Introduction
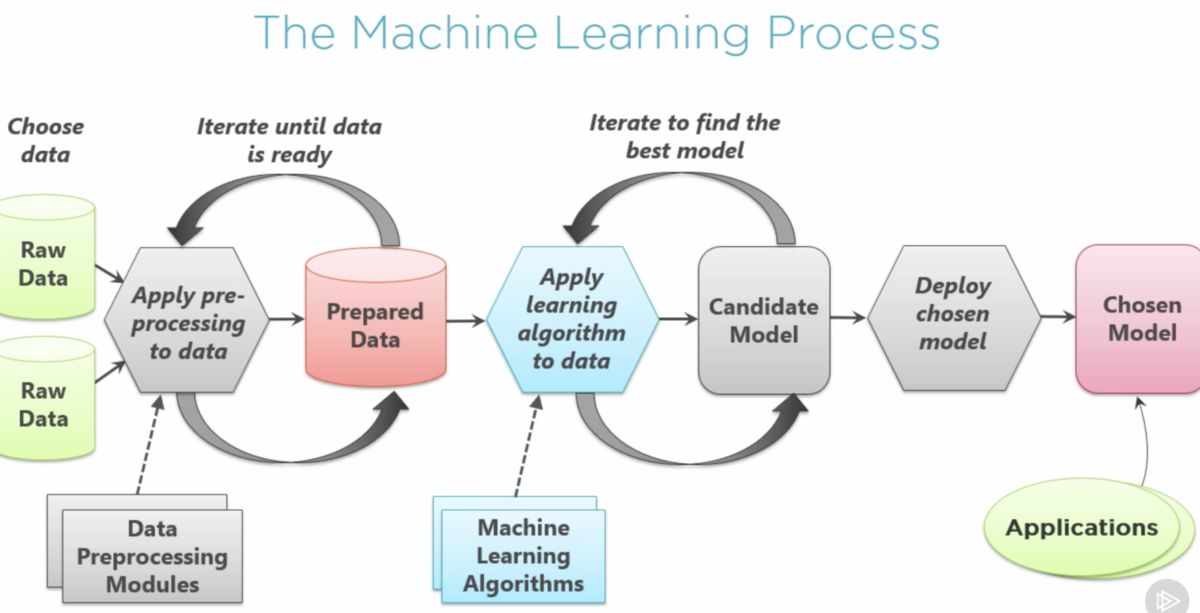
Machine learning algorithms have gained immense popularity and are revolutionizing various industries. These algorithms are capable of learning from data and making accurate predictions or decisions. However, for machine learning models to perform optimally, several factors need to be considered, one of which is hyperparameter tuning.
Hyperparameters are key components of machine learning algorithms that define the behavior and performance of the models. They are not learned from data but rather set manually before training the model. Hyperparameters have a significant impact on the model’s ability to generalize well, avoid overfitting, and make accurate predictions on unseen data.
Understanding hyperparameters and their importance is crucial for anyone involved in machine learning. In this article, we will explore the concept of hyperparameters, their difference from parameters, their role in machine learning, and the techniques used to choose optimal hyperparameters for models.
By the end of this article, you will have a better understanding of hyperparameters and their significance in machine learning, empowering you to improve the performance of your models.
Definition of a Hyperparameter
Before diving into the specifics, let’s define what a hyperparameter is. In the context of machine learning, a hyperparameter is a configuration value or setting that is determined before training a model. It is not learned from the data but rather set by the practitioner or researcher.
Unlike parameters, which are learned from the data during training, hyperparameters are fixed values that define the behavior and characteristics of the machine learning model. Think of hyperparameters as the knobs or dials that you tweak to optimize the performance of your model.
To further illustrate this concept, consider a popular machine learning algorithm like the Support Vector Machine (SVM). Some common hyperparameters for an SVM include the choice of kernel function, the regularization parameter C, and the kernel-specific parameters such as the degree of the polynomial kernel or the gamma value for a radial basis function kernel. These hyperparameters influence how the SVM model fits the data and makes predictions.
