Introduction
Welcome to the world of machine learning! In this rapidly advancing field, algorithms are designed to learn and make intelligent decisions without explicit programming. One of the key concepts that plays a crucial role in many machine learning algorithms, particularly in computer vision, is convolution.
Convolution is a fundamental operation that is widely used in various domains such as image processing, natural language processing, and signal processing. It is a mathematical operation that combines two functions to produce a third function that represents the way one function modifies the other.
Convolution plays a critical role in machine learning tasks, as it allows us to extract meaningful features from raw data. By applying convolution to input data, we can detect patterns, edges, and textures, which form the basis for further analysis and decision-making in machine learning algorithms.
The purpose of this article is to provide a comprehensive understanding of convolution in machine learning. We will explore the basic concepts and terminologies associated with convolution, delve into how it works in machine learning algorithms, and discuss its applications, advantages, and disadvantages.
Whether you’re new to the field of machine learning or looking to deepen your understanding, this article will serve as a valuable resource.
What is Convolution?
Convolution is a mathematical operation that combines two functions or sets of data to obtain a third function or set of data. It is widely used in various fields, including signal processing, image processing, and machine learning. In the context of machine learning, convolution plays a crucial role in extracting useful features from raw data.
At its core, convolution involves a sliding window or a filter, which is applied to an input signal or image. The filter is a small matrix or kernel that is designed to detect specific patterns or features in the input data. As the filter moves across the input data, it performs element-wise multiplication and summation operations, resulting in a transformed output.
The main idea behind convolution is to scan the input data with the filter, capturing local patterns and aggregating them into a meaningful representation. This process is inspired by how the neurons in the visual