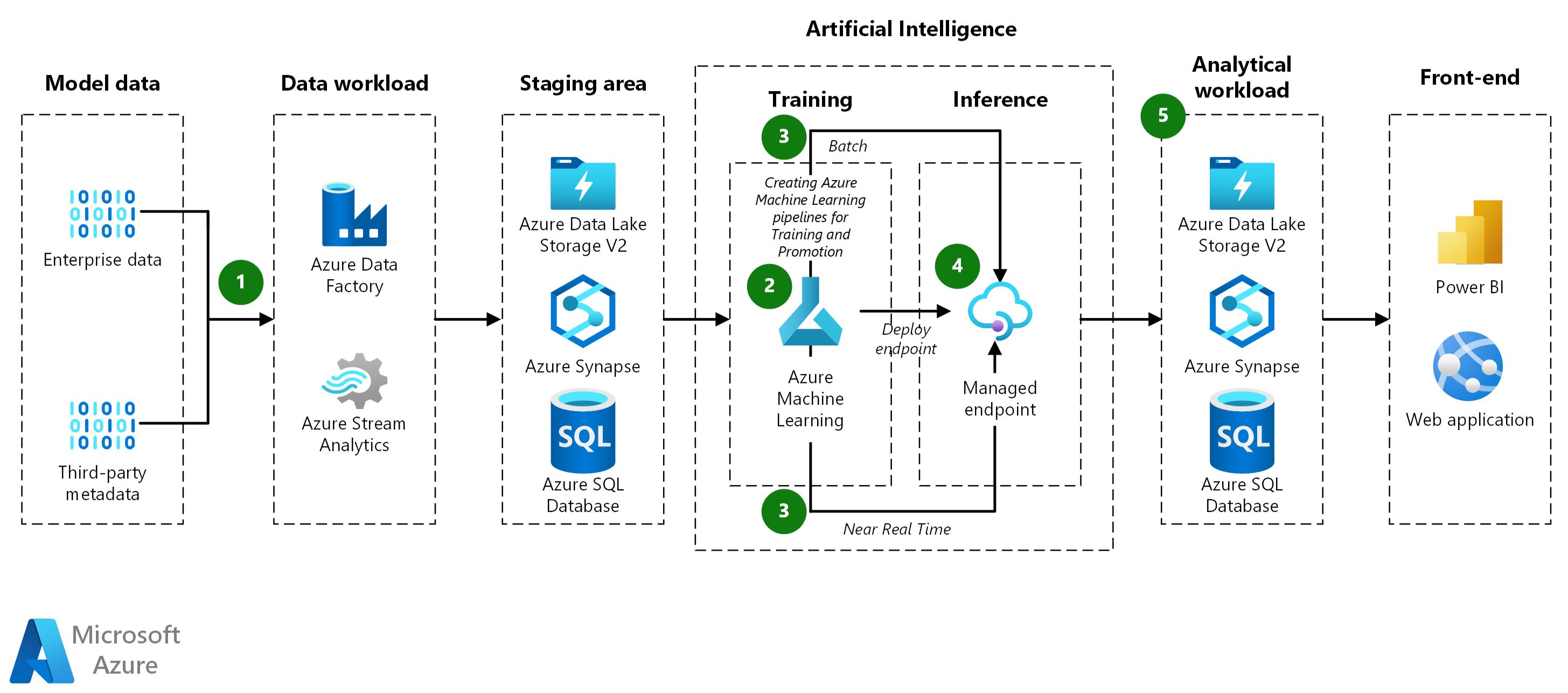
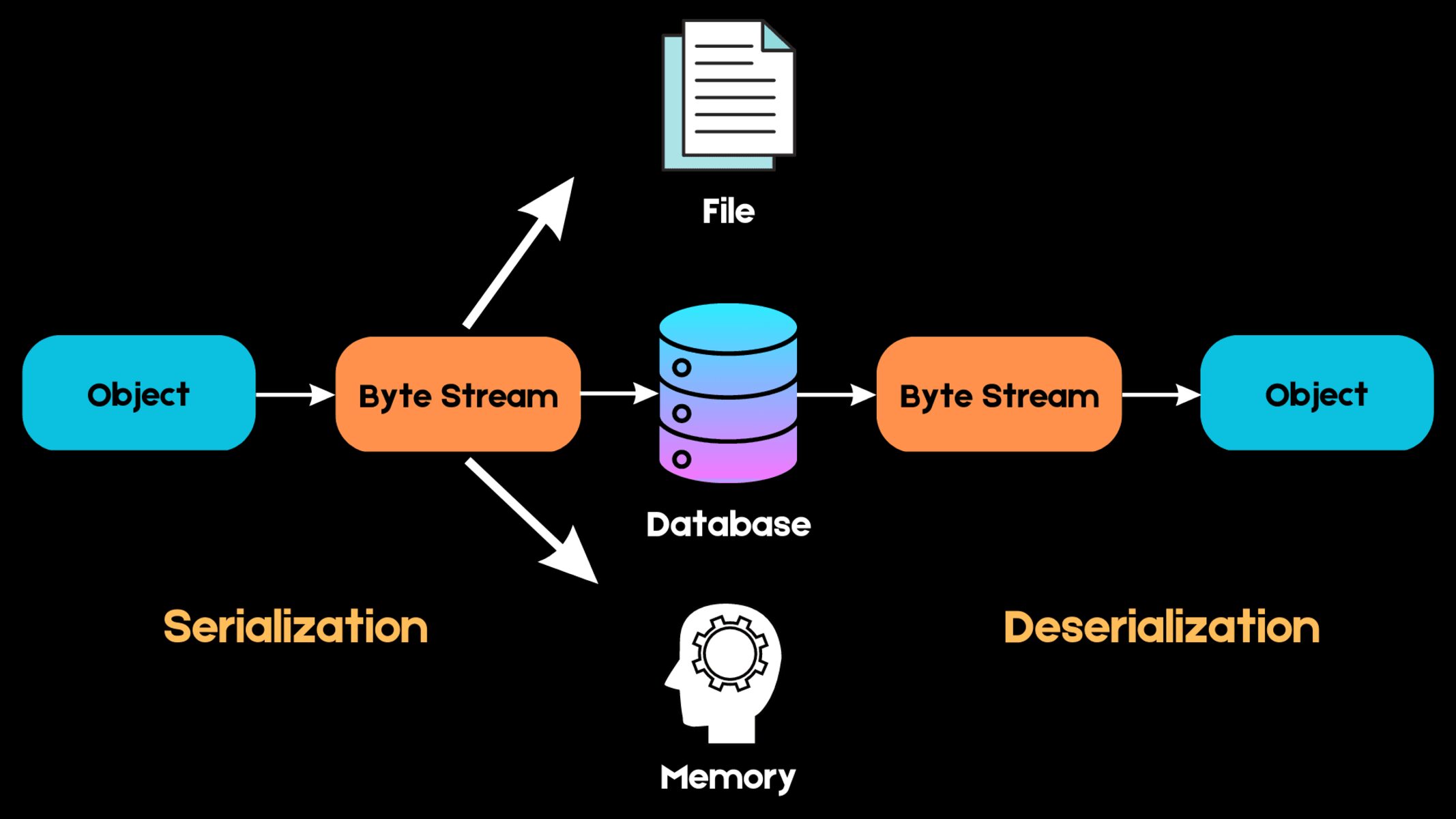
Introduction
Welcome to the world of machine learning! In this era of rapidly evolving technology, machine learning has emerged as a powerful tool that enables computers to learn from data and make intelligent decisions. The ability to process vast amounts of data and extract meaningful insights has opened up endless possibilities in various fields, including finance, healthcare, marketing, and more.
In this article, we will explore the process of coding machine learning algorithms. Whether you are a seasoned programmer or just starting your coding journey, this guide will provide you with the necessary steps to get started with machine learning coding.
Machine learning involves training a computer model to learn patterns and make predictions from data. It is an interdisciplinary field that combines statistics, mathematics, and computer science. By leveraging algorithms, machine learning allows us to uncover hidden patterns, build predictive models, and make data-driven decisions.
