Introduction
Machine learning, a subfield of artificial intelligence, has been rapidly advancing with the development of sophisticated algorithms and powerful computing capabilities. One of the key challenges in machine learning is the interpretability of the models used to make predictions or decisions.
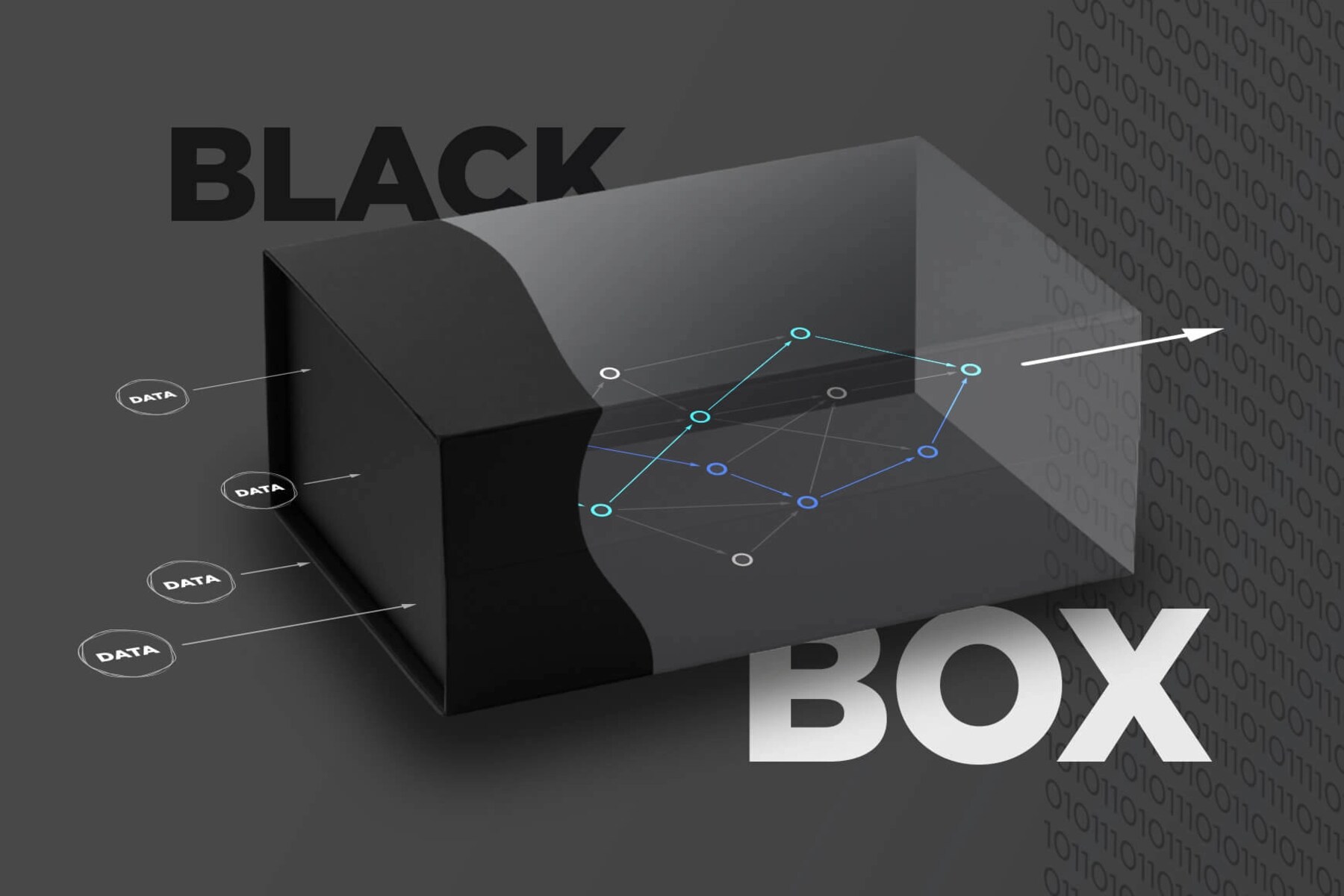
A concept that arises during this process is the term “black box.” In the context of machine learning, a black box refers to a model or algorithm that can make predictions or decisions but whose inner workings are not easily understandable by humans. The black box model can be seen as a metaphorical container that holds complex calculations, statistical methods, or neural networks, allowing it to generate accurate predictions or decisions.
The lack of transparency in black box models has sparked debates regarding their validity and reliability, especially when the decisions made by these models impact critical areas such as healthcare, finance, and autonomous systems. While black box models can deliver high accuracy, their lack of interpretability can raise concerns regarding bias, discrimination, and fairness. Hence, striking a balance between model performance and interpretability is crucial in the field of machine learning.
Definition of Black Box in Machine Learning
In the realm of machine learning, a black box refers to a model, algorithm, or system that can provide accurate predictions or decisions without revealing the internal mechanisms or reasoning behind its outputs. The term “black box” is derived from the notion that the inner workings of the model are obscured or hidden from human understanding, much like a sealed box that cannot be opened.
Black box models are designed to process input data and produce output without explicitly exposing the intermediate steps or computations involved. These models are often characterized by complex structures, such as neural networks, ensemble methods, or deep learning architectures. The decision-making process of black box models is based on intricate mathematical calculations, statistical methods, or iterative learning processes, making it challenging for humans to decipher the exact logic employed by the model.
One of the key features of black box models is their ability to generalize and make accurate predictions across a wide range of input data. This generalization is achieved by learning from large datasets during training, identifying patterns, and capturing the underlying relationships between input variables and target outcomes. However, due to the complexity and opacity of the models, these relationships may not be easily explainable or interpretable by humans.
Black box models can be contrasted with transparent or interpretable models, such as decision trees or logistic regression, where the decision-making process is based on explicit rules or equations that can be easily understood by humans. In contrast, black box models trade interpretability for higher predictive performance, allowing them to handle complex and non-linear relationships in the data. This trade-off between interpretability and accuracy is an ongoing challenge in machine learning research and applications.
Characteristics of Black Box Models
Black box models in machine learning exhibit several key characteristics that distinguish them from transparent or interpretable models. Understanding these characteristics can provide insights into the advantages and limitations of using black box models in various applications.
1. Complexity: Black box models tend to be highly complex, often composed of numerous interconnected layers, nodes, or parameters. This complexity allows them to capture intricate patterns and relationships in the data, but it also makes them difficult to interpret, as the decision-making process is non-trivial and obscured.
2. Non-linearity: Black box models excel at capturing non-linear relationships between input features and output predictions. This capability is especially valuable when dealing with complex and high-dimensional data, where linear models may struggle to capture the underlying patterns and nuances.
3. Ensemble methods: Black box models often employ ensemble techniques, such as random forests or gradient boosting, which combine multiple individual models to improve predictive accuracy. By aggregating the predictions of multiple models, ensemble methods can mitigate biases and reduce variance, leading to more robust and accurate outcomes.
4. Automatic feature learning: Black box models have the ability to automatically learn relevant features from raw data, eliminating the need for human feature engineering. This feature learning capability allows the model to extract high-level representations and latent patterns that may not be apparent through manual feature selection or engineering.
5. Lack of transparency: Perhaps the most defining characteristic of black box models is their lack of transparency. The inner workings of these models are usually hidden and difficult to understand, making it challenging to explain the specific reasoning behind their predictions or decisions. This lack of transparency can pose challenges in scenarios where interpretability, fairness, or regulatory compliance are key considerations.
Despite these characteristics, black box models continue to be widely used and valued for their ability to deliver accurate predictions in many domains, including image and speech recognition, natural language processing, and financial modeling. However, it is important to be aware of the limitations and potential risks associated with using black box models and to carefully consider the trade-offs between performance and interpretability in each specific application.
Advantages of Black Box Models
Black box models in machine learning offer several key advantages that make them valuable in various applications. While they lack interpretability, their strengths lie in their ability to handle complex data and deliver high predictive performance.
1. Accuracy: Black box models are known for their ability to achieve high accuracy in predictions or decisions. Their complex structures and non-linear relationships enable them to capture intricate patterns in the data, making them suitable for tasks where precision is crucial, such as image recognition or fraud detection.
2. Robustness: Black box models often employ ensemble techniques, where multiple models are combined to improve predictive performance. This ensemble approach enhances the model’s robustness by reducing bias and variance, yielding more reliable and stable predictions across different datasets or variations in input.
3. Adaptability: Black box models can adapt and generalize well to unseen or unfamiliar data. By learning from large datasets during training, they can discover complex relationships and make accurate predictions even when presented with new instances or variations in the input features. This adaptability makes them suitable for dynamic and evolving environments.
4. Feature Extraction: Black box models can automatically learn relevant features from raw data, minimizing the need for manual feature engineering. This capability is particularly beneficial when dealing with high-dimensional or unstructured data, such as images, texts, or sensor data. By extracting meaningful and informative features, black box models can improve prediction accuracy without human intervention.
5. Scalability: Black box models can handle large-scale datasets efficiently. Leveraging advancements in parallel computing and distributed systems, these models can process vast amounts of data in a timely manner, making them suitable for applications requiring real-time or near real-time predictions, such as online advertising or recommendation systems.
6. Continuous Learning: Black box models can continuously learn and adapt to new data without the need for manual retraining. Through techniques like online learning or incremental training, these models can update their predictions or decisions as new data becomes available, ensuring that they remain relevant and accurate over time.
While the lack of interpretability in black box models is a trade-off for their advantages, they are still a valuable tool in certain domains where accuracy and performance take precedence over transparency. However, it is essential to assess the specific requirements and considerations of each application to determine whether the benefits of using black box models outweigh the potential downsides.
Limitations of Black Box Models
While black box models in machine learning offer high accuracy and performance, they are not without limitations. These limitations primarily stem from their lack of interpretability and potential ethical concerns. Understanding these limitations is essential when considering the use of black box models in different contexts.
1. Lack of transparency: Black box models are opaque and provide no insight into the internal decision-making process. This lack of transparency makes it challenging to understand how and why a specific prediction or decision is made. This can be problematic in scenarios where explainability, fairness, or accountability is crucial, as it becomes difficult to identify and rectify biases, errors, or discriminatory patterns.
2. Ethical concerns: Black box models can inadvertently perpetuate biases present in the training data. If the training data contains inherent biases or discriminatory patterns, the model may learn and amplify these biases, leading to unfair or discriminatory outcomes. This can have significant ethical implications, particularly in domains such as hiring, loan approvals, or criminal justice, where biased decisions can reinforce societal inequalities.
3. Limited control: Due to their opacity, black box models offer limited control over the decision-making process. Users have little ability to intervene or adjust the model’s behavior based on domain knowledge or changing circumstances. This lack of control can be problematic when the outcomes of the model’s decisions have significant consequences or when specific regulations or guidelines must be followed.
4. Lack of interpretability: The inability to interpret the reasoning behind black box model predictions limits their adoption in fields where explainability is essential, such as healthcare or autonomous systems. Without a clear understanding of how decisions are made, it becomes challenging to ensure trust, verify the model’s accuracy, or address potential errors or biases.
5. Data requirements: Black box models often require large amounts of high-quality labeled data for training. Acquiring and labeling such data can be time-consuming, expensive, or may not be readily available for certain applications or niche domains. This data requirement can pose challenges for smaller organizations or industries where labeled data is scarce.
It is crucial to consider these limitations when deciding whether to adopt black box models. Organizations must carefully assess the specific requirements and constraints of their domain and determine how these limitations align with their ethical, interpretability, and regulatory needs. In some cases, using alternative transparent or interpretable models may be more appropriate, while in others, further research and techniques for explaining and addressing the limitations of black box models may be necessary.
Examples of Black Box Models in Machine Learning
Black box models are prevalent in various domains and have been successfully applied to solve complex problems. These models leverage their ability to handle intricate patterns and non-linear relationships in the data to deliver accurate predictions or decisions. Here are a few examples of black box models used in machine learning:
1. Deep Neural Networks (DNNs): DNNs are a type of black box model inspired by the structure and function of the human brain’s neural networks. They consist of multiple layers of artificial neurons that learn and extract complex representations from the input data. DNNs have demonstrated remarkable performance in various applications, such as image recognition, natural language processing, and speech synthesis.
2. Random Forests: Random forests are an ensemble learning method that combines multiple decision trees to make predictions. Each decision tree in the ensemble is trained on a random subset of the data, and the final prediction is obtained by aggregating the predictions of individual trees. Random forests can handle complex relationships and are widely used in applications like classification, regression, and anomaly detection.
3. Support Vector Machines (SVMs): SVMs are a black box model that separates data into different classes by finding an optimal hyperplane that maximally separates the data points. SVMs can handle high-dimensional data and are particularly effective in tasks like text classification, image classification, and bioinformatics.
4. Gradient Boosting Machines (GBMs): GBMs are another ensemble learning method that combines multiple weak learner models to create a strong predictive model. GBMs iteratively train weak models to correct the mistakes made by previous models, resulting in a powerful ensemble. GBMs have achieved state-of-the-art performance in various applications, including ranking, recommendation systems, and fraud detection.
5. Recurrent Neural Networks (RNNs): RNNs are deep learning models designed to handle sequential or time-dependent data. With the ability to retain memory and capture temporal relationships, RNNs have been successful in tasks like language modeling, speech recognition, and sentiment analysis. However, their black box nature makes interpreting the inner workings challenging.
These examples illustrate the versatility and effectiveness of black box models in solving complex real-world problems. However, it is crucial to carefully consider the specific requirements, limitations, and potential ethical implications of using these models in different applications.
Techniques for Interpreting Black Box Models
Interpreting the predictions and decisions made by black box models is a challenging task due to their lack of transparency. However, researchers and practitioners have been developing various techniques to shed light on the inner workings of these models and enhance their interpretability. These techniques aim to provide insights into how the model arrived at its predictions or decisions. Here are some common techniques used for interpreting black box models:
1. Feature Importance: This technique helps identify the most influential features or variables in the model’s decision-making process. By quantifying the impact of each feature on the output, feature importance methods like permutation importance, feature contribution, or gradient-based methods provide insights into which features are driving the model’s predictions.
2. Partial Dependence Plots: Partial dependence plots show the relationship between a specific input feature and the model’s predictions while keeping other features constant. By visualizing how changes in a single feature affect the model’s output, partial dependence plots provide an understanding of how the model responds to different feature values.
3. LIME (Local Interpretable Model-Agnostic Explanations): LIME is a model-agnostic technique that explains individual predictions made by black box models. It generates local approximations of the model’s behavior by training interpretable models on local subsets of the data. By highlighting the most influential features for a specific prediction, LIME provides explanations at an instance-level.
4. SHAP (SHapley Additive exPlanations): SHAP values provide a unified framework for interpreting the predictions of black box models. Derived from cooperative game theory, SHAP values assign contributions to each feature based on its impact on the model’s output predictions. This technique takes into account the interactions between features and provides more comprehensive explanations.
5. Model Distillation: Model distillation is a technique that aims to create a simpler, more interpretable model that approximates the predictions of a black box model. By compressing the knowledge of the complex model into a simpler one, such as a decision tree or logistic regression, model distillation offers interpretability while preserving accuracy to some extent.
6. Rule Extraction: Rule extraction techniques aim to extract human-readable rules from black box models. By identifying decision rules or logical conditions that mimic the behavior of the complex model, rule extraction provides a more interpretable representation of the model’s decision-making process.
These techniques are just a few examples of the diverse methodologies available for interpreting black box models. Each approach has its strengths and limitations, and the choice of technique depends on the specific requirements, constraints, and interpretability needs of the application at hand.
Importance of Balancing Interpretability and Performance in Machine Learning Models
When designing and deploying machine learning models, striking a balance between interpretability and performance is crucial. While black box models often offer high predictive accuracy, their lack of transparency can raise concerns regarding fairness, accountability, and trust. Here are some key reasons why finding the right balance between interpretability and performance is important:
1. Transparency in decision-making: In many domains, it is essential to comprehend and justify the reasoning behind the decisions made by machine learning models. Interpretability enables stakeholders, including data scientists, regulators, and end-users, to understand how the model arrives at its predictions or decisions. This transparency helps build trust and credibility, as well as facilitates error detection, bias mitigation, and compliance with legal and ethical regulations.
2. Ensuring fairness and avoiding biases: Machine learning models can inadvertently learn and amplify biases present in the training data. Without interpretability, it becomes challenging to identify and address these biases. By using interpretable models or interpreting the inner workings of black box models, it is possible to detect and mitigate discriminatory patterns, ensuring fair and unbiased decision-making.
3. Compliance with regulations and guidelines: In certain industries, such as healthcare, finance, or autonomous systems, interpretability is a legal or regulatory requirement. Regulatory bodies recognize the importance of understanding and justifying the decisions made by automated systems. Compliance with regulations often entails providing explanations, auditability, and accountability, which can be achieved through interpretable models or interpretability techniques applied to black box models.
4. Interpreting complex models for domain experts: In domains where expert knowledge is crucial, interpretable models can help bridge the gap between data-driven predictions and human expertise. Interpretable models provide insights and explanations that domain experts can understand and validate based on their experience. This collaboration between machine learning models and human experts can lead to more informed and accurate decisions.
5. User acceptance and adoption: For machine learning models to be successfully adopted and used in real-world settings, they need to be understandable and accepted by end-users. If the decisions made by the model are perceived as arbitrary or inscrutable, end-users may resist or reject them. Interpretability helps in presenting the model’s predictions or decisions in a manner that is comprehensible and aligns with the mental models of the users.
Striking the right balance between interpretability and performance is not a one-size-fits-all solution. It requires careful consideration of the specific domain, application, and stakeholder needs. Different use cases may call for different trade-offs, where interpretability is prioritized over performance or vice versa. The key is to examine the impact of interpretability on performance and vice versa, making informed decisions to achieve the desired outcome for a particular application.
Conclusion
Black box models have emerged as powerful tools in machine learning, providing accurate predictions and decisions for a wide range of applications. However, their lack of interpretability poses challenges in understanding and justifying their outputs. Balancing interpretability and performance is crucial to ensure transparency, fairness, compliance, and user acceptance.
While black box models excel at handling complex data and capturing non-linear relationships, they often lack transparency, making it difficult to explain the reasoning behind their decisions. Techniques such as feature importance, partial dependence plots, LIME, and SHAP values help shed light on their inner workings, but they are not without limitations.
Interpretability is essential for domains that require transparency, fairness, or compliance with regulations. It enables human experts to validate decisions, detect biases, and address ethical concerns. Interpretable models offer clear explanations and justifications, fostering trust and accountability. However, they may sacrifice some predictive accuracy compared to black box models.
Striking the balance between interpretability and performance requires considering the specific requirements, constraints, and stakeholders of each application. Different use cases may call for different trade-offs, where interpretability is prioritized over performance or vice versa. Organizations must carefully assess the impact of interpretability on biases, fairness, and user acceptance, making informed decisions about the suitability of black box models or alternative interpretable models.
As research and techniques in interpretable machine learning continue to advance, there is hope for bridging the gap between performance and interpretability. Ongoing efforts to improve transparency, develop better interpretability techniques, and ensure fairness in models are vital to building trustworthy and responsible machine learning systems.
Ultimately, the choice between black box models and interpretable models depends on the specific needs and considerations of each application. By weighing the advantages, limitations, and ethical implications, practitioners can harness the power of black box models while striving for transparency and interpretability in the pursuit of responsible and ethical machine learning.