Introduction
Welcome to the world of machine learning! If you’re new to this field, you may have come across the terms “labeled data” and “unlabeled data.” These are two fundamental concepts that play a crucial role in machine learning algorithms and models.
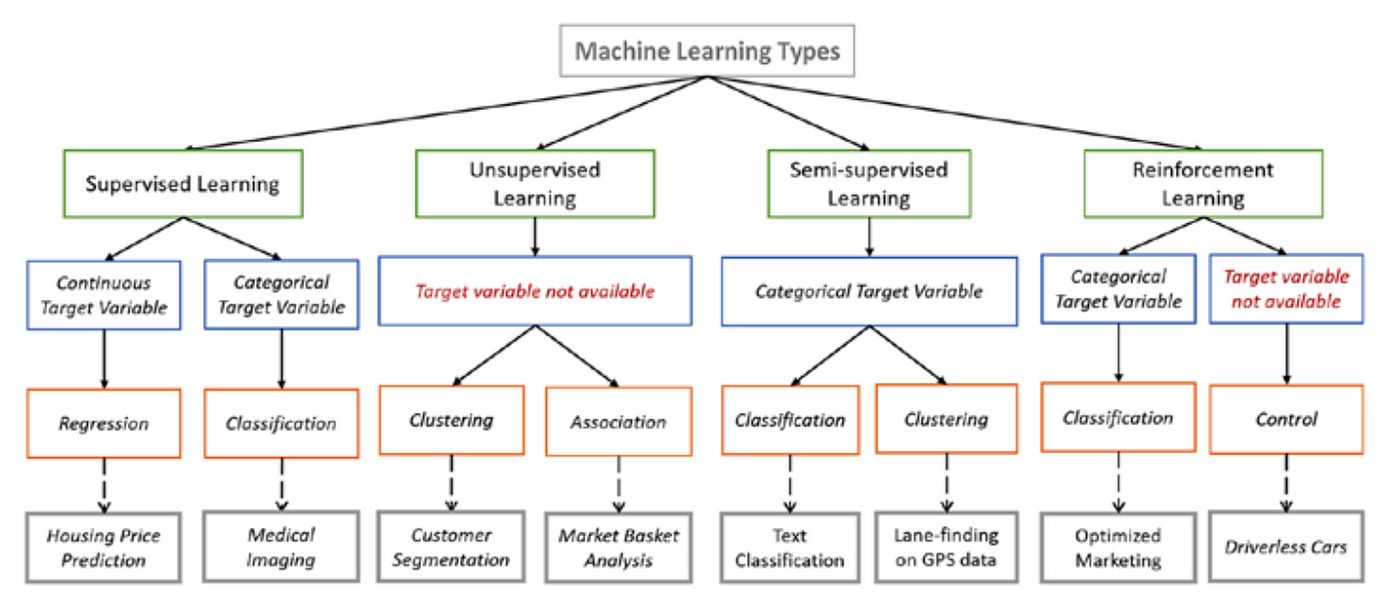
Machine learning is all about training algorithms to make predictions or take actions based on patterns found in data. Labeled data and unlabeled data are the two main types of datasets used to train these algorithms.
Labeled data refers to a dataset where each data point is accompanied by a specific target or output value. This means that for every input data point, there is a corresponding desired output or label. On the other hand, unlabeled data is a dataset where the target values or labels are not available.
The availability and quality of labeled and unlabeled data have a significant impact on the performance and accuracy of machine learning models. Labeled data provides a clear and precise understanding of the relationship between the input features and the desired output, making it easier for algorithms to learn and make predictions. Unlabeled data, although lacking explicit labels, can still contain valuable information and patterns that can be harnessed through unsupervised learning techniques.
Understanding the difference between labeled and unlabeled data is crucial for designing effective machine learning systems. In this article, we will delve deeper into the characteristics and importance of labeled and unlabeled data, as well as their specific applications in different machine learning paradigms. So, let’s dive in and explore the fascinating world of labeled and unlabeled data in machine learning!
Labeled Data
Labeled data, also known as supervised data, is a type of dataset where each data point is accompanied by a specific target or output value. In other words, the desired outcome or label for each input data point is provided. This labeling process is usually done manually by domain experts or through crowdsourcing.