Before diving into the coding aspect, it is essential to have a basic understanding of programming languages like Python or R, as they are commonly used for machine learning tasks. Additionally, a solid grasp of key concepts such as variables, functions, loops, and conditional statements will be beneficial throughout your coding journey.
While the world of machine learning is vast and ever-expanding, we will focus on the coding aspect in this article. We will cover key steps involved in coding machine learning algorithms, from choosing the right algorithm to deploying the model into production.
Throughout this guide, we will emphasize practical implementation and provide examples to help you grasp the concepts better. By the end of this article, you will have a solid foundation in coding machine learning algorithms and be ready to embark on your own machine learning projects.
So, let’s dive in and explore the exciting world of coding machine learning algorithms!
Prerequisites
Before you start coding machine learning algorithms, it is important to ensure that you have a solid foundation in a few key areas. Gaining proficiency in these prerequisites will set you up for success in your machine learning coding journey.
1. Programming Language: Understanding a programming language is crucial for coding machine learning algorithms. Python and R are popular choices due to their extensive libraries and resources specifically designed for machine learning tasks. It is recommended to have a good understanding of at least one of these languages before diving into machine learning coding.
2. Mathematics and Statistics: Machine learning algorithms rely heavily on mathematical concepts and statistical analysis. A solid understanding of linear algebra, calculus, and probability theory will help you grasp the underlying algorithms and make informed decisions during the coding process.
3. Data Manipulation and Analysis: Machine learning requires working with large datasets. Familiarity with data manipulation and analysis libraries like Pandas is essential. These libraries allow you to clean, transform, and preprocess your dataset before feeding it to the machine learning algorithms.
4. Data Visualization: Visualizing the data is crucial for gaining insights and understanding patterns. Matplotlib and Seaborn are popular libraries for data visualization in Python, while ggplot2 is widely used in R. A good understanding of these libraries will help you create meaningful visualizations to support your machine learning coding project.
5. Machine Learning Concepts: Having a basic understanding of key concepts in machine learning, such as supervised learning, unsupervised learning, and model evaluation, is essential. Familiarize yourself with different types of machine learning algorithms and their applications to choose the right algorithm for your task.
While these prerequisites may seem overwhelming, keep in mind that machine learning is a journey that requires continuous learning and practice. Dedicate time to study and practice these areas, and with persistence, you will soon develop the skills needed to effectively code machine learning algorithms.
Now that we have covered the prerequisites, we can move on to the next step: choosing the right machine learning algorithm.
Choosing the Right Machine Learning Algorithm
Choosing the right machine learning algorithm is a critical step in the coding process. Different algorithms are designed to solve different types of problems, so selecting the appropriate one for your task is essential for successful model development. Here are some key considerations when choosing a machine learning algorithm:
1. Problem Type: Determine whether your problem is a classification, regression, or clustering problem. Classification algorithms are used when the output is a category or class, regression algorithms when the output is a continuous value, and clustering algorithms when you want to group similar data points together.
2. Dataset Size: Consider the size of your dataset. Some algorithms perform better with small datasets, while others are more suitable for large datasets. For example, decision trees and random forests work well with small to medium-sized datasets, while deep learning models excel with large datasets.
3. Interpretability vs. Accuracy: Consider whether interpretability or accuracy is more important for your task. Some algorithms, like logistic regression or decision trees, are easily interpretable, allowing you to understand the underlying logic. On the other hand, complex models like neural networks may provide higher accuracy but lack interpretability.
4. Model Complexity: Evaluate the complexity of the algorithm and your available computational resources. Some algorithms, such as linear regression or Naive Bayes, are relatively simple and computationally efficient. In contrast, complex algorithms like support vector machines or deep learning models can be more resource-intensive.
5. Data Quality and Features: Analyze the quality of your data and the relevance of the available features. Some algorithms may be more robust to missing data or outliers. Additionally, some algorithms work well with numerical data, while others are more suitable for categorical or text data. Consider the nature of your data and whether any preprocessing or feature engineering is required.
6. Algorithm Performance: Evaluate the performance of different algorithms on your specific problem. Consider metrics like accuracy, precision, recall, or F1 score to assess the performance of different algorithms. Experiment with multiple algorithms and compare their results to choose the one that best meets your requirements.
