Introduction
Welcome to the fascinating world of machine learning! In today’s fast-paced digital age, extracting valuable insights from vast amounts of data has become paramount. Machine learning – a branch of artificial intelligence – offers powerful algorithms and techniques to automate the analysis and decision-making process. One crucial aspect of machine learning is model fitting, which plays a vital role in the accuracy and reliability of predictive models.
In this article, we will delve into the concept of model fitting in machine learning. We will explore the importance of finding the right balance between underfitting and overfitting, and how it affects the performance of a model. By understanding the intricacies of fitting in machine learning, we can design better models that yield accurate predictions and insights.
Before we dive into the details, let’s take a moment to understand what machine learning entails. At its core, machine learning is all about training computers to learn from data patterns and make informed decisions or predictions without being explicitly programmed. Instead, machines use statistical techniques and algorithms to analyze and identify patterns in data, allowing them to make accurate predictions or decisions based on new, unseen data.
Machine learning models can be trained using various algorithms such as linear regression, decision trees, support vector machines, or neural networks. The process involves feeding the model with labeled data – a set of input variables or features and their corresponding output values. The model then learns from this data and creates a mathematical function or model that can predict the output for new, unseen input data.
However, building a machine learning model is not as straightforward as feeding it with data and expecting accurate results. The process involves various complexities and challenges, with model fitting being a crucial aspect to consider.
Model fitting, also known as model training or model estimation, refers to the process of finding the optimal parameters or coefficients of a mathematical function that best represents the relationships between the input variables and the output variable. In simpler terms, it is about adjusting the model’s internal parameters to minimize the difference between the predicted and actual outputs.
In the next sections of this article, we will explore the concepts of underfitting and overfitting, examine how to evaluate model fit, and discuss techniques for improving model fit. So, let’s buckle up and embark on this journey to unravel the mysteries of fitting in machine learning!
Overview of Machine Learning
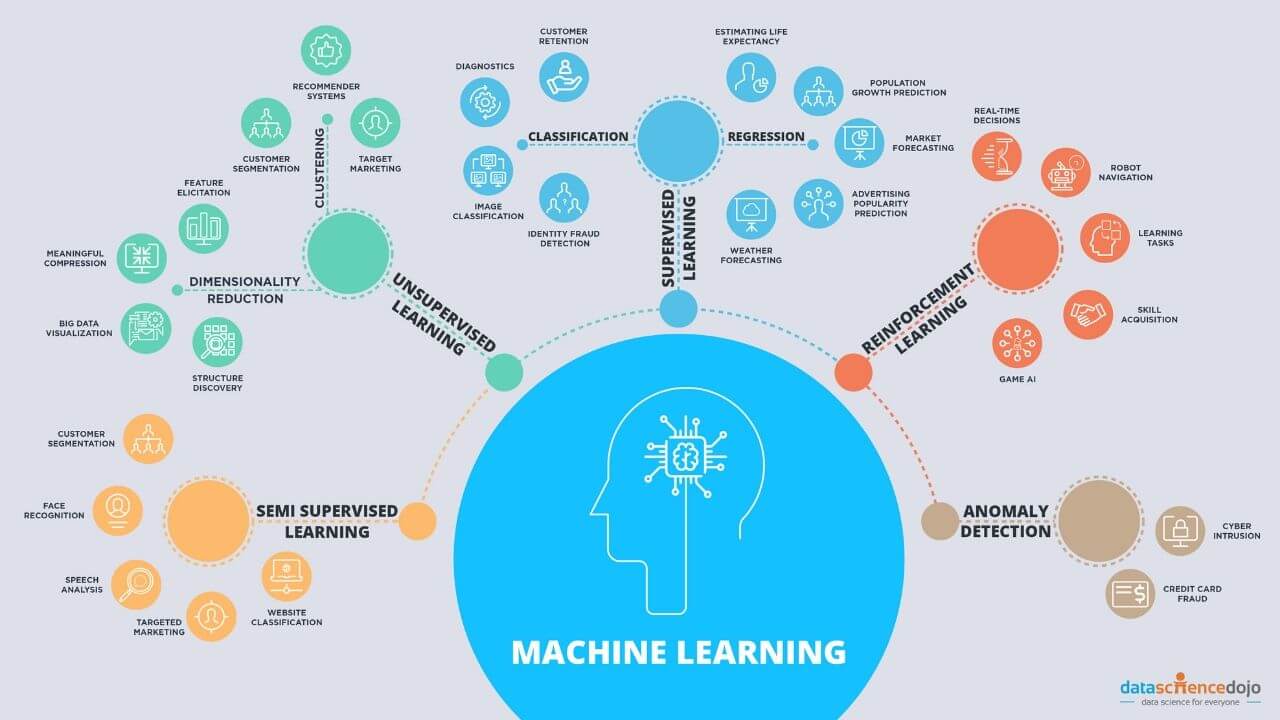
Machine learning is a field of study that enables computers to learn and make predictions or decisions without explicit programming. It is a subset of artificial intelligence (AI) that focuses on algorithms and statistical models to enable computers to analyze large datasets and identify patterns or relationships. By leveraging these patterns, machine learning models can make accurate predictions or decisions on unseen data, allowing businesses and organizations to gain valuable insights and improve decision-making processes.
