Introduction
Welcome to the fascinating world of machine learning! As technology continues to advance, machine learning has emerged as a powerful tool for extracting insights and making predictions from vast amounts of data. From image recognition to natural language processing, machine learning algorithms have enabled impressive advancements in various domains.
However, one aspect that has garnered significant attention in the field of machine learning is interpretability. Interpretability refers to the ability to understand and explain the decisions made by machine learning models. It involves unraveling the black box nature of these models and shedding light on the factors that influence their predictions.
Why is interpretability important in machine learning? The answer lies in the need for transparency, fairness, and accountability. As machine learning algorithms play an increasingly significant role in critical decision-making processes, such as loan approval or medical diagnosis, it is crucial to understand why and how these decisions are being made.
Interpretability also allows us to uncover potential biases and ethical concerns embedded within machine learning models. By providing explanations for their predictions, we can ensure that these models are not perpetuating discriminatory or harmful practices. Additionally, interpretability enables us to build trust with users, regulators, and stakeholders by demonstrating that our models are reliable, accurate, and accountable.
Interpreting machine learning models can also help us gain valuable insights into the underlying data patterns and relationships. Understanding why certain features are more influential in the decision-making process can provide a deeper understanding of the problem at hand. This knowledge can be leveraged to improve the model’s performance or make informed decisions based on the model’s outputs.
There are various methods and techniques available to interpret machine learning models. Some techniques aim to provide a global understanding of the model’s overall behavior, while others focus on gaining insights at the local level for individual predictions. Each approach has its strengths and limitations, and the choice of technique depends on the specific requirements and context of the problem.
However, achieving interpretability in machine learning is not without its challenges. The trade-off between interpretability and model accuracy is an ongoing debate. In some cases, more interpretable models might sacrifice a certain degree of predictive performance. Balancing interpretability with accuracy is crucial, as a highly interpretable model with poor performance may not be practically useful.
In this article, we will delve deeper into the concept of interpretability in machine learning. We will explore different methods and techniques for interpreting machine learning models, discuss the trade-offs between interpretability and accuracy, and examine the applications and benefits of interpretability in real-world scenarios. Furthermore, we will also touch upon the challenges and limitations in achieving interpretabi
Definition of Interpretability in Machine Learning
Before delving into the complexities of interpretability in machine learning, it is important to establish a clear definition. Interpretability can be defined as the ability to explain and understand the decisions made by machine learning models in a human-understandable and transparent manner.
Interpretability involves unraveling the inner workings of machine learning algorithms and understanding the factors that contribute to their predictions. It goes beyond merely knowing the outcomes and aims to provide insights into the reasoning and decision-making processes of these models.
There are different levels of interpretability, ranging from the basic understanding of how a model has arrived at a prediction to a detailed understanding of the specific features, relationships, and interactions that influenced the outcome.
Interpretability can be seen as a continuum. At one end, we have highly interpretable models like decision trees or linear regression, where the decision-making process is transparent and can be easily explained. These models provide clear rules and coefficients that determine their predictions.
On the other end of the spectrum, we have complex models like neural networks or ensemble methods, which are often referred to as black box models. These models operate with multiple layers of interconnected nodes and weights, making it difficult to understand their inner workings without specialized techniques.
The overarching goal of interpretability in machine learning is to bridge the gap between these two ends of the spectrum. It involves developing techniques and methodologies to make black box models more interpretable by revealing the underlying patterns and relationships they have learned from the training data.
Interpretability is not limited to understanding the model’s predictions but also encompasses understanding the impact of the input features on the output. By attributing importance or relevance to individual features, we gain valuable insights into the significance of different variables in influencing the model’s decisions.
Furthermore, interpretability can also extend to understanding the limitations and biases present in machine learning models. It allows us to identify potential errors, biases, or unfairness that may arise due to the training data, algorithmic choices, or other factors. Uncovering these limitations enables us to address them and build more fair and unbiased models.
