





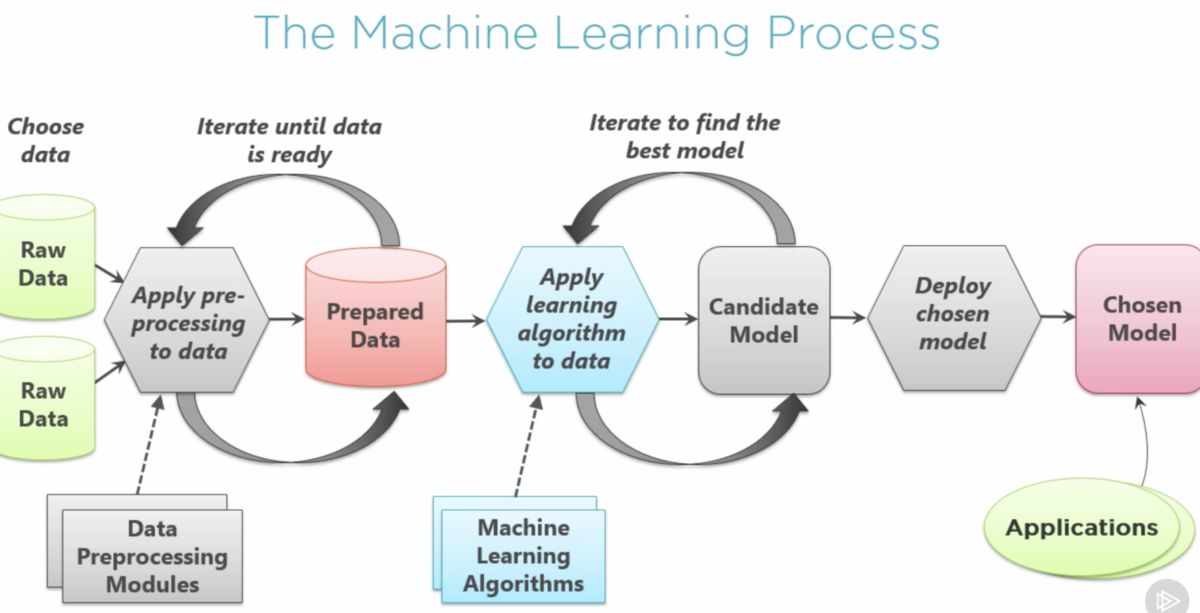
Introduction
Machine learning has revolutionized many industries and has become an integral part of our daily lives. From personalized recommendations on streaming platforms to fraud detection in financial institutions, machine learning algorithms are constantly working behind the scenes to make our lives easier and more efficient.
But what exactly is machine learning? In simple terms, it is a subset of artificial intelligence that enables computers to learn and improve from experience without being explicitly programmed. Instead of following predefined rules, machine learning algorithms take data as input and use statistical techniques to make predictions or decisions.
There are different types of machine learning algorithms, each with its own strengths and applications. Supervised learning algorithms are trained on labeled data to predict outcomes or classify new data points. Unsupervised learning algorithms, on the other hand, find patterns and relationships in unlabeled data without prior knowledge of the output. Lastly, reinforcement learning algorithms learn through trial and error by receiving feedback based on their actions.
Choosing the right machine learning algorithm for a specific task depends on various factors, such as the type and size of the dataset, the desired outcome, and the available computational resources. It requires a thorough understanding of the problem at hand and the strengths and limitations of different algorithms.
Gathering and preparing data is a crucial step in the machine learning process. High-quality and relevant data plays a significant role in the performance and accuracy of the final model. This involves collecting data from various sources, ensuring data integrity, and handling missing or erroneous values. It may also involve data preprocessing techniques, such as feature scaling and normalization, to ensure that the data is in a suitable format for the algorithms.