The labels in a labeled dataset can represent various things depending on the problem at hand. For instance, in a classification problem, the labels can correspond to different classes or categories that the data points belong to. In a regression problem, the labels can be numerical values that represent a particular quantity or measurement. The key aspect is that these labels provide clear guidance to the machine learning algorithm on what it should learn and predict.
Labeled data plays a critical role in supervised learning algorithms. By training models with labeled data, the algorithm can learn the relationship between the input features and the corresponding target values. It learns to associate certain patterns or characteristics in the data with the correct labels, enabling it to make accurate predictions on unseen data.
One of the key advantages of labeled data is that it allows model evaluation and performance measurement. Since the ground truth labels are known for the training data, it becomes possible to assess how well the model performs in predicting the target values. This evaluation helps in estimating the accuracy, precision, recall, and other performance metrics of the model.
However, acquiring and preparing labeled data can be a challenging and time-consuming process. It requires experts with domain knowledge to accurately label the data, and the cost of labeling can be high for large datasets. Additionally, ensuring the consistency and quality of labels can also be a concern.
Despite these challenges, labeled data remains invaluable in supervised learning tasks. It is the foundation on which the models are built, allowing them to learn from the labeled examples and make predictions on unseen data. The availability and quality of labeled data greatly influence the performance and generalization capabilities of supervised learning algorithms.
Unlabeled Data
Unlike labeled data, unlabeled data does not come with specific target or output values. It refers to a dataset where the labels or desired outcomes are missing or unknown. Unlabeled data is abundant and readily available in various domains, such as text corpora, customer behavior logs, sensor data, and more.
Unlabeled data may seem less informative at first glance, but it contains valuable hidden patterns, structures, and relationships that can be uncovered through unsupervised learning techniques. Unsupervised learning algorithms are designed to make sense of unlabeled data by extracting meaningful representations, clusters, or associations.
One common application of unlabeled data is in clustering or grouping similar data points together. Unsupervised learning algorithms can analyze the underlying structure of the data to identify common patterns and group data points that are similar to each other. This can be useful in customer segmentation, anomaly detection, and personalized recommendations.
Another application of unlabeled data is in dimensionality reduction, where high-dimensional datasets are transformed into lower-dimensional representations while preserving the important information. This can help in visualizing the data, reducing computational complexity, and improving the performance of algorithms.
Furthermore, unlabeled data can be used in generative modeling, where the goal is to learn a model that can generate new samples similar to the ones in the dataset. By learning the underlying distribution of the unlabeled data, the model can generate new instances that are indistinguishable from the original data, leading to applications in text generation, image synthesis, and more.
While unlabeled data has its own benefits, it also comes with its challenges. Since the ground truth labels are missing, it can be difficult to evaluate the performance of unsupervised learning algorithms objectively. Additionally, cleaning and preprocessing unlabeled data to remove noise and irrelevant information can be a complex task.
Despite these challenges, unlabeled data provides a vast resource for discovering hidden patterns, structures, and relationships in the data. By leveraging unsupervised learning techniques, machine learning algorithms can gain insights and make sense of the unlabeled data, leading to improved decision-making and predictive capabilities.
Difference between Labeled and Unlabeled Data
Labeled and unlabeled data differ in terms of the availability of target or output values. Labeled data consists of input data points along with their corresponding desired outcome or label, while unlabeled data lacks this explicit labeling.
One of the main differences between labeled and unlabeled data is the level of supervision they provide in machine learning. Labeled data provides direct supervision as the relationship between the input features and the target values is explicitly known. It guides the learning process and allows algorithms to make accurate predictions based on the provided labels. On the other hand, unlabeled data requires unsupervised learning algorithms to infer relationships and patterns from the data itself, leading to a more exploratory and self-discovery approach.
In terms of processing and analysis, the handling of labeled and unlabeled data also differs. Labeled data can be used for training and evaluating supervised learning algorithms, where the labels act as ground truth for performance assessment. In contrast, unlabeled data is typically used in unsupervised learning algorithms for tasks such as clustering, dimensionality reduction, or generative modeling.
Another key distinction is the quality and availability of labeled and unlabeled data. Labeled data involves a time-consuming and often costly process of manual labeling by domain experts. It requires expertise and careful annotation to ensure accuracy and relevance. In contrast, unlabeled data is generated organically or collected without the need for explicit labeling, making it more readily available in large quantities.
