Introduction
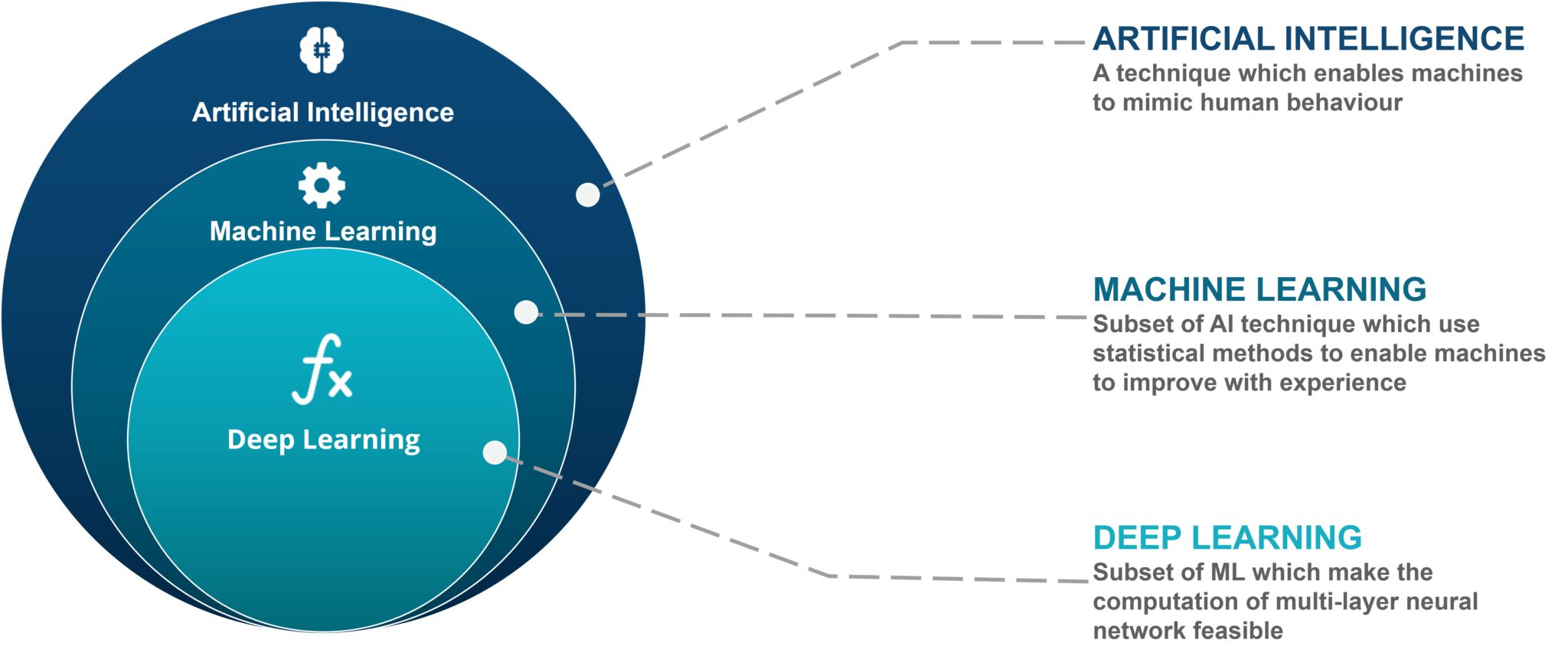
Machine Learning and Deep Learning are two revolutionary technologies that have gained significant popularity in recent years. Both of these fields are subsets of Artificial Intelligence (AI), and their applications have revolutionized various industries including healthcare, finance, retail, and more.
Machine Learning involves the development of algorithms and statistical models that enable computers to learn from and make predictions or decisions based on data, without being explicitly programmed. It focuses on providing systems with the ability to learn and improve through experience.
On the other hand, Deep Learning, a subfield of Machine Learning, goes a step further by using artificial neural networks to simulate the functioning of the human brain. Deep Learning algorithms are designed to learn and understand complex patterns and relationships in data by using multiple layers of interconnected nodes.
