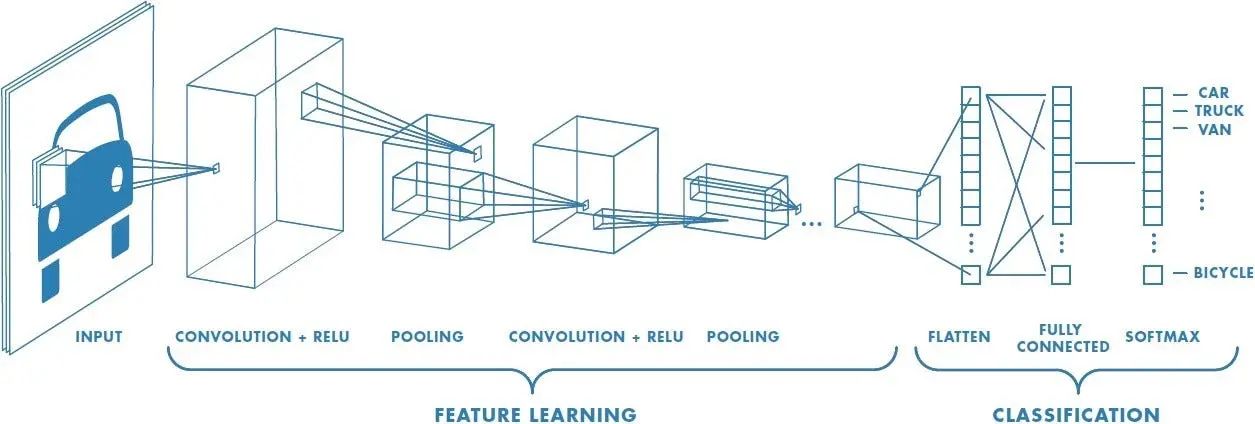
Introduction
When it comes to machine learning, there are various concepts and techniques that play a crucial role in the development of models. One such concept is the stride, which is an important parameter used in many machine learning algorithms, particularly in convolutional neural networks (CNNs).
The stride refers to the number of steps a filter moves horizontally or vertically across an input volume. It determines how the filter moves through the data, impacting the size of the output volume and the computational efficiency of the model. Understanding the stride and its role in machine learning is essential for building efficient and accurate models.
In simple terms, a larger stride means the filter moves more frequently, resulting in a smaller output volume and faster computation. Conversely, a smaller stride means the filter moves less frequently, giving rise to a larger output volume and slower computation. The choice of stride depends on the specific task at hand and the characteristics of the data being processed.
While the stride might seem like a small and technical parameter, it can have a significant impact on the performance and effectiveness of a machine learning model. By choosing the appropriate stride value, researchers can control the trade-off between computational efficiency and the model’s ability to capture intricate patterns in the data.
In the following sections, we will delve deeper into the importance of stride in machine learning, its specific applications in convolutional neural networks, the impact of stride on model performance, and common values used for stride. Additionally, we will explore how researchers can experiment with stride to optimize their machine learning models.
Definition of Stride
In machine learning, stride refers to the number of steps a filter takes while moving across an input volume or feature map. It determines the spatial displacement of the filter as it convolves or scans over the data. The stride value dictates how the filter moves both horizontally and vertically, influencing the size of the output volume.
To better understand the concept of stride, let’s consider a simple example. Imagine a two-dimensional input image with a filter of size 3×3. If the stride is set to 1, the filter moves one pixel at a time across both the width and height of the image. On the other hand, if the stride is set to 2, the filter moves two pixels at a time.
The choice of stride has a direct impact on the output volume size. A larger stride value will result in a smaller output volume, as the filter covers less ground with each step. Conversely, a smaller stride value will produce a larger output volume, as the filter overlaps more areas and captures more information.
Stride is a critical parameter in convolutional neural networks (CNNs), a popular architecture utilized in image and video processing tasks. In these networks, the stride is used in the pooling and convolutional layers to downsample the input and reduce the dimensionality of the data. This downsampling process helps to extract and preserve the most relevant features while reducing computational complexity.
