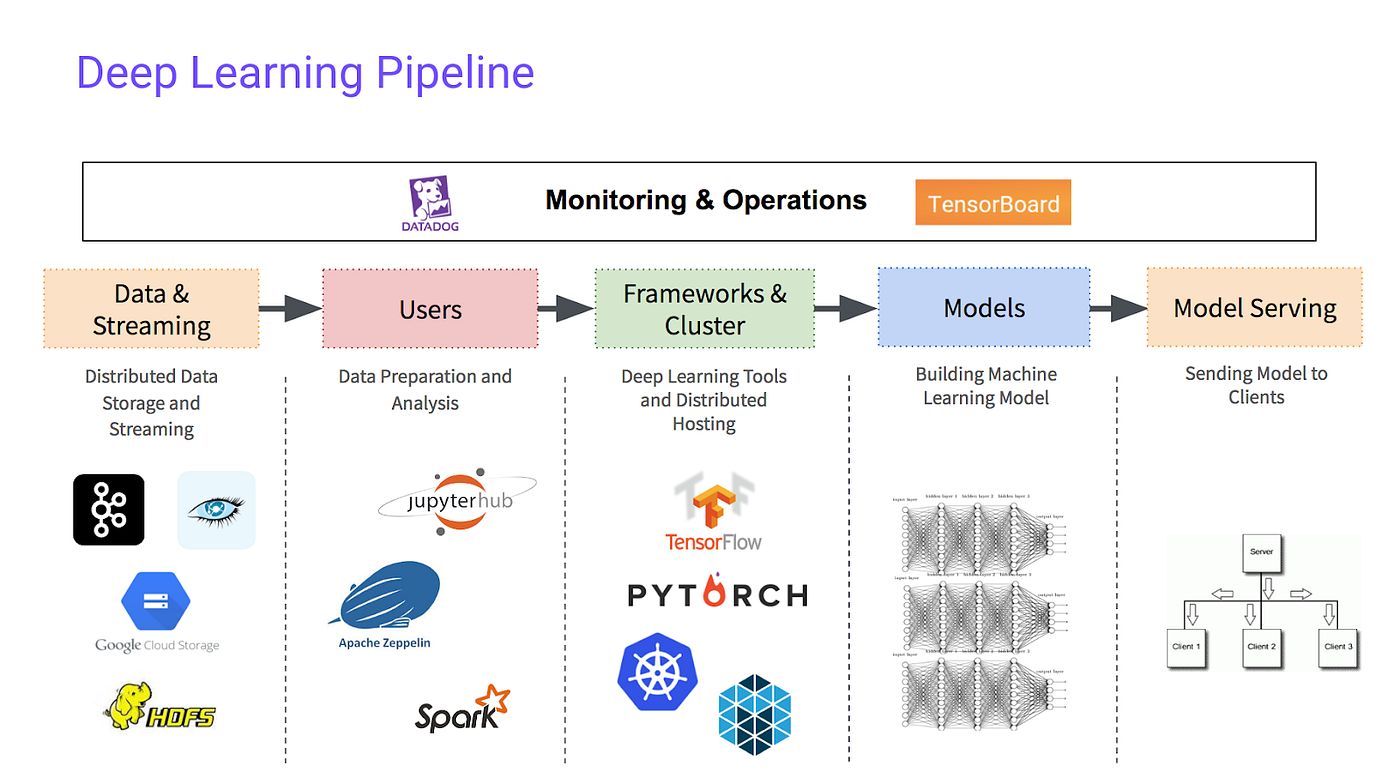
Introduction
Welcome to the world of machine learning model deployment! As the field of artificial intelligence continues to expand, the ability to effectively deploy models and make them accessible to end users becomes paramount. Deploying a machine learning model involves the process of taking a trained model and making it available for real-world use, whether it’s for predicting customer behavior, analyzing data patterns, or providing personalized recommendations.
Machine learning model deployment is a crucial step, as it bridges the gap between the development of a model and its practical application. Without proper deployment, a machine learning model remains confined to the realm of experimentation, rendering it useless for solving real-world problems and delivering meaningful insights.