cortex of the human brain respond to visual stimuli. Convolution mimics the receptive fields of these neurons, enabling the machine learning models to analyze complex patterns and make intelligent decisions.
In the context of image processing, convolution is commonly used for tasks such as edge detection, blurring, and sharpening. The filter weights or kernel values determine the type of features that are extracted from the input image. For example, a filter designed to detect vertical edges will have positive weights on the left side and negative weights on the right side, allowing it to detect the change in intensity between adjacent pixels.
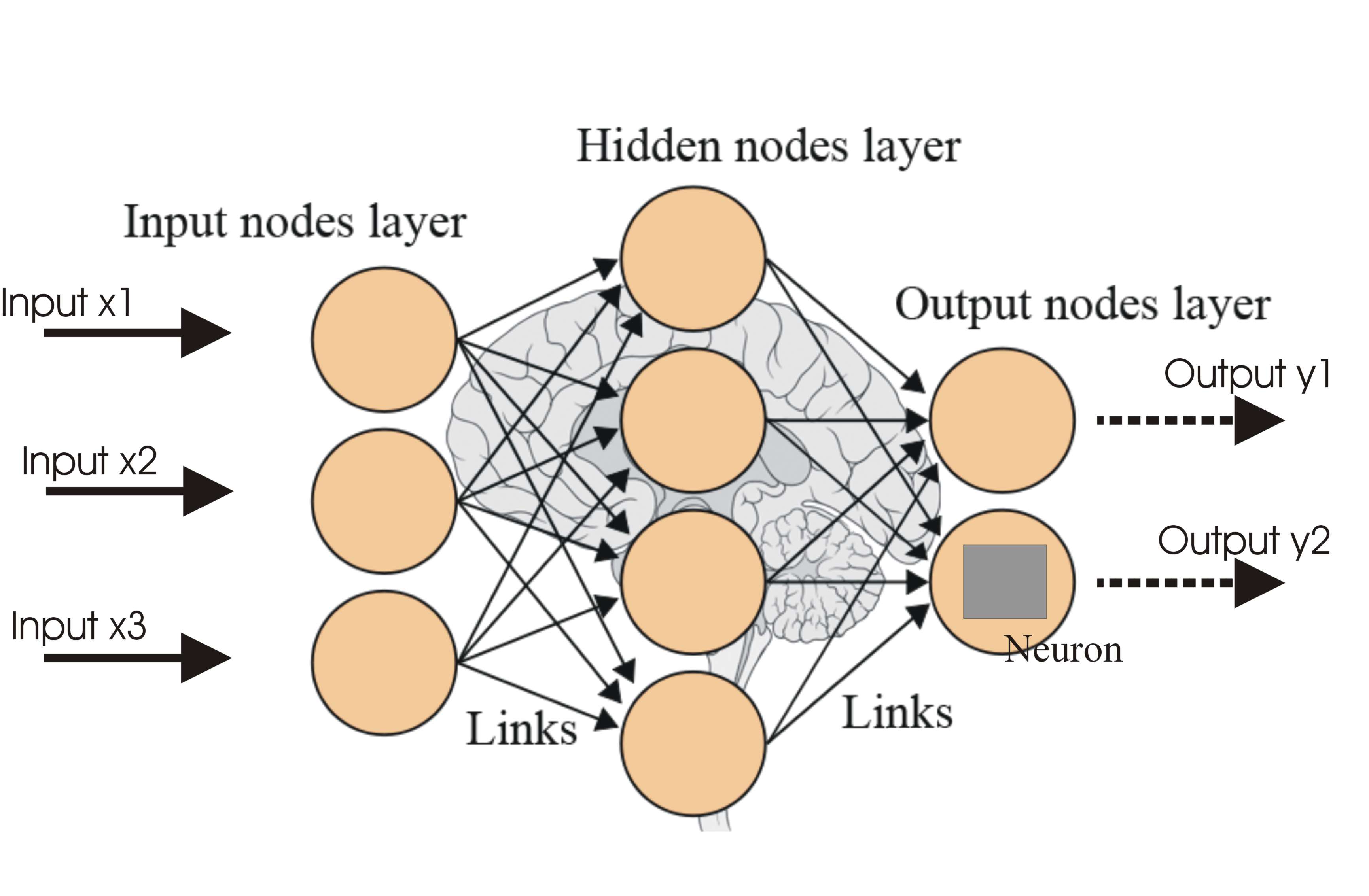
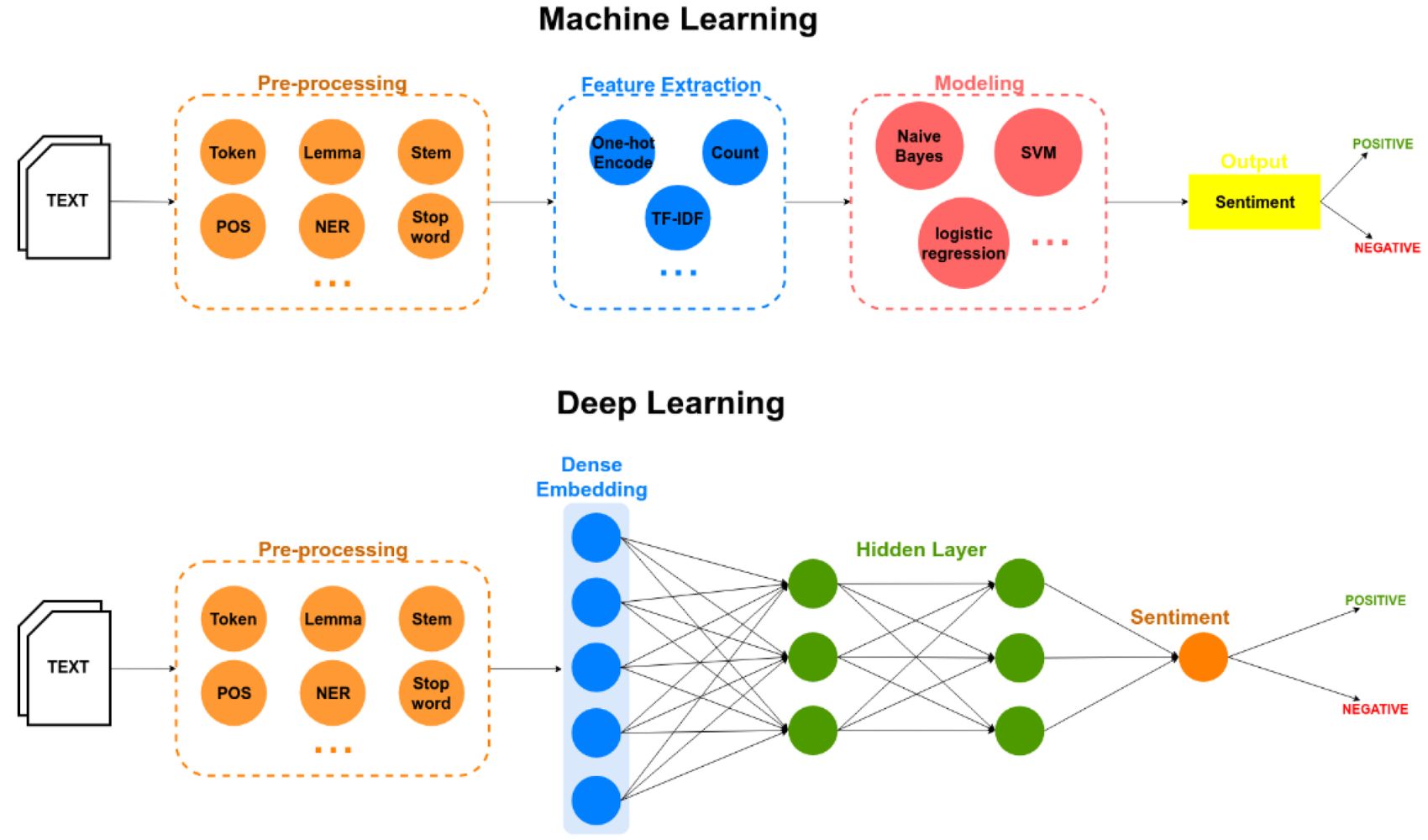
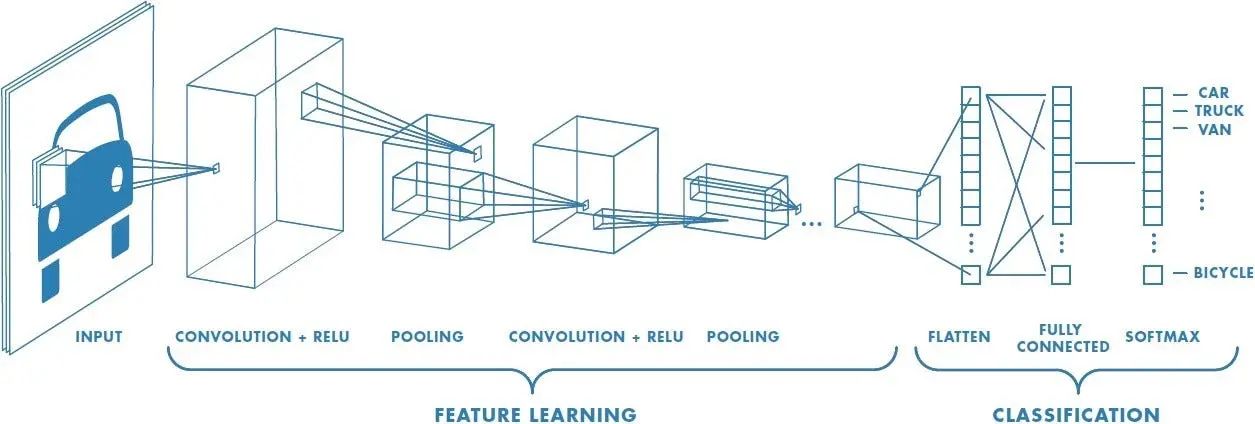
In the field of machine learning, convolution is a key operation in the domain of computer vision. Convolutional Neural Networks (CNNs) leverage the power of convolution to automatically learn and extract relevant features from images. CNNs consist of multiple layers of convolutional and pooling operations, followed by fully connected layers for classification or regression tasks.
