Introduction
Machine learning has revolutionized various industries by enabling computers to learn and make predictions or decisions without explicit programming. From recommending personalized content to facial recognition, machine learning algorithms have become invaluable tools in our everyday lives. However, as with any technology, there are potential pitfalls that need to be addressed. One of the most critical challenges in machine learning is the presence of bias.
Bias in machine learning refers to the systematic and unfair favoritism or discrimination that can occur in the decision-making process of algorithms. Just like humans, machines can inadvertently adopt biased views and perpetuate unjust outcomes. While bias can emerge from multiple sources, it is important to understand its various forms and the potential consequences it can have on individuals and society.
This article will delve into the concept of bias in machine learning, exploring the different types of bias that can arise in the algorithms, as well as the factors contributing to these biases. Additionally, we will discuss the implications of bias and the challenges involved in mitigating it. Lastly, we will explore strategies that can be employed to address bias in machine learning and promote fairness and equity.
Understanding Bias in Machine Learning
In order to effectively address bias in machine learning, it is crucial to have a clear understanding of what bias entails in this context. In simple terms, bias refers to the tendency of a machine learning algorithm to consistently favor certain groups or outcomes over others. This can be a result of inherent biases in the data used to train the algorithm or biases introduced by the developers during the algorithm’s design.
When a machine learning model is trained, it learns patterns and correlations from the data it is provided. If the training data is flawed or biased, the algorithm can unintentionally learn and perpetuate these biases. For example, if the data used to train a facial recognition algorithm mostly includes images of lighter-skinned individuals, the algorithm may struggle to accurately identify and categorize darker-skinned individuals, leading to biased outcomes.
It is important to recognize that bias in machine learning can manifest in various forms. One common form of bias is called “historical bias.” This occurs when the training data contains historical prejudice or discrimination based on race, gender, or other protected attributes. As a result, the algorithm may make predictions or decisions that reflect these biases, even though they are unfair and discriminatory.
Another form of bias in machine learning is “sample bias.” This occurs when the training data does not effectively represent the target population, leading to inaccuracies or skewed results. For example, if a loan application algorithm is trained on data primarily from affluent communities, it may unfairly favor wealthier individuals and discriminate against those from lower-income backgrounds.
It is also important to note that bias in machine learning can impact various stages of the decision-making process. From data collection and preprocessing to algorithm design and evaluation, bias can be present at each step. Recognizing these different sources and types of bias is crucial in order to implement effective strategies for bias mitigation and promote fairness and ethicality in machine learning algorithms.
Types of Bias in Machine Learning
Bias in machine learning can manifest in different ways, impacting the fairness and accuracy of the algorithm’s predictions or decisions. Let’s explore some of the common types of bias that can arise in machine learning:
- Data Bias: Data bias occurs when the training data used to train the algorithm is unrepresentative or skewed. It can result from historical prejudices, limited sample size, or data collection methods that inadvertently favor certain groups. Data bias can lead to biased predictions and perpetuate unfair treatment of individuals.
- Algorithmic Bias: Algorithmic bias refers to biases that are introduced or amplified during the algorithm’s design or implementation. It can occur when developers unintentionally or knowingly incorporate biased assumptions, features, or decision-making rules into the algorithm. Algorithmic bias can lead to discriminatory outcomes, such as biased hiring decisions or unfair loan approvals.
- Interaction Bias: Interaction bias occurs when bias is introduced through the interaction between the algorithm and users or other systems. It can arise from feedback loops or reinforcement learning processes that reinforce existing biases. For example, if a recommendation algorithm continually suggests content aligned with a user’s pre-existing biases, it can further entrench those biases.
- Measurement Bias: Measurement bias refers to biases that arise due to errors or inconsistencies in the measurement or evaluation of the algorithm’s performance. If the evaluation metrics used to assess the algorithm favor certain groups or fail to capture important aspects of fairness, it can result in biased evaluations and inadequate detection of bias.
It is important to note that these types of bias can often intersect and compound each other, leading to more complex and entrenched biases within the algorithm. Furthermore, biases can impact different groups of people in various ways, resulting in disparities and unfair treatment.
