Introduction
Machine learning has become an essential part of various industries, from image recognition and natural language processing to fraud detection and recommendation systems. With the increasing volume of data, running machine learning jobs efficiently has become a challenging task. This is where Apache Spark, a fast and general-purpose cluster computing system, comes into play.
Spark provides a distributed and parallel computing framework, enabling the processing of large-scale data sets in a highly efficient manner. It is widely recognized for its ability to handle big data workloads and is particularly well-suited for distributed machine learning jobs.
By using Spark, machine learning tasks can be distributed across a cluster of machines, allowing for faster and more scalable processing. Spark’s main advantage lies in its ability to handle large datasets by partitioning them into smaller, more manageable chunks, which can be processed in parallel.
Moreover, Spark offers a rich ecosystem of machine learning libraries and tools that make it easier for developers and data scientists to implement and deploy machine learning models. These libraries provide a wide range of algorithms and techniques, making Spark a versatile platform for machine learning tasks.
In this article, we will explore how Spark handles machine learning jobs. We will look at how Spark distributes these jobs across a cluster, the concept of Resilient Distributed Datasets (RDDs), the machine learning libraries available in Spark, and how Spark optimizes performance for machine learning tasks. By the end, you will have a better understanding of how Spark empowers developers and data scientists to efficiently process and analyze large-scale machine learning workloads.
Spark and Machine Learning
Machine learning has revolutionized the way we extract knowledge and insights from data. It involves training models on existing data and using these models to make predictions or decisions on new, unseen data. However, as the size and complexity of datasets continue to grow, traditional machine learning algorithms often struggle to handle the computational demands efficiently.
Apache Spark, with its distributed computing capabilities, provides an ideal solution for processing large-scale machine learning workloads. Spark can handle data stored in distributed storage systems like Hadoop Distributed File System (HDFS), allowing for seamless integration with big data infrastructure.
Spark’s distributed computing model enables it to distribute the computation of machine learning algorithms across a cluster of machines. This not only speeds up the processing time but also allows for scalability when dealing with massive datasets. Spark achieves this through its core abstraction called Resilient Distributed Datasets (RDDs), which are fault-tolerant collections of data that can be processed in parallel.
Additionally, Spark provides a rich ecosystem of machine learning libraries, such as MLlib and SparkML, that can be seamlessly integrated to perform a variety of tasks. MLlib, the older machine learning library in Spark, includes a wide range of algorithms for classification, regression, clustering, and recommendation. SparkML, on the other hand, provides a higher-level API and a set of tools for building machine learning pipelines.
Spark’s integration with popular machine learning frameworks, such as TensorFlow and Keras, further enhances its capabilities. This allows data scientists and developers to leverage the power of Spark for distributed training and inference of deep learning models, enabling them to tackle complex machine learning problems efficiently.
In summary, Apache Spark provides a robust and scalable platform for executing machine learning algorithms on big data. Its distributed computing capabilities allow for faster processing of large-scale datasets, and its extensive machine learning libraries and integration with popular frameworks make it a versatile tool for data scientists and developers. In the following sections, we will dive deeper into how Spark distributes machine learning jobs and how it optimizes performance for these tasks.
How Spark Distributes Machine Learning Jobs
One of the key strengths of Apache Spark is its ability to efficiently distribute machine learning jobs across a cluster of machines. This parallel processing capability allows Spark to handle large-scale datasets and deliver faster results. Let’s explore how Spark accomplishes this distribution.
The distribution of machine learning jobs in Spark is based on the concept of Resilient Distributed Datasets (RDDs). RDDs are fault-tolerant collections of data that can be processed in parallel across a cluster. They provide a high-level API that allows users to perform operations on data stored in a distributed manner, without exposing the complexities of distributed computing.
When executing a machine learning job in Spark, the input data is partitioned into smaller chunks, and each partition is assigned to a worker node in the cluster. This partitioning allows Spark to process each portion of the data in parallel, leveraging the computing power of multiple machines.
Spark uses a master/worker architecture, where a driver program coordinates the distribution and execution of tasks across the cluster. The driver program divides the machine learning job into smaller tasks and assigns them to the worker nodes. Each worker node then processes its assigned tasks on its portion of the data.
Furthermore, Spark employs a data-parallel model, where the same machine learning algorithm is applied to each partition of the data. This approach maximizes parallelism and ensures that the results can be easily combined or aggregated.
