Introduction
Machine learning is a powerful technology that has the ability to extract valuable insights from data and make predictions or decisions autonomously. However, like any other modeling technique, it can suffer from certain limitations that hinder its performance. Underfitting is one such limitation that can occur in machine learning algorithms.
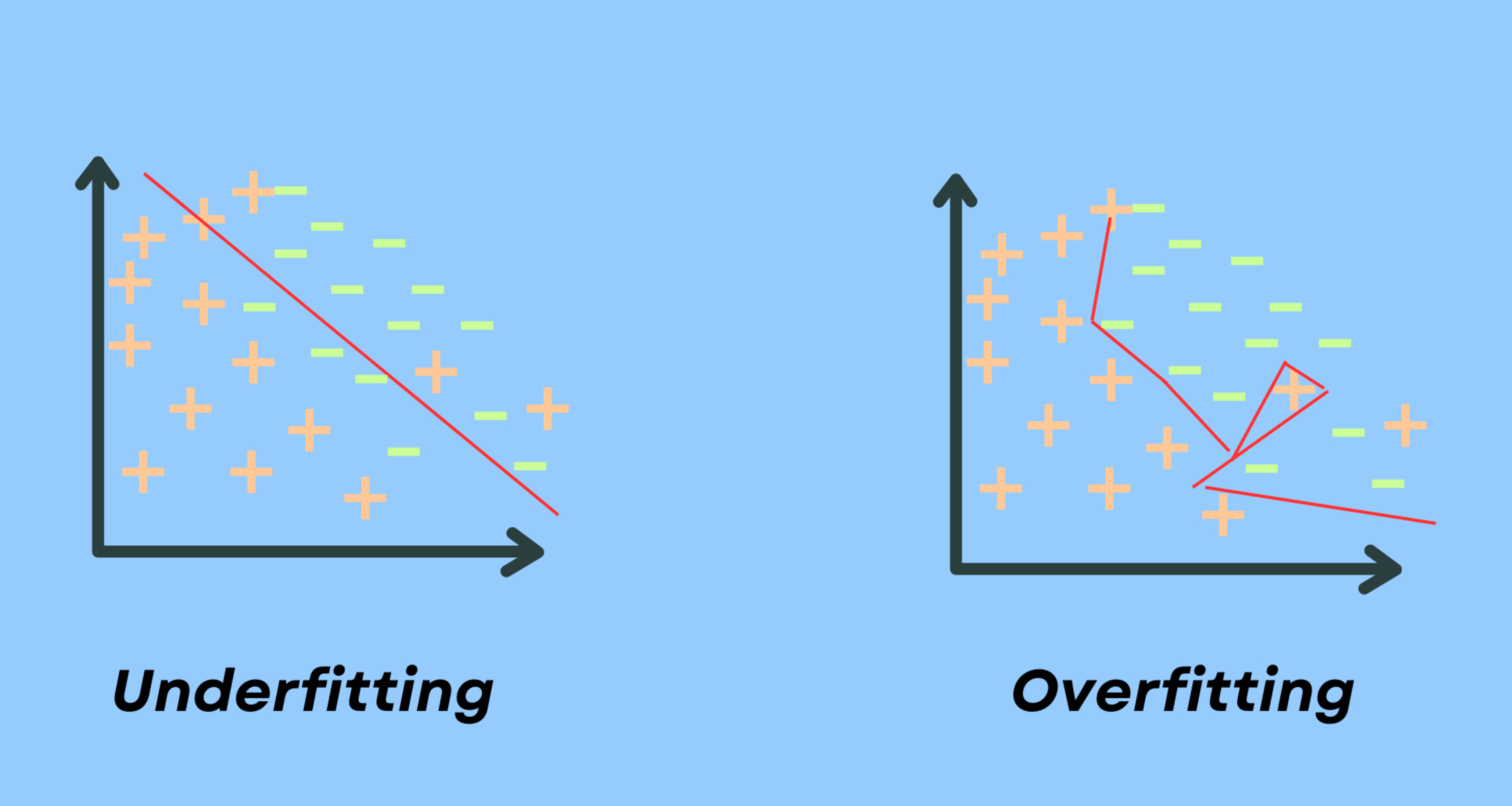
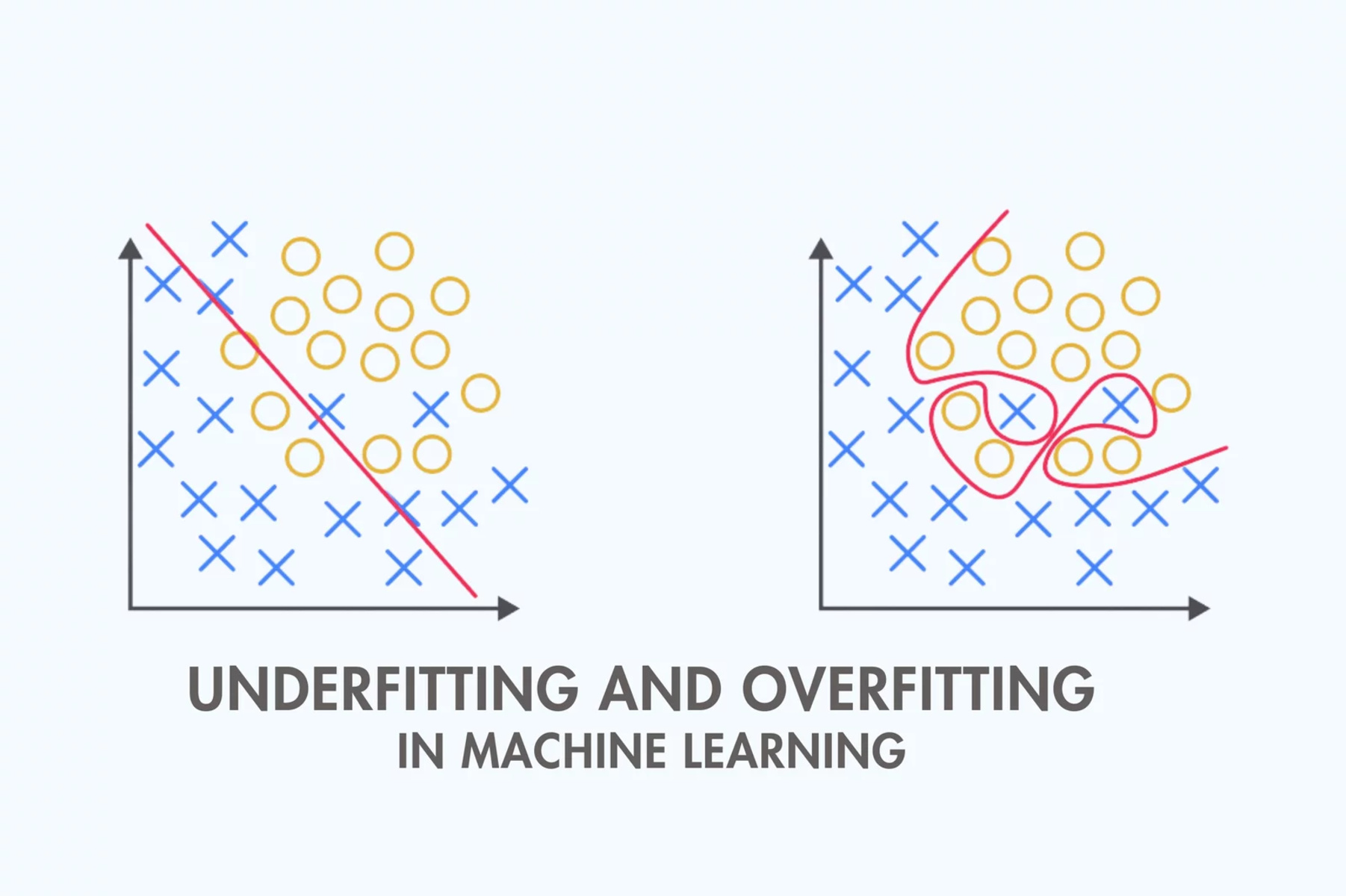
Underfitting refers to a situation where a machine learning model is too simple to capture the underlying patterns in the data. It occurs when the model fails to adequately learn from the training data and therefore performs poorly on both the training and test data. In simple terms, an underfit model is like a student who hasn’t studied enough for an exam and lacks the necessary knowledge to answer the questions correctly.
