Introduction
Machine learning has emerged as one of the most fascinating and popular fields in the realm of technology and data science. It is a branch of artificial intelligence that focuses on the development of algorithms and statistical models that enable computers to learn from and make predictions or decisions based on data. By analyzing vast amounts of data and patterns in real-time, machine learning enables computers to improve their performance and accuracy over time without being explicitly programmed.
In recent years, machine learning has found its application in various industries and domains, revolutionizing the way we interact with technology and solving complex problems that were once considered impossible. From digital personal assistants to self-driving cars, machine learning has become an integral part of our daily lives.
This article explores some notable examples of machine learning and their practical applications in different fields. By showcasing these examples, we can gain a deeper understanding of how machine learning is impacting various industries and paving the way for new possibilities.
Definition of Machine Learning
Machine learning is a subset of artificial intelligence that focuses on the development of algorithms and models that enable computers to learn from and make predictions or decisions based on data, without being explicitly programmed. It relies on the concept of pattern recognition and statistical analysis to learn and improve from experience.
At its core, machine learning involves feeding a computer system with historical data and allowing it to learn from that data to make accurate predictions or decisions in the future. The algorithms used in machine learning extract meaningful patterns and relationships from the data, and these patterns are then used to make predictions or take actions.
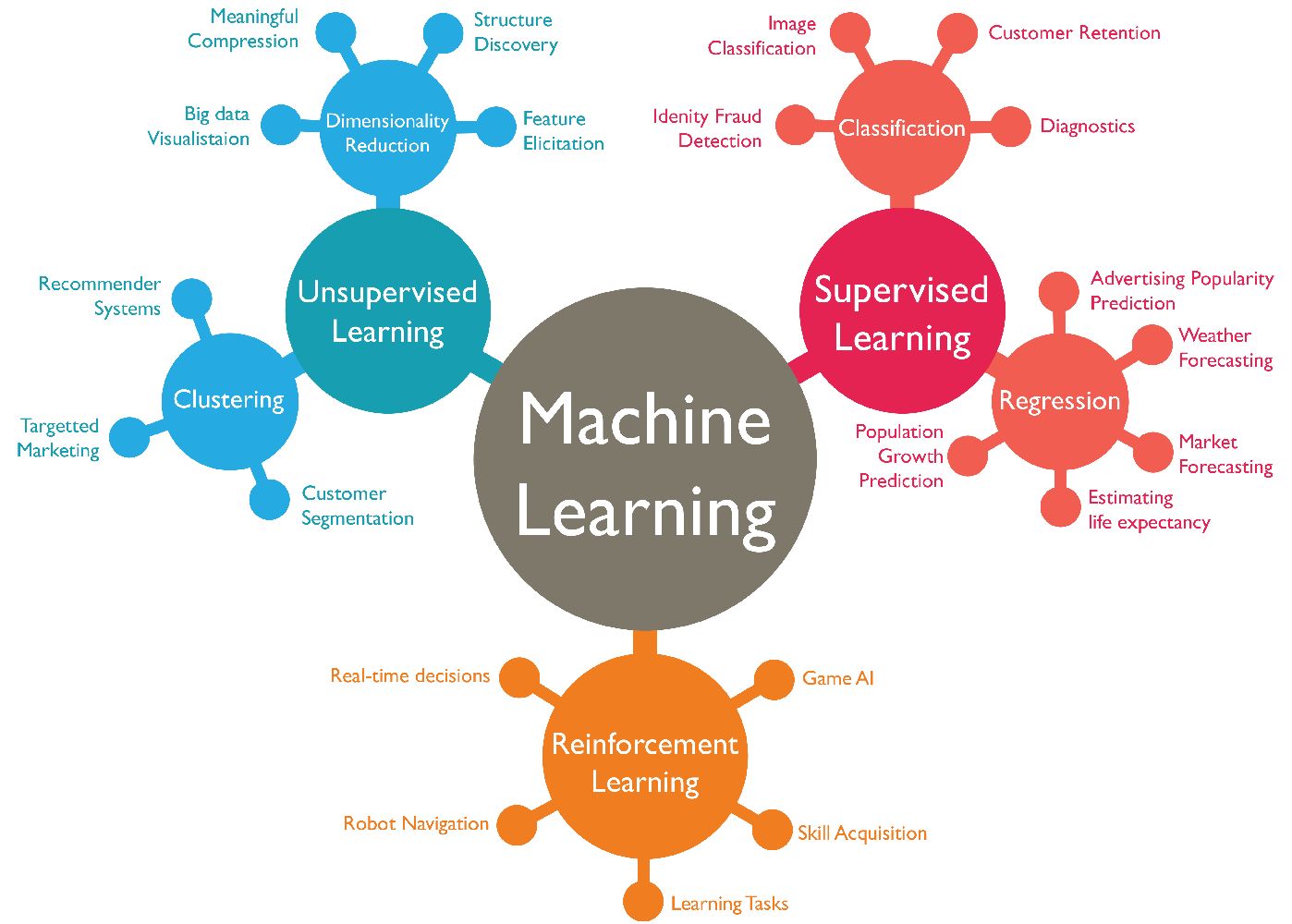
There are three main types of machine learning:
- Supervised Learning: In supervised learning, the algorithm is trained on a labeled dataset, where the input data is already categorized or has a known outcome. The algorithm learns the relationship between the input variables and the corresponding output or label, enabling it to make accurate predictions on new, unseen data. Classification and regression problems are common examples of supervised learning.