Moreover, Spark provides fault tolerance through RDDs. If a worker node fails during the execution of a machine learning job, the lost partitions are automatically recomputed on other available nodes. This resilience ensures that the job continues without interruption, even in the face of failures.
Overall, Spark’s distribution model for machine learning jobs allows for efficient use of computational resources and significantly reduces the processing time for large-scale datasets. By leveraging parallelism and fault tolerance through RDDs, Spark provides a scalable and robust framework for handling demanding machine learning workloads.
Spark’s Resilient Distributed Dataset (RDD)
Resilient Distributed Datasets (RDDs) are a fundamental concept in Apache Spark that underlies its ability to efficiently distribute and process data across a cluster. RDDs provide fault-tolerant and distributed collections of data that can be processed in parallel, enabling Spark to handle large-scale datasets in a scalable manner.
An RDD is an immutable distributed collection of objects that can be partitioned across multiple nodes in a cluster. The partitions of an RDD are the basic units of parallelism in Spark’s distributed computing model. Each partition of an RDD contains a subset of the data, and Spark can process each partition in parallel on different machines.
RDDs in Spark are fault-tolerant, meaning that they can recover from node failures. Spark achieves this fault tolerance by keeping track of the lineage of transformations applied to the base data. By storing the sequence of transformations that were used to create the RDD, Spark can efficiently recompute lost or damaged partitions of the RDD when needed.
RDDs support two types of operations: transformations and actions. Transformations are operations that create a new RDD from an existing one, such as filtering, mapping, or joining. These operations are lazily evaluated, meaning that they are not immediately executed but rather build up a directed acyclic graph (DAG) of transformations that define the RDD lineage.
Actions, on the other hand, trigger the execution of the DAG and return a result to the driver program or write data to an external storage system. Examples of actions include counting the number of elements in an RDD, aggregating values, or saving the RDD to disk.
Spark provides a rich set of transformations and actions that can be applied to RDDs, allowing for complex data processing and analysis. RDDs can be created from various data sources, including Hadoop Distributed File System (HDFS), local file systems, and distributed key-value stores.
Overall, RDDs are a powerful abstraction in Spark that enable distributed processing and fault tolerance. They provide the foundation for Spark’s parallel execution and make it possible to distribute machine learning and data processing tasks across a cluster of machines effectively.
Machine Learning Libraries in Spark
Apache Spark offers a comprehensive ecosystem of machine learning libraries that empower developers and data scientists to build and deploy advanced machine learning models on large-scale datasets. These libraries provide a wide range of algorithms and tools for various machine learning tasks, making Spark a versatile platform for data analysis and predictive modeling.
One of the prominent machine learning libraries in Spark is MLlib. MLlib is the original machine learning library in Spark and has been widely used for a long time. It includes a vast collection of algorithms and utilities for classification, regression, clustering, recommendation, and more. MLlib provides scalable implementations of popular algorithms like decision trees, random forests, support vector machines (SVM), and k-means clustering, among others.
Another notable addition to the Spark ecosystem is SparkML. SparkML is a higher-level library that provides a streamlined interface for building machine learning pipelines. It leverages the DataFrame API in Spark and simplifies the process of transforming raw data into a format suitable for training models. SparkML supports various machine learning algorithms and features utilities for data preprocessing, feature extraction, model selection, and evaluation.
Spark’s machine learning libraries also provide integration with popular external tools and frameworks. For example, Spark can seamlessly integrate with TensorFlow, an open-source deep learning framework. This integration enables distributed training and inference of deep learning models using Spark’s powerful distributed computing capabilities.
In addition, Spark provides support for distributed feature engineering through its FeatureTools package. This enables data engineers to handle the complexities of feature engineering at scale, extracting useful features from large and diverse datasets efficiently.
Furthermore, Spark offers interoperability with other machine learning ecosystems, such as scikit-learn and XGBoost. This allows users to leverage existing models and integrate them into Spark workflows seamlessly.
Overall, the machine learning libraries in Spark provide a comprehensive set of tools and algorithms for a wide range of machine learning tasks. From traditional algorithms to deep learning frameworks, Spark enables developers and data scientists to build powerful and scalable machine learning models on big data platforms.
