Introduction
Machine learning is a fascinating field that empowers computers to learn and make predictions or decisions without being explicitly programmed. It utilizes various algorithms and statistical models to analyze data, identify patterns, and make accurate predictions or classifications. From self-driving cars to personalized recommendations on e-commerce platforms, machine learning has become an integral part of our lives.
Machine learning can be categorized into supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the model is trained on labeled data, meaning it learns from examples with input features and corresponding output labels. Unsupervised learning, on the other hand, deals with unlabeled data, where the model identifies patterns and structure without any predefined labels. Reinforcement learning is focused on training an agent to take actions in an environment to maximize rewards.
In this article, we will delve into the step-by-step process involved in machine learning, providing a comprehensive understanding of how to develop effective models. Each step plays a critical role, from data collection, preprocessing, and feature engineering to model selection, training, evaluation, and deployment.
The goal of machine learning is to create models that can generalize well on unseen data, making accurate predictions or decisions. This is achieved by finding the right balance between underfitting and overfitting. Underfitting occurs when the model fails to capture the underlying patterns in the data, while overfitting happens when the model becomes too complex and memorizes the training data, leading to poor performance on new data.
Throughout this article, we will explore each step in detail, discussing best practices and techniques used by machine learning practitioners. By the end, you will have a solid understanding of the sequential process involved in machine learning and how it can be applied to solve real-world problems.
Data Collection
Data collection is the first crucial step in the machine learning pipeline. It involves acquiring the necessary data from various sources to build a robust and reliable model. The quality and quantity of data collected greatly influence the performance and accuracy of the machine learning model.
There are different sources from where data can be collected, such as databases, APIs, web scraping, or even manually entering data. Depending on the problem domain, data can be structured (e.g., relational databases) or unstructured (e.g., text, images, videos). It is essential to ensure that the collected data is representative of the problem we are trying to solve.
When collecting data, it is important to consider the following aspects:
- Data Source: Choose reliable and relevant sources that provide high-quality data. Consider the credibility, reputation, and suitability of the data source for your specific problem.
- Data Quantity: Collect a sufficient amount of data to provide enough examples for the model to learn from. Too little data may result in an underperforming model, while too much data may lead to longer processing times.
- Data Quality: Ensure the data collected is accurate, complete, and free from errors. This may involve performing data cleaning, eliminating outliers, and handling missing values.
- Data Privacy and Ethics: Respect privacy regulations and ethical considerations when collecting data. Anonymize or encrypt sensitive data to protect individuals’ privacy.
Furthermore, it is essential to maintain a well-organized data collection process. Properly labeling and categorizing the data can save time and effort during the subsequent stages of the machine learning project. Additionally, consider creating a data backup and versioning system to prevent data loss or corruption.
Overall, the success of a machine learning model heavily relies on the quality and diversity of the collected data. Thoroughly assessing and curating the data before moving forward ensures a solid foundation for subsequent stages, such as data preprocessing and model training.
Data Preprocessing
Data preprocessing is a crucial step in machine learning that involves preparing the collected data for effective analysis and model training. Raw data often contains noise, inconsistencies, missing values, and outliers, which can negatively impact the performance and accuracy of the models. Data preprocessing aims to address these issues and ensure that the data is in a suitable format for analysis.
There are several techniques involved in data preprocessing, including the following:
- Data Cleaning: This step involves handling missing values, incorrect or inconsistent data, and outliers. Missing values can be either removed, replaced with suitable values (e.g., mean or median), or imputed using advanced techniques. Inconsistent data can be corrected or removed, while outliers can be detected and dealt with using statistical methods.
- Data Transformation: Transformation techniques are applied to normalize the data distribution and make it suitable for modeling. Common transformations include scaling, logarithmic transformation, or using techniques like Box-Cox to achieve a more Gaussian distribution.
- Feature Selection: In some cases, the dataset may contain irrelevant or redundant features that do not contribute much to the model’s performance. Feature selection techniques help identify and retain only the most informative and relevant features, reducing the dimensionality of the dataset.
- Encoding Categorical Variables: Machine learning models typically work with numerical data, so categorical variables need to be encoded appropriately. This includes techniques like one-hot encoding, label encoding, or ordinal encoding to represent categorical variables as numerical values.
