Introduction
Welcome to the fascinating world of machine learning! In today’s digital age, the ability to harness the power of data and extract meaningful insights has become indispensable. Machine learning, a subfield of artificial intelligence, plays a pivotal role in this process by enabling computers to learn and make predictions or decisions without explicit programming.
With the exponential growth of data and the need for accurate and efficient analysis, machine learning has gained significant popularity across various industries. From predicting customer behavior in e-commerce to analyzing medical data for disease diagnosis, machine learning offers endless possibilities.
But how exactly do we leverage machine learning algorithms to achieve these results? This is where the concept of a machine learning pipeline comes into play. A machine learning pipeline is a systematic and efficient process that encompasses all the necessary steps involved in building, training, evaluating, and deploying a machine learning model.
Think of a machine learning pipeline as a well-organized assembly line, where raw data is transformed into valuable insights. It serves as a roadmap, guiding us through the complex journey of turning data into actionable intelligence.
In this article, we will dive deeper into the components of a machine learning pipeline, the challenges it poses, and the importance of each step in the process. By understanding the intricacies of a machine learning pipeline, you will be well-equipped to design and implement efficient solutions tailored to your specific business needs.
So, whether you are a data scientist, a software engineer, or simply interested in harnessing the power of machine learning, let’s embark on this exciting journey together and unravel the mysteries of the machine learning pipeline.
What is Machine Learning?
Machine learning is a subset of artificial intelligence that focuses on enabling computers to learn from data and make predictions or decisions without being explicitly programmed. It is based on the idea that computers can identify patterns and learn from experiences, just like humans.
At its core, machine learning involves developing algorithms that can analyze and interpret massive amounts of data to identify trends, relationships, and patterns. These algorithms use statistical techniques to make predictions or take actions based on the patterns they discover.
There are three broad types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, the machine learning model is trained on labeled data, where the desired output is known. The model learns from this labeled data to make predictions on new, unseen data. For example, a supervised learning model can be trained on a dataset of emails labeled as spam or non-spam, and it can then predict whether new emails are spam or not.
In unsupervised learning, the model is not provided with any labeled data. Instead, it learns from the inherent structure and patterns within the data. Unsupervised learning is often used for tasks such as clustering, where the goal is to group similar data points together.
Reinforcement learning is a type of machine learning used for decision-making and control problems. The model learns by interacting with an environment and receiving feedback in the form of rewards or penalties. The goal is for the model to learn the optimal actions to maximize the rewards over time.
Machine learning algorithms can be applied to various domains and problems, such as image recognition, natural language processing, fraud detection, recommendation systems, and many more. The possibilities are endless, and machine learning continues to revolutionize industries and drive innovation.
It’s important to note that machine learning is not a one-size-fits-all solution. The choice of algorithms, data preprocessing techniques, and model evaluation methods heavily depends on the specific problem and the available data. As a result, machine learning requires a combination of domain expertise, statistical knowledge, and programming skills to effectively utilize its potential.
In the next sections, we will explore the different components of a machine learning pipeline and understand how they contribute to the overall process of building and deploying machine learning models.
What is a Machine Learning Pipeline?
