Introduction
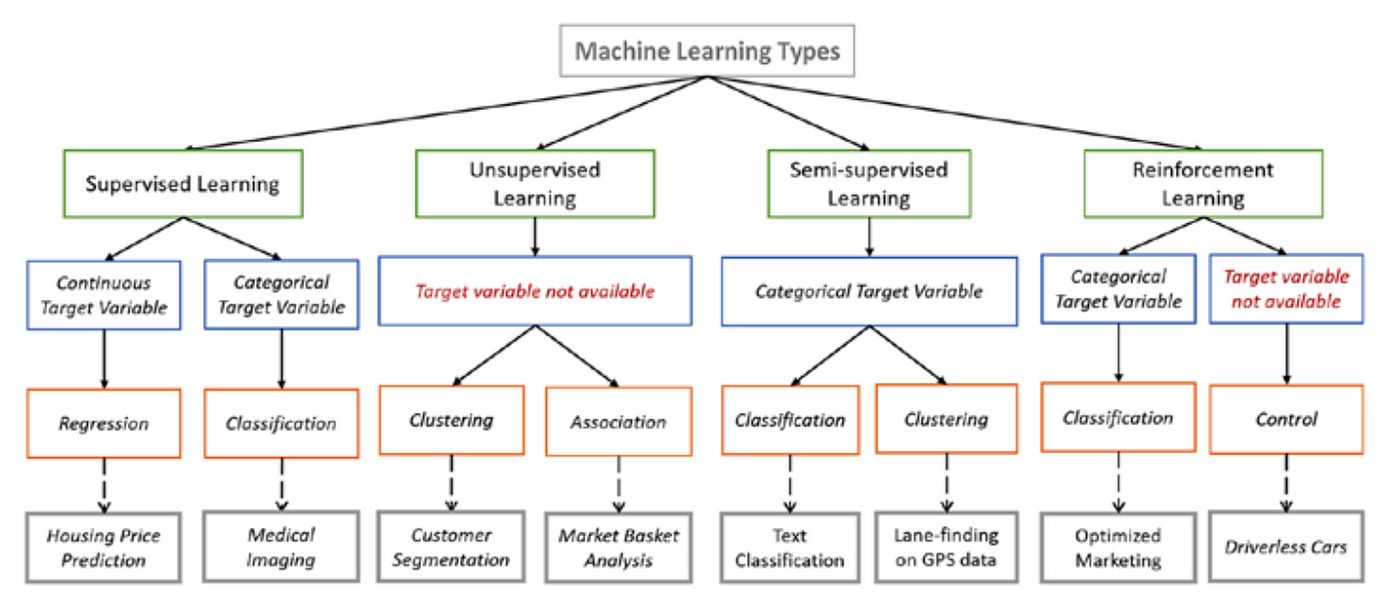
Semi-supervised learning is a powerful technique in the field of machine learning that aims to bridge the gap between supervised learning, where labeled data is abundant, and unsupervised learning, where only unlabeled data is available. In traditional supervised learning, a machine learning model learns from a labeled dataset, where each data point is associated with a specific label or category. However, collecting labeled data can be time-consuming and expensive.
On the other hand, unsupervised learning techniques enable machines to learn patterns and structures in unlabeled data without any predefined labels. While this approach is valuable in many scenarios, it often lacks the precision and accuracy achieved through supervised learning.
Semi-supervised learning, as the name suggests, combines elements of both supervised and unsupervised learning. It leverages a limited amount of labeled data along with a larger amount of unlabeled data to train a machine learning model. By incorporating the unlabeled data, the model can learn more generalized representations and capture underlying structures present in the dataset.
The main idea behind semi-supervised learning is that the labeled data provides valuable information about the specific categories, while the unlabeled data helps in uncovering additional information and relationships between the data points. This combination allows the model to make more accurate predictions on unseen data.
One of the key advantages of semi-supervised learning is its ability to utilize large amounts of readily available but unlabeled data, significantly reducing the need for costly and time-consuming manual labeling. This makes it particularly beneficial in scenarios where labeling a massive dataset is impractical, such as in medical imaging, speech recognition, and natural language processing.
In the following sections, we will delve deeper into the concept of semi-supervised learning, explore its techniques, and discuss its applications and challenges in real-world scenarios. Let us now understand how semi-supervised learning works and how it can enhance the capabilities of machine learning algorithms.