Both Machine Learning and Deep Learning enable us to analyze vast amounts of data, identify patterns, and make predictions or take actions based on those patterns. However, there are important differences between these two approaches that are worth exploring.
In this article, we will delve deeper into the definitions, algorithms, data requirements, training and performance aspects, as well as the applications and advantages and disadvantages of both Machine Learning and Deep Learning. By understanding these differences, you will be able to make informed decisions regarding which approach is best suited for your specific needs.
Definition of Machine Learning
Machine Learning refers to the field of study and development of algorithms that enable computers to learn from data and improve their performance over time, without being explicitly programmed. It is concerned with the design and development of computational models that can automatically learn and make predictions or decisions based on patterns and relationships in data.
The core idea behind Machine Learning is to create systems that can continually learn and adapt without being explicitly programmed for every possible scenario. Instead, these systems use algorithms that automatically adjust their behavior based on patterns and correlations found in the training data.
Machine Learning can be categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the algorithm is trained on a labeled dataset, where each data point is associated with a known outcome or target variable. The algorithm learns to map input variables to the desired output by identifying patterns in the labeled data.
Unsupervised learning, on the other hand, involves training the algorithm on an unlabeled dataset, where the data points do not have any predefined outcomes. The algorithm learns to identify patterns and relationships in the data without any external guidance. It can be used for tasks such as clustering, anomaly detection, and dimensionality reduction.
Reinforcement learning is a type of Machine Learning where an agent learns to make decisions or take actions in an environment to maximize a reward signal. The algorithm interacts with the environment, learns from the feedback it receives, and adjusts its behavior accordingly. This approach is often used in applications such as autonomous driving, robotics, and game playing.
Overall, Machine Learning is a versatile and powerful approach that has revolutionized data analysis and decision making. It enables computers to learn from data and make predictions or decisions without being explicitly programmed, opening up a wide range of possibilities for applications in various industries.
Definition of Deep Learning
Deep Learning, a subfield of Machine Learning, is a branch of Artificial Intelligence that focuses on developing algorithms inspired by the structure and function of the human brain. It aims to enable computers to learn, understand, and make decisions based on complex patterns and relationships in data.
The key characteristic of Deep Learning is the use of artificial neural networks, which are composed of interconnected nodes or “neurons.” These networks are designed to simulate the behavior and functionality of the human brain, allowing for the processing and interpretation of large amounts of data.
Deep Learning algorithms are built using multiple layers of neurons, each layer performing specific calculations and passing the results to the next layer. These layers enable the algorithm to extract increasingly abstract features from the input data, resulting in a hierarchy of representations that capture intricate patterns and nuances.
The ability of Deep Learning algorithms to automatically learn hierarchical representations from data makes them well-suited for handling complex tasks such as image and speech recognition, natural language processing, and even game playing. Deep Learning has achieved remarkable success in these domains, surpassing the performance of traditional machine learning approaches.
One of the key advantages of Deep Learning is its ability to learn directly from raw data. Unlike other machine learning algorithms that require handcrafted features, Deep Learning algorithms can automatically learn and extract relevant features from the data, reducing the need for manual feature engineering.
Deep Learning also benefits from the availability of massive amounts of data and advances in computing power. The ability to process and train on vast amounts of data allows Deep Learning algorithms to improve their performance and accuracy, as they have access to a broader range of information.
Overall, Deep Learning is a powerful approach that has revolutionized various domains by enabling computers to learn and make decisions based on complex patterns and relationships in data. Its ability to automatically learn hierarchical representations and process large amounts of data has propelled it to be at the forefront of Artificial Intelligence research and applications.
Understanding Machine Learning Algorithms
Machine Learning algorithms are the driving force behind the learning and decision-making capabilities of Machine Learning systems. These algorithms are designed to analyze data, identify patterns, and make predictions or decisions based on those patterns. Understanding different types of Machine Learning algorithms is essential to grasp the nuances and applications of this field.
