Introduction
Computer vision is an interdisciplinary field that focuses on enabling computers to understand and interpret visual information, similar to how humans perceive and analyze visual data. It combines principles from computer science, mathematics, and artificial intelligence to develop algorithms and models that can extract meaningful insights and recognize patterns from images, videos, and other visual data.
With the advancement of machine learning techniques, computer vision has gained prominence in a wide range of applications, revolutionizing industries such as healthcare, autonomous vehicles, surveillance, retail, and entertainment. The ability of machines to perceive, understand, and respond to visual information has opened up possibilities for new innovations, increased efficiency, improved accuracy, and enhanced user experiences.
Computer vision aims to replicate human visual perception by enabling machines to detect and recognize objects, understand scenes, analyze facial expressions, track motion, measure depth, and much more. It involves the extraction of relevant features and patterns from visual data, followed by the application of machine learning algorithms to process and interpret this information.
By leveraging machine learning techniques, computer vision can identify objects, classify images, segment scenes, detect anomalies, and even predict future events. Machine learning algorithms enable the computer vision system to learn from a vast amount of labeled or unlabeled data, improving its understanding and accuracy over time.
The field of computer vision is constantly evolving, with researchers and developers continually exploring new algorithms, models, and techniques to tackle complex challenges. Despite the significant progress made in recent years, there are still obstacles to overcome, such as occlusion, variability in lighting conditions, viewpoint variations, and complex background environments.
Training data plays a crucial role in the success of computer vision models. Large, diverse, and accurately labeled datasets are essential for training models to recognize and classify objects with high accuracy. Additionally, advancements in hardware infrastructure, such as high-performance GPUs and specialized processing units, have accelerated the training and deployment of computer vision models.
This article provides an overview of computer vision in machine learning, exploring its applications, challenges, the role of machine learning algorithms, popular models and algorithms used in computer vision, evaluation metrics, and future directions in the field. Understanding the fundamentals of computer vision and its integration with machine learning will shed light on the incredible potential of this technology and the possibilities it holds for the future.
What is Computer Vision?
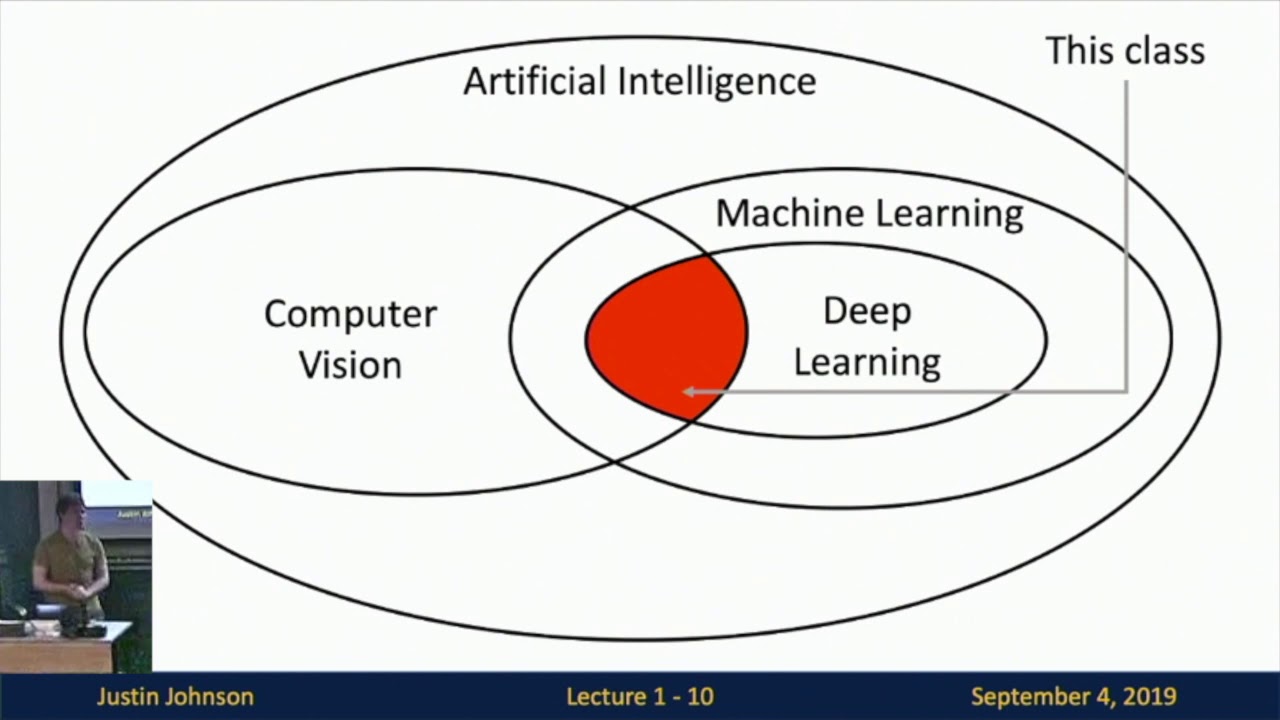
Computer vision is a field within the broader domain of artificial intelligence (AI) that focuses on enabling computers to interpret and understand visual data. It involves developing algorithms and models that can extract meaningful information from images, videos, and other visual inputs, similar to how the human visual system works.
