Introduction
Machine learning has emerged as a revolutionary field in the ever-evolving realm of technology. With the ability to analyze vast amounts of data and uncover patterns, machine learning algorithms have opened up a world of possibilities. Predicting, one of the core components of machine learning, enables the algorithms to make intelligent forecasts and estimations based on the available data.
Predicting in machine learning refers to the process of using historical data to make predictions about future events or outcomes. This is achieved by training a model on the existing data and then using this model to predict the outcome of unseen data. Predicting algorithms are designed to find relationships and patterns within the data that can be used to make accurate predictions.
The ability to predict future outcomes is immensely valuable in various domains such as finance, healthcare, e-commerce, and more. By leveraging predictive capabilities, businesses can make informed decisions, optimize operations, and gain a competitive advantage in the market.
As technology continues to advance, the importance of predicting in machine learning grows exponentially. With the abundance of data available, the potential for deriving meaningful insights and making accurate predictions becomes even more significant.
In this article, we will delve deeper into the concept of predicting in machine learning. We will explore different types of predictions, discuss their importance, and highlight the evaluation metrics used to measure their accuracy. By the end of this article, you will have a solid understanding of the role of predicting in machine learning and its significance in various industries.
What Is Predicting in Machine Learning?
Predicting in machine learning is the process of using historical data to make accurate estimations or forecasts about future events or outcomes. It involves training a machine learning model on a dataset containing features (input variables) and corresponding labels (output variables). The model learns patterns and relationships within the data, and then applies this knowledge to predict the value of the label for new, unseen instances.
The primary objective of predicting is to minimize the error or deviation between the predicted outcomes and the actual outcomes. Machine learning algorithms employ various techniques to accomplish this, such as regression, classification, and time series analysis.
Predicting plays a vital role in many domains across various industries. For instance, in finance, predicting is utilized to forecast stock prices, identify market trends, and assess investment risks. In healthcare, predicting can help diagnose diseases, predict patient outcomes, and recommend personalized treatments. E-commerce companies use predicting to understand customer behavior, make product recommendations, and optimize pricing strategies.
To make accurate predictions, machine learning models require high-quality and relevant data. The dataset used for training the model should be representative of the real-world scenarios and include a diverse range of input features. It is crucial to preprocess and clean the data to handle missing values, outliers, and other anomalies that may impact the model’s performance.