The intended use of labeled and unlabeled data differs as well. Labeled data is primarily used in supervised learning tasks where the goal is to classify or predict specific target values. It is suitable for applications such as sentiment analysis, object recognition, and predictive modeling. Unlabeled data, on the other hand, is used to discover hidden patterns, structures, or relationships in the data. It is useful in tasks like clustering, anomaly detection, and exploratory data analysis.
In summary, the main difference between labeled and unlabeled data lies in the presence or absence of explicit target values. Labeled data provides direct supervision and is used in supervised learning, while unlabeled data requires unsupervised learning algorithms to infer patterns and relationships from the data itself. Despite their differences, both types of data play crucial roles in various machine learning applications, allowing algorithms to make accurate predictions and uncover hidden insights.
Importance of Labeled and Unlabeled Data in Machine Learning
Labeled and unlabeled data are both essential for the development and success of machine learning algorithms. They provide different types of information and serve distinct purposes in training and refining models. Let’s explore the importance of labeled and unlabeled data in machine learning.
Labeled Data:
Labeled data plays a critical role in supervised learning algorithms. It provides a clear understanding of the relationship between the input features and the desired output or target values. This allows machine learning models to learn and make predictions based on the labeled examples.
Some key reasons why labeled data is important in machine learning include:
- Model Training: Labeled data serves as the training set for supervised learning algorithms. It enables the models to learn the patterns and relationships between the features and the target values. The more accurately labeled data we have, the better the model can learn and generalize.
- Model Evaluation: Labeled data provides a benchmark for evaluating the performance of machine learning models. By comparing the predicted output to the labeled target values, we can measure the model’s accuracy, precision, recall, and other performance metrics. This evaluation helps in assessing the model’s effectiveness and identifying areas for improvement.
- Decision-Making: Labeled data allows machine learning models to make informed decisions. By associating the input features with specific target values, the model can predict the most likely outcome for new, unseen data. This prediction capability is essential in various applications, ranging from predicting customer behavior to diagnosing medical conditions.
Unlabeled Data:
Although unlabeled data may lack explicit target values, it still holds immense value in machine learning. Unlabeled data can provide rich insights and enable algorithms to discover patterns, relationships, and structures in the data.
Here are some reasons why unlabeled data is important in machine learning:
- Feature Extraction: Unlabeled data can help in extracting meaningful features or representations from the data. Unsupervised learning algorithms can identify hidden patterns and structure in the unlabeled data, allowing for more informative and compact feature representations that can enhance the performance of machine learning models.
- Data Exploration: By analyzing unlabeled data, machine learning algorithms can gain a deeper understanding of the underlying structure and distribution of the data. This exploration can uncover previously unknown insights, patterns, or anomalies, leading to valuable discoveries or improvements in decision-making processes.
- Transfer Learning: Unlabeled data can be leveraged in transfer learning, where a model trained on a source task with labeled data is adapted to a related target task with limited labeled data. The unlabeled data from the target domain can assist in fine-tuning the model and improving its performance on the target task.
In summary, labeled and unlabeled data are both crucial in machine learning. Labeled data provides direct guidance for learning and prediction, while unlabeled data enables discovery, feature extraction, and data exploration. By incorporating both types of data into machine learning workflows, we can build more robust and accurate models that can make meaningful predictions and uncover hidden insights from the data.
Labeled Data in Supervised Learning
Supervised learning is a machine learning approach that relies heavily on labeled data. It involves training models to make predictions or take actions based on the relationships learned from labeled examples. Labeled data acts as the foundation for building accurate and reliable supervised learning models. Let’s dive deeper into the role of labeled data in supervised learning.
In supervised learning, the labeled data consists of input features as well as the corresponding target or output values. The primary goal is to learn a mapping between the input features and the target values, enabling the model to make predictions on unseen data. Labeled data provides the necessary supervision and guidance for the learning process.
Here are a few key aspects of labeled data in supervised learning:
- Training Set: Labeled data forms the training set for supervised learning models. It is used to train the model on various input features to learn the patterns and relationships that exist between the features and the corresponding target values. The larger and more diverse the labeled training set, the better the model can learn and generalize.
- Model Training: Labeled data is used to train the supervised learning model using various algorithms and techniques. The model learns to associate the input features with the correct target values, capturing the underlying patterns and making accurate predictions.