In this article, we will explore the various aspects of deploying machine learning models, from data preparation to selecting the right deployment method. We will delve into the steps involved in building and training a model, evaluating its performance, and preparing it for deployment. Additionally, we will discuss the importance of choosing the right deployment method and explore two popular options: hosting the model on the cloud and deploying it on a web server.
To ensure a comprehensive understanding, we will also touch upon the essential concepts of monitoring and maintaining the deployed model, as well as the significance of Dockerization in the deployment process. By the end of this article, you will have gained valuable insights into the best practices and considerations involved in deploying machine learning models, empowering you to deliver impactful and practical solutions.
Understanding Machine Learning Model Deployment
Machine learning model deployment is the process of operationalizing a trained model and making it available for use in real-world scenarios. It involves taking the model and its associated components, such as data preprocessors and feature transformers, and integrating them into a system that can handle input data and provide reliable output predictions.
Deploying a machine learning model requires a clear understanding of the model’s purpose and the problem it aims to solve. It is essential to identify the target audience and determine how the model will be used by end users. This understanding helps in selecting the appropriate deployment strategy and optimizing the model for its intended application.
During the deployment process, it is crucial to consider factors such as scalability, performance, and security. The deployed model should be able to handle a high volume of requests efficiently, provide accurate and timely predictions, and ensure the confidentiality and integrity of the data being processed.
Furthermore, model deployment involves managing dependencies and ensuring compatibility between the model and the deployment environment. This includes considering the programming languages, frameworks, and libraries used in the model development phase and ensuring they are supported in the deployment environment.
Model deployment also requires quality assurance practices, such as testing the model’s performance on new data samples and validating its robustness against potential edge cases. It is important to ensure that the deployed model consistently performs well and remains accurate in a variety of scenarios.
Understanding machine learning model deployment also entails considering the lifecycle of the model. Models may require periodic updates and retraining to adapt to changing data patterns, evolving user needs, or improvements in the underlying algorithms. A well-planned deployment strategy takes into account these factors and provides mechanisms for model maintenance and updates.
In summary, understanding machine learning model deployment involves grasping the purpose of the model, identifying the target audience, selecting an appropriate deployment strategy, considering scalability and performance requirements, ensuring compatibility and managing dependencies, performing quality assurance, and planning for the model’s lifecycle. By gaining a deep understanding of these aspects, we can successfully deploy machine learning models that effectively address real-world problems and deliver value to end users.
Data Preparation for Model Deployment
Data preparation is a crucial step in machine learning model deployment as it lays the foundation for building a successful and accurate model. Before a model can be trained and deployed, the raw data needs to be processed, transformed, and preprocessed to ensure its quality and suitability for the model’s requirements.
The first step in data preparation is data cleaning. This involves handling missing values, removing outliers, and resolving any inconsistencies or errors in the data. Missing values can be filled using techniques such as imputation or interpolation, while outliers can be identified and either removed or treated separately.
Next, it is essential to conduct exploratory data analysis (EDA) to understand the characteristics of the data and identify potential patterns or relationships. EDA involves visualizing the data, calculating summary statistics, and performing statistical tests to gain insights into the data’s distribution, correlations, and other key attributes.
After data cleaning and EDA, feature engineering comes into play. Feature engineering is the process of transforming and creating new features from the existing data to enhance the predictive power of the model. This can involve techniques such as scaling, normalization, binning, one-hot encoding, and more, depending on the nature of the data and the requirements of the machine learning algorithm.
Feature selection is another important aspect of data preparation. It involves identifying the most relevant and informative features for the model while discarding irrelevant or redundant ones. Feature selection techniques can help improve the model’s performance, reduce training time, and minimize overfitting.
Once the data has been cleaned, transformed, and preprocessed, it needs to be split into training and testing datasets. The training dataset is used to train the model, while the testing dataset is used to evaluate its performance. The data split is typically done randomly, ensuring that both datasets represent the underlying data distribution.
For some machine learning algorithms, additional steps such as dimensionality reduction or data resampling may be required. Dimensionality reduction techniques, such as principal component analysis (PCA), can help reduce the number of features while retaining most of the variance in the data. Data resampling techniques, such as oversampling or undersampling, can be employed to address class imbalance issues.