Furthermore, feature selection and engineering are essential steps in predicting. Selecting the most relevant features can improve the model’s efficiency and accuracy. Additionally, transforming and creating new features based on domain knowledge can enhance the model’s predictive capabilities.
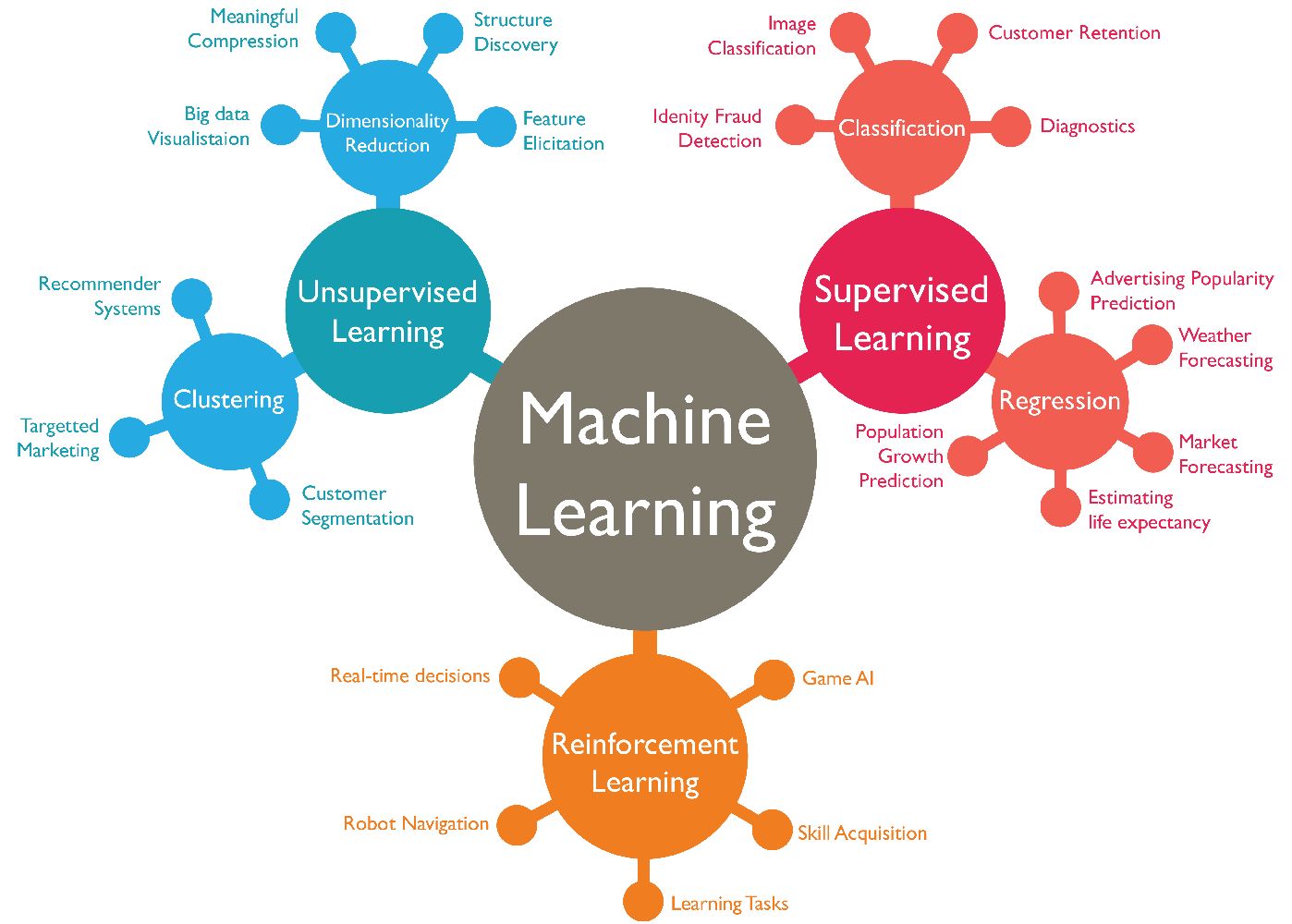
Machine learning algorithms use a variety of techniques to make predictions. Supervised learning is a type of predicting where the model learns from labeled data, where each instance is associated with a known output. Unsupervised learning, on the other hand, involves predicting patterns and structures in unlabeled data. Classification predictions categorize instances into different classes or groups, while regression predictions estimate a continuous value. Time series predictions analyze data points collected over time to forecast future trends and patterns.
In the next sections, we will explore the different types of predictions in machine learning and delve into their underlying techniques and applications.
Importance of Predicting in Machine Learning
Predicting holds immense importance in the field of machine learning as it enables organizations to make informed decisions, optimize processes, and gain a competitive edge. Here are some key reasons why predicting is essential:
1. Anticipating Future Trends: By analyzing historical data and identifying patterns, machine learning algorithms can predict future trends and developments. This allows businesses to anticipate changes in customer preferences, market conditions, and industry trends. Armed with this knowledge, organizations can adapt their strategies and stay one step ahead of their competitors.
2. Enhancing Decision-making: Predicting empowers decision-makers by providing them with valuable insights and information. For example, in the healthcare industry, predicting can aid in diagnosing diseases, selecting appropriate treatments, and predicting patient outcomes. In finance, predicting can guide investment decisions, evaluate risks, and optimize portfolio management. By leveraging accurate predictions, decision-makers can make informed choices that lead to better outcomes.
3. Optimizing Operations: Predicting helps organizations optimize their operations and improve efficiency. For instance, in manufacturing, predictive maintenance can be used to anticipate machine failures and schedule maintenance proactively, reducing downtime and optimizing productivity. In supply chain management, predicting future demand allows companies to forecast inventory requirements and streamline their supply chain, minimizing costs and improving customer satisfaction.
4. Personalizing Experiences: Predicting enables organizations to provide personalized experiences to customers. By analyzing customer data and predicting their preferences, companies can offer tailored recommendations, personalized marketing campaigns, and customized product offerings. This enhances customer satisfaction and loyalty, leading to increased sales and customer retention.
5. Risk Management: Predicting plays a crucial role in risk management and mitigation across various industries. In finance, predicting can help identify fraudulent activities and detect anomalies in transactions. Insurance companies use predicting to assess risks and calculate premiums accurately. By accurately predicting risks, organizations can implement proactive measures to mitigate potential losses and safeguard their business.
