Introduction
Machine learning has emerged as a revolutionary technology that enables computers to learn and make predictions or decisions without being explicitly programmed. It is a subset of artificial intelligence that focuses on algorithms and statistical models to analyze vast amounts of data and extract meaningful insights. With the power of machine learning, businesses and industries have been able to improve efficiency, enhance decision-making processes, and unlock new opportunities.
Python, a versatile and popular programming language, has become the go-to choice for many professionals and enthusiasts entering the field of machine learning. Its simplicity, readability, and extensive library ecosystem, particularly with frameworks like TensorFlow and scikit-learn, make it an ideal language for implementing machine learning algorithms.
In this article, we will explore the journey of learning machine learning with Python. Whether you are a beginner looking to understand the basics or an experienced developer aiming to upskill, this guide will provide you with a solid foundation to get started.
Before diving into the details of Python and machine learning techniques, it is essential to understand the fundamental concepts and principles behind machine learning. This field revolves around the idea that machines can learn from data, detect patterns, and make informed decisions or predictions.
Machine learning can be divided into three main types: supervised learning, unsupervised learning, and reinforcement learning. Each type has its own approach and purpose, but they all share the goal of enabling machines to learn and improve their performance over time.
In supervised learning, the model is trained on labeled data, which means the input data is accompanied by the correct output. The model learns from this labeled data and can make predictions on unlabeled or new data.
Unsupervised learning, on the other hand, deals with unlabeled data. The model’s task is to find patterns, relationships, or structures within the data without any prior knowledge of the correct output.
Reinforcement learning is a type of learning where an agent interacts with an environment and learns by receiving feedback in the form of rewards or punishments. The goal is to maximize the rewards by taking the correct actions in different situations.
In this article, we will cover these different types of learning in detail, providing practical examples and code snippets using Python. We will also discuss preprocessing data, building and evaluating machine learning models, and deploying them in real-world scenarios.
By the end of this guide, you will have a solid understanding of machine learning with Python and be ready to embark on your own machine learning projects. So, let’s get started on this exciting journey!
The Basics of Machine Learning
Before diving into the intricacies of machine learning with Python, it’s important to grasp the basic concepts that underpin this fascinating field. Machine learning is a subset of artificial intelligence that focuses on developing algorithms and models that enable computers to learn from data and make predictions or decisions without being explicitly programmed.
The core idea of machine learning is to enable computers to recognize patterns in data and make informed decisions based on those patterns. This is achieved through the use of algorithms and statistical models that can analyze large amounts of data and extract valuable insights.
One of the key concepts in machine learning is the training phase. During this phase, the model is exposed to a large dataset, known as the training data, which consists of input features and their corresponding labels or outputs. The model then learns from this labeled data to make predictions or decisions on new, unseen data.
Machine learning algorithms can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, the model is trained on labeled data where each input feature is associated with a known output label. The aim of the model is to learn the relationship between the input features and their corresponding labels so that it can make accurate predictions on new, unseen data. Examples of supervised learning algorithms include linear regression, logistic regression, decision trees, and support vector machines.
Unsupervised learning, on the other hand, deals with unlabeled data. The goal of unsupervised learning algorithms is to find patterns or structures within the data without any prior knowledge of the correct output. Clustering algorithms are commonly used in unsupervised learning to group similar data points together based on their features.
Reinforcement learning is a type of learning where an agent interacts with an environment and learns by receiving feedback in the form of rewards or punishments. The agent’s goal is to maximize the rewards it receives by taking the correct actions in different situations. Reinforcement learning algorithms have been successful in autonomous robotics, game-playing agents, and optimizing processes.
It is important to note that machine learning models are only as good as the data they are trained on. High-quality, well-structured, and representative data is crucial for building accurate and robust machine learning models. Understanding the data and preprocessing it appropriately is a vital step in the machine learning pipeline.
In the next sections, we will delve deeper into each type of machine learning, providing practical examples and code snippets using Python. We will explore the different algorithms and techniques used in supervised learning, unsupervised learning, and reinforcement learning.
Now that we have covered the basics of machine learning, let’s move on to understanding how Python can be used in this exciting field.
Understanding Python for Machine Learning
Python has gained immense popularity among data scientists, machine learning practitioners, and researchers due to its simplicity, versatility, and extensive library ecosystem. It provides a user-friendly and intuitive programming language to implement and experiment with different machine learning algorithms and techniques.
Python’s success in the field of machine learning can be attributed to its rich library ecosystem. Two widely used libraries for machine learning in Python are TensorFlow and scikit-learn.