Remember, choosing the right algorithm may involve some trial and error, and it is not always a one-size-fits-all approach. Experimentation and iterative refinement are key to finding the algorithm that yields optimal results for your specific task.
Now that you have a better understanding of how to choose the right machine learning algorithm, we can move on to setting up the development environment.
Setting up the Development Environment
Before you can start coding machine learning algorithms, it is important to set up your development environment. A well-configured environment enables you to efficiently write, test, and debug your code. Here are the key steps to set up your machine learning development environment:
1. Install Python or R: If you haven’t already, install Python or R on your system. Both languages have extensive libraries and frameworks for machine learning. Python is particularly popular due to its simplicity and the availability of libraries like NumPy, Pandas, and Scikit-learn. R is also widely used, especially in the field of statistics.
2. Choose an Integrated Development Environment (IDE): An IDE provides a user-friendly interface for writing, running, and debugging your code. Popular choices for Python include PyCharm, Spyder, and Jupyter Notebook. For R, RStudio is a highly recommended IDE. Pick the one that suits your preferences and install it on your system.
3. Set up the Required Libraries: Machine learning algorithms rely on various libraries and frameworks. Use package managers, such as pip for Python or CRAN for R, to install the required libraries and their dependencies. Some essential libraries for Python include NumPy, Pandas, Matplotlib, and Scikit-learn. For R users, install libraries like dplyr, ggplot2, and caret.
4. Virtual Environments (Optional): Consider using virtual environments to manage project dependencies. Virtual environments create isolated Python or R environments, allowing you to have different sets of libraries and versions for each project. This helps prevent conflicts between project requirements. Tools like virtualenv for Python and renv for R are available to set up and manage virtual environments.
5. Understand the Documentation: Familiarize yourself with the documentation and resources available for the libraries and frameworks you will be using. Understanding the documentation will help you leverage the full potential of the libraries and troubleshoot any issues that may arise during coding.
6. Test the Setup: Once you have installed the necessary tools and libraries, it’s a good practice to test your setup. Write a simple “Hello World” program or run a sample machine learning script to verify that everything is working correctly. This will ensure a smooth coding experience moving forward.
By following these steps and setting up your development environment correctly, you will be ready to start coding machine learning algorithms with ease and efficiency.
Next, we will move on to the crucial step of collecting and preparing the data for your machine learning project.
Collecting and Preparing the Data
In machine learning, data is the fuel that powers the algorithm. To create an effective machine learning model, you need to collect and prepare relevant data. This step involves gathering data from various sources, cleaning and preprocessing it, and ensuring its quality and suitability for the machine learning task at hand. Here are the key steps in collecting and preparing the data:
1. Define the Problem: Clearly define the problem you are trying to solve. Determine the target variable (the variable you want the model to predict) and the features (the variables that will be used to make predictions). Having a clear problem definition will guide you in the data collection process.
2. Identify Data Sources: Identify the sources from which you will collect the data. It can include databases, APIs, online repositories, or data generated by sensors or IoT devices. Ensure that the data sources align with your problem statement and have the necessary permissions and rights to access the data.
3. Data Acquisition: Collect the data from the identified sources. This may involve scraping websites, querying databases, or accessing APIs. Ensure that the data collected is representative of the problem you are trying to solve and captures a wide range of scenarios and possibilities.
4. Data Cleaning: Clean the data to remove any inconsistencies, errors, or missing values. This process may involve removing duplicate records, handling missing data through imputation or deletion, and standardizing data formats. Cleaning the data is crucial to ensure accurate and reliable results from your machine learning model.
5. Data Preprocessing: Preprocess the data to transform it into a suitable format for the machine learning algorithm. This step may involve data normalization, feature scaling, encoding categorical variables, or handling outliers. Preprocessing prepares the data for modeling and enhances the performance of the machine learning algorithm.
6. Data Splitting: Divide the dataset into training and testing sets. The training set is used to train the machine learning model, while the testing set evaluates the trained model’s performance. Splitting the data helps assess the model’s ability to generalize to unseen data and avoid overfitting.