There are several types of Machine Learning algorithms, including:
1. Supervised Learning: In this type of algorithm, the model is trained on labeled data, where each data point is associated with a known outcome. The algorithm learns to map input variables to the desired output by analyzing patterns and relationships in the labeled data. Common supervised learning algorithms include linear regression, logistic regression, decision trees, and support vector machines.
2. Unsupervised Learning: Unsupervised learning algorithms are used when the training data is unlabeled, meaning there are no predefined outcomes. The algorithm learns to identify patterns and relationships in the data without any external guidance. Common unsupervised learning algorithms include clustering algorithms, such as k-means clustering, and dimensionality reduction algorithms, such as principal component analysis (PCA).
3. Semi-supervised Learning: This type of algorithm is a combination of both supervised and unsupervised learning. It is used when a dataset has only a small portion of labeled data and a larger portion of unlabeled data. The labeled data is used to guide the learning process, while the unlabeled data helps the algorithm identify patterns and relationships. Semi-supervised learning is commonly used when labeling data is costly or time-consuming.
4. Reinforcement Learning: Reinforcement Learning algorithms involve an agent learning to interact with an environment to maximize a reward signal. The agent takes actions in the environment, receives feedback in the form of rewards or punishments, and adjusts its behavior accordingly. This type of learning is often used in complex scenarios, such as game playing and robotics.
5. Ensemble Learning: Ensemble learning algorithms combine multiple models or classifiers to make predictions or decisions. By pooling the knowledge of multiple models, ensemble learning can improve accuracy and reduce the risk of overfitting. Common ensemble learning algorithms include random forests and gradient boosting.
Understanding these different types of Machine Learning algorithms is crucial for selecting the appropriate approach for a given task. Each algorithm has its own strengths and limitations, and the choice depends on factors such as the nature of the data, the desired outcome, and the available resources.
Understanding Deep Learning Algorithms
Deep Learning algorithms are the foundation of Deep Learning, a subfield of Machine Learning that focuses on building artificial neural networks to mimic the functioning of the human brain. Deep Learning algorithms are designed to learn and understand complex patterns and relationships in data, enabling them to perform tasks such as image recognition, natural language processing, and speech synthesis.
Deep Learning algorithms are typically built using multiple layers of interconnected nodes, also known as artificial neurons. Each layer is responsible for performing specific calculations and passing the results to the next layer. The interconnectedness of these layers allows the algorithm to extract increasingly abstract features from the input data, leading to a hierarchical representation of the data.
Some commonly used Deep Learning algorithms include:
1. Convolutional Neural Networks (CNN): CNNs are commonly used in computer vision tasks, such as image classification and object recognition. These algorithms consist of convolutional layers, pooling layers, and fully connected layers. CNNs are known for their ability to automatically learn and extract relevant features from images.
2. Recurrent Neural Networks (RNN): RNNs are often used for sequential data processing, such as natural language processing and speech recognition. These algorithms have connections that span across time steps, allowing them to capture temporal dependencies in the data. Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) are popular variants of RNNs.
3. Generative Adversarial Networks (GAN): GANs consist of two neural networks, a generator network and a discriminator network, that are trained in a adversarial manner. GANs are used for tasks such as image synthesis, where the generator network learns to generate realistic images, and the discriminator network learns to differentiate between real and fake images.
4. Deep Reinforcement Learning: Deep Reinforcement Learning combines Deep Learning with Reinforcement Learning to enable agents to learn and make decisions in complex environments. These algorithms have been successful in games, such as AlphaGo, where the agent learns to play against human players or other agents through trial and error.
Understanding these Deep Learning algorithms is crucial for effectively applying Deep Learning techniques to various domains. The choice of algorithm depends on the specific task and the nature of the data. Deep Learning algorithms have shown remarkable success in areas such as computer vision, natural language processing, and robotics, and continue to advance the field of Artificial Intelligence.
Difference in Structure and Complexity
One of the key differences between Machine Learning and Deep Learning lies in the structure and complexity of their algorithms. While both approaches utilize algorithms to learn from data, their underlying architectures and computational requirements differ significantly.