Definition of Semi-Supervised Learning
Semi-supervised learning is a machine learning approach that lies between supervised learning and unsupervised learning methods. It combines a small amount of labeled data with a larger amount of unlabeled data to train a model that can make predictions on unseen data.
In supervised learning, the training data consists of input examples and their corresponding labels. The model learns to associate the input features with the correct output labels by minimizing a loss function. However, obtaining labeled data can be expensive and time-consuming, especially when dealing with large datasets.
On the other hand, unsupervised learning algorithms analyze unlabeled data to discover meaningful patterns and structures. Without the guidance of explicit labels, these algorithms leverage statistical techniques to cluster data points or learn representation learning.
Semi-supervised learning augments the labeled data with a significant amount of unlabeled data, allowing the model to learn from both sources of information. The idea is that the unlabeled data can provide additional insights and help the model uncover hidden structures or discover new patterns that may improve its performance on unseen data.
Several methods can be used for semi-supervised learning. One common approach is transductive learning, where the model uses the labeled data to make predictions on the unlabeled data during the training phase. Another approach is generative modeling, where the model learns the joint distribution of the labeled and unlabeled data to estimate the missing labels.
Semi-supervised learning has gained significant attention in the machine learning community due to its potential to overcome the limitations of supervised learning, such as the need for extensive labeled data. By utilizing both labeled and unlabeled data, semi-supervised learning offers a practical and cost-effective solution for training accurate and robust models, particularly when labeled data is scarce or difficult to obtain.
In the next section, we will explore the benefits of semi-supervised learning and understand why it is a valuable technique in the field of machine learning.
Benefits of Semi-Supervised Learning
Semi-supervised learning offers several significant benefits compared to traditional supervised learning methods. These benefits make it a valuable technique in various domains and applications. Let’s explore the key advantages of semi-supervised learning:
- Utilization of large amounts of unlabeled data: Semi-supervised learning leverages the abundance of unlabeled data that is readily available in many domains. This allows models to benefit from a more extensive dataset, leading to improved generalization and performance.
- Reduced labeling effort and cost: Labeling large datasets can be time-consuming, expensive, and often requires expert knowledge. Semi-supervised learning reduces the reliance on labeled data by incorporating unlabeled data, minimizing the need for extensive manual labeling.
- Improved generalization and robustness: By incorporating unlabeled data that represents a wider range of real-world variability, semi-supervised learning helps models capture more diverse patterns and features. This leads to improved generalization and robustness when making predictions on unseen data.
- Adaptability to changing and evolving data: In many real-world applications, the data distribution can change over time. Semi-supervised learning provides the flexibility to adapt and incorporate new unlabeled data, allowing the model to learn from the evolving data distribution.
- Enhanced accuracy and performance: By utilizing both labeled and unlabeled data, semi-supervised learning mitigates the risk of overfitting that can occur in supervised learning with limited labeled examples. This often results in improved accuracy and performance on unseen data.
These benefits highlight why semi-supervised learning is a valuable technique in machine learning. By maximizing the use of available data and minimizing the reliance on expensive labeled data, semi-supervised learning provides a practical and efficient solution for training accurate and robust models across a wide range of applications.
Now that we understand the benefits of semi-supervised learning, let’s delve into how it works and the various techniques used in the process.