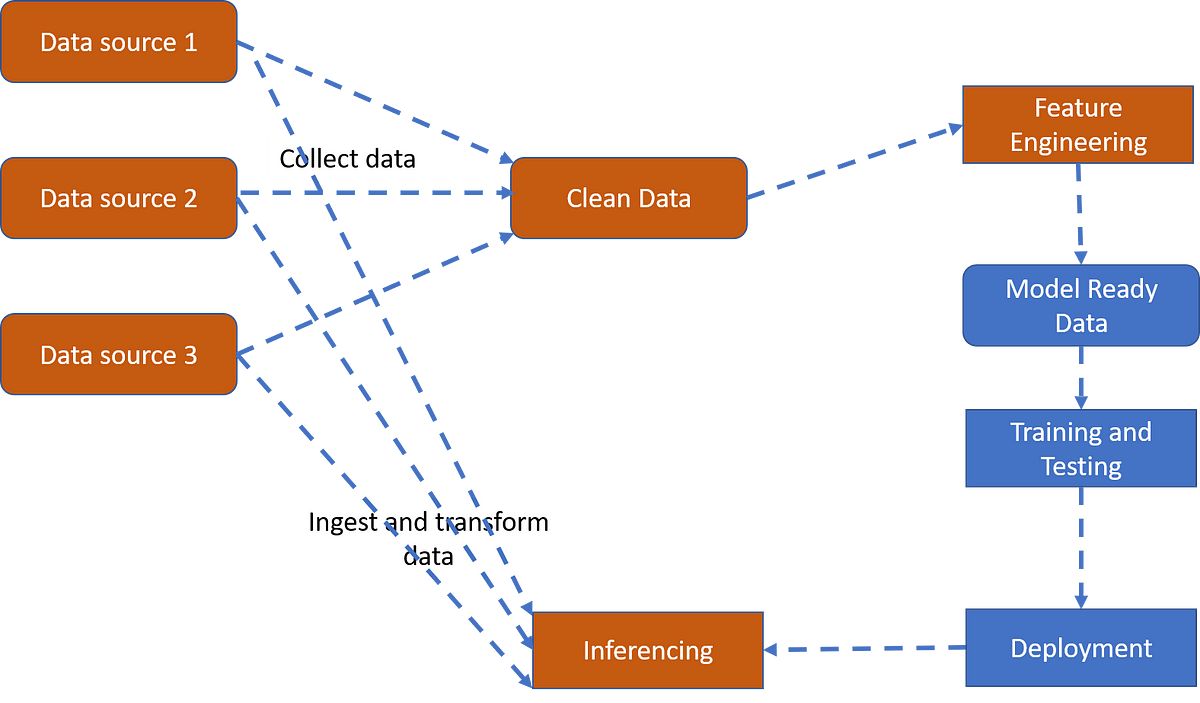
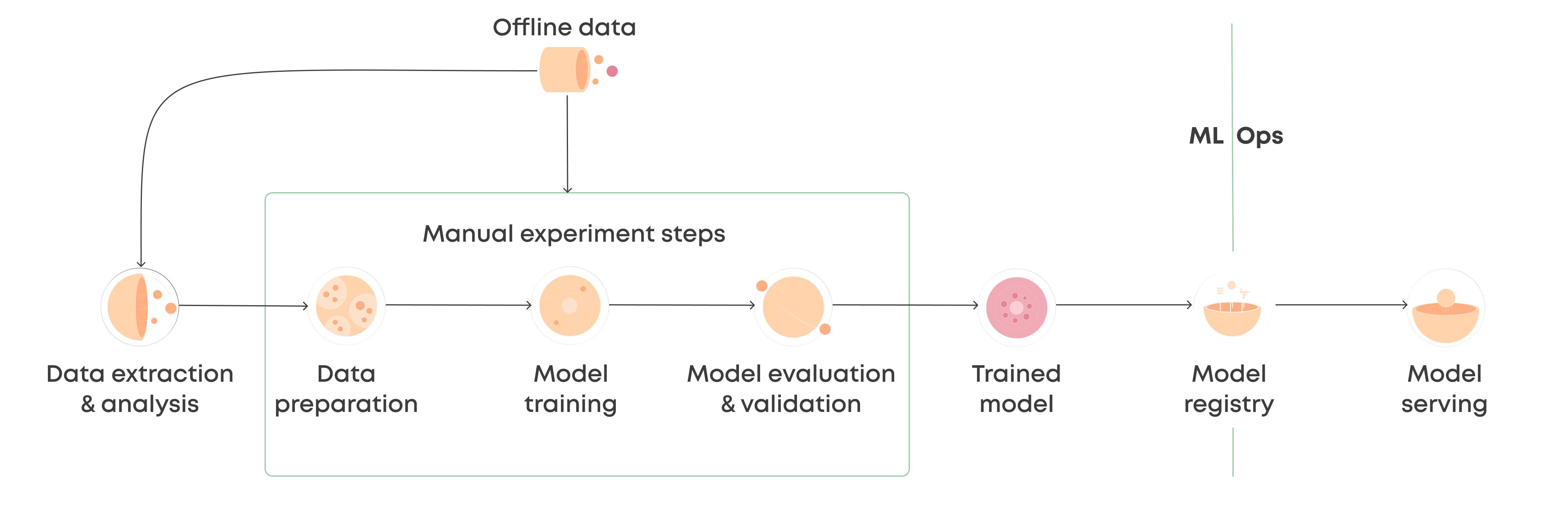
A machine learning pipeline is a series of interconnected steps and processes that collectively contribute to the development, training, evaluation, and deployment of a machine learning model. It provides a systematic and organized approach to handling data, transforming it, and building a predictive model that can be easily deployed for real-world applications.