In summary, data preparation plays a critical role in the success of machine learning model deployment. It involves cleaning the data, conducting exploratory data analysis, performing feature engineering and selection, splitting the data into training and testing sets, and potentially applying dimensionality reduction or data resampling techniques. By investing time and effort in data preparation, we can ensure that the deployed model is built on a solid foundation and is capable of delivering accurate and meaningful predictions in real-world scenarios.
Building and Training the Machine Learning Model
Building and training a machine learning model is a crucial step in the process of deploying it for real-world use. This step involves selecting an appropriate algorithm, preparing the training data, and optimizing the model’s parameters to achieve the best performance.
The first step in building a machine learning model is selecting the right algorithm or combination of algorithms. The choice of algorithm depends on the nature of the problem, the type of data available, and the desired output. Common types of machine learning algorithms include decision trees, random forests, support vector machines, neural networks, and gradient boosting algorithms like XGBoost or LightGBM.
Once the algorithm is chosen, the next step is to prepare the training data. This involves transforming the data into a format suitable for model training. The data should be in numerical form, and categorical variables may need to be encoded using techniques such as one-hot encoding or label encoding.
Feature scaling is another important preprocessing step in model training. Scaling features ensures that they are on a similar scale, preventing certain features from dominating the training process due to their larger magnitude. Common scaling techniques include standardization (mean removal and unit variance) and normalization (scaling to a specified range).
After data preparation, the machine learning model is ready to be trained. The training process involves feeding the prepared data to the model and adjusting its parameters to minimize the difference between predicted and actual values. This is typically done using an optimization algorithm, such as gradient descent, which updates the model’s parameters iteratively based on the calculated error or loss function.
During the training process, it is important to monitor the model’s performance. This can be done by evaluating metrics such as accuracy, precision, recall, or mean squared error, depending on the specific problem and output type. It is also advisable to split the training data into smaller subsets known as validation sets to measure the model’s performance on unseen data and prevent overfitting.
The optimization of the model’s parameters, known as hyperparameter tuning, is another critical step in building and training a machine learning model. Hyperparameters are settings that are not learned from the data but are set by the user. Examples of hyperparameters include learning rate, regularization factor, number of hidden layers in a neural network, or maximum depth of a decision tree. Hyperparameter tuning involves searching for the best combination of hyperparameters that leads to optimal model performance.
In summary, building and training a machine learning model involves selecting the right algorithm, preparing the training data, scaling features, training the model using optimization algorithms, monitoring performance metrics, and tuning hyperparameters. By following these steps, we can create a well-performing model that is ready for deployment and capable of making accurate predictions on real-world data.
Model Evaluation and Selection
Model evaluation and selection are essential steps in the machine learning pipeline. These steps involve assessing the performance of different models and choosing the most suitable one for deployment based on specific evaluation metrics.
Model evaluation starts with splitting the data into training and testing sets. The testing set, also known as the validation set, is used to evaluate the model’s performance on unseen data. This step helps to assess how well the model generalizes to new data and provides an unbiased estimate of its performance.
There are various evaluation metrics that can be used depending on the nature of the problem. For classification tasks, common evaluation metrics include accuracy, precision, recall, F1 score, and area under the receiver operating characteristic curve (AUC-ROC). For regression tasks, evaluation metrics can include mean square error (MSE), mean absolute error (MAE), and R-squared.
It is important to select the evaluation metric that aligns with the objective of the problem at hand. For instance, if the focus is on minimizing false positives, precision may be a more relevant metric. On the other hand, if the goal is to capture as many true positives as possible, recall may be the metric of interest.
Model selection involves comparing the performance of different models using the chosen evaluation metric(s). This can be done by training and evaluating multiple models on the same data and comparing their performance. The best-performing model, based on the chosen evaluation metric(s), is then selected for deployment.
It is worth noting that model evaluation and selection can be influenced by various factors, such as dataset size, data quality, and the complexity of the problem. It is generally recommended to use cross-validation techniques, such as k-fold cross-validation, to obtain a more robust estimate of a model’s performance by repeating the evaluation process on multiple subsets of the data.