Machine Learning algorithms typically involve the design and implementation of statistical models that learn from labeled or unlabeled data. These models are often built using mathematical equations and algorithms that map input variables to the desired output. The complexity of Machine Learning algorithms is usually lower compared to Deep Learning, as they don’t typically require multiple layers of interconnected nodes.
In contrast, Deep Learning algorithms are characterized by their deep neural networks, which consist of multiple layers of interconnected nodes. These layered structures allow Deep Learning algorithms to automatically extract complex and hierarchical representations from the input data. The depth and complexity of these networks contribute to the powerful learning abilities of Deep Learning, as they can capture intricate patterns and relationships in the data.
Deep Learning algorithms require a significant amount of computational resources, both in terms of memory and processing power, due to their complex architectures. Training deep neural networks can be computationally intensive and time-consuming. Moreover, the training process often requires large amounts of labeled or annotated data to achieve optimal performance. This data requirement is a distinguishing factor between Machine Learning and Deep Learning.
While Machine Learning algorithms can often achieve satisfactory results with relatively small datasets, Deep Learning algorithms thrive on big data. The large amount of data facilitates the discovery of complex patterns and improves the accuracy and generalization capabilities of Deep Learning models. However, if there is a lack of sufficient training data, Deep Learning algorithms may face challenges in achieving good performance.
In summary, the structure and complexity of algorithms differentiate Machine Learning from Deep Learning. Machine Learning utilizes statistical models and algorithms to learn from data, while Deep Learning employs deep neural networks with multiple layers to automatically extract complex patterns and relationships. The computationally intensive nature of Deep Learning and its reliance on big data make it suitable for tasks requiring high complexity and large datasets.
Data Requirements
Data is a critical component in both Machine Learning and Deep Learning, but the data requirements differ between the two approaches. The amount, quality, and type of data needed play a significant role in the effectiveness and performance of the algorithms.
Machine Learning algorithms typically require labeled or annotated data for training. This labeled data consists of input variables along with their corresponding output or target variable. The availability of labeled data is crucial for the algorithm to learn the patterns and relationships necessary to make accurate predictions or decisions. The size of the training dataset varies depending on the complexity of the problem, but Machine Learning algorithms can often produce acceptable results with smaller datasets.
On the other hand, Deep Learning algorithms often require a vast amount of data, especially for complex tasks such as image or speech recognition. Deep Learning models have millions, or even billions, of parameters to learn, and having a sufficient amount of diverse and annotated data helps in capturing the intricate patterns present in the data. The availability of big data allows Deep Learning algorithms to generalize well and make accurate predictions or decisions in various scenarios.
The quality of the data is also crucial in both approaches. In Machine Learning, noise or incorrect labels in the training data can negatively impact the accuracy of the model. Therefore, data cleaning and preprocessing are necessary to ensure the quality and reliability of the training dataset. Similarly, in Deep Learning, data preprocessing and augmentation techniques are used to enhance the quality and diversity of the training data, leading to better model performance.
Another aspect of data requirements is the type of data that is suitable for each approach. Machine Learning algorithms can handle structured and tabular data effectively. They are well-suited for problems where the input variables have clear relationships and can be represented as numerical or categorical features. Deep Learning algorithms, on the other hand, excel in handling unstructured data, such as images, audio, and text. Their ability to automatically learn hierarchical representations makes them ideal for tasks where the data has complex patterns and relationships.
In summary, both Machine Learning and Deep Learning require data for training, but the amount, quality, and type of data differ. Machine Learning algorithms can produce satisfactory results with smaller labeled datasets, while Deep Learning algorithms thrive on big, diverse, and unstructured data. Understanding the data requirements helps in selecting the appropriate approach based on the available data resources and the complexity of the problem at hand.
Training and Performance
The training and performance characteristics of Machine Learning and Deep Learning models are distinct due to the differences in their architectures and learning approaches.
Machine Learning models are trained using an iterative process that involves optimizing a defined objective function. During the training phase, the model adjusts its internal parameters based on the input data and the desired output. The optimization process aims to minimize the difference between the predicted outputs and the actual outcomes in the training dataset. The convergence of a Machine Learning model depends on various factors, including the complexity of the problem, the quality and quantity of the training data, and the chosen algorithm.
