Introduction
Welcome to this guide on how to calculate accuracy in machine learning. Accuracy is an essential performance metric used to evaluate the effectiveness of machine learning models. In the realm of supervised learning, where models are trained on labeled datasets, accuracy measures the proportion of correct predictions made by the model. It provides a valuable insight into how well a model is able to classify or predict outcomes.
As machine learning continues to revolutionize various industries, understanding and analyzing accuracy is crucial for assessing the performance and reliability of models. By calculating accuracy, developers and data scientists can determine how well their models are performing, identify areas for improvement, and make informed decisions about model selection.
In this guide, we will walk you through the process of calculating accuracy in machine learning. We will delve into the definition of accuracy, highlighting its importance and how it is calculated. Additionally, we will provide examples to help you better understand the concept and discuss the limitations of accuracy as a performance metric. Finally, we will explore alternative performance metrics that provide a more comprehensive evaluation of model performance.
Whether you are a beginner in the field of machine learning or an experienced practitioner, this guide will equip you with the knowledge and tools to effectively calculate accuracy and make informed decisions about your models.
What is accuracy in machine learning?
Accuracy is a performance metric commonly used in machine learning to evaluate the effectiveness of classification models. It measures the proportion of correct predictions made by a model out of the total number of predictions. This metric provides a clear indication of how well a model is able to classify or predict outcomes.
In a classification problem, the goal is to assign input data into specific categories or classes. For example, classifying an email as spam or non-spam, or identifying handwritten digits as numbers from 0 to 9. Accuracy reflects the model’s ability to correctly categorize unseen data based on patterns and relationships learned during the training phase.
The accuracy score is calculated by dividing the number of correct predictions by the total number of predictions, and is often represented as a percentage. A higher accuracy score indicates that the model is more successful in correctly predicting the class labels for the given dataset.
For example, if we have a dataset with 100 samples and our model predicts 80 of them correctly, the accuracy will be calculated as 80/100 = 0.8 or 80%. This means the model has an accuracy of 80%, implying that it correctly classifies 80% of the unseen data.
Accuracy is a widely used performance metric due to its simplicity and interpretability. It provides a straightforward evaluation of how well a model is performing, making it easier to compare different models and select the best one for a given task.
While accuracy is a useful metric, it should be noted that it may not always be the most appropriate measure of a model’s performance, especially in scenarios with imbalanced datasets or when different types of classification errors have varying consequences. Nevertheless, accuracy remains a fundamental metric in machine learning evaluation, forming the basis for more complex performance metrics such as precision, recall, and F1 score.
Why is accuracy important?
Accuracy is a crucial metric in machine learning as it provides a fundamental assessment of how well a model is performing in classifying or predicting outcomes. Here are some key reasons why accuracy is important:
Evaluation of Model Performance: Accuracy allows us to measure and compare the performance of different models. It serves as a benchmark to determine the effectiveness of a model in making correct predictions and helps in selecting the best model for a particular task.
Quality Control and Decision Making: Accuracy plays a vital role in various industries where the reliability and correctness of predictions are crucial. For instance, in healthcare, accurate predictions can aid in disease diagnosis and treatment recommendations. In finance, accurate models can assist in credit risk assessment and fraud detection. Accuracy helps decision-makers have confidence in the outputs generated by machine learning models.
Improvement of Models: By calculating accuracy, data scientists and machine learning practitioners can identify areas of a model that need improvement. This evaluation metric serves as a feedback mechanism for model refinement, leading to higher accuracy and better performance over time.
Interpretability and Transparency: Accuracy provides an understandable measure of model performance. It helps stakeholders, including end-users and decision-makers, to comprehend and assess the reliability of the machine learning system. Additionally, accuracy facilitates the communication of model outputs and predictions to non-technical individuals.
Comparison with Baseline Models: Accuracy allows for comparisons with baseline models or “naive” approaches. This comparison enables us to identify if our machine learning model is providing a significant improvement over a simple or random guessing strategy. It helps in gauging the value and effectiveness of investing resources in building and deploying the model.
While accuracy is an important metric, it is worth noting that it may not be suitable in all situations. In cases where class imbalance is present, accuracy can be misleading. For instance, if a binary classification problem has a significantly imbalanced dataset, where one class has a much higher occurrence than the other, a model that only predicts the majority class will have a high accuracy but may not be truly effective.