How Semi-Supervised Learning Works
Semi-supervised learning combines the principles of both supervised and unsupervised learning to train a machine learning model with a mixture of labeled and unlabeled data. The goal is to leverage the abundance of unlabeled data to improve the model’s performance and generalization on unseen data. Let’s explore how semi-supervised learning works in detail:
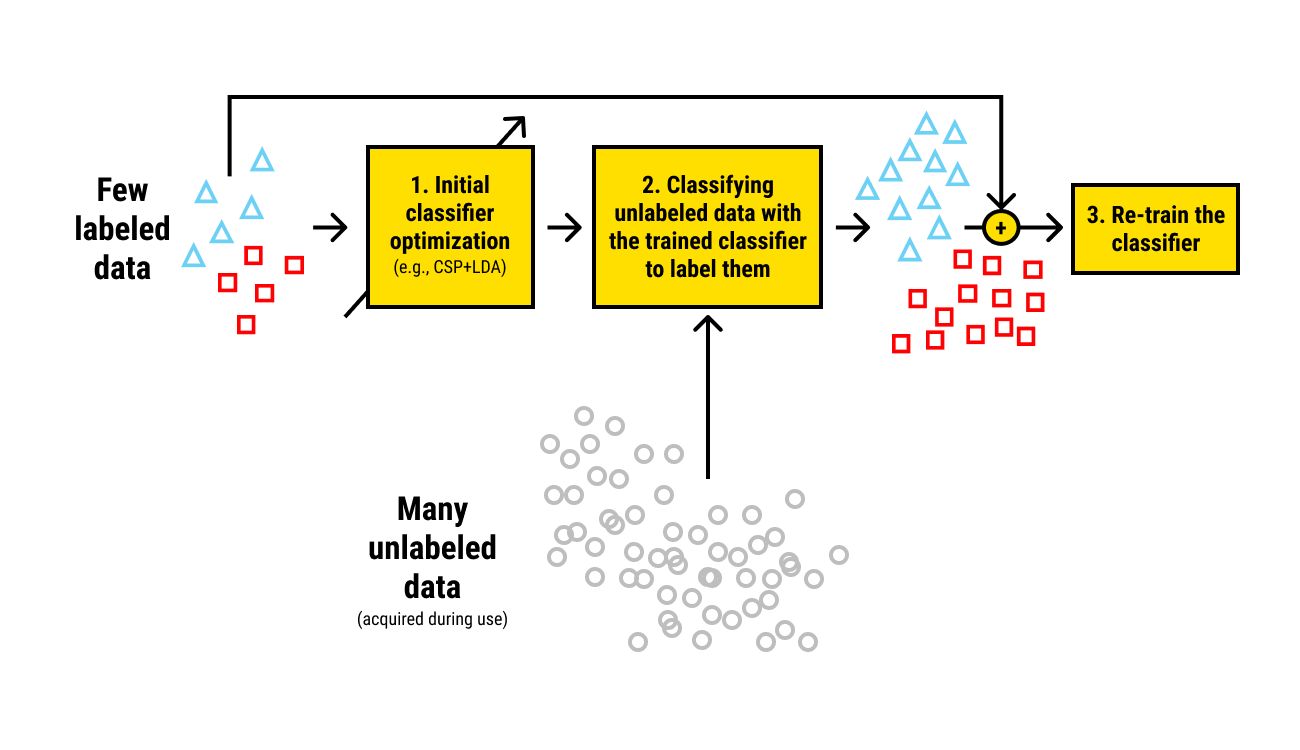
1. Splitting the data: The available dataset is divided into three separate sets: labeled data, unlabeled data, and a validation/test set. The labeled data contains a small subset of examples with their corresponding labels, while the unlabeled data consists of a larger portion of data without any explicit labels.
2. Training the model on labeled data: Initially, the model is trained on the labeled data using traditional supervised learning techniques. This step involves minimizing a loss function, such as cross-entropy loss, to optimize the model’s parameters and learn the mapping between input features and output labels.
3. Using unlabeled data to improve the model: After training on the labeled data, the model incorporates the unlabeled data to further enhance its performance. The model utilizes various techniques and algorithms to leverage the additional information present in the unlabeled data.
4. Learning from semantically meaningful representations: In semi-supervised learning, the model aims to learn from unlabeled data that captures the underlying structure and patterns in the data. This is achieved by encouraging the model to generate semantically meaningful representations, either through unsupervised learning techniques or by employing explicit regularization methods.
5. Combining labeled and unlabeled data: The model combines the information learned from both the labeled and unlabeled data to make predictions. By incorporating the unlabeled data, the model can refine its decision boundaries and improve its flexibility in handling unseen data points.
6. Evaluating on the validation/test set: The performance of the semi-supervised learning model is evaluated on the validation or test set, which contains labeled examples withheld from the training process. This serves as a measure of the model’s accuracy, generalization, and its ability to make predictions on unseen data.
By leveraging the benefits of both labeled and unlabeled data, semi-supervised learning bridges the gap between supervised and unsupervised learning. It enables models to take advantage of vast amounts of unlabeled data while benefiting from the precision and guidance provided by labeled data. This approach can significantly improve the performance and efficiency of machine learning models in real-world scenarios.
Next, we will explore some of the techniques commonly used in semi-supervised learning to effectively utilize the unlabeled data.
