What is a Confidence Score in Machine Learning?
A confidence score is a numerical value that indicates the level of certainty or accuracy of predictions made by a machine learning model. It is an important metric that helps evaluate and interpret the reliability of the model’s output. The confidence score represents the model’s confidence in its prediction or classification for a given input data point.
In machine learning, algorithms are trained on labeled data to learn patterns and make predictions or classifications. However, these predictions are not always 100% accurate or certain. The confidence score serves as a measure of how confident the model is in its prediction by estimating the probability of correctness.
The confidence score can range from 0 to 1, where 0 indicates no confidence or very low accuracy, and 1 represents complete confidence or high accuracy. Values between 0 and 1 indicate varying degrees of confidence.
The confidence score is closely related to the concept of probability. It provides a quantitative measure of how likely a prediction is correct. For example, if a model predicts whether an email is spam or not, a confidence score of 0.95 indicates that the model is 95% confident in its prediction.
The interpretation of the confidence score depends on the specific application and the problem being solved. It is important to set an appropriate threshold for the confidence score to determine the level of confidence required to accept or reject predictions. Setting a higher threshold may lead to more accurate but conservative predictions, while a lower threshold may result in more confident but potentially inaccurate predictions.
The confidence score is especially useful in scenarios where decisions based on predictions have significant consequences. For example, in healthcare, a high confidence score is desired when diagnosing diseases or recommending treatments. In financial fraud detection, a reliable confidence score helps determine the likelihood of a transaction being fraudulent.
In summary, a confidence score provides a quantitative measure of a machine learning model’s confidence in its predictions. It allows decision-makers to assess the reliability and accuracy of the model’s output and make informed decisions based on the level of confidence.
Factors that Affect Confidence Score Calculation
The calculation of a confidence score in machine learning involves several factors that can influence its value. These factors determine the reliability and accuracy of the predictions made by the model. Understanding these factors is crucial for interpreting and evaluating the confidence score. Here are some key factors that affect confidence score calculation:
- Dataset Quality: The quality and reliability of the dataset used for training the machine learning model greatly impact the confidence score. A well-prepared, diverse, and representative dataset leads to more accurate predictions and higher confidence scores. Conversely, a biased or incomplete dataset may result in lower confidence scores and less reliable predictions.
- Data Quantity: The amount of data available for training the model can affect the confidence score. In general, a larger dataset provides more information for the model to learn from and can result in higher confidence scores. Insufficient data can lead to uncertainty and lower confidence in the predictions.
- Feature Relevance: The choice and relevance of features used for training the model influence the confidence score. Including irrelevant or redundant features can introduce noise into the model and lower the confidence score. Selecting meaningful and informative features improves the model’s accuracy and confidence in predictions.
- Algorithm Complexity: The complexity of the machine learning algorithm used can impact the confidence score. Some algorithms, such as deep learning models with multiple layers, may have higher capacities to capture complex patterns and produce higher confidence scores. However, overly complex models can also be prone to overfitting and lead to lower confidence scores on unseen data.
- Model Training and Tuning: The process of training and tuning the model affects the confidence score. Proper training techniques, such as cross-validation and regularization, can enhance the model’s generalization capability and, consequently, improve the confidence score. Fine-tuning hyperparameters and optimizing the model’s performance also contribute to higher confidence scores.
- Model Interpretability: The interpretability of the machine learning model plays a role in the confidence score calculation. Models that provide clear explanations or understandable reasoning for their predictions tend to have higher confidence scores. Black-box models, on the other hand, may have lower confidence scores due to the difficulty in interpreting their decision-making process.
These are just a few of the factors that impact the calculation of a confidence score in machine learning. It is essential to consider these factors and evaluate their influence when interpreting the confidence score and making decisions based on the model’s predictions.