- Unsupervised Learning: In unsupervised learning, the algorithm is given an unlabeled dataset and tasked with finding patterns or structures within the data. Unlike supervised learning, there is no known output or label for the algorithm to learn from. Unsupervised learning techniques are used for clustering, anomaly detection, and dimensionality reduction.
- Reinforcement Learning: Reinforcement learning involves an agent interacting with an environment and learning to take actions that maximize a reward or minimize a penalty. The agent learns through trial and error, receiving feedback in the form of rewards or punishments in response to its actions. Reinforcement learning is used in autonomous systems, gaming, and robotics.
Machine learning techniques are not limited to these three types and can be further categorized into subfields such as natural language processing, computer vision, and more. These techniques are continuously evolving, driven by advancements in computing power and the availability of vast amounts of data.
By harnessing the power of machine learning, organizations can gain valuable insights from data, automate processes, improve decision-making, and develop innovative solutions to complex problems. Machine learning has the potential to transform industries and society as a whole, making it a highly sought-after skill in the fields of technology and data science.
Supervised Learning
Supervised learning is a type of machine learning where the algorithm is trained on a labeled dataset, where the input data is already categorized or has a known outcome. The goal of supervised learning is to learn the relationship between the input variables and the corresponding output or label, enabling the algorithm to make accurate predictions on new, unseen data.
There are two main types of supervised learning: classification and regression.
- Classification: Classification is the task of predicting a discrete class or category for a given input. For example, in email spam detection, the algorithm is trained on a dataset of emails labeled as spam or not spam, and it learns to classify new emails into the appropriate category. Popular classification algorithms include logistic regression, decision trees, and support vector machines.
- Regression: Regression, on the other hand, involves predicting a continuous or numerical value based on input variables. For instance, in predicting housing prices, the algorithm is trained on a dataset with features like the number of bedrooms, square footage, and location, and it learns to predict the price of a house. Linear regression, random forests, and neural networks are commonly used regression algorithms.
Supervised learning algorithms learn from the provided labeled data by finding patterns and relationships between the input features and the output labels. These algorithms use mathematical techniques and optimization algorithms to find the best model that fits the data and maximizes prediction accuracy.
Applications of supervised learning are vast and found in various industries. In healthcare, supervised learning algorithms can be used to predict diseases based on patient symptoms and medical records, aiding in early diagnosis and treatment planning. In finance, these algorithms can be used for credit scoring, fraud detection, and stock market prediction. In marketing, supervised learning is used for customer segmentation and targeted advertising.
Although supervised learning requires labeled data for training, labeled datasets can sometimes be difficult and time-consuming to acquire. Additionally, the accuracy of supervised learning models heavily depends on the quality and representativeness of the labeled training data. However, with the availability of large datasets and advancements in algorithms, supervised learning has become a powerful tool for making accurate predictions and driving innovation in various domains.