Recognizing these types of bias is a crucial step in mitigating bias in machine learning. By understanding the sources and forms of bias, developers and researchers can implement strategies to address these biases and make machine learning algorithms more fair, transparent, and accountable.
Data Bias
Data is a fundamental building block of machine learning algorithms, and the quality and representativeness of the data used for training greatly impact the fairness and accuracy of the algorithm’s predictions. Data bias occurs when the training data used to teach a machine learning model is unrepresentative or contains inherent biases.
There are several factors that can contribute to data bias. One common source of data bias is the presence of historical prejudice or discrimination. If the training data reflects societal biases, such as biased hiring practices or disparities in healthcare outcomes, the machine learning algorithm can inadvertently learn and perpetuate these biases in its predictions or decisions.
Data bias can also arise from limited or skewed training data. For example, if the training data primarily consists of images of lighter-skinned individuals, a facial recognition algorithm may struggle to accurately identify and categorize individuals with darker skin tones, leading to biased outcomes.
Data bias can also emerge due to biases in the data collection process itself. Biases can be introduced during data collection if certain groups are underrepresented or excluded from the dataset. For instance, if a voice recognition algorithm is trained predominantly on male voices, it may struggle to accurately recognize and transcribe female voices.
It is important to recognize that data bias can perpetuate and amplify existing inequalities and discriminatory practices. When biased data is used to train machine learning models, it can lead to biased outcomes and reinforce systemic biases in society.
Addressing data bias requires careful consideration and proactive measures. One approach is to ensure that the training data is diverse and representative of the target population. This may involve collecting data from a wide range of sources and ensuring proper inclusion of all demographic groups.
Data preprocessing techniques can also be employed to mitigate bias. Methods such as data augmentation and oversampling can help balance the representation of different groups in the training data, reducing potential biases. Additionally, techniques like debiasing and fairness-aware machine learning can be applied to actively counteract the biases present in the data.
Regular monitoring and evaluation of the training data for biases is also crucial. This involves ongoing assessment of the data collection process, identification of potential biases, and taking corrective actions to mitigate them.
To build fair and unbiased machine learning algorithms, it is essential to recognize and address data bias. By ensuring that the training data is representative and diverse, and implementing appropriate preprocessing and evaluation techniques, we can work towards more equitable and fair outcomes in machine learning applications.
Algorithmic Bias
Algorithmic bias refers to biases that are introduced or amplified during the design, development, and implementation of machine learning algorithms. These biases can lead to discriminatory outcomes and perpetuate existing inequalities in society.
Algorithmic bias can arise from various sources. One common source is biased assumptions or decision-making rules that are incorporated into the algorithm. These biases can stem from the biases of the developers or from the limitations of the available data. For example, if a loan approval algorithm is trained using historical data that reflects biases in lending practices, the algorithm may perpetuate those biases and unfairly discriminate against certain groups.
Another form of algorithmic bias is feature bias, which occurs when certain features or attributes in the data are more heavily weighted or given undue importance in the decision-making process. If an algorithm assigns more weight to attributes such as gender or race, it can result in biased outcomes. For instance, an automated resume screening algorithm that favors certain educational backgrounds or specific keywords may discriminate against candidates from marginalized communities.
Feedback loops can also contribute to algorithmic bias. When an algorithm is trained or refined based on user feedback, it has the potential to reinforce existing biases. For example, if a recommendation system consistently reinforces stereotypes or preferences of a particular group, it can perpetuate biases and limit the exposure of users to diverse perspectives or content.
Addressing algorithmic bias requires a multi-faceted approach. It starts with fostering diversity and inclusiveness within the development teams to minimize the incorporation of biased assumptions. Encouraging ethical design practices, such as developing algorithms with fairness and transparency in mind, can also help mitigate algorithmic bias.
Regular auditing and evaluation of algorithms is crucial to identify and address biases. This involves monitoring the outcomes of the algorithm and conducting fairness tests to assess whether it is disproportionately impacting certain groups. If biases are identified, developers can adjust the algorithms and recalibrate the decision-making process to mitigate those biases.
