts the accuracy and performance of algorithms trained on visual data. Here are several key reasons why labeling images is of utmost importance:
Training Machine Learning Models: Labeled images serve as training data for machine learning models. By tagging images with accurate and relevant labels, we provide the necessary information to teach algorithms to recognize and differentiate different objects, shapes, and patterns.
Enhancing Object Recognition: Properly labeled images enable machines to identify and classify objects with precision. With accurate labels, algorithms can learn the distinguishing features of various objects, enabling them to recognize and categorize them more effectively.
Improving Accuracy: By labeling images, we can optimize the performance of machine learning models. The more accurately and comprehensively we label images, the better the models can generalize and make accurate predictions. This is particularly important in applications such as medical image analysis, where misclassification may have critical consequences.
Enabling Autonomous Systems: Autonomous systems, such as self-driving cars and drones, heavily rely on image data for decision-making. Properly labeled images can assist these systems in identifying traffic signs, pedestrians, and other objects, enabling them to navigate their surroundings safely and efficiently.
Facilitating Research and Development: Labeled image datasets are invaluable resources for researchers and developers working on improving machine learning algorithms. These datasets allow them to benchmark the performance of their models, compare results, and iterate on their algorithms, contributing to advancements in computer vision and artificial intelligence.
Supporting Contextual Understanding: Proper labels provide contextual information about images, allowing algorithms to understand the relationships between objects, scenes, and concepts. This contextual understanding is crucial in various applications, such as image captioning, where algorithms generate descriptive text based on the content of images.
In summary, image labeling is essential for training accurate and robust machine learning models, enabling object recognition, improving accuracy, facilitating autonomous systems, supporting research and development, and enhancing contextual understanding. Now that we understand the importance of image labeling, let’s delve into different types of labels to consider in the next section.
Types of Labels to Consider
When it comes to labeling images for machine learning, there are various types of labels to consider. The choice of labels depends on the specific task and the level of granularity required. Here are some common types of labels:
Class Labels: Class labels are used to categorize images into a predefined set of classes or categories. For example, in an image recognition task, images can be labeled as “cat,” “dog,” “car,” or “tree.” Class labels are valuable for tasks that require image classification and object recognition.
Bounding Boxes: Bounding box labels involve drawing a rectangle around an object of interest within an image. This type of labeling is useful for object detection tasks, where the goal is to identify and locate specific objects within an image.
Segmentation Masks: Segmentation masks outline specific regions or pixels within an image that belong to a particular object. This type of labeling is useful in tasks that require pixel-level accuracy, such as semantic segmentation or instance segmentation.
Keypoints: Keypoint labels involve marking specific points or landmarks within an image. This type of labeling is common in tasks that require precise localization of specific features, such as facial landmark detection or pose estimation.
Attributes: Attribute labels describe specific characteristics or properties of objects within an image. For example, in a fashion dataset, images can be labeled with attributes such as “color,” “sleeve length,” or “pattern.” Attribute labels add additional information to the dataset and enable more detailed analysis.
Relationships: Relationship labels capture the relationships or interactions between objects within an image. For instance, in an image of a soccer game, labels can indicate the players’ positions, ball movement, and team formations. Relationship labels provide contextual information and assist in understanding the scene.
Temporal Labels: Temporal labels are used when dealing with sequential image data, such as videos or time-lapse images. These labels help establish the order or sequence of frames and enable tasks such as action recognition or video summarization.
It is essential to carefully consider the type of labels required for a specific task to ensure the generated dataset meets the objectives. Some tasks may necessitate multiple types of labels to capture different aspects of the data.
Now that we have explored the different types of labels, let’s move on to the next section, where we will discuss how to choose the right labeling method.
Choosing the Right Labeling Method
Choosing the right labeling method is crucial for efficient and accurate image annotation. Several factors need to be considered depending on the complexity of the task, available resources, and the level of precision required. Here are some common labeling methods to consider:
Manual Labeling: Manual labeling involves humans annotating images by drawing bounding boxes, segmentation masks, keypoints, or assigning class labels. This approach provides high accuracy and control but can be time-consuming and expensive, especially for large datasets.
Semi-Automatic Labeling: Semi-automatic labeling combines human annotation with automated tools or algorithms. For example, bounding boxes can be generated automatically using object detection algorithms, and humans refine the annotations as needed. This method can save time while maintaining annotation quality.
Crowdsourced Labeling: Crowdsourcing platforms can be used to distribute labeling tasks to a large number of contributors. This method enables parallel annotation of images, reducing the time required to label large datasets. However, quality control and consistency may be challenging with multiple annotators.