In simple terms, computer vision is about teaching machines to see and interpret the world around them. By utilizing machine learning, statistical techniques, and pattern recognition algorithms, computers can analyze and make sense of visual data to perform various tasks, such as object detection, image classification, scene understanding, and even facial recognition.
One of the fundamental challenges in computer vision is to enable machines to process and interpret visual data in a way that is similar to human perception. This includes understanding the structure, content, and context of visual information, recognizing objects, understanding spatial relationships, and identifying patterns and anomalies.
Computer vision algorithms often involve multiple stages of processing, starting with low-level image processing techniques such as edge detection and image filtering. These early-stage techniques help extract basic features and enhance the quality of the visual data. As the processing continues, more advanced algorithms can be applied, including feature extraction, object detection, segmentation, and scene understanding.
Computer vision has a wide range of applications across various industries. For instance, in healthcare, computer vision can be used for medical imaging analysis, assisting in the diagnosis of diseases and abnormalities. In autonomous vehicles, computer vision plays a vital role in recognizing traffic signs, pedestrians, and obstacles, enabling the vehicle to make informed decisions. In retail, computer vision is used for inventory management, product recognition, and customer behavior analysis, among other things.
Computer vision also intersects with other fields, such as robotics and augmented reality, where machines need to perceive and interact with the physical world in real-time. By equipping machines with the ability to see and understand visual data, computer vision opens up a myriad of possibilities for automation, efficiency improvement, and innovation across multiple domains.
As the field of computer vision continues to advance, researchers and engineers are constantly developing new algorithms, models, and techniques to enhance the capabilities and performance of computer vision systems. By leveraging various machine learning approaches, such as deep learning and convolutional neural networks, computer vision models can achieve remarkable accuracy and generalization.
Overall, computer vision is a fascinating and rapidly evolving field that holds immense potential for revolutionizing industries and transforming the way machines interact with the visual world. By teaching machines to interpret and understand visual data, computer vision enables them to perform complex tasks that were once limited to humans, paving the way for a future where technology and human perception converge.
Applications of Computer Vision
Computer vision has seen a tremendous impact across various industries, with applications that have transformed the way we interact with technology and understand the world around us. Let’s explore some of the key areas where computer vision is being utilized:
- Healthcare: Computer vision is revolutionizing the healthcare industry by enabling faster and more accurate diagnosis through medical imaging analysis. It can assist in detecting tumors, identifying abnormalities on X-rays or MRI scans, and analyzing histopathology slides. Computer vision also plays a crucial role in robot-assisted surgery, where it provides real-time imaging and guidance to surgeons.
- Autonomous Vehicles: The development of self-driving cars is heavily reliant on computer vision technologies. By analyzing and interpreting visual data from cameras, LiDAR, and other sensors, autonomous vehicles can detect and track objects, identify road signs, navigate complex environments, and make informed decisions to ensure safe and efficient transportation.
- Surveillance and Security: Computer vision has transformed surveillance systems by providing advanced video analytics capabilities. It can detect and track objects of interest, monitor crowd movements, recognize faces, and identify suspicious activities. These applications are essential for enhancing public safety, securing facilities, and preventing crime.
- Retail: Computer vision is being utilized in retail to improve customer experiences and optimize operations. Facial recognition technology, for example, can personalize shopping experiences by identifying loyal customers and customizing product recommendations. Computer vision also facilitates inventory management by automating stock counting, detecting product placements, and monitoring shelf conditions.
- Augmented Reality: Computer vision plays a crucial role in augmented reality (AR) applications, where it enables the overlay of digital information onto the real-world environment. By recognizing and tracking objects in real-time, AR systems can enhance user experiences by providing contextual information, interactive gestures, and virtual objects seamlessly integrated into the physical world.
