Introduction
Machine Learning is a rapidly growing field that involves the development of algorithms and models that allow computers to learn from data and make predictions or decisions without being explicitly programmed. One of the key tasks in machine learning is measuring the performance and evaluating the accuracy of these models.
When it comes to evaluating the effectiveness of a machine learning model, there are several metrics available. F-Measure, also known as F1-Score, is one such metric that is commonly used in machine learning to assess the overall performance of a model.
In essence, the F-Measure takes into account both precision and recall, two fundamental components of a classification model’s performance. It provides a single value that represents the model’s accuracy, making it a popular metric for comparing different models and selecting the best one for a given task.
The F-Measure has gained significant importance in the field of machine learning, as it allows practitioners to balance the trade-off between precision and recall. It is particularly useful in scenarios where class imbalance exists, or when the cost of false positives and false negatives is significantly different.
Throughout this article, we will delve deeper into the concept of F-Measure, understand its calculation, explore its importance in machine learning, and discuss its advantages and limitations. By the end, you will have a comprehensive understanding of this crucial metric and its role in evaluating machine learning models.
Definition of F-Measure
The F-Measure, also known as the F1-Score, is a measure of a classification model’s accuracy that takes into account both precision and recall. It provides a single value that represents the harmonic mean of these two metrics, thereby offering a balanced view of the model’s performance.
Precision is a measure of the proportion of correctly predicted positive instances out of all predicted positive instances. In simpler terms, it calculates how ‘precise’ the model is when identifying true positive cases. On the other hand, recall, also known as sensitivity or true positive rate, measures the proportion of correctly predicted positive instances out of all actual positive instances. It determines how ‘sensitive’ the model is in identifying the positive cases.
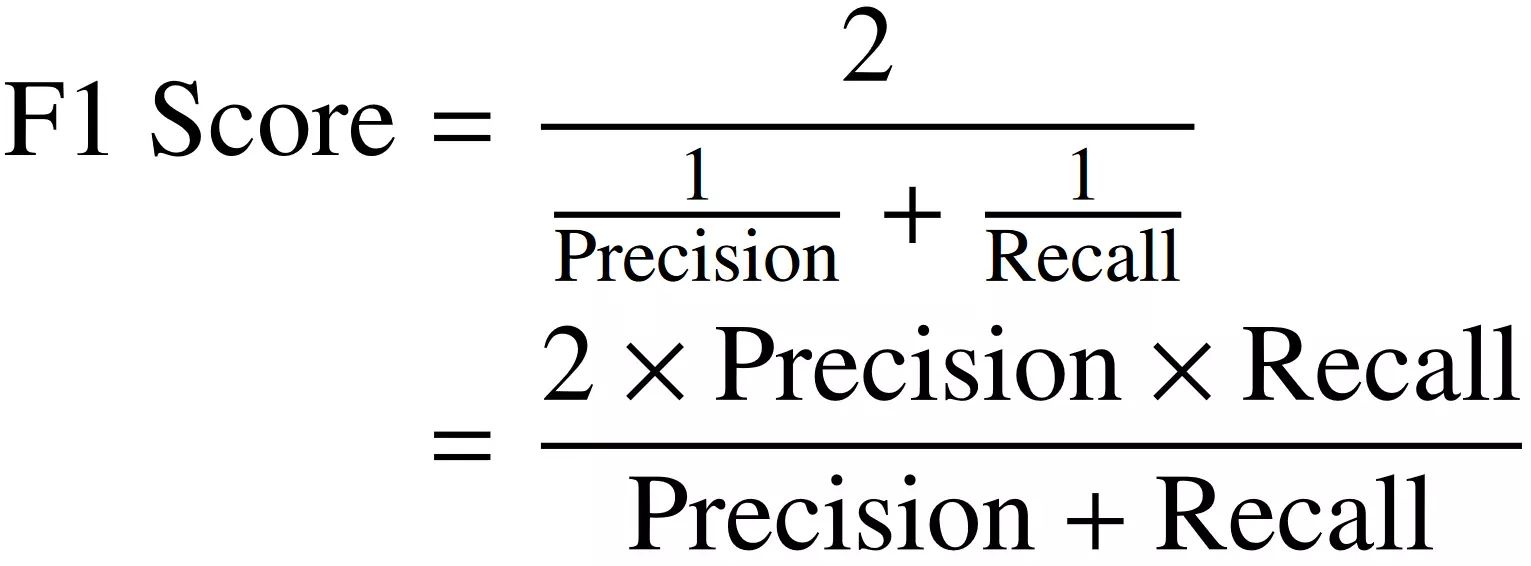
The F-Measure combines these two metrics to provide a comprehensive evaluation of the model’s performance. It takes into account both the precision and recall by calculating the harmonic mean of these two values. The harmonic mean is used instead of the arithmetic mean to give equal significance to both precision and recall, even if one of them is significantly lower than the other.