Semi-Supervised Learning Techniques
Semi-supervised learning employs various techniques to effectively leverage the wealth of unlabeled data along with the limited labeled data. These techniques help improve the model’s performance and generalization on unseen data. Here are some common techniques used in semi-supervised learning:
- Self-Training: Self-training is a simple and intuitive approach in semi-supervised learning. It involves training an initial model using the labeled data and then using this model to predict labels for the unlabeled data. These predicted labels are then treated as “pseudo-labels” and combined with the original labeled data to retrain the model iteratively.
- Co-Training: Co-training is a technique suitable in scenarios where the feature space can be divided into multiple views. It involves training multiple models on different subsets of features or views of the data. The models then collaborate by exchanging and incorporating information from each other’s predictions, enhancing the overall learning performance.
- Generative Models: Generative models, such as Gaussian Mixture Models (GMM) or Variational Autoencoders (VAEs), learn the joint distribution of the labeled and unlabeled data. By modeling the underlying data distribution, these models can estimate the missing labels for the unlabeled data points based on the learned distribution.
- Graph-Based Methods: Graph-based methods are widely used in semi-supervised learning. These methods leverage the inherent structure and relationships within the data to propagate labels from the labeled to the unlabeled data points. Graph-based algorithms, such as Label Propagation or Graph Convolutional Networks, utilize the graph representation of the data to perform the label propagation.
- Semi-Supervised Support Vector Machines (S3VM): S3VM extends the classical Support Vector Machine (SVM) algorithm to handle semi-supervised learning scenarios. It constructs a decision boundary that maximizes the margin between the labeled samples and the unlabeled samples while preserving the decision boundary from the supervised SVM.
These are just a few examples of the techniques commonly used in semi-supervised learning. Each technique has its strengths and limitations, and the choice of technique depends on the characteristics of the dataset and the specific problem being addressed.
By utilizing these techniques, semi-supervised learning provides a flexible and effective way to make the most of both labeled and unlabeled data. It empowers machine learning models to leverage the abundant unlabeled data to improve their performance, accuracy, and generalization, making it a powerful approach in various real-world applications.
In the next section, we will explore one specific application of semi-supervised learning: anomaly detection.
Anomaly Detection using Semi-Supervised Learning
Anomaly detection is a critical task in many domains, aiming to identify rare events or outliers that deviate significantly from the normal behavior of a system. Traditional anomaly detection methods often rely on labeled data, where anomalies and normal instances are explicitly labeled. However, obtaining labeled anomalies can be challenging and time-consuming.
Semi-supervised learning offers a compelling solution for anomaly detection by utilizing a combination of labeled and unlabeled data. Here’s how semi-supervised learning can be leveraged for anomaly detection:
1. Training on normal instances: In the semi-supervised setting, the model is trained on a dataset consisting mostly of normal instances, which are readily available. These instances form the labeled data, providing a representation of the normal behavior of the system.
2. Labeling anomalies: A small subset of anomalies is labeled, representing the abnormal instances. This limited set of labeled anomalies helps guide the model in identifying similar anomalous patterns in the unlabeled data.
3. Learning from unlabeled data: The model leverages the large amount of unlabeled data, which consists primarily of normal instances, to capture the complex patterns and structures within the normal behavior. By learning from this unlabeled data, the model can obtain a more comprehensive representation of the normal distribution.
4. Anomaly scoring: Once the model is trained, it can assign anomaly scores to previously unseen data instances. The model calculates the likelihood or distance of each instance from the learned normal behavior. Instances with higher anomaly scores are more likely to deviate from the normal behavior and are flagged as anomalies.
5. Threshold determination: Setting an appropriate threshold for the anomaly scores is crucial in determining the trade-off between detection sensitivity and false positives. This threshold depends on the specific requirements and constraints of the application.
Semi-supervised learning for anomaly detection has proven to be effective in scenarios where labeling anomalous instances is challenging or expensive. The combination of labeled normal instances and a larger set of unlabeled data allows the model to learn the normal behavior more precisely while identifying anomalies in an unsupervised manner. This approach is especially useful in detecting anomalies in systems where the anomalous behavior is sporadic or constantly evolving.
By leveraging semi-supervised learning techniques for anomaly detection, organizations can better identify potential security breaches, fraud, or abnormal behavior in various domains such as cybersecurity, financial transactions, network monitoring, and predictive maintenance.
Next, we will discuss how active learning can further enhance the performance of semi-supervised learning methods.