Feature Importance in Confidence Score Calculation
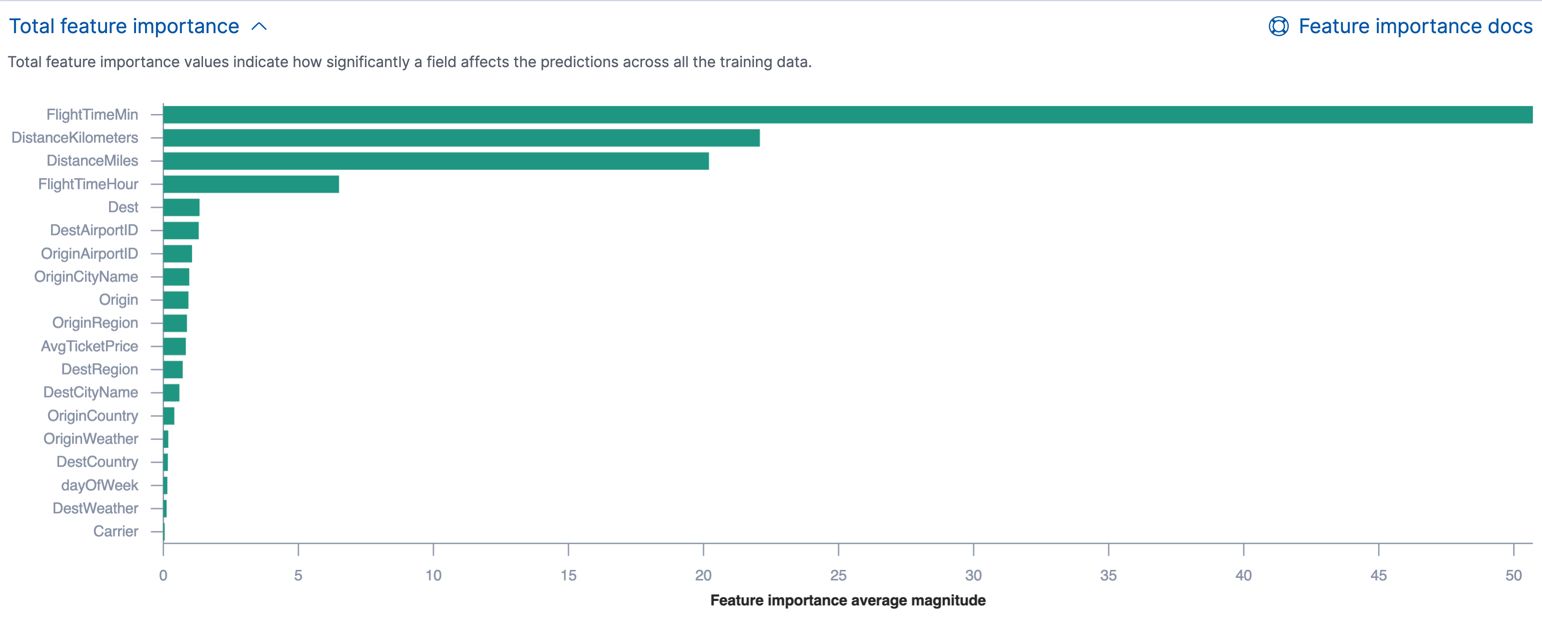
In machine learning, feature importance refers to the significance or contribution of different input features to the prediction or classification task. Understanding feature importance plays a crucial role in the calculation of the confidence score. By considering the importance of features, we can assess the reliability and accuracy of the model’s predictions. Here are some key points about feature importance in confidence score calculation:
- Identification of Informative Features: Feature importance helps identify which features have the most influence on the model’s predictions. By analyzing the importance of each feature, we can gain insights into which variables or characteristics are most relevant to the prediction task. This understanding aids in the interpretation and evaluation of the confidence score.
- Weighting of Features: Feature importance provides a way to quantify the impact of each feature on the model’s output. The weights assigned to each feature help determine the contribution of that feature to the final prediction. Features with higher importance or weight have a greater influence on the overall confidence score, while those with lower importance have less impact.
- Improving Model Performance: Understanding feature importance can guide feature selection and feature engineering efforts to improve the model’s performance and, subsequently, the confidence score. By focusing on the most important features, we can prioritize data preprocessing, feature extraction, or feature selection techniques to enhance the model’s accuracy.
- Feature Subset Selection: Feature importance can assist in selecting the most relevant subset of features for prediction tasks. By considering only the most important features, we can simplify the model’s complexity and improve interpretability. This can lead to higher confidence scores and more reliable predictions.
- Interpretability and Explainability: The importance of features plays a crucial role in the interpretability and explainability of machine learning models. Models that assign high importance to features that are easily interpretable by humans tend to have higher confidence scores. This allows decision-makers to understand why the model makes certain predictions and enhances trust in the model’s output.
It’s important to note that the method used to calculate feature importance can vary depending on the machine learning algorithm and the specific problem domain. Common techniques for assessing feature importance include statistical measures (e.g., correlation, mutual information), model-specific approaches (e.g., coefficients in linear regression), and tree-based methods (e.g., Gini importance, permutation importance).
By considering feature importance in the confidence score calculation, we can gain valuable insights into the relevance and impact of different features on the model’s predictions. This understanding enhances the interpretability, performance, and reliability of machine learning models.