The formula to calculate the F-Measure can be written as:
F-Measure = 2 * ((Precision * Recall) / (Precision + Recall))
The resulting F-Measure value ranges between 0 and 1, where a value of 0 represents poor performance and a value of 1 represents perfect performance. A higher F-Measure indicates that the model has achieved a good balance between precision and recall.
It’s important to note that the F-Measure is most commonly used when dealing with imbalanced datasets or when the cost of false positives and false negatives is significantly different. This is because it places equal importance on both precision and recall, allowing practitioners to adjust the trade-off based on specific requirements.
Precision and Recall
Precision and recall are two crucial metrics used to evaluate the performance of classification models, and they serve as the building blocks for calculating the F-Measure.
Precision measures how accurately the model predicts the positive instances out of all the instances it classified as positive. It is calculated by dividing the number of true positive instances by the sum of true positive and false positive instances. In other words, precision assesses the proportion of correctly predicted positive instances out of all instances predicted as positive. A high precision indicates that the model has a low rate of false positives.
On the other hand, recall, also known as sensitivity or true positive rate, measures the model’s ability to correctly identify positive instances out of all the actual positive instances. It is calculated by dividing the number of true positive instances by the sum of true positive and false negative instances. In simpler terms, recall determines the proportion of correctly predicted positive instances out of all actual positive instances. A high recall indicates that the model has a low rate of false negatives.
While precision and recall are both important metrics, they often have an inverse relationship with each other. Increasing the model’s precision may lead to a decrease in recall, and vice versa. This is known as the precision-recall trade-off and is typically observed in imbalanced datasets or scenarios where the cost of false positives and false negatives is significantly different.
To illustrate this trade-off, let’s consider an example where the task is to identify fraudulent credit card transactions. With a high precision model, the number of false positives (legitimate transactions flagged as fraudulent) will be low, resulting in a low rate of false accusations. However, in this scenario, the recall may suffer as the model may miss out on some actual fraudulent transactions, leading to a high rate of false negatives. On the other hand, with a high recall model, the number of false negatives (fraudulent transactions classified as legitimate) will be low, minimizing the risk of missing actual fraud. However, the model may also flag many legitimate transactions as fraudulent, resulting in a high rate of false positives and reduced precision.
The F-Measure takes into account both precision and recall to provide a balanced evaluation of the model’s performance. It considers the harmonic mean of these two metrics, ensuring that a good balance is achieved between them.
Calculating the F-Measure
The F-Measure combines precision and recall into a single value that represents the overall performance of a classification model. It provides a balance between these two metrics and is calculated using a simple formula.
To calculate the F-Measure, we first compute the precision and recall for the model. The precision is calculated by dividing the number of true positive instances by the sum of true positive and false positive instances. Recall is calculated by dividing the number of true positive instances by the sum of true positive and false negative instances.
Once we have the precision and recall values, we can then calculate the F-Measure using the following formula:
F-Measure = 2 * ((Precision * Recall) / (Precision + Recall))
The resulting F-Measure value ranges between 0 and 1, where a value of 0 indicates poor performance and a value of 1 represents perfect performance.
Let’s consider an example to illustrate the calculation of the F-Measure. Suppose we have a binary classification model that predicts whether an email is spam or not. After evaluating the model on a test dataset, we obtain the following performance metrics:
Precision: 0.85
Recall: 0.78
To calculate the F-Measure, we plug these values into the formula:
F-Measure = 2 * ((0.85 * 0.78) / (0.85 + 0.78))
F-Measure = 2 * (0.663 / 1.63)
F-Measure = 1.287 / 1.63
F-Measure ≈ 0.790
In this example, the F-Measure of the model is approximately 0.790, indicating a reasonably balanced performance in terms of precision and recall.
By calculating the F-Measure, we can assess the overall effectiveness of a classification model and compare multiple models to determine the best one for a given task. It provides a single value that considers both precision and recall, allowing us to find the optimal balance between these two metrics.
Importance of F-Measure in Machine Learning
The F-Measure plays a significant role in machine learning as it provides a comprehensive evaluation of a classification model’s performance. Here are some key reasons why the F-Measure is important:
1. Balancing Precision and Recall: Unlike other metrics that focus solely on precision or recall, the F-Measure combines both metrics into a single value. This allows practitioners to strike a balance between precision (how precise the model is in identifying positive instances) and recall (how sensitive the model is in identifying positive instances). The F-Measure provides a holistic view of the model’s effectiveness by considering both aspects, ensuring that the model performs well in terms of both false positives and false negatives.
2. Handling Imbalanced Datasets: In real-world scenarios, datasets are often imbalanced, meaning that the number of instances in one class significantly outweighs the other. In such cases, accuracy alone may not provide an accurate measure of the model’s performance. The F-Measure, by considering both precision and recall, is better suited to tackle this issue. It allows practitioners to evaluate the model’s performance on both classes, ensuring that it performs well on the minority class as well.