In summary, interpretability in machine learning refers to the ability to understand and explain the decisions made by machine learning models in a transparent and human-understandable manner. It involves various techniques and approaches that aim to reveal the inner workings of these models and provide insights into the factors that drive their predictions. By achieving interpretability, we can build trust, ensure fairness, and gain valuable insights from machine learning models.
Importance of Interpretability in Machine Learning
Interpretability plays a crucial role in the field of machine learning, offering numerous benefits and addressing important considerations. Let’s explore some key reasons why interpretability is of utmost importance in this domain.
Transparency and Accountability: Machine learning models are increasingly being used in high-stakes decision-making processes, such as credit scoring, medical diagnosis, and autonomous driving. Users and stakeholders have the right to understand why a particular decision was made and how it was influenced by various factors. Interpretability provides transparency, allowing users to assess the fairness and legality of these decisions. It also promotes accountability, ensuring that machine learning models are not making biased or discriminatory judgments.
Ethical and Legal Considerations: Interpretability is vital in identifying and addressing potential biases and ethical concerns embedded within machine learning models. By understanding the decision-making process, we can detect and rectify instances of unfairness or discrimination. This is crucial to prevent reinforcing societal inequalities or inadvertently making decisions that infringe upon legal requirements, such as those outlined in data protection or privacy laws.
Improved Trust and Acceptance: Interpretable machine learning models foster trust among users, regulators, and stakeholders. When users understand how a model arrived at a prediction, they are more likely to trust its outputs and rely on its recommendations. This applies to both individual users and organizations that utilize machine learning models for decision support. Increased trust and acceptance result in greater adoption and utilization of these models, leading to their wider use and potential positive impact.
Insights and Understandability: Interpretability allows us to gain valuable insights into the underlying patterns and relationships within the data. By comprehending the influential factors, we can uncover meaningful information about the problem domain and make data-informed decisions. Interpretability also enhances our understanding of complex phenomena, enabling domain experts to validate and refine machine learning models based on their expert knowledge.
Model Improvement and Debugging: Through interpretability, we can identify potential issues or weaknesses in machine learning models. By understanding the factors that contribute to incorrect predictions or suboptimal performance, we can introduce necessary improvements. Interpretability provides a framework for debugging and refining machine learning models, increasing their accuracy and reliability.
Education and Communication: Interpretability facilitates effective communication and education about machine learning models. When complex algorithms are made interpretable, they can be explained to non-technical stakeholders, such as clients, policymakers, or the general public, in a comprehensible manner. This promotes wider understanding and engagement with machine learning concepts, contributing to responsible and informed decision-making.
Overall, interpretability is pivotal in ensuring transparency, fairness, and ethical use of machine learning models. It helps build trust, provides valuable insights, aids in model improvement, enhances communication, and addresses legal and ethical considerations. As the field of machine learning continues to advance, the importance of interpretability remains a cornerstone for responsible and reliable deployment of these powerful algorithms.