TensorFlow: TensorFlow is an open-source library developed by Google for numerical computation and machine learning. It is particularly renowned for its capabilities in building and training deep learning models. TensorFlow provides a high-level neural network API known as Keras, which simplifies the process of building and training deep learning models.
scikit-learn: scikit-learn is a powerful library that provides a wide range of machine learning algorithms and tools. It offers various modules for regression, classification, clustering, dimensionality reduction, and model evaluation. scikit-learn also provides easy-to-use functions for data preprocessing, feature selection, and model evaluation metrics.
Python’s syntax and readability make it an ideal language for prototyping, quickly iterating, and experimenting with machine learning algorithms. It allows developers to focus on the problem at hand rather than getting bogged down by complex syntax or low-level details.
Moreover, Python’s vast community and active development contribute to the availability of numerous tutorials, guides, and code samples that help beginners and professionals alike in their machine learning journey. The extensive support and resources available ensure that users can find help and answers to their questions and problems along the way.
When it comes to data manipulation, Python offers powerful libraries such as NumPy and pandas. NumPy provides efficient handling of multidimensional arrays and matrices, making it suitable for numerical operations and mathematical computations. pandas, on the other hand, offers data structures and functions to manipulate and analyze structured data, including data importing, cleaning, filtering, and transformation.
In addition, Python seamlessly integrates with other popular tools and frameworks used in the machine learning ecosystem. For example, Jupyter Notebook, an interactive computing environment, allows you to create and share live code, visualizations, and narrative text, making it an excellent tool for experimenting and documenting machine learning projects.
Overall, Python’s simplicity, extensive library ecosystem, and compatibility with other tools make it the preferred choice for many practitioners and researchers in the field of machine learning. By leveraging the power of Python, you can effectively and efficiently implement machine learning algorithms, analyze data, and build predictive models.
In the next sections, we will explore the different types of machine learning techniques in Python, starting with supervised learning.
Getting Started with Machine Learning
If you’re new to machine learning, getting started can seem intimidating. However, with the right approach and tools, you can embark on your machine learning journey with confidence. In this section, we will guide you through the essential steps to get started with machine learning.
1. Define Your Goal: Begin by clearly defining your goal. What problem are you trying to solve with machine learning? Having a clear objective will help you make informed decisions throughout the process.
2. Learn the Basics: Get familiar with the basics of machine learning. Understand the different types of learning, such as supervised, unsupervised, and reinforcement learning, as well as the key concepts and terminology associated with each type.
3. Acquire the Necessary Skills: Familiarize yourself with programming languages commonly used in machine learning, such as Python. Learn the basics of Python, including data manipulation, control structures, and object-oriented programming.
4. Understand Data and Preprocessing: Data is the fuel that drives machine learning models. Learn how to handle and preprocess data effectively, including tasks such as data cleaning, feature selection, and normalization.
5. Explore Machine Learning Libraries: Python offers a wide range of machine learning libraries, such as scikit-learn and TensorFlow. Take time to explore and understand these libraries, as they will be instrumental in implementing machine learning algorithms.
6. Start with Simple Algorithms: Begin your machine learning journey by implementing simple algorithms, such as linear regression or k-nearest neighbors, to gain hands-on experience. This will help you understand the underlying concepts and build your confidence.
7. Learn from Examples and Tutorials: Take advantage of the vast resources available online. Explore tutorials, code examples, and interactive notebooks to deepen your understanding and learn best practices in implementing machine learning algorithms.
8. Practice with Datasets: Work with diverse datasets to gain practical experience. Experiment with different techniques, algorithms, and preprocessing methods to get a holistic view of machine learning in action.
9. Evaluate and Iterate: Evaluate the performance of your models using appropriate evaluation metrics. Analyze the results and iterate on your approach to improve your models’ accuracy and effectiveness.
10. Stay Curious and Keep Learning: Machine learning is a rapidly evolving field. Stay curious, keep up with the latest advancements, and continue learning to stay ahead of the curve.
Getting started with machine learning may seem daunting, but by following these steps and gradually building your knowledge and skills, you’ll be well on your way to becoming proficient in this exciting field.
In the next sections, we will delve deeper into the different types of machine learning, starting with supervised learning, and explore practical examples and code snippets using Python.
Supervised Learning
Supervised learning is a type of machine learning where the model is trained on labeled data, with each input feature corresponding to a known output label. The goal is to learn the underlying relationship between the input features and their corresponding labels so that the model can make accurate predictions on new or unseen data.
In supervised learning, the labeled data is split into two main components: the training set and the test set. The training set is used to train the model, while the test set is used to evaluate its performance and gauge its ability to generalize well to new data.
There are various algorithms and techniques used in supervised learning, each with its own strengths and applications. Here are a few commonly used supervised learning algorithms:
- Linear Regression: Linear regression is a popular algorithm used for regression tasks, where the goal is to predict a continuous output value. It models the relationship between the input features and the target variable by fitting a linear equation.