- Robotics: Computer vision is essential in robotics applications, enabling robots to perceive and interact with the environment. Robots can use computer vision to recognize objects, navigate obstacles, perform precise movements, and collaborate with humans in various industries, such as manufacturing, logistics, and healthcare.
- Image and Video Analysis: Computer vision is widely used for image and video analysis tasks. Content-based image retrieval systems can search for images based on their visual features, while video surveillance systems can analyze footage to detect abnormal events or track the movement of individuals. Additionally, computer vision technologies are used in the entertainment industry for video editing, special effects, and virtual reality experiences.
These are just a few examples of the vast array of applications where computer vision is making a significant impact. As the technology continues to advance, we can expect even more innovative and transformative use cases across various domains, improving efficiency, accuracy, and our understanding of the visual world.
Challenges in Computer Vision
While computer vision has made significant advancements in recent years, there are still several challenges that researchers and engineers face in developing robust and accurate computer vision systems. Some of the key challenges include:
- Variability in Visual Data: The real world is filled with diverse and complex visual data, including variations in lighting conditions, viewpoints, object appearances, and occlusions. This variability poses a challenge for computer vision systems to accurately perceive and interpret visual information across different scenarios.
- Object Recognition and Classification: One of the fundamental tasks in computer vision is object recognition and classification. However, accurately identifying objects in different contexts can be challenging due to variations in object appearances, background clutter, and occlusions. Developing robust algorithms that can handle these variations and generalize well is an ongoing challenge.
- Segmentation and Scene Understanding: Understanding the spatial layout of a scene and segmenting objects from the background are important tasks in computer vision. However, accurate segmentation and scene understanding can be challenging due to complex scenarios, overlapping objects, and variations in object shapes and sizes. Developing algorithms that can handle these challenges and provide precise segmentations is an active area of research.
- Real-Time Processing: Many computer vision applications, such as robotics and autonomous vehicles, require real-time processing of visual data. Achieving high-speed processing while maintaining accuracy can be a challenge, as it often requires optimizing algorithms for efficient execution and utilizing hardware acceleration techniques.
- Lack of Labeled Data: Building accurate computer vision models typically requires large annotated datasets. However, creating these datasets can be time-consuming and expensive, especially when dealing with more specialized or niche domains. The availability of high-quality and diverse labeled datasets remains a challenge in many areas of computer vision.
- Generalization and Transfer Learning: Computer vision models often struggle to generalize well to unseen data or different environments. They may perform well on training data but fail to adapt to new conditions. Transfer learning techniques, which leverage pre-trained models on large datasets, have shown promise in addressing this challenge, but there is still a need for more robust methods that can effectively transfer knowledge across domains.
- Ethical Considerations: With the increasing adoption of computer vision technologies, ethical considerations come into play. Concerns regarding privacy, bias in algorithms, potential misuse of facial recognition technology, and ethical implications in surveillance applications need to be addressed to ensure responsible and ethical deployment of computer vision systems.
Addressing these challenges requires a combination of advanced algorithms, improved data collection and labeling techniques, computational resources, and interdisciplinary collaborations. Despite these challenges, the field of computer vision continues to evolve rapidly, and researchers are actively working towards innovative solutions to push the boundaries of what is possible.