Once you have collected and prepared the data, you are ready to move on to the next step: creating and training the machine learning model. Taking the time to collect and prepare quality data ensures the accuracy and reliability of your model’s predictions.
Splitting the Data into Training and Testing Sets
When building a machine learning model, it is important to divide your dataset into separate training and testing sets. This step, known as data splitting, allows us to evaluate the performance of the model on unseen data and assess its ability to generalize. Here’s how to split the data into training and testing sets:
1. Purpose of Data Splitting: The main purpose of data splitting is to assess the model’s performance on unseen data. By training the model on one set of data and evaluating it on another, we can estimate how well the model will perform in real-world scenarios.
2. Training Set: The training set is used to train the machine learning model. It contains a significant portion of the dataset and is used to learn the underlying patterns and relationships between the features and the target variable.
3. Testing Set: The testing set is used to evaluate the performance of the trained model. It contains data that the model has not seen during the training phase. By comparing the predicted outputs with the actual outputs, we can assess the model’s accuracy and measure its performance.
4. Size of the Split: The appropriate size of the split depends on the size of the dataset. A common practice is to allocate around 70% to 80% of the data for training and the remaining 20% to 30% for testing. However, in cases where the dataset is limited, a larger portion may be reserved for training to ensure sufficient training data is available.
5. Randomness in Splitting: It is important to randomly split the data to ensure a representative distribution of samples in both the training and testing sets. Randomness helps prevent any bias that may arise from an ordered or grouped dataset.
6. Repeatability: To ensure consistency and reproducibility, set a random seed before dividing the data. This ensures that the data splitting process remains the same each time you run the code.
By splitting the data into training and testing sets, you can evaluate the performance of your machine learning model objectively and assess its ability to generalize. This step is crucial in ensuring that the model performs accurately and reliably in real-world scenarios.
The next step is to create and train the machine learning model using the training set. We will explore this step in detail in the upcoming section.
Creating and Training the Machine Learning Model
Once you have collected and prepared your data, the next step in coding machine learning algorithms is to create and train the model. This step involves selecting the appropriate algorithm for your task, configuring its parameters, and training the model on the training data. Here are the key steps to creating and training a machine learning model:
1. Selecting the Algorithm: Based on your problem type and requirements, choose an algorithm that best suits your task. Common algorithms include decision trees, support vector machines, random forests, and neural networks. Consider the strengths and weaknesses of each algorithm and select the one that aligns with your project goals.
2. Model Configuration: Configure the parameters of the selected algorithm to fine-tune its behavior. These parameters control various aspects of the model, such as the learning rate, regularization strength, or the number of hidden layers. Experimentation and optimization of these parameters may be required to achieve the best performance.
3. Train the Model: Use the training data to train the model. During the training process, the model learns the underlying patterns and relationships between the input features and the target variable. It adjusts its internal parameters to minimize the error and make accurate predictions. The training process involves multiple iterations, known as epochs, where the model makes predictions, compares them to the actual outputs, and updates its parameters accordingly.
4. Evaluation Metrics: Evaluate the performance of the trained model using appropriate evaluation metrics. Common metrics include accuracy, precision, recall, and F1 score, depending on the problem type. These metrics provide insights into the model’s predictive performance and its ability to generalize to unseen data.
5. Model Validation: Validate the model’s performance on the testing set. This step assesses the model’s ability to make accurate predictions on unseen data. By comparing the predicted outputs with the actual outputs from the testing set, you can measure the model’s performance and identify any potential issues, such as overfitting or underfitting.
6. Iteration and Improvement: Based on the evaluation metrics and validation results, iteratively fine-tune the model to improve its performance. This may involve adjusting the algorithm parameters, adding more training data, or trying different algorithms altogether. The goal is to create a model that performs well on unseen data and generalizes to real-world scenarios.
By following these steps, you can create and train a machine learning model that accurately predicts outcomes or makes intelligent decisions based on the input data. Remember that experimentation and continuous improvement are key to developing robust and effective machine learning models.
In the next section, we will explore how to evaluate the model’s performance and make necessary adjustments to optimize its effectiveness.