- Feature Scaling: To ensure that features are on a similar scale, normalization or standardization techniques are applied. Normalization scales the data to a range between 0 and 1, while standardization transforms the data to have zero mean and unit variance.
During data preprocessing, it is essential to strike a balance between removing noise and maintaining the integrity of the data. Over-processing or manipulating the data excessively can lead to loss of information and potentially introduce bias into the model.
By effectively preprocessing the data, the machine learning models can learn patterns more accurately and make better predictions. It sets a solid foundation for the subsequent stages of the machine learning pipeline, such as feature engineering and model training.
Exploratory Data Analysis
Exploratory Data Analysis (EDA) is a vital step in the machine learning pipeline that helps in understanding the structure, patterns, and relationships within the data. It involves visualizing and summarizing the data to extract meaningful insights and identify potential correlations that can guide feature selection and model design.
During EDA, various statistical and graphical techniques are applied to gain a deeper understanding of the data. Some commonly used EDA techniques include:
- Summary Statistics: Calculate statistical measures such as mean, median, standard deviation, and quartiles to understand the central tendency, dispersion, and distribution of the variables.
- Data Visualization: Create visual representations of the data using plots like histograms, box plots, scatter plots, and correlation matrices. Visualizations provide a concise and intuitive way to explore relationships between variables, identify outliers, and detect patterns.
- Correlation Analysis: Determine the relationships between variables by calculating correlation coefficients. This helps to identify variables that are strongly correlated, which can impact feature selection and model performance.
- Dimensionality Reduction: Utilize techniques like principal component analysis (PCA) or t-SNE to reduce the number of variables while retaining the most important information. This helps in visualizing and understanding high-dimensional data.
- Data Imbalance Analysis: If the dataset is imbalanced, where one class dominates over others, it is important to examine and address this issue. Techniques like oversampling or undersampling can be used to balance the dataset.
EDA helps reveal potential data quality issues, such as missing values, outliers, or inconsistent patterns. It also provides insights into the relationships between variables, helping to select the most important features for model training. Additionally, EDA can guide the choice of appropriate machine learning algorithms based on the data characteristics and problem requirements.
By gaining a deeper understanding of the data through EDA, machine learning practitioners can make informed decisions regarding data preprocessing, feature engineering, and model development. EDA acts as a bridge between data collection and model building, enabling more effective and accurate predictions or decisions.
Feature Engineering
Feature engineering is a critical step in the machine learning pipeline that involves transforming raw data into meaningful features that can enhance the performance of the models. It is the process of selecting, creating, and transforming features to represent the data in a way that captures relevant information and improves predictive power.
Feature engineering is driven by domain knowledge and understanding of the problem at hand. It requires a deep understanding of the data and the specific requirements of the machine learning task.
There are several techniques and approaches utilized in feature engineering:
- Feature Extraction: This involves extracting meaningful information from the existing data variables to create new features. For example, extracting the day, month, and year from a timestamp can be useful in time series analysis.
- Feature Encoding: Transforming categorical variables into numerical representations that can be understood by the machine learning algorithms. This can be accomplished through one-hot encoding, label encoding, or target encoding.
- Normalization: Scaling features to have similar scales or distributions to prevent some variables from overpowering others in the model. Techniques like min-max scaling or z-score normalization are commonly used.
- Feature Interaction: Creating new features by combining or interacting existing features. This can capture non-linear relationships and improve model performance. Examples include multiplying or dividing two variables or creating interaction terms in regression models.
- Feature Selection: Identifying and selecting the most relevant features for the machine learning task. This can be achieved through statistical techniques like correlation analysis, feature importance ranking, or using domain knowledge.
Feature engineering requires a careful balance between creating informative features and preventing overfitting. The aim is to provide the machine learning model with the most relevant and informative features while keeping the model complexity manageable.
It is important to iterate and experiment with different feature engineering techniques to find the optimal set of features that improves the performance of the machine learning models. Feature engineering is an iterative process that involves constant evaluation and refinement based on model performance and feedback.
By investing time and effort into feature engineering, the machine learning models can leverage the power of meaningful and informative features, ultimately leading to improved prediction accuracy and better insights.
Model Selection
Model selection is a crucial step in the machine learning process where the most suitable algorithm or model is chosen to solve the problem at hand. The selected model should have the ability to effectively capture the patterns and relationships present in the data and make accurate predictions or classifications.