In addition to evaluation metrics, it is essential to consider other factors when selecting a model for deployment. These factors include the interpretability of the model, its computational efficiency, and its scalability to handle large volumes of data and high concurrency.
Furthermore, it is beneficial to experiment with different variations of the same model or different algorithms altogether to discover the one that performs best on the given problem. This experimentation can involve tweaking hyperparameters, exploring different feature combinations, or trying ensemble methods which combine the predictions of multiple models.
In summary, model evaluation and selection are critical steps in the machine learning model deployment process. By evaluating models using appropriate evaluation metrics, comparing their performance, and considering other factors such as interpretability and scalability, we can select the best-performing model for deployment. These steps help ensure that the deployed model delivers accurate and reliable predictions, meeting the requirements of the intended application.
Preparing the Model for Deployment
Preparing a machine learning model for deployment involves several important steps to ensure its seamless integration into a production environment. This phase focuses on packaging the model and its associated components, optimizing its performance, and ensuring its compatibility with the deployment infrastructure.
The first step in preparing the model for deployment is saving or serializing the trained model and its associated preprocessing components. This allows the model to be easily loaded and used for making predictions in a deployment environment. Common serialization formats include JSON, XML, or binary formats like Pickle or joblib.
Next, it is crucial to perform any necessary performance optimizations to ensure the model can handle the expected workload efficiently. This may involve techniques such as model pruning to reduce the size and complexity of the model, quantization to reduce memory and computational requirements, or using model compression techniques like network pruning or weight sharing.
Compatibility with the deployment infrastructure is another key consideration. This involves ensuring that the programming language and versions, as well as any required libraries or dependencies, are compatible with the deployment environment. It is also important to consider any hardware or software restrictions imposed by the deployment infrastructure and make the necessary adjustments for a smooth deployment.
Model versioning is an essential aspect of preparing the model for deployment. Keeping track of different versions of the model allows for easy rollback in case of issues and enables proper documentation and communication with stakeholders. Versioning can be achieved through version control systems or by implementing a model versioning strategy within the deployment pipeline.
Data pipeline integration is another consideration when preparing the model for deployment. This involves ensuring that the model can seamlessly integrate with the data pipeline or data ingestion system, allowing for real-time or batch prediction processing. This often requires building APIs or connectors to enable data flow between the model and other components of the system.
Finally, it is crucial to perform rigorous testing and validation of the prepared model to ensure its correctness and reliability. This includes conducting unit tests to verify that the model behaves as expected, as well as testing the integration of the model within the deployment infrastructure. It is also valuable to simulate and stress-test the model under different scenarios to evaluate its robustness and scalability.
In summary, preparing a machine learning model for deployment involves saving the trained model, optimizing its performance, ensuring compatibility with the deployment infrastructure, implementing versioning and integration with the data pipeline, and conducting thorough testing and validation. By following these steps, we can ensure a smooth and successful deployment of the model, enabling it to deliver accurate predictions in a real-world production environment.
Choosing a Deployment Method
Choosing the right deployment method is crucial for successfully deploying a machine learning model. The choice of method depends on various factors, such as the nature of the problem, the intended audience, scalability requirements, infrastructure capabilities, and the level of control and customization needed.
One popular deployment method is hosting the model on the cloud. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), provide infrastructure and services that simplify the deployment process. This method offers scalability, flexibility, and ease of management since the platform handles the infrastructure and provides tools for monitoring and scaling resources based on demand.
Another deployment method is deploying the model on a web server. This method involves setting up a web server to host the model and building an API that accepts input data and returns model predictions. This approach provides control and customization options, allowing for fine-tuning of the deployment environment and integration with existing systems or applications.
Containerization using tools like Docker has gained popularity as a deployment method. Docker allows packaging the model and all its dependencies into a container, providing a consistent and portable environment. Containers can be deployed on cloud platforms, local servers, or managed containerization services like Kubernetes. This method offers flexibility, scalability, and isolation, making it easier to deploy and manage models across different environments.