Think of a machine learning pipeline as a well-defined roadmap that guides you through the entire machine learning process, from data collection and preprocessing to model deployment and monitoring. Each step in the pipeline has a specific purpose and plays a crucial role in ensuring the accuracy, efficiency, and reliability of the final model.
By leveraging a machine learning pipeline, you can streamline the workflow, improve reproducibility, and reduce errors throughout the machine learning lifecycle.
One of the key advantages of using a machine learning pipeline is that it promotes modularity and reusability. The pipeline can be designed as a series of modular and independent steps, allowing you to swap, modify, or add new components as needed. This flexibility enables iterative development and experimentation, ultimately leading to improved models and results.
Moreover, a machine learning pipeline increases efficiency by automating repetitive and time-consuming tasks. It ensures consistency in data preprocessing, feature extraction, and model training, eliminating the need for manual intervention and reducing human error.
Furthermore, a machine learning pipeline enhances collaboration and reproducibility. By documenting and sharing the pipeline, multiple individuals or teams can work on different stages of the process simultaneously. It also enables easier model retraining and updates as new data becomes available.
Overall, a machine learning pipeline brings structure, organization, and efficiency to the machine learning process. It serves as a framework for managing complex data flows, transforming raw data into actionable insights, and ensuring the scalability and reliability of machine learning models.
In the next sections, we will explore the different components of a machine learning pipeline in detail, understanding their functions and importance in building successful machine learning models.
Components of a Machine Learning Pipeline
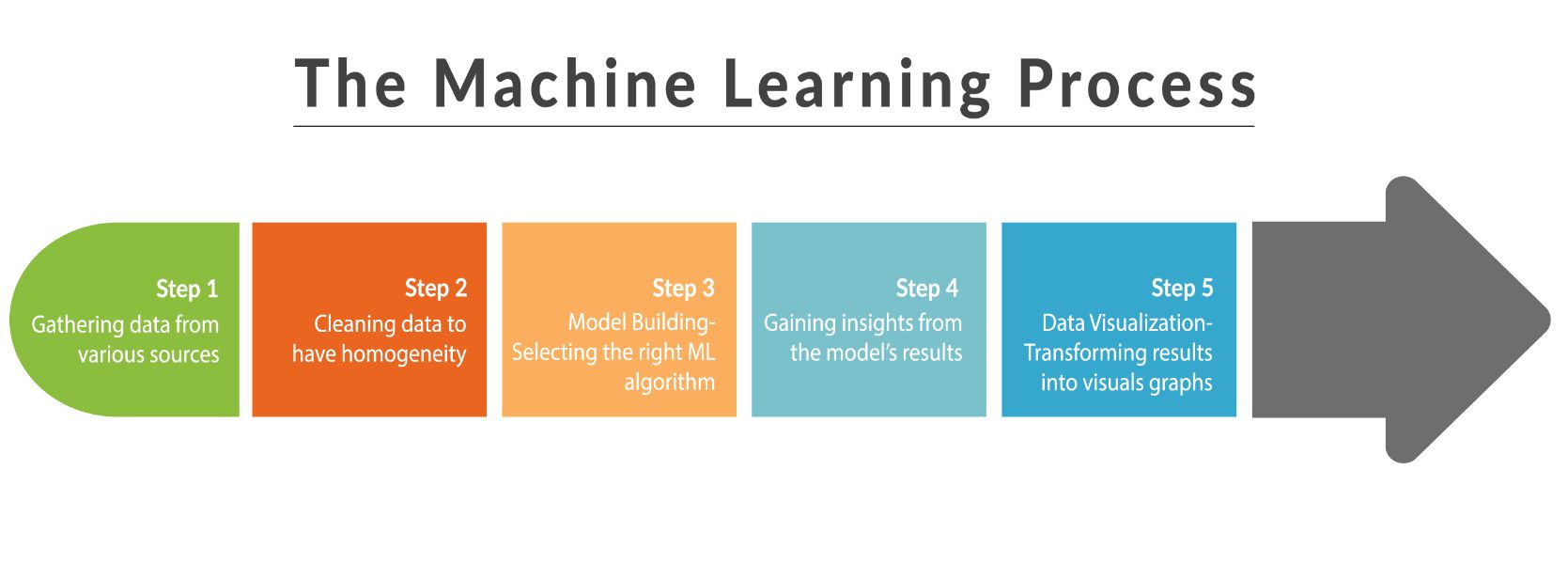
A machine learning pipeline consists of several interconnected components that work together to transform raw data into a trained and deployable machine learning model. Each component serves a specific purpose in the pipeline and contributes to the final outcome. Let’s take a closer look at the key components of a machine learning pipeline:
Data Collection and Preprocessing
Data collection is the first step in the machine learning pipeline. It involves gathering the relevant data required for model training and evaluation. This data can come from various sources, such as databases, APIs, or CSV files. Once the data is collected, it needs to be preprocessed. This involves tasks like cleaning the data, handling missing values, removing outliers, and normalizing or scaling the features. Data preprocessing ensures that the data is in a suitable format for further analysis and model training.