The main goal of machine learning is to develop algorithms that can automatically learn from data and improve their performance without being explicitly programmed. This is achieved through a process called “training,” where machine learning models are exposed to labeled datasets and adjust their internal parameters to minimize the difference between predicted and actual outputs.
There are several types of machine learning algorithms, each designed to solve specific types of problems. Supervised learning is one such type, where the machine learning model learns from labeled data, with each data point having an associated target or output variable. The model learns to make predictions by finding patterns between the input variables and the target variable.
On the other hand, unsupervised learning involves working with unlabeled data, where the machine learning model seeks to find inherent patterns or structures in the data. Clustering algorithms, dimensionality reduction techniques, and anomaly detection are common applications of unsupervised learning.
Another type of machine learning is reinforcement learning, which involves an agent learning to interact with an environment and make decisions based on feedback or rewards received. The goal is for the agent to learn the optimal strategy or policy over time through trial and error.
Machine learning models require a training phase where they learn from historical data, and a testing or evaluation phase where their performance is assessed on new, unseen data. The accuracy and effectiveness of a machine learning model are evaluated based on various metrics such as accuracy, precision, recall, and F1 score.
Machine learning has a wide range of applications across different industries. In healthcare, it can be used to diagnose diseases or predict patient outcomes. In finance, machine learning models can help detect fraudulent activities or make better investment decisions. Other applications include image recognition, natural language processing, recommendation systems, and autonomous vehicles.
As the field of machine learning continues to evolve, advancements in algorithms, computational power, and data availability are driving rapid progress. Businesses and organizations are increasingly relying on machine learning to gain insights, automate processes, and improve decision-making. Understanding the fundamentals of machine learning and its applications is crucial for anyone looking to harness its power and unlock its potential.
Understanding Fitting in Machine Learning
In machine learning, fitting refers to the process of finding the optimal parameters or coefficients of a model that best capture the relationships between the input variables and the output variable. The goal is to create a model that accurately represents the patterns and trends present in the data, allowing for accurate predictions or decisions on new, unseen data.