The use of stride allows researchers to control the balance between preserving fine-grained detail and reducing the computational load. A smaller stride value allows for more detailed feature extraction, but comes at the cost of increased memory and computation. Conversely, a larger stride value sacrifices some detail but accelerates the processing time and reduces memory requirements.
Overall, the stride is a fundamental component of machine learning algorithms, particularly in the field of computer vision. It plays a crucial role in determining the spatial resolution of the output volume and influencing the overall performance and efficiency of the model.
Importance of Stride in Machine Learning
The stride parameter is of paramount importance in machine learning, as it directly affects the performance and efficiency of models. Let’s explore why stride is crucial in various aspects of machine learning.
First and foremost, stride influences the size of the output volume or feature map. By controlling the stride value, researchers can adjust the spatial resolution of the output data. A smaller stride value preserves more spatial information and results in a larger output. This can be beneficial when fine-grained details are important, such as in image recognition tasks. On the other hand, a larger stride value leads to a smaller output volume, which can reduce the computational complexity of the model.
Furthermore, the choice of stride impacts the receptive field of the model. The receptive field refers to the region of the input volume that a neuron’s output is dependent upon. A smaller stride covers a smaller area of the input, resulting in a more localized receptive field. This can be advantageous when the model needs to capture precise patterns or small details. Conversely, a larger stride leads to a larger receptive field, allowing the model to capture more global context and spatial relationships.
Another important aspect is computational efficiency. Since stride affects the number of operations required to process the data, it plays a key role in model efficiency. A larger stride reduces the number of computations, thereby speeding up the processing time. This is particularly beneficial in real-time applications where fast inference is essential. On the other hand, a smaller stride increases computational complexity, but can improve model accuracy by capturing more detailed features.
Moreover, the stride parameter is closely related to the downsampling process in convolutional neural networks (CNNs). Stride is used in pooling layers to downsample the feature maps, reducing the dimensionality of the data. This downsampling not only helps in reducing the memory footprint of the model but also aids in suppressing irrelevant or redundant information. By adjusting the stride value, researchers can fine-tune the trade-off between preserving important features and reducing the computational load.
In summary, the importance of the stride parameter in machine learning cannot be overstated. It determines the spatial resolution, receptive field, computational efficiency, and downsampling process of models. The appropriate choice of stride allows researchers to strike a balance between capturing detailed features and optimizing the performance and efficiency of their models.
How Stride is Used in Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are designed to process and analyze visual data, such as images or videos, and have proven to be highly effective in many computer vision tasks. Stride is a crucial parameter used in CNNs to control the movement of filters across the input data. Let’s explore how stride is used in CNNs in more detail.
In CNNs, one of the primary operations is the convolution operation. During this operation, filters, also known as kernels or feature detectors, are convolved with the input data to extract relevant features. The stride determines the step size of the filter as it moves across the input.
The stride value has a direct impact on the size of the output feature map. With a stride of 1, the filter moves one step at a time, resulting in a feature map with the same spatial resolution as the input. However, when a larger stride value, such as 2 or more, is used, the filter skips pixels and covers larger areas with each movement. This leads to a downsampled output feature map with reduced spatial dimensions.
In CNNs, the use of stride serves multiple purposes. First and foremost, it aids in downsampling the data, which is essential for reducing the computational and memory burden of the model. By reducing the spatial dimensions, the number of parameters and computations needed for subsequent layers is significantly reduced, making the model more computationally efficient.
Additionally, stride contributes to the translation invariance property of CNNs. Translation invariance implies that the neural network can recognize and extract the same features regardless of their location in the input data. By using a larger stride, the network becomes less sensitive to small shifts in the input, making it more robust to translation variations.
Stride also influences the receptive field of the network. A larger stride covers a larger area of the input, leading to a larger receptive field. This allows the network to capture more global information and contextual relationships between features. On the other hand, a smaller stride results in a smaller receptive field, focusing on local details and fine-grained features.
It is worth noting that stride is not limited to convolutional layers alone. It is also commonly used in pooling layers, where it plays a crucial role in downsampling the feature maps. Pooling operations, such as max pooling or average pooling, help reduce the spatial dimensionality further, offering the network a broader view of the data with fewer parameters.