6. Improving Product Development: Predicting aids in product development by enabling organizations to understand customer needs and preferences. By analyzing market data and predicting consumer demand, companies can develop products that align with customer expectations. Predicting also helps in optimizing product features, pricing, and marketing strategies, enhancing the chances of success in the market.
Overall, the importance of predicting in machine learning cannot be overstated. It empowers organizations to make data-driven decisions, optimize operations, and gain a competitive advantage in the dynamic business landscape.
Types of Predictions in Machine Learning
Machine learning encompasses various types of predictions, each serving a unique purpose and catering to different data scenarios. Here are the main types of predictions in machine learning:
1. Supervised Predictions: This type of prediction involves training a machine learning model on labeled data, where each instance is associated with a known output. The model learns patterns and relationships between the input features and the corresponding labels, enabling it to make predictions on unseen data. Supervised predictions are commonly used for tasks like classification and regression.
2. Unsupervised Predictions: Unsupervised predictions involve analyzing unlabeled data and identifying patterns, structures, or groupings within the data. Unlike supervised predictions, there are no predefined labels or outcomes. Unsupervised algorithms aim to discover the inherent relationships and dependencies within the data. Common applications of unsupervised predictions include clustering, anomaly detection, and dimensionality reduction.
3. Classification Predictions: Classification predictions are used to categorize instances into different classes or categories based on their features. The model learns from labeled data and then assigns new instances to the most appropriate class. Classification is widely used in areas such as sentiment analysis, image recognition, and spam filtering. Popular algorithms for classification include logistic regression, decision trees, and support vector machines.
4. Regression Predictions: Regression predictions involve estimating a continuous value or quantity based on input features. This type of prediction is used when the output variable is numeric instead of categorical. Regression is commonly used for tasks such as predicting house prices, stock market trends, and sales forecasting. Linear regression, random forests, and neural networks are popular algorithms for regression predictions.
5. Time Series Predictions: Time series predictions analyze data points collected at regular intervals over time to forecast future trends and patterns. This type of prediction is prevalent in domains such as stock market analysis, weather forecasting, and demand forecasting. Time series algorithms take into account the sequential nature of the data and incorporate historical patterns and seasonality to make accurate predictions.
While these are the main types of predictions in machine learning, it is important to note that they are not mutually exclusive. Some tasks may require a combination of different prediction techniques, such as using supervised learning for feature extraction followed by unsupervised learning for clustering.
By understanding the different types of predictions in machine learning, organizations can choose the most appropriate algorithms and methodologies that align with their specific data and objectives. This enables them to derive meaningful insights and make accurate predictions for various applications.
Supervised Predictions
Supervised predictions are a fundamental aspect of machine learning, involving the use of labeled data to train a model and make predictions on new, unseen instances. This type of prediction is widely used in tasks such as classification and regression, where the goal is to predict the output variable based on the input features.
In supervised predictions, the training data consists of pairs of input features and their corresponding labels. The model learns from this labeled data by identifying patterns and relationships between the features and labels. It then uses this learned knowledge to predict the labels for new, unseen instances.
In classification predictions, the output variable is categorical, meaning it falls into a predefined set of classes or categories. The goal is to assign a new sample to the most appropriate class based on its features. For example, in email spam filtering, the classification model learns to classify emails as either spam or non-spam based on various features such as subject line, sender, and content.
In regression predictions, on the other hand, the output variable is continuous, meaning it can take on any numeric value. The aim is to estimate the value of the output variable based on the input features. Regression is commonly used for tasks like predicting house prices based on features such as location, square footage, and number of bedrooms.
Supervised predictions require a large, high-quality training dataset that accurately reflects the real-world scenarios and covers a wide range of possible input feature values. The dataset should be labeled by experts or through manual annotation to ensure accurate training of the model.
Popular algorithms for supervised predictions include logistic regression, decision trees, support vector machines (SVM), random forests, and neural networks. Each algorithm has its own strengths and weaknesses, and the choice of algorithm depends on the nature of the problem, the size of the dataset, and other factors.
When evaluating the performance of supervised prediction models, various metrics can be used, such as accuracy, precision, recall, F1 score, and mean squared error (MSE) for regression. These metrics help assess how well the model generalizes to unseen data and whether it is accurately predicting the output variable.