After training, a Machine Learning model is evaluated on a separate test dataset to assess its performance. The performance metrics depend on the specific task, but common evaluation measures include accuracy, precision, recall, and F1-score. The performance of Machine Learning models can be influenced by factors such as feature selection, algorithm choice, and hyperparameter tuning.
Deep Learning models, on the other hand, follow a similar training process but with some notable differences. Training deep neural networks involves a technique called “backpropagation,” where the error from the output layer is propagated backward through the network to update the weights at each layer. Deep Learning models have multiple layers of interconnected nodes, allowing them to learn complex hierarchical representations of the input data.
The training process of Deep Learning models can be computationally intensive and time-consuming, especially when dealing with large datasets and complex architectures. Training deep neural networks often requires significant computational resources, such as powerful GPUs or distributed systems, to expedite the learning process. However, once trained, Deep Learning models can exhibit exceptional performance, particularly in tasks that involve unstructured data, such as image and speech recognition.
Deep Learning models have demonstrated remarkable results in various domains, often outperforming traditional Machine Learning approaches. However, the performance improvement of Deep Learning models comes at the cost of increased complexity and potential overfitting. Deep Learning models with insufficient training data or inadequate regularization techniques can suffer from overfitting, where the model becomes too specialized to the training data and performs poorly on unseen data.
Regularization techniques, such as dropout and weight decay, are commonly employed in Deep Learning to mitigate overfitting. Additionally, the performance of Deep Learning models can be affected by hyperparameter choices, architecture design, and regularization strategies.
In summary, both Machine Learning and Deep Learning models undergo a training process to learn from data. Machine Learning models optimize an objective function using iterative techniques, while Deep Learning models use backpropagation to update weights in multiple layers. Deep Learning models often require more computational resources and data to train effectively, but they can achieve exceptional performance in complex tasks involving unstructured data.
Applications of Machine Learning
Machine Learning has a wide range of applications across various industries, revolutionizing processes and bringing about significant advancements. Here are some notable applications:
1. Healthcare: Machine Learning is transforming healthcare by enabling early disease detection and diagnosis, predicting patient outcomes, and personalizing treatment plans. It helps analyze medical images, identify genetic markers, and develop precision medicine approaches.
2. Finance: In the finance industry, Machine Learning is used for fraud detection, credit scoring, algorithmic trading, and risk assessment. It helps financial institutions make data-driven decisions, detect anomalies in transactions, and automate trading strategies.
3. Retail and E-commerce: Machine Learning powers recommendation systems that personalize product suggestions based on customer behavior and preferences. It also enables dynamic pricing, demand forecasting, inventory management, and fraud detection in online transactions.
4. Marketing and Advertising: Machine Learning is used to analyze customer data, segment target audiences, and optimize marketing campaigns. It helps businesses understand consumer behavior, predict customer churn, and enhance personalized advertising.
5. Transportation and Logistics: Machine Learning plays a vital role in logistics management, route optimization, and demand forecasting. It helps in predicting delivery times, optimizing supply chain operations, and improving fleet management.
6. Natural Language Processing (NLP): NLP techniques, a subset of Machine Learning, are used for sentiment analysis, chatbots, voice assistants, and language translation. It enables the analysis and understanding of human language for various applications.
7. Manufacturing and Industry 4.0: Machine Learning is leveraged in predictive maintenance, quality control, and process optimization. It helps identify potential failures, optimize production schedules, and improve product quality.
8. Energy and Utilities: Machine Learning aids in energy demand forecasting, load balancing, predictive maintenance of equipment, and energy efficiency optimization. It helps optimize energy consumption and reduce operational costs.
These are just a few examples of the diverse range of applications for Machine Learning. The versatility of Machine Learning algorithms and their ability to analyze complex patterns in data make them invaluable in solving real-world problems and driving innovation across industries.