Feature selection and engineering is another important aspect of machine learning. It involves identifying the most relevant features from the dataset that contribute significantly to the prediction or classification task. This process not only helps in reducing dimensionality but also improves the model’s performance and prevents overfitting.
Once the data is collected, preprocessed, and the features are selected, the next step is to build a machine learning model. This involves choosing the appropriate algorithm, setting hyperparameters, and training the model on the training dataset. The performance of the model is then evaluated on a separate test dataset to assess its generalization capabilities.
The evaluation of the model provides insights into its performance and helps identify areas for improvement. Fine-tuning the model involves tweaking the hyperparameters, adjusting the feature set, or trying out different algorithms to achieve better results. This iterative process continues until satisfactory performance is achieved.
Finally, the trained and fine-tuned machine learning model is ready to be deployed. Whether it’s integrating it into an existing system or creating a standalone application, deploying the model involves making it accessible and functional for real-world applications. It is important to ensure that the deployed model is scalable, secure, and can handle varying input data.
Machine learning has opened up a world of possibilities and continues to evolve rapidly. It has the potential to transform industries and drive innovation in the future. By understanding the machine learning process and following the essential steps, individuals and organizations can harness the power of these algorithms to make informed decisions and gain valuable insights.
What is Machine Learning?
Machine learning is a subset of artificial intelligence that focuses on enabling computers to learn and improve from experience without being explicitly programmed. Instead of following predefined rules, machine learning algorithms analyze data, identify patterns, and make predictions or decisions based on the patterns they discover.
At its core, machine learning is all about algorithms that automatically learn and improve from data. It relies on statistical techniques to find patterns in data and make predictions or decisions without human intervention.
The key idea behind machine learning is that instead of programming computers with explicit instructions to perform specific tasks, we feed them with data and provide algorithms that allow them to learn and improve from that data. This makes machine learning highly adaptable and capable of handling complex problems or tasks that are difficult to program explicitly.
There are three main types of machine learning algorithms:
- Supervised Learning: This type of machine learning algorithm is trained on labeled data, where the input data is associated with corresponding output labels. The algorithm learns to predict or classify new data points based on the patterns it finds in the training data.
- Unsupervised Learning: In unsupervised learning, the algorithm is given unlabeled data and must find patterns or relationships within the data without any prior knowledge of the output. It aims to discover hidden structures or groupings in the data.
- Reinforcement Learning: Reinforcement learning relies on the concept of reward-based learning. The algorithm learns through trial and error by receiving feedback based on its actions. It aims to find the optimal sequence of actions to maximize the cumulative reward.
Machine learning has a wide range of applications across various industries. It is used in natural language processing, image and speech recognition, recommendation systems, fraud detection, autonomous vehicles, and much more.
One of the key advantages of machine learning is its ability to handle large and complex datasets. With the increasing availability of big data, machine learning algorithms can process and analyze vast amounts of data to extract meaningful insights and make accurate predictions.
Machine learning is continuously evolving, with new algorithms and techniques being developed and refined. It requires a solid understanding of statistics, programming, and domain knowledge to effectively apply machine learning algorithms to real-world problems.
In summary, machine learning is a powerful approach that allows computers to learn and improve from data without explicit programming. It has the potential to drive innovation and solve complex problems across various industries, making it a crucial component of artificial intelligence.
Types of Machine Learning Algorithms
Machine learning algorithms can be categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. Each type has its own characteristics and applications, allowing machines to learn and make predictions or decisions based on different types of input data.
1. Supervised Learning: In supervised learning, the machine learning algorithm is trained on labeled data, where the input data points are associated with corresponding output labels. The algorithm learns to map the input data to the correct output labels by finding patterns and relationships in the training data. Examples of supervised learning algorithms include linear regression, logistic regression, decision trees, support vector machines, and neural networks. Supervised learning is commonly used in tasks such as classification, regression, and time series forecasting.