Supervised predictions have significant applications across industries. They can be used for sentiment analysis, image recognition, fraud detection, medical diagnosis, customer churn prediction, and many more tasks that require the classification or estimation of an output variable.
By leveraging supervised predictions, organizations can make accurate predictions and utilize them to drive decision-making, improve efficiency, and gain insights into their data.
Unsupervised Predictions
Unsupervised predictions are a type of machine learning technique that involves analyzing unlabeled data to uncover hidden patterns, structures, or groupings within the data. Unlike supervised predictions, unsupervised predictions do not have a predefined set of labels or outcomes to guide the learning process.
In unsupervised predictions, the model aims to understand the inherent relationships and dependencies among the data points. It does this by exploring the data and identifying similarities, differences, and clusters within the dataset. Unsupervised predictions are particularly useful when the data does not come with any prior knowledge or annotations.
Clustering is a common application of unsupervised predictions. It involves grouping similar data points together based on certain similarities or distances between them. For example, in customer segmentation, unsupervised prediction algorithms can group customers into distinct segments based on purchasing behavior, demographics, or other relevant characteristics.
Another application of unsupervised predictions is dimensionality reduction. This technique is used to simplify complex datasets by reducing the number of input features while still preserving the meaningful information. By eliminating redundant or less informative features, dimensionality reduction can enhance the efficiency and interpretability of machine learning algorithms.
Anomaly detection is yet another example where unsupervised predictions are valuable. Anomalies, or outliers, are data points that significantly deviate from the normal pattern or distribution. Unsupervised prediction algorithms can identify these anomalies by learning the underlying patterns in the data and flagging instances that do not fit those patterns. This has applications in fraud detection, network intrusion detection, and quality control.
There are various unsupervised learning algorithms that can be applied for different purposes. Some popular techniques include K-means clustering, hierarchical clustering, principal component analysis (PCA), and autoencoders. Each algorithm utilizes different approaches to uncover patterns and structures in the data.
Evaluating unsupervised predictions can be more challenging compared to supervised predictions since there are no predefined labels to compare against. Evaluation typically involves inspecting the output clustering or visualizing the reduced-dimensional data to analyze if the groups or patterns make sense and align with expected behavior.
Unsupervised predictions have applications in a wide range of domains, including market research, customer segmentation, anomaly detection, social network analysis, and more. They provide insights and understanding of complex data without the need for manual labeling or predetermined outcomes.
By utilizing unsupervised predictions, organizations can gain valuable insights, uncover hidden patterns, and make data-driven decisions, ultimately deriving meaningful knowledge from their data.
Classification Predictions
Classification predictions are a fundamental aspect of machine learning, aiming to categorize instances into different classes or categories based on their features. This type of prediction is widely used in various domains, including text classification, image recognition, fraud detection, and more.
In classification predictions, the algorithm learns from labeled training data, where each instance is associated with a known class or category. The model analyzes the input features and maps them to the corresponding class label. The goal is to build a robust model that can accurately classify new, unseen instances into the appropriate class.
There are several algorithms and techniques used for classification predictions. Some of the popular ones include logistic regression, decision trees, support vector machines (SVM), random forests, naive Bayes, and neural networks.
Logistic regression is a commonly used algorithm for binary classification, which involves classifying instances into two classes. It models the relationship between the features and the probability of belonging to a particular class. Decision trees, on the other hand, create a tree-like structure to make decisions based on various feature values, allowing for both binary and multiclass classification.
Support vector machines (SVM) aim to find a hyperplane that separates the instances into different classes with the maximum margin. Random forests, as an ensemble method, combine several decision trees to make predictions and improve accuracy. Naive Bayes is based on Bayes’ theorem and uses probabilistic calculations to classify instances.
Neural networks, particularly deep learning models, have gained significant popularity in recent years for their ability to handle complex data and deliver high classification performance. Convolutional neural networks (CNN) are often used for image classification tasks, while recurrent neural networks (RNN) are suitable for sequential data such as natural language processing.
Evaluating the performance of classification models involves a range of metrics such as accuracy, precision, recall, F1 score, and area under the receiver operating characteristic (ROC) curve. These measures provide insights into the model’s ability to correctly classify instances and its performance across different classes.
Classification predictions have widespread applications across industries. In sentiment analysis, for instance, classification algorithms can determine if a given sentence expresses a positive or negative sentiment. In fraud detection, classification models can identify anomalous transactions or activities. In medical diagnosis, classification algorithms can help predict diseases based on symptoms and patient data.