Evaluating the Model’s Performance
Once you have trained a machine learning model, it is crucial to evaluate its performance to ensure its effectiveness and reliability. Evaluating the model allows you to assess how well it performs on unseen data and whether it meets the desired level of accuracy. Here are the key steps in evaluating the model’s performance:
1. Evaluation Metrics: Select appropriate evaluation metrics based on the problem type and your project goals. Common evaluation metrics for classification tasks include accuracy, precision, recall, and F1 score. For regression tasks, metrics like mean squared error (MSE) or root mean squared error (RMSE) can be used. These metrics provide quantifiable measures of how well the model is performing.
2. Validation Set: Use a separate validation dataset to evaluate the model’s performance. This dataset should be different from both the training and testing datasets. By evaluating the model on unseen data, you can obtain a more realistic assessment of its predictive abilities.
3. Performance Visualization: Visualize the model’s performance using appropriate graphs or plots. For classification tasks, you can create a confusion matrix or plot a receiver operating characteristic (ROC) curve to analyze the model’s true positive and false positive rates. For regression tasks, you can plot the predicted values against the actual values to assess the model’s accuracy.
4. Cross-Validation: Perform cross-validation to further validate the model’s performance. Cross-validation involves splitting the dataset into multiple subsets (folds) and training and evaluating the model on different combinations of these subsets. It helps assess the model’s stability and robustness by obtaining average performance across different splits of the data.
5. Model Comparison: Compare the performance of your model with other models or baselines. This allows you to determine if your model outperforms existing methods or if further improvements are required. Model comparison helps you make informed decisions about the effectiveness and suitability of your machine learning model.
6. Iterative Improvement: Based on the evaluation results, make necessary adjustments to improve the model’s performance. This may involve tweaking the model’s hyperparameters, collecting more data, or even considering a different algorithm altogether. Continuously evaluate and refine the model until it meets your desired level of performance.
By thoroughly evaluating the model’s performance, you can determine its effectiveness and identify areas for improvement. Through iterative refinement, you can optimize the model to achieve accurate predictions or decision-making capabilities for your specific task.
Next, we will explore the process of fine-tuning the model to optimize its performance further.
Fine-Tuning the Model
Fine-tuning is an essential step in optimizing the performance of your machine learning model. It involves adjusting various aspects, such as hyperparameters and training techniques, to achieve better accuracy and generalization. Fine-tuning enables you to extract the maximum potential from your model. Here are the key steps in the fine-tuning process:
1. Hyperparameter Tuning: Hyperparameters are parameters that are not learned directly from the data but define the behavior and performance of the model. Examples include the learning rate, regularization strength, or the number of hidden layers in a neural network. Use techniques like grid search or random search to systematically explore different combinations of hyperparameters and identify the best configuration for your model.
2. Regularization Techniques: Regularization techniques help prevent overfitting, where the model performs well on the training data but fails to generalize to new, unseen data. Techniques like L1 or L2 regularization, dropout, or early stopping can be applied to regularize the model and improve its ability to generalize to unseen data.
3. Training Strategies: Experiment with different training strategies to enhance the model’s performance. Techniques like batch normalization, data augmentation, or transfer learning can be utilized to boost the model’s accuracy and efficiency. These strategies leverage prior knowledge or adjust the training process to enhance the model’s ability to capture complex patterns and make accurate predictions.
4. Ensemble Methods: Consider using ensemble methods to improve the model’s performance. Ensemble methods combine multiple models to make predictions collectively, often achieving better results than individual models. Techniques like bagging, boosting, or stacking can be employed to build powerful ensembles and enhance the performance of your model.
5. Cross-Validation and Performance Evaluation: Re-evaluate the model’s performance after making adjustments. Use cross-validation to assess the model’s stability and validate its performance on unseen data. Compare the newly fine-tuned model’s metrics with previous evaluations to measure the improvement achieved through the fine-tuning process.
6. Iterative Refinement: Fine-tuning is an iterative process. Continuously repeat the steps mentioned above, making gradual adjustments and evaluating the model’s performance until you achieve the desired level of accuracy and generalization.
