Introduction
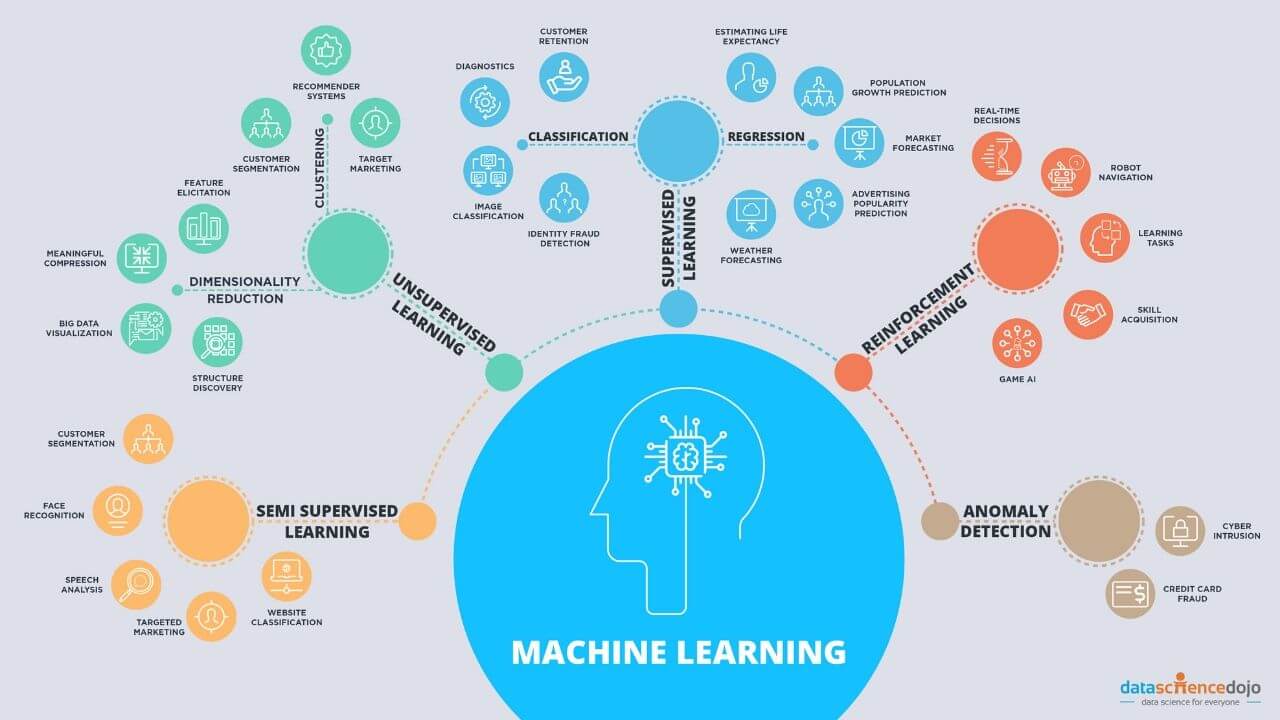
Machine learning has become an integral part of many industries, revolutionizing the way we analyze data and make informed decisions. By utilizing algorithms and statistical models, machine learning enables computers to learn from and adapt to data without explicit programming. This powerful technology has opened up new possibilities in fields such as finance, healthcare, marketing, and more, driving advancements and improving efficiency.