In some cases, edge deployment may be preferred. Edge deployment involves deploying the model directly on edge devices, such as smartphones, IoT devices, or edge servers. This approach is useful when real-time predictions are needed without relying on continuous internet connectivity or when data privacy and security are paramount. Edge deployment minimizes latency and allows for offline capabilities.
The choice of deployment method should also align with the intended audience and application requirements. For example, a web-based application may benefit from a web server deployment, while an application targeting mobile users may require edge deployment to minimize latency and leverage device capabilities.
Additionally, considerations such as data privacy and regulatory compliance should play a role in the selection of a deployment method. Some industries or jurisdictions may have strict regulations on data handling and storage, requiring the deployment to adhere to specific security protocols and certifications.
In summary, choosing the right deployment method involves considering factors such as problem nature, scalability requirements, infrastructure capabilities, customization needs, audience, data privacy, and regulatory compliance. Cloud hosting, web server deployment, containerization, and edge deployment are among the popular methods to choose from. By carefully evaluating these factors, we can select the deployment method that best suits the requirements of the machine learning model and enables seamless integration into the desired environment.
Hosting the Model on the Cloud
Hosting a machine learning model on the cloud has become a popular deployment method due to its scalability, flexibility, and ease of management. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), provide infrastructure and services that simplify the process of hosting and deploying machine learning models.
One of the advantages of hosting the model on the cloud is the ability to scale resources based on demand. Cloud platforms offer features like auto-scaling, which automatically adjusts the number of resources allocated to handle varying workloads. This ensures that the model can handle spikes in traffic without compromising performance or incurring unnecessary costs.
Cloud platforms also provide services for managing and monitoring the deployed models. These services include resource monitoring, logging, and error handling. Additionally, cloud platforms offer features to streamline the deployment process, such as pre-built API frameworks and deployment pipelines that automate the packaging and deployment of the model.
Hosting the model on the cloud also allows for easy integration with other cloud services and APIs. This integration enables the model to access additional data sources, utilize advanced analytics and machine learning services, or leverage storage and database solutions offered by the cloud platform. This seamless integration enhances the capabilities and versatility of the deployed model.
Moreover, cloud platforms provide security measures to protect the model and its data. They offer features such as encryption, role-based access control, and security monitoring to ensure the confidentiality, integrity, and availability of the deployed model. Cloud platforms comply with industry standards and regulations, making them a suitable choice for applications with strict security and compliance requirements.
Cost-effectiveness is another advantage of hosting a model on the cloud. Cloud platforms offer pay-as-you-go pricing models, allowing users to pay only for the resources they consume. This eliminates the need for upfront hardware costs and provides flexibility in adjusting resource allocation as the model’s usage patterns change over time. Additionally, cloud platforms offer cost management tools to monitor and optimize spending on deployed models.
When hosting a model on the cloud, it is important to consider factors such as the choice of cloud provider, data privacy and compliance requirements, and the scalability and performance needs of the application. Proper planning, architecture design, and monitoring are essential to ensure a reliable and efficient deployment on the cloud platform.
In summary, hosting a machine learning model on the cloud offers scalability, flexibility, ease of management, integration with other services, security measures, and cost-effectiveness. Cloud platforms provide the infrastructure and tools necessary for deploying and managing machine learning models in a reliable and efficient manner, enabling organizations to make their models accessible and available to a wider audience.
Dockerizing the Model
Dockerizing a machine learning model has gained popularity as a deployment method due to its flexibility, portability, and ease of reproducibility. Docker allows packaging the model, its dependencies, and the runtime environment into a portable container, ensuring consistency across different environments and simplifying the deployment process.
The first step in Dockerizing a model is creating a Dockerfile. A Dockerfile is a text file that contains a series of instructions for building a Docker image. These instructions include specifying the base image, installing dependencies and libraries required by the model, copying the model’s code and associated files into the container, and defining the commands to execute when the container starts.
Once the Dockerfile is created, the next step is building the Docker image. This is done by executing the “docker build” command and providing the path to the directory containing the Dockerfile. The command builds the image according to the instructions in the Dockerfile and creates a self-contained and executable image that encapsulates the model and its dependencies.