When it comes to fitting a machine learning model, there are two primary considerations: underfitting and overfitting. Let’s take a closer look at these two concepts:
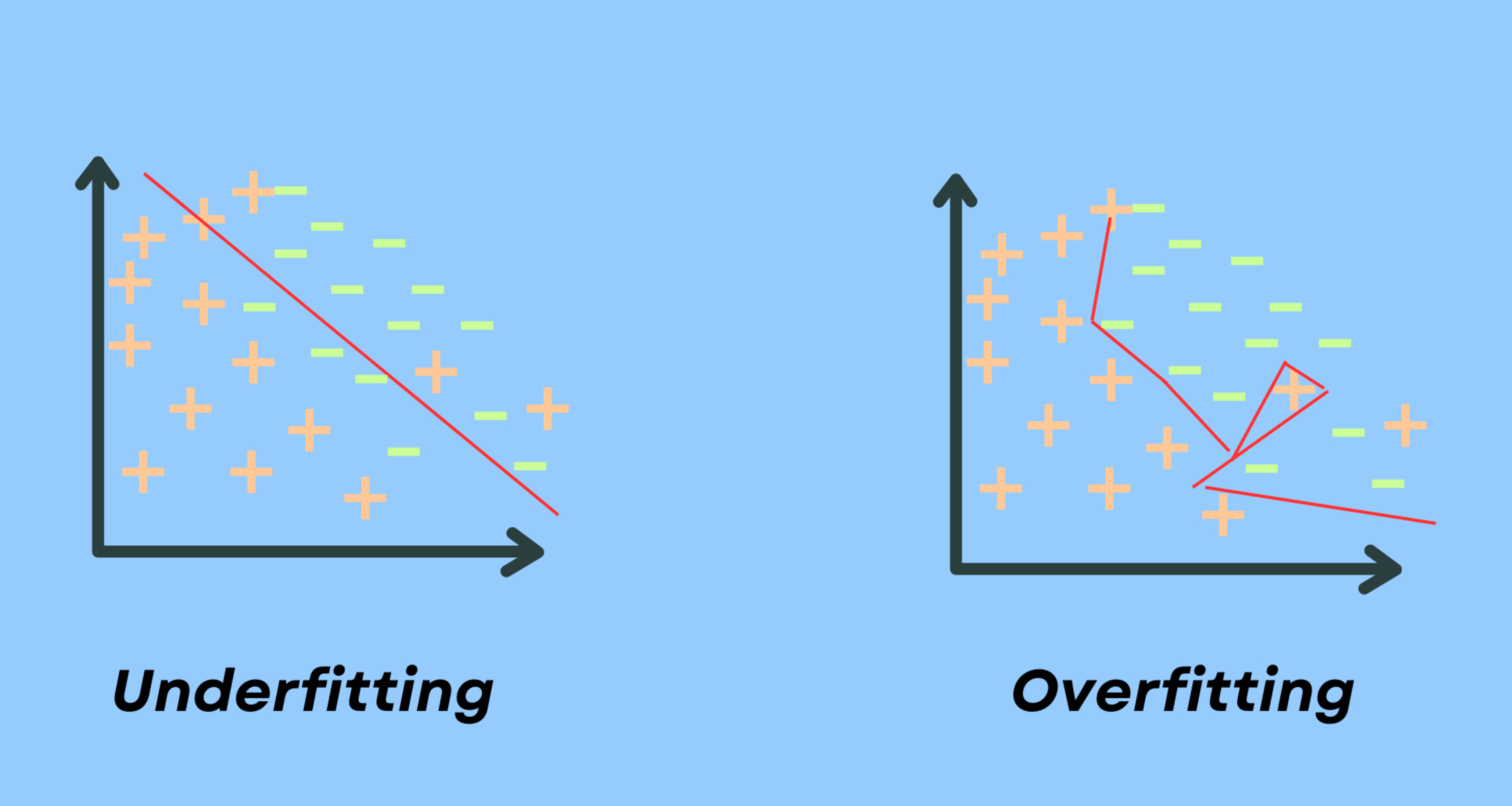
Underfitting: Underfitting occurs when a model fails to capture the underlying patterns or relationships in the data. It happens when the model is too simple or lacks the necessary complexity to accurately represent the data. As a result, an underfit model will have high bias and low variance. This means that the model will consistently provide inaccurate predictions or decisions, regardless of the input data. In essence, an underfit model fails to learn from the training data, and its performance on both the training and testing data is subpar.
Overfitting: Overfitting, on the other hand, happens when a model becomes too complex and starts to “memorize” the noise or random fluctuations in the training data. In this case, the model fits the training data extremely well, but struggles to generalize to new, unseen data. An overfit model has low bias and high variance, meaning it can capture the noise and outliers in the training data, but fails to provide accurate predictions or decisions on new data. Overfitting commonly occurs when the model is too flexible or has too many degrees of freedom, allowing it to fit the noise in the training data rather than the underlying patterns.
The key to achieving good model fitting is finding the right balance between underfitting and overfitting. This balance is often referred to as the “bias-variance trade-off.” Bias refers to the error introduced by approximating a real-world problem with a simplified model, while variance refers to the sensitivity of the model to fluctuations in the training data.
When a model has high bias, it means it is making strong assumptions about the data and oversimplifying the relationships. On the other hand, high variance means the model is highly sensitive to small changes in the training data, leading to overfitting. The ideal model has an optimal level of bias and variance, striking a balance between simplicity and complexity to accurately capture the underlying patterns in the data.
Evaluating the fit of a machine learning model is crucial to ensure its performance and reliability. Different evaluation metrics, such as mean squared error, accuracy, or area under the curve, can be used to quantify how well the model fits the training and testing data. By assessing the performance of the model, we can make informed decisions about improving its fit and generalizability.
In the next sections, we will explore techniques for improving model fit and mitigating the issues of underfitting and overfitting. Understanding the concept of fitting and its impact on machine learning models is essential for developing accurate, robust models that can make reliable predictions or decisions in real-world scenarios.