There is a wide range of machine learning algorithms to choose from, each with its own strengths and limitations. The choice of algorithm depends on various factors, including:
- Data Characteristics: Consider the nature of the data, such as its size, complexity, linearity, and distribution. Some algorithms perform better on structured data, while others are more suitable for unstructured data like text or images.
- Problem Type: Determine whether the problem is a regression, classification, or clustering task. Different algorithms are better suited for specific problem types.
- Model Complexity: Take into account the complexity and interpretability of the model. Sometimes, a simpler model (like linear regression) may be sufficient, while in other cases, more complex models (such as ensemble methods or deep learning) may be necessary.
- Training Speed: Consider the computational requirements and training time of the algorithms, especially when dealing with large datasets or real-time applications.
- Domain Knowledge and Expertise: Your familiarity with specific algorithms and their performance on similar problems can also influence the model selection decision.
It is good practice to evaluate and compare multiple models to select the most appropriate one. This can be done through techniques such as cross-validation, where the data is split into multiple subsets for training and evaluation. Performance metrics like accuracy, precision, recall, and F1 score are used to assess the models’ performance.
Additionally, it is important to consider the potential biases and limitations of the selected model. Some models may perform well on the training data but struggle to generalize to unseen data. It is important to strike a balance between bias and variance, ensuring the model does not underfit or overfit the data.
Model selection is an iterative process, where the models are refined and fine-tuned based on their performance. It is important to consider feedback from model evaluation and adjust the hyperparameters or algorithm choice accordingly.
By carefully selecting the appropriate model, you set the foundation for accurate predictions or decisions, which is crucial to the success of any machine learning project.
Model Training
Model training is a key step in the machine learning pipeline where the selected algorithm or model is trained on the labeled data to learn patterns and make accurate predictions or classifications. The purpose of training is to optimize the model’s parameters so that it can generalize well and perform effectively on unseen data.
The process of model training involves the following steps:
- Data Splitting: The labeled data is divided into separate training and validation sets. The training set is used to train the model, while the validation set is used to evaluate its performance during training and fine-tune the model.
- Model Initialization: The model is initialized with predefined weights or parameters. The initial values can be random or based on prior knowledge.
- Forward Propagation: The training examples are fed into the model, and the outputs are computed using the current set of parameters. This involves propagating the inputs forward through the neural network or algorithm.