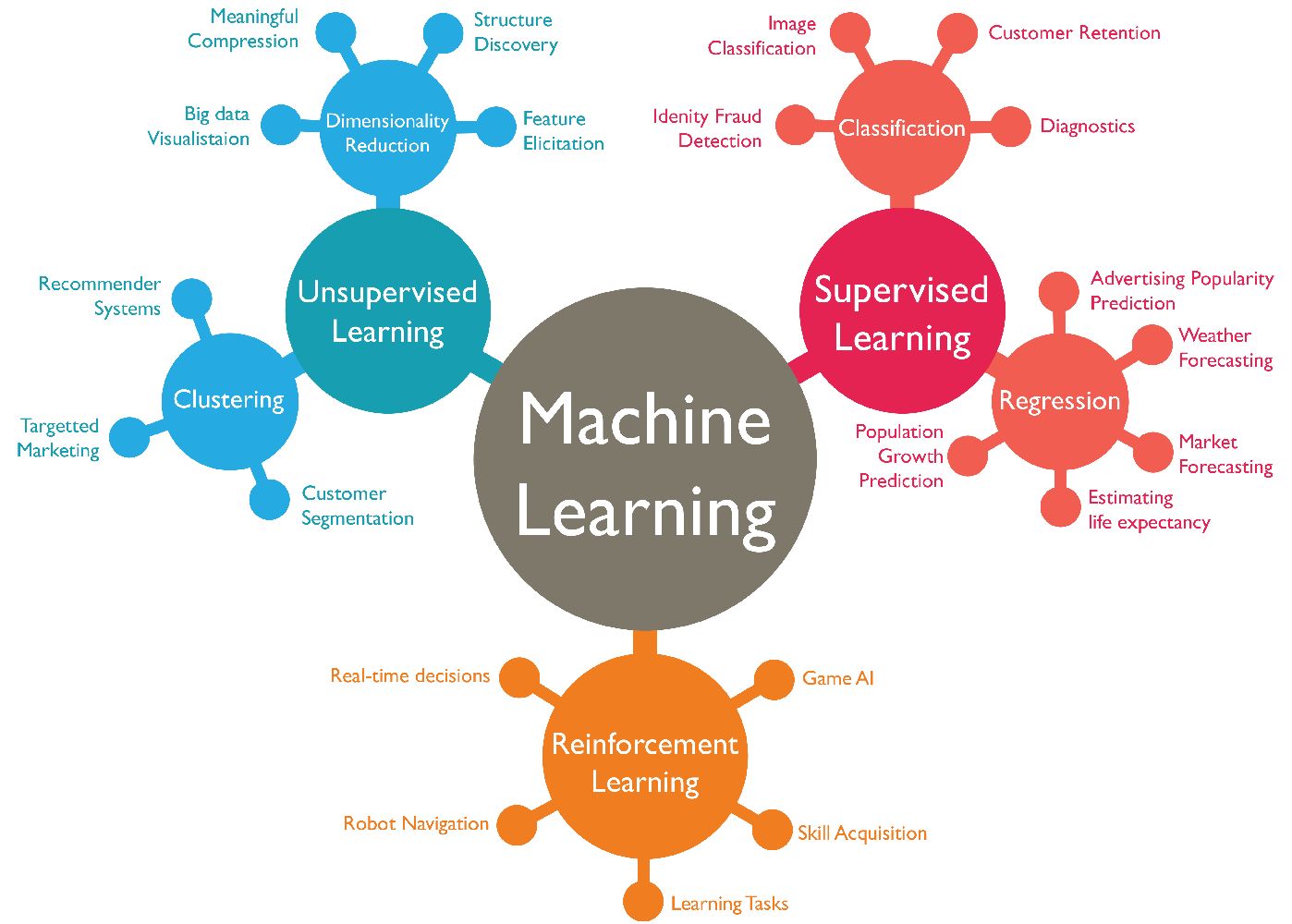
How Machine Learning is Used in Computer Vision
Machine learning plays a pivotal role in computer vision, empowering systems to analyze and understand visual data. By leveraging machine learning algorithms and techniques, computer vision models can learn from large datasets, recognize patterns, and make accurate predictions. Here are some ways in which machine learning is used in computer vision:
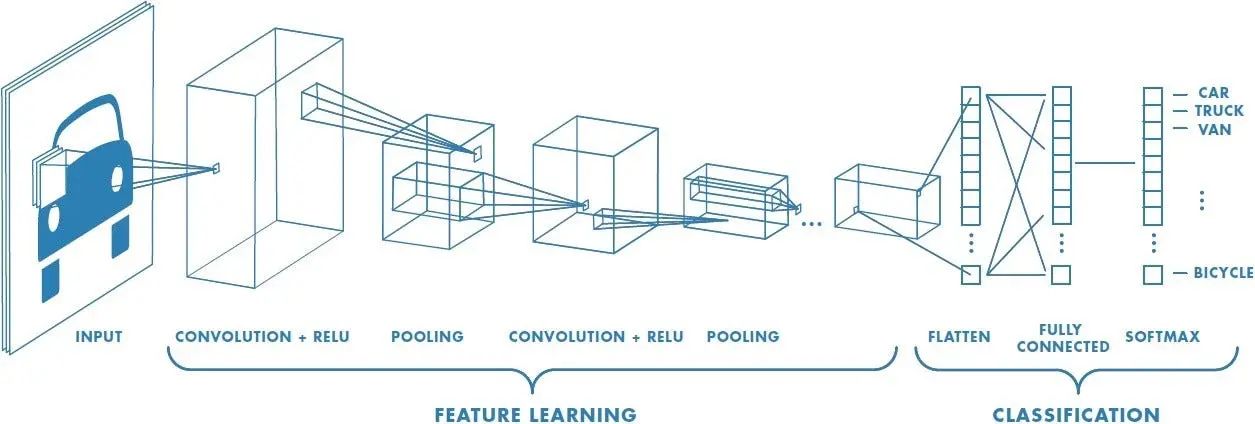
- Object Detection and Recognition: Machine learning algorithms, particularly deep learning techniques like convolutional neural networks (CNNs), have significantly advanced the field of object detection and recognition. These models can learn from large labeled datasets to detect and classify objects in images and videos, enabling applications like automatic image tagging, face recognition, and real-time object tracking.