- Logistic Regression: Logistic regression is used for classification tasks, where the goal is to predict discrete class labels. It models the probability of an input belonging to a particular class using a logistic function.
- Decision Trees: Decision trees are versatile algorithms used for both classification and regression tasks. They build a hierarchical structure of decisions based on the input features to reach a prediction or decision.
- Random Forests: Random forests are an ensemble learning method that combines multiple decision trees to make predictions. They are known for their robustness and ability to handle large datasets.
- Support Vector Machines (SVM): SVM is a powerful algorithm used for both classification and regression tasks. It aims to find an optimal hyperplane that separates the classes or predicts the target variable accurately.
When working with supervised learning, it’s important to preprocess and prepare the data before feeding it into the model. This includes tasks such as handling missing values, normalizing or standardizing features, and dealing with categorical variables through one-hot encoding or feature engineering.
Evaluating the performance of a supervised learning model is crucial to assess its accuracy and generalization ability. Common evaluation metrics for regression tasks include mean squared error (MSE) and R-squared, while classification tasks often use metrics such as accuracy, precision, recall, and F1 score.
Cross-validation is a widely used technique in supervised learning to assess the model’s performance. It involves splitting the dataset into multiple subsets and training the model on different combinations of these subsets to obtain a more reliable estimate of its generalization ability.
Hyperparameter tuning is another crucial step in supervised learning. Hyperparameters are parameters set by the practitioner, such as learning rate or regularization strength. Optimizing these hyperparameters helps find the best configuration of the model and can significantly impact its performance.
In Python, libraries like scikit-learn provide a wide range of functions and utilities for supervised learning. These libraries offer easy-to-use APIs, extensive documentation, and a wealth of resources to support you in implementing and deploying supervised learning models.
Now that we have covered the basics of supervised learning, we can move on to exploring unsupervised learning techniques in the next section.
Unsupervised Learning
In contrast to supervised learning, unsupervised learning does not rely on labeled data with known output labels. Instead, it aims to find patterns, relationships, or structures within the data without any prior knowledge of the correct output.
Unsupervised learning is particularly useful when working with unlabeled or unstructured data, as it can reveal hidden insights and provide a deeper understanding of the underlying structure. It is often used for tasks such as clustering, dimensionality reduction, and anomaly detection.
Clustering: Clustering is a common technique in unsupervised learning, where the goal is to group similar data points together based on their features. It helps identify inherent patterns or groups within the data. Examples of clustering algorithms include k-means clustering, hierarchical clustering, and DBSCAN.
Dimensionality Reduction: Dimensionality reduction aims to reduce the number of input features while preserving the most relevant information. It is used to tackle the curse of dimensionality, improve computational efficiency, and visualize high-dimensional data. Popular dimensionality reduction algorithms include principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE).
Anomaly Detection: Anomaly detection focuses on identifying rare or abnormal data points that deviate significantly from the majority. It is commonly used in fraud detection, intrusion detection, and outlier analysis. One-class SVM and isolation forest are popular algorithms for anomaly detection.
Preprocessing and scaling of data are crucial steps in unsupervised learning. It is essential to handle missing values, normalize or scale features, and handle categorical variables appropriately. Unsupervised learning algorithms are sensitive to the scale and distribution of input features, and preprocessing ensures optimal performance.
Evaluating the performance of unsupervised learning algorithms can be challenging since there are no known output labels for comparison. However, there are metrics such as silhouette score and within-cluster sum of squares that can assess the quality and compactness of the clusters generated by clustering algorithms.
When working with unsupervised learning, it’s important to explore and visualize the data to gain insights into its structure and characteristics. Data visualization techniques such as scatter plots, heatmaps, and dendrograms can provide valuable visual representations of the data and aid interpretation.
In Python, libraries like scikit-learn and pandas offer a wide range of functions and utilities for unsupervised learning. These libraries provide easy-to-use APIs, extensive documentation, and numerous tutorials to support you in implementing and experimenting with unsupervised learning algorithms.
Unsupervised learning is a powerful tool that can help uncover hidden patterns, relationships, and structures within data. By utilizing these techniques, you can gain valuable insights and make informed decisions without relying on labeled data.
In the next section, we will explore reinforcement learning, a unique type of learning that involves an agent interacting with an environment and learning through trial and error.
Reinforcement Learning
Reinforcement learning is a type of machine learning that involves an agent interacting with an environment and learning through trial and error. The goal of reinforcement learning is to teach the agent to take a sequence of actions in different states to maximize cumulative rewards.
In reinforcement learning, the agent learns from feedback in the form of rewards or punishments received after taking specific actions. The agent’s objective is to learn an optimal policy, which is a mapping from states to actions that maximizes the cumulative rewards over time.