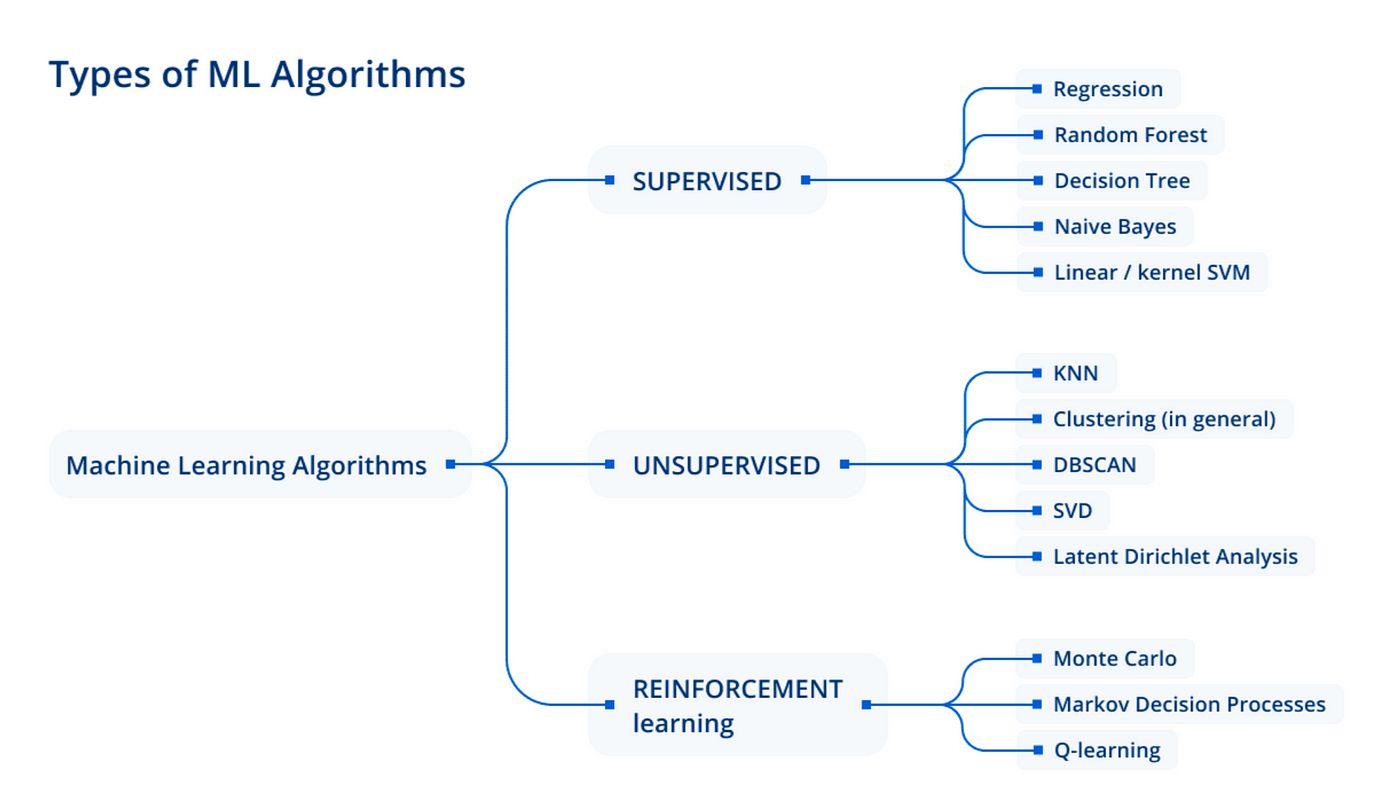
Machine learning algorithms are at the core of this technology, providing the framework for computers to learn and make predictions or decisions based on data. These algorithms are designed to analyze patterns, create models, and make accurate predictions or classifications. With various machine learning algorithms available, each with its strengths and weaknesses, it’s crucial to understand their characteristics and applications.
In this article, we will explore some popular machine learning algorithms and their applications. From linear regression to neural networks, each algorithm possesses unique properties and use cases. Whether you’re a data scientist, a developer, or just curious about the world of machine learning, understanding these algorithms can help you leverage their power and make informed decisions based on data.
It’s important to note that the selection of a machine learning algorithm depends on the specific problem you’re trying to solve and the nature of your data. Some algorithms are better suited for regression tasks, while others are more effective for classification or clustering. By gaining a comprehensive understanding of these algorithms, you’ll be better equipped to choose the right approach for your particular needs.
Now, let’s dive into the world of machine learning algorithms and explore their functionalities, applications, and advantages.
Linear Regression
Linear regression is one of the simplest and most widely used machine learning algorithms for regression tasks. It aims to establish a linear relationship between an input variable (or a set of input variables) and a continuous output variable. The algorithm calculates the best-fit line that minimizes the distance between the predicted values and the actual values in the training data.