Therefore, it is essential to consider the context and the specific requirements of a problem while evaluating model performance. Other performance metrics such as precision, recall, F1 score, or area under the ROC curve (AUC-ROC) may provide a more comprehensive and accurate assessment of a model’s performance in different scenarios.
How to calculate accuracy
Calculating accuracy in machine learning involves determining the proportion of correctly predicted instances compared to the total number of instances in a dataset. Here’s a step-by-step guide on how to calculate accuracy:
- Step 1: Prepare the dataset
- Step 2: Train the model
- Step 3: Generate predictions
- Step 4: Compare predictions to ground truth labels
- Step 5: Calculate accuracy
- Step 6: Interpret the accuracy score
Ensure that you have a labeled dataset with known ground truth values for the target variable. This dataset should be divided into two subsets: a training set used to train the model and a testing set used to evaluate its performance. The testing set should contain instances that the model has not been exposed to during training.
Choose an appropriate machine learning algorithm and train it using the labeled training set. The model will learn patterns and relationships between input features and target labels during the training process.
Using the trained model, make predictions on the instances in the testing set. The model will assign predicted labels to these instances based on the patterns it learned during training.
Compare the predicted labels with the known ground truth labels for the instances in the testing set. Identify the instances where the predicted label matches the ground truth label.
Divide the number of correctly predicted instances by the total number of instances in the testing set. Multiply the result by 100 to obtain the accuracy score as a percentage.
Accuracy = (Number of Correctly Predicted Instances / Total Number of Instances) * 100
An accuracy score of 100% indicates that the model has made correct predictions for all instances in the testing set. Lower accuracy scores indicate that some instances were incorrectly predicted. The higher the accuracy score, the more reliable the model’s predictions are.
By following these steps, you can calculate accuracy for your machine learning model and gain insights into its performance. Remember that accuracy alone may not provide a complete picture of a model’s efficacy, especially in cases with imbalanced datasets or when different types of classification errors have varying consequences. Therefore, it is important to consider other performance metrics as well to assess the overall performance of a model.
Example: Calculating accuracy for a binary classification model
Let’s walk through an example to illustrate how to calculate accuracy for a binary classification model. In this scenario, we will consider a model that predicts whether an email is spam or not spam.
Suppose we have a testing dataset of 200 emails, and the ground truth labels indicate that 150 emails are non-spam (negative class) and 50 emails are spam (positive class). After training our model, we apply it to the testing dataset and obtain the following predictions:
- Correctly predicted non-spam: 140 emails
- Incorrectly predicted non-spam (false negatives): 10 emails
- Correctly predicted spam: 45 emails
- Incorrectly predicted spam (false positives): 5 emails
To calculate the accuracy, we sum up the correctly predicted instances (140 non-spam and 45 spam) and divide it by the total number of instances (200 emails). Finally, we multiply the result by 100 to express it as a percentage:
Accuracy = ((140 + 45) / 200) * 100 = 92.5%
The accuracy of our binary classification model is 92.5%. This means that the model correctly classifies 92.5% of the emails in the testing set as either spam or non-spam.
It’s important to interpret accuracy in the context of the problem domain. While 92.5% accuracy may seem impressive, it is essential to consider other performance metrics, such as precision, recall, and F1 score, to gain a more comprehensive understanding of the model’s performance and any potential trade-offs between true positives, false positives, true negatives, and false negatives.
By following this example, you can calculate the accuracy for your own binary classification models and evaluate their effectiveness in making accurate predictions.
Example: Calculating accuracy for a multi-class classification model
Now we will explore an example to illustrate how to calculate accuracy for a multi-class classification model. Imagine we have developed a model that predicts the species of flowers based on various features, such as petal length, petal width, sepal length, and sepal width. The dataset consists of 150 instances, with three flower species: setosa, versicolor, and virginica.
After training and evaluating the model on a testing dataset, let’s say the model made the following predictions:
- Setosa: correctly predicted 45 flowers
- Versicolor: correctly predicted 35 flowers
- Virginica: correctly predicted 40 flowers
- Misclassifications: 5 flowers
To calculate the accuracy for this multi-class classification model, we sum up the number of correctly predicted flowers for each class (45, 35, and 40) and divide it by the total number of flowers (150). Finally, we multiply the result by 100 to express it as a percentage:
Accuracy = ((45 + 35 + 40) / 150) * 100 = 73.33%
The accuracy of our multi-class classification model is 73.33%. This means that the model correctly classifies 73.33% of the flowers in the testing set into their respective species.