The interaction between the agent and the environment is modeled as a Markov Decision Process (MDP). An MDP consists of a set of states, actions, transition probabilities, and rewards. The agent takes actions based on its current state, receives a reward, moves to a new state, and repeats the process until it reaches a terminal state.
Reinforcement learning algorithms can explore the environment in two ways: exploitation and exploration. Exploitation refers to taking actions that are known to yield higher rewards based on past experiences. Exploration, on the other hand, involves taking new actions to gather more information about the environment and potentially discover better strategies.
One of the fundamental algorithms in reinforcement learning is Q-learning. Q-learning is an off-policy algorithm that learns the optimal Q-values, which represent the expected cumulative rewards for taking a certain action in a given state. The Q-values are updated iteratively based on the rewards received and the Q-values of the next state.
Another popular algorithm in reinforcement learning is Deep Q-Network (DQN). DQN combines Q-learning with deep neural networks to handle high-dimensional state spaces. Deep neural networks provide a function approximation capability, allowing the agent to learn from complex and continuous state representations.
Reinforcement learning has been successful in various domains, including game playing, robotics, recommendation systems, and autonomous vehicles. It has the ability to learn optimal strategies that can adapt to dynamic environments and situations.
When working with reinforcement learning, it’s important to carefully design the reward function. The reward function defines the goals and motivations for the agent and directly influences its learning progress. Properly shaping the reward function is crucial to guide the agent towards desirable behaviors.
Reinforcement learning algorithms often require a large number of interactions with the environment to converge to optimal or near-optimal policies. This can be computationally expensive, especially in complex environments. Techniques such as experience replay and target networks can be used to stabilize and accelerate the learning process.
In Python, libraries like TensorFlow and OpenAI Gym provide tools and frameworks for implementing reinforcement learning algorithms. These libraries offer pre-built environments, algorithms, and utilities that make it easier to get started with reinforcement learning.
Reinforcement learning is a fascinating field that enables machines to learn and make decisions by interacting with their environment. By employing this type of learning, agents can discover optimal strategies and make informed decisions in dynamic and uncertain conditions.
In the next section, we will explore deep learning, a subset of machine learning that utilizes artificial neural networks to solve complex problems.
Deep Learning
Deep learning is a subset of machine learning that focuses on training artificial neural networks to learn from and make predictions on complex data. It has gained significant attention and popularity due to its ability to handle large-scale, high-dimensional datasets and solve a wide range of challenging problems.
Deep learning models are composed of multiple interconnected layers of artificial neurons, known as neural networks. Each layer performs a specific function, such as extracting features or making predictions, and the overall network learns to recognize patterns and make accurate predictions by adjusting the weights and biases of these layers.
One of the key advantages of deep learning is its ability to automatically learn feature representations from raw data, eliminating the need for manual feature engineering. This is particularly useful for tasks such as image recognition, natural language processing, and speech recognition, where extracting meaningful features can be highly complex.
Convolutional Neural Networks (CNNs) are a popular type of deep learning model commonly used in computer vision tasks. CNNs are designed to automatically recognize visual patterns by applying convolutional operations and pooling layers to extract progressively more abstract features from images.
Recurrent Neural Networks (RNNs) are another type of deep learning model commonly used in natural language processing tasks and sequential data analysis. RNNs have the ability to capture temporal dependencies and handle variable-length input sequences, making them suitable for tasks such as speech recognition, machine translation, and sentiment analysis.
Deep learning models require a large amount of labeled data for training, as well as significant computational resources. However, advancements in hardware, such as Graphics Processing Units (GPUs), have made it more feasible to train deep learning models efficiently.
Moreover, deep learning frameworks like TensorFlow, PyTorch, and Keras have simplified the implementation and training of deep learning models. These frameworks provide high-level APIs, pre-trained models, and extensive documentation that facilitate building, training, and deploying deep learning models.
Transfer learning is a technique often used in deep learning to leverage pre-trained models. By taking advantage of the knowledge learned from large-scale datasets, pre-trained models can be used as a starting point for new tasks, thus reducing the amount of data and training time required.
One of the challenges in deep learning is overfitting, where the model learns the training data too well and does not generalize well to new, unseen data. Techniques like dropout, regularization, and early stopping are commonly used to mitigate overfitting and improve the generalization ability of deep learning models.
Deep learning has achieved remarkable success in various domains, including image and speech recognition, natural language processing, autonomous vehicles, and healthcare. Its ability to automatically learn feature representations and solve complex problems has revolutionized the field of machine learning.
Now that we have covered the basics of deep learning, we will move on to discussing the process of choosing and preprocessing data for machine learning in the next section.
Choosing and Preprocessing Data for Machine Learning
Selecting and preprocessing data is a crucial step in preparing for a successful machine learning project. The quality and suitability of the data can significantly impact the performance and accuracy of the resulting machine learning models. In this section, we will explore the process of choosing and preprocessing data for machine learning.