In simple terms, linear regression models the relationship between the independent variables (features) and the dependent variable (target) by fitting a straight line to the data. This line can then be used to predict the target variable for new input data. The strength of the relationship is measured by the correlation coefficient, which indicates how closely the data points are to the fitted line.
Linear regression has a wide range of applications, including predicting housing prices based on factors such as square footage and location, forecasting sales based on historical data, and analyzing the impact of advertising budgets on sales.
One advantage of linear regression is its interpretability. The coefficients of the linear equation provide insights into the importance and direction of each feature’s effect on the target variable. Additionally, linear regression is computationally efficient and can be trained quickly, even with large datasets.
However, linear regression assumes a linear relationship between the variables, which may not always be the case. If the data exhibits non-linear patterns, linear regression may not capture the complexity effectively. In such cases, more advanced regression algorithms like polynomial regression or decision tree regression may be more suitable.
Despite its limitations, linear regression remains a fundamental algorithm in the field of machine learning. Its simplicity and interpretability make it a valuable tool for analyzing and predicting continuous variables. By understanding the assumptions and limitations of linear regression, data scientists can leverage its strengths and make accurate predictions within the linear relationship.
Logistic Regression
Logistic regression is a popular machine learning algorithm used for classification tasks. Unlike linear regression, which is used for continuous variables, logistic regression models the relationship between independent variables and a binary dependent variable. It predicts the probability of an event occurring based on the input features.
The algorithm applies the logistic function to transform the output of a linear equation into a value between 0 and 1, representing the probability of the event. This transformed output can then be interpreted as the likelihood of a certain class or category. If the probability exceeds a certain threshold (default is usually set to 0.5), the algorithm predicts the event as occurring; otherwise, it predicts the event as not occurring.
Logistic regression has various applications, including sentiment analysis, fraud detection, and medical diagnosis. For example, it can be used to classify email messages as spam or not spam based on input features like subject line, body content, and sender information.
One of the main advantages of logistic regression is its simplicity and interpretability. The coefficients of the linear equation provide insights into the influence of each feature on the probability of the event. Similar to linear regression, logistic regression is computationally efficient and can handle large datasets.
However, logistic regression assumes a linear relationship between the independent variables and the logarithm of the odds ratio. It may not perform well when the relationship is non-linear. In such cases, more complex algorithms like decision trees or support vector machines may yield better results.
Another consideration is the assumption of independence of observations. Logistic regression assumes that the observations are independent of each other, which may not hold true in some scenarios. Violation of this assumption can lead to biased results.
Despite its limitations, logistic regression is a widely used algorithm in binary classification problems. Its simplicity, interpretability, and efficiency make it a valuable tool for understanding and predicting binary outcomes. By understanding the strengths and limitations of logistic regression, data scientists can employ it effectively in a range of applications.
k-Nearest Neighbors (k-NN)
The k-Nearest Neighbors (k-NN) algorithm is a versatile and intuitive machine learning algorithm used for both classification and regression tasks. It operates based on the principle that similar data points tend to share similar labels or outcomes. In other words, it assumes that data points in the same vicinity are more likely to belong to the same class or have similar values.
The k-NN algorithm works by calculating the distance between the input data point and its neighbors in a feature space. It then assigns a label or value to the input point based on the labels or values of its k nearest neighbors. The value of k, the number of neighbors considered, is an important parameter that affects the performance of the algorithm.
k-NN can handle both categorical and continuous variables, making it applicable to a wide range of problems. For example, it can be used to perform image classification by finding the k most similar images in a dataset and assigning a label based on the majority vote of their labels.
One of the advantages of the k-NN algorithm is its simplicity and ease of implementation. It doesn’t require an explicit training phase, as the algorithm simply stores the training data and performs calculations during the prediction phase. This makes it a suitable choice for online or dynamic learning scenarios, where the data is continuously updated.