By applying convolution to input data, machine learning models can effectively capture local patterns and hierarchies of features, leading to improved accuracy and robustness. Convolution enables the models to generalize well to new, unseen data by focusing on the most informative aspects of the input.
In the next section, we will dive deeper into the key terminologies associated with convolution in machine learning.
Key Terminologies
Before we delve deeper into the workings of convolution in machine learning, let’s familiarize ourselves with some key terminologies:
- Input Signal: The original data or signal that is fed into the convolution operation. It can be in the form of images, time series data, or any other structured or unstructured data.
- Filter or Kernel: A small matrix or set of weights that is applied to the input signal. The filter determines the features or patterns that will be extracted from the input. It is commonly represented as a matrix of dimensions (N x N), where N is an odd number.
- Stride: The stride refers to the number of pixels or units by which the filter shifts or moves across the input signal at each step. A larger stride means the filter moves more quickly, resulting in a smaller output size, while a smaller stride leads to a slower movement and a larger output size.
- Padding: Padding is the process of adding extra pixels or values around the borders of the input signal. It is done to preserve the spatial dimensions of the input and ensure that the size of the output matches the original input size. Common padding techniques include zero padding and reflection padding.
- Feature Map: The output of the convolutional operation, also known as the feature map, represents the extracted features or patterns from the input signal. It is a transformed version of the input, where each pixel or unit corresponds to a specific feature detected by the filter.
- Activation Function: The activation function introduces non-linearity into the convolutional operation. Common activation functions include ReLU (Rectified Linear Unit), sigmoid, and tanh. The activation function introduces non-linear relationships between features, allowing the model to learn more complex patterns.
- Pooling: Pooling is an operation commonly performed after convolution to reduce the spatial dimensions of the feature maps. Pooling helps to extract the most important features while reducing computational complexity. Max pooling and average pooling are popular pooling techniques.
- Output Layer: The final layer of a convolutional neural network (CNN) that produces the desired output, such as a classification label or a regression value. The output layer is typically connected to one or more fully connected layers, which process the extracted features and make predictions.
These terminology definitions will be essential as we journey further into understanding the mechanics and applications of convolution in machine learning.
How Convolution Works in Machine Learning
Convolution plays a vital role in machine learning algorithms, especially in the domain of computer vision. In this section, we will explore how convolution works in the context of machine learning.
Convolution in machine learning involves the application of filters or kernels to the input data. Each filter is designed to detect specific patterns or features in the data. The convolution operation consists of sliding the filter across the input data and computing the dot product between the filter weights and the corresponding input values at each position. This process creates a transformed feature map that represents the presence or absence of specific features in the input.
One important aspect of convolution in machine learning is the concept of parameter sharing. In traditional neural networks, each neuron has its own set of weights for connections with previous layers. In contrast, in convolutional neural networks (CNNs), the same set of weights is shared across different spatial locations of the input. This greatly reduces the number of parameters and allows the model to effectively learn local patterns regardless of their location within the input.
The convolution operation also takes into account the stride and padding parameters. The stride determines the step size at which the filter moves across the input. A larger stride results in a smaller output size, while a smaller stride preserves more spatial information but increases computational complexity. Padding is used to maintain the spatial dimensions of the input and ensure that the output size matches the original input size.
In addition to convolution, CNNs often include other layers such as pooling and activation functions. Pooling layers reduce the spatial dimensions of the feature maps, helping to extract the most relevant features while reducing computational complexity. Common pooling techniques include max pooling and average pooling.
Activation functions introduce non-linearity into the convolutional operation, allowing the model to learn complex patterns and relationships between features. The most commonly used activation function in CNNs is the Rectified Linear Unit (ReLU), which sets all negative values to zero and keeps positive values unchanged.
By applying convolution to the input data and incorporating pooling and activation functions, CNNs can effectively learn and extract meaningful features from complex data such as images. These features are then used for tasks such as classification, object detection, and image segmentation.
Convolutional architectures have revolutionized the field of computer vision and have achieved state-of-the-art performance in many tasks. By using convolution as a fundamental building block, machine learning models can learn hierarchical representations of data and make accurate predictions based on learned features.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a specific type of neural network architecture that are primarily used for computer vision tasks. CNNs leverage the power of convolution to automatically learn and extract relevant features from images, making them highly effective in tasks such as image classification, object detection, and image segmentation.