Spark’s Machine Learning Pipeline
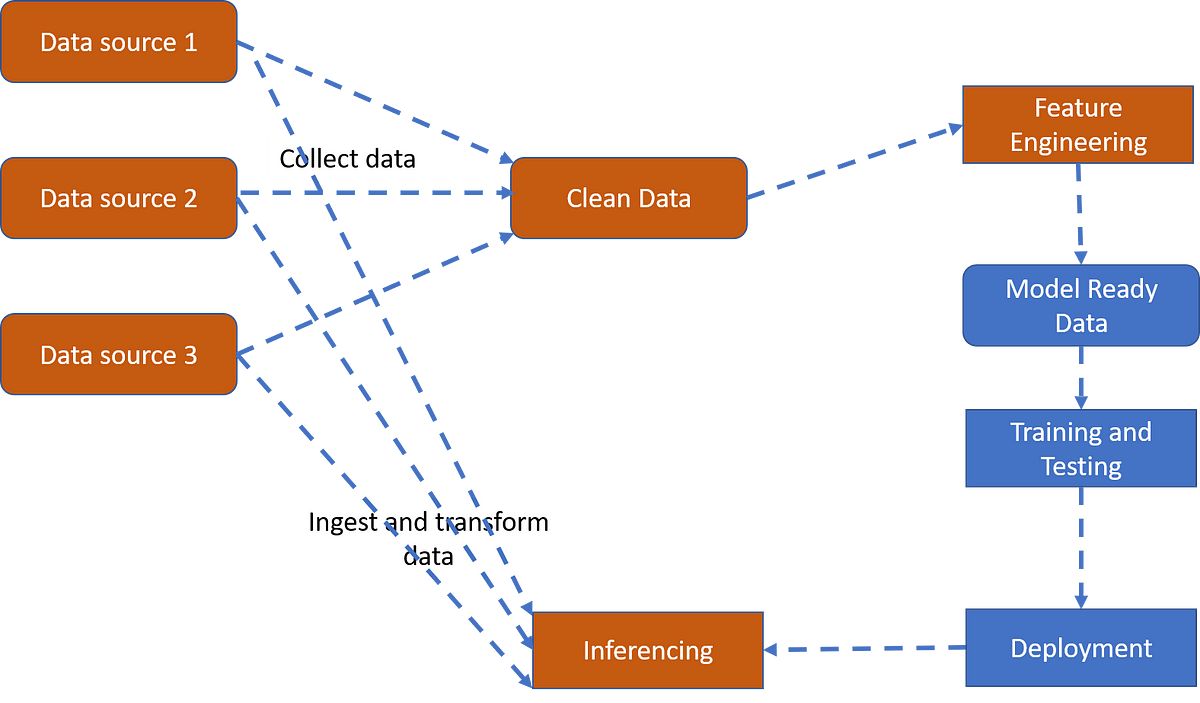
Apache Spark’s machine learning pipeline is a powerful feature that simplifies the process of building and deploying machine learning models. The machine learning pipeline in Spark provides a structured and efficient way to organize the stages of a machine learning workflow, from data preprocessing to model training and prediction.
The pipeline concept in Spark allows users to define a sequence of data transformations and model training steps as a single unit. This makes it easier to maintain and reproduce the entire machine learning workflow consistently, while also enabling efficient deployment and scaling.
Spark’s machine learning pipeline consists of several interconnected components. One of the key components is the DataFrame API, which serves as the foundation for data manipulation and transformation within the pipeline. DataFrames provide a structured and tabular representation of data, enabling easy integration with various data sources and compatibility with Spark’s distributed computing capabilities.
Within the pipeline, data preprocessing is an essential step. Spark provides a wide range of transformers for data cleaning, feature extraction, and feature transformation. These transformers can be chained together using the pipeline API, allowing for seamless data transformations in a sequential manner.
Once the data has been preprocessed, users can choose from a variety of machine learning algorithms available in Spark’s MLlib and SparkML libraries. These algorithms cover a wide range of tasks, including classification, regression, clustering, and recommendation. Users can select an appropriate algorithm and easily incorporate it into the pipeline for model training.
After the model has been trained, the pipeline enables users to apply the model to new data for prediction or classification. This helps in streamlining the entire machine learning workflow, from data preprocessing to model evaluation and deployment. The pipeline also facilitates model evaluation by providing metrics and tools for assessing the performance of the trained models.
Furthermore, Spark’s machine learning pipeline supports hyperparameter tuning, allowing users to automatically search for the best set of hyperparameters for their models. This helps optimize the model’s performance and improves its accuracy and generalization capabilities.