Feature Selection and Engineering
Feature selection and engineering is the process of choosing the most relevant and informative features from the dataset. It involves analyzing the correlation between different features, identifying redundant or irrelevant features, and selecting the subset of features that have the most impact on the target variable. Additionally, feature engineering involves creating new features derived from the existing ones, which can enhance the predictive power of the model.
Model Training and Evaluation
In this component, machine learning algorithms are applied to the preprocessed and feature-engineered data to train the model. The model is trained on the labeled data, learning the patterns and relationships between the input features and the target variable. Once the model is trained, it is evaluated using suitable evaluation metrics to assess its performance. This helps in determining the accuracy, precision, recall, and other performance metrics of the model on unseen data.
Model Deployment and Monitoring
Once the model is trained and evaluated, it needs to be deployed for real-world applications. This involves integrating the model into a production environment, where it can make predictions or decisions based on new data. The deployment process may include building APIs, creating interfaces, or deploying the model on cloud platforms. Additionally, it is important to establish a monitoring system to track the model’s performance over time, detect any anomalies or drift in data, and ensure that the model continues to deliver accurate and reliable results.
These components form the core of a machine learning pipeline and provide the necessary framework to transform data into actionable insights. However, it is important to note that the pipeline can be tailored and customized based on the specific requirements of the problem and the available resources.
In the next sections, we will delve deeper into each component, exploring the techniques, challenges, and best practices associated with them.
Data Collection and Preprocessing
Data collection and preprocessing are essential steps in the machine learning pipeline. They involve gathering relevant data and preparing it for analysis and model training. Let’s explore each of these components in detail:
Data Collection
Data collection is the process of gathering the required data to train and evaluate a machine learning model. The data can come from various sources, such as databases, APIs, web scraping, or even manual data entry. It is crucial to ensure that the collected data is representative, unbiased, and relevant to the problem at hand. Additionally, it is important to consider factors like data privacy, compliance with regulations, and the quality of the collected data.