Additionally, involving stakeholders from diverse backgrounds in the design and evaluation process can help uncover and address biases that may have been overlooked. Taking into account multiple perspectives and incorporating ethical guidelines in the algorithmic decision-making can contribute to more fair and inclusive outcomes.
It is important to acknowledge that completely eliminating algorithmic bias is a complex challenge. However, by being aware of the potential for bias, actively working towards addressing it, and implementing robust evaluation and mitigation strategies, we can strive to develop more equitable and unbiased machine learning algorithms.
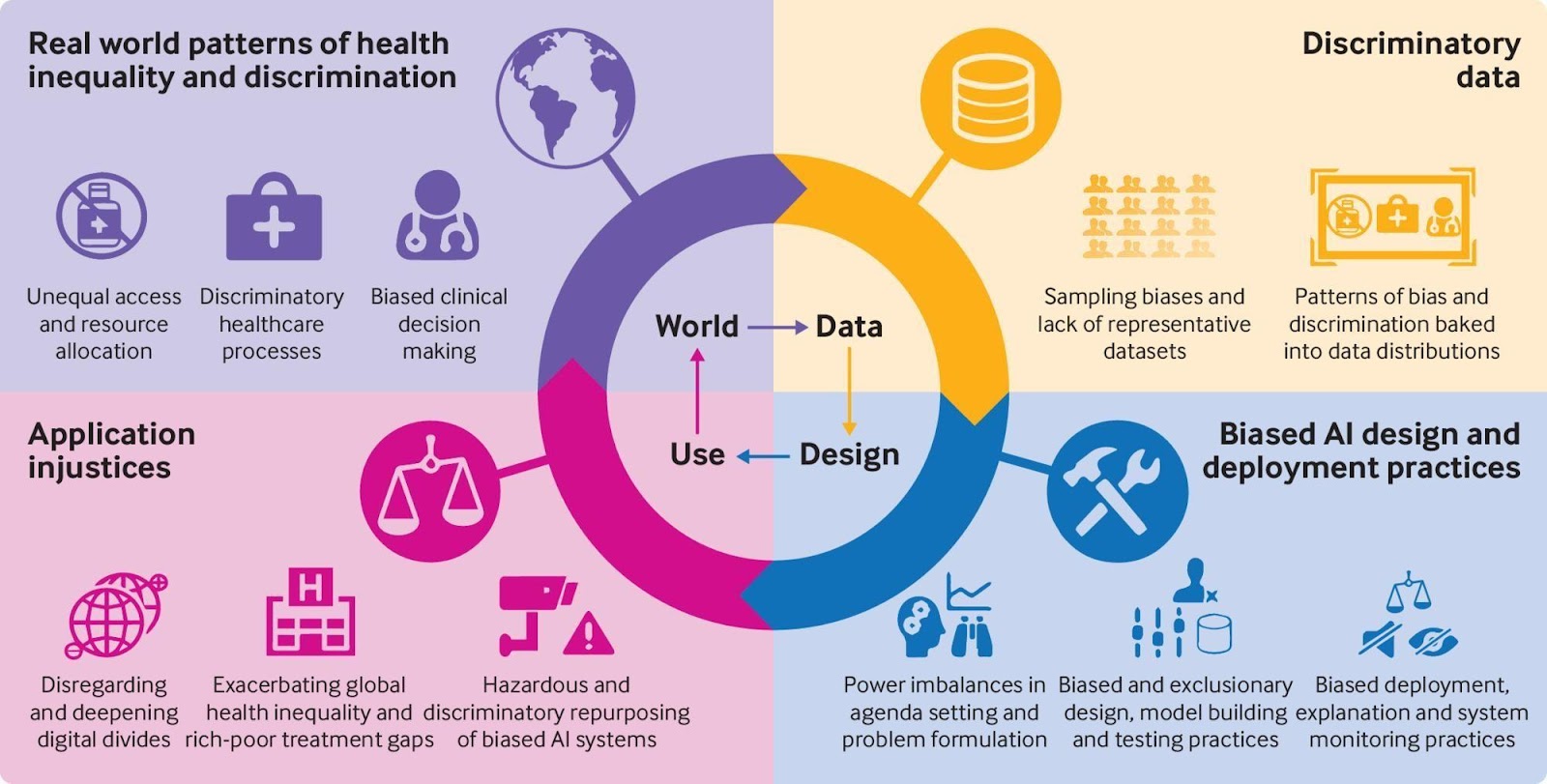
Sources of Bias in Machine Learning
Bias in machine learning can originate from various sources, both within the data used to train algorithms and in the processes involved in algorithm development and implementation. Understanding these sources is crucial to effectively address biases and promote fairness in machine learning applications.