Methods and Techniques for Interpreting Machine Learning Models
Interpreting machine learning models is a challenging yet essential task in gaining insights into their decision-making processes. Fortunately, there are various methods and techniques available to help us understand and interpret these models. Let’s explore some common approaches:
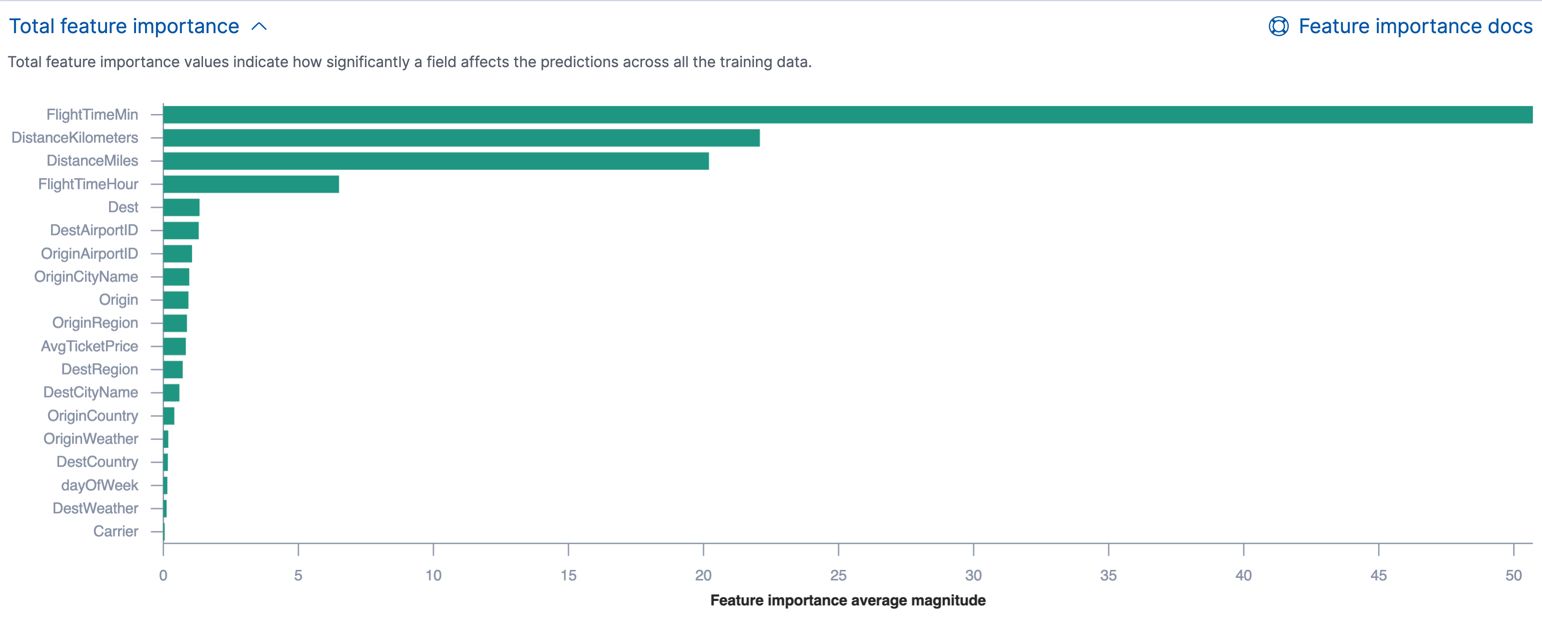
Feature Importance: One of the simplest and most straightforward techniques for interpreting machine learning models is to analyze the importance of individual features in the decision-making process. Methods like feature importance scores or coefficients in linear models provide a quantitative measure of how much each feature contributes to the model’s predictions.
Partial Dependence Plots: Partial dependence plots (PDPs) visualize the relationship between a specific feature and the model’s predictions while holding other features constant. This technique helps us understand the dependence between the selected feature and the output, revealing patterns, non-linearities, and interactions.
Local Interpretable Model-agnostic Explanations (LIME): LIME is a popular technique for understanding individual predictions of machine learning models. It creates interpretable models around the prediction of interest and provides insights into the important features that influenced that specific prediction. LIME operates by perturbing the input data and observing the corresponding changes in the output prediction.
Shapley Values: Shapley values are based on cooperative game theory and provide a way to distribute the “importance” of each feature across the different predictions of the model. By analyzing the Shapley values, we can understand the impact each feature has on the model’s overall predictions.
Decision Trees and Rule-based Models: Decision trees inherently provide interpretability as they consist of a series of if-else statements that lead to specific outcomes. These models can be easily visualized, and the decision-making process can be traced through the branching paths. Rule-based models, such as rule learners or decision lists, also offer interpretability by directly mapping rules to predictions.
Layer-wise Relevance Propagation (LRP): LRP is a technique specifically designed for interpreting deep neural networks. It assigns relevance scores to individual input features based on the impact they have on the model’s predictions. LRP allows us to understand which parts of the input the model pays attention to when making its decisions.