However, k-NN has some limitations. It can be sensitive to the choice of distance metric and the number of neighbors considered. The algorithm may struggle with high-dimensional data, as the concept of distance becomes less meaningful in high-dimensional spaces. Additionally, k-NN can be computationally expensive, especially when dealing with large datasets or when the number of neighbors is high.
Despite these limitations, the k-NN algorithm remains a valuable tool in machine learning. Its simplicity, flexibility, and ability to handle both classification and regression tasks make it a popular choice for many applications. By selecting an appropriate distance metric and tuning the value of k, data scientists can leverage the power of k-NN to make accurate predictions and classifications.
Support Vector Machines (SVM)
Support Vector Machines (SVM) is a powerful and versatile machine learning algorithm that can be used for classification, regression, and outlier detection tasks. SVM aims to find the best hyperplane that separates the data points into different classes or groups, maximizing the margin between the classes.
The algorithm works by mapping the data points into a high-dimensional feature space using kernel functions. In this feature space, SVM finds the optimal hyperplane that maximizes the margin between the closest data points from different classes. These closest data points, known as support vectors, play a crucial role in determining the decision boundary.
SVM is effective in handling linearly separable data as well as complex, non-linear data. It can use various types of kernel functions, such as linear, polynomial, and radial basis function (RBF), to model non-linear relationships. This flexibility allows SVM to capture complex decision boundaries and handle data with overlapping classes.
One of the advantages of SVM is its ability to handle high-dimensional data efficiently. This is achieved by finding the decision boundary in the transformed feature space instead of explicitly operating in the original input space. Additionally, SVM is less affected by the presence of irrelevant features, making it robust in the presence of noisy data.
However, SVM can be computationally expensive, especially when dealing with large datasets or complex kernel functions. Additionally, the selection of the appropriate kernel function and tuning the hyperparameters can be challenging and require domain knowledge.
SVM has found numerous applications in various fields, including image and text classification, gene expression analysis, and anomaly detection. For example, in image classification, SVM can be used to classify images into different categories based on features extracted from the images.
Despite its computational demands and hyperparameter tuning complexities, SVM remains a popular choice for many classification and regression tasks. Its ability to handle both linear and nonlinear data, robustness to noise, and efficiency in high-dimensional spaces make it a valuable tool in machine learning.
Decision Trees
Decision trees are widely used machine learning algorithms that can be used for both classification and regression tasks. They are intuitive and easy to understand, as they mimic the decision-making process by creating a tree-like structure of if-else conditions based on the input features.
The algorithm works by recursively partitioning the data based on the features that provide the most information gain or decrease in impurity. It selects the best split based on certain criteria, such as Gini impurity or information gain. This split creates branches that represent different conditions, leading to the formation of a decision tree.
Decision trees have clear advantages when it comes to interpretability and transparency, as each decision and condition can be easily visualized. They can handle both numerical and categorical data, making them versatile for different types of problems. Decision trees also perform well in situations where the data has interactions and non-linear relationships.
One of the key strengths of decision trees is their ability to handle feature interactions and capture complex decision boundaries. Each node in the tree represents a split on a feature, allowing the algorithm to consider multiple interacting features simultaneously. Decision trees are also robust against outliers and can handle missing data by effectively imputing values at each split.
However, decision trees have some limitations. They can easily overfit the training data, especially when the tree becomes too deep, resulting in poor generalization to unseen data. This issue can be mitigated by pruning techniques, such as cost-complexity pruning or minimum sample split criteria.
Moreover, decision trees are sensitive to small changes in the training data, as even a slight variation can lead to different splits and, subsequently, different decision boundaries. Ensemble methods like random forests or gradient boosting can be employed to overcome this issue by combining the predictions of multiple decision trees.
Decision trees find applications in various fields, including finance, healthcare, and natural language processing. For instance, in credit risk assessment, decision trees can be used to determine the creditworthiness of a customer based on features like income, employment history, and credit history.
Despite their limitations, decision trees offer a transparent and interpretable alternative for making predictions and classifications. Their capability to handle complex relationships and interactions, robustness against outliers, and flexibility in handling different types of data make them a valuable tool in the machine learning toolbox.