After the Docker image is built, it can be deployed on any system that has Docker installed, making the deployment process consistent and reproducible across different environments. Docker images can be run on cloud platforms, local servers, or managed containerization services like Kubernetes.
Docker provides isolation between the model and the underlying host system, ensuring that the model runs in an isolated and controlled environment. This isolation prevents conflicts with other systems or applications running on the same host and provides security by limiting access to system resources.
Docker also allows for easy scaling and resource management. Multiple instances of the same Docker image can be run simultaneously, allowing for horizontal scaling and load balancing. Docker provides tools and APIs for monitoring and managing containers, making it easier to monitor resource usage, manage logs, and scale containers up or down based on demand.
Another advantage of Dockerizing a model is the ability to leverage existing Docker images and community-contributed images. Docker has a vast repository of pre-built images for popular frameworks and libraries, such as TensorFlow, PyTorch, and scikit-learn. These images can be used as a base, reducing the effort required to set up the model’s environment and ensuring compatibility with established best practices and standards.
It is worth noting that Dockerizing a model requires careful consideration of the model’s requirements, dependencies, and resource constraints. Proper testing and validation of the Docker image are essential to ensure that it behaves as expected and reproduces the same results as when running the model natively.
In summary, Dockerizing a machine learning model provides flexibility, portability, and reproducibility in the deployment process. Docker images encapsulate the model, its dependencies, and the runtime environment, ensuring consistency across different environments. Docker enables easy scaling, resource management, and isolation, making it a popular choice for deploying machine learning models in a variety of environments.
Deploying the Model on a Web Server
Deploying a machine learning model on a web server is a popular method that allows for real-time predictions and easy integration with web-based applications. With a web server deployment, the model is hosted on a server and can be accessed through HTTP endpoints, providing a straightforward and scalable way to interact with the model.
The first step in deploying a model on a web server is setting up the server infrastructure. This can be done using traditional web server software like Apache or Nginx or by leveraging modern web application frameworks like Flask or Django. These frameworks provide a foundation for building the server infrastructure, handling HTTP requests, and managing the model’s lifecycle.
Once the server infrastructure is set up, the model needs to be integrated with the web server application. This involves writing code to load the trained model, preprocess input data, and make predictions using the model. Frameworks like Flask or Django provide tools and APIs to handle these tasks, simplifying the integration process.
When deploying the model on a web server, it is important to design a well-defined API that allows clients to interact with the model. The API should specify the input format and provide clear documentation on how to make requests and interpret the model’s response. Following best practices for API design ensures a user-friendly experience and makes it easier for developers to integrate the model into their applications.
Scalability is a critical consideration when deploying a model on a web server. As the number of users and requests increases, the server should be able to handle the load without compromising performance. Techniques like load balancing and horizontal scaling can be employed to distribute the workload across multiple server instances, ensuring efficient resource utilization and response times.
Security is another important aspect of deploying a model on a web server. Measures like authentication, encryption, and input validation should be implemented to protect the model and the data being sent to and received from the server. Access controls and rate limiting can also be employed to prevent abuse and ensure the resources are used responsibly.
Monitoring and logging are essential for maintaining the deployed model on a web server. Monitoring tools can track performance metrics, server response times, and resource usage, enabling proactive identification and resolution of issues. Logging allows for capturing and analyzing server and model-related events, providing valuable insights for troubleshooting and improvement.
In summary, deploying a machine learning model on a web server allows for real-time predictions and seamless integration with web applications. Setting up the server infrastructure, integrating the model with the application, designing a well-defined API, ensuring scalability and security, and implementing monitoring and logging are crucial steps in deploying the model on a web server. By following these steps, the model can be made accessible to users through HTTP endpoints, facilitating its usability and integration with a wide range of web-based applications.
Monitoring and Maintaining the Deployed Model
Monitoring and maintaining a deployed machine learning model is essential to ensure its continued reliability, accuracy, and performance. Regular monitoring allows for identifying and addressing issues, tracking performance metrics, and making necessary adjustments to the model or infrastructure as needed.