When working with multi-class classification problems, accuracy provides a valuable measure of overall model performance. However, it’s important to note that accuracy alone may not provide insights into how well the model performs for each individual class. For a more detailed analysis, you can consider other performance metrics such as precision, recall, and F1 score for each class.
By following this example, you can calculate the accuracy for your own multi-class classification models and gauge their ability to correctly classify instances across multiple classes.
Limitations of accuracy as a performance metric
While accuracy is a commonly used performance metric in machine learning, it is important to be aware of its limitations. Accuracy may not always provide a complete and accurate representation of a model’s performance. Here are some key limitations to consider:
Imbalanced Datasets: Accuracy can be misleading in datasets where the classes are imbalanced, meaning one class has significantly more instances than the others. In such cases, a model that predicts the majority class for all instances may achieve high accuracy, even though it fails to correctly classify the minority class. It is essential to consider other metrics such as precision, recall, and F1 score, which take the class imbalances into account.
Unequal Misclassification Costs: Accuracy assumes that all misclassifications have equal costs or consequences. However, in many real-life scenarios, the cost of misclassifying different classes can vary. For example, in detecting cancers, a false negative (misclassifying a cancer patient as healthy) may have severe consequences compared to a false positive (misclassifying a healthy person as having cancer). Accuracy alone does not provide insights into the trade-offs between different types of misclassifications.
Misinterpretation in Skewed Datasets: Accuracy can be misleading when the dataset is heavily skewed towards one class. For example, in a dataset where 95% of instances belong to one class, a model that labels all instances as that class will achieve high accuracy. However, this model is not useful, as it does not capture the patterns or characteristics of the other class. Therefore, it is crucial to carefully evaluate model performance using multiple metrics and consider the practical implications of the results.
Context-Specific Evaluation: Accuracy may not be the most appropriate metric in certain domains or applications. For example, in recommendation systems, accuracy alone does not account for the relevance or utility of recommendations to users. Other metrics like precision at a certain recall level or mean average precision might be more relevant in such cases.
Assumption of Binary Decision Threshold: Accuracy assumes a binary decision threshold for classification models. However, in certain scenarios, the decision threshold might need to be adjusted based on the specific trade-offs between false positives and false negatives. Evaluation metrics like the receiver operating characteristic (ROC) curve and area under the curve (AUC) provide a more comprehensive analysis of the model’s performance across various thresholds.
Understanding these limitations of accuracy can help in conducting a more nuanced evaluation of model performance and selecting appropriate evaluation metrics to gain a comprehensive understanding of a machine learning model’s strengths and weaknesses.
Other performance metrics to consider
While accuracy is a widely used performance metric in machine learning, it is important to consider additional metrics that provide a more nuanced evaluation of model performance. Here are some other performance metrics to consider:
Precision: Precision measures the proportion of correctly predicted positive instances out of the total instances predicted as positive by the model. It is calculated as the number of true positives divided by the sum of true positives and false positives. Precision helps assess the model’s ability to minimize false positives.
Recall: Recall, also known as sensitivity or true positive rate, measures the proportion of correctly predicted positive instances out of the total actual positive instances in the dataset. It is calculated as the number of true positives divided by the sum of true positives and false negatives. Recall helps assess the model’s ability to capture all positive instances, minimizing false negatives.