Applications of Deep Learning
Deep Learning, with its ability to automatically learn complex patterns and representations from data, has seen remarkable success in various domains. Its applications have transformed industries and opened up new possibilities for solving complex problems. Here are some notable applications of Deep Learning:
1. Image and Object Recognition: Deep Learning has enabled significant advancements in image recognition, object detection, and classification. It powers applications such as facial recognition, self-driving cars, and visual inspection in manufacturing.
2. Natural Language Processing (NLP): Deep Learning algorithms have revolutionized NLP tasks such as machine translation, sentiment analysis, and speech recognition. Virtual assistants like Siri and Alexa utilize Deep Learning techniques to understand and respond to human language.
3. Healthcare: Deep Learning has shown promise in medical image analysis, assisting radiologists in diagnosing diseases such as cancer from X-rays, MRIs, and CT scans. It also aids in drug discovery and genomics research.
4. Autonomous Vehicles: Deep Learning plays a vital role in autonomous driving, enabling vehicles to perceive their environment, make real-time decisions, and navigate safely. Deep Learning algorithms process sensor data, including images, lidar, and radar, to detect and respond to road conditions and objects.
5. Robotics: Deep Learning is utilized in robotic systems, enhancing their perception, object recognition, and motion planning capabilities. Robotic control systems that can learn from experience and adapt to changing environments benefit from Deep Learning techniques.
6. Financial Analysis: Deep Learning is used in financial institutions for credit risk assessment, fraud detection, and algorithmic trading. It helps analyze large volumes of data, identify patterns, and make predictions for more accurate financial decision-making.
7. Gaming: Deep Learning has demonstrated exceptional performance in playing complex games. Deep Learning algorithms have defeated human champions in games like chess, go, and poker. They learn strategies and decision-making policies by playing against themselves or human opponents.
8. Generative Models: Deep Learning enables the generation of new content, such as images, music, and text. Generative models like Generative Adversarial Networks (GANs) can create realistic images, compose music, and even generate human-like text.
These are just a few examples of the diverse applications of Deep Learning. With its ability to automatically learn and understand complex patterns in data, Deep Learning continues to push boundaries and drive innovations in numerous domains.
Advantages and Disadvantages of Machine Learning
Machine Learning offers a range of advantages that have made it a powerful tool for solving complex problems. However, it also has its limitations. Let’s explore the advantages and disadvantages of Machine Learning:
Advantages:
- Data-Driven Decision Making: Machine Learning enables data-driven decision-making by analyzing vast amounts of data and extracting insights and patterns that human analysts may miss.
- Automation and Efficiency: Machine Learning models can automate repetitive tasks, leading to increased productivity and efficiency. They can process large datasets and make predictions or decisions at a speed not achievable by humans.
- Improves Accuracy: Machine Learning models can achieve high levels of accuracy in tasks such as classification, regression, and pattern recognition, surpassing human performance in some cases.
- Scalability: Machine Learning models can scale to handle large and complex datasets. They can handle increasing volumes of data without significant performance degradation.
- Adaptability and Generalization: Machine Learning models have the ability to adapt to new data and generalize well to unseen examples. This allows them to make predictions or decisions in real-world scenarios.
Disadvantages:
- Data Dependency: Machine Learning models heavily rely on quality and quantity of training data. Insufficient or biased data can lead to inaccurate results.
- Interpretability: Some Machine Learning models, such as deep neural networks, lack interpretability. It can be challenging to understand why the model makes specific predictions or decisions.
- Overfitting: Machine Learning models can become overfit to the training data, meaning they perform well on training data but poorly on unseen data. Regularization techniques and careful model selection are required to mitigate overfitting.
- Computational Resources: Training complex Machine Learning models, especially deep neural networks, requires substantial computational resources, including processing power and memory.
- External Bias: Machine Learning models can perpetuate biases present in the training data, leading to discriminatory or unfair results. Care should be taken to ensure fairness and mitigate bias.
Understanding the advantages and disadvantages of Machine Learning is crucial for effectively utilizing this technology and mitigating its limitations. By being aware of these factors, one can make informed decisions and leverage Machine Learning’s capabilities while addressing its challenges.