Active Learning: Active learning involves training an initial model with a small labeled dataset and using it to select the most informative samples for annotation. This iterative process focuses human annotation efforts on challenging or uncertain images, improving model performance while minimizing annotation costs.
Transfer Learning: Transfer learning leverages pre-trained models and existing labeled datasets to reduce the amount of manual annotation needed. By fine-tuning a pre-trained model on a smaller dataset, it is possible to achieve good performance with fewer labeled examples.
Simulation-based Labeling: In some cases, annotations can be generated through simulation or synthetic data generation. This approach is useful when real-world annotations are difficult or expensive to obtain. However, the effectiveness of simulation-based labeling depends on how well the synthetic data reflects real-world scenarios.
When choosing a labeling method, it is important to assess the requirements of the specific task and consider factors such as dataset size, complexity, cost, and time constraints. A combination of different labeling methods may also be applicable, depending on the project’s needs.
Now that we understand different labeling methods, in the next section, we will discuss the available tools and software for image labeling.
Tools and Software for Image Labeling
There are various tools and software available to assist in the process of image labeling. These tools provide user-friendly interfaces, annotation functionalities, and automation features to streamline the labeling workflow. Here are some popular tools and software for image labeling:
LabelImg: LabelImg is an open-source graphical image annotation tool. It allows users to draw bounding boxes on images and assign corresponding class labels. LabelImg supports various annotation formats, making it compatible with popular machine learning frameworks.
RectLabel: RectLabel is a macOS-based annotation tool specifically designed for object detection labeling. It offers features such as polygon and pixel-wise segmentation, keypoints labeling, and automatic annotation suggestions. RectLabel aims to simplify the annotation process and increase annotation efficiency.
VGG Image Annotator (VIA): VIA is a versatile image annotation tool that offers a wide range of annotation capabilities, including bounding boxes, polygons, keypoints, and region-based labeling. It supports multiple annotation file formats and allows collaboration among multiple annotators.
Labelbox: Labelbox is a web-based annotation platform that supports various annotation types, including bounding boxes, polygons, and segmentation masks. It also offers advanced features like data management, project collaboration, and automation using machine learning models.
Supervise.ly: Supervise.ly is an annotation platform that combines automated annotation features with manual annotation capabilities. It offers tools for object detection, classification, and semantic segmentation, along with data collaboration and version control.
Amazon SageMaker Ground Truth: SageMaker Ground Truth is a fully managed data labeling service provided by Amazon. It offers both manual and automated annotation capabilities and supports a range of annotation tasks, including object detection, semantic segmentation, and text classification.
Custom In-House Tools: Many organizations develop their own custom tools or integrate existing annotation libraries into their workflows. These tools are tailored to specific project requirements, providing flexibility and control over the annotation process.
Before selecting an annotation tool or software, it is essential to evaluate the specific needs of the project, such as annotation types, collaboration features, ease of use, and integration capabilities. Selecting the right tool can significantly improve annotation efficiency, data quality, and overall project productivity.
Now that we have explored the tools available for image labeling, let’s move on to the next section, where we will discuss best practices for image labeling.
Best Practices for Image Labeling
Effective image labeling is essential for generating high-quality datasets and training accurate machine learning models. Here are some best practices to follow when labeling images:
Define Clear Annotation Guidelines: Clearly define the annotation guidelines to ensure consistency among annotators. Include detailed instructions on label definitions, annotation techniques, and examples of correctly labeled images.
Ensure Label Accuracy: Pay attention to label accuracy and correctness. Double-check labels for each image and cross-reference with other annotators if necessary. Consistently review and validate the annotations to maintain a high level of accuracy.
Use Multiple Annotators: Employ multiple annotators for quality control purposes. This allows for inter-annotator agreement and helps identify and resolve annotation discrepancies. Consensus can be reached through discussions or by selecting the majority opinion.
Consider Context and Ambiguity: Take into account the context of the image and potential label ambiguity. Analyze the image as a whole and consider variations in poses, angles, lighting conditions, and object occlusions when assigning labels.
Document Uncertainty and Challenges: Maintain a record of challenging images or instances where labeling uncertainty arises. This documentation can be beneficial for future reference, model improvement, and sharing insights with the annotation team.
Address Class Imbalance: Pay attention to class imbalance in the dataset. Ensure that each class has a sufficient number of labeled examples to prevent bias and ensure accurate model training and evaluation.
Iterative Annotation and Feedback: Engage in an iterative process of annotation and feedback. Regularly review and assess the labeled dataset, provide feedback to annotators, and address any issues or confusion that may arise throughout the labeling process.