Random Forests
Random Forests is a powerful ensemble learning algorithm that combines the predictions of multiple decision trees to make more accurate and robust predictions. It is commonly used for both classification and regression tasks in machine learning.
The algorithm works by creating an ensemble or a collection of decision trees. Each tree is trained on a random subset of the training data, and at each split, a random subset of features is considered. By combining the predictions of these individual trees through voting (for classification) or averaging (for regression), Random Forests reduce the risk of overfitting and provide more reliable predictions.
Random Forests have several advantages over single decision trees. Firstly, it reduces the variance and increases the stability of the model by averaging the predictions of multiple trees. This helps in handling noise and outliers in the data. Secondly, by considering a random subset of features at each split, it promotes feature diversity and reduces the bias of individual trees.
Another advantage is the ability to assess the importance of features. By measuring the average decrease in impurity or the mean decrease in accuracy caused by a feature, Random Forests provide insights into the relevance and contribution of each feature in making predictions.
Random Forests are robust against overfitting and are less sensitive to the choice of hyperparameters compared to individual decision trees. They also work well with high-dimensional data and can handle missing values and outliers effectively.
However, Random Forests are computationally expensive, especially when dealing with large datasets or a high number of trees in the ensemble. The interpretability of Random Forests is also more challenging compared to a single decision tree, as the model’s predictions are a combination of multiple trees.
Random Forests find applications in various domains, including finance, healthcare, and image classification. For instance, in medical diagnosis, Random Forests can be used to predict the presence of a disease based on various medical features and risk factors.
Despite the trade-offs, Random Forests have proven to be a highly effective and popular algorithm in machine learning. Their ability to reduce overfitting, handle high-dimensional data, and provide insights into feature importance make them a valuable tool for accurate and robust predictions.
Naive Bayes
Naive Bayes is a probabilistic machine learning algorithm commonly used for classification tasks. It is based on Bayes’ theorem, which calculates the probability of a certain event given prior knowledge or evidence. Naive Bayes assumes that the features are conditionally independent of each other, hence the name “naive.”
The algorithm works by estimating the probability of each class based on the features of the input data. It assumes that each feature contributes independently to the probability of a certain class and calculates the likelihood of the features belonging to each class. The final classification is determined by selecting the class with the highest probability.
Naive Bayes is known for its simplicity, computational efficiency, and ability to handle high-dimensional data. It requires a relatively small amount of training data to estimate the parameters, making it suitable for both batch and online learning scenarios. Naive Bayes also performs well in situations with a large number of features and is relatively robust against irrelevant features.
One key assumption of Naive Bayes is the independence of features, which may not always hold true in real-world data. This can lead to suboptimal performance if there are strong dependencies between the features. However, despite this simplifying assumption, Naive Bayes has been successfully applied in various domains, such as text classification, spam filtering, and sentiment analysis.
There are several variations of Naive Bayes, including Gaussian Naive Bayes for continuous data, Multinomial Naive Bayes for discrete count data, and Bernoulli Naive Bayes for binary data. These variations allow Naive Bayes to handle different types of data and make it a versatile algorithm.
When applying Naive Bayes, it’s important to preprocess the data carefully, ensuring that the feature independence assumption is not violated. Feature engineering and selection also play vital roles in improving the performance of Naive Bayes. Additionally, Naive Bayes may struggle with rare events or imbalanced datasets, as it relies on the available evidence to estimate probabilities.
Despite its simplifying assumptions, Naive Bayes remains a valuable algorithm in machine learning. Its simplicity, efficiency, and ability to handle high-dimensional data make it a popular choice for classification tasks. By understanding and addressing the limitations, data scientists can leverage Naive Bayes to make accurate and efficient predictions in various domains.
Neural Networks
Neural Networks, often referred to as artificial neural networks (ANN), are a class of machine learning algorithms inspired by the structure and functionality of the human brain. They consist of interconnected nodes, or “neurons,” which process and transmit information. Neural networks have gained tremendous popularity in recent years due to their ability to learn complex patterns and make accurate predictions.