The selection of appropriate hyperparameters is crucial as it determines how well the model generalizes to unseen data. Choosing the right hyperparameter values can prevent overfitting (when the model performs well on the training data but poorly on new data) and underfitting (when the model fails to capture the underlying patterns in the data).
It is important to note that the process of finding the optimal values for hyperparameters is known as hyperparameter tuning, and it is typically performed through experimentation and iterative testing.
Difference between Hyperparameters and Parameters
While hyperparameters and parameters are both essential components of machine learning algorithms, it is important to understand the distinction between the two.
Parameters, also known as model parameters, are the internal variables that are learned from the training data during the model fitting process. These parameters define the relationship between the input features and the predicted output. In simpler terms, parameters are the values that the model adjusts to make accurate predictions on the training data.
On the other hand, hyperparameters are external settings that define the behavior and configuration of the learning algorithm. They are not learned from the data but are set manually before training the model. Hyperparameters influence how the model learns and generalizes from the training data.
Let’s consider an example to illustrate this distinction. In a neural network, the weights and biases between the layers are the parameters. During training, these parameters are adjusted to minimize the loss function and improve the model’s performance. The learning rate, number of hidden layers, and number of neurons in each layer are examples of hyperparameters in a neural network. These hyperparameters are set before training the neural network and can greatly impact its performance.
One key difference between hyperparameters and parameters is that hyperparameters are typically defined at the algorithm level, whereas parameters are specific to a trained model. Hyperparameter values are usually shared across multiple training instances of the same algorithm.
Understanding the difference between hyperparameters and parameters is crucial for effectively tuning machine learning models and optimizing their performance.
Importance of Hyperparameters in Machine Learning
Hyperparameters play a critical role in the performance of machine learning models. Choosing the right hyperparameter values can significantly impact the model’s ability to generalize well and make accurate predictions on unseen data. Let’s explore why hyperparameters are important in machine learning:
- Model performance optimization: Hyperparameters determine the configuration of the model and directly impact its performance. By tuning hyperparameters, practitioners can optimize the model’s accuracy, precision, recall, or other performance metrics.
- Preventing overfitting and underfitting: Overfitting occurs when a model learns the training data too well and fails to generalize to new data. Underfitting, on the other hand, happens when a model is too simple and cannot capture the underlying patterns in the data. Properly selecting hyperparameters helps strike the right balance and mitigates the risk of overfitting or underfitting.
- Trade-off between bias and variance: Hyperparameters can influence the bias-variance trade-off. A high-bias model tends to underfit the data, while a high-variance model tends to overfit the data. By appropriately tuning hyperparameters, practitioners can find the optimal trade-off between bias and variance to achieve the best model performance.
- Computational efficiency: Hyperparameters, such as the learning rate or batch size, can affect the computational efficiency of training a model. By fine-tuning these hyperparameters, practitioners can optimize the training time and resource requirements.
- Domain-specific considerations: Different domains and datasets may require different hyperparameter settings. Understanding the domain-specific considerations and tweaking the hyperparameters accordingly can help improve model performance in specific scenarios.
Overall, hyperparameters have a substantial impact on the performance and behavior of machine learning models. By meticulously tuning these hyperparameters, practitioners can optimize their models, prevent overfitting or underfitting, and achieve better predictive performance.
Common Examples of Hyperparameters
Hyperparameters can vary depending on the specific machine learning algorithm used. Here are some common examples of hyperparameters and their significance in model configuration:
- Learning rate: The learning rate determines the step size at which the model adjusts the parameters during training. A higher learning rate can lead to faster convergence but may risk overshooting the optimal solution, while a lower learning rate may result in slower convergence or getting stuck in a suboptimal solution.
- Number of hidden layers and neurons: In neural networks, the number of hidden layers and the number of neurons in each layer are hyperparameters. These parameters control the complexity and capacity of the model. Adding more layers or neurons can increase the model’s ability to learn complex patterns, but it also increases the risk of overfitting if not properly regularized.