Model Surrogates: Surrogate models are simpler, interpretable models trained to approximate the behavior of complex machine learning models. They act as proxies, providing insights into the decision-making process of the original model. Surrogates, such as linear models or decision trees, can be easily interpreted and can help us gain a better understanding of black box models.
These are just some of the methods and techniques available for interpreting machine learning models. Each approach has its own advantages and limitations, and the choice of technique depends on various factors, including the complexity of the model, the nature of the data, and the specific interpretability goals.
It’s worth noting that while these techniques provide valuable insights, there is often a trade-off between interpretability and the predictive performance of the model. Striking the right balance between model accuracy and interpretability is essential to ensure that the model not only provides explanations but also makes reliable predictions.
By utilizing these methods and techniques, we can delve deeper into the inner workings of machine learning models, gain an understanding of their decision-making processes, and extract valuable insights from their predictions.
Local Interpretability vs. Global Interpretability
Interpretability in machine learning can be classified into two broad categories: local interpretability and global interpretability. Each approach offers unique insights into the workings of machine learning models, but they differ in their scope and level of detail. Let’s explore the differences between local and global interpretability:
Local Interpretability: Local interpretability focuses on understanding the decision-making process of individual predictions made by machine learning models. It aims to answer the question, “Why did the model make this specific prediction for this particular input?” Local interpretability techniques provide insights into the factors and features that influenced a specific prediction, allowing us to examine the model’s behavior on a case-by-case basis.
Local interpretability methods, such as LIME or individual feature importance analysis, create simplified surrogate models or generate explanations specific to the prediction of interest. These explanations offer a fine-grained understanding of how the model arrived at its decision for a single instance, highlighting the important features and their contributions.
Local interpretability is particularly useful when we need to understand why a certain prediction was made, especially if the model’s decision seems counterintuitive or unexpected. It helps in identifying potential biases or errors in the predictions and allows for targeted model improvement.
Global Interpretability: In contrast, global interpretability aims to provide a holistic understanding of the machine learning model’s behavior and decision-making process across all predictions and input instances. It focuses on answering broader questions like, “How does the model work in general?”, “What are the important features overall?”, or “What patterns and relationships are captured by the model?” Global interpretability techniques focus on understanding the overall behavior and patterns exhibited by the model.
Global interpretability methods often involve analyzing the model’s internal representations, such as feature importance rankings across multiple predictions or aggregating explanations from different instances. Techniques like decision tree visualization, feature importance across the entire dataset, or Shapley values, provide insights into the important features and relationships that influence the model’s predictions in a more general sense.
Global interpretability allows us to understand the model’s overall decision-making strategy and identify the key factors driving its behavior across various inputs. It helps in gaining a broader understanding of the problem domain and uncovering trends and patterns in the data that the model has learned.
Both local and global interpretability are valuable in different contexts and scenarios. Local interpretability is beneficial for understanding individual predictions, identifying biases or errors, and making targeted improvements. Global interpretability, on the other hand, provides a higher-level understanding of the model’s behavior and can be useful in gaining insights into the overall patterns and relationships captured by the model.
It’s important to note that the choice between local and global interpretability depends on the specific requirements of the problem at hand. In some cases, both types of interpretability may be necessary to gain a comprehensive understanding of the model’s behavior.
By combining local and global interpretability techniques, we can gain a more nuanced understanding of machine learning models, uncover important insights, ensure transparency, and make informed decisions based on their outputs.
Trade-offs between Interpretability and Model Accuracy
When it comes to machine learning models, there often exists a trade-off between interpretability and model accuracy. While interpretability is crucial for understanding the decision-making processes and gaining trust in the model, it may come at the expense of predictive performance. Let’s explore the trade-offs between interpretability and model accuracy:
Model Complexity: Interpretable models, such as linear regression or decision trees, often have simpler structures and fewer parameters compared to complex models like deep neural networks or ensemble methods. By simplifying the model structure, interpretability is enhanced, but the model may not capture the intricacies and nuances of the data, potentially leading to decreased accuracy.