- Model Evaluation: Labeled data is also crucial for evaluating the performance and accuracy of the supervised learning model. By comparing the predicted output of the model to the actual labeled target values, we can measure various metrics such as accuracy, precision, recall, and F1-score. This evaluation helps in assessing the effectiveness of the model and fine-tuning it if necessary.
- Prediction and Decision-Making: Once the supervised learning model is trained using labeled data, it can make predictions on new, unseen data. By leveraging the learned relationships between the input features and the target values, the model can provide valuable insights and make informed decisions in various applications, such as image classification, sentiment analysis, fraud detection, and more.
Labeled data, however, comes with its own challenges. It requires expert knowledge to properly label the data and ensure accuracy, consistency, and relevance. Acquiring labeled data can be time-consuming and costly, especially for large-scale projects. Additionally, the availability of high-quality labeled data may be limited in certain domains or industries.
Despite these challenges, labeled data remains fundamental to the success of supervised learning. It provides the necessary information for models to learn and make accurate predictions. The quality and quantity of labeled data greatly influence the performance and generalization capabilities of supervised learning algorithms.
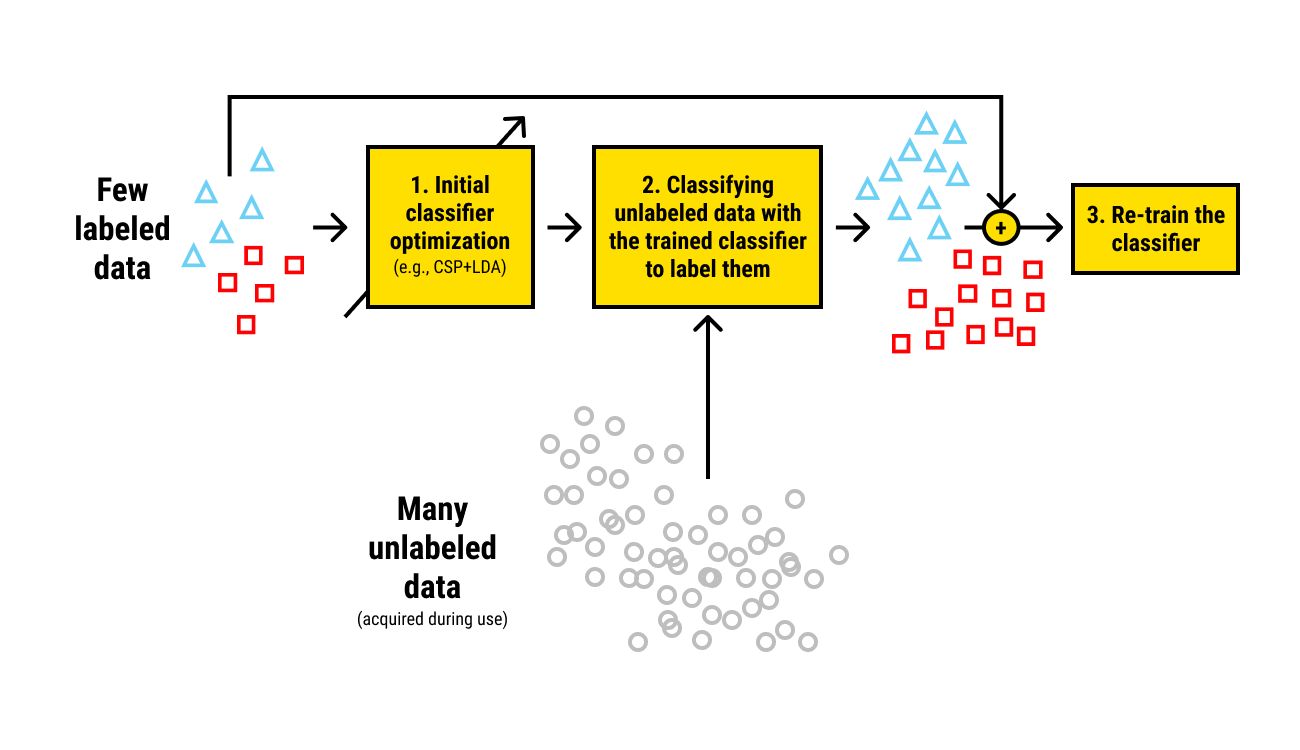
Semi-Supervised Learning with Labeled and Unlabeled Data
Semi-supervised learning is an approach that combines both labeled and unlabeled data to train machine learning models. It leverages the limited availability of labeled data along with the abundance of unlabeled data to improve model performance and generalization. Let’s explore the concept and benefits of semi-supervised learning with both labeled and unlabeled data.