- Regularization strength: Regularization is used to prevent overfitting by adding a penalty term to the loss function. The regularization strength hyperparameter controls the amount of regularization applied. A higher regularization strength reduces the model’s flexibility and decreases the risk of overfitting, but it may also lead to underfitting if set too high.
- Kernel choice and hyperparameters: In algorithms like Support Vector Machines (SVM), the choice of the kernel function (e.g., linear, polynomial, or radial basis function) and its associated hyperparameters (e.g., degree of the polynomial kernel, gamma value for the RBF kernel) influence how the model fits the data and can greatly impact the accuracy and complexity of the SVM model.
- Batch size: For algorithms that employ mini-batch stochastic gradient descent, the batch size is a hyperparameter that determines the number of training samples used in each iteration. A larger batch size can improve the stability of the model’s parameter updates, while a smaller batch size may introduce more randomness but can lead to faster convergence.
These are just a few examples of the many hyperparameters that can be tweaked to optimize machine learning models. The choice and proper tuning of these hyperparameters depend on the specific problem, dataset characteristics, and the desired goals of the model.
Techniques to Choose Hyperparameters
Choosing the right hyperparameters is crucial for building machine learning models that perform well. While there is no one-size-fits-all approach, several techniques can help in effectively selecting hyperparameters:
- Expert knowledge and heuristics: Domain experts or practitioners with prior experience in a specific field may have insights into suitable hyperparameter values based on their expertise. These initial values can serve as a good starting point for further fine-tuning.
- Grid search: Grid search involves manually specifying a set of possible values for each hyperparameter and exhaustively evaluating the model’s performance for each combination. This method can be time-consuming but provides a comprehensive evaluation of different hyperparameter combinations.
- Random search: Random search involves randomly sampling hyperparameter values from specified ranges. This approach explores a wider range of hyperparameter space and can often find good hyperparameter combinations more efficiently than grid search.
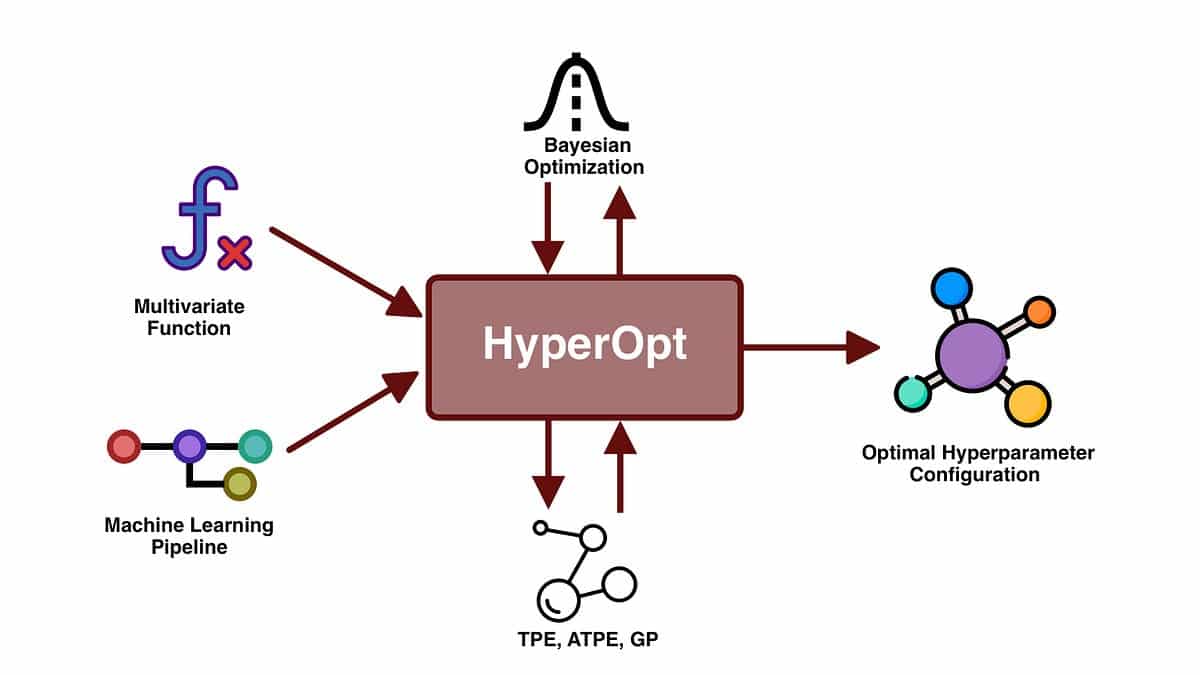
- Bayesian optimization: Bayesian optimization is an iterative method that builds a probabilistic model of the hyperparameter space based on past evaluations. It uses this model to intelligently choose the next hyperparameter combination to evaluate, aiming to find the optimal values with fewer evaluations compared to random or grid search.