- Image Classification: Machine learning-based classifiers have been developed to accurately classify images into specific categories. With the help of labeled training data, these models can learn the discriminative features that distinguish different objects or scenes. Image classification has numerous applications, including content-based image retrieval, quality control in manufacturing, and medical image analysis.
- Image Segmentation: Machine learning techniques are utilized for image segmentation tasks, where the goal is to partition an image into different regions or objects. Deep learning-based approaches, such as fully convolutional networks (FCNs), have shown great success in segmenting objects from complex backgrounds, enabling applications like autonomous driving, medical image analysis, and video editing.
- Transfer Learning: Transfer learning has emerged as a powerful technique in computer vision, allowing models to leverage knowledge learned from one task or dataset and apply it to another. Pre-trained models, such as those trained on the ImageNet dataset, provide a strong foundation for feature extraction and can be fine-tuned on specific tasks with limited labeled data. Transfer learning aids in overcoming the limitations of training data scarcity and accelerates the development of accurate computer vision models.
- Generative Models: Generative models, such as generative adversarial networks (GANs) and variational autoencoders (VAEs), have been employed in computer vision to generate realistic images, enhance image quality, and perform image-to-image translation tasks. These models learn the underlying distribution of the training data and can generate new samples or transform images by capturing their high-level features.
- Video Understanding: Machine learning algorithms are applied to video understanding tasks, such as action recognition, video summarization, and activity detection. Recurrent neural networks (RNNs) and 3D convolutional networks are commonly used to model temporal dependencies and analyze the sequential nature of video data. These techniques enable automated video surveillance, video content analysis, and video recommendation systems.
- Deep Feature Extraction: Deep learning models, such as CNNs, are often used as feature extractors in computer vision tasks. By utilizing the intermediate layers of a pre-trained network, these models can capture high-level abstract representations of images, which can then be fed into other machine learning algorithms for tasks like clustering, retrieval, and anomaly detection.
The integration of machine learning in computer vision has revolutionized the field, enabling more accurate and efficient processing of visual data. By harnessing the power of machine learning algorithms, computer vision systems are capable of analyzing vast amounts of visual information, recognizing complex patterns, and making intelligent decisions, thereby opening up a wide range of applications across industries and domains.
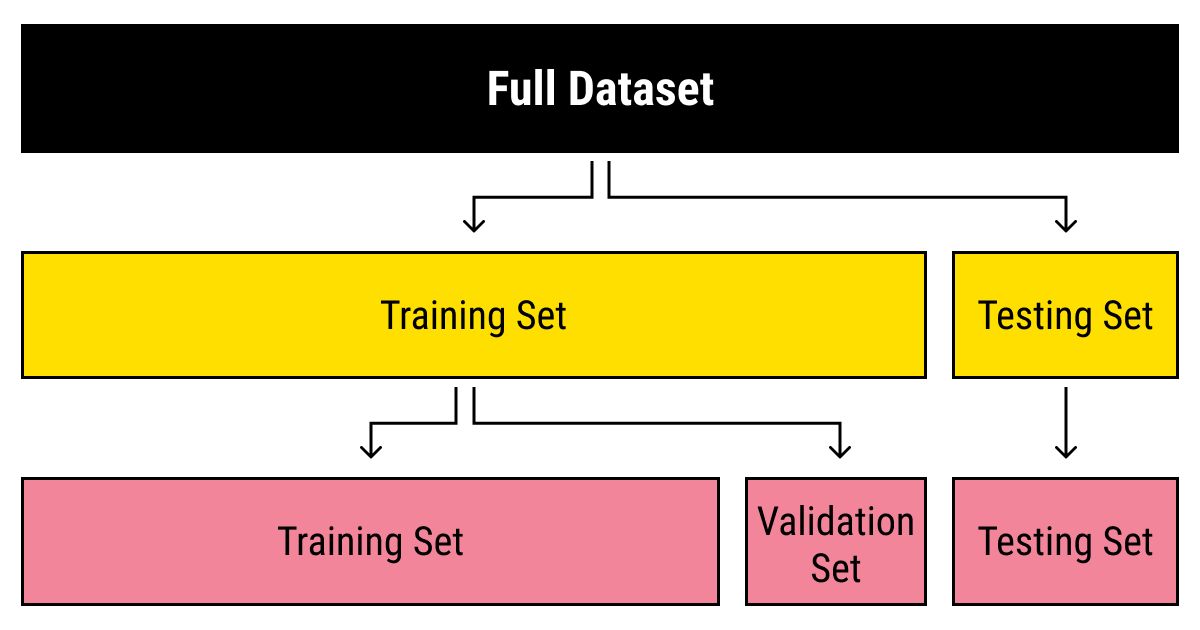
Training Data for Computer Vision Models
Training data is a crucial component in developing accurate and robust computer vision models. The quality, diversity, and quantity of training data directly impact the performance and generalization ability of these models. Here are some key considerations when it comes to training data for computer vision:
Data Collection: Collecting relevant and representative data is essential for training computer vision models. The data should cover a wide range of scenarios, object variations, lighting conditions, and backgrounds to ensure that the model can generalize well to unseen data. Data can be collected using various strategies, including manual labeling, crowd-sourcing, web scraping, or utilizing pre-existing labeled datasets.