In summary, stride is a key parameter in Convolutional Neural Networks that controls the movement of filters and influences the spatial resolution, receptive field, and downsampling process of the model. By appropriately selecting the stride value, researchers can strike a balance between computational efficiency, translation invariance, and the ability to capture both local and global features in the input data.
Impact of Stride on Model Performance
The choice of stride in machine learning models, particularly in convolutional neural networks (CNNs), can have a significant impact on the performance and effectiveness of the model. Let’s explore the various ways in which the stride parameter influences model performance.
Firstly, the stride value affects the spatial resolution of the output feature maps. A smaller stride value captures more fine-grained details and produces output feature maps with higher resolution. This can be beneficial in tasks where precise localization of features is important, such as object detection or segmentation. On the other hand, a larger stride value reduces the spatial dimensions of the output feature maps, sacrificing some detail but increasing computational efficiency.
The choice of stride also impacts the receptive field of the model. A smaller stride leads to a smaller receptive field, enabling the network to focus on local details and capturing fine-grained features. This can be advantageous in scenarios where local patterns and specific spatial relationships are crucial for accurate predictions. Conversely, a larger stride results in a larger receptive field, allowing the model to capture more global context and spatial relationships. This is beneficial when broader context and overall scene understanding are important.
Another important consideration is the computational efficiency of the model. The stride parameter directly affects the number of operations required to process the data. A larger stride reduces the number of computations, resulting in faster processing times and reduced memory requirements. This is particularly valuable in real-time applications or resource-constrained environments. However, a larger stride may also sacrifice some level of model accuracy, as it reduces the amount of information processed.
The choice of stride also depends on the characteristics of the input data and the specific task at hand. In some cases, a smaller stride may be necessary to capture intricate patterns or fine details in the data. For example, in medical image analysis, where subtle anomalies need to be detected, a smaller stride helps in preserving the necessary level of detail. However, in other cases, a larger stride may be preferable to enable faster processing and generalization to more diverse inputs.
Furthermore, the impact of stride extends beyond individual layers. It can influence the architecture and connectivity patterns of the entire model. The stride value in one layer affects the subsequent layer’s input size and receptive field, influencing the flow of information and the ability to capture meaningful patterns throughout the network. Careful consideration of stride values across multiple layers is necessary to ensure effective information flow and feature extraction.
In summary, the stride parameter plays a crucial role in the performance of machine learning models. It determines the spatial resolution, receptive field, and computational efficiency of the model. By choosing the appropriate stride value, researchers can strike a balance between capturing detailed features, optimizing computational resources, and achieving high model performance for specific tasks and datasets.
Common Values for Stride
The choice of stride value in machine learning models is a crucial decision that can significantly impact the model’s performance and behavior. While the optimal stride value depends on the specific task and dataset, there are some common values that are frequently used in practice. Let’s explore these common values for stride and their implications.
Firstly, a stride value of 1 is widely used in many convolutional neural network (CNN) architectures. With a stride of 1, the filter moves one step at a time across the input, resulting in output feature maps with the same spatial resolution as the input. This allows for fine-grained spatial information to be preserved, making it suitable for tasks where precise localization of features is important, such as object detection or semantic segmentation.
On the other hand, a stride value of 2 is commonly used for downsampling the data and reducing computational complexity. With a stride of 2, the filter covers larger areas and overlaps less, resulting in output feature maps with reduced spatial dimensions. This downsampling helps to decrease the memory footprint and computational load of the model, making it more efficient for real-time applications or when dealing with large input volumes.
Furthermore, a stride value of 3 or more can be used for even greater downsampling, sacrificing more spatial detail for enhanced computational efficiency. This is particularly useful when working with high-resolution images or when a significant reduction in the spatial dimensions is desired. However, it is important to note that using larger stride values may lead to a loss of fine-grained information and can impact the model’s ability to capture small, localized patterns.
In some cases, different stride values can be used within the same model, specifically in multi-scale or pyramid architectures. These architectures involve parallel branches or layers with different stride values, allowing for capturing features at multiple scales and resolutions. This approach enables the model to have a broader receptive field and a more comprehensive understanding of the data, incorporating both local and global information.