Unsupervised Learning
Unsupervised learning is a type of machine learning where the algorithm is given an unlabeled dataset and tasked with finding patterns or structures within the data. Unlike supervised learning, there is no known output or label for the algorithm to learn from. Instead, the algorithm aims to uncover hidden relationships and groupings in the data without any explicit guidance.
One of the primary goals of unsupervised learning is to discover clusters. Clustering algorithms group similar data points together based on their inherent characteristics or proximity. This can be valuable for segmenting customers into distinct groups for targeted marketing campaigns or for identifying patterns in large datasets.
Anomaly detection is another application of unsupervised learning. By analyzing the normal patterns within a dataset, unsupervised learning algorithms can identify unusual or anomalous data points. This is useful in fraud detection, network intrusion detection, or identifying faulty equipment in manufacturing processes.
Dimensionality reduction is also a popular use case of unsupervised learning. In many datasets, there are often redundant or irrelevant features that can negatively impact the performance of machine learning models. Unsupervised learning algorithms can reduce the dimensionality of the dataset by mapping it to a lower-dimensional space while preserving relevant information. Principle Component Analysis (PCA) and t-SNE are commonly used techniques for dimensionality reduction.
One of the main challenges in unsupervised learning is evaluating the performance of the algorithm. Without labeled data to compare the results against, it can be challenging to measure the accuracy or quality of the clustering or dimensionality reduction. Evaluation methods such as silhouette score or elbow method are often employed to assess the effectiveness of unsupervised learning algorithms.
Unsupervised learning algorithms have a wide range of applications across industries. In finance, they can be used to detect anomalies in credit card transactions or identify suspicious patterns in financial data. In healthcare, unsupervised learning can help in patient segmentation and pattern detection for disease diagnosis and treatment planning. In recommendation systems, unsupervised learning algorithms can be employed to group similar items or users together to provide personalized recommendations.
Overall, unsupervised learning plays a crucial role in data exploration and uncovering valuable insights in unlabeled datasets. It provides a powerful tool for pattern discovery, data visualization, and data preprocessing for further analysis.
Reinforcement Learning
Reinforcement learning is a type of machine learning that involves an agent interacting with an environment and learning to take actions that maximize a reward or minimize a penalty. It emulates the process of learning through trial and error, similar to how humans learn from their experiences.
In reinforcement learning, the agent receives feedback from the environment in the form of rewards or punishments based on its actions. The goal of the agent is to learn a policy, which is a set of rules that guide its decision-making process, in order to achieve the highest cumulative reward over time.
One of the key concepts in reinforcement learning is the notion of the “reward signal.” The agent’s actions are influenced by the potential rewards it can receive from the environment. By associating specific actions with positive or negative rewards, the agent can learn which actions lead to desirable outcomes.
Reinforcement learning has been successfully applied in various domains, including gaming, robotics, and autonomous systems. In gaming, reinforcement learning algorithms have achieved remarkable results in games such as chess, Go, and Atari games, surpassing human expertise in some cases. These algorithms learn to make decisions based on the game state and interactions with the environment.
In robotics, reinforcement learning enables robots to learn complex tasks through trial and error, allowing them to navigate in dynamic environments or manipulate objects with dexterity. Robots can learn to optimize their actions through interactions with the physical world, adapting to changing conditions and achieving their objectives.
Autonomous systems, such as self-driving cars, also benefit from reinforcement learning. They learn to navigate through traffic, make decisions at intersections, and respond to unexpected situations by interacting with the environment and receiving feedback in the form of rewards or penalties. Reinforcement learning algorithms enable these systems to adapt and improve their performance over time.
While reinforcement learning has shown remarkable achievements in various domains, it also poses challenges. The exploration-exploitation dilemma is one such challenge, where the agent needs to strike a balance between exploring new actions to gather more information and exploiting known actions to maximize rewards. Finding the optimal trade-off between exploration and exploitation is a crucial aspect of reinforcement learning.
With advancements in computing power and algorithms, reinforcement learning is gaining traction as a powerful technique for training agents to make intelligent decisions in complex and dynamic environments. It has the potential to revolutionize fields like gaming, robotics, and autonomous systems, opening up new possibilities for human-machine interaction and problem-solving.
Natural Language Processing
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on the interaction between computers and human language. It involves the analysis, understanding, and generation of natural language text or speech, allowing computers to comprehend and respond to human language in a meaningful way.