When a model underfits, it fails to generalize well to unseen data points. This can have serious consequences, as the model may provide inaccurate or unreliable outputs. Underfitting can occur in various machine learning algorithms, including regression, classification, and decision trees.
The causes of underfitting can be traced back to either an excessively simple model or a lack of training data. If the model is too simple, it may not have enough capacity to learn complex patterns. On the other hand, if the training data is insufficient or doesn’t represent the true distribution of the data, the model may not be able to learn the underlying patterns accurately.
It is essential to detect underfitting as early as possible in order to avoid making unreliable predictions or decisions based on faulty models. In the next sections, we will explore the causes, effects, and methods to detect and overcome underfitting in machine learning models.
Definition of Underfitting
Underfitting is a phenomenon that occurs in machine learning when a model is too simple to accurately represent the underlying patterns in the data. It refers to a situation where the model fails to capture important features or relationships in the data, leading to poor performance in both training and testing phases.
When a model underfits, it typically exhibits a high bias. Bias refers to the error introduced when a model makes assumptions about the relationship between the input variables and the target variable. An underfit model has a high bias because it oversimplifies the underlying patterns in the data, making it unable to accurately represent the true relationship.
Underfitting can be caused by various factors. One common cause is using a model that is too simplistic for the complexity of the data. For example, fitting a linear regression model to a dataset that has a non-linear relationship will likely result in underfitting.
Another cause of underfitting is insufficient training data. If the model does not have enough examples to learn from, it may not be able to capture the underlying patterns accurately. The lack of data can lead to an overly generalized model that fails to capture the nuances and intricacies within the dataset.
Underfitting can be detrimental to the overall performance of a machine learning model. It leads to poor predictions or classifications and reduces the model’s ability to generalize well to unseen data. In essence, an underfit model is like an overly simplified representation of the true data distribution, which limits its ability to accurately capture and predict new instances.
Causes of Underfitting
Underfitting can occur in machine learning models due to several factors. Understanding these causes is crucial for identifying and addressing underfitting effectively. Here are some common causes of underfitting:
1. Model Complexity: One of the primary causes of underfitting is using a model that is too simple or has low complexity. For instance, fitting a linear regression model when the underlying relationship between variables is nonlinear can lead to underfitting. Models with low complexity may not be able to capture the complexity of the data, resulting in poor performance.
2. Insufficient Number of Features: Underfitting can also be caused by a lack of informative features in the dataset. If the model has limited inputs or fails to incorporate relevant variables, it may struggle to capture the underlying patterns adequately. Adding more relevant features or conducting feature engineering can help mitigate underfitting caused by insufficient features.
3. Insufficient Training Data: Inadequate training data is another common cause of underfitting. If the dataset used for training the model is too small or unrepresentative of the overall population, the model may not learn the underlying patterns well. Increasing the training data or employing data augmentation techniques can help alleviate underfitting caused by insufficient training data.
4. Over-regularization: Regularization techniques, such as L1 or L2 regularization, are commonly used to prevent overfitting in machine learning models. However, excessive regularization can also lead to underfitting. Setting the regularization parameters too high or using overly aggressive regularization techniques can constrain the model too much, preventing it from learning the true patterns in the data.