It is crucial to experiment with different stride values and evaluate their impact on the model’s performance for a specific task and dataset. Factors such as the size and complexity of the input data, the desired level of detail, and the computational constraints should be considered when determining the appropriate stride value.
In summary, while there are common values for stride in machine learning models, the choice of stride ultimately depends on the specific requirements and constraints of the task at hand. Experimenting with different stride values and considering the trade-offs between spatial resolution, computational efficiency, and feature capture is essential for achieving optimal model performance.
Experimenting with Stride in Machine Learning Models
When designing and training machine learning models, it is essential to experiment with different values for the stride parameter. By systematically exploring and evaluating various stride values, researchers can gain insights into the impact of stride on model performance and make informed decisions. Let’s delve into the process of experimenting with stride in machine learning models.
Firstly, it is important to establish a baseline performance by training the model with a default or commonly used stride value. This allows for comparison and serves as a starting point for further experiments. Once the baseline is established, researchers can gradually modify the stride value and assess its impact on various performance metrics.
One key consideration is understanding the trade-offs associated with different stride values. A smaller stride typically preserves more spatial detail but increases computational complexity. Researchers can analyze the model’s performance in terms of accuracy, speed, memory usage, and resource requirements for different stride values. This helps in finding the optimal balance between model performance and computational efficiency.
Researchers should also assess the effect of stride on model generalizability. It’s important to evaluate performance across different datasets or validation sets to ensure that the chosen stride value achieves consistent results. This analysis helps in determining if the model is overfitting or underfitting to the training data based on the chosen stride value.
Experimenting with stride can also involve analyzing the impact on model training dynamics. Researchers may observe changes in convergence speed, stability, or the ability to find an optimal solution. Monitoring the learning curves and loss functions during training helps in understanding the behavior of the model with different stride values.
Furthermore, it can be beneficial to visualize the feature maps at different layers of the model with various stride values. This helps in understanding how the chosen stride affects the model’s ability to capture and represent different levels of abstraction. Researchers can identify whether important features are preserved or lost due to a specific stride value.
Machine learning models often require tuning multiple hyperparameters simultaneously. When experimenting with stride, it is essential to consider the interactions with other hyperparameters such as learning rate, batch size, or network architecture. Conducting a systematic hyperparameter search helps in identifying the optimal combination of hyperparameters, including stride, to achieve the best overall model performance.
In summary, experimenting with stride in machine learning models plays a vital role in understanding its impact on model performance, computational efficiency, generalization capability, and training dynamics. It involves systematically evaluating different stride values and analyzing various metrics to make informed decisions about the optimal stride value for a particular task and dataset.
Conclusion
The stride parameter is a fundamental component in machine learning models, particularly in convolutional neural networks (CNNs), that determines the movement and behavior of filters across input data. Throughout this article, we have explored the definition of stride, its importance in machine learning, its specific use in CNNs, its impact on model performance, common values used for stride, and the process of experimenting with stride in machine learning models.
The stride parameter plays a critical role in controlling the spatial resolution, receptive field, computational efficiency, and downsampling process of models. By carefully choosing the stride value, researchers can optimize the trade-off between capturing detailed features and reducing computational complexity, based on specific tasks, datasets, and resource constraints.
Understanding the impact of stride on model performance is crucial for building efficient and accurate machine learning models. Different stride values can significantly influence the spatial resolution, generalization capability, and training dynamics of a model. Experimentation and evaluation of various stride values allow researchers to make informed decisions and find the best settings for their specific machine learning task.
By systematically exploring the impact of stride, researchers can gain insights into model behavior, assess performance metrics, evaluate trade-offs, and fine-tune hyperparameters for optimal model performance. The ability to analyze and experiment with stride is essential for advancing the field of machine learning, particularly in computer vision and other areas where spatial information is critical.
In conclusion, the stride parameter is a powerful tool that enables researchers to control the movement and behavior of filters in machine learning models. Its impact on the model’s performance, efficiency, and ability to capture important features should be carefully considered and experimented with for each specific task and dataset. The stride parameter provides a valuable means to balance computational efficiency with feature extraction, ultimately leading to the development of more accurate and efficient machine learning models.