Data Preprocessing
Data preprocessing involves transforming the raw data into a format that can be readily used for analysis and model training. This step plays a vital role in ensuring the quality and accuracy of the final model. Here are some common techniques used in data preprocessing:
- Data Cleaning: This involves removing any irrelevant or noisy data, handling missing values, and dealing with outliers. Missing values can be imputed using techniques like mean imputation, median imputation, or predictive imputation. Outliers can be detected and treated using statistical methods like the z-score or interquartile range.
- Feature Scaling: Scaling the features to a common range can improve the performance of many machine learning algorithms. Common scaling techniques include standardization (mean=0, variance=1) and normalization (scaling to a specific range, e.g., 0-1).
- Feature Encoding: Categorical variables need to be encoded into numerical values so that the machine learning algorithms can process them. This can be done through techniques like one-hot encoding, label encoding, or target encoding.
- Dimensionality Reduction: If the dataset has a large number of features, dimensionality reduction techniques like principal component analysis (PCA) or feature extraction methods can be applied to reduce the complexity and computational requirements of the model.
Data preprocessing is an iterative process that may require different techniques for different datasets. It is important to analyze the data, understand its characteristics, and select the appropriate preprocessing techniques based on the specific requirements of the problem.
By collecting and preprocessing the data effectively, you can ensure that the subsequent steps in the machine learning pipeline are built on a strong foundation. The quality and cleanliness of the data significantly impact the accuracy, reliability, and performance of the final machine learning model.
In the next sections, we will explore the techniques, challenges, and best practices associated with feature selection and engineering, which are crucial steps in the machine learning pipeline.
Feature Selection and Engineering
Feature selection and engineering are crucial steps in the machine learning pipeline that involve selecting the most relevant features from the dataset and creating new features that enhance the predictive power of the model. Let’s delve into these components in more detail:
Feature Selection
Feature selection is the process of choosing a subset of features from the dataset that have the most impact on the target variable. By selecting the most informative features, we can improve the accuracy of the model, reduce overfitting, and enhance its interpretability. There are several techniques for feature selection:
- Univariate Selection: This technique involves selecting features based on their individual performance, using statistical tests like chi-square, ANOVA, or correlation analysis.
- Recursive Feature Elimination (RFE): RFE recursively eliminates the least important features based on the model’s performance and importance weights assigned to each feature.
- Feature Importance: Some machine learning algorithms, such as decision trees and random forests, provide a measure of feature importance. Features with higher importance values are selected for the model.
It is important to consider domain knowledge and interpretability when selecting features. In some cases, domain experts may have insights into specific features that are highly relevant to the problem. Additionally, carefully considering the trade-off between model complexity and performance can help in choosing the ideal set of features.
Feature Engineering
Feature engineering involves creating new features or transforming existing features to improve the model’s performance. This step requires domain knowledge and creativity to extract valuable information from the available data. Some common techniques used in feature engineering include:
- Polynomial Features: Transforming the features by adding interaction terms or polynomial terms can capture non-linear relationships in the data.
- Scaling and Normalization: Scaling features to a specific range or normalizing them can help in comparison and convergence of certain machine learning algorithms.
- Encoding Categorical Variables: Converting categorical variables into numerical representations, such as one-hot encoding or target encoding, allows the model to process them effectively.
- Creating Domain-Specific Features: Leveraging domain knowledge to create features that encapsulate specific characteristics or patterns related to the problem can significantly improve the model’s performance.
Feature engineering requires careful experimentation and evaluation of the impact of each engineered feature on the model’s performance. It is an iterative process that involves testing various feature combinations and transformations to find the optimal set of features.
By selecting the most relevant features and engineering new ones, you can extract maximum information from the dataset and improve the model’s predictive capabilities. In the next sections, we will explore the process of model training and evaluation, which forms the core of the machine learning pipeline.
Model Training and Evaluation
Model training and evaluation are critical components of the machine learning pipeline that involve training the model on the preprocessed data and assessing its performance. Let’s delve into these components in more detail:
Model Training
Model training is the process of using the preprocessed data to build a machine learning model. Various algorithms, such as linear regression, decision trees, support vector machines, or neural networks, can be employed to train the model. The goal is to find the best set of parameters or weights that minimize the error and maximize the accuracy of the model on the given training data.