Underfitting
Underfitting is a phenomenon that occurs when a machine learning model fails to capture the underlying patterns or relationships in the data. It happens when the model is too simplistic or lacks the necessary complexity to accurately represent the data, resulting in high bias and low variance.
When a model underfits, it means that it is unable to learn from the training data and provide accurate predictions or decisions. An underfit model oversimplifies the problem and fails to capture the nuances and complexities present in the data.
There are several reasons why underfitting may occur:
- Inadequate complexity: The model may not have sufficient complexity to accurately represent the relationships between the input variables and the output variable. This can happen when using linear models for data with non-linear relationships, resulting in a poor fit.
- Insufficient training: The model may not have been trained for a sufficient number of iterations or epochs. Insufficient training can prevent the model from converging to an optimal solution and result in underfitting.
- Lack of relevant features: If the model does not have access to all the relevant features or variables that contribute to the outcome, it will struggle to capture the complete picture and underfit the data.
- Over-regularization: Regularization techniques, such as L1 or L2 regularization, are often used to prevent overfitting. However, when applied excessively, regularization can lead to underfitting by excessively penalizing the model’s parameters.
Underfitting can be identified by evaluating the performance of the model on both the training and testing data. An underfit model will exhibit high error rates on both datasets, indicating that it is unable to learn the underlying patterns and generalize to new, unseen data.
Addressing underfitting requires a careful balance between model complexity and the availability of relevant data. Here are some techniques to mitigate underfitting:
- Increase model complexity: If the model is too simplistic, consider using a more complex algorithm or increasing the number of layers, nodes, or features to capture the underlying patterns in the data.
- Collect more data: Insufficient training data can contribute to underfitting. Collecting more relevant data can help the model better understand the relationships and improve its performance.
- Feature engineering: Ensure that the model has access to all relevant features by carefully selecting or engineering features that capture the important characteristics of the data.
- Tune regularization: Adjust the regularization parameters to find the right balance between preventing overfitting and allowing the model to capture the underlying patterns effectively.
By addressing the causes of underfitting and implementing appropriate techniques, it is possible to improve the model’s fit and its ability to provide accurate predictions or decisions. Recognizing underfitting and taking proactive steps to address it is essential for developing robust and reliable machine learning models.
Overfitting
Overfitting is a common problem in machine learning where a model becomes overly complex and starts to “memorize” the noise or random fluctuations in the training data. It occurs when a model fits the training data too closely, but fails to generalize well to new, unseen data.
When a model overfits, it means that it has low bias and high variance. The model can capture the noise and outliers present in the training data, but struggles to make accurate predictions or decisions on new data points.
There are several reasons why overfitting may occur:
- Model complexity: When a model is too complex or has too many parameters, it can easily memorize the training data, including the noise and outliers. This leads to an overly specific model that fails to generalize well.
- Insufficient training data: In some cases, having a small training dataset can contribute to overfitting. With fewer data points, the model may find it easier to fit the noise rather than capturing the underlying patterns.
- Over-reliance on outliers: Outliers in the training data can have a significant impact on the model’s fit. If the model assigns too much importance to these outliers, it can result in overfitting.
- Lack of regularization: Regularization techniques, such as L1 or L2 regularization, are used to prevent overfitting by adding penalties to the model’s parameters. The absence or weak application of regularization can lead to overfitting.
Overfitting can be identified by evaluating the performance of the model on both the training and testing data. While an overfit model may perform exceptionally well on the training data, it will have high error rates when applied to unseen data. The model will struggle to generalize beyond the training set, indicating the presence of overfitting.
To mitigate overfitting, it is crucial to strike a balance between model complexity and the available data. Here are some techniques to combat overfitting:
- Regularization: Apply regularization techniques such as L1 or L2 regularization to add penalties to the model’s parameters, discouraging overfitting.
- Cross-validation: Use techniques like k-fold cross-validation to obtain a more robust estimate of the model’s performance and identify potential overfitting issues.
- Feature selection: Carefully select the most relevant and informative features for the model, discarding irrelevant or noisy features that can contribute to overfitting.
- Ensemble methods: Ensemble methods, such as random forests or boosting, combine multiple models to make predictions. These methods can reduce overfitting by averaging out the individual models’ predictions.
By implementing these techniques, it is possible to reduce the impact of overfitting and improve the model’s ability to generalize to new, unseen data. Recognizing and mitigating overfitting is essential for building robust and reliable machine learning models that can provide accurate predictions or decisions in real-world scenarios.