Black Box Models: Highly accurate machine learning models like deep learning models or ensemble methods often exhibit complex, non-linear relationships within the data. These models, known as black box models, offer superior accuracy but can be challenging to interpret. The complex internal structure of these models hampers our ability to understand their decision-making process, sacrificing interpretability.
Feature Engineering: In some cases, feature engineering techniques may be necessary to improve model accuracy. However, these engineered features might make the model less interpretable. Advanced feature transformations or combinations may obscure the direct relationship between the original features and the model’s predictions, making it difficult to explain the decision-making process to stakeholders.
Data Representation: Certain types of data, such as raw images or text, are inherently complex and high-dimensional. Models that operate on such data, like convolutional neural networks or natural language processing models, often achieve remarkable accuracy but lack interpretability. The complex mapping between the input data and the model’s predictions makes it challenging to decipher the underlying patterns and relationships.
Trade-off Strategies: Researchers and practitioners have proposed different strategies to balance interpretability and model accuracy. Some approaches involve constructing surrogate models, which are simpler and interpretable models trained to approximate the behavior of complex models. These surrogate models aim to strike a balance between model accuracy and interpretability.
Context and Application: The choice between interpretability and model accuracy depends on the specific context and application. In certain domains, such as healthcare or finance, interpretability is a critical requirement, outweighing the need for the highest possible accuracy. In other cases, like certain research settings, pursuing the highest accuracy may take precedence over interpretability.
User Needs and Preferences: Understanding the needs and preferences of the end-users is crucial in determining the appropriate level of interpretability. Some users may prioritize accurate predictions and trust in the model, while others may value understanding the decision-making process, even at the cost of slight decreases in model accuracy.
It is important to strike a balance between interpretability and model accuracy based on the specific context and requirements of the problem at hand. Trade-offs may need to be made depending on factors such as the complexity of the data, the availability of domain expertise, ethical considerations, and the level of transparency desired.
Efforts continue to be made to develop models and techniques that offer both high model accuracy and interpretability. Bridging the gap between these two objectives remains an active area of research, with the goal of achieving accurate models that can be easily understood and trusted by stakeholders.
Applications and Benefits of Interpretability in Machine Learning
The applications and benefits of interpretability in machine learning are vast and span across various domains. Let’s explore some of the key areas where interpretability plays a crucial role:
Healthcare: Interpretability is of utmost importance in healthcare, where accurate and transparent decision-making is essential. Interpretable machine learning models help in medical diagnosis, identifying risk factors, and providing explanations for treatment recommendations. Interpretability allows healthcare professionals to understand and trust the predictions and supports decision-making in critical medical scenarios.
Finance and Credit Decisions: In finance, interpretability provides transparency and accountability in credit scoring and loan approval processes. It allows lenders to understand the factors that influence credit decisions and identify potential discriminatory practices. Interpretability helps ensure fairness, prevent biases, and comply with legal requirements in making financial decisions.
Autonomous Systems and Robotics: Interpretability is vital in autonomous systems and robotics, where decisions made by machines have significant consequences. Explaining the decision-making process helps to build trust and ensure that autonomous systems operate in a safe and reliable manner. Interpretability allows users and stakeholders to understand why an autonomous system made a specific decision and ensures transparency in their operations.
Legal and Judicial Systems: Interpretability has implications for legal and judicial systems, especially in cases where machine learning models are used for risk assessment, parole decisions, or evidence prediction. Transparent explanations provided by interpretable models help legal professionals and judges understand how decisions are reached, ensuring fairness, and enabling explanations in legal proceedings.
Image and Text Analysis: Interpretability is valuable in image and text analysis tasks, such as computer vision and natural language processing. Understanding why a particular image or text was classified in a certain way helps in identifying potential biases, evaluating model reliability, and gaining insights into the learned representations. Interpretability aids in debugging, improving model performance, and verifying the validity of model outputs in these domains.
Consumer Applications: In consumer-facing applications, interpretability enhances user trust and engagement. By providing explanations for recommendations or predictions, machine learning models can help users understand the reasoning behind personalized suggestions. Interpretability allows users to make informed decisions, increases the effectiveness of recommender systems, and ultimately improves the user experience.