2. Unsupervised Learning: Unsupervised learning algorithms are trained on unlabeled data, where the algorithm aims to find patterns or relationships within the data without any prior knowledge of the output. The goal of unsupervised learning is to discover the underlying structure or groupings in the data. Common unsupervised learning algorithms include clustering algorithms such as k-means, hierarchical clustering, and DBSCAN, as well as dimensionality reduction techniques such as principal component analysis (PCA) and t-SNE. Unsupervised learning is extensively used in tasks such as customer segmentation, anomaly detection, and recommendation systems.
3. Reinforcement Learning: Reinforcement learning is based on the concept of reward-based learning. The algorithm learns through trial and error by taking actions in an environment and receiving feedback in the form of rewards or penalties. The goal of reinforcement learning is to find the optimal sequence of actions that maximize the cumulative reward. Reinforcement learning algorithms include Q-learning, policy gradients, and deep Q-networks. Reinforcement learning is widely used in applications such as game playing, autonomous robotics, and financial trading.
It is worth mentioning that there are also hybrid approaches that combine elements from different types of machine learning algorithms. For example, semi-supervised learning combines labeled and unlabeled data to improve the performance of supervised learning algorithms in scenarios where labeled data is scarce. Transfer learning leverages knowledge learned from one task to improve performance on a different but related task.
Choosing the right type of machine learning algorithm depends on the specific problem, the nature of the data, and the desired outcome. Each type has its own strengths and limitations, and a thorough understanding of the problem at hand is crucial for selecting the appropriate algorithm.
In summary, machine learning algorithms can be categorized into supervised learning, unsupervised learning, and reinforcement learning. Each type has its own unique characteristics and applications, allowing machines to learn and make predictions or decisions based on different types of input data.
Choosing the Right Machine Learning Algorithm
Choosing the right machine learning algorithm is crucial for achieving accurate and reliable results. There is no one-size-fits-all approach, as the choice of algorithm depends on various factors such as the type of problem, the characteristics of the data, and the desired outcome.
Here are some key considerations to keep in mind when choosing a machine learning algorithm:
1. Problem Type: The first step is to determine the type of problem you are trying to solve. Is it a classification problem, a regression problem, or a clustering problem? Depending on the nature of the problem, you can narrow down the choice of algorithms that are specifically designed for that type of problem.
2. Size of the Dataset: The size of the dataset can impact the performance of machine learning algorithms. Some algorithms work well with small datasets, while others are designed to handle large-scale datasets. It is essential to consider the computational requirements and scalability of the algorithm when dealing with large datasets.
3. Data Complexity: Take into account the complexity of the data. Are there non-linear relationships, high-dimensional features, or missing values? Some algorithms are better suited for complex data, such as support vector machines or deep neural networks, while others might be more suitable for simpler data, such as logistic regression or decision trees.
4. Interpretability: Consider whether interpretability is a critical factor in your analysis. Some algorithms, like decision trees or logistic regression, provide transparent and interpretable models that allow you to understand the decision-making process. In contrast, algorithms like artificial neural networks or random forests may provide better accuracy but are less interpretable.
5. Computational Resources: Assess the available computational resources, such as memory and processing power. Some algorithms, like deep learning, require significant computational resources, while others are more lightweight and can be executed on simpler hardware.
6. Algorithm Performance: Investigate the performance of different algorithms on similar tasks or benchmarks. Look for empirical evidence of the algorithm’s performance, such as accuracy, precision, recall, or F1 score. It is also beneficial to consider the algorithms’ robustness to noise or outliers in the data.
7. Domain Knowledge: Finally, consider your domain knowledge and expertise. Some algorithms might be better suited for specific domains or industries. Understanding the problem and the domain can help you choose the most appropriate algorithm and interpret the results effectively.
It is crucial to note that the choice of algorithm may not be final. It may require experimentation and iteration to find the algorithm that best fits your specific problem and data. It is advisable to compare the performance of multiple algorithms, fine-tune the hyperparameters, and evaluate the impact on the results.