1. Define the Problem: Begin by clearly defining the problem you are trying to solve. Identifying the specific goal and understanding the desired outcome will help guide your data selection process.
2. Identify Relevant Features: Determine the features, also known as variables or attributes, that are most relevant to the problem at hand. These features will serve as the input variables for your machine learning model.
3. Gather Data: Collect a suitable dataset that contains examples of the target variable and relevant features. Data can come from various sources, such as databases, APIs, or public datasets. Ensure that the data is representative and covers the range of possible scenarios.
4. Data Exploration and Understanding: Dive into the data and gain a thorough understanding of its structure, patterns, and characteristics. Utilize descriptive statistics, visualizations, and exploratory data analysis techniques to uncover important insights.
5. Handle Missing Data: Missing values can be present in datasets and can hinder the performance of machine learning models. Implement strategies to handle missing data, such as imputation techniques, or consider excluding instances with missing values if appropriate.
6. Clean the Data: Clean the dataset by addressing any inconsistencies, errors, outliers, or redundant information. This includes removing duplicates, correcting errors, and dealing with outliers using techniques like winsorization or removing extreme values.
7. Normalize or Standardize Features: Normalize or standardize the features to ensure that they are on a similar scale. This is important when using machine learning algorithms that are sensitive to the magnitude of input variables. Techniques like min-max scaling or z-score standardization can be applied.
8. Handle Categorical Variables: If your dataset contains categorical variables, encode them appropriately. Common approaches include one-hot encoding, label encoding, or ordinal encoding depending on the nature of the categorical data and the requirements of the specific algorithm.
9. Feature Selection: Select the most relevant features to include in your machine learning model. Eliminate irrelevant or redundant features that do not contribute significantly to the prediction task. Feature selection techniques like correlation analysis, recursive feature elimination, or feature importance can aid in this process.
10. Split the Dataset: Split the dataset into training and test sets. The training set is used to train the machine learning model, while the test set is used to evaluate its performance on unseen data. The commonly used ratio is 70-30 or 80-20 for training and testing, respectively.
Choosing and preprocessing the right data is essential for building accurate and reliable machine learning models. Understanding the problem, exploring and cleaning the data, handling missing values, normalizing features, and selecting relevant attributes are crucial steps in this process.
In the next section, we will delve into the process of building and evaluating machine learning models, covering various algorithms and techniques.
Building and Evaluating Machine Learning Models
Building and evaluating machine learning models is a vital step in the machine learning pipeline. In this section, we will explore the process of constructing models using different algorithms and techniques and evaluating their performance.
1. Choose a Model: Select an appropriate machine learning algorithm based on the nature of the problem, the available data, and the desired outcome. Consider factors such as interpretability, scalability, and computational requirements.
2. Train the Model: Use the training set to fit the chosen model to the data. The model learns the underlying patterns and relationships between the input features and the target variable. This involves adjusting the model’s parameters using optimization techniques such as gradient descent or optimization algorithms specific to the chosen algorithm.
3. Validate the Model: Validate the model’s performance using validation techniques like cross-validation. Cross-validation involves dividing the training set into multiple subsets, training the model on different combinations of these subsets, and evaluating its performance on the remaining data. This helps assess the model’s generalization ability and mitigate the risk of overfitting.
4. Hyperparameter Tuning: Fine-tune the model’s hyperparameters to optimize its performance. Hyperparameters are adjustable parameters that determine the behavior and performance of the model. Techniques like grid search or random search can be used to systematically explore different combinations of hyperparameters and determine the best configuration.
5. Evaluate on Test Set: Evaluate the final model’s performance on the test set, which contains unseen data. This provides an unbiased estimate of the model’s performance in real-world scenarios. Compare the predicted values with the true values and use appropriate evaluation metrics to assess the accuracy, precision, recall, or any other relevant criteria for the specific problem.
6. Model Performance Metrics: Select suitable performance metrics depending on the type of problem. Regression tasks commonly use metrics such as mean squared error (MSE) or root mean squared error (RMSE), while classification tasks employ metrics like accuracy, precision, recall, F1 score, or area under the receiver operating characteristic (ROC) curve.
7. Iterative Refinement: Analyze the model’s performance and its impact on the problem at hand. Identify areas for improvement and iterate through the process by tweaking the feature selection, preprocessing, or model architecture. This iterative refinement helps enhance the model’s accuracy and generalization ability.
8. Model Deployment: Once satisfied with the model’s performance, deploy it in a real-world setting. This involves integrating the model into an application or system where it can make predictions or assist in decision-making. Ensure that the model’s performance is continuously monitored, and periodic retraining or updating is done as the underlying data distribution and requirements change.
Building and evaluating machine learning models involve a combination of art and science. By carefully selecting the right algorithms, fine-tuning hyperparameters, and thoroughly assessing the models’ performance, you can create accurate and reliable models to solve a wide range of problems.