NLP algorithms are designed to process and interpret unstructured textual data, enabling computers to perform tasks like sentiment analysis, language translation, text summarization, question answering, and more. These algorithms utilize techniques from machine learning, computational linguistics, and statistics to extract and understand information from text.
One of the fundamental challenges in NLP is language understanding. Computers need to comprehend the meaning and context of words, sentences, and documents to perform tasks accurately. Techniques like tokenization, part-of-speech tagging, and syntactic parsing help break down text into manageable units and capture linguistic information.
Sentiment analysis is a popular application of NLP, where algorithms analyze text to determine the sentiment or emotion expressed. This is useful for monitoring customer feedback, social media sentiment analysis, and brand perception analysis. By understanding sentiment, businesses can make informed decisions and improve customer satisfaction.
Another prominent area of NLP is language translation. Machine translation algorithms leverage statistical models or deep learning techniques to automatically translate text from one language to another. This has applications in areas like international communication, document translation, and global content localization.
NLP is also widely used in chatbots and virtual assistants. These systems utilize natural language understanding to interpret user queries and generate appropriate responses. By processing and understanding the intent behind user questions, chatbots can provide valuable information or perform specific tasks for users, enhancing customer support and user experiences.
Named Entity Recognition (NER) is another important task in NLP. It involves identifying and classifying named entities such as people, organizations, locations, dates, or other specific terms within text. NER is useful for information extraction, entity linking, and building knowledge graphs from unstructured text data.
However, NLP also faces challenges related to language ambiguity, context understanding, and the complexity of human language. Understanding idiomatic expressions, sarcasm, or subtle nuances in language remains a difficult task for computers. Additionally, language models that generate text need to ensure the generated content is coherent, grammatically sound, and contextually appropriate.
Overall, natural language processing is a rapidly evolving field with a wide range of applications. It enables computers to understand and interact with human language, enhancing communication, information retrieval, and decision-making processes. As NLP techniques continue to advance, we can expect further breakthroughs in language understanding and communication between humans and machines.
Computer Vision
Computer Vision is a field within artificial intelligence that focuses on enabling computers to understand, analyze, and interpret visual information from images or videos. It involves extracting valuable insights and knowledge from visual data, mimicking the human ability to perceive and understand the visual world.
Computer Vision algorithms leverage techniques from machine learning, image processing, and pattern recognition to analyze and interpret visual data. These algorithms can perform tasks like object detection, image classification, facial recognition, image segmentation, and more.
Object detection is one of the critical applications of computer vision. Algorithms can identify and locate specific objects within an image or video stream. This is valuable in various domains, such as autonomous driving, surveillance systems, and object tracking in videos.
Image classification is another common task in computer vision, where algorithms categorize images into predefined classes or categories. By learning from labeled training data, these algorithms can accurately classify images based on their visual features. Image classification has applications in medical imaging, quality control in manufacturing, and content filtering in social media.
Facial recognition is a popular application of computer vision that involves identifying and verifying individuals based on their facial features. It has numerous applications, including security systems, access control, and personalized advertising. Facial recognition algorithms can map facial landmarks and compare them with a database of known faces to identify individuals.
Image segmentation aims to divide an image into meaningful and distinct regions or objects. It is useful for applications like object recognition, scene understanding, and image editing. Computer vision algorithms can segment images based on color, texture, or other visual features, enabling precise analysis and manipulation of specific image regions.
Computer vision techniques are also applied in augmented reality and virtual reality applications. By analyzing real-world visual information, computer vision algorithms can overlay computer-generated images or information onto a user’s view, enhancing their perception and interaction with the environment.
However, computer vision faces challenges related to the variability and complexity of visual data. Variations in lighting conditions, viewpoints, and occlusions can impact the accuracy and robustness of computer vision algorithms. Additionally, training large-scale computer vision models requires extensive labeled datasets and significant computational resources.
Nonetheless, computer vision continues to make significant strides in enabling machines to understand and interpret visual data. It has enormous potential in a wide range of fields, including healthcare, manufacturing, autonomous systems, entertainment, and more. As computer vision techniques advance, we can expect even more sophisticated and powerful applications that will reshape various industries.