CNNs are designed to mimic the functioning of neural connections in the visual cortex of the human brain. They consist of multiple layers, including convolutional, pooling, and fully connected layers. The convolutional layers utilize filters or kernels to perform convolution operations, extracting local patterns and features from the input images.
One of the key advantages of CNNs is the utilization of parameter sharing. By sharing the same set of weights across different spatial locations of the input, CNNs are able to effectively learn and detect features regardless of their location within the image. This drastically reduces the number of parameters involved and allows the network to efficiently generalize from one part of the image to another.
Pooling layers are often inserted between convolutional layers in CNNs. Pooling is used to downsample the feature maps obtained from convolution, reducing the spatial dimensions while retaining the most salient information. Max pooling and average pooling are commonly used pooling techniques in CNNs.
Along with convolution and pooling, activation functions play a crucial role in CNNs. Activation functions introduce non-linear relationships between features, allowing the model to learn complex patterns. The Rectified Linear Unit (ReLU) activation function is typically used in CNNs, as it is computationally efficient and has shown to be effective in deep learning models.
Another important component of CNNs is the fully connected layer, which is typically placed at the end of the network. The fully connected layer takes the extracted features from the convolutional layers and makes predictions based on the learned representations. The number of neurons in the fully connected layer depends on the specific task, such as the number of output classes in image classification.
CNNs have achieved remarkable success in various computer vision tasks, outperforming traditional machine learning algorithms. They have demonstrated state-of-the-art performance in tasks such as image recognition, object detection, facial recognition, and image generation. Their ability to automatically learn hierarchical representations of data through convolutional operations makes them highly effective in handling visual data.
In the next section, we will explore some of the applications of convolution in machine learning.
Applications of Convolution in Machine Learning
Convolution is a versatile operation that finds applications in various domains of machine learning. Its ability to extract meaningful features from input data makes it a powerful tool for solving complex problems. Let’s explore some of the applications of convolution in machine learning:
- Computer Vision: Convolution is extensively used in computer vision tasks such as image classification, object detection, image segmentation, and image generation. Convolutional Neural Networks (CNNs) leverage convolution to automatically learn and extract features from images, enabling accurate and efficient analysis of visual data.
- Natural Language Processing (NLP): In NLP, convolution is employed for tasks such as text classification, sentiment analysis, and text generation. Convolutional models can capture local patterns in textual data and leverage them for making predictions or generating new text sequences.
- Speech Recognition: Convolution has shown great potential in automatic speech recognition tasks. It can be used to analyze speech signals by extracting relevant speech features and building models that can recognize and transcribe spoken words.
- Signal Processing: Convolution is a fundamental operation in signal processing applications. It is used for tasks such as filtering, noise reduction, audio and video compression, and audio enhancement. Convolution allows for the analysis and manipulation of multi-dimensional signals.
- Medical Imaging: Convolution is applied in medical imaging tasks to extract meaningful features from medical images such as X-rays, CT scans, and MRIs. It aids in tasks like tumor detection, disease diagnosis, and medical image segmentation.
- Autonomous Vehicles: In the field of autonomous vehicles, convolution plays a crucial role in computer vision algorithms used for object detection, lane detection, and obstacle avoidance. Convolution enables real-time analysis of sensor data and helps vehicles make informed decisions.
- Video Analysis: Convolution is deployed in the analysis of video data, where it helps in tasks like action recognition, video summarization, and video anomaly detection. By analyzing the spatial and temporal features of video frames, convolutional models can understand and interpret complex dynamic scenes.
These are just a few examples of the wide range of applications where convolution is employed in machine learning. Convolution enables models to efficiently extract features, learn meaningful representations from raw data, and make accurate predictions, revolutionizing various fields with its ability to handle complex and high-dimensional data.