Research and Scientific Discoveries: Interpretability in machine learning has implications in research and scientific domains. It enables researchers to understand the features and relationships that contribute to specific outcomes, leading to new insights and scientific discoveries. Interpretability helps validate and refine models, facilitating the process of knowledge discovery and advancing research across various disciplines.
Overall, interpretability in machine learning has numerous applications and benefits across different fields. It provides transparency, ensures fairness, enhances trust, improves decision-making, aids in model debugging, enables compliance with legal and ethical requirements, and enhances user experiences. Incorporating interpretability into machine learning models is crucial in building reliable, accountable, and understandable systems that can be trusted and utilized effectively.
Challenges and Limitations in Achieving Interpretability
While interpretability is of great importance in machine learning, there are several challenges and limitations that make achieving interpretability a complex task. Let’s explore some of the key challenges in this area:
Complexity of Models: Modern machine learning models, such as deep neural networks and ensemble methods, often have complex architectures and millions of parameters. Understanding the decision-making process of these models can be challenging due to their non-linearities, high dimensionality, and intricate internal representations. The complexity of the models poses a significant hurdle in achieving interpretability.
Trade-offs with Model Accuracy: There can be a trade-off between interpretability and model accuracy. More interpretable models, like decision trees or linear regression, may sacrifice some level of predictive power. Striking the right balance between interpretability and accuracy is crucial to ensure that the model not only provides explanations but also makes reliable predictions.
Limited Human Capacity: Humans have cognitive limitations when it comes to understanding and processing complex information. Machine learning models with thousands or millions of features or interactions may overwhelm human interpretability. Simplifying the models or reducing the dimensionality can aid in human understanding, but this process can result in information loss or reduced accuracy.
Domain-specific Interpretability: The methods and techniques for interpretability may vary depending on the domain or problem at hand. What is interpretable in one domain might not be applicable in another. Developing domain-specific interpretability techniques poses a challenge, as it requires deep understanding of the domain and the characteristics of the data.
Interpretability-Performance Trade-offs: Adding interpretability features or techniques to a model can have a negative impact on its performance. Increasing interpretability often implies adding constraints or simplifications, which may limit the model’s ability to learn complex patterns and relationships. Balancing the trade-off between interpretability and model performance is an ongoing challenge in the field.
Data Privacy and Security: Interpretability may clash with the requirements of data privacy and security. In certain applications, data may contain sensitive or private information that should not be exposed or directly linked to the model’s predictions. Anonymization or privacy-preserving techniques should be employed to ensure interpretability without compromising confidentiality.
Contextual and Dynamic Interpretability: Interpretability can be context-dependent and may change over time as the data distribution shifts or new patterns emerge. Models that are interpretable in one context may not be interpretable in another. Adapting interpretability techniques to changing contexts and ensuring model explanations remain valid over time pose additional challenges.
Interpretability Metrics and Evaluation: Developing quantitative metrics and standardized evaluation methodologies for interpretability is a complex task. Defining what constitutes a “good” or “interpretable” model is subjective and context-dependent. Establishing robust evaluation methods and benchmarks for interpretability remains a challenge in the field.
Despite these challenges and limitations, efforts are being made to advance the field of interpretability in machine learning. Researchers are actively exploring new techniques, developing domain-specific approaches, and addressing the trade-offs between interpretability and accuracy. By overcoming these challenges, we can unlock the full potential of interpretability and build more trustworthy and reliable machine learning systems.
Future Directions in Interpretability Research
Interpretability in machine learning has garnered significant attention in recent years, and ongoing research continues to explore new directions and advancements in this field. Here are some key areas of future research that hold promise in enhancing interpretability:
Explainable Deep Learning: Deep neural networks have achieved remarkable success but lack interpretability due to their complex architectures. Future research aims to develop techniques that provide transparent explanations for deep learning models, helping to understand the underlying features, relationships, and decision-making process. Incorporating interpretability into deep learning architectures will be crucial for their widespread adoption in practical applications.