Fraud Detection
Fraud detection is a critical area where machine learning and data analytics play a crucial role in identifying and preventing fraudulent activities. Traditional rule-based systems for fraud detection often fall short in detecting sophisticated and evolving fraud patterns. Machine learning algorithms, on the other hand, can analyze large volumes of data, detect anomalies, and uncover patterns that indicate fraudulent behavior.
Machine learning algorithms for fraud detection learn from historical data that includes both legitimate and fraudulent transactions. By training on this labeled dataset, algorithms can identify patterns and characteristics that distinguish fraudulent transactions from legitimate ones. This enables the algorithms to flag potentially fraudulent activities in real-time, allowing organizations to take prompt action.
One of the common techniques used in fraud detection is anomaly detection. Anomalies refer to transactions or patterns that deviate significantly from the norm. By analyzing transactional data, machine learning algorithms can identify unusual patterns, such as unexpected transaction amounts, abnormal purchase locations, or suspicious transaction sequences. These anomalies can indicate potential fraudulent behavior.
Another approach to fraud detection is the use of predictive modeling. Predictive modeling algorithms learn from historical data, including past fraudulent activities, to build models that can predict the likelihood of fraud for new transactions. These models can assign a risk score to incoming transactions, enabling organizations to focus their resources on high-risk transactions that require further investigation.
Machine learning algorithms can also leverage network analysis to detect fraud. By analyzing the relationships and connections between entities like individuals, accounts, or devices, algorithms can identify patterns of fraudulent networks or organized fraud rings. Network analysis provides valuable insights into the underlying structure and dynamics of fraud.
Continuous monitoring and real-time analysis are critical in fraud detection. Machine learning algorithms process large volumes of transaction data and can identify patterns or anomalies that signify potential fraud in real-time. This allows organizations to respond swiftly, minimizing financial losses and protecting customers from fraudulent activities.
Fraud detection using machine learning is employed in various industries, including banking, insurance, e-commerce, and healthcare. In the banking sector, algorithms can detect fraudulent credit card transactions, identify account takeover attempts, or flag suspicious activities in online banking. In the insurance industry, these algorithms can help detect fraudulent claims and identify patterns of fraudulent behavior. E-commerce platforms use machine learning to recognize fraudulent online transactions, protecting both consumers and businesses.
While machine learning algorithms have demonstrated remarkable success in fraud detection, it is an ongoing cat-and-mouse game. Fraudsters continuously adapt and develop new techniques to evade detection. As a result, fraud detection systems must evolve and constantly update their algorithms and models to stay ahead of emerging fraud patterns.
Overall, machine learning algorithms are powerful tools in fraud detection, enabling organizations to detect and prevent fraudulent activities effectively. By leveraging advanced analytics and real-time monitoring, these algorithms contribute to the protection of businesses, customers, and the integrity of financial systems.
Customer Segmentation
Customer segmentation is a crucial strategy in marketing and business that involves dividing a customer base into distinct groups based on shared characteristics, behaviors, or preferences. By segmenting customers, businesses can gain insights into their varied needs and behaviors, allowing for more targeted and personalized marketing efforts.
Machine learning algorithms play a key role in customer segmentation by analyzing large amounts of customer data and identifying patterns and similarities. These algorithms can process various types of data, including demographic information, purchase history, website interactions, and social media activity, among others.
One common approach to customer segmentation is clustering analysis. Machine learning algorithms can group customers into clusters based on their features or behaviors. This enables businesses to identify segments with similar characteristics and tailor marketing strategies to suit their specific needs. Clustering algorithms like k-means, hierarchical clustering, or Gaussian mixture models are often used for customer segmentation.
Another approach to customer segmentation is predictive modeling, where machine learning algorithms build models to predict customer behavior or preferences. These models can help identify segments that are more likely to respond to certain marketing campaigns or have higher customer lifetime value. By understanding customer behavior, businesses can effectively allocate resources and develop personalized marketing approaches.
Personalization is a key advantage of customer segmentation. By understanding the unique needs and preferences of different customer segments, businesses can tailor their products, services, and marketing efforts to resonate with each segment. This leads to improved customer satisfaction, increased engagement, and higher conversion rates.