One of the primary sources of bias in machine learning is the data itself. Bias can be inherent in the data due to historical prejudices, systemic inequalities, or limited representation of certain groups. For example, if a facial recognition algorithm is trained using predominantly male faces, it may struggle to accurately recognize and categorize female faces, leading to gender bias. Similarly, if a hiring algorithm is trained using data from a predominantly male workforce, it may inadvertently discriminate against women in the hiring process.
Data collection methods can also introduce biases. If the process of collecting data is not carefully designed to ensure inclusivity and diversity, certain groups may be underrepresented or excluded from the dataset. This can result in biased outcomes when the algorithm is applied. For instance, if a public transportation routing algorithm primarily considers data from affluent areas, it may neglect the needs and accessibility of marginalized communities.
Algorithmic biases can also arise from the design and implementation process. Biases can be unintentionally introduced due to biased assumptions, flawed decision-making rules, or limited perspectives during algorithm development. For example, if the developers of a predictive policing algorithm focus on historical crime data that disproportionately targets marginalized communities, the algorithm may perpetuate biased policing practices.
An additional source of bias is the training process itself, especially if it is not properly supervised or monitored. If the training process is not carefully controlled and biased inputs or guidance are introduced, the algorithm can learn and mimic those biases. This can result in biased outcomes during prediction or decision-making processes.
Lastly, biases can also be introduced due to societal and cultural factors. These biases are embedded in broader social structures, norms, and values. Machine learning algorithms may unintentionally reflect and amplify these biases if not properly addressed. For instance, if a language translation algorithm translates gender-neutral pronouns in a biased manner, it can perpetuate gender stereotypes and inequalities.
Recognizing these various sources of bias is critical in order to develop effective strategies to mitigate bias in machine learning. By addressing biases in the data, data collection methods, algorithm design, and training processes, we can work toward building more fair and inclusive machine learning models.
Impacts of Bias in Machine Learning
Bias in machine learning algorithms can have wide-ranging impacts on individuals, communities, and society as a whole. These biases can perpetuate existing inequalities and discriminatory practices, leading to unfair treatment and limiting opportunities for certain groups. Understanding the impacts of bias is crucial in order to address and mitigate these harmful effects.
One of the significant impacts of bias is the potential for discrimination and unfair treatment. If a machine learning algorithm is biased, it can lead to preferential treatment or discrimination against individuals based on their gender, race, age, or other protected attributes. This can result in barriers to access, such as biased loan approvals, inequitable hiring processes, or unfair allocation of resources.
Bias in machine learning algorithms can also reinforce and exacerbate existing societal biases and stereotypes. If algorithms make decisions based on biased historical data, they can perpetuate discriminatory practices and further entrench societal inequalities. For example, a recommendation algorithm that consistently suggests content aligned with certain stereotypes can reinforce biases and limit individuals’ exposure to diverse perspectives.
Another impact of bias is the potential for amplifying systemic injustices. Biased algorithms can reinforce discriminatory practices and widen existing disparities. This can lead to a lack of representation and opportunities for marginalized communities. For instance, if a facial recognition algorithm has difficulty accurately identifying individuals from certain racial backgrounds, it can contribute to biased surveillance and criminal profiling.
Bias in machine learning algorithms can also erode trust and confidence in the technology. If individuals perceive that algorithms are biased or discriminatory, they may be less willing to engage with or rely on machine learning systems. This can hinder the adoption and potential benefits of machine learning technologies in various domains.