Domain-Specific Interpretability: Different domains have unique characteristics and interpretability requirements. Future research will focus on developing domain-specific interpretability techniques that specifically cater to the needs and nuances of specific applications. From healthcare to finance, custom interpretability approaches will enable domain experts to understand and trust machine learning models within their specific contexts.
Interpretability with Complex Data Types: As machine learning expands into areas like computer vision, natural language processing, and genomics, interpretability techniques need to adapt to handle complex data types. Future research will explore interpretable methods tailored to handle high-dimensional images, textual data, time series, and other specialized data structures, enabling deeper insights into the decision-making processes of models operating on these data.
Quantitative Metrics and Evaluation: Developing robust metrics and evaluation frameworks for interpretability remains a challenge. Future research will focus on defining quantitative measures for interpretability to provide standardized evaluation methodologies. This will enable fair comparisons between different interpretability techniques and establish benchmarks for assessing the effectiveness of interpretability methods.
Hybrid Approaches: Researchers will explore hybrid approaches that combine the strengths of black box models, such as deep neural networks, with interpretable components. These hybrid models aim to preserve the high accuracy of complex models while incorporating interpretability features to provide explanations for their predictions. Such approaches will allow for the best of both worlds – accuracy and interpretability.
Interactive and User-Centered Interpretability: Future research will focus on making interpretability an interactive and user-centered process. Techniques that enable users to explore and interact with the model’s decision-making process in real-time will enhance their understanding and trust in the model. Providing personalized and contextually relevant explanations will be crucial for promoting user engagement and acceptance of machine learning models.
Ethical Considerations in Interpretability: Alongside technical advancements, research will explore the ethical dimensions of interpretability. Understanding the ethical considerations and potential societal impacts of interpretability techniques will guide their responsible and unbiased deployment. Ensuring fairness, avoiding bias, and addressing privacy concerns will be vital aspects of future interpretability research.
Education and Communication: Future research will focus on developing educational resources and tools that enable non-technical stakeholders to understand and engage with interpretability. Communicating the benefits, limitations, and implications of interpretable machine learning models will be crucial for fostering trust and promoting responsible adoption of these technologies.
As interpretability continues to evolve, interdisciplinary collaboration between researchers, practitioners, and domain experts will be important. Combining expertise from fields such as machine learning, human-computer interaction, ethics, and psychology will drive advancements in interpretability research, leading to more explainable, trustworthy, and accountable machine learning models.
Conclusion
Interpretability is a crucial aspect of machine learning that allows us to understand and explain the decision-making processes of complex models. It plays a vital role in building trust, ensuring fairness, and promoting accountability in machine learning systems. While achieving interpretability poses challenges and trade-offs, ongoing research and advancements are shaping the future of this field.
From healthcare to finance, interpretability finds applications in various domains, providing transparency and enabling informed decision-making. It allows us to uncover biases, address ethical concerns, and comply with legal requirements. Interpretability enhances user trust, improves model performance, validates scientific discoveries, and supports responsible use of machine learning models.
Future research directions include developing techniques for explainable deep learning, domain-specific interpretability, and handling complex data types. Quantitative metrics and evaluation frameworks will be refined to assess the effectiveness of interpretability techniques. Hybrid approaches combining accuracy and interpretability will continue to evolve, and interactive and user-centered interpretability will enhance user engagement.
Ethical considerations and communication of interpretability benefits and limitations will guide responsible deployment of these technologies. Education and multidisciplinary collaboration will drive advancements in the field, ensuring that interpretability research aligns with societal needs and values.
In summary, interpretability is essential for building reliable, accountable, and understandable machine learning models. By striving for interpretability, we can unlock the potential of these models and gain valuable insights into their decision-making processes. It is an ongoing journey, and as interpretability techniques continue to evolve, we are moving closer to a future where machine learning models are not only accurate but also transparent, trustworthy, and accountable.