Overall, Spark’s machine learning pipeline provides a structured and efficient framework for building, evaluating, and deploying machine learning models. By organizing the steps of data preprocessing, model training, and prediction into a coherent pipeline, Spark simplifies the development process and enables scalable and reproducible machine learning workflows.
Spark’s MLlib vs. Other Machine Learning Libraries
When it comes to machine learning, there are several popular libraries and frameworks available, each with its strengths and use cases. Spark’s MLlib, as part of the Apache Spark ecosystem, offers unique advantages compared to other machine learning libraries.
One notable advantage of Spark’s MLlib is its ability to handle big data efficiently. Spark’s distributed computing model allows it to process large-scale datasets in a distributed and parallel manner. This gives MLlib an edge when working with datasets that exceed the memory capacity of a single machine, enabling seamless scalability and faster processing times.
Moreover, MLlib provides a wide range of machine learning algorithms for classification, regression, clustering, and recommendation. It includes both traditional algorithms like linear regression, decision trees, and k-means clustering, as well as advanced techniques such as gradient-boosted trees and deep learning models. This comprehensive collection of algorithms makes MLlib a versatile and powerful library for various machine learning tasks.
In addition to its extensive algorithmic support, MLlib offers integration with other Spark components. This integration allows MLlib to leverage the capabilities of Spark’s ecosystem, such as distributed data processing, SQL querying, and streaming analytics. This means that MLlib can seamlessly integrate machine learning workflows with other data processing tasks, providing a unified and efficient platform for data analysis and machine learning.
Compared to other machine learning libraries, MLlib’s integration with Spark also provides benefits like fault tolerance and scalability. Spark’s ability to recover from failures and handle distributed computing makes MLlib robust and suitable for large-scale deployments. This sets it apart from libraries that are designed for single-machine environments, where scalability and fault tolerance may be limited.
However, it’s worth mentioning that MLlib may not always be the best choice for every machine learning use case. Libraries like scikit-learn and TensorFlow offer their unique features and strong community support. Scikit-learn, for example, offers a comprehensive set of traditional machine learning algorithms with a focus on ease of use and straightforward implementation. TensorFlow, on the other hand, is widely recognized for its dominance in deep learning and provides advanced tools for building and training neural networks.
In summary, Spark’s MLlib offers distinct advantages through its distributed computing model, extensive algorithmic support, and integration with the Apache Spark ecosystem. Its ability to handle big data at scale and seamless integration with other Spark components make MLlib a powerful choice for tackling large-scale machine learning tasks. However, depending on the specific use case and requirements, other libraries like scikit-learn and TensorFlow may still be preferable alternatives.
Spark’s Handling of Big Data in Machine Learning
One of Apache Spark’s key strengths is its ability to handle big data effectively, making it a popular choice for large-scale machine learning tasks. Spark’s distributed computing model and its various mechanisms for handling big data make it a versatile and powerful platform for processing and analyzing massive datasets.
When it comes to machine learning, Spark’s handling of big data provides several advantages. Firstly, Spark can parallelize machine learning tasks across a cluster of machines, enabling the processing of large-scale datasets in a distributed and scalable manner. Spark distributes the data across partitions, allowing for efficient parallel processing and significantly reducing the overall processing time.
Spark’s Resilient Distributed Datasets (RDDs) play a crucial role in handling big data for machine learning tasks. RDDs partition the data and distribute it across machines, ensuring that each machine processes its portion of the data in parallel. This distributed processing capability allows Spark to handle large datasets that are too big to fit into the memory of a single machine, making it well-suited for big data analytics and machine learning.
In addition to RDDs, Spark leverages in-memory computing to further boost its performance when handling big data in machine learning. By caching intermediate data and computation results in memory, Spark minimizes the need for disk access, which can be a significant bottleneck when dealing with large datasets. The ability to keep data in memory facilitates faster iterative computations, benefiting iterative machine learning algorithms like gradient descent and collaborative filtering.
Spark’s support for distributed data storage systems, such as Hadoop Distributed File System (HDFS), also enhances its handling of big data in machine learning. Spark can seamlessly read and write data from HDFS, enabling integration with existing big data infrastructure. This eliminates the need for data movement and duplication, further improving efficiency and facilitating the integration of Spark into big data workflows.