In the next section, we will explore the concept of cross-validation, a crucial technique for model evaluation and selection.
Cross-Validation
Cross-validation is a widely used technique in machine learning for model evaluation and selection. It helps assess how well a machine learning model can generalize to unseen data and provides an unbiased estimate of its performance. In this section, we will explore the concept of cross-validation and its importance in model evaluation.
K-Fold Cross-Validation: K-fold cross-validation is a popular method where the dataset is divided into K subsets, or folds, of approximately equal size. The model is trained and evaluated K times, each time using a different fold as the validation set, while the remaining folds are used as the training set. The results are then averaged to obtain an overall performance measure.
Benefits of Cross-Validation: Cross-validation overcomes the limitations of evaluating models on a single train-test split. It provides a more reliable estimate of a model’s performance by leveraging multiple train-test splits. It helps identify models that are more likely to generalize well to unseen data and reduces the risk of overfitting, as the model is exposed to different portions of the dataset during training and validation.
Hyperparameter Tuning and Cross-Validation: Cross-validation is commonly used to tune hyperparameters, which are adjustable parameters that control the behavior and performance of a model. By iterating over different hyperparameter configurations and measuring the cross-validated performance, it is possible to identify the best combination of hyperparameters that optimize the model’s performance.
Variations of Cross-Validation: In addition to K-fold cross-validation, there are other variations of cross-validation that offer different advantages in specific scenarios. Stratified K-fold cross-validation is useful when the dataset is imbalanced or when the class distribution needs to be preserved in each fold. Leave-One-Out cross-validation (LOOCV) involves using a single instance as the validation set and the remaining instances as the training set, providing a more exhaustive evaluation at the cost of increased computation.
Implementing Cross-Validation: Python libraries like scikit-learn provide convenient functions and utilities to implement cross-validation easily. The cross_val_score function, for example, allows you to perform K-fold cross-validation and retrieve the performance scores of a model. Grid search techniques, combined with cross-validation, can efficiently tune hyperparameters and select the best model configuration.
Interpreting Cross-Validation Results: Cross-validated performance metrics can provide insights into how well the model generalizes. It helps identify potential issues, such as high variance or overfitting, and enables the selection of the best-performing model configuration. It is important, however, to consider the variability of the performance metrics across the folds and not just rely on their average values.
Cross-validation is a valuable technique for model evaluation, selection, and hyperparameter tuning. It provides a robust assessment of a model’s performance by utilizing multiple train-test splits. By employing cross-validation, practitioners can make more informed decisions about their machine learning models and ensure their ability to generalize well to new, unseen data.
In the next section, we will explore the concept of hyperparameter tuning and its significance in improving model performance.
Hyperparameter Tuning
Hyperparameter tuning is an essential step in optimizing the performance of machine learning models. Hyperparameters are parameters that are not learned from the data but set by the practitioner before training the model. In this section, we will delve into the concept of hyperparameter tuning and its significance in improving model performance.
What are Hyperparameters? Hyperparameters are adjustable parameters that control the behavior and performance of a machine learning model. They are set by the practitioner and have a significant impact on the model’s ability to learn and generalize from the data.
The Importance of Hyperparameter Tuning: Properly tuning hyperparameters is critical for achieving the best performance of a machine learning model. Different hyperparameter configurations can lead to significantly different model outcomes, such as accuracy, precision, or generalization ability. Tuning hyperparameters allows for finding the optimal combination that maximizes the model’s performance on unseen data.
Hyperparameter Search Techniques: There are various techniques to search for optimal hyperparameter configurations:
- Grid Search: Grid search involves exhaustively trying all possible combinations of hyperparameters defined in a predefined grid. This method is straightforward but can be computationally expensive.
- Random Search: Random search, on the other hand, randomly samples hyperparameters from predefined distributions. It can be more efficient than grid search when the search space is large, and not all hyperparameters significantly impact model performance.
- Bayesian Optimization: Bayesian optimization is a more intelligent search technique that uses probabilistic models to choose the next set of hyperparameters to evaluate. It narrows down the search space based on previous evaluations, making it efficient for finding promising configurations.
Evaluating Hyperparameter Configurations: To evaluate different hyperparameter configurations, cross-validation is often used. By performing cross-validation, the model’s performance is assessed on multiple train-test splits, providing a more reliable estimate of its ability to generalize. Performance metrics, such as accuracy, precision, or F1 score, are used to compare and select the best-performing hyperparameter configuration.
Common Hyperparameters: The choice of hyperparameters depends on the specific algorithm or model being used. Some common hyperparameters include learning rate, regularization strength, number of layers or nodes in a neural network, the depth of a decision tree, or the number of neighbors in a k-nearest neighbors algorithm.
