Introduction
Welcome to the world of machine learning! In this rapidly evolving era of technology, machine learning has emerged as a powerful tool for solving complex problems and making significant advancements in various industries. By harnessing the power of algorithms and data, machine learning enables computers to learn from patterns and make predictions or decisions without being explicitly programmed.
Machine learning has revolutionized fields such as healthcare, finance, marketing, and more, allowing businesses to gain valuable insights and make data-driven decisions. Whether you are a developer, data scientist, or an aspiring machine learning enthusiast, understanding the basics of machine learning algorithms is essential for leveraging this transformative technology.
In this article, we will delve into the fundamentals of machine learning algorithms and provide step-by-step guidance on how to build your own machine learning model. By the end of this article, you will have a clear roadmap to apply machine learning algorithms to solve real-world problems.
But before we dive into the technicalities, let’s begin by exploring what exactly machine learning is and why it has become such a hot topic in the tech world.
What is Machine Learning?
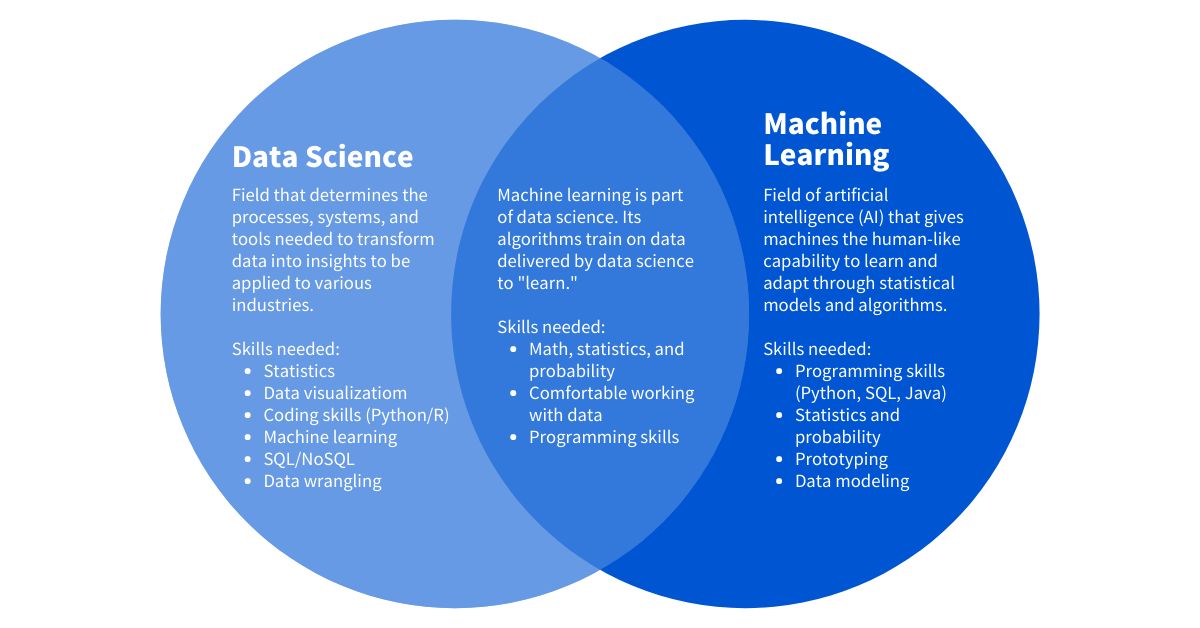
Machine learning is a subset of artificial intelligence (AI) that focuses on developing algorithms and models that enable computers to learn from data and improve their performance over time. Rather than being explicitly programmed, machine learning algorithms are trained to identify patterns, make predictions, or take actions based on the data they have been exposed to.
At its core, machine learning embraces the idea that computers can learn and adapt without being explicitly programmed for every possible scenario. Instead, they rely on statistical analysis and pattern recognition to make informed decisions.