One crucial aspect of monitoring a deployed model is tracking its performance metrics. This includes monitoring metrics such as accuracy, precision, recall, or mean squared error, depending on the specific problem and evaluation requirements. Monitoring these metrics helps identify any degradation in performance over time and enables proactive measures to maintain or improve the model’s performance.
In addition to model-specific metrics, it is important to monitor the runtime environment and infrastructure on which the model is deployed. This includes tracking resource usage, server response times, and network latency. Monitoring these metrics allows for detecting bottlenecks, identifying potential performance issues, and scaling resources or making infrastructure adjustments as needed.
Error monitoring and logging are crucial for identifying and resolving any issues or anomalies that arise during model deployment. Log files can provide valuable insights into the behavior of the deployed model, helping identify any errors or unexpected behaviors. This information is vital for troubleshooting and making necessary adjustments to improve the model’s stability and reliability.
Continuous integration and deployment (CI/CD) practices can also be employed for maintaining the deployed model. By implementing automated testing, version control, and deployment pipelines, developers can ensure that any changes or updates to the model are thoroughly tested and can be deployed with minimal disruption. CI/CD practices help in maintaining the model’s correctness, stability, and reliability while enabling seamless updates.
Regular model retraining and updates are important to keep the model’s performance optimized. As new data becomes available and the underlying patterns change, retraining the model periodically ensures that it remains accurate and up to date. Retraining can be done on a scheduled basis or triggered by predefined criteria, such as reaching a certain threshold of data or when performance metrics indicate a significant decrease in accuracy.
Data quality monitoring is another vital aspect of maintaining a deployed model. Ensuring the quality and consistency of input data is essential for the model’s accuracy and generalizability. Data quality monitoring involves performing sanity checks on the input data, conducting periodic data audits, and implementing data validation processes to identify and handle potential data issues.
Feedback and user feedback gathering is an important part of maintaining the deployed model. Collecting feedback from end users, receiving bug reports, and analyzing user behavior helps in understanding how the model performs in real-world scenarios. This feedback can lead to insights on model improvements, feature requests, or potential issues that need to be addressed.
In summary, monitoring and maintaining a deployed machine learning model is crucial for ensuring its continued accuracy, reliability, and performance. Regularly tracking performance metrics, monitoring the runtime environment, implementing error monitoring and logging, following CI/CD practices, retraining the model, monitoring data quality, and gathering user feedback are key steps in successfully maintaining a deployed model. By incorporating these practices, organizations can ensure that their machine learning models deliver reliable and impactful results over time.
Conclusion
Deploying a machine learning model is a crucial step in leveraging its predictive power and making it accessible to end users. Throughout this article, we have explored various aspects of model deployment, from data preparation to selecting the right deployment method and monitoring and maintaining the deployed model.
Data preparation involves cleaning, preprocessing, and engineering the data to ensure its quality and suitability for model training. Building and training the model require selecting the right algorithm, preparing the training data, and optimizing parameters for optimal performance. Model evaluation and selection allow us to compare different models and choose the most suitable one based on specific evaluation metrics.
Preparing the model for deployment involves saving the trained model, optimizing its performance, ensuring compatibility with the deployment infrastructure, and validating its correctness. Choosing a deployment method involves considering factors such as the problem nature, scalability requirements, infrastructure capabilities, and audience needs.
Hosting the model on the cloud provides scalability, flexibility, and ease of management, while dockerizing the model offers portability, reproducibility, and isolation. Deploying the model on a web server enables real-time predictions and seamless integration with web-based applications. Monitoring and maintaining the deployed model involve tracking performance metrics, monitoring the runtime environment, implementing error monitoring and logging, and regularly retraining the model.
By following best practices for each step of the deployment process, organizations and developers can ensure that their machine learning models deliver accurate, reliable, and impactful results in real-world scenarios. The choice of deployment method, ongoing monitoring, and consistent maintenance are essential to guarantee the model’s continued success.
In conclusion, machine learning model deployment is a dynamic and iterative process that requires careful consideration at every stage. With proper planning, preparation, and monitoring, organizations can maximize the value of their machine learning models and drive meaningful insights to solve real-world problems.