By carefully considering these factors, you can choose the machine learning algorithm that aligns with your specific requirements, resulting in accurate predictions or decisions.
Gathering and Preparing Data
Gathering and preparing data is a crucial step in the machine learning process. High-quality and relevant data plays a significant role in the performance and accuracy of the final model. Here are some key considerations when it comes to gathering and preparing data:
1. Data Collection: The first step is to collect the data required for your machine learning task. This may involve gathering data from various sources, such as databases, APIs, web scraping, or even manual data entry. It is important to ensure that the data collected is representative of the problem and covers a wide range of scenarios.
2. Data Integrity: Ensuring data integrity is crucial to obtain reliable results. This involves checking the data for inconsistencies, errors, or missing values. Data cleaning techniques, such as removing duplicates, handling missing data, or resolving inconsistencies, should be applied to address any data quality issues.
3. Data Exploration and Visualization: Exploring and visualizing the data can provide valuable insights and help identify patterns or outliers. Statistical techniques and visualization tools can be used to gain a better understanding of the data distribution, relationships between variables, and potential data issues.
4. Feature Engineering: Feature engineering involves transforming raw data into meaningful features that can enhance the performance of the machine learning model. This may include creating new features, combining existing features, or extracting relevant information from the data. Domain knowledge and understanding the problem can guide the feature engineering process.
5. Data Preprocessing: Preprocessing the data involves preparing it in a suitable format for the machine learning algorithm. This may include data scaling, normalization, or one-hot encoding for categorical variables. Data preprocessing ensures that the algorithm can effectively learn from the data and avoids any biases or inconsistencies.
6. Data Splitting: Splitting the data into training and testing sets is essential to evaluate the performance of the model. Typically, a certain percentage of the data is set aside for testing to assess how well the model generalizes to unseen data. Cross-validation techniques can also be used to avoid overfitting and provide a more robust evaluation.
7. Data Augmentation: In cases where the dataset is small or unbalanced, data augmentation techniques can be used to artificially increase the size or create new data points. This can help improve the model’s performance and prevent overfitting by providing more diverse examples for the algorithm to learn from.
Gathering and preparing data requires careful attention to detail and a thorough understanding of the problem at hand. It is an iterative process that may involve going back and forth between data collection, exploration, and preprocessing to ensure the data is of high quality and suitable for the machine learning task.
By investing time and effort in gathering and preparing the data, you can lay a solid foundation for building accurate and reliable machine learning models.
Feature Selection and Engineering
Feature selection and engineering is a critical step in the machine learning process that involves identifying and preparing the most relevant features from the dataset. Effective feature selection and engineering can significantly impact the performance and accuracy of the machine learning model. Here are some key considerations when it comes to feature selection and engineering:
1. Feature Selection: Feature selection involves identifying the subset of features from the dataset that are most relevant to the machine learning task. This process aims to reduce the dimensionality of the data and eliminate irrelevant or redundant features. Feature selection techniques include statistical methods, such as correlation analysis or feature importance from tree-based models, as well as feature ranking algorithms like Recursive Feature Elimination (RFE) or L1 regularization.
2. Domain Knowledge: A deep understanding of the domain and the problem at hand is invaluable when it comes to feature selection and engineering. Domain experts can provide insights into which features are likely to be influential in the desired outcome. Leveraging domain knowledge can help identify relevant features, create new features, or even discard irrelevant ones.
3. Feature Engineering: Feature engineering involves transforming and creating new features based on the existing data. This process aims to extract meaningful information and capture the underlying patterns or relationships in the data. Techniques for feature engineering include mathematical transformations, binning, one-hot encoding for categorical variables, scaling, normalization, and creating interaction or polynomial features.
4. Handling Missing Data: Missing data is a common challenge in machine learning. Dealing with missing values requires careful consideration, as they can impact the performance of the model. Techniques for handling missing data include imputation methods (such as mean imputation or regression imputation) or creating an additional binary indicator feature to indicate missingness.