Advantages and Disadvantages of Deep Learning
Deep Learning, with its ability to automatically learn complex patterns and representations from data, has several advantages that have propelled it to the forefront of Artificial Intelligence research. However, it also comes with its own set of limitations. Let’s explore the advantages and disadvantages of Deep Learning:
Advantages:
- High Accuracy: Deep Learning models have demonstrated state-of-the-art performance in various domains, surpassing traditional Machine Learning approaches. Their ability to automatically learn hierarchical representations enables them to capture intricate patterns in data and make accurate predictions or decisions.
- Feature Learning: Deep Learning algorithms have the capability to automatically learn relevant features from raw data. They can extract complex representations that capture discriminative features without the need for manual feature engineering.
- Handling Unstructured Data: Deep Learning excels in handling unstructured data such as images, audio, and text. It has transformed tasks such as image recognition, natural language processing, and speech synthesis by achieving unprecedented performance.
- Generalization: Deep Learning models can generalize well to unseen examples, allowing them to make accurate predictions or decisions in real-world scenarios. Their ability to learn complex representations aids in handling variations and noise in the data.
- Parallel Processing: Deep Learning models can take advantage of parallel processing architectures, such as GPUs, to speed up training and inference. This makes them suitable for handling large datasets and training deep neural networks more efficiently.
Disadvantages:
- Need for Large Datasets: Deep Learning models typically require a large amount of labeled or annotated data to achieve optimal performance. If there is a lack of sufficient training data, the models may not generalize well or suffer from overfitting.
- Computational Resources: Training deep neural networks can be computationally intensive and requires significant computational resources, such as powerful GPUs or distributed systems. This can limit the accessibility of Deep Learning to individuals or organizations with limited resources.
- Limited Interpretability: Deep Learning models can be black boxes, making it challenging to interpret why they make specific predictions or decisions. Understanding the inner workings of deep neural networks and explaining their outputs remains an active research area.
- Overfitting: Deep Learning models, particularly with complex architectures, can be prone to overfitting if not properly regularized. Regularization techniques, such as dropout and weight decay, are necessary to prevent over-reliance on the training data.
- Data-Intensive Training: Training Deep Learning models with large datasets requires substantial memory and storage capacity. The large model sizes and the need to store intermediate activations during training can be resource-intensive.
Understanding the advantages and disadvantages of Deep Learning is crucial for leveraging its capabilities effectively. By embracing its strengths and addressing its limitations, Deep Learning can unlock new possibilities and drive advancements in various domains.
Conclusion
Machine Learning and Deep Learning are two powerful branches of Artificial Intelligence that have transformed numerous industries and applications. While Machine Learning focuses on developing algorithms that learn from data and make predictions or decisions, Deep Learning goes a step further by using artificial neural networks to automatically learn complex representations from raw data.
Both Machine Learning and Deep Learning have their own unique advantages and disadvantages. Machine Learning offers data-driven decision-making, automation, and scalability, making it suitable for a wide range of tasks with smaller datasets. On the other hand, Deep Learning excels in handling unstructured data, achieving high accuracy, and automatically learning relevant features, making it well-suited for complex tasks that involve images, text, and speech.
Understanding the differences between Machine Learning and Deep Learning is essential for selecting the most appropriate approach for specific applications. Machine Learning can be a good choice when the available dataset is limited and well-structured, whereas Deep Learning shines when dealing with big data and tasks that require complex pattern recognition.
Both approaches have made significant contributions to various domains, including healthcare, finance, retail, and more. Machine Learning has been instrumental in fraud detection, credit scoring, and personalized recommendations, while Deep Learning has revolutionized computer vision, natural language processing, and autonomous driving.
As AI continues to evolve, the boundaries between Machine Learning and Deep Learning are getting blurrier. Researchers and practitioners are constantly exploring ways to combine the strengths of both approaches to create more robust and efficient AI systems. With ongoing advancements, these technologies will continue to shape the future of AI, offering even more innovative solutions to complex real-world problems.