Customer segmentation has applications across industries. In e-commerce, businesses can identify high-value customers and personalize their shopping experiences to increase customer loyalty and drive repeat purchases. In the hospitality industry, customer segmentation helps hotels target specific groups of travelers with tailored promotions and offerings. Similarly, in the telecommunications industry, customer segmentation aids in providing customized service plans based on usage patterns and preferences.
Machine learning algorithms not only help analyze existing customer data, but they can also assist in real-time segmentation. By continuously monitoring and analyzing customer interactions and behavior in real-time, businesses can dynamically adjust their marketing approaches and offer personalized experiences in the moment.
However, customer segmentation should not be static. Customer behaviors and preferences change over time, so businesses must regularly update and refine their segmentation strategies. By leveraging machine learning algorithms, businesses can adapt and evolve their customer segments based on changing market dynamics and customer needs.
Overall, customer segmentation driven by machine learning algorithms enables businesses to understand their customer base better and implement targeted marketing strategies. By tailoring messages, products, and services to specific customer segments, businesses can improve customer satisfaction, increase engagement, and ultimately drive business growth.
Recommender Systems
Recommender systems are a key component of many online platforms and services, providing personalized recommendations to users based on their preferences and behaviors. These systems leverage machine learning algorithms to analyze user data and make predictions about their interests, ultimately guiding users towards relevant content, products, or services.
Recommendation algorithms can be categorized into two main types: collaborative filtering and content-based filtering.
Collaborative filtering algorithms analyze user behavior, such as past purchases, ratings, or interactions, to find similarities and patterns among users. By identifying users with similar preferences, these algorithms can recommend items that other like-minded users have found appealing. Collaborative filtering is useful in scenarios where users’ past behaviors are strong indicators of their future preferences, such as movie recommendations or product suggestions.
Content-based filtering algorithms, on the other hand, focus on the characteristics or attributes of items themselves. By analyzing the features of items that a user has interacted with, these algorithms recommend items with similar or related characteristics. For example, in a music streaming platform, a content-based filtering algorithm might recommend songs with a similar genre or tempo to a user’s favorite tracks.
Hybrid recommender systems combine collaborative and content-based filtering techniques to provide personalized recommendations that take into account both user preferences and item characteristics. By combining the strengths of the two approaches, hybrid systems aim to improve the accuracy and relevance of recommendations.
Recommender systems have extensive applications across industries. In e-commerce, these systems are used to suggest products to customers based on their browsing and purchase history, increasing the chances of conversion. In media streaming platforms, recommender systems help users discover new content that aligns with their interests, enhancing user engagement and retention. In news websites or social media platforms, recommendation algorithms can surface relevant articles or posts based on users’ reading habits or social connections.
Machine learning algorithms are continuously learning and adapting to user preferences, allowing recommender systems to provide more accurate and relevant recommendations over time. As users interact with the system and provide feedback, the algorithms can adjust their recommendations to better match individual preferences and changing interests.
However, recommender systems also face challenges such as the “cold-start” problem, where new users or items have limited or no historical data available for accurate recommendations. Addressing this challenge often requires the integration of other techniques, such as content-based recommendations or leveraging demographic and contextual information.
Overall, recommender systems powered by machine learning algorithms have become an integral part of many online platforms, enhancing user experiences, and driving user engagement. By providing personalized recommendations, businesses can increase customer satisfaction, drive sales, and foster long-term customer loyalty.
Predictive Maintenance
Predictive maintenance is a technique that utilizes machine learning algorithms and data analytics to predict when and how industrial equipment or machinery might fail. By analyzing real-time and historical data from sensors, machines, and maintenance records, predictive maintenance algorithms can identify patterns and indicators of potential equipment failure.
Traditional maintenance approaches such as preventive maintenance or reactive maintenance are often inefficient and costly. Preventive maintenance involves regularly scheduled maintenance tasks, regardless of the actual condition of the equipment. Reactive maintenance, on the other hand, involves repairing equipment once it has already failed, leading to costly downtime and repairs.
Predictive maintenance, however, aims to optimize maintenance schedules and reduce unplanned downtime by predicting when equipment failure is likely to occur. This allows maintenance tasks to be performed only when they are truly necessary, minimizing disruptions to operations and reducing maintenance costs.