Active Learning in Semi-Supervised Learning
Active learning is a popular technique used in semi-supervised learning to improve the efficiency and effectiveness of the labeling process. It addresses the challenge of selecting the most valuable instances from a large pool of unlabeled data to be manually labeled by an expert or annotator.
In traditional supervised learning, the labeled data is assumed to be readily available. However, in semi-supervised learning scenarios, the labeling process can be expensive and time-consuming. Active learning mitigates this issue by actively selecting the instances for which the model is most uncertain or would benefit the most from additional labeling.
Here’s how active learning works within the context of semi-supervised learning:
1. Initial training on labeled data: The semi-supervised learning model is initially trained on a small set of labeled data, as in the traditional supervised learning pipeline.
2. Uncertainty estimation: The model uses various uncertainty estimation techniques to assess its confidence or uncertainty in predicting the labels for the unlabeled instances. Different approaches, such as entropy-based methods or margin sampling, measure the uncertainty based on the model’s prediction probabilities or decision boundaries.
3. Query selection: Active learning algorithms select instances that are difficult or uncertain for the model to classify. These instances are chosen to be manually labeled, as they have the potential to provide the most valuable information for improving the model’s performance.
4. Labeling and retraining: The selected instances are labeled by an expert or annotator and then incorporated into the training set. The model is retrained using this updated dataset, which now includes the newly labeled instances. This process is repeated iteratively as more instances are selected for labeling.
Active learning reduces the annotation effort required by focusing on the critical instances that contribute the most to the model’s learning process. By actively selecting instances to label, active learning algorithms can achieve higher labeling efficiency while maintaining or even improving the model’s accuracy and generalization performance.
Active learning in semi-supervised learning is especially valuable in scenarios where labeled data is scarce or expensive to obtain. It enables the model to make efficient use of limited labeling resources by prioritizing the instances that are most informative or challenging for the model to correctly classify.
Now that we have explored active learning in the context of semi-supervised learning, let’s move on to discuss the real-world applications where semi-supervised learning has demonstrated its effectiveness.
Semi-Supervised Learning in Real-World Applications
Semi-supervised learning has found extensive applications across various domains and industries where labeled data is limited, expensive, or difficult to obtain. Let’s explore some real-world applications that have benefited from the use of semi-supervised learning:
- Medical Diagnosis: In the field of healthcare, obtaining labeled medical data for training machine learning models can be challenging due to privacy concerns and the limited availability of annotated data. Semi-supervised learning has been successfully used in medical imaging analysis, disease diagnosis, and predicting patient outcomes by combining limited labeled medical data with large amounts of unlabeled data for improved accuracy and generalization.
- Natural Language Processing: Language-related tasks, such as sentiment analysis, text classification, and entity recognition, often require large labeled datasets for training accurate models. Semi-supervised learning techniques have been employed to leverage the abundance of unlabeled text data to enhance the performance and alleviate the burden of manual labeling in natural language processing applications.
- Speech Recognition: Speech recognition systems generally rely on extensive labeled speech data for training. However, acquiring precise phonetic transcriptions for a large volume of speech data can be time-consuming and expensive. Semi-supervised learning has proven to be effective in leveraging the available unlabeled speech data to enhance speech recognition accuracy and minimize the need for laborious manual annotation.
- Cybersecurity: Detecting intrusions and anomalies in network traffic is crucial for maintaining cybersecurity. Semi-supervised learning techniques have been utilized to analyze large volumes of unlabelled network traffic data and identify suspicious activities or network attacks. By combining labeled instances of known attacks with unlabeled data, semi-supervised learning models can effectively detect and classify network intrusions.
- Image and Video Analysis: Image and video analysis tasks, such as object detection, semantic segmentation, and action recognition, often require vast amounts of labeled data. Semi-supervised learning has been applied to leverage unlabeled visual data to improve the accuracy and scalability of these tasks. By learning from the abundant unlabeled visual data, semi-supervised models can capture richer and more diverse visual representations.
These are just a few examples of the many applications where semi-supervised learning has shown its effectiveness. The versatility of this approach allows it to be applied in diverse domains, enabling organizations to make the most out of limited labeled data while leveraging the wealth of unlabeled data available.
As semi-supervised learning continues to evolve and new techniques are developed, we can expect to see its application expand even further, addressing challenges in various domains and unlocking the potential of unlabeled data for enhanced machine learning models.