To achieve accurate classification predictions, it is crucial to have high-quality, representative training data that adequately covers the different classes. Feature engineering, including selecting relevant features and encoding categorical variables, is also essential in classification tasks. Additionally, model tuning and optimization can further improve the classification performance.
Overall, classification predictions are fundamental in machine learning and provide valuable insights for decision-making, enabling organizations to categorize and understand their data more effectively.
Regression Predictions
Regression predictions in machine learning involve estimating a continuous value or quantity based on input features. This type of prediction is widely used in various domains, including finance, economics, healthcare, and sales forecasting.
In regression predictions, the algorithm learns from labeled training data, where each instance is associated with a known output value. The model analyzes the input features and learns the relationship between the features and the output variable. The goal is to build a predictive model that can accurately estimate the output variable for new, unseen instances.
There are several algorithms and techniques used for regression predictions. Some of the popular ones include linear regression, decision trees, random forests, support vector regression (SVR), and neural networks.
Linear regression is a simple yet powerful algorithm that models the relationship between the features and the output variable using a linear equation. It estimates the coefficients to minimize the error between the predicted and actual output values. Decision trees and random forests can also be used for regression tasks by training on labeled data and predicting the continuous output value.
Support vector regression (SVR) is an extension of support vector machines (SVM) for regression tasks. SVR aims to find a hyperplane that fits as many instances as possible within a margin of error. Neural networks, particularly deep learning models, have also shown excellent performance in regression tasks by capturing nonlinear relationships between the features and the output variable.
Evaluating the performance of regression models typically involves metrics such as mean squared error (MSE), mean absolute error (MAE), root mean squared error (RMSE), and coefficient of determination (R-squared). These metrics assess how well the model predicts the continuous output variable and quantify the extent of the prediction error.
Regression predictions have diverse applications. For example, in finance, regression models can be used to predict stock market trends or estimate the price of a financial instrument based on economic indicators. In healthcare, regression predictions can help forecast patient outcomes, analyze the impact of treatments, or predict disease progression based on patient data.
Feature selection and engineering play a critical role in regression tasks. Selecting the most relevant features can improve the model’s accuracy and efficiency. Feature transformations, such as scaling or encoding categorical variables, may be necessary to ensure compatibility with the regression algorithms.
To achieve accurate regression predictions, it is important to have a representative training dataset, handle missing values appropriately, and perform data preprocessing if necessary. Additionally, model tuning and optimization techniques can help improve the performance of regression models.
Overall, regression predictions provide valuable insights and estimations of continuous variables, enabling organizations to make data-driven decisions and understand the relationship between input features and output values.
Time Series Predictions
Time series predictions are a specialized type of machine learning technique that focuses on analyzing data points collected over time to forecast future trends and patterns. This type of prediction is widely used in domains such as finance, economics, weather forecasting, stock market analysis, and demand forecasting.
In time series predictions, the data is organized in a temporal order, with each data point representing an observation at a specific time interval. The objective is to understand the underlying patterns, trends, and dependencies in the data to make accurate predictions about future values or behaviors.
Time series predictions consider various factors, such as seasonality, trends, and historical patterns, to forecast future values. They utilize the temporal relationship between data points to make predictions. The time component adds an additional layer of complexity compared to other prediction tasks.
There are specific algorithms and techniques designed specifically for time series predictions. Some common methods include autoregressive integrated moving average (ARIMA), seasonal decomposition of time series (STL), exponential smoothing methods, and state space models.
ARIMA models are widely used for time series predictions and involve analyzing the autocorrelation and moving average of the data. These models capture the trend and seasonality by differencing the data and incorporate lagged values to make robust forecasts.
Exponential smoothing methods, such as single, double, or triple exponential smoothing, are based on giving more weight to recent observations and gradually decreasing the significance of older data points. These methods are particularly useful when the data exhibits trend and seasonality.
State space models, such as the Kalman filter or particle filter, provide a flexible framework for modeling complex temporal dependencies and making predictions. They are able to handle non-linearities and irregular observations effectively.
Time series predictions require thorough analysis and understanding of the data. Some important considerations include identifying and handling missing values, dealing with outliers, and selecting appropriate forecasting horizons. It’s also important to evaluate the performance of time series models using metrics such as mean squared error (MSE), mean absolute error (MAE), or forecasting accuracy measures.