- Loss Calculation: A loss function is used to measure the difference between the predicted outputs and the actual labels. This quantifies how well the model is performing.
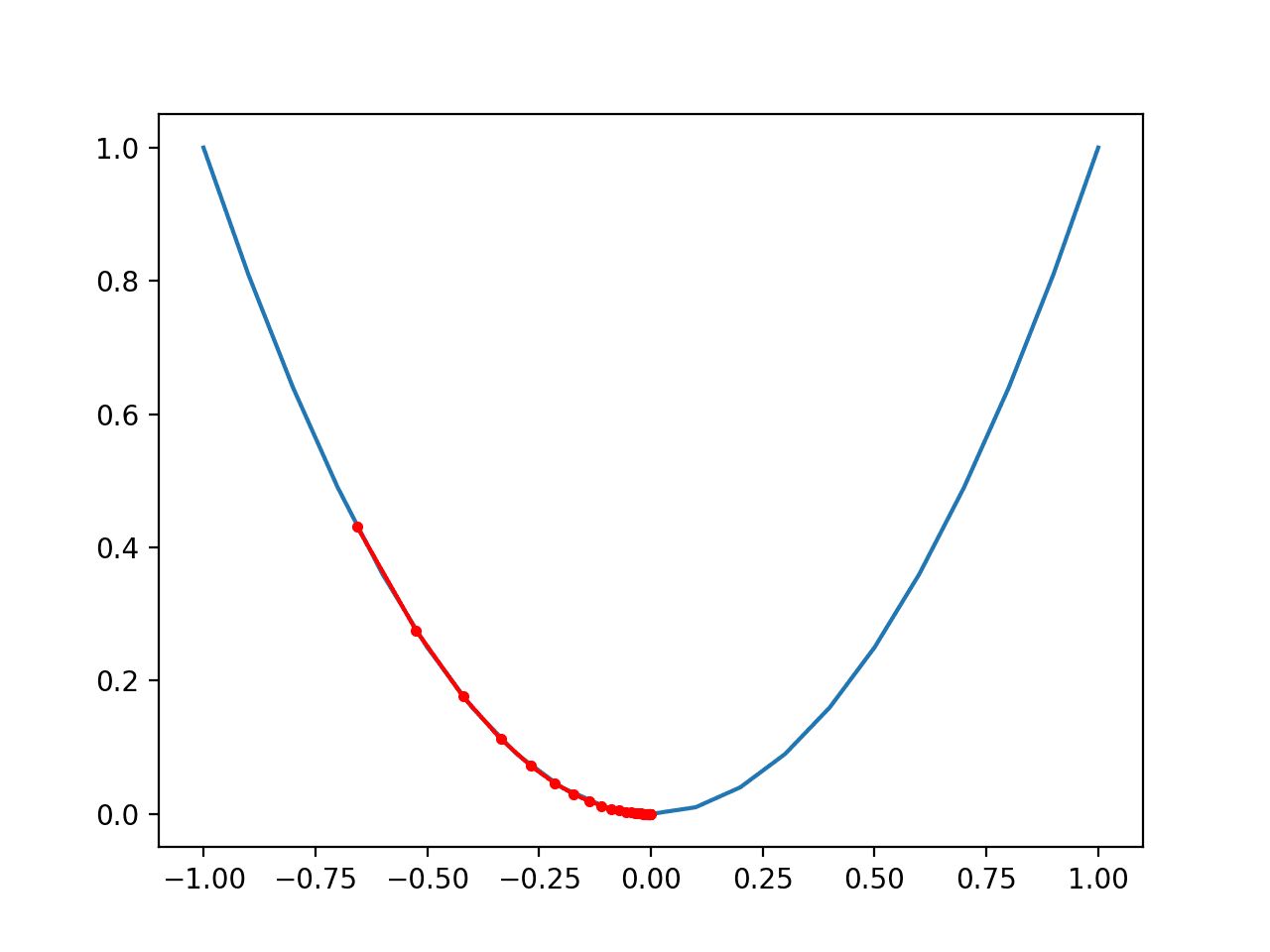
- Backward Propagation: The gradients of the loss function with respect to the model parameters are calculated. These gradients represent how the loss will change with respect to the parameters of the model.
- Parameter Update: The model parameters are updated using an optimization algorithm such as gradient descent. This involves adjusting the weights or parameters in the direction that minimizes the loss function.
- Iterative Training: The steps of forward propagation, loss calculation, backward propagation, and parameter update are repeated for multiple epochs or iterations to optimize the model’s performance.
During model training, hyperparameters such as learning rate, batch size, regularization techniques, and activation functions are fine-tuned to find the best configuration that minimizes the loss and maximizes the model’s performance.
It is important to monitor the training process and evaluate the model’s performance on the validation set at regular intervals to prevent overfitting or underfitting. Early stopping techniques can be employed to halt training when the model’s performance on the validation set starts to decline.
Once the model has been trained and its performance on the validation set is satisfactory, it can be further evaluated on a separate test set or deployed for real-world predictions.
Model training requires computational resources and time, especially for complex models or large datasets. It is crucial to have efficient processes and infrastructure in place to train models effectively.
By successfully training the model, you have created a model that has learned from the data and is capable of making accurate predictions or classifications. The trained model is now ready for evaluation and deployment.
Model Evaluation
Model evaluation is a critical step in the machine learning pipeline where the performance of the trained model is assessed to determine its effectiveness and reliability. It involves measuring the model’s ability to make accurate predictions or classifications on unseen data.
There are various evaluation metrics and techniques used to assess the performance of machine learning models. Some commonly used evaluation techniques include:
- Accuracy: This metric calculates the percentage of correct predictions made by the model. It is a simple and intuitive measure but can be misleading in the presence of class imbalance.
- Precision and Recall: Precision measures the proportion of correctly predicted positive instances out of the total predicted positive instances, while recall measures the proportion of correctly predicted positive instances out of the total actual positive instances. These metrics are particularly useful in binary classification problems.
- F1 Score: The F1 score is the harmonic mean of precision and recall. It provides a balanced measure that combines both precision and recall, making it particularly useful when there is an imbalance between the positive and negative classes.