By fine-tuning the model, you can unlock its full potential and optimize its performance. Adjusting hyperparameters, employing regularization techniques, exploring different training strategies, and utilizing ensemble methods can greatly enhance the model’s accuracy and ability to generalize to new data.
Next, we will explore the crucial step of deploying the trained model into a production environment.
Deploying the Model into Production
Deploying your trained machine learning model into a production environment is the final step in bringing your solution to life. It involves making your model accessible and usable by end-users or integrating it into existing systems. Here are the key steps for deploying your machine learning model into production:
1. Model Exporting: Save or export your trained model in a format that can be easily loaded and used by your production environment. Common formats include PMML (Predictive Model Markup Language) or serialized models in frameworks like TensorFlow, PyTorch, or scikit-learn.
2. Model Integration: Integrate your model into the existing software or system where it will be used. This integration can vary based on the technology stack and requirements of your production environment. Ensure compatibility with the required programming languages, libraries, or APIs used in the target system.
3. APIs or Microservices: Expose your model through APIs or microservices to enable easy and controlled access. This allows other applications or systems to make requests to your model and receive predictions in return. Well-defined APIs provide a standardized interface for interacting with the model and enable seamless integration with various platforms.
4. Scalability and Performance: Optimize your model’s deployment for scalability and performance. Consider factors such as concurrent user requests, response time requirements, and resource consumption. Techniques like model caching, parallel processing, or distributed computing can be employed to achieve improved scalability and performance.
5. Monitoring and Maintenance: Implement monitoring mechanisms to track the performance and behavior of your deployed model. Continuously monitor for issues such as model drift, data quality changes, or runtime errors. Regularly update and retrain the model using new data to maintain its accuracy and relevance in the production environment.
6. Security and Privacy: Ensure the security and privacy of your deployed model and the data it processes. Implement measures like authentication, encryption, and access controls to protect against unauthorized access or data breaches. Comply with data protection regulations and industry best practices to maintain privacy and security standards.
By carefully deploying your machine learning model into a production environment, you can make it accessible and available for real-world use. Following best practices for integration, scalability, performance, monitoring, and security ensures the reliability and effectiveness of your model in production settings.
With the model successfully deployed, you can now leverage its capabilities to make data-driven decisions, automate processes, or deliver valuable insights to end-users.
Conclusion
Coding machine learning algorithms requires a combination of technical expertise, domain knowledge, and a systematic approach. Throughout this article, we have explored the key steps involved in coding machine learning algorithms, from understanding the prerequisites to deploying the trained model into production.
We started by discussing the prerequisites, including proficiency in programming languages, understanding of mathematics and statistics, and familiarity with data manipulation and analysis. These prerequisites lay the foundation for successfully coding machine learning algorithms.
We then delved into the process of choosing the right machine learning algorithm, considering factors such as problem type, dataset size, complexity, and interpretability. Selecting the appropriate algorithm is crucial for achieving accurate and reliable results.
We explored setting up the development environment, including installing the required programming languages, choosing an IDE, and configuring the necessary libraries. A well-configured environment enhances productivity and provides a smooth coding experience.
Collecting and preparing the data is a critical step in the machine learning pipeline. We discussed the importance of defining the problem, identifying data sources, cleaning and preprocessing the data, and splitting it into training and testing sets. Clean and relevant data is essential for training and evaluating machine learning models.
Creating and training the machine learning model involves selecting the algorithm, configuring its parameters, and training it on the training data. We emphasized the significance of evaluating the model’s performance using appropriate metrics, validation sets, and visualization techniques.
We explored the process of fine-tuning the model to optimize its performance by adjusting hyperparameters, applying regularization techniques, experimenting with training strategies, and utilizing ensemble methods. Fine-tuning helps unlock the model’s potential and achieve higher accuracy and generalization.
Finally, we discussed deploying the trained model into production. This involves exporting the model, integrating it into the production environment, and ensuring scalability, performance, monitoring, and security.
By following these steps and continuously iterating and improving, you can effectively code machine learning algorithms and harness the power of data to make informed decisions and create innovative solutions in various domains.
So, armed with this knowledge, go forth and explore the fascinating world of machine learning coding, unleash your creativity, and contribute to the exciting advancements in this dynamic field.