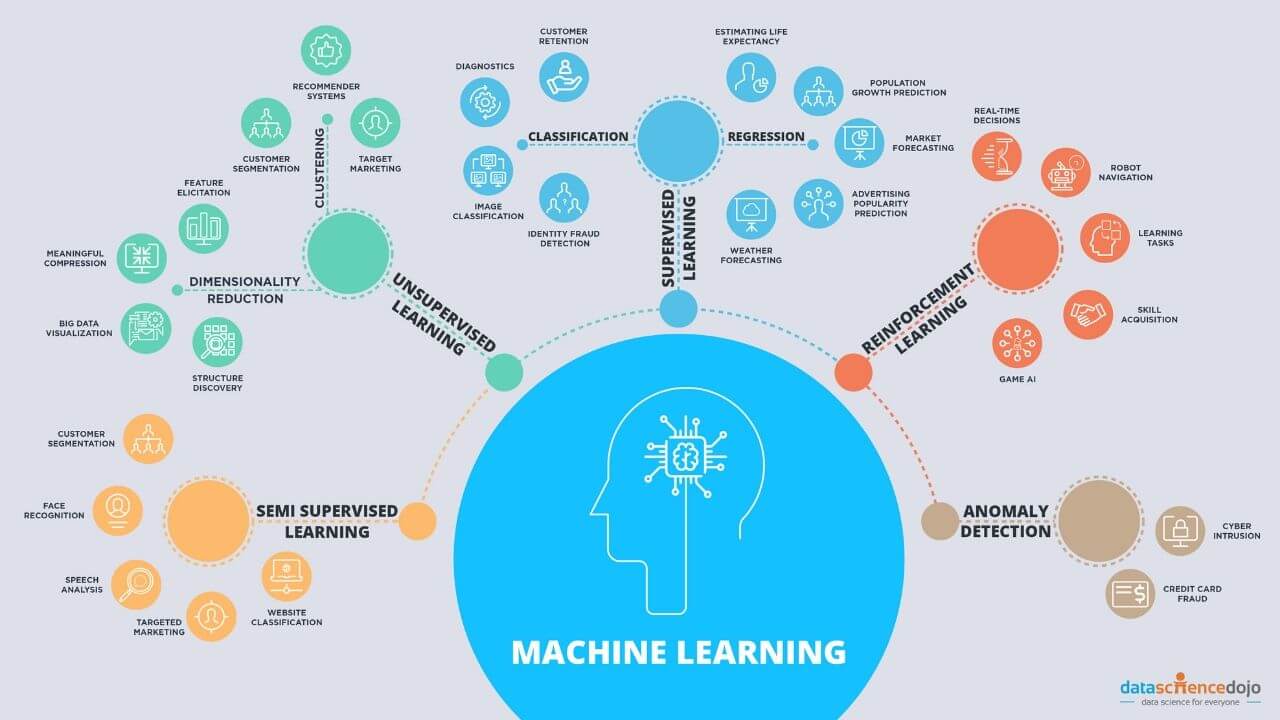
There are various types of machine learning approaches, including supervised learning, unsupervised learning, and reinforcement learning.
- Supervised Learning: In supervised learning, the algorithm is trained on labeled data, where each data point is accompanied by a target label. The algorithm learns to map input features to the correct output by minimizing the difference between its predictions and the actual labels. Examples of supervised learning algorithms include linear regression, decision trees, and neural networks.
- Unsupervised Learning: Unsupervised learning involves training models on unlabeled data and allowing them to uncover patterns or structures without any predefined outcomes. Clustering and dimensionality reduction are common tasks in unsupervised learning. Popular unsupervised learning algorithms include k-means clustering, hierarchical clustering, and principal component analysis (PCA).
- Reinforcement Learning: Reinforcement learning is a type of machine learning where an agent learns to make decisions and take actions in an environment. The agent receives feedback in the form of rewards or penalties based on its actions, allowing it to learn from trial and error. Reinforcement learning is often used in applications such as robotics and game playing.