How to Calculate Confidence Score in Machine Learning
The calculation of the confidence score in machine learning depends on the specific algorithm and problem being addressed. However, there are some common approaches and techniques that are widely used to calculate the confidence score. Here’s an overview of the typical steps involved:
- Training the Model: The first step is to train a machine learning model using labeled data. The model learns patterns and relationships in the data to make predictions or classifications.
- Obtaining Prediction Probabilities: After training, the model can generate prediction probabilities for each class or outcome. These probabilities indicate the likelihood of a specific prediction being correct.
- Threshold Determination: Next, a threshold value is set to determine the minimum confidence level required for a prediction to be considered valid. This threshold can be based on domain knowledge, desired accuracy, or specific requirements of the problem.
- Calculating Confidence Score: The confidence score is usually derived from the prediction probabilities using various methods. One common approach is to use the maximum prediction probability among all classes as the confidence score. Alternatively, some algorithms provide built-in mechanisms to calculate the confidence score directly.
In addition to these general steps, there are specific techniques used to calculate the confidence score in different machine learning algorithms:
- Probabilistic Models: Probabilistic models, such as Naive Bayes or Logistic Regression, directly estimate probabilities for each class. The model’s confidence score can be calculated as the predicted probability of the selected class.
- Ensemble Methods: Ensemble methods, like Random Forests or Gradient Boosting, combine multiple individual models to make predictions. The confidence score can be determined by aggregating the probabilities or votes from each individual model.
- Neural Networks: Neural networks, especially in deep learning, often generate prediction probabilities using softmax activation in the output layer. The confidence score can be calculated by taking the maximum value from the softmax output.
It’s worth noting that the calculation of confidence scores is a topic of ongoing research and can vary based on specific algorithm improvements and domain-specific considerations. It’s important to select an approach that aligns with the nature of the problem and the desired level of confidence required for decision-making.
Overall, the calculation of the confidence score involves training the model, obtaining prediction probabilities, setting a threshold, and deriving the confidence score from those probabilities. Understanding the calculation process enables better interpretation and evaluation of the confidence score, leading to more reliable and informed decision-making in machine learning applications.
Algorithms and Techniques for Confidence Score Calculation
Several algorithms and techniques are employed in machine learning to calculate the confidence score, providing valuable insights into the reliability and accuracy of predictions. These approaches may vary based on the problem domain and the specific requirements of the task at hand. Here are some common algorithms and techniques used for confidence score calculation:
- Probabilistic Models: Probabilistic models, such as Naive Bayes and Logistic Regression, are well-suited for calculating confidence scores. These models estimate the probabilities of different classes and can provide reliable confidence measures based on the likelihood of each prediction.
- Ensemble Methods: Ensemble methods like Random Forests and Gradient Boosting, which combine multiple models into a unified prediction, can be used to derive confidence scores. These approaches aggregate predictions from various models and can assign confidence based on the consensus or agreement among the individual model predictions.
- Neural Networks: Neural networks, particularly deep learning models, can generate confidence scores by incorporating softmax activation in the output layer. Softmax assigns probabilities to each class, allowing for the calculation of confidence based on the highest probability prediction. Bayesian neural networks also offer a probabilistic approach to confidence score calculation.
- Margin-based Methods: Margin-based methods, such as Support Vector Machines (SVMs), utilize the concept of decision boundaries to calculate confidence scores. The distance between a data point and the decision boundary serves as an indication of the model’s confidence in the prediction. Larger margins correspond to higher confidence scores.
- Bootstrap Aggregating (Bagging): Bagging is a resampling technique that can be applied to various machine learning algorithms to generate confidence scores. By training multiple models on different subsets of the training data and then aggregating their predictions, bagging can provide an estimation of confidence based on the variability and agreement among the models.
- Calibration Techniques: Calibration techniques are employed to refine confidence scores by aligning them with the actual accuracy of predictions. These techniques aim to minimize miscalibration and ensure that the confidence score corresponds to the true level of accuracy. Examples of calibration methods include Platt scaling and isotonic regression.
It’s worth noting that the availability and suitability of these algorithms and techniques may vary depending on the specific machine learning framework or library being used. Additionally, domain-specific considerations and problem requirements may dictate the choice of algorithm or technique for confidence score calculation.
By leveraging these algorithms and techniques, machine learning models can generate confidence scores that aid in decision-making. These scores provide valuable insights into the reliability and accuracy of predictions, allowing for more informed and trustworthy outcomes in a wide range of applications.