3. Cost-Sensitive Applications: In some applications, the cost of false positives and false negatives may differ significantly. For example, in medical diagnosis, a false negative (misdiagnosing a disease) may have severe consequences, while a false positive (diagnosing a disease when there is none) could lead to unnecessary interventions. The F-Measure, by balancing precision and recall, allows practitioners to adjust the trade-off between these costs based on the specific requirements of the application.
4. Model Selection and Comparison: The F-Measure is a valuable metric for comparing different models and selecting the best one for a given task. By calculating the F-Measure for multiple models, practitioners can identify the model that strikes the best balance between precision and recall. This helps in determining the most suitable model that will perform well in terms of both false positives and false negatives.
5. Performance Optimization: The F-Measure can be used as an optimization objective in machine learning algorithms. By optimizing the F-Measure, practitioners can fine-tune the model parameters or make algorithmic adjustments to improve the overall performance of the model in terms of both precision and recall.
In summary, the F-Measure is an important metric in machine learning as it provides a balanced evaluation of classification models. By considering both precision and recall, it allows practitioners to strike a balance between false positives and false negatives, making it particularly valuable in scenarios with imbalanced datasets or cost-sensitive applications.
Advantages and Limitations of F-Measure
The F-Measure is a widely used metric in machine learning for evaluating the performance of classification models. It offers several advantages, but it also has its limitations. Let’s explore the advantages and limitations of the F-Measure:
Advantages:
1. Balance Between Precision and Recall: One of the main advantages of the F-Measure is that it provides a balanced evaluation of a classification model’s performance by considering both precision and recall. This allows practitioners to assess the model’s effectiveness in terms of both false positives and false negatives, making it a valuable metric in tasks where both aspects are equally important.
2. Handling Imbalanced Datasets: The F-Measure is particularly useful in dealing with imbalanced datasets. In such scenarios, where the number of instances in one class significantly outweighs the other, accuracy alone may not provide an accurate measure of the model’s performance. The F-Measure, by combining precision and recall, provides a more reliable evaluation by considering the performance on both classes, ensuring that the model performs well on the minority class as well.
3. Flexibility in the Trade-off: The F-Measure allows practitioners to adjust the trade-off between precision and recall based on the specific requirements of the application. This flexibility is especially beneficial in cost-sensitive applications, where the cost of false positives and false negatives may differ significantly. By optimizing the F-Measure, practitioners can find the optimal balance that minimizes the overall cost.
Limitations:
1. Single Metric Evaluation: While the F-Measure provides a single value that represents the overall performance of a classification model, it is important to note that it is just one metric among many others. Depending on the specific requirements of the task, other metrics such as accuracy, specificity, or area under the ROC curve may also be important to consider.
2. Sensitivity to Threshold: The F-Measure, like other metrics based on precision and recall, is sensitive to the threshold used to make binary predictions. Changing the threshold can significantly impact the precision, recall, and ultimately, the F-Measure value. This sensitivity should be taken into account when interpreting the F-Measure results and comparing different models.
3. Does Not Capture Other Errors: The F-Measure focuses primarily on false positives and false negatives but does not capture other types of errors. For example, it does not consider the rate of true negatives, which can be important in certain applications. Therefore, it is essential to assess the F-Measure in conjunction with other metrics to gain a comprehensive understanding of the model’s performance.
In summary, the F-Measure offers a balanced evaluation of classification model performance and is particularly useful in imbalanced datasets and cost-sensitive applications. However, it should be considered alongside other metrics and its limitations in terms of being a single metric and sensitivity to threshold values should be taken into account.
Conclusion
The F-Measure, also known as the F1-Score, is a vital metric in machine learning for evaluating the performance of classification models. By considering both precision and recall, it offers a balanced assessment of a model’s effectiveness, making it an essential tool for practitioners in various fields.
In this article, we have explored the definition of the F-Measure and its calculation, understanding how it combines precision and recall to provide a comprehensive measure of a model’s accuracy. Moreover, we have highlighted the importance of the F-Measure in machine learning, such as its ability to handle imbalanced datasets and adjust the trade-off between false positives and false negatives based on specific requirements.
Additionally, we have discussed the advantages of the F-Measure, including its balance between precision and recall, its flexibility in handling imbalanced datasets, and its usefulness in cost-sensitive applications. However, we have also acknowledged the limitations of the F-Measure, such as its sensitivity to threshold values and its focus on false positives and false negatives without capturing other types of errors.
Overall, the F-Measure provides valuable insights into the performance of classification models. It serves as a guide for model selection and comparison, helps optimize performance, and aids in decision-making in real-world applications. While it is crucial to consider other metrics alongside the F-Measure and be aware of its limitations, its ability to balance precision and recall makes it a powerful tool in the evaluation and improvement of machine learning models.