Moreover, biases in machine learning algorithms can result in the perpetuation of misinformation and skewed viewpoints. If algorithms prioritize certain information or perspectives over others, it can limit the diversity of content and hinder the discovery of alternative viewpoints. This can contribute to the spread of misinformation and reinforce echo chambers or filter bubbles.
Finally, the impact of bias extends beyond individuals to society as a whole. Biased algorithms can perpetuate inequities in healthcare, criminal justice, educational opportunities, and other critical domains. This can hinder progress towards a more inclusive and equitable society.
Recognizing the impacts of bias in machine learning is critical in order to create awareness and drive positive change. By actively addressing biases and promoting fairness, transparency, and inclusivity in machine learning algorithms, we can work towards harnessing the potential of technology to benefit all members of society.
Challenges in Addressing Bias in Machine Learning
While addressing bias in machine learning algorithms is crucial, it is not without its challenges. Overcoming these challenges requires careful consideration, collaboration, and innovation. Let’s explore some of the key challenges in addressing bias in machine learning.
Data Availability and Quality: One of the primary challenges is ensuring the availability of diverse and representative data. Collecting and curating unbiased datasets can be difficult, particularly for underrepresented groups or sensitive attributes. Moreover, ensuring the quality and accuracy of the data is crucial to avoid reinforcing biases present in the training data.
Subjectivity and Contextual Bias: Identifying and addressing subjectivity and contextual bias is another challenge. Certain biases can be subjective and context-dependent, making it challenging to define and quantify them objectively. Developing frameworks and guidelines to address these nuances is essential to promote fairness and inclusivity in machine learning algorithms.
Ethical Considerations: Incorporating ethical considerations into algorithm design and decision-making processes poses challenges. Determining the appropriate trade-offs between fairness, accuracy, and other competing factors can be complex. Balancing the needs and values of different stakeholders while avoiding unintended consequences is a critical challenge in addressing bias.
Interpretability and Explainability: Machine learning algorithms, such as deep neural networks, can be highly complex and difficult to interpret. This lack of interpretability can make it challenging to understand how and why biases emerge in algorithmic decisions. Developing techniques to enhance interpretability and explainability can facilitate the identification and mitigation of biases.
Continuous Monitoring and Evaluation: Bias mitigation is an ongoing process that requires continuous monitoring and evaluation. This poses challenges in terms of establishing effective frameworks and metrics to assess algorithmic fairness. Regular auditing and evaluation processes need to be developed to identify and address biases that may emerge over time or due to changing contexts.
Algorithmic Bias Amplification: Addressing bias in one part of the machine learning pipeline can sometimes lead to biases being amplified in other parts. For example, debiasing techniques applied to the training data may inadvertently introduce new biases in the learning process or lead to suboptimal performance. Understanding and mitigating these unintended consequences is a challenge.
Limited Awareness and Expertise: Many developers and practitioners may lack awareness and expertise in addressing bias in machine learning algorithms. Bridging this knowledge gap and fostering a culture of inclusivity and fairness within the machine learning community is crucial. Providing resources, training, and guidelines can help to empower developers and researchers to effectively tackle bias.
Legal and Regulatory Frameworks: Developing appropriate legal and regulatory frameworks to address bias in machine learning poses challenges. Striking the right balance between regulating algorithmic bias while encouraging innovation can be complex. It requires collaboration between policymakers, experts, and stakeholders to create policies that promote fairness and accountability.
While these challenges exist, they should not deter efforts to address bias in machine learning algorithms. By recognizing these challenges and working collaboratively to develop strategies, frameworks, and tools, we can make significant progress in promoting fairness, inclusivity, and ethicality in machine learning.
Strategies to Mitigate Bias in Machine Learning
Addressing bias in machine learning algorithms requires a proactive and multi-faceted approach. By implementing appropriate strategies and techniques, we can work towards mitigating biases and promoting fairness in algorithmic decision-making. Here are some key strategies to consider:
1. Diverse and Representative Training Data: Ensuring that the training data used to train the algorithm is diverse and representative of the target population is crucial. Collecting data from a wide range of sources and including underrepresented groups can help mitigate biases that may arise from limited or skewed datasets.