Evaluating Confidence Score: Metrics and Techniques
Evaluating the confidence score in machine learning is crucial to ensure its reliability and effectiveness. Various metrics and techniques are used to assess the quality and performance of confidence scores. By evaluating these scores, we can gain insights into the model’s predictive capabilities. Here are some common metrics and techniques for evaluating confidence scores:
- Accuracy: Accuracy is a fundamental metric used to assess the overall performance of a model. It measures the proportion of correct predictions made by the model. By comparing the predicted outcomes with the ground truth labels, we can determine the accuracy of the model’s confident predictions and assess the reliability of the confidence scores.
- Calibration Metrics: Calibration metrics help evaluate how well the confidence scores align with the actual accuracy of predictions. Common calibration metrics include calibration curves, reliability diagrams, and Brier score. These metrics allow us to assess the calibration of the confidence scores and identify any miscalibration issues that may affect the reliability of the scores.
- Confusion Matrix: Confusion matrix provides a comprehensive view of the accuracy and performance of a model across different classes or outcomes. By analyzing the true positive, true negative, false positive, and false negative rates, we can evaluate the confidence scores for each class and identify any potential biases or inaccuracies.
- Area Under the ROC Curve (AUC-ROC): AUC-ROC is a widely used evaluation metric for binary classification problems. It measures the trade-off between the true positive rate and the false positive rate across different confidence score thresholds. A high AUC-ROC indicates a good separation between positive and negative samples, demonstrating the effectiveness of the confidence scores in distinguishing between classes.
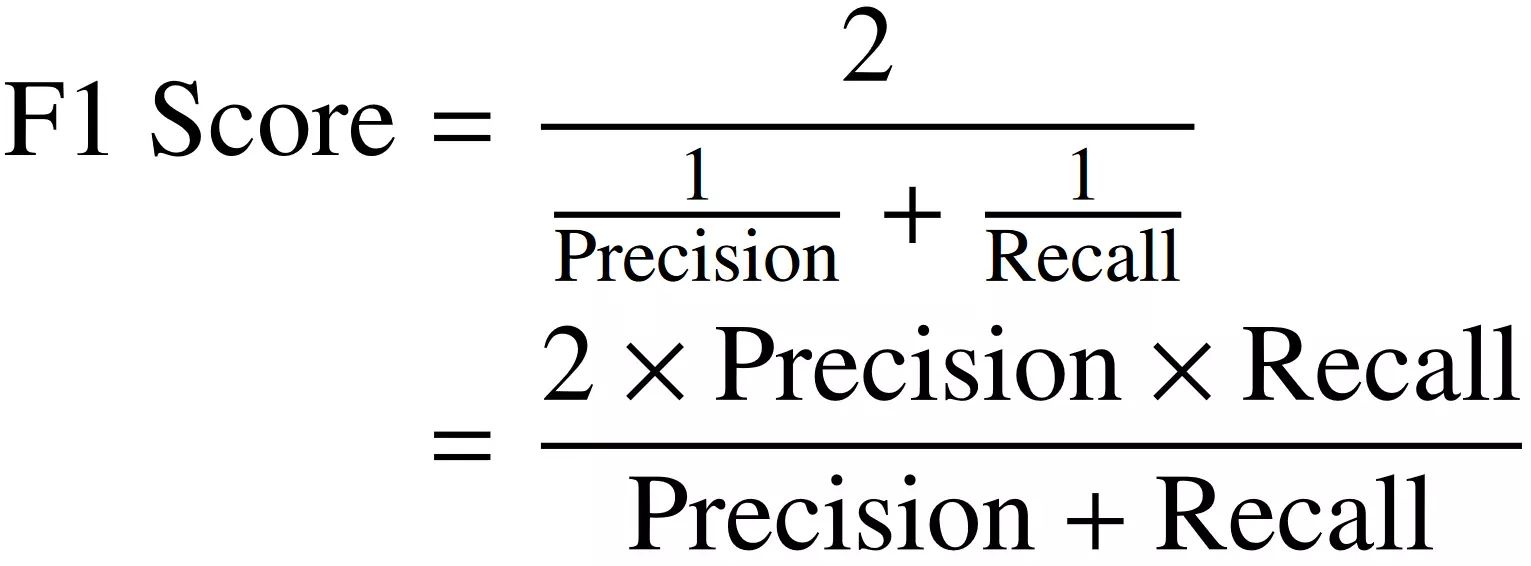
- Precision and Recall: Precision and recall are important metrics for evaluating the model’s performance in binary or multi-class classification tasks. Precision measures the proportion of true positive predictions among all positive predictions, while recall measures the proportion of true positive predictions among all actual positive samples. These metrics help assess the reliability of the confidence scores with respect to true positive predictions.