During the training phase, the model learns the patterns and relationships between the input features and the target variable. This is achieved through an iterative optimization process, where the model adjusts its parameters based on the errors or losses computed during each iteration. The training process continues until the model reaches a point where further iterations do not significantly improve its performance.
It is important to split the available data into training and validation sets to evaluate the model’s performance during training. This prevents overfitting, where the model memorizes the training data without generalizing well to unseen data. Cross-validation techniques, such as k-fold cross-validation, can also be employed to ensure a robust assessment of the model’s performance.
Model Evaluation
Once the model is trained, it needs to be evaluated to assess its performance on unseen data. This involves using evaluation metrics that measure how well the model predicts the target variable. The choice of evaluation metrics depends on the problem at hand, but common ones include accuracy, precision, recall, F1 score, and area under the receiver operating characteristic (ROC) curve.
Model evaluation also involves considering the trade-off between bias and variance. A high-bias model may underfit the data, while a high-variance model may overfit the data. It is crucial to strike a balance between these two extremes to achieve a model that generalizes well to new data.
Aside from using evaluation metrics, visualizations such as confusion matrices, precision-recall curves, or ROC curves can provide insights into the model’s performance and its ability to make accurate predictions.
Iterative fine-tuning of the model’s parameters, hyperparameter optimization, and ensemble methods can be employed to further improve the model’s performance. These techniques help in optimizing the model’s performance and adjusting it according to the specific requirements of the problem.
By training the model on the preprocessed data and evaluating its performance using appropriate metrics, you can ascertain the efficacy of the model. This assessment forms the basis for making informed decisions regarding model deployment and further improvements in the machine learning pipeline.
In the next section, we will explore the final component of the machine learning pipeline: model deployment and monitoring.
Model Deployment and Monitoring
Model deployment and monitoring mark the final stages of the machine learning pipeline, where the trained model is deployed for real-world applications and continuously monitored to ensure optimal performance. Let’s dive into these components in more detail:
Model Deployment
Model deployment involves integrating the trained machine learning model into a production environment where it can make predictions or decisions based on new, unseen data. The deployment process can vary depending on the specific application and infrastructure, but some common techniques include:
- Building APIs: Creating APIs (Application Programming Interfaces) allows other software or systems to interact with the model and send data for predictions or receive the model’s predictions as outputs.
- Creating Interfaces: Designing user interfaces or dashboards that allow users to interact with the model and receive real-time predictions or insights.
- Deploying on Cloud Platforms: Leveraging cloud platforms such as Amazon Web Services (AWS) or Google Cloud Platform (GCP) to host and scale the model, ensuring accessibility and reliability.
During the deployment phase, it is crucial to consider factors such as security, scalability, latency, and infrastructure requirements to ensure smooth and efficient operation of the model in the production environment.
Model Monitoring
Once the model is deployed, it is essential to monitor its performance to ensure ongoing accuracy and reliability. Model monitoring involves tracking various metrics and indicators to detect any performance issues or deviations over time. Some aspects of model monitoring include:
- Data Monitoring: Tracking the distribution and properties of the input data and identifying any shifts or anomalies that may affect the model’s performance.
- Performance Monitoring: Continuously evaluating the model’s predictive performance using real-time data and comparing it against the expected performance metrics (e.g., accuracy, precision, recall) established during evaluation.
- Drift Detection: Detecting and addressing concept drift, which occurs when the statistical properties of the input data change over time, potentially impacting the reliability of the model’s predictions.
- Feedback Loop: Incorporating a feedback loop to collect users’ feedback on the model’s predictions or decisions and iteratively improving the model based on the feedback received.
Model monitoring ensures that the deployed model remains up-to-date, accurate, and reliable for the intended business use. It helps identify and address performance issues proactively, allowing for timely interventions and updates as needed.
Regular model maintenance, periodic model retraining, and version control mechanisms are also essential in ensuring that the deployed model stays aligned with the evolving business requirements and the changing nature of the input data.