Iterative Refinement: Hyperparameter tuning often involves an iterative process of experimentation and evaluation. After an initial search, based on the evaluation results, adjustments can be made to further explore a narrower range or different combinations of hyperparameters. This iterative refinement helps find the optimal hyperparameter configuration.
Automated Hyperparameter Tuning: Several automated hyperparameter tuning methods, like the use of libraries such as scikit-learn’s GridSearchCV and RandomizedSearchCV, or more advanced techniques like Bayesian optimization libraries such as Optuna or Hyperopt, can simplify and streamline the hyperparameter tuning process. These tools provide efficient ways to search for optimal hyperparameter configurations with less manual effort.
Hyperparameter tuning is a crucial step in optimizing machine learning models and improving their performance. By systematically exploring different combinations of hyperparameters and evaluating their impact on model performance, practitioners can fine-tune their models for optimal results.
In the next section, we will look into the process of deploying machine learning models to real-world scenarios.
Deploying Machine Learning Models
Deploying machine learning models is the process of making them available for practical use in real-world scenarios. It involves taking a trained model and integrating it into an application, system, or production environment where it can make predictions, provide insights, or assist in decision-making. In this section, we will explore the process of deploying machine learning models.
Choosing the Deployment Scenario: Consider the specific requirements and constraints of the deployment scenario. Determine whether the model will be deployed on embedded devices, cloud platforms, or edge devices. This choice will impact factors such as computational resources, memory constraints, response time, and data privacy.
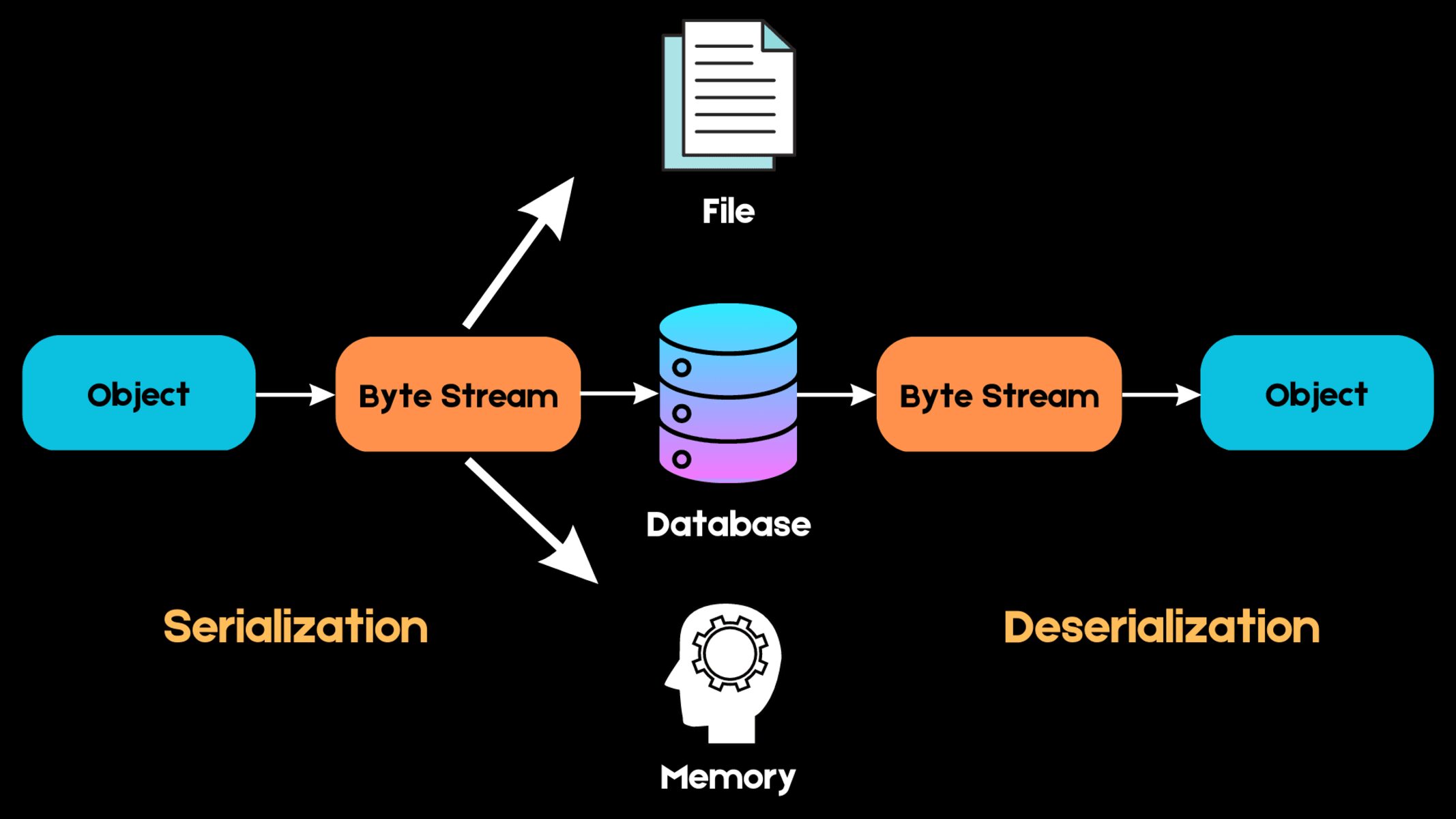
Model Serialization: Serialize the trained model into a format that can be easily saved and loaded by the deployment environment. Common serialization formats include pickle, JSON, or ONNX (Open Neural Network Exchange) for interoperability across different frameworks.