Applications of time series predictions are widespread. For instance, in finance, time series predictions can be used to forecast stock prices, exchange rates, or commodity prices. In weather forecasting, these predictions help estimate temperature, precipitation, or wind patterns. In business, time series predictions are commonly used for demand forecasting, sales projections, or resource planning.
By leveraging time series predictions, organizations can gain insights into future trends, make informed decisions, and develop effective strategies for their operations.
Evaluation Metrics for Predictions in Machine Learning
Evaluation metrics play a vital role in assessing the performance and accuracy of predictions made by machine learning models. These metrics provide quantitative measures to evaluate how well the model generalizes to unseen data and how accurately it predicts the output variable. Different evaluation metrics are used based on the type of prediction task, whether it’s classification, regression, or any other specific prediction problem.
1. Classification Metrics: Classification tasks involve categorizing instances into different classes or categories. Common evaluation metrics for classification predictions include:
- Accuracy: The proportion of correctly classified instances out of the total number of instances. It provides a general overview of the model’s performance but can be misleading in imbalanced datasets.
- Precision: The percentage of correctly predicted positive instances out of all instances predicted as positive. It measures the model’s ability to avoid false positives.
- Recall: The percentage of correctly predicted positive instances out of all actual positive instances. It measures the model’s ability to identify all positive instances.
- F1 Score: The harmonic mean of precision and recall. It provides a balanced measure of the model’s accuracy and is particularly useful in imbalanced datasets.
- ROC-AUC: The area under the receiver operating characteristic curve. It measures the model’s ability to differentiate between positive and negative instances, considering different classification thresholds.
2. Regression Metrics: Regression tasks involve estimating a continuous value or quantity. Common evaluation metrics for regression predictions include:
- Mean Squared Error (MSE): The average squared difference between the predicted and actual values. It provides a measure of the model’s average prediction error, with larger errors penalized more.
- Mean Absolute Error (MAE): The average absolute difference between the predicted and actual values. It provides a measure of the model’s average prediction error without considering squared differences.
- Root Mean Squared Error (RMSE): The square root of the mean squared error. It provides an interpretable measure in the same unit as the output variable, representing the average magnitude of error.
- Coefficient of Determination (R-squared): The proportion of the variance in the output variable explained by the model. It ranges from 0 to 1, where 1 indicates a perfect fit.
3. Other Metrics: There are additional evaluation metrics specific to different prediction tasks. Time series predictions, for example, often use metrics like mean absolute percentage error (MAPE) or forecast accuracy measures such as percentage of accurate predictions within a certain tolerance.
It is critical to choose the appropriate evaluation metrics based on the specific prediction task and the priorities of the problem at hand. The choice of metrics should align with the business objectives and provide meaningful insights into the model’s performance.
Evaluation metrics help in benchmarking different models, comparing their performance, and fine-tuning the model parameters or features to achieve the desired prediction accuracy and performance.
Conclusion
Predicting in machine learning is a powerful capability that enables organizations to make accurate estimations and forecasts based on historical data. It plays a vital role in various industries, bringing valuable insights and driving data-driven decision-making.
We explored the different types of predictions in machine learning, including supervised predictions, unsupervised predictions, classification predictions, regression predictions, and time series predictions. Each type serves a unique purpose and utilizes specific algorithms and techniques to achieve accurate predictions.
Supervised predictions involve training models on labeled data to classify instances or estimate continuous values. Unsupervised predictions focus on analyzing unlabeled data to uncover patterns, structures, or anomalies. Classification predictions categorize instances into different classes, while regression predictions estimate continuous values. Time series predictions analyze data points collected over time to forecast future trends and patterns.
Evaluation metrics are used to assess the performance of predictions. In classification tasks, metrics such as accuracy, precision, recall, F1 score, and ROC-AUC provide insights into the model’s ability to correctly classify instances. In regression tasks, metrics like mean squared error, mean absolute error, root mean squared error, and coefficient of determination measure the accuracy of continuous value estimation.
As machine learning continues to advance, predicting will remain a crucial aspect of deriving insights and making informed decisions. The accuracy and reliability of predictions depend on factors such as data quality, feature selection, model selection, and evaluation metrics.
By understanding the different types of predictions and utilizing appropriate algorithms and evaluation metrics, organizations can leverage the power of machine learning to uncover hidden patterns, predict outcomes, optimize processes, and gain a competitive edge in their respective industries.