Machine learning algorithms can be leveraged to solve a wide range of problems, including image and speech recognition, natural language processing, fraud detection, recommendation systems, and much more.
Now that we have a basic understanding of machine learning let’s explore the key steps involved in building a machine learning algorithm.
Understanding the Basics of Machine Learning Algorithms
Machine learning algorithms are the heart and soul of every machine learning model. They are designed to analyze data, identify patterns, and make predictions or decisions based on the insights derived from the data. Understanding the basics of machine learning algorithms is essential for building effective models that can solve real-world problems.
Here are some key concepts to help you grasp the fundamentals of machine learning algorithms:
- Feature Selection: The success of a machine learning algorithm heavily depends on the selection of relevant features. Features are the individual measurable properties or characteristics of the data that are used as inputs to the algorithm. Choosing the right features that have a strong correlation with the target variable is crucial for accurate predictions.
- Training and Testing: Before deploying a machine learning algorithm, it is essential to train the model on a labeled dataset. Training involves feeding the algorithm with data and corresponding labels, allowing it to learn the underlying patterns. Once the model is trained, it is evaluated on a separate testing dataset to assess its performance and generalization abilities.
- Hyperparameter Tuning: Machine learning algorithms often have hyperparameters that can be fine-tuned to optimize the model’s performance. Hyperparameters are configuration variables that are not learned from the data but need to be set before training the algorithm. Techniques such as cross-validation and grid search can be employed to find the best combination of hyperparameters.
- Model Evaluation Metrics: Different evaluation metrics are used to assess the performance of machine learning algorithms. Common evaluation metrics include accuracy, precision, recall, F1-score, and area under the curve (AUC). The choice of evaluation metric depends on the nature of the problem and the desired outcome.
- Overfitting and Underfitting: Overfitting occurs when a model performs well on the training dataset but fails to generalize to unseen data. Underfitting, on the other hand, happens when the model is too simple and fails to capture the underlying patterns in the data. Balancing between these extremes is crucial to building a robust and accurate machine learning model.
By understanding these key concepts, you can gain insights into how machine learning algorithms work and make informed decisions when building your own models. In the next sections, we will explore the step-by-step process of creating a machine learning algorithm, from defining the problem to deployment and integration.
Step 1: Define the Problem
The first and most crucial step in building a machine learning algorithm is defining the problem you want to solve. Clearly understanding the problem will help you identify the appropriate data and choose the right algorithm to tackle it.
Here are the key considerations in defining your problem:
- Problem Type: Determine whether your problem requires classification, regression, clustering, or any other machine learning technique. Classification problems involve assigning data points into predefined classes or categories, regression problems involve predicting continuous values, and clustering problems involve grouping similar data points together.
- Objectives: Clearly define the objectives you want to achieve with your machine learning algorithm. Are you seeking to improve accuracy, reduce errors, increase efficiency, or optimize a particular metric? Having well-defined objectives will guide your choices throughout the process.
- Available Data: Assess the availability and quality of the data that can be used to train and test your machine learning algorithm. Identify the relevant features and labels needed to build a robust model. If the required data is not readily available, consider data collection or finding alternative sources.
- Ethical Considerations: Consider any ethical implications associated with the problem. Ensure that your machine learning algorithm adheres to legal and ethical guidelines, especially if it involves sensitive data, decision-making, or social impact.
By clearly defining the problem you want to solve, you provide a solid foundation for the rest of the machine learning process. This step sets the stage for data collection and preparation, which is the next phase in building your machine learning algorithm.