In traditional supervised learning, models are trained solely on the labeled data. However, in many real-world scenarios, acquiring labeled data can be costly, time-consuming, or infeasible due to various reasons. This is where semi-supervised learning comes into play, offering an alternative approach.
The key idea behind semi-supervised learning is to use a small amount of labeled data in combination with a large amount of unlabeled data to achieve better model performance. The unlabeled data provides additional information and assists in learning the underlying structure and patterns in the data.
Here are some key aspects of semi-supervised learning with labeled and unlabeled data:
- Utilizing Labeled Data: Labeled data is used as a starting point in semi-supervised learning. The small amount of labeled data is crucial for training the model on known patterns and relationships. It acts as a reference to guide the learning process and provide initial supervision to the model.
- Uncovering Hidden Patterns: Unlabeled data plays an important role in semi-supervised learning by helping the model uncover hidden patterns and structure in the data. By leveraging unsupervised learning techniques, the model can capture meaningful representations, clusters, or associations from the unlabeled data.
- Semi-Supervised Training: The model is trained using both the labeled and unlabeled data. The labeled data provides direct supervision, allowing the model to make accurate predictions on labeled examples. The unlabeled data, on the other hand, aids in capturing additional information and enhancing the model’s generalization capabilities.
- Performance Improvement: Semi-supervised learning with labeled and unlabeled data often leads to improved model performance. Incorporating unlabeled data helps the model generalize better by capturing the underlying distribution of the data and discovering hidden patterns that might not be apparent from the labeled data alone.
- Practical Applications: Semi-supervised learning has found applications in various domains, such as natural language processing, computer vision, and medical diagnostics. It enables models to perform well even with limited labeled data, making it particularly useful in scenarios where labeled data is scarce or expensive to obtain.
Semi-supervised learning strikes a balance between the benefits of labeled data for supervision and the information-rich nature of unlabeled data. It harnesses the strengths of both types of data to enhance model performance, improve generalization, and reduce the dependency on large labeled datasets.
However, it is important to note that the success of semi-supervised learning heavily relies on the quality and representativeness of the labeled data and the ability of the model to effectively leverage the unlabeled data for learning and generalization. Appropriate algorithms and techniques need to be employed to make the most of both labeled and unlabeled data in semi-supervised learning scenarios.
Active Learning with Labeled and Unlabeled Data
Active learning is a learning paradigm that aims to maximize the performance of machine learning models by strategically selecting and labeling the most informative instances from a large pool of unlabeled data. It combines the benefits of labeled and unlabeled data to achieve efficient and effective model training. Let’s explore the concept and advantages of active learning with labeled and unlabeled data.
In traditional supervised learning, models are trained on pre-labeled data without considering the quality or relevance of the labeled instances. However, active learning takes a proactive approach by actively selecting the most informative data points to be labeled by an expert or an oracle.
Here are some key aspects of active learning with labeled and unlabeled data:
- Query Strategy: Active learning utilizes a query strategy to select the most informative instances from the pool of unlabeled data. There are various query strategies, such as uncertainty sampling, margin sampling, and diversity sampling, that aim to select instances that are most uncertain, close to the decision boundary, or representative of the class distribution.
- Model Training: In active learning, the initial model is trained on a small labeled dataset. The model is then used to make predictions on the unlabeled data, and the instances with highest uncertainty or informative characteristics are selected for labeling. These newly labeled instances are incorporated into the training dataset in an iterative process to improve the model’s performance.
- Efficient Data Labeling: Active learning provides a cost-effective approach to labeling data. Instead of labeling the entire unlabeled dataset, only a small subset of instances are selected for labeling, reducing the labeling effort and cost. This makes active learning particularly valuable in scenarios where labeling large datasets is time-consuming or expensive.
- Improved Model Performance: Active learning focuses on actively selecting the most informative instances for labeling, leading to improved model performance. By selecting diverse or uncertain instances, the model is exposed to challenging or ambiguous cases, which helps it learn more effectively and generalize better on unseen data.