Regular Quality Control: Implement quality control procedures to ensure the ongoing accuracy and consistency of annotations. Randomly sample a subset of annotated images for review and audits. Track and document annotator performance for continuous improvement.
Evaluate and Improve: Continually evaluate the performance of the labeled dataset and the trained models. Analyze model performance metrics, identify areas of improvement, and iterate on the labeling process to enhance the quality of future annotations.
By following these best practices, you can ensure the integrity and accuracy of your labeled datasets, leading to improved machine learning model performance and more reliable results.
In the next section, we will explore the process of annotating images for different machine learning tasks.
Annotating Images for Different Machine Learning Tasks
Annotating images for machine learning tasks involves tailoring the labeling process to the specific objectives and requirements of each task. Here are some common machine learning tasks and the corresponding annotation techniques:
Object Detection: For object detection tasks, bounding box annotation is typically used. Annotators draw rectangles around objects of interest, providing spatial information for the machine learning model to identify and localize objects within the image.
Image Classification: Image classification tasks involve assigning one or multiple class labels to images. Annotators assign the appropriate label(s) to each image, effectively categorizing it based on the content or attributes it represents.
Semantic Segmentation: Semantic segmentation aims to label individual pixels or regions in an image with corresponding classes. Annotators outline and label the boundaries of each object or region within the image accurately, pixel by pixel.
Instance Segmentation: Instance segmentation combines object detection and semantic segmentation. Annotators draw bounding boxes around individual objects and label each pixel within the box with an instance-specific class label.
Keypoint Detection: Keypoint detection tasks involve identifying and labeling specific points or landmarks within an image. Annotators mark and label these keypoints, enabling the machine learning model to locate and understand the spatial relationships between them.
Text Annotation: Text annotation tasks involve labeling text instances within images. Annotators identify and outline the text regions, providing accurate transcriptions or extracting specific information from the text.
Scene Understanding: Scene understanding tasks require annotating various visual elements within an image, such as objects, relationships, spatial layout, and attributes. Annotators label objects, assign relationships between them, and provide additional contextual information as necessary.
Temporal Annotation: Temporal annotation is used for video or sequential data. Annotators label frames or timestamps with corresponding annotations, allowing for tasks such as action recognition, event detection, or video summarization.
It is crucial to select the appropriate annotation technique for the specific task at hand. Careful consideration should be given to the level of detail, accuracy, and consistency required to train the machine learning model effectively.
In the next section, we will discuss common challenges that arise during the image labeling process and how to overcome them.
Common Challenges in Image Labeling
The process of image labeling for machine learning comes with its fair share of challenges. Here are some common challenges faced during the image labeling process:
Subjectivity: Labeling can be subjective, especially when dealing with ambiguous or complex images. Annotators may have different interpretations or understandings of the same image, leading to inconsistencies in the labeling. Clear annotation guidelines, regular training, and inter-annotator agreement sessions can help mitigate subjectivity.
Labeling Cost and Time: Labeling a large dataset can be time-consuming and expensive, particularly when relying on manual annotation. Balancing the need for accuracy and cost-effectiveness requires careful planning and consideration of different labeling methods, automation, and resource allocation.
Labeling Scalability: Scaling the labeling process to handle large datasets can present logistical challenges. Managing multiple annotators, maintaining consistency, and ensuring quality control become more complex as the dataset size grows. Efficient workflows, clear communication, and collaboration platforms can assist in addressing scalability challenges.
Data Imbalance and Bias: Imbalanced datasets, where certain classes or labels are underrepresented, can lead to biased machine learning models. Ensuring a balanced representation of classes through careful dataset curation or augmentation is crucial to avoid bias and improve model performance.
Complex Labeling Requirements: Some machine learning tasks require intricate annotations, such as pixel-level segmentation or landmark detection. Achieving high-quality annotations for these tasks can be challenging, requiring skilled annotators, clear guidelines, and close supervision to maintain accuracy and detail.
Data Security and Privacy: Working with sensitive or private image data can raise concerns regarding data security and privacy. Ensuring secure data handling practices, confidential storage, and considering data anonymization techniques are vital to protect the privacy of individuals and comply with regulations.
Quality Control: Maintaining annotation quality and consistency throughout the entire labeling process is essential. Implementing robust quality control measures, such as regular inter-annotator agreement evaluations, auditing, and feedback loops, helps maintain high levels of accuracy and reliability.
Adaptability to Model Requirements: The labeling process should consider the specific needs of the machine learning model being trained. Flexibility is required to adapt annotations to evolving model requirements, such as fine-tuning, transfer learning, or domain-specific adaptations.