Data Annotation: Annotation involves labeling the training data with ground truth information, such as object boundaries, object classes, or semantic segmentation masks. Annotation can be a time-consuming and labor-intensive process, particularly for complex computer vision tasks. Techniques like bounding box annotation, polygon segmentation, and keypoint annotation are commonly used to annotate training data for object detection, segmentation, and pose estimation tasks.
Label Quality: Ensuring the accuracy and quality of labels is crucial for training effective computer vision models. Labeling errors can introduce noise and hinder model performance. Establishing clear annotation guidelines and implementing rigorous quality control measures during the annotation process is essential to maintain label accuracy.
Data Augmentation: Data augmentation techniques are often employed to increase the size and diversity of training data. Common augmentation techniques include random image rotations, translations, scaling, flipping, and adding noise. Augmentation helps improve model generalization, robustness, and reduces overfitting by exposing the model to a wider range of data variations.
Data Balance: Balancing the distribution of different classes or categories in the training data is crucial to avoid bias in the model. Imbalanced data can lead to poor performance on underrepresented classes. Techniques such as oversampling, undersampling, or using class-weighted loss functions can help address data imbalance and improve model performance.
Domain Adaptation: In some cases, the training data might come from a different domain than the target application. Domain adaptation techniques aim to bridge the gap between the source and target domains by adapting the model to the target domain using limited labeled data. This is particularly useful when collecting labeled data in the target domain is expensive or impractical.
Availability of Datasets: Several large-scale benchmark datasets are available in the computer vision community, such as ImageNet, COCO, and PASCAL VOC. These datasets provide labeled images across various object classes and can serve as valuable resources for training and evaluating computer vision models. Additionally, domain-specific datasets may exist for specific applications, such as medical imaging or autonomous driving, which cater to the specific requirements of those domains.
Training data serves as the foundation for building and fine-tuning computer vision models. However, it’s important to remember that the quality of the model is not solely dependent on the training data. Other factors, such as model architecture, optimization techniques, and hyperparameter tuning, also contribute towards achieving high performance in computer vision tasks. A balanced approach between data quality, model design, and algorithmic techniques paves the way for successful computer vision applications.
Popular Algorithms and Models in Computer Vision
Computer vision has witnessed significant advancements in algorithms and models, enabling sophisticated analysis and understanding of visual data. Here are some of the popular algorithms and models frequently used in the field of computer vision:
- Convolutional Neural Networks (CNNs): CNNs have revolutionized computer vision and achieved groundbreaking results in various tasks. These deep learning models are designed to automatically learn hierarchical representations of visual data. CNNs excel at image classification, object detection, and image segmentation, thanks to their ability to capture spatial dependencies through convolutional layers and downsample input data through pooling layers.
- Recurrent Neural Networks (RNNs): RNNs are commonly used for tasks involving sequential or temporal data, such as video analysis and natural language processing. In computer vision, RNNs are employed in tasks like action recognition, video captioning, and video synthesis, allowing models to learn and reason about temporal dependencies in visual data.
- Generative Adversarial Networks (GANs): GANs are a class of generative models that consist of a generator network and a discriminator network that compete against each other. GANs have been instrumental in generating realistic images, enhancing image quality, and performing image-to-image translations. They have applications in areas such as image generation, style transfer, and data augmentation.