- Genetic algorithms: Inspired by the principles of natural evolution, genetic algorithms iteratively search for optimal hyperparameters by mimicking the process of genetic variation, selection, and reproduction. These algorithms can handle a large search space efficiently and may find good hyperparameter combinations in complex optimization problems.
It is important to note that the choice of the technique depends on the computation resources available, the size of the hyperparameter space, and the specific requirements of the problem. It is also advisable to use cross-validation techniques to evaluate the model’s performance for different hyperparameter values and mitigate the risk of overfitting.
Ultimately, the process of selecting hyperparameters involves a combination of knowledge, experimentation, and iterative refinement. It requires a deep understanding of the problem, the data, and the performance trade-offs associated with different hyperparameter settings.
Hyperparameter Tuning Methods
Hyperparameter tuning, also known as hyperparameter optimization, is the process of finding the optimal combination of hyperparameter values that maximizes the performance of a machine learning model. Various methods and algorithms can be employed to tune hyperparameters effectively:
- Grid Search: Grid search involves specifying a grid of hyperparameter values and exhaustively evaluating the model’s performance for each combination. It provides a systematic search over the hyperparameter space, but it can be computationally expensive when the number of hyperparameters and their possible values is large.
- Random Search: Random search randomly samples hyperparameter values from specified ranges. It explores a wider range of hyperparameter space and can often find good hyperparameter combinations more efficiently than grid search. Random search is particularly useful when the impact of individual hyperparameters on the model’s performance is not well understood.
- Bayesian Optimization: Bayesian optimization builds a probabilistic model of the hyperparameter space based on previous evaluations. It intelligently selects the next hyperparameter combination to evaluate, aiming to find optimal values with fewer iterations compared to random or grid search. Bayesian optimization is efficient in scenarios where hyperparameter evaluations are costly.
- Genetic Algorithms: Genetic algorithms mimic the principles of natural evolution to iteratively search for optimal hyperparameters. They use techniques such as mutation, crossover, and selection to create a population of hyperparameter combinations. Genetic algorithms can handle large search spaces efficiently and are particularly useful when there are non-linear relationships between hyperparameters and performance.
- Gradient-based Optimization: Some hyperparameters can be optimized using gradient-based optimization methods. This typically involves computing the gradient of a performance metric with respect to the hyperparameter and updating its value accordingly. Gradient-based optimization is commonly used for hyperparameters that control the learning process, such as learning rate or momentum in neural networks.
It is important to note that the choice of the hyperparameter tuning method depends on factors such as the computational resources available, the size of the hyperparameter space, and the specific requirements of the problem. Additionally, techniques like cross-validation can be employed to assess the model’s performance for different hyperparameter values and ensure robustness.
Hyperparameter tuning is an iterative process that requires experimentation and evaluation of various hyperparameter combinations. By systematically searching and optimizing hyperparameters, practitioners can improve the performance and robustness of their machine learning models.
Cross-Validation in Hyperparameter Selection
When tuning hyperparameters, it is crucial to avoid overfitting to the training data and ensure that the selected hyperparameter values generalize well to unseen data. One commonly used technique for evaluating hyperparameters is cross-validation.