By effectively deploying the trained model and monitoring its performance over time, you can ensure the continuous delivery of accurate and reliable predictions or decisions.
In the next section, we will explore some common challenges encountered in a machine learning pipeline and strategies to overcome them.
Common Challenges in a Machine Learning Pipeline
Building and implementing a machine learning pipeline is a complex and iterative process that comes with its own set of challenges. Understanding and addressing these challenges is crucial for the successful development and deployment of machine learning models. Let’s explore some common challenges that can arise during various stages of the pipeline:
Data Quality and Availability
One of the primary challenges in a machine learning pipeline is ensuring high-quality data. Data may be incomplete, contain errors, or have biases, which can adversely affect the model’s performance. Gathering and preprocessing large and diverse datasets can also be time-consuming and resource-intensive.
Feature Selection and Engineering
Choosing the right set of features and engineering new ones requires domain knowledge and creativity. It can be challenging to identify the most relevant features that truly contribute to the predictive power of the model. Feature engineering often involves trial and error, and it can be time-consuming to explore and experiment with different transformations and combinations.
Model Selection and Optimization
The selection of an appropriate machine learning algorithm and its hyperparameters is crucial for achieving optimal model performance. The model may suffer from underfitting or overfitting, and finding the right balance between complexity and generalization can be challenging. Additionally, optimizing the model’s performance may require significant computational resources.
Deployment and Maintenance
Deploying a machine learning model into production systems can be complex, requiring integrations and compatibility considerations. Ensuring smooth deployment, scalability, and security can pose technical challenges. Furthermore, monitoring and maintaining the model’s performance over time as data distributions change can be demanding.
Ethical and Legal Considerations
Machine learning models can have ethical implications, such as bias in predictions or privacy concerns related to sensitive data. Understanding and addressing these ethical concerns is crucial for responsible deployment and usage of machine learning models. Additionally, legal considerations, such as compliance with data protection regulations, must be adhered to.
To overcome these challenges, it is important to adopt best practices and strategies. This includes thorough data exploration and preprocessing, careful feature selection and engineering, systematic model evaluation and optimization, and robust deployment and monitoring processes. Collaborative efforts and regular communication between data scientists, domain experts, and stakeholders can ensure the alignment of the model with the desired business outcomes.
By being aware of these challenges and addressing them diligently, organizations can harness the full potential of machine learning and drive meaningful insights and value.
In the final section, we will summarize the key points covered in the article and emphasize the importance of a well-designed machine learning pipeline.
Conclusion
In this article, we explored the concept of a machine learning pipeline and its crucial components. We learned that a machine learning pipeline provides a systematic and organized approach to building, training, evaluating, and deploying machine learning models. It guides us through the complex process of turning raw data into valuable insights.
We discussed the importance of each component in the pipeline, starting with data collection and preprocessing, where data is gathered and transformed into a suitable format. We then examined feature selection and engineering, where relevant features are chosen and new features are created to enhance the model’s predictive power.
We delved into model training and evaluation, where the model is trained on the preprocessed data and its performance is assessed using appropriate evaluation metrics. Finally, we explored model deployment and monitoring, where the trained model is deployed for real-world applications and continuously monitored to ensure accurate and reliable performance.
We also discussed the common challenges that can arise in a machine learning pipeline, such as data quality, feature selection, model selection, and ethical considerations. By understanding these challenges and employing best practices and strategies, organizations can overcome them and build effective machine learning solutions.
A well-designed machine learning pipeline is crucial for leveraging the power of machine learning and extracting valuable insights from data. It streamlines the workflow, enhances collaboration, improves reproducibility, and ensures scalability and reliability.
As technology continues to advance and more data becomes available, the importance of a robust machine learning pipeline cannot be overstated. It empowers businesses to make data-driven decisions, gain a competitive edge, and unlock new opportunities for growth and innovation.
So, whether you are a data scientist, a software engineer, or a business leader, understanding and implementing a well-structured machine learning pipeline is a key step towards harnessing the potential of machine learning and driving success in the digital era.