Balancing Bias and Variance
In machine learning, finding the right balance between bias and variance is crucial for developing accurate and reliable models. Bias refers to the error introduced by simplifying a real-world problem with a model, while variance refers to the model’s sensitivity to fluctuations in the training data.
When working with machine learning models, the goal is to strike a balance between bias and variance to achieve optimal model performance. An overly biased model may oversimplify the relationships in the data and fail to capture important patterns, leading to underfitting. On the other hand, an overly complex model with high variance may fit the training data too closely and struggle to generalize to new, unseen data, resulting in overfitting.
Understanding and managing bias and variance is essential for model selection and optimization. Here are a few key considerations when balancing bias and variance:
- Model complexity: The complexity of a model directly affects the trade-off between bias and variance. Simple models, such as linear regression, have high bias but low variance, as they make strong assumptions and oversimplify the relationships. Complex models, such as deep neural networks, have low bias but high variance, as they can capture intricate patterns in the data and fit noise. It is important to choose a model with appropriate complexity that can effectively capture the underlying relationships without overfitting.
- Regularization: Regularization techniques can help balance bias and variance. By introducing penalties to the model’s parameters, regularization discourages overfitting and reduces variance. Regularization techniques, such as L1 or L2 regularization, help prevent the model from over-relying on specific features or parameters, ensuring a more balanced and generalized fit.
- Data availability: The amount and quality of data play a crucial role in balancing bias and variance. Having more training data can help reduce variance by providing a more representative sample of the underlying population. Additionally, collecting diverse and relevant data can help reduce bias and ensure the model learns to generalize well to new instances.
- Model evaluation: It is important to evaluate a model’s performance on both the training and testing data to assess bias and variance. A model with high bias will perform poorly on both datasets, while a model with high variance will show a significant gap in performance between the training and testing datasets. By analyzing the performance metrics, such as accuracy, precision, or mean squared error, it is possible to determine if the model is balanced or leans towards underfitting or overfitting.
Striking the right balance between bias and variance requires experimentation, iteration, and fine-tuning of different models. Techniques like cross-validation and hyperparameter optimization can help in finding the optimal model configuration that minimizes bias and variance.
Remember, the goal is not to completely eliminate bias or variance but rather to find the right compromise that yields the best overall performance. Balancing bias and variance ensures that the model can adequately capture the essential patterns in the data while maintaining generalizability to new data points, leading to reliable and accurate predictions or decisions.
Evaluating Model Fit
Evaluating the fit of a machine learning model is crucial to ensuring its performance and reliability. By assessing how well the model captures the underlying patterns in the data, we can determine its ability to make accurate predictions or decisions on new, unseen data. Here are some common techniques used for evaluating model fit:
1. Training and Testing Performance: One way to assess model fit is to evaluate its performance on both the training and testing datasets. The model should be trained on a subset of the data, and then tested on a separate set that was not used during training. If the model performs well on the training data but poorly on the testing data, it indicates overfitting. Conversely, if the model performs poorly on both the training and testing datasets, it suggests underfitting.
2. Cross-Validation: Cross-validation is a technique used to estimate a model’s performance by dividing the data into multiple subsets or folds. The model is trained and tested on different combinations of these folds, allowing for a more robust evaluation. Common cross-validation methods include k-fold cross-validation, where the data is divided into k equal-sized parts and the model is trained on k-1 parts and tested on the remaining part. This helps to provide a more reliable estimate of the model’s fit and generalization performance.
3. Performance Metrics: Performance metrics are used to quantify how well a model fits the data. The choice of metrics depends on the specific problem and the nature of the data. For classification tasks, metrics such as accuracy, precision, recall, F1 score, or area under the curve (AUC) can be used. Regression tasks can be evaluated using metrics like mean squared error, mean absolute error, or R-squared. These metrics provide quantitative measures of how well the model fits the data and can be used to compare different models and algorithms.
4. Bias-Variance Analysis: Analyzing the bias and variance of a model can provide insights into its fit. High bias indicates underfitting, while high variance indicates overfitting. By finding the right balance between bias and variance, the model can achieve optimal performance. Techniques like learning curves and validation curves can help visualize the bias-variance trade-off and guide model selection and optimization.
5. Out-of-Sample Validation: An effective way to evaluate model fit is by using an independent validation dataset that was not used during model training. This dataset represents unseen data and helps assess the model’s ability to generalize. The model’s performance on the validation dataset provides a reliable estimate of its fit and can help validate its predictive power in real-world scenarios.