In the next section, we will discuss the challenges and limitations associated with semi-supervised learning.
Challenges and Limitations of Semi-Supervised Learning
While semi-supervised learning offers numerous advantages, it also faces its fair share of challenges and limitations. Understanding these limitations is crucial when considering the use of semi-supervised learning techniques. Let’s explore some of the key challenges and limitations:
- Limited effectiveness with small labeled datasets: Semi-supervised learning tends to be more effective when a significant amount of unlabeled data is available. However, if the labeled dataset is small, it may not provide sufficient guidance for the model to learn robust representations and accurately generalize to unseen data.
- Dependency on the quality of unlabeled data: The performance of semi-supervised learning relies heavily on the quality and representativeness of the unlabeled data. If the unlabeled data is noisy, contains outliers, or is biased, it may negatively impact the learning process and lead to reduced performance.
- Difficulty in selecting informative instances: The effectiveness of active learning, which is commonly employed in semi-supervised learning, depends on the ability to select the most informative instances to label. Choosing the right instances that provide the most value for improving the model’s performance can be challenging, especially in complex and high-dimensional data spaces.
- Sensitivity to labeling errors: In semi-supervised learning, errors in the initial labeling of the few labeled instances can propagate and affect the overall learning process. The model relies on these labels to make predictions, and if they are incorrect or biased, it can lead to suboptimal performance.
- Limited understanding of uncertainty estimation: Estimating uncertainty or ambiguity in the predictions of semi-supervised learning models is crucial for active learning and decision-making processes. However, interpreting and understanding the uncertainty estimation can be challenging, and the effectiveness of the uncertainty estimation techniques can vary across different applications.
These challenges and limitations highlight the need for careful consideration and evaluation when applying semi-supervised learning techniques. Understanding the specific characteristics of the dataset, the quality of the labeled and unlabeled data, and the limitations of the chosen techniques is essential for achieving optimal results.
Despite these challenges, researchers and practitioners continue to explore and develop new algorithms and approaches in semi-supervised learning to overcome these limitations and enhance its effectiveness in real-world applications.
Now, let’s conclude our discussion on semi-supervised learning.
Conclusion
Semi-supervised learning is a valuable approach that combines the strengths of supervised and unsupervised learning, enabling the utilization of both labeled and unlabeled data. By leveraging the abundance of unlabeled data, semi-supervised learning enhances the performance, efficiency, and generalization of machine learning models in various real-world scenarios.
We explored the benefits of semi-supervised learning, such as the ability to utilize large amounts of unlabeled data, reduced labeling effort and cost, improved generalization and robustness, adaptability to changing data, and enhanced accuracy and performance. These advantages make it an attractive technique for domains where obtaining labeled data is challenging or expensive.
In our discussion, we examined how semi-supervised learning works, including data splitting, training on labeled data, learning from unlabeled data, and combining both types of data for prediction. We also discussed various techniques commonly used in semi-supervised learning, such as self-training, co-training, generative models, graph-based methods, and semi-supervised support vector machines.
Additionally, we explored two important concepts related to semi-supervised learning: anomaly detection and active learning. Semi-supervised learning has proven effective in detecting anomalies by combining labeled normal instances with unlabeled data. Active learning, on the other hand, helps improve the efficiency of the annotation process by selecting the most informative instances for manual labeling.
Furthermore, we discussed the real-world applications of semi-supervised learning, including medical diagnosis, natural language processing, speech recognition, cybersecurity, and image and video analysis. These examples highlight the versatility and impact of semi-supervised learning in solving complex problems across various domains.
However, we also acknowledge the challenges and limitations associated with semi-supervised learning, such as its effectiveness with small labeled datasets, the quality of the unlabeled data, difficulty in selecting informative instances, sensitivity to labeling errors, and the interpretation of uncertainty estimation.
Despite these challenges, researchers and practitioners continue to explore and develop new algorithms and techniques to overcome these limitations and enhance the effectiveness of semi-supervised learning in real-world applications.
In conclusion, semi-supervised learning is a powerful tool that leverages both labeled and unlabeled data to enhance the capabilities of machine learning models. By utilizing the abundant unlabeled data, semi-supervised learning offers enhanced accuracy, reduced labeling effort, and improved generalization, making it a valuable technique in the field of machine learning.