Introduction
Machine learning has gained immense popularity in recent years due to its ability to analyze large amounts of data and make predictions or decisions based on patterns. However, for machine learning algorithms to accurately understand and interpret data, it is essential to label the data. Data labeling is the process of assigning meaningful and relevant tags or labels to the data, enabling the machine learning model to identify patterns and make accurate predictions.
Data labeling plays a crucial role in the