The basic architecture of a neural network includes an input layer, one or more hidden layers, and an output layer. Each layer consists of nodes, or neurons, that perform computations on the input data and pass them on to the next layer. The strength of the connections between neurons, known as weights, are adjusted during the training process to optimize the network’s performance.
Neural networks are known for their ability to learn directly from the data, extracting intricate relationships and features. This capability makes them well-suited for tasks such as image classification, natural language processing, and speech recognition. Through the application of various activation functions, such as sigmoid, ReLU, or tanh, neural networks can model non-linear relationships and solve complex problems.
One of the significant advantages of neural networks is their ability to perform automatic feature extraction. Traditional machine learning algorithms require manual feature engineering, where domain knowledge is used to select relevant features. Neural networks, on the other hand, can learn meaningful representations from raw or high-dimensional data, reducing the need for extensive feature engineering.
Neural networks, however, can be computationally expensive and require large amounts of training data to achieve good performance. They are also prone to overfitting, particularly when the model size is excessive or when the training dataset is small. Regularization techniques, such as dropout or weight decay, can be employed to mitigate this issue.
Recent advancements in neural network architecture, such as convolutional neural networks (CNN) for image processing and recurrent neural networks (RNN) for sequential data, have further expanded the capabilities of these models. Deep learning, a subfield of neural networks, focuses on networks with multiple hidden layers and has achieved remarkable success in various domains, including computer vision and natural language processing.
Neural networks have revolutionized many industries, driving advancements in fields such as healthcare, finance, and autonomous vehicles. Their ability to learn complex patterns and make accurate predictions makes them a valuable tool for solving a wide range of problems.
By understanding the architectural components of neural networks, data scientists can design and train models that leverage the power and flexibility of this algorithm. Through careful parameter tuning, regularization techniques, and monitoring, neural networks can achieve state-of-the-art performance in various machine learning tasks.
Clustering Algorithms
Clustering algorithms are a subset of unsupervised machine learning algorithms that aim to group similar data points together based on their inherent patterns and similarities. Clustering is an essential task in exploratory analysis, data mining, and pattern recognition. It helps identify hidden structures and gain insights into the underlying characteristics of the data.
Clustering algorithms operate on the assumption that data points within the same cluster are more similar to each other than to those in other clusters. These algorithms assign data points to clusters, which can be either predefined or automatically determined based on the algorithm’s output.
There are several common clustering algorithms, each with its unique approach and characteristics. K-means is one of the most widely used clustering algorithms. It partitions data into k clusters by minimizing the sum of squared distances between the data points and their respective cluster centroids.
Hierarchical clustering, on the other hand, builds a hierarchy of clusters by iteratively merging or splitting them based on certain distance measures. Agglomerative hierarchical clustering starts with each data point as a separate cluster and progressively merges the most similar clusters until a desired number of clusters is achieved.
Density-based clustering algorithms, such as DBSCAN (Density-Based Spatial Clustering of Applications with Noise), group together data points that are close to each other in density, while treating sparser regions as noise or outliers. DBSCAN is particularly useful for discovering clusters of arbitrary shape and handling datasets with varying densities.
Spectral clustering is another popular algorithm that utilizes the eigenvectors of the similarity matrix to perform dimensionality reduction and clustering simultaneously. It projects the data into a lower-dimensional space where clustering is performed, capturing the most salient features of the data.
Clustering algorithms find applications in various domains, including customer segmentation, anomaly detection, and image segmentation. For example, in customer segmentation, clustering can be used to identify groups of customers with similar preferences and behaviors, helping businesses tailor their marketing strategies accordingly.
It’s important to note that the choice of clustering algorithm depends on the nature of the data, the desired number of clusters, and the desired output. Evaluating the quality of the clusters can be subjective, and different algorithms may yield different results based on their assumptions and limitations.
Clustering algorithms can be combined with other machine learning techniques to achieve more comprehensive analyses and insights. They provide a valuable tool for exploring and understanding complex datasets, enabling data scientists to discover meaningful patterns and relationships in an unsupervised manner.