5. Data Noise: When the dataset contains a significant amount of noise or irrelevant features, the model may struggle to discern the true underlying patterns. Noise in the data can lead to the model fitting to the noise rather than the actual signal, resulting in underfitting. Data preprocessing techniques, such as removing outliers or performing feature selection, can help mitigate the impact of noise on the model.
By understanding these causes of underfitting, you can take appropriate measures to address them and improve the performance of your machine learning models.
Example of Underfitting
Let’s consider a simple example to demonstrate the concept of underfitting. Suppose we have a dataset with two input variables, X and Y, and a target variable, Z, representing a non-linear relationship. We want to build a regression model to predict Z based on X and Y.
If we use a linear regression model to fit the data, the model’s simplicity may result in underfitting. The linear regression model assumes a linear relationship between the input and target variables. However, in this case, the true relationship is non-linear.
As a result, the linear regression model may struggle to capture the complexity of the data. It will produce a line that does not fit the points well, resulting in a high error or residuals. The model will likely provide inaccurate predictions, both for the training data and unseen test data.
To overcome underfitting in this example, we can employ a more complex model, such as polynomial regression. By introducing higher-order terms or nonlinear transformations of the input features, the polynomial regression model can capture the non-linear relationship between X, Y, and Z more effectively.
By fitting the polynomial regression model to the data, we can observe a better fit that closely follows the data points. This improved model can provide more accurate predictions and reduce the underfitting bias present in the initial linear regression model.
This example highlights the importance of choosing a model that is appropriate for the complexity of the data and the underlying relationships. Using a simplistic model when the data has non-linear patterns can lead to underfitting and hinder the model’s performance.
It is crucial to analyze the data and understand its inherent complexities before selecting and training a machine learning model to avoid underfitting and obtain accurate predictions.
Effects of Underfitting
Underfitting in machine learning models can have various detrimental effects on their performance. Understanding these effects is essential for evaluating and mitigating underfitting effectively. Here are some of the key effects of underfitting:
1. Poor Predictive Accuracy: One of the primary effects of underfitting is a significant reduction in the model’s predictive accuracy. An underfit model fails to capture the complex patterns and relationships present in the data, leading to inaccurate predictions. This can be especially problematic when the model is used for critical decision-making tasks, such as financial forecasting or medical diagnosis.
2. Limited Generalization: Underfitting negatively impacts a model’s ability to generalize well to unseen data points. A model that underfits tends to oversimplify the data, resulting in a high bias. This means that the model may not correctly identify patterns and make accurate predictions on new, unseen data. Consequently, the model’s utility and reliability are greatly compromised.
3. Inability to Capture Complex Relationships: Underfitting can prevent a model from capturing the intricate and nuanced relationships present in the data. In cases where the relationship between the input features and the target variable is non-linear or involves interactions between variables, an underfit model may fail to capture these complexities. This can lead to missed opportunities for extracting valuable insights from the data.
4. Unreliable Decision Making: Underfitting can result in unreliable decision-making based on the model’s outputs. Decision makers and stakeholders rely on machine learning models to provide accurate and actionable insights. However, an underfit model may produce incorrect predictions or classifications, leading to misguided decisions that can have significant consequences.
5. Low Model Confidence: Underfitting often leads to low confidence in the model’s predictions. Confidence intervals and prediction intervals can widen significantly in underfit models, indicating the uncertainty and lack of reliability in the model’s outputs. This can erode trust in the model and make stakeholders hesitant to rely on its predictions and recommendations.
Overall, the effects of underfitting are detrimental to the performance and reliability of machine learning models. It is crucial to address and mitigate underfitting to ensure accurate predictions, reliable decision-making, and confidence in the model’s outputs.