Evaluating model fit is an ongoing process that requires continuous monitoring and refinement. It is important to consider the specific problem, the available data, and the evaluation metrics relevant to the task at hand. By assessing model fit properly, we can make informed decisions about model selection, hyperparameter tuning, and potential improvements to enhance the accuracy and reliability of machine learning models.
Techniques for Improving Model Fit
Improving the fit of a machine learning model is essential for enhancing its accuracy and reliability. Whether the model is underfitting or overfitting, there are several techniques that can be employed to improve its performance and achieve a better fit. Here are some common techniques used to enhance model fit:
1. Increasing Model Complexity: If the model is underfitting, a straightforward approach is to increase its complexity. This can involve using a more sophisticated algorithm or adding more layers, nodes, or features to the model. By introducing more complexity, the model can better capture the underlying patterns or relationships in the data, resulting in improved fit.
2. Feature Engineering: Feature engineering involves transforming or creating new features that better represent the underlying problem. By carefully selecting or engineering features, adding interactions or transformations, or removing irrelevant ones, the model can better capture the important aspects of the data and improve its fit. Domain knowledge and understanding of the problem are crucial in effective feature engineering.
3. Regularization Techniques: Regularization techniques, such as L1 or L2 regularization, can help prevent overfitting by adding penalties to the model’s parameters. Regularization encourages the model to focus on the most informative features and avoid over-reliance on noisy or irrelevant ones. By finding the right balance of regularization strength, the model can achieve improved fit while reducing the risk of overfitting.
4. Ensemble Methods: Ensemble methods combine the predictions of multiple models to obtain a final prediction. Techniques like random forests, bagging, and boosting can improve model fit by reducing overfitting and improving generalization. By combining the strengths of multiple models, ensemble methods help capture a wider range of patterns and provide more accurate predictions or decisions.
5. Cross-Validation and Hyperparameter Tuning: Cross-validation techniques, such as k-fold cross-validation, can help estimate a model’s performance and guide hyperparameter tuning. By systematically evaluating the model’s performance on different folds or subsets of data, optimal hyperparameters can be identified to improve fit. This iterative process helps fine-tune the model and prevent overfitting or underfitting.
6. Increasing Training Data: In some cases, a model may benefit from an increase in training data. More data can help the model capture a broader range of patterns and reduce the risk of overfitting. Collecting additional relevant data or synthesizing new data points can lead to improved model fit and generalization.
7. Iterative Model Evaluation: Regular model evaluation is crucial for monitoring and improving fit. By analyzing performance metrics, bias-variance trade-offs, and learning curves, it is possible to iteratively refine the model. This may involve adjusting hyperparameters, revisiting feature engineering techniques, or experimenting with different model architectures to enhance fit.
Improving model fit requires a thoughtful approach that takes into account the specific problem, available data, and evaluation metrics. Applying these techniques, along with a deep understanding of the problem domain, can lead to models that better capture the underlying patterns in the data and provide more accurate predictions or decisions in real-world scenarios.
Conclusion
In the realm of machine learning, achieving the right fit for models is crucial for accurate predictions and reliable decision-making. Throughout this article, we have explored the concepts of fitting in machine learning, including the challenges of underfitting and overfitting.
Underfitting occurs when models are too simplistic and fail to capture the underlying patterns in the data. On the other hand, overfitting happens when models become overly complex and start to memorize noise or random fluctuations in the training data.
However, finding the balance between bias and variance is key to achieving optimal model fit. Bias refers to error introduced by oversimplifying the model, while variance refers to sensitivity to fluctuations in the training data. Striking the right balance ensures that models can capture the complexities in the data without overfitting or underfitting.
Evaluating model fit is essential for assessing performance and making informed decisions. Techniques such as training and testing performance analysis, cross-validation, performance metrics, and bias-variance analysis can provide valuable insights into the model’s fit and generalization ability.
Finally, improving model fit involves a combination of techniques. Increasing model complexity, feature engineering, regularization, ensemble methods, cross-validation, increasing training data, and iterative model evaluation are approaches that can enhance model fit and overall performance.
By understanding and implementing these techniques, machine learning practitioners can develop models that accurately capture the underlying patterns in the data and make reliable predictions or decisions in real-world scenarios.
As the field of machine learning continues to evolve, it is crucial to stay abreast of the latest advancements, tools, and techniques for improving model fit. The quest for model fit is an ongoing process, and continuous learning and refinement are necessary to harness the full potential of machine learning in solving complex real-world challenges.