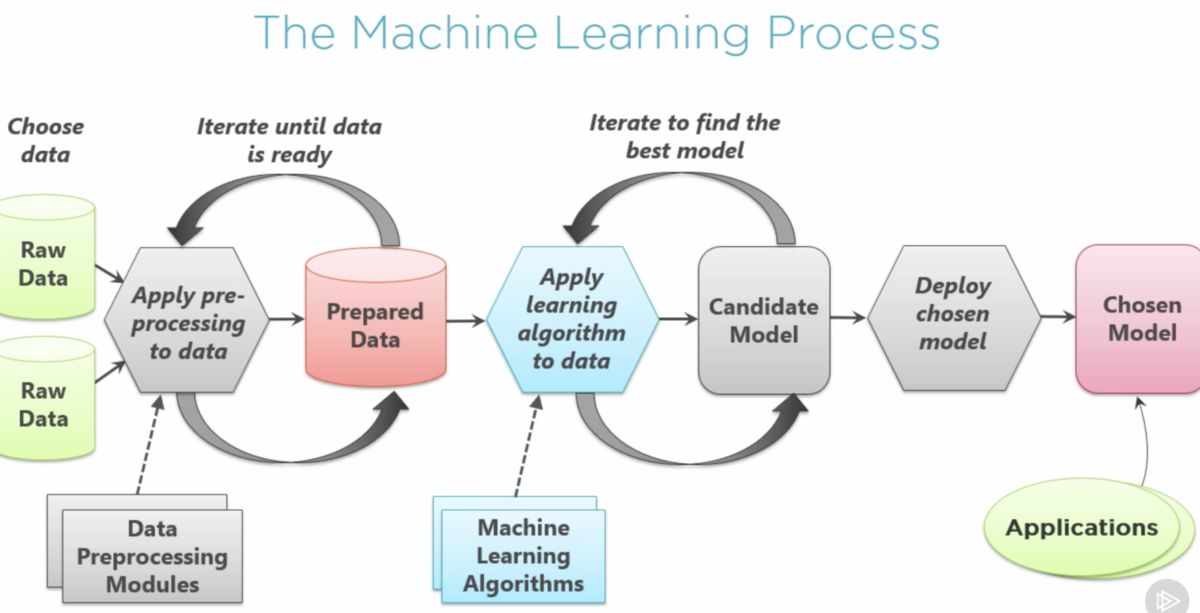
Step 2: Data Collection and Preparation
Once you have defined the problem, the next step in building a machine learning algorithm is to collect and prepare the data that will be used to train and test your model. Data plays a crucial role in the success of your algorithm, and proper data collection and preparation are essential for accurate results.
Here is a breakdown of the key tasks involved in data collection and preparation:
- Data Collection: Identify the sources of data relevant to your problem. This can include existing datasets, public APIs, web scraping, or even manual data entry if required. Ensure that the collected data represents the problem domain adequately.
- Data Cleaning: Clean the data by identifying and handling missing values, outliers, duplicates, or any other inconsistencies. Data cleaning is crucial to ensure the quality and integrity of your dataset, as dirty data can negatively impact the performance of your machine learning algorithm.
- Feature Engineering: Feature engineering involves transforming the raw data into meaningful features that can be used as inputs to your algorithm. This can include scaling numerical features, encoding categorical variables, creating new features based on domain knowledge, or using techniques such as dimensionality reduction.
- Data Splitting: Split your dataset into training and testing subsets. The training set is used to train the algorithm, while the testing set is used to evaluate its performance. It is essential to maintain a proper balance between the two sets to avoid overfitting or underfitting.
Proper data collection and preparation are crucial steps in the machine learning process as they directly influence the performance and reliability of your algorithm. By ensuring the cleanliness of your data and extracting meaningful features, you enhance the predictive power of your model.
Once the data is collected and prepared, you are ready to move on to the next step: choosing the right algorithm for your problem.
Step 3: Choosing the Right Algorithm
After defining the problem and preparing the data, the next critical step in building a machine learning algorithm is selecting the right algorithm that best suits your problem domain. Choosing the appropriate algorithm is essential as different algorithms have different strengths, limitations, and suitability for specific types of problems.
Here are some factors to consider when choosing the right algorithm:
- Problem Type: Consider the problem type you defined in the first step. Some algorithms are specifically designed for classification problems, while others are more suitable for regression or clustering tasks. Understanding the problem type will help narrow down your choices.