5. Feature Scaling: Feature scaling is an essential preprocessing step that ensures all features are on a similar scale. This is particularly important for algorithms that rely on distance-based calculations, such as support vector machines or k-nearest neighbors. Common scaling techniques include standardization (z-score normalization) or min-max scaling to a specific range.
6. Feature Importance: Understanding the importance of different features can provide insights into their contributions to the machine learning model’s predictions or decisions. Techniques like feature importance from tree-based models or permutation importance can help identify the most influential features.
7. Iterative Process: Feature selection and engineering are often iterative processes that involve experimenting with different combinations of features, evaluating the impact on the model’s performance, and refining the feature set accordingly. It may require multiple iterations and fine-tuning to find the optimal feature set for the specific machine learning task.
By focusing on feature selection and engineering, you can enhance the performance of your machine learning model, improve interpretability, and mitigate the risk of overfitting. Extracting the most relevant information from the data leads to more accurate predictions or decisions, allowing you to gain valuable insights from your machine learning analysis.
Building a Machine Learning Model
Building a machine learning model involves selecting the appropriate algorithm and configuring it to analyze the data and make predictions or decisions. This step is crucial for the success of your machine learning project, and it requires careful consideration and understanding of the problem at hand. Here are some key steps to consider when building a machine learning model:
1. Algorithm Selection: Selecting the right algorithm for your machine learning task is essential. Consider the problem type, the nature of the data, and the desired outcome. Supervised learning algorithms such as linear regression, decision trees, support vector machines, or neural networks are commonly used for classification and regression tasks. Unsupervised learning algorithms such as clustering or dimensionality reduction techniques can be utilized for exploratory analysis. Reinforcement learning algorithms are suitable for scenarios involving trial-and-error learning.
2. Configuration and Hyperparameters: Configure the algorithm by setting its hyperparameters, which are parameters that control the learning process. Hyperparameters can affect the performance and behavior of the model. Tuning the hyperparameters requires experimentation and validation to find the optimal values. Techniques such as grid search, random search, or Bayesian optimization can be used to optimize the hyperparameter settings.
3. Training Data: Split your data into training and testing sets. The training set is used to train the model by providing inputs and the corresponding expected outputs. It is crucial to ensure that the training data is representative and diverse enough for the model to learn from. The testing set is used to assess the model’s generalization capabilities and evaluate its performance.
4. Model Training: Train the model on the training data using the chosen algorithm and the configured hyperparameters. During training, the model learns the underlying patterns and relationships in the data. The training process aims to minimize the difference between the model’s predicted outputs and the expected outputs.
5. Model Evaluation: Evaluate the trained model using the testing data. Common evaluation metrics depend on the task at hand and may include accuracy, precision, recall, F1 score, or mean squared error. Evaluating the model helps assess its performance, identify potential issues (such as overfitting or underfitting), and compare different models or approaches.
6. Model Optimization: If the model performance is not satisfactory, further optimize the model by adjusting the hyperparameters, refining the feature set, addressing data quality issues, or trying different algorithms. This iterative process helps improve the model’s performance and achieve better results.
7. Model Persistence: Once you have a trained and optimized model, you may want to save it for future use. Model persistence involves storing the trained model’s parameters and architecture so that it can be loaded and used later for making predictions on new, unseen data.
Building a machine learning model is a dynamic process that involves selecting the right algorithm, configuring hyperparameters, training the model, evaluating its performance, and optimizing the results. With careful attention to these steps, you can create a powerful machine learning model that effectively solves your specific problem and makes accurate predictions or decisions.
Training and Testing the Model
Training and testing the model is a crucial step in the machine learning process that evaluates the model’s performance and assesses its ability to generalize to new, unseen data. This step ensures that the model is reliable and capable of making accurate predictions or decisions. Here are some key steps to consider when training and testing a machine learning model:
1. Data Split: Split the available dataset into a training set and a testing set. The training set is used to train the model, while the testing set is used to evaluate its performance. A common split is to allocate a certain percentage of the data, such as 70-30 or 80-20, for training and testing, respectively.