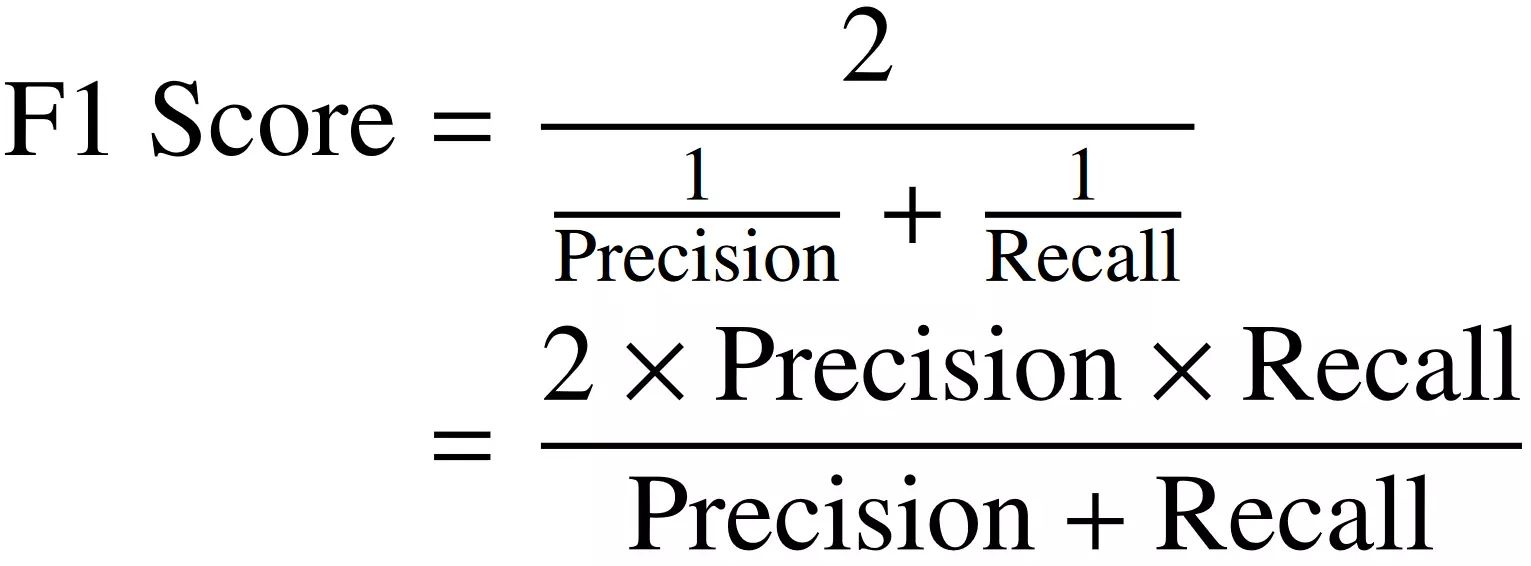
F1 Score: The F1 score is the harmonic mean of precision and recall. It provides a balanced measure of a model’s performance by considering both false positives and false negatives. The F1 score is particularly useful when there is an uneven class distribution or when false positives and false negatives have different consequences.
Area under the ROC Curve (AUC-ROC): The AUC-ROC metric measures the performance of a binary classification model across various decision thresholds. It plots the true positive rate (TPR or recall) against the false positive rate (FPR). A higher AUC-ROC score indicates better model performance in distinguishing between positive and negative instances.
Mean Average Precision (mAP): mAP is commonly used in object detection and information retrieval tasks. It calculates the average precision for each class and then takes the mean across all classes. mAP provides an overall performance measure by considering both precision and recall across multiple classes.
Log Loss: Log loss, or logarithmic loss, measures the performance of probabilistic models. It quantifies the accuracy of a model by penalizing incorrect predictions, resulting in a more fine-grained evaluation. Log loss is commonly used in scenarios where the output should represent a probability distribution over multiple classes.
These metrics provide a more comprehensive understanding of a model’s performance beyond accuracy. They help assess various aspects such as true positives, false positives, false negatives, precision, recall, and the trade-offs between them. By considering these metrics, you can gain a more nuanced evaluation of your machine learning model and make informed decisions in different scenarios.
Conclusion
Accuracy is a fundamental performance metric in machine learning that measures the proportion of correct predictions made by a model out of the total number of predictions. It provides an intuitive and straightforward evaluation of how well a model is performing in classifying or predicting outcomes.
However, it is important to be aware of the limitations of accuracy as a performance metric. Imbalanced datasets, unequal misclassification costs, skewed datasets, context-specific evaluation, and assumptions of binary decision thresholds are factors that can impact the interpretability and applicability of accuracy.
To gain a more comprehensive evaluation of a model’s performance, it is essential to consider additional performance metrics such as precision, recall, F1 score, AUC-ROC, mean average precision, and log loss. These metrics provide valuable insights into the model’s ability to minimize false positives, false negatives, and capture all relevant instances.
As machine learning continues to evolve and be applied in various domains, understanding and effectively calculating performance metrics is crucial. By leveraging a combination of performance metrics, data scientists and machine learning practitioners can evaluate models more accurately, make informed decisions about model selection, and identify areas for improvement.
In conclusion, accuracy serves as a foundational metric for assessing model performance, but it should be complemented by other metrics to obtain a more comprehensive understanding of a model’s strengths and weaknesses. Considering different performance metrics leads to a more informed evaluation and empowers stakeholders to confidently utilize machine learning models in real-world applications.