2. Data Preprocessing Techniques: Applying data preprocessing techniques can help mitigate bias in the training data. Methods such as data augmentation, oversampling, or undersampling can help balance the representation of different groups in the dataset, reducing potential biases.
3. Regular Evaluation and Audit: Regularly evaluating and auditing the algorithm’s outcomes for biases is essential. This involves assessing the fairness and equity of the algorithm’s predictions or decisions and using various evaluation metrics to identify potential biases. If biases are detected, corrective actions can be taken to rectify them.
4. Algorithmic Fairness Techniques: Leveraging algorithmic fairness techniques can help counteract biases introduced during algorithm design and implementation. Techniques such as statistical parity, equal opportunity, and individual fairness can be employed to ensure equitable outcomes across different groups.
5. Transparency and Explainability: Enhancing the transparency and explainability of machine learning algorithms can help identify and mitigate biases. By providing users with clear explanations of how the algorithm works and the factors influencing its decisions, biases can be more easily identified and addressed.
6. Regular Bias Testing: Conducting regular bias testing during the development and deployment of machine learning algorithms can help identify and mitigate biases. Testing for disparate impact, calibration, and other fairness metrics can provide insights into any potential biases and guide improvements.
7. Ethical Guidelines and Governance: Establishing ethical guidelines and governance frameworks can promote responsible and fair deployment of machine learning algorithms. This involves considering the ethical implications of algorithmic decisions, involving diverse stakeholders in decision-making processes, and ensuring ongoing accountability and oversight.
8. Collaboration and Diversity: Encouraging collaboration and fostering diversity within development teams can help address biases from different perspectives. Involving individuals from various backgrounds, disciplines, and communities can help uncover biases and ensure the development of more inclusive and equitable algorithms.
9. User Feedback and Redress: Encouraging user feedback and providing mechanisms for users to address biases is important. Actively soliciting feedback, investigating complaints, and providing redress helps to correct biases and improve the algorithm’s performance over time.
10. Continuous Learning and Improvement: Recognizing that bias mitigation is an ongoing process is crucial. Machine learning algorithms should be continuously monitored, evaluated, and improved to address emerging biases and adapt to changing contexts.
By employing these strategies, we can make significant progress in mitigating bias in machine learning algorithms and working towards more fair and equitable outcomes. It requires a comprehensive and collaborative effort from developers, researchers, policymakers, and users to drive positive change in the field of machine learning.
Conclusion
Bias in machine learning algorithms is a complex and critical challenge that requires attention and proactive measures. As we increasingly rely on these algorithms to make important decisions, it becomes crucial to mitigate biases and promote fairness, transparency, and inclusivity. Throughout this article, we have explored the concept of bias in machine learning, the different types of bias, and the sources from which biases can emerge.
We have discussed the impact of bias, which can perpetuate discrimination, reinforce inequalities, and erode trust in technology. Addressing bias in machine learning algorithms, however, is not without its challenges. The availability of diverse and representative data, subjective and contextual biases, ethical considerations, and limited awareness and expertise are just a few of the hurdles that need to be overcome.
Nevertheless, there are strategies and approaches that can help mitigate bias in machine learning. Ensuring diverse and representative training data, implementing data preprocessing techniques, regular evaluation and audit, algorithmic fairness techniques, transparency and explainability, and ethical guidelines are some of the key strategies that can be employed.
It is important to recognize bias as an ongoing concern that demands continuous monitoring, learning, and improvement. By engaging in collaboration, promoting diversity, and involving multiple stakeholders, we can address biases, challenge assumptions, and foster more equitable and fair machine learning algorithms.
Ultimately, the goal is to harness the potential of machine learning to benefit individuals and society as a whole, while avoiding the reinforcement of biases and discriminatory practices. By actively working towards understanding, acknowledging, and addressing bias in machine learning algorithms, we can strive for a future where these technologies contribute to a more just, inclusive, and equitable world.