Model Serving: Set up a serving infrastructure that allows the deployed model to receive incoming data and make predictions. This infrastructure can be implemented using framework-specific tools like TensorFlow Serving or PyTorch/MLflow Serving. Alternatively, it can be built using web frameworks like Flask or Django.
Preprocessing and Featurization: Reapply the necessary preprocessing and featurization steps that were performed during model training. Ensure that the incoming data is in the same format, scale, or encoding as expected by the deployed model. This may involve handling missing data, scaling features, or converting text or categorical variables.
Data Pipeline: Develop an efficient and robust data pipeline that feeds relevant data to the deployed model. This pipeline may involve data retrieval from various sources, such as databases, APIs, or streaming platforms. Ensure that the pipeline handles data processing, transformation, and any necessary feature engineering before feeding it into the model.
Monitoring and Maintenance: Continuously monitor the performance and behavior of the deployed model in the production environment. Keep track of metrics such as prediction accuracy, response time, and resource utilization. Update the model periodically with new training data to ensure that it adapts to changes in the underlying data distribution and maintains its performance over time.
Testing and Versioning: Implement a robust testing process to validate the deployed model’s functionality and performance. Use unit tests, integration tests, and A/B testing when possible. Ensure that the deployed model is version controlled to maintain a record of changes, facilitate rollbacks if necessary, and support reproducibility.
Security and Privacy Considerations: Pay attention to security and privacy concerns when deploying machine learning models. Protect sensitive data, implement access controls, and follow best practices for data privacy and compliance, such as anonymization and encryption. Be aware of any legal or ethical implications associated with the data or the predictions made by the model.
User Interface and Visualization: Consider the development of a user interface or visualization component that allows users or stakeholders to interact with the deployed model effectively. This can involve creating interactive dashboards, APIs, or visual representations of predictions and insights.
Deploying a machine learning model successfully involves careful consideration of the deployment environment, proper preprocessing of incoming data, efficient data pipelines, monitoring, testing, and security considerations. By effectively addressing these aspects, machine learning models can be integrated seamlessly into real-world applications and systems.
In the next section, we will summarize the key points discussed in this article and provide a final perspective on learning machine learning with Python.
Conclusion
In this article, we explored the journey of learning machine learning with Python. We started by understanding the basics of machine learning, including supervised learning, unsupervised learning, reinforcement learning, and deep learning. Python, with its simplicity and extensive library ecosystem, emerged as a powerful language for implementing machine learning algorithms.
We discussed the importance of choosing and preprocessing data for machine learning, emphasizing the need to define the problem, gather relevant features, handle missing data, clean the dataset, normalize or standardize features, and select the appropriate attributes. These steps lay the foundation for building accurate and reliable machine learning models.
Next, we delved into the process of building and evaluating machine learning models. We highlighted the significance of selecting the appropriate model, training it on relevant data, validating its performance through techniques like cross-validation, and iteratively refining it to improve accuracy and generalization. Performance evaluation metrics helped us assess the model’s capability to make accurate predictions.
Hyperparameter tuning emerged as an essential step in maximizing model performance. We discussed the significance of hyperparameters, techniques like grid search and random search for tuning them, and the use of cross-validation for evaluating different hyperparameter configurations. Automated tools simplified the process and expedited hyperparameter search.
Finally, we explored the process of deploying machine learning models, emphasizing considerations such as serialization, model serving, preprocessing and featurization, data pipelines, monitoring, and security. Deploying the model in the right environment, with proper maintenance and user interfaces, ensured that it could effectively contribute to real-world applications.
As you embark on your journey of learning machine learning with Python, continue to explore and experiment with different algorithms, techniques, and datasets. Stay curious, keep up with advancements in the field, and participate in online communities to exchange knowledge and ideas.
Machine learning offers endless possibilities for solving complex problems and making data-driven decisions. With Python as your ally, you have a powerful toolset to explore the fascinating world of machine learning and unlock valuable insights from data.