2. Training the Model: Feed the training data into the model for the learning process. The model takes the input features and corresponding output labels to adjust its internal parameters and learn from the data. The training process aims to minimize the difference between the model’s predictions and the actual output labels.
3. Model Evaluation: Once the model is trained, evaluate its performance using the testing set. The testing set contains input data points that the model has not seen during training. By making predictions on the testing set and comparing them to the actual output labels, you can assess how well the model generalizes to new, unseen data.
4. Evaluation Metrics: Choose appropriate evaluation metrics based on the problem type. For classification tasks, metrics such as accuracy, precision, recall, F1 score, or area under the receiver operating characteristic (ROC) curve can be used. For regression tasks, metrics like mean squared error (MSE) or mean absolute error (MAE) are commonly used. These metrics provide quantitative measures of the model’s performance.
5. Performance Analysis: Analyze the model’s performance by interpreting the evaluation metrics and considering any specific requirements or constraints of the problem. Determine if the model meets the desired performance threshold and whether it satisfies the business objectives.
6. Generalization and Overfitting: Pay attention to signs of overfitting, where the model memorizes the training data instead of learning the underlying patterns. Overfitting can lead to poor performance on unseen data. Techniques such as regularization, early stopping, or increasing the training data can help mitigate overfitting and improve generalization.
7. Model Refinement: If the model’s performance is unsatisfactory, consider refining the model by adjusting hyperparameters, revisiting the feature selection process, or using different algorithms. Iteratively refine the model until the desired performance is achieved.
Training and testing the model validate its capability to make accurate predictions or decisions on unseen data. By careful evaluation, analysis, and refinement, you can improve the model’s performance and ensure that it is reliable for real-world applications.
Evaluating and Fine-tuning the Model
Evaluating and fine-tuning the model is an iterative process that helps to improve its performance, fine-tune the parameters, and enhance its overall accuracy. This step is crucial in ensuring that the model is robust, reliable, and capable of making accurate predictions or decisions. Here are some key steps to consider when evaluating and fine-tuning a machine learning model:
1. Evaluation Metrics: Select appropriate evaluation metrics based on the problem type and the desired outcomes. Common evaluation metrics for classification tasks include accuracy, precision, recall, F1 score, and area under the receiver operating characteristic (ROC) curve. For regression tasks, metrics like mean squared error (MSE) or mean absolute error (MAE) are commonly used.
2. Cross-validation: Utilize cross-validation techniques, such as k-fold cross-validation, to obtain a more robust evaluation of the model. Cross-validation divides the data into multiple subsets (folds) and trains the model on different combinations of the folds. This helps to reduce the bias in performance estimation and provides a more accurate assessment of the model’s generalization capabilities.
3. Model Comparison: Compare the performance of different models or variations of the same model to identify the best-performing one. Consider different algorithms, hyperparameter settings, or feature selections to assess their impact on the model’s performance. This process helps in selecting the most effective and efficient model for the given task.
4. Overfitting and Underfitting: Beware of overfitting, where the model performs exceedingly well on the training data but fails to generalize to unseen data. Similarly, underfitting occurs when the model is too simplistic and fails to capture the underlying patterns in the data. Fine-tuning the model involves striking a balance to minimize overfitting and underfitting by adjusting hyperparameters, using regularization techniques, or increasing the complexity of the model.
5. Feature Selection and Engineering: Revisit the feature selection and engineering process to refine the set of features used in the model. Remove irrelevant or redundant features that may lead to noise or bias. Experiment with different feature engineering techniques to extract more informative features that can improve the model’s performance.