- Dataset Size: Take into account the size of your dataset. Some algorithms perform better with large datasets, while others work well with smaller datasets. If you have a small dataset, you may need to consider algorithms that are more robust to avoid overfitting.
- Algorithm Complexity: Evaluate the complexity of the algorithm and its interpretability. Some algorithms, such as decision trees or linear regression, are easy to interpret and understand, while others, like neural networks or ensemble methods, may be more complex but offer higher performance.
- Domain Knowledge: Consider your domain knowledge and expertise. Some algorithms may require a deeper understanding of the problem domain and the underlying assumptions. If you have limited domain knowledge, it may be more advantageous to choose simpler and more widely-used algorithms.
- Algorithm Performance: Assess the performance of different algorithms on your specific problem. This can be done through experimentation, cross-validation, or by referring to published benchmarks and research papers. Choose an algorithm that not only performs well but also aligns with your objectives.
It’s important to note that choosing the right algorithm may require some trial and error. Experimenting with different algorithms and comparing their performance can help you identify the best one for your problem.
Once you have selected the algorithm, you can proceed to the next step: building the model using your chosen algorithm.
Step 4: Model Building
Now that you have chosen the right algorithm, it’s time to build your machine learning model. Model building involves training the algorithm on the prepared dataset and fine-tuning the parameters to optimize its performance.
Here are the key steps involved in model building:
- Training the Model: Feed the algorithm with the training dataset to enable it to learn the patterns and relationships in the data. The algorithm will iteratively adjust its internal parameters based on the input data and corresponding labels.
- Model Parameter Tuning: Fine-tune the parameters of the model to optimize its performance. This can be done through techniques such as grid search, random search, or Bayesian optimization. Adjusting hyperparameters can help achieve better accuracy, reduce overfitting, and improve the model’s ability to generalize.
- Model Evaluation: Evaluate the performance of your model using the testing dataset that was set aside during the data preparation phase. Use appropriate evaluation metrics to assess the accuracy, precision, recall, or any other relevant metrics based on your problem and objectives.
- Iterative Improvement: If the model’s performance is not satisfactory, iterate through the process of model building by making adjustments to data preprocessing, feature engineering, or algorithm selection. This iterative approach helps in gradually refining the model and ensuring better results.
During the model building phase, it is crucial to strike a balance between underfitting and overfitting. Underfitting occurs when the model is too simple and fails to capture the intricacies of the data, leading to poor performance. On the other hand, overfitting occurs when the model becomes too complex and performs well on the training data but fails to generalize to new data. Regularization techniques can be used to mitigate overfitting.
Remember that building an effective machine learning model requires continuous experimentation, testing, and fine-tuning. By iteratively refining your model, you can achieve better performance and more accurate predictions.
Once you are satisfied with the performance of your model, you can proceed to the next step: model evaluation and improvement.
Step 5: Model Evaluation and Improvement
After building the initial version of your machine learning model, it’s time to evaluate its performance and identify areas for improvement. Model evaluation helps gauge how well your model is performing and provides insights into any necessary refinements or optimizations.
Here are the key steps involved in model evaluation and improvement:
- Evaluation Metrics: Assess the performance of your model using appropriate evaluation metrics. Select metrics that are relevant to your problem and align with your objectives. Common metrics include accuracy, precision, recall, F1-score, and area under the curve (AUC).
- Cross-Validation: Perform cross-validation to validate your model’s performance. This technique involves dividing the data into multiple subsets and evaluating the model on different combinations of training and testing data. Cross-validation provides a more reliable estimate of the model’s performance.
- Identify Improvement Areas: Analyze the evaluation results to identify areas where your model may be underperforming. Look for patterns, trends, or specific data subsets where the model exhibits lower accuracy or higher errors.
- Feature Selection and Engineering: Refine feature selection and engineering techniques to improve the model’s performance. Experiment with different combinations of features, consider domain knowledge, and test feature engineering approaches that may enhance the model’s ability to extract relevant information from the data.