Overcoming these challenges requires careful planning, continuous improvement, and a commitment to maintaining high data quality. Employing best practices, using appropriate tools, and building a skilled annotation team can alleviate many of these challenges and contribute to successful image labeling projects.
In the next section, we will explore the importance of quality control and data annotation in image labeling.
Quality Control and Data Annotation
Quality control and data annotation are integral aspects of the image labeling process. Ensuring the accuracy, consistency, and reliability of annotated data is crucial for training effective machine learning models. Here are some key considerations for quality control and data annotation:
Inter-Annotator Agreement: Regular checks of inter-annotator agreement help assess the consistency and accuracy of annotations. Evaluating the agreement between multiple annotators on a subset of images helps identify and address discrepancies and ensures that the labeling guidelines are well understood and applied consistently.
Quality Assurance Checks: Implementing quality assurance measures involves conducting periodic reviews and audits of annotated datasets. Randomly selecting a subset of images for manual review allows for the identification of potential errors, ensuring that the annotations meet the desired level of quality and accuracy.
Feedback and Iterative Improvement: Establishing a feedback loop between annotators and reviewers promotes continuous improvement in annotation quality. Feedback can be provided on an ongoing basis, addressing specific issues, providing clarification on guidelines, and offering suggestions for improvement to enhance overall annotation accuracy.
Documentation and Guidelines: Thorough documentation of annotation guidelines and instructions is essential for maintaining consistency and accuracy. Clear guidelines prevent ambiguity, provide clarity on annotation techniques and rules, and serve as a reference for annotators throughout the labeling process.
Data Validation and Sanity Checks: Performing data validation and sanity checks on the annotated datasets ensures their reliability. Automated or manual checks can be conducted to identify any inconsistencies, errors, or outliers in the annotated data, allowing for prompt correction and enhancing the overall quality of the dataset.
Regular Training and Calibration: Providing regular training sessions to annotators promotes a deeper understanding of the labeling guidelines and improves annotation consistency. Calibration exercises and continuous learning opportunities help address any drift in annotation quality over time.
Reviewing Complex Annotations: For tasks involving complex annotations, such as pixel-level segmentation or landmark detection, engaging experts or experienced annotators is crucial. Regular reviews and feedback cycles help maintain the requisite level of accuracy and ensure that the fine details are correctly captured.
Version Control and Annotation History: Maintaining version control and annotation history helps track changes and facilitates transparency and reproducibility. Having access to the annotation history allows for retrospection, tracking improvements, and reverting to previous versions if necessary.
Implementing robust quality control measures and establishing a culture of constant improvement ensures high-quality annotated datasets. Consistent monitoring, training, and feedback loops bring about improvements in annotation accuracy, reducing the chances of biases and increasing the overall reliability of the data.
In the final section, we will summarize the key points discussed in this article.
Conclusion
In the field of machine learning, image labeling is a crucial step in training accurate and robust models. By assigning relevant and accurate labels to images, machines can learn to recognize and interpret visual data, enabling a wide range of applications such as object detection, image classification, and semantic segmentation.
In this article, we explored the importance of image labeling in machine learning and discussed various types of labels to consider, including class labels, bounding boxes, segmentation masks, keypoints, and attributes. We also examined different labeling methods, such as manual labeling, crowdsourcing, and active learning, and highlighted the significance of choosing the right method according to the task requirements and available resources.
We then discussed several tools and software available for image labeling, including LabelImg, RectLabel, VIA, Labelbox, and Amazon SageMaker Ground Truth. These tools provide user-friendly interfaces and annotation functionalities to streamline the labeling workflow and improve efficiency.
Furthermore, we outlined best practices for image labeling, emphasizing the importance of clear annotation guidelines, label accuracy, multiple annotators for quality control, addressing labeling challenges, and regular quality control measures. We also discussed common challenges in image labeling, such as subjectivity, cost, scalability, imbalanced data, and label complexity.
Quality control and data annotation were highlighted as critical aspects of the image labeling process. Inter-annotator agreement, quality assurance checks, feedback loops, and documentation of guidelines are essential for maintaining high-quality annotations and reliable datasets.
In conclusion, image labeling is a fundamental process that significantly impacts the performance and accuracy of machine learning models. Through proper annotation techniques, efficient labeling methods, and robust quality control measures, we can overcome challenges and generate high-quality labeled datasets. By following best practices and using appropriate tools, we can enhance the efficiency, accuracy, and reliability of the image labeling process, enabling the development of powerful machine learning models that can interpret and understand visual data.