- Confusion Matrix: A confusion matrix provides a detailed breakdown of the model’s predictions, showing the number of true positives, true negatives, false positives, and false negatives. It provides insights into the model’s performance for each class.
- ROC Curve and AUC: The receiver operating characteristic (ROC) curve plots the true positive rate against the false positive rate at various classification thresholds. The area under the ROC curve (AUC) provides a measure of the model’s ability to distinguish between different classes.
It is important to choose appropriate evaluation metrics based on the problem type and the desired outcome. The evaluation should provide insights into how well the model generalizes to unseen data and how reliable its predictions are.
In addition to evaluation metrics, it is crucial to perform appropriate statistical tests, such as cross-validation or bootstrapping, to ensure the reliability of the evaluation results.
Model evaluation should be an ongoing process as new data becomes available or as model updates are made. This ensures that the model’s performance remains consistent and reliable over time.
By thoroughly evaluating the model’s performance, you gain insights into its strengths, weaknesses, and limitations. This information can guide further improvements or adjustments to the model, leading to more accurate predictions or classifications.
Model Deployment
Model deployment is the final stage in the machine learning pipeline, where the trained model is deployed and integrated into a production environment to make real-time predictions or classifications. The goal of model deployment is to make the model accessible and usable by end-users or applications.
There are several considerations involved in the deployment of machine learning models:
- Scalability: The model should be able to handle a large volume of requests and provide real-time responses efficiently. Scalability can be achieved through various techniques, such as deploying the model on cloud-based platforms or using distributed computing.
- Integration: The model needs to be integrated with existing systems or applications to ensure seamless interaction. This may involve designing APIs or building custom interfaces to facilitate communication between the model and other components.
- Monitoring and Maintenance: After deployment, the deployed model should be monitored regularly to ensure its continued performance and effectiveness. Performance metrics, such as prediction accuracy or response time, should be tracked, and any potential issues or drifts in performance should be addressed promptly through model updates or retraining.
- Security and Privacy: Security measures should be implemented to protect sensitive data and prevent unauthorized access to the deployed model. Data encryption, access controls, and secure communication protocols are some common security practices in model deployment.
- Versioning and Rollback: It is essential to maintain version control of the deployed model to track changes and ensure reproducibility. This allows for easy rollback to a previous version if any issues arise.
Documentation and clear instructions should accompany the deployed model, providing information on its usage, input requirements, and output formats. This ensures that users or developers can effectively utilize the model without confusion or ambiguity.
Continuous improvement is crucial in model deployment. Regular feedback from end-users and monitoring outcomes can help identify areas for improvement or new features that may be necessary for better performance.
Model deployment brings the benefits of machine learning to real-world applications, allowing the model to make predictions or classifications in a production environment. A successful deployment contributes to optimized processes, better decision-making, and enhanced user experience.
Conclusion
Machine learning has revolutionized the way we analyze data and make predictions or decisions. The step-by-step process involved in machine learning, from data collection and preprocessing to model selection, training, evaluation, and deployment, is intricately designed to develop effective models with high accuracy and performance.
Starting with data collection, careful consideration is given to the quality, quantity, and relevance of the data. Preprocessing techniques are then employed to clean, transform, and prepare the data for analysis. Exploratory data analysis provides valuable insights into the data, guiding feature engineering and model selection decisions.
Feature engineering plays a crucial role in extracting meaningful information from the data and creating effective features for training the models. Model selection involves choosing the most suitable algorithm or model based on the problem requirements, data characteristics, and performance considerations. The selected model is then trained using the labeled data, utilizing techniques such as forward and backward propagation, and optimization algorithms.
Model evaluation is performed to assess the model’s performance and reliability using metrics such as accuracy, precision, recall, and AUC. Once the model proves to be effective, it is deployed in a production environment, ensuring scalability, integration, and continued monitoring and maintenance.
Throughout this process, it is crucial to incorporate domain knowledge, iterate, and fine-tune the models based on evaluation results and user feedback. Machine learning is an ongoing journey, with opportunities for continuous improvement and optimization.
In summary, the steps in machine learning allow us to harness the power of data, unleash insights, and make accurate predictions or decisions. By following these steps diligently and adapting them to the specific problem at hand, we can unlock the full potential of machine learning for various applications and domains.