Recommendation Algorithms
Recommendation algorithms are a type of machine learning algorithm that provide personalized recommendations to users based on their preferences, behaviors, and historical data. They are widely used in various industries, including e-commerce, streaming services, and social media, to enhance user experiences and increase engagement.
There are different types of recommendation algorithms, each designed to tackle different recommendation scenarios. Collaborative filtering is a commonly used approach that analyzes user behavior and item interactions to make recommendations. It identifies similar users or items based on their past behavior and leverages this information to recommend items that users have not interacted with.
Content-based filtering is another approach that focuses on the characteristics of items. It creates user profiles based on their preferences and recommends items that share similar attributes or features. This approach is effective in situations where user-item interactions are scarce or where user preferences are diverse.
Hybrid recommendation algorithms combine the strengths of collaborative filtering and content-based filtering. By leveraging both user behavior and item attributes, these algorithms can generate more accurate and diverse recommendations. Hybrid approaches can be designed as simple ensemble models or complex architectures that fuse information from multiple sources.
Recommendation algorithms rely on user feedback, such as ratings, reviews, or implicit signals like clicks or purchases, to learn users’ preferences and build accurate models. They employ techniques like matrix factorization, similarity measures, or deep learning architectures to identify patterns in the data and make personalized recommendations.
One challenge in recommendation algorithms is the cold-start problem, where there is limited or no user engagement data available for new users or items. Various strategies, such as using demographic information, item popularity, or leveraging knowledge from similar users or items, can be employed to tackle this issue.
Recommendation algorithms have significantly impacted industries by enhancing user experiences, increasing customer satisfaction, and boosting business revenue. They help users discover new products, movies, or content they may be interested in while providing businesses with valuable insights into user preferences and behavior.
However, it’s important to strike a balance in recommendations to avoid over-exposure or creating “filter bubbles” where users are only exposed to items similar to their previous choices. A well-designed recommendation algorithm should consider diversity, serendipity, and fairness to provide a rich and engaging user experience.
Overall, recommendation algorithms play a vital role in personalizing the user experience and helping users navigate through the vast amount of information available. By analyzing user data and making intelligent predictions, these algorithms enable businesses to connect users with the most relevant and appealing content, products, or services.
Conclusion
Machine learning algorithms have revolutionized various industries by providing powerful tools for data analysis, prediction, and decision-making. From linear regression and logistic regression to k-nearest neighbors and support vector machines, each algorithm possesses unique characteristics and applications.
Linear regression and logistic regression are fundamental algorithms for regression and classification tasks, respectively. They offer interpretability and efficiency in analyzing relationships between variables and making predictions. K-nearest neighbors leverages distance measures to classify or regress data points based on their proximity to neighbors. Support vector machines excel in finding optimal decision boundaries and handling high-dimensional data.
Decision trees, random forests, and naive Bayes are versatile algorithms that can be used for both classification and regression. Decision trees provide interpretable decision rules, while random forests combine multiple decision trees to improve performance and robustness. Naive Bayes assumes independence between features and is computationally efficient in handling high-dimensional data.
Neural networks, or artificial neural networks, have gained popularity for their ability to learn complex patterns and make accurate predictions. They excel in tasks such as image classification and natural language processing, and deep learning architectures have extended their capabilities even further.
Clustering algorithms, like k-means, hierarchical clustering, and DBSCAN, enable the discovery of hidden structures and patterns within data. They are valuable for customer segmentation, anomaly detection, and image segmentation. Recommendation algorithms, including collaborative filtering, content-based filtering, and hybrid approaches, personalize recommendations and enhance user experiences in various domains.
Understanding the characteristics and applications of these machine learning algorithms empowers data scientists, developers, and decision-makers to choose the most suitable approach for specific problems and datasets. By leveraging the strengths of these algorithms and accounting for their limitations, accurate predictions, and valuable insights can be obtained from data.
The world of machine learning is continuously evolving, with new algorithms and techniques being developed. As technology advances, staying updated with the latest trends and advancements in the field will be crucial for leveraging the full potential of machine learning algorithms and driving innovation across industries.