6. Hyperparameter Optimization: Fine-tune the model’s hyperparameters to optimize its performance. Hyperparameters control the learning process and architecture of the model. Apply techniques such as grid search, random search, or Bayesian optimization to find the optimal combination of hyperparameters for the given task.
7. Validation Set: Apart from the training and testing sets, set aside a validation set from the data to evaluate the model during the fine-tuning process. The validation set helps to assess the model’s performance on unseen data and aids in making decisions about hyperparameter adjustments or feature selection.
By evaluating and fine-tuning the model, you can enhance its performance, improve its generalization capabilities, and ensure that it is robust and reliable. This iterative process helps to identify areas of improvement and optimize the model to achieve better accuracy and predictive power.
Deploying the Machine Learning Model
Deploying a machine learning model involves making it accessible and functional for real-world applications. It is the final step in the machine learning process, where the model is put into production and used to make predictions or decisions on new, unseen data. Here are key steps to consider when deploying a machine learning model:
1. Model Packaging: Package the trained model into a format that can be easily deployed and used. This may involve saving the model weights, architecture, or parameters into a file or container that can be loaded and executed efficiently.
2. Integration: Integrate the model into existing systems or applications to seamlessly incorporate its functionality. This may involve connecting the model to APIs, databases, or other data sources to ensure a smooth flow of data between the model and the application.
3. Scalability: Optimize the model’s performance and scalability to handle large volumes of data and high traffic demands. This may involve techniques such as parallelization, distributed computing, or utilizing cloud computing services to ensure the model can efficiently handle real-time predictions or decisions.
4. Input Data Validation: Validate and preprocess the input data to ensure it meets the model’s requirements and is in the expected format. This may involve data formatting, scaling, or performing any necessary preprocessing steps to make the data compatible with the model.
5. Model Monitoring: Implement a system to continuously monitor the model’s performance and health. This includes monitoring input data quality, prediction accuracy, model drift, and other key metrics. By monitoring the model, you can identify any issues or deviations from the expected behavior and take appropriate actions.
6. Security Considerations: Ensure the security of the deployed model and the data it processes. Implement measures such as encryption, access controls, and authentication mechanisms to protect sensitive data and prevent unauthorized access to the model or predictions.
7. Documentation and Versioning: Properly document the deployed model, including its functionality, inputs, and outputs. Additionally, maintain version control to track changes and updates made to the model. This facilitates reproducibility, debugging, and collaboration in future development or enhancement of the model.
Deploying a machine learning model requires careful planning, integration, and optimization to ensure its successful integration into the target system. By following these steps, you can make your machine learning model accessible, scalable, and secure, allowing it to provide valuable insights and predictions in real-world applications.
Conclusion
Machine learning is a powerful tool that has revolutionized many industries by allowing computers to learn and make predictions or decisions without being explicitly programmed. Understanding the machine learning process and following best practices is crucial for achieving accurate and reliable results.
Throughout this article, we have explored various stages of the machine learning journey. It starts with gathering and preparing data, ensuring its quality and relevance. Feature selection and engineering help identify the most important features that contribute to the model’s performance.
Building a machine learning model involves selecting the appropriate algorithm, configuring its hyperparameters, and training it on the data. Evaluating the model’s performance and fine-tuning it based on evaluation metrics gives insights into its accuracy and generalization capabilities.
Finally, deploying the machine learning model involves making it accessible, integrating it into existing systems, and ensuring scalability and security. Monitoring the model’s performance and version control documentation are crucial for ongoing maintenance and improvement.
By following these steps, we can harness the power of machine learning to gain valuable insights, make data-driven decisions, and drive innovation across various industries.
Machine learning continues to evolve, with new algorithms and techniques being developed. Staying up-to-date with advancements and continuously refining our models allows us to leverage the full potential of this exciting field. With careful consideration of data, feature engineering, algorithm selection, model evaluation, and deployment, machine learning can be a powerful tool that drives meaningful impact and empowers us to tackle complex problems in the modern world.
