Machine learning algorithms employed in predictive maintenance analyze various data sources to identify patterns that precede equipment failure. These patterns might include anomalous sensor readings, changes in temperature or vibration, or other indicators that the equipment is deviating from its normal operating mode. By identifying these patterns early, maintenance personnel can take preventative action, such as scheduling maintenance tasks or replacing faulty components before a major failure occurs.
In addition to reducing downtime and maintenance costs, predictive maintenance also enables businesses to optimize spare parts inventory. With accurate predictions of when and which parts might fail, businesses can stock the necessary components in advance, ensuring that maintenance tasks can be completed swiftly and efficiently.
Predictive maintenance is widely used in various industries, including manufacturing, energy, transportation, and healthcare. In the manufacturing sector, predictive maintenance helps identify potential machine failures, anticipate maintenance needs, and optimize production schedules. In the energy industry, it assists in monitoring the health of power plants and predicting equipment failures to prevent power outages. In healthcare, predictive maintenance can be used to anticipate equipment failures in medical devices, ensuring that critical equipment is always available for patient care.
Implementing predictive maintenance requires gathering and analyzing relevant data from sensors and maintenance systems. Historical data is used to train the algorithms, while real-time data is continuously monitored for any anomalies or patterns that indicate impending failures. Machine learning algorithms can be trained using both supervised and unsupervised learning techniques, depending on the available data and desired outcomes.
However, implementing predictive maintenance requires a sound data infrastructure and reliable sensor networks. Accurate and timely data collection is vital for the success of predictive maintenance algorithms. Moreover, monitoring and evaluating the performance of the predictive maintenance system is crucial to continuously improve its accuracy and effectiveness.
Overall, predictive maintenance powered by machine learning algorithms has revolutionized the maintenance strategies in various industries. By proactively identifying potential equipment failures, businesses can minimize downtime, optimize maintenance schedules, and reduce costs, ultimately enhancing productivity and operational efficiency.
Conclusion
Machine learning has become a powerful tool in various domains, transforming industries and revolutionizing the way we solve complex problems. The examples of machine learning discussed in this article, including supervised learning, unsupervised learning, reinforcement learning, natural language processing, computer vision, fraud detection, customer segmentation, recommender systems, and predictive maintenance, highlight the versatility and impact of machine learning algorithms.
Supervised learning algorithms have proven their effectiveness in making accurate predictions and classifications based on labeled training data. They enable businesses to automate processes, develop personalized experiences, and make informed decisions based on patterns and relationships within the data. Unsupervised learning algorithms excel in analyzing unlabeled data, uncovering hidden patterns, detecting anomalies, and reducing the dimensionality of complex datasets.
Reinforcement learning algorithms, inspired by human trial and error learning, enable machines to learn through interaction with the environment. This has led to significant advancements in gaming, robotics, and autonomous systems, as machines learn to optimize their actions and make intelligent decisions in dynamic environments.
Natural Language Processing algorithms enable computers to understand and interact with human language, opening up opportunities in chatbots, language translation, sentiment analysis, and more. Computer Vision algorithms analyze and interpret visual data, allowing machines to understand images and videos, enabling applications such as object detection, image classification, and facial recognition.
Fraud detection algorithms use machine learning to identify patterns of fraudulent behavior, preventing financial losses and safeguarding businesses and consumers. Customer segmentation algorithms cluster users based on their behaviors and preferences, allowing businesses to deliver tailored experiences and targeted marketing strategies for better customer satisfaction and engagement.
Recommender systems leverage machine learning to personalize recommendations for users, improving user experiences and driving engagement across various platforms. Predictive maintenance algorithms utilize data analytics and machine learning to predict potential equipment failures, optimizing maintenance schedules and reducing downtime and costs.
As machine learning algorithms continue to advance and evolve, we can expect further breakthroughs and applications in diverse domains. The growth of big data and advancements in computing power have fueled the development and adoption of machine learning algorithms. Organizations across industries are harnessing the power of machine learning to gain insights from data, automate processes, enhance decision-making, and deliver personalized experiences to their customers.
Machine learning is a rapidly growing field that requires continuous learning and adaptation. As algorithms continue to learn from new data and adapt to changing environments, the potential for innovation and problem-solving is boundless. Embracing machine learning can unlock new opportunities, propel businesses forward, and pave the way for a smarter and more connected future.