Advantages and Disadvantages of Convolution
Convolution has become a key component in many machine learning algorithms, providing several advantages that make it a powerful tool for extracting features from data. However, it also has certain limitations. Let’s explore the advantages and disadvantages of convolution:
Advantages:
- Feature Extraction: Convolution allows for effective feature extraction from raw data. By applying filters, convolution can detect patterns, edges, textures, and other relevant features in the input data. This ability to extract meaningful features is essential for many machine learning tasks.
- Parameter Sharing: In convolutional neural networks (CNNs), parameter sharing greatly reduces the number of parameters and enables efficient learning. By sharing the weights of filters across the input, CNNs can generalize well to different locations within the data, leading to improved performance with fewer parameters.
- Translation Invariance: Convolution captures local patterns irrespective of their location within the data. This translation invariance property makes convolution robust to variations in scale, orientation, and position, allowing models to learn features that are truly representative of the underlying patterns.
- Reduced Sensitivity to Noise: Convolution helps mitigate the impact of noise in data. By filtering out noise through convolutional operations, models can focus on the essential features, making them more resilient to noisy input and resulting in more accurate predictions.
- Efficient Computation: Convolution operations can be highly computationally efficient, particularly when implemented using specialized hardware like graphics processing units (GPUs). The local nature of convolution allows for parallelization, leading to faster training and inference times.
Disadvantages:
- Limited Contextual Understanding: Convolution operates on local neighborhoods of data and may have limited contextual understanding. It does not take into account dependencies between distant features, which may be essential in some complex tasks. Additional layers and techniques, such as recurrent connections or self-attention, can address this limitation.
- Fixed Filter Size: Convolution relies on fixed-sized filters or kernels. While this allows for efficient computation, it can restrict the ability to detect features at different scales or extract features that span larger contexts. Pooling and multiple layers can partially address this limitation.
- Loss of Spatial Information: Using pooling and strided convolutions can lead to a loss of spatial information. This can pose challenges when fine-grained details or precise spatial relationships are important for the task at hand. Techniques like skip connections and up-sampling can help mitigate this issue.
- Input Size Constraints: Convolutional neural networks typically require fixed input sizes due to the use of fully connected layers. This can limit the flexibility of the models when working with images or sequences of varying sizes. Techniques like resize operations or padding can be used to handle different input sizes.
Despite these limitations, the advantages of convolution make it an indispensable tool in various machine learning applications, particularly in computer vision and signal processing tasks. With ongoing research and advancements, convolutional models continue to evolve and address some of these challenges, further expanding their effectiveness in handling complex data.
Conclusion
Convolution is a fundamental operation in machine learning that has revolutionized the field of computer vision and beyond. It allows models to extract informative features from input data, enabling tasks such as image classification, object detection, and natural language processing. Convolutional Neural Networks (CNNs) leverage the power of convolution to automatically learn and analyze complex patterns in data, leading to state-of-the-art performance in various domains.
Throughout this article, we have explored the concept of convolution, its key terminologies, and how it works in machine learning algorithms. We have also discussed the advantages, such as efficient feature extraction and robustness to noise, as well as the limitations, such as limited contextual understanding and fixed filter sizes, of convolution. Despite these limitations, convolution continues to play a critical role in extracting meaningful representations from data and has paved the way for advancements in computer vision, speech recognition, and other fields.
As the machine learning field continues to evolve, convolution remains a powerful technique for analyzing and understanding complex data. Ongoing research is addressing the limitations of convolution, such as incorporating contextual information and handling varying input sizes, to further enhance its capabilities.
In conclusion, convolution is a cornerstone operation in machine learning algorithms, providing the foundation for analyzing and extracting meaningful features from data. Its applications are extensive, ranging from computer vision to natural language processing to signal processing. By understanding the principles and applications of convolution, we can harness its potential to develop more accurate and robust machine learning models that can solve complex real-world problems.


![7 Best AI Video Upscaling Software in 2024 [Free & Paid]](https://robots.net/wp-content/uploads/2023/12/Guy-in-headphones-editing-video-with-astronauts-for-space-blog-in-professional-program-300x169.jpeg)