How to Detect Underfitting
Detecting underfitting in machine learning models is crucial to identify and address the limitations of the model’s performance. Here are some approaches to detect underfitting:
1. Training and Testing Performance: One of the simplest ways to detect underfitting is by comparing the model’s performance on the training and testing datasets. If the model performs poorly on both datasets and shows low accuracy or high error rates, it may indicate underfitting. A significant performance gap between the training and testing data suggests that the model is not capturing the underlying patterns accurately.
2. Learning Curve Analysis: Analyzing the learning curve of a model can provide insights into potential underfitting. A learning curve plots the model’s performance (e.g., accuracy or error) against the number of training samples. If the learning curve plateaus early with low training performance and remains consistently low, it suggests underfitting. In contrast, a learning curve that continues to improve with increased training size indicates that the model can benefit from more training data.
3. Model Evaluation Metrics: Monitoring and analyzing evaluation metrics can help identify underfitting. Metrics such as mean squared error, root mean squared error, or classification accuracy can provide insights into the model’s performance. If these metrics show consistently high errors or low accuracy, it may indicate underfitting. Comparing these metrics with benchmarks or industry standards can further clarify the presence of underfitting.
4. Visualization of Predictions: Visualizing the model’s predictions can provide a qualitative assessment of potential underfitting. Plotting the predicted values against the actual values in a scatter plot can reveal any significant deviations. If the predictions do not align closely with the true values and exhibit a scattered pattern, it suggests that the model is not capturing the underlying patterns effectively and may be underfitting.
5. Cross-Validation: Utilizing cross-validation techniques, such as k-fold cross-validation, can help detect underfitting. By partitioning the data into multiple subsets and evaluating the model’s performance on each subset, it becomes possible to assess whether the model is consistently performing poorly across different data splits. Poor performance on multiple cross-validation folds indicates potential underfitting.
It is worth noting that the detection of underfitting is not always straightforward, and multiple assessment approaches may need to be applied for a comprehensive evaluation. Additionally, domain expertise and a deep understanding of the data can contribute to the effective detection of underfitting.
Solutions for Underfitting
Addressing underfitting in machine learning models requires implementing specific strategies to enhance their capacity to capture the underlying patterns accurately. Here are some solutions to mitigate underfitting:
1. Increase Model Complexity: One of the most straightforward solutions for underfitting is to increase the complexity of the model. This can be achieved by using models with higher flexibility, such as deep learning networks, ensemble methods, or polynomial regression. These models have more parameters and can capture more complex relationships in the data.
2. Feature Engineering: Improving the model’s performance can also involve feature engineering techniques. This process involves transforming existing features or creating new ones based on domain knowledge to better represent the underlying patterns. Techniques such as polynomial features, interaction terms, or dimensionality reduction like principal component analysis (PCA) can help uncover hidden relationships and reduce underfitting.
3. Augment Training Data: Insufficient training data can contribute to underfitting. Increasing the size of the training dataset or generating synthetic data through techniques like data augmentation can help improve the model’s ability to generalize. By providing a more diverse and representative set of instances, the model can learn more effectively and reduce underfitting.
4. Regularization Techniques: Regularization techniques can prevent overfitting, but they can also be employed to mitigate underfitting. Methods like L1 or L2 regularization add a penalty to the model’s objective function, discouraging the parameters from becoming too large. By tuning the regularization strength, it is possible to strike a balance and prevent the model from oversimplifying while retaining its ability to generalize.
5. Model Ensemble: Combining multiple models through ensemble methods, such as bagging, boosting, or stacking, can help overcome underfitting. By aggregating predictions from different models, ensemble methods can capture more diverse relationships and enhance the overall predictive performance.