Furthermore, Spark provides optimization techniques for handling big data in machine learning. For example, it offers tools for data partitioning, allowing users to partition data based on specific attributes or key values. This enables more efficient data processing and reduces the amount of data shuffling across the cluster, resulting in improved performance.
Overall, Spark’s handling of big data in machine learning is made possible through its distributed computing model, RDDs, in-memory caching, and support for distributed data storage systems. These features collectively enable Spark to process large-scale datasets efficiently, making it a powerful tool for machine learning tasks on big data.
Performance Optimization in Spark’s Machine Learning
Apache Spark provides various mechanisms for performance optimization in machine learning tasks, allowing for faster and more efficient execution of algorithms on large-scale datasets. These optimization techniques help to leverage Spark’s distributed computing model, minimize data movement, and utilize available computational resources effectively.
One key performance optimization technique in Spark’s machine learning is data partitioning. By partitioning data properly, Spark can distribute the workload evenly across the cluster, ensuring that each worker node operates on a manageable portion of the data. This reduces the amount of data shuffling and maximizes parallelism during computation, resulting in improved overall performance.
Another important optimization technique is caching. Spark allows intermediate data and computation results to be cached in memory, which reduces the need for disk I/O and speeds up iterative algorithms. By keeping frequently accessed data in memory, Spark avoids re-computation and minimizes data transfer between nodes, leading to significant performance improvements.
Spark also offers techniques for avoiding unnecessary data shuffling. For example, the use of appropriate join algorithms, like broadcast joins or sort-merge joins, can reduce the amount of data movement during join operations. Additionally, Spark provides mechanisms for controlling the size of data sent over the network and optimizing the shuffle process to minimize network I/O and improve performance.
Furthermore, Spark’s machine learning libraries, such as MLlib and SparkML, provide built-in support for distributed training and inference of models. Distributed training allows the parallel processing of large-scale datasets, accelerating the model training process. Distributed inference enables the efficient application of trained models to new data in parallel, facilitating real-time predictions and scalability.
Spark’s compatibility with various cluster managers, such as Apache Mesos, Hadoop YARN, and Kubernetes, also contributes to performance optimization. These cluster managers help allocate available resources effectively, ensuring that Spark jobs are executed with optimal resource utilization and efficient scheduling.
Lastly, Spark’s compatibility with hardware accelerators, such as GPUs, further enhances performance for certain machine learning tasks. By leveraging the computational power of GPUs, Spark can accelerate operations like matrix multiplication and deep learning inference, leading to significant speed improvements.
In summary, Spark provides a range of performance optimization techniques to improve the execution speed and efficiency of machine learning tasks. From data partitioning and caching to minimizing data shuffling and leveraging hardware accelerators, these optimization techniques make Spark a powerful platform for processing large-scale datasets and executing machine learning algorithms with high performance.
Conclusion
Apache Spark is an incredibly powerful platform for handling large-scale machine learning tasks. Its ability to distribute and process data across a cluster of machines, coupled with its comprehensive set of machine learning libraries, makes it a go-to choice for developers and data scientists.
Throughout this article, we have explored various aspects of Spark’s machine learning capabilities. We learned how Spark distributes machine learning jobs across a cluster using Resilient Distributed Datasets (RDDs), providing parallel and fault-tolerant processing. We also discussed Spark’s MLlib and SparkML libraries, which offer a wide range of algorithms and tools for building and deploying machine learning models.
Spark’s machine learning pipeline allows for streamlined workflows, simplifying the process of data preprocessing, model training, and prediction. Spark’s efficient handling of big data through data partitioning, in-memory caching, and integration with distributed data storage systems sets it apart from other machine learning libraries.
Furthermore, Spark’s performance optimizations, such as data partitioning, caching, and avoidance of unnecessary data shuffling, contribute to faster and more efficient execution of machine learning algorithms on large-scale datasets. Spark’s compatibility with hardware accelerators and cluster managers further enhances its performance and scalability.
In conclusion, Apache Spark provides a robust and scalable platform for handling machine learning tasks on big data. Its distributed computing capabilities, extensive machine learning libraries, and optimization techniques make it a versatile and efficient tool for processing and analyzing large-scale datasets. Whether it’s handling big data, building complex machine learning models, or optimizing performance, Spark empowers developers and data scientists to tackle challenging machine learning problems effectively and deliver impactful results.