- Reliability Curves: Reliability curves can provide insights into the calibration of confidence scores. These curves plot the observed accuracy of predictions against the average confidence scores across different confidence intervals. The closer the curve follows the ideal diagonal line, the better the calibration and reliability of the confidence scores.
It’s essential to consider the specific problem domain and the objectives of the machine learning task when selecting the appropriate evaluation metrics and techniques for assessing the confidence scores. The choice of metrics should align with the desired level of accuracy, calibration, and predictive performance.
By leveraging these metrics and techniques, we can evaluate and refine the confidence scores, ensuring their integrity and effectiveness in making informed decisions based on machine learning predictions.
Use Cases and Applications of Confidence Score in Machine Learning
The confidence score in machine learning finds various applications across different domains and use cases. It plays a vital role in decision-making processes where the reliability and accuracy of predictions are of utmost importance. Here are some prominent use cases and applications of the confidence score:
- Fraud Detection: In fraud detection systems, the confidence score helps identify potentially fraudulent transactions or activities. A high confidence score indicates a high likelihood of fraud, enabling quick action to prevent financial losses.
- Medical Diagnostics: Confidence scores are valuable in medical diagnostics, where accurate and reliable predictions are critical. Confidence scores can assist in determining the likelihood of a particular disease or condition, aiding healthcare professionals in making informed treatment decisions.
- Customer Churn Prediction: For businesses, predicting customer churn is essential for retention strategies. Confidence scores can help identify customers at high risk of churn, enabling targeted interventions to retain them.
- Sentiment Analysis: In sentiment analysis, the confidence score allows for the classification of text or social media posts as positive, negative, or neutral. The confidence score indicates the reliability of the sentiment prediction, helping businesses understand customer opinions and make data-driven decisions.
- Anomaly Detection: Anomaly detection systems utilize confidence scores to identify unusual or anomalous patterns in data. By setting a threshold on the confidence score, these systems can flag and investigate potential anomalies, such as network intrusions or fraudulent behavior.
- Speech and Image Recognition: Confidence scores are utilized in speech and image recognition systems to determine the accuracy and reliability of the identified speech or image features. This enables more reliable and confident recognition of spoken words or object identification in images.
- Autonomous Vehicles: In autonomous vehicle systems, confidence scores play a crucial role in decision-making. They help assess the reliability of object detection, obstacle avoidance, and navigation algorithms, ensuring safe and accurate autonomous driving.
- Credit Scoring: Confidence scores can be used in credit scoring models to estimate the risk associated with granting credit to individuals or businesses. A high confidence score indicates a low risk of default, facilitating informed lending decisions.
These are just a few examples of how confidence scores are utilized in various real-world applications. The confidence score provides a quantitative measure of reliability, allowing businesses and organizations to make informed decisions and take appropriate actions based on machine learning predictions.
Challenges and Limitations of Confidence Score Calculation
While confidence scores are valuable in assessing the reliability of machine learning predictions, there are several challenges and limitations associated with their calculation. It is important to be aware of these limitations to make informed decisions and interpretations. Here are some common challenges and limitations of confidence score calculation:
- Data Quality: The accuracy and quality of the training data directly impact the reliability of confidence scores. If the training data is biased, incomplete, or of poor quality, the confidence scores may be inaccurate or unreliable.
- Overfitting: Machine learning models can sometimes become overfitted to the training data, resulting in overconfident predictions and high confidence scores. This can lead to poor generalization on new, unseen data and inaccurate confidence assessments.
- Imbalanced Data: In situations where the dataset is imbalanced, i.e., one class has significantly fewer instances than the other, the confidence scores for the minority class may be relatively lower. This can make it challenging to set an appropriate threshold for confident predictions.
- Threshold Selection: Determining the appropriate threshold for accepting confident predictions can be subjective and domain-specific. Setting the threshold too low may result in accepting unreliable predictions, while setting it too high may lead to rejecting potentially accurate predictions.
- Unknown Unknowns: Confidence scores may not account for unknown unknowns, meaning situations where the model encounters data that is fundamentally different from what it was trained on. In such cases, the confidence scores may be misleading and not reflect the true reliability of the predictions.
- Interpretability: Confidence scores themselves may lack interpretability, especially in complex machine learning models. It can be challenging to understand why a particular confidence score was assigned, making it difficult to trust and interpret the reliability of the predictions.
- Domain Shift: Confidence scores may be affected by domain shifts, where the distribution of the test data differs significantly from the training data. This can lead to a mismatch between the confidence scores and the actual reliability of the predictions.
It’s crucial to understand these challenges and limitations when interpreting and utilizing confidence scores in machine learning applications. These limitations highlight the need for ongoing research and development to improve confidence score calculation methods and address these challenges in practice.