- Human-in-the-Loop: Active learning involves human involvement in the labeling process. An expert or an oracle is responsible for labeling the selected instances, ensuring high-quality and accurate labels. The iterative feedback loop between the model and the expert enables refining the model’s predictions and continually improving its performance.
Active learning with labeled and unlabeled data enables efficient and dynamic model training. It allows the model to focus on the most crucial instances, learn from challenging or uncertain cases, and adapt to new data. By actively selecting instances for labeling, active learning maximizes the potential of the available labeled and unlabeled data and offers an effective solution for improving model performance with limited resources.
However, it is important to consider potential biases in the labeled instances and select a diverse range of examples during the active learning process to avoid overfitting to specific subgroups or patterns. Careful monitoring and evaluation of the active learning process are necessary to ensure its effectiveness and mitigate any biases that may arise.
Unsupervised Learning with Unlabeled Data
Unsupervised learning is a machine learning approach that deals with unlabeled data. Unlike supervised learning, where labeled data provides explicit guidance, unsupervised learning algorithms aim to discover patterns, relationships, and structures in the data without the need for predefined target values. It relies solely on the characteristics of the unlabeled data to learn and make sense of the underlying information.
Unsupervised learning with unlabeled data offers several advantages and applications. Let’s explore the concept and benefits of unsupervised learning with unlabeled data.
Here are some key aspects of unsupervised learning with unlabeled data:
- Data Exploration: Unsupervised learning enables exploration of the data without any preconceived notion or bias. It allows for a deeper understanding of the data and can provide insights into the underlying distribution, patterns, and relationships.
- Dimensionality Reduction: Unlabeled data can be high-dimensional, making it challenging to analyze and visualize. Unsupervised learning techniques, such as Principal Component Analysis (PCA) and t-SNE, can help reduce the dimensionality of the data while preserving its important characteristics. This aids in visualization, data compression, and computational efficiency.
- Clustering: Unsupervised learning algorithms can discover natural groupings or clusters in the data based on similarity or proximity. Clustering techniques, such as k-means, hierarchical clustering, or DBSCAN, enable the identification of cohesive clusters within the unlabeled data, potentially revealing underlying patterns or segments.
- Anomaly Detection: Unsupervised learning can also detect anomalies or outliers within the data. By learning the normal patterns from the unlabeled data, any data points that deviate significantly from the learned patterns can be identified as anomalies. This has applications in fraud detection, network intrusion detection, and outlier analysis.
- Generative Modeling: Unlabeled data can be used to learn the underlying distribution or structure of the data. Generative models, such as Autoencoders and Variational Autoencoders (VAEs), can learn the latent representation of the unlabeled data and generate new samples that resemble the original data distribution.
Unsupervised learning greatly relies on the quality and representativeness of the unlabeled data. As the unlabeled data is not explicitly labeled, ensuring its cleanliness, completeness, and relevance becomes crucial. Preprocessing steps, such as data cleaning, normalization, and feature engineering, are essential to extract meaningful information from the unlabeled data.
Unsupervised learning with unlabeled data is particularly useful when labeled data is scarce, expensive, or not readily available. It provides a means to extract insights and knowledge from the data itself, allowing for a more exploratory and hypothesis-free approach to learning.
However, evaluating the performance of unsupervised learning algorithms can be challenging as the absence of ground truth labels makes it difficult to objectively measure accuracy. Therefore, the effectiveness of unsupervised learning is often assessed through qualitative analysis, domain knowledge, and downstream tasks.
Overall, unsupervised learning with unlabeled data opens up a world of possibilities for uncovering hidden patterns, structures, and relationships within the data. It provides valuable insights and assists in various tasks, including data exploration, dimensionality reduction, clustering, anomaly detection, and generative modeling.
Transfer Learning with Labeled and Unlabeled Data
Transfer learning is a machine learning technique that allows models to leverage knowledge learned from one domain or task and apply it to another domain or task. It involves transferring insights, representations, or learned patterns from a source domain, where labeled or unlabeled data is available, to a target domain with limited labeled data. Transfer learning with labeled and unlabeled data offers numerous benefits and facilitates efficient model training. Let’s explore the concept and advantages of transfer learning.
In traditional machine learning, models are typically trained from scratch using labeled data specific to the target task or domain. However, this approach may not be feasible when labeled data is limited or costly to acquire. Transfer learning addresses this challenge by utilizing knowledge gained from a related or similar domain.