Cross-validation involves dividing the available data into multiple subsets or folds. The model is trained on a subset of the data called the training set and evaluated on the remaining fold(s) called the validation set(s). This process is repeated multiple times, with each fold serving as the validation set once. The performance metrics obtained from the validation sets are averaged to give an estimate of the model’s performance.
During hyperparameter selection, cross-validation helps assess the impact of different hyperparameter values on the model’s performance. By comparing the performance across different hyperparameter settings, practitioners can identify the set of hyperparameters that leads to the best performance on average.
K-fold cross-validation is a common approach, where the data is divided into K folds, and the model is trained and evaluated K times. Other variations include stratified k-fold validation, leave-one-out cross-validation (LOOCV), and nested cross-validation.
It is important to note that the choice of the number of folds (K) in cross-validation can impact the performance estimates. A smaller number of folds may result in higher variance and an unstable performance estimate, while a larger number of folds may increase computation time but provide a more reliable estimate.
By performing cross-validation, practitioners can assess the model’s performance across different hyperparameter values, identify potential overfitting, and select the hyperparameter values that lead to the most robust and generalized model.
Pros and Cons of Hyperparameter Tuning
Hyperparameter tuning can significantly improve the performance of machine learning models, but it is important to consider both the advantages and limitations of this process:
Pros:
- Improved performance: Hyperparameter tuning allows models to achieve better performance by finding the optimal configuration of hyperparameters.
- Generalization: Tuning hyperparameters helps prevent overfitting and underfitting, leading to models that can generalize well to unseen data.
- Customization: Hyperparameter tuning enables practitioners to customize models based on the specific requirements and characteristics of the problem and dataset.
- Fine-grained control: By adjusting hyperparameters, practitioners can fine-tune the trade-off between bias and variance in their models, helping to strike the right balance.
- Domain expertise utilization: Hyperparameter tuning allows practitioners with domain knowledge to leverage their expertise and effectively select hyperparameters.
Cons:
- Computational cost: Hyperparameter tuning often involves evaluating multiple combinations of hyperparameters, which can be computationally expensive, especially when the search space is large.
- Increased complexity: The process of hyperparameter tuning adds an additional layer of complexity to the model development pipeline, requiring careful consideration and experimentation.
- No free lunch: There is no guarantee that hyperparameter tuning will always lead to improved performance. It is a trial-and-error process, and the optimal hyperparameters may vary across different datasets or problems.
- Data dependence: Different datasets may require different hyperparameter settings. Models that perform well on one dataset may not generalize well to another, leading to the need for re-tuning hyperparameters.
Despite the challenges, the benefits of hyperparameter tuning outweigh the limitations in many cases. By carefully considering the pros and cons and using appropriate techniques, practitioners can optimize their machine learning models and achieve better performance.
Conclusion
Hyperparameters are crucial components of machine learning algorithms that significantly impact the performance, generalization, and customization of models. They define the behavior and configuration of the learning algorithm and must be carefully selected to optimize model performance.
In this article, we have explored the definition of hyperparameters, the difference between hyperparameters and parameters, and the importance of hyperparameters in machine learning. We have also discussed common examples of hyperparameters, techniques to choose them, and various methods for hyperparameter tuning.
By fine-tuning hyperparameters, practitioners can improve the accuracy, precision, and robustness of their models. However, hyperparameter tuning comes with both advantages and limitations. It requires computational resources, introduces complexity, and is dependent on the dataset and problem at hand. Nevertheless, the benefits of hyperparameter tuning, such as improved performance and customization, make it an essential step in the machine learning pipeline.
Remember, hyperparameter tuning is an iterative and experimental process that requires knowledge, expertise, and careful evaluation. It is crucial to assess the impact of hyperparameters using techniques like cross-validation and to strike the right balance between underfitting and overfitting.
As machine learning continues to advance, the exploration and optimization of hyperparameters will remain a critical task, enabling practitioners to build models that excel in solving complex real-world problems.