- Parameter Fine-tuning: Fine-tune the model’s hyperparameters to optimize its performance. Adjusting parameters such as learning rate, regularization, or number of hidden layers in neural networks can have a significant impact on the model’s ability to generalize and make accurate predictions.
- Ensemble Methods: Consider ensemble methods to improve the model’s performance. Ensemble methods combine multiple individual models to make more accurate predictions. Techniques like bagging, boosting, or stacking can help mitigate errors and improve overall model performance.
Continuous model evaluation and improvement are essential for maintaining the relevance and accuracy of your machine learning algorithm. Iteratively refining the model based on evaluation results and feedback enhances its ability to generalize and make reliable predictions.
Once you have made the necessary improvements and achieved your desired performance, you can move on to the final step: model deployment and integration.
Step 6: Deployment and Integration
After successfully building and evaluating your machine learning model, the next step is to deploy it into a production environment and integrate it into your existing systems or workflows. Deployment and integration are crucial to ensure that your model can be effectively utilized to generate valuable insights and predictions.
Here are the key considerations for deploying and integrating your machine learning model:
- Choose Deployment Method: Determine the best deployment method for your model. This can include deploying the model on a cloud platform, embedding it into an application, or hosting it as an API. Consider factors such as scalability, accessibility, and cost when selecting the appropriate deployment method.
- Infrastructure and Resource Planning: Plan and allocate the necessary infrastructure and resources for model deployment. Ensure that the deployment environment has the required computational power, storage capacity, and network connectivity to handle the model’s prediction requests efficiently.
- API Design and Documentation: If deploying your model as an API, design a well-defined and user-friendly API interface. Document the inputs, outputs, and expected behavior of the API so that other developers or systems can easily integrate and interact with your model.
- Testing and Performance Monitoring: Conduct thorough testing of the deployed model to ensure its stability, reliability, and accuracy in a production environment. Implement monitoring mechanisms to track the model’s performance, identify any degradation, and prompt necessary updates or retraining as new data becomes available.
- Versioning and Updates: Establish a versioning system for your model and track any updates or improvements made over time. This allows you to deploy new versions without disrupting existing integrations or workflows.
- User Support and Documentation: Provide documentation and support to users who will be utilizing the model’s predictions in their applications or decision-making processes. Clear documentation helps users understand how to interact with the model and interpret its outputs.
Successful deployment and integration ensure that your machine learning model can be seamlessly utilized in real-world scenarios, fostering data-driven decision-making, automation, and improved business outcomes.
With the model deployed and integrated, it’s time to continuously monitor its performance and gather feedback for further improvements. By iterating through this process, you can refine your model and maximize its impact in solving real-world problems.
Conclusion
Building a machine learning algorithm is a fascinating journey that involves several key steps, from defining the problem to model deployment and integration. By following these steps, you can harness the power of data and algorithms to solve complex problems, make accurate predictions, and drive data-driven decision-making.
Throughout the process, it is crucial to have a clear understanding of the problem, collect and prepare data meticulously, choose the appropriate algorithm, build and refine the model through iterative processes, evaluate its performance, and ultimately deploy and integrate it effectively.
Remember to consider the specific characteristics of your problem domain, evaluate different algorithms, and select the most suitable one. Experimentation, testing, and continuous improvement are essential for achieving optimal results. Regular evaluation and refinement are also vital to address any limitations and ensure that your model can perform reliably in real-world situations.
Successful deployment and integration of your machine learning model enable you to leverage its capabilities to generate valuable insights and predictions in various applications, ranging from healthcare and finance to marketing and beyond.
As technology continues to advance, machine learning algorithms will play an increasingly important role in unlocking new possibilities and transforming industries. By mastering the art of building machine learning algorithms, you can contribute to this exciting field, solving complex problems, and driving innovation.
So, dive into the world of machine learning, harness its power, and embark on your journey to build remarkable algorithms that make a meaningful impact on the world.