Here are some key aspects of transfer learning with labeled and unlabeled data:
- Source Domain: In transfer learning, a source domain is a domain where labeled or unlabeled data is available in abundance. This data-rich source domain serves as the knowledge source to transfer information to the target domain.
- Representation Learning: One common approach in transfer learning is to learn generic and robust feature representations from the source domain. These learned representations capture valuable information and patterns that are applicable across domains, minimizing the need for extensive labeled data in the target domain.
- Domain Adaptation: Transfer learning also includes domain adaptation techniques that enable models to adapt the learned knowledge from the source domain to the target domain. This adaptation accounts for disparities or differences between the two domains, ensuring improved performance and generalization in the target domain.
- Label Propagation: If labeled data is available in the source domain, transfer learning can incorporate labeled source data along with limited labeled data in the target domain. By leveraging this combined set of labeled data, models can benefit from a larger and more diverse training dataset.
- Unsupervised Pretraining: In scenarios where labeled data is limited in both the source and target domains, transfer learning with unsupervised pretraining can be employed. Unlabeled data from the source domain is used to pretrain the model in an unsupervised manner, capturing valuable representations that can be fine-tuned with limited labeled data in the target domain.
Transfer learning with labeled and unlabeled data offers several advantages:
- Efficient Model Training: By leveraging knowledge from the source domain, transfer learning reduces the dependency on large amounts of labeled data in the target domain. This improves the efficiency of model training, making it viable for domains where labeled data is scarce or costly to obtain.
- Improved Generalization: Transfer learning enables models to generalize better by incorporating knowledge and patterns learned from the source domain. The learned representations capture more robust and domain-independent features, enhancing the model’s ability to perform well in the target domain.
- Domain-Specific Adaptation: Transfer learning allows for adaptation to the specific characteristics of the target domain. By considering the differences between the source and target domains, models can adjust or fine-tune the learned knowledge to improve performance and address domain-specific nuances.
- Knowledge Transfer: Transfer learning fosters knowledge transfer between related domains, enabling advancements and learnings from one domain to benefit others. This promotes the development of more efficient and effective machine learning models across various applications.
Transfer learning with labeled and unlabeled data provides a powerful framework for effective model training and improved generalization. It alleviates the need for large amounts of labeled data and facilitates knowledge transfer between related domains, leading to more efficient and accurate machine learning models.
Conclusion
Labeled and unlabeled data are fundamental components in the field of machine learning. Labeled data provides direct supervision and guidance to algorithms, enabling accurate predictions and model evaluation. On the other hand, unlabeled data offers a wealth of untapped information and aids in discovering hidden patterns and structures in the data. Understanding the differences and importance of labeled and unlabeled data is crucial for effective machine learning.
In supervised learning, labeled data forms the foundation for training models and making predictions. It provides explicit target values that guide algorithms to learn the relationships between input features and desired outcomes. Labeled data empowers models to make informed decisions and achieve high accuracy in various applications.
Unlabeled data, while lacking explicit labels, contains valuable insights and patterns. Unsupervised learning techniques allow algorithms to discover hidden structures and relationships in the data, enabling tasks such as clustering, dimensionality reduction, and anomaly detection. Unlabeled data is particularly valuable when labeled data is scarce or expensive to acquire.
Semi-supervised learning combines the benefits of labeled and unlabeled data, leveraging a small amount of labeled data with the vastness of unlabeled data. It improves model performance by incorporating additional information from the unlabeled data and reduces the cost and effort of labeling large datasets.
Active learning focuses on strategically selecting the most informative instances from unlabeled data and actively involving human interaction to label those instances. This approach optimizes the use of labeled and unlabeled data, effectively improving model performance while minimizing the labeling effort.
Transfer learning allows models to leverage knowledge from a source domain with labeled or unlabeled data and apply it to a target domain with limited labeled data. This knowledge transfer enhances model training efficiency, improves generalization, and fosters advancements across related domains.
In conclusion, labeled and unlabeled data play vital roles in machine learning. Labeled data guides algorithms, while unlabeled data offers untapped insights. By leveraging both types of data intelligently, we can build more accurate and robust machine learning models capable of making meaningful predictions and uncovering hidden patterns in various domains.