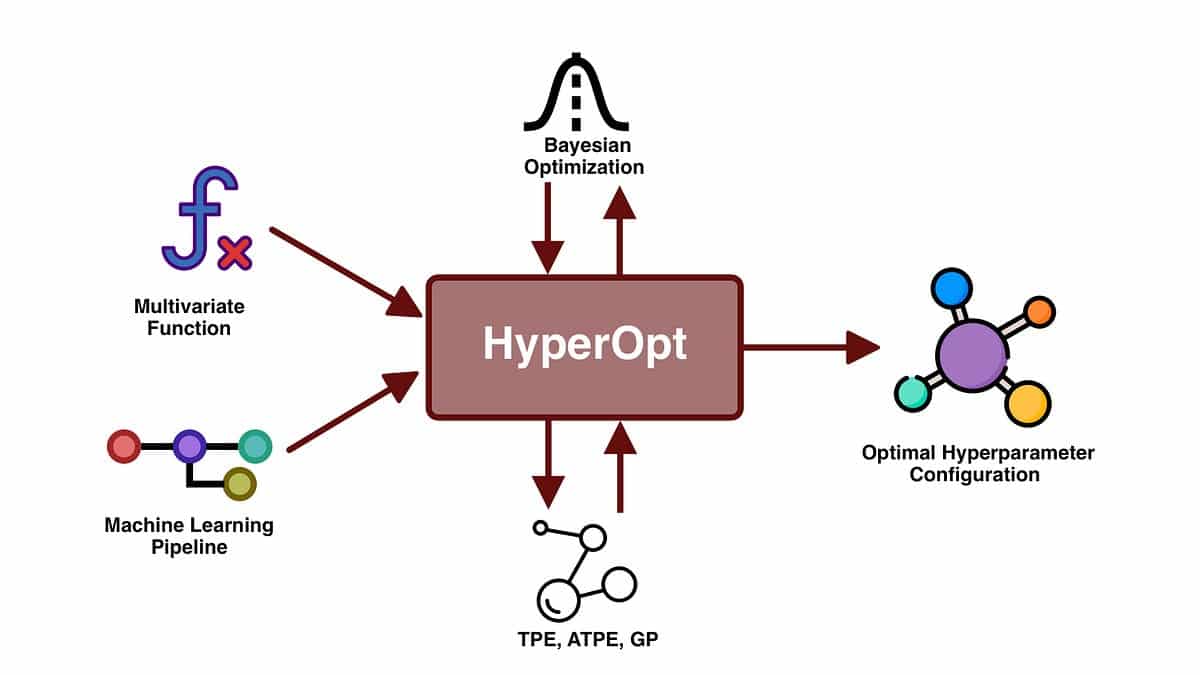
6. Fine-tuning Hyperparameters: Hyperparameters, such as learning rate, number of hidden units, or regularization strength, significantly impact the model’s performance. By thoroughly tuning these hyperparameters, either manually or through automated methods like grid search or Bayesian optimization, it is possible to find the optimal configuration that balances out underfitting and overfitting.
It’s important to note that the choice of solution depends on the specific dataset and problem at hand. A combination of different approaches may be required to effectively mitigate underfitting and improve the model’s performance.
Conclusion
Underfitting is a common challenge in machine learning, where the model fails to capture the underlying patterns in the data due to its simplicity or lack of training. It can lead to poor predictive accuracy, limited generalization, and unreliable decision-making. Detecting and addressing underfitting is essential for building robust and accurate machine learning models.
To detect underfitting, analyzing the training and testing performance, learning curve analysis, and evaluating model metrics can provide valuable insights. Visualization of predictions and cross-validation techniques can also aid in detecting underfitting. However, a thorough assessment combining multiple approaches is recommended for accurate detection.
Various solutions exist to address underfitting. Increasing model complexity, using feature engineering techniques, augmenting training data, employing regularization methods, and leveraging model ensembles are effective strategies. Fine-tuning hyperparameters is also crucial to strike the right balance between underfitting and overfitting.
Overall, addressing underfitting is crucial for improving the performance and reliability of machine learning models. By choosing appropriate models, feature engineering, and maintaining a balance between model complexity and regularization, underfitting can be effectively mitigated. This allows models to accurately capture the underlying patterns, make reliable predictions, and support informed decision-making.