- Region-based Convolutional Neural Networks (R-CNN): R-CNNs pioneered the use of region proposals for object detection and recognition. The model first generates a set of region proposals using techniques like selective search and then processes each proposal independently. R-CNNs achieved state-of-the-art results in object detection and laid the foundation for subsequent models such as Fast R-CNN and Faster R-CNN.
- Mask R-CNN: Mask R-CNN is an extension of Faster R-CNN that includes a pixel-level segmentation branch in addition to object detection. It enables accurate instance segmentation by predicting masks for each detected object. Mask R-CNN has been widely adopted in various applications, such as medical image analysis, autonomous driving, and semantic segmentation.
- YOLO (You Only Look Once): YOLO is a real-time object detection model that achieves impressive speed and accuracy. It processes the entire image in a single pass, predicting class probabilities and bounding box coordinates for detected objects. YOLO has found applications in real-time object tracking, surveillance systems, and robotics.
- Siamese Networks: Siamese networks are used for tasks like face recognition, image similarity, and object tracking. These networks learn a similarity metric to measure the similarity between pairs of images or objects. Siamese networks have been effective in one-shot learning scenarios, where the model can determine if two input images belong to the same class or not.
- DeepLab: DeepLab is a family of models for semantic image segmentation that employs atrous convolutions, dilated convolutions, and conditional random fields. It achieves state-of-the-art performance in pixel-level image segmentation tasks and has been used in applications such as autonomous driving, medical image analysis, and scene understanding.
These are just a few examples of the many algorithms and models that have had a significant impact on computer vision. It’s worth noting that the field is rapidly evolving, and researchers are continuously developing new architectures, techniques, and model variants to push the boundaries of what is possible in visual understanding and analysis.
Evaluation Metrics in Computer Vision
Evaluation metrics are crucial in assessing the performance and accuracy of computer vision models. These metrics provide quantitative measures to compare different algorithms and models, aiding in the development and optimization of computer vision systems. Here are some commonly used evaluation metrics in computer vision:
- Accuracy: Accuracy is a fundamental metric that measures the overall correctness of predictions made by a model. It is calculated by dividing the number of correctly classified instances by the total number of instances in a dataset. Accuracy is commonly used in image classification tasks, where the goal is to correctly classify images into different categories.
- Precision and Recall: Precision and recall are important metrics in tasks like object detection and segmentation. Precision represents the proportion of correctly detected instances among all the instances detected by the model. Recall, on the other hand, measures the proportion of correctly detected instances among all the actual instances present in the dataset. These metrics help evaluate the trade-off between accuracy, sensitivity, and the number of false positives and false negatives.
- F1 Score: The F1 score is the harmonic mean of precision and recall. It is a balanced metric that combines both precision and recall into a single value, providing a summary measure of a model’s performance. The F1 score is commonly used when there is an uneven class distribution or when both precision and recall are considered equally important.
- Intersection over Union (IoU): IoU measures the overlap between predicted and ground truth bounding boxes or segmentation masks. It is widely used in tasks like object detection and semantic segmentation. IoU is calculated by dividing the area of overlap between the predicted and ground truth region by the area of union between the two regions. Higher IoU values indicate better object localization and segmentation accuracy.
- Mean Average Precision (mAP): mAP is a popular metric used in object detection tasks. It measures the average precision across multiple detection thresholds, taking into account precision and recall values at different levels of object detection confidence. mAP quantifies the effectiveness of object detection algorithms in terms of both accuracy and the number of false positives.
- Mean Intersection over Union (mIoU): mIoU is a popular metric for evaluating semantic segmentation models. It calculates the average IoU over all the classes in a dataset, providing an overall measure of segmentation accuracy. Higher mIoU values indicate better segmentation performance and effective object boundary localization.
- Receiver Operating Characteristic (ROC) Curve and Area Under the Curve (AUC): ROC curves are used to evaluate and compare binary classification models. They illustrate the performance of a model by plotting the true positive rate against the false positive rate at various classification thresholds. The AUC represents the overall performance of the model and provides a single scalar value to compare different models. Higher AUC values indicate better discrimination ability of the model.
- Mean Error or Euclidean Distance: Mean error or Euclidean distance metrics are used to measure the accuracy of regression models. These metrics calculate the mean distance or difference between predicted and ground truth coordinates or values. They evaluate the model’s ability to estimate continuous variables, such as object pose, depth estimation, or facial landmark localization.
It is important to select the appropriate evaluation metrics that align with the specific task and objectives of the computer vision problem at hand. Different tasks may require different metrics, and the chosen metrics should reflect the priorities and requirements of the application, taking into consideration factors such as class distribution, annotation difficulty, and the desired trade-offs between precision, recall, and accuracy.
Future Directions in Computer Vision
Computer vision continues to evolve rapidly, driven by ongoing research, advancements in machine learning, and the increasing availability of large-scale labeled datasets. The field holds immense potential for further innovation and breakthroughs. Here are some exciting future directions in computer vision:
- Deep Learning Advancements: Deep learning has made significant strides in computer vision, but there is still room for improvement. Future research will likely focus on developing more efficient architectures, reducing the need for large amounts of labeled data, and improving model interpretability. Advancements in areas like self-supervised learning, transfer learning, and multi-modal learning will further enhance the capabilities of computer vision models.
- 3D Vision: While computer vision has primarily focused on 2D image analysis, there is a growing interest in 3D vision. Future research in this area aims to enable machines to understand and interpret the 3D structure of objects and scenes. This includes tasks like 3D object detection, reconstruction, depth estimation, and scene understanding, which have significant implications for applications such as robotics, augmented reality, and autonomous navigation.
- Contextual Understanding: Context plays a vital role in human visual perception, and incorporating contextual information is crucial for advancing computer vision systems. Future directions will focus on developing models that can reason about the relationships and interactions between objects, scenes, and people. This will enable a deeper understanding of visual data and facilitate more complex decision-making processes.
- Robustness and Generalization: Building computer vision models that are robust and generalize well across different scenarios and domains remains a challenge. Future research will aim to develop algorithms and techniques that can handle variations in lighting conditions, viewpoints, occlusions, and other real-world challenges. Adapting computer vision models to unseen or out-of-distribution data will be a key focus as well.
- Explainability and Interpretability: As computer vision models become more complex, there is a growing need for explainability and interpretability. Researchers will strive to develop methods to understand and interpret the decisions made by these models. Explainable AI techniques, such as attention mechanisms, visual explanations, and transparent model architectures, are areas of active research that aim to provide insights into the reasoning processes of computer vision systems.
- Few-shot and One-shot Learning: Training computer vision models with limited labeled data remains a challenge. Future directions will focus on developing techniques that can learn from few or even one labeled example, enabling models to recognize and understand new objects or classes with minimal training data. Few-shot and one-shot learning approaches will facilitate faster adaptation to new tasks and improve the scalability of computer vision systems.
- Ethical and Responsible AI: With the increasing adoption of computer vision technologies, there is a need for ethical and responsible development and deployment. Future research will address concerns related to data privacy, bias, fairness, and the ethical use of computer vision systems. Developing robust frameworks for evaluating and mitigating these issues will be crucial for ensuring the responsible and trustworthy implementation of computer vision technology.
The future of computer vision holds tremendous promise as researchers explore new algorithms, models, and techniques. As the field advances, solutions to existing challenges will emerge, paving the way for transformative applications in healthcare, robotics, autonomous vehicles, entertainment, and beyond. Exciting times lie ahead as computer vision continues to reshape our world and enhance our understanding of visual information.
Conclusion
Computer vision, powered by machine learning, has transformed the way we perceive and interpret visual data. It has progressed from simple image processing algorithms to sophisticated deep learning models capable of understanding and analyzing complex visual scenes. The applications of computer vision are diverse, ranging from healthcare and autonomous vehicles to surveillance, retail, and augmented reality.
As computer vision continues to evolve, future directions in the field will focus on advancements in deep learning techniques, the development of 3D vision capabilities, improved robustness and generalization of models, and the incorporation of contextual understanding. Explainability and interpretability will become essential as models become more complex, and few-shot learning approaches will enable models to adapt to new tasks with minimal training data.
Ethical considerations will also play a significant role in the future of computer vision, ensuring responsible and unbiased implementation of technologies and addressing concerns related to data privacy, fairness, and accountability.
While computer vision has made great strides, there are still challenges to overcome, such as handling variability in visual data, improving object recognition and segmentation, and addressing ethical implications. Addressing these challenges will require a collaborative effort from researchers, engineers, and policymakers.
In conclusion, computer vision is a rapidly progressing field that offers immense potential for innovation and impact. By leveraging machine learning techniques, computer vision enables machines to perceive, understand, and interact with the visual world, transforming industries and augmenting human capabilities. With continued research and advancements, the future of computer vision holds the promise of even more remarkable developments, shaping the way we interact with technology and enhancing our understanding of the visual world.