What is a Pickle File?
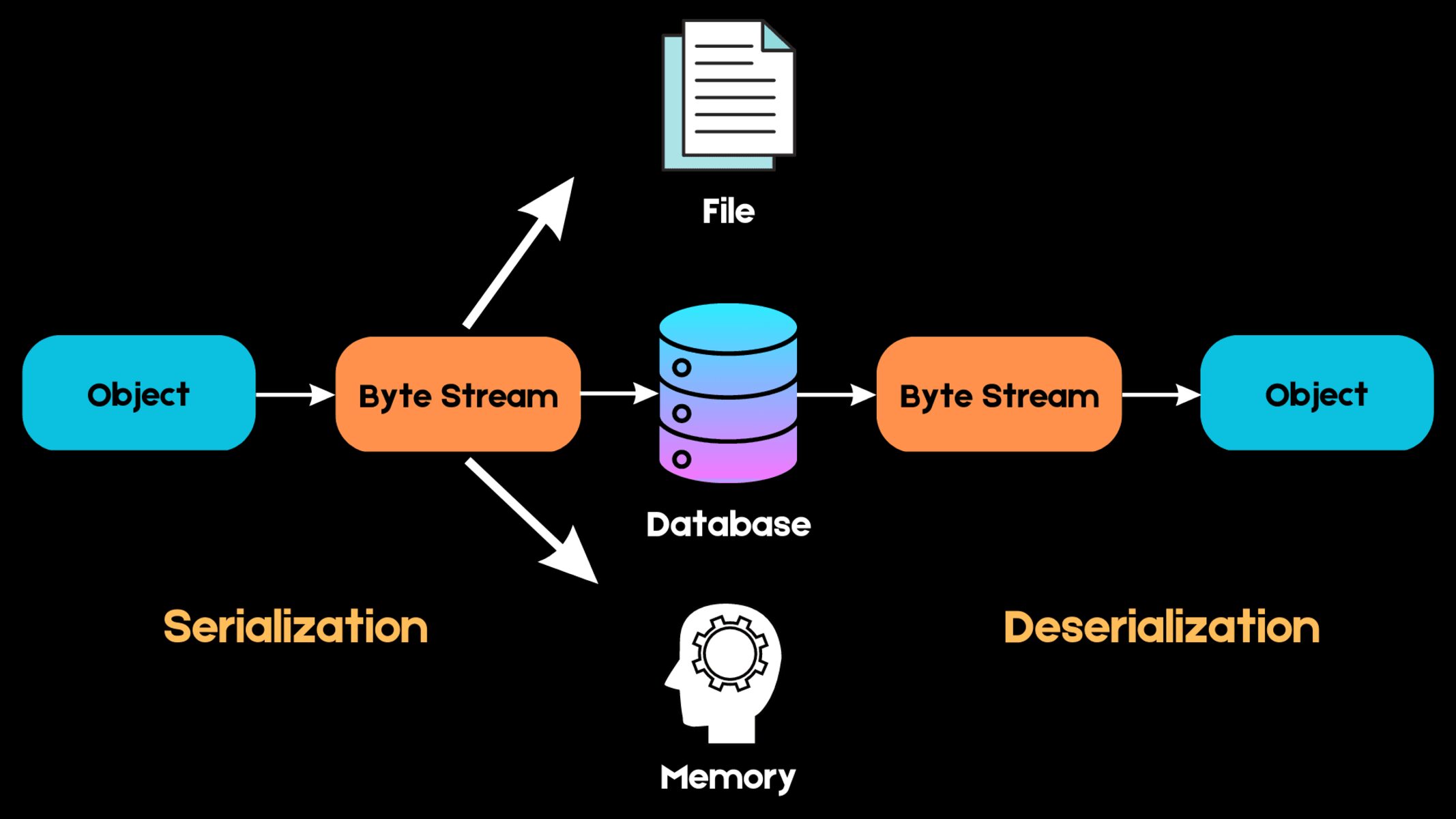
A pickle file is a serialized data structure commonly used in machine learning to store and retrieve Python objects. It allows you to save objects such as trained models, data preprocessing pipelines, and other complex data structures into a file. This file can then be easily loaded back into memory at a later time, allowing you to use the stored information without having to recalibrate or preprocess the data again.
The name “pickle” comes from the concept of preserving or “pickling” objects, similar to how food is preserved in vinegar or brine. In the context of machine learning, pickling refers to the process of encoding the internal state of an object into a byte stream, which can then be saved and later reconstructed.
Python’s pickle module provides a straightforward and efficient way to serialize and deserialize objects. It handles the conversion process transparently, ensuring that the object hierarchy, data types, and references are preserved during the pickling and unpickling operation.
One of the significant advantages of using pickle files is the ability to store and retrieve complex objects, including machine learning models and their associated parameters. This allows you to save the time and computational resources required to retrain your models and instead focus on the evaluation or deployment phase.
Pickle files are versatile and can be used to store a variety of objects, such as lists, dictionaries, custom classes, and even more advanced data structures like pipelines or ensemble models. They provide a convenient way to package and transport your models across different environments or share them with colleagues for collaboration.
However, it’s important to note that pickle files are specific to the Python programming language, and they may not be compatible with other programming languages or versions. This can be a limitation when working with multi-language environments or when collaborating with individuals who use different programming languages.
Overall, pickle files are a valuable tool in the machine learning arsenal. They simplify the process of persisting and loading objects, allowing for more efficient model deployment and sharing. In the next section, we will explore why pickle files are widely used in machine learning applications.
Why Use Pickle in Machine Learning?
Pickle files play a crucial role in the field of machine learning. They offer several advantages that make them a popular choice for storing and sharing machine learning models and related objects. Let’s explore some of the reasons why pickle is widely used in the machine learning community.
1. Easy Serialization: Pickle provides a simple and efficient way to serialize Python objects. It automatically handles the conversion of complex data structures, such as models, pipelines, and other customized classes, into a byte stream. This makes it easy to save and load these objects, ensuring that their internal states are preserved during the serialization process.
2. Time and Resource Savings: By pickling and saving a trained machine learning model, you can avoid the need to retrain it from scratch. This can save a significant amount of time and computational resources, especially for models that require long training cycles or large datasets. With pickle, you can store the model’s parameters and other necessary information, allowing you to quickly load and use the model whenever needed.
3. Reproducibility: Pickle files enable you to reproduce the exact state of a model or any other complex object at a later time. This is particularly valuable in research environments or when working with collaborative teams. By sharing the pickle file, others can easily replicate your model and results, ensuring more accurate and reproducible experiments.
4. Flexibility: Pickle files are not limited to just storing machine learning models. They can also be used to save and load other objects such as preprocessed datasets, trained transformers, or even intermediate results from complex data processing pipelines. This flexibility allows you to create more comprehensive and reusable workflows within your machine learning projects.
5. Compatibility with Python: Since pickle is a Python-specific module, it seamlessly integrates with the rest of the Python ecosystem. This makes it easy to use pickle files alongside popular machine learning libraries like scikit-learn, TensorFlow, and PyTorch. You can pickle and unpickle objects without worrying about compatibility issues, ensuring smooth integration within your Python-based machine learning workflow.
While pickle files offer numerous advantages, it’s important to keep in mind their limitations. Pickle files can only be used within the Python ecosystem, meaning they may not be compatible with other programming languages. Additionally, unpickling untrusted pickle files can pose a security risk, as they can execute arbitrary code during the deserialization process. It’s essential to only unpickle files from trusted sources to prevent any potential security vulnerabilities.
Now that we understand why pickle is a popular choice in machine learning, let’s explore how to create and load pickle files in the upcoming sections.
How to Create a Pickle File
Creating a pickle file in Python is a straightforward process. The pickle module provides the necessary functions to serialize and save objects into a file. Follow these steps to create a pickle file:
Step 1: Import the necessary modules: Start by importing the pickle module in your Python script or notebook. This will give you access to the functions needed for pickling objects.
Step 2: Prepare the object to be pickled: Before pickling an object, make sure it is in a state that you want to save. This can include trained machine learning models, data preprocessing pipelines, or any other custom object you want to store.
Step 3: Open a file in write binary mode: Use the built-in `open()` function to open a file in write binary mode. Specify the file path and name, along with the file extension `.pkl` to indicate that it’s a pickle file.
Step 4: Pickle the object: Use the `pickle.dump()` function to serialize and save the object into the open file. Pass the object as the first argument and the file object as the second argument.
Step 5: Close the file: After the pickling is complete, make sure to close the file using the `close()` method. This ensures that the data is written and the file is properly closed.
Here is a code snippet that demonstrates the process of creating a pickle file:
import pickle
# Step 1: Import the necessary modules
# Step 2: Prepare the object to be pickled
model = RandomForestClassifier()
# Step 3: Open a file in write binary mode
with open(“model.pkl”, “wb”) as file:
# Step 4: Pickle the object
pickle.dump(model, file)
# Step 5: Close the file
file.close()
By following these steps, you can create a pickle file and store your objects for future use. Remember to customize the file name and extension based on your requirements.
Now that you know how to create a pickle file, let’s explore how to load and use the pickled objects in the next section.
How to Load a Pickle File
Loading a pickle file in Python is a simple process that allows you to retrieve and use the serialized objects. To load a pickle file, follow the steps outlined below:
Step 1: Import the necessary modules: Begin by importing the pickle module into your Python script or notebook. This will enable you to access the functions required for unpickling objects.
Step 2: Open the pickle file: Use the `open()` function to open the pickle file in read binary mode. Specify the path and name of the pickle file that you want to load.
Step 3: Unpickle the object: Utilize the `pickle.load()` function to deserialize and load the object from the opened pickle file. Assign the returned object to a variable for further use.
Step 4: Close the file: After loading the object, ensure that you close the pickle file using the `close()` method. This will release system resources and avoid potential issues.
Here is an example code snippet that demonstrates the process of loading a pickle file:
import pickle
# Step 1: Import the necessary modules
# Step 2: Open the pickle file
with open(“model.pkl”, “rb”) as file:
# Step 3: Unpickle the object
loaded_model = pickle.load(file)
# Step 4: Close the file
file.close()
By following these steps, you can successfully load a serialized object from a pickle file. Adjust the file path and name based on the specific location and name of your pickle file.
Once the object is loaded, you can use it just like any other Python object. In the example above, the unpickled object is assigned to `loaded_model`, allowing you to apply the loaded machine learning model or access its properties and methods.
It’s important to note that when loading a pickle file, you must ensure that the code execution environment has the required libraries and dependencies installed for the unpickled object to function correctly. Additionally, be cautious when loading pickle files from untrusted sources, as they can potentially execute arbitrary code during the deserialization process.
Now that you know how to create and load pickle files, let’s explore the advantages and limitations of using pickle files in machine learning models.
Advantages and Limitations of Pickle Files
Pickle files offer several advantages that make them a popular choice for storing and sharing machine learning models and other objects. However, they also have a few limitations that need to be considered. Let’s explore the advantages and limitations of using pickle files:
Advantages:
1. Ease of Use: Pickle files provide a simple and intuitive way to serialize and deserialize complex objects. With just a few lines of code, you can save and load entire machine learning models, including their parameters, preprocessing steps, and other associated data.
2. Time and Resource Savings: By pickling and saving trained models, you can avoid the time-consuming process of retraining. Instead, you can load the model directly from the pickle file, saving valuable computational resources and reducing development time.
3. Reproducibility: Pickle files allow for the reproducibility of machine learning models and experiments. By sharing the pickle file, others can replicate your work, ensuring consistency in results and facilitating collaboration.
4. Flexibility: Pickle files are versatile and can be used to serialize various types of objects, including custom classes, data preprocessing pipelines, and more. This flexibility allows for the seamless integration of different components within machine learning workflows.
5. Compatibility with Python Ecosystem: As pickle is a Python-specific module, it integrates smoothly with popular machine learning libraries like scikit-learn, TensorFlow, and PyTorch. This compatibility simplifies the process of working with pickle files within the Python ecosystem.
Limitations:
1. Python-Specific: Pickle files are specific to the Python programming language and may not be compatible with other programming languages. This can be a limitation when collaborating with individuals using different languages or when working in multi-language environments.
2. Version Compatibility: Pickle files may have issues with version compatibility. Loading a pickle file created with a different version of Python or a different library may lead to compatibility issues and errors. It is important to ensure compatibility between the pickle file’s creation and loading environment.
3. Security Risks: Unpickling untrusted pickle files from unknown or unverified sources can pose security risks. Pickle files have the potential to execute arbitrary code during deserialization. It is important to only unpickle files from trusted and verified sources to prevent any security vulnerabilities.
4. Maintenance Challenges: Pickle files can become challenging to maintain over time, especially when changes are made to the code or external dependencies. Updating or modifying pickled objects may require additional work to ensure compatibility and consistency.
Understanding the advantages and limitations of pickle files is important when considering their use in machine learning projects. By weighing these factors, you can make informed decisions about when and how to leverage pickle files effectively.
Now that we have explored the advantages and limitations of pickle files, let’s delve into some best practices for using pickle files in machine learning models.
Best Practices for Using Pickle Files in Machine Learning Models
When working with pickle files in machine learning models, several best practices can help ensure optimal usage and avoid potential issues. These practices include:
1. Version Control: It is crucial to use version control systems, such as Git, to track changes and maintain different versions of your code and pickle files. This allows you to revert back to previous versions if needed and keeps your codebase organized.
2. Carefully Choose What to Pickle: Be selective about what objects you choose to pickle. Avoid pickling large datasets or unnecessary variables that can easily be recreated. Only pickle what is required for the model’s functionality to minimize the size of the pickle file.
3. Update Pickle Files Regularly: Pickle files should be updated whenever changes are made to the underlying code or dependencies. This ensures compatibility between the pickle file and the rest of the project, minimizing the risk of errors or compatibility issues.
4. Documentation: Maintain clear documentation that describes the purpose, contents, and usage of the pickle file. Include information about the version of Python and the libraries used during pickling to ensure proper compatibility and facilitate future maintenance.
5. Handle Version Compatibility: Be mindful of version compatibility when working with pickle files. Ensure that the pickle file is created and loaded using the same version of Python and relevant libraries to avoid compatibility issues. Version control and documentation can also help in maintaining compatibility between different versions of the pickle file.
6. Use Secure and Trusted Pickle Files: Only unpickle files from trusted sources, as unpickling untrusted pickle files can execute arbitrary code and pose security risks. Avoid downloading or using pickle files from unverified or unknown sources.
7. Consider Alternative Serialization Methods: While pickle files are a convenient choice for many use cases, there may be instances where alternative serialization methods, such as JSON or HDF5, are more appropriate. Evaluate the specific requirements and constraints of your project to determine the most suitable serialization approach.
8. Regularly Audit Pickle Files: Perform periodic audits of pickle files to ensure they are still relevant and necessary. Remove any obsolete pickle files that are no longer needed to reduce clutter and potential confusion in the project.
9. Test Pickle Files: Create unit tests to validate the loading and functionality of pickle files. This helps identify any issues or errors that may arise during the loading or unpickling process and ensures that the pickle file functions as intended.
By following these best practices, you can maximize the benefits of using pickle files in your machine learning projects while minimizing potential issues or limitations.
Now that we have explored the best practices, let’s conclude this article with a summary of the key points discussed.
Conclusion
Pickle files are a valuable tool in the field of machine learning. They provide a convenient and efficient way to serialize and deserialize complex Python objects, such as machine learning models, pipelines, and data preprocessing steps. By using pickle files, you can save time and computational resources by avoiding the need to retrain models or recreate objects from scratch. Pickle files also offer reproducibility, flexibility, and compatibility with the Python ecosystem, making them widely used in machine learning applications.
When working with pickle files, it is important to follow best practices to ensure optimal usage. This includes version control, careful selection of objects to pickle, regular updates, documentation, handling version compatibility, using secure and trusted pickle files, considering alternative serialization methods when appropriate, regular audits, and testing of pickle files.
While pickle files offer numerous advantages, they also have limitations that need to be considered. They are specific to the Python programming language, may have compatibility issues across different versions, and can pose security risks when unpickling untrusted pickle files.
In summary, pickle files are a powerful tool for storing and sharing machine learning models and related objects. By following best practices and understanding their advantages and limitations, you can effectively utilize pickle files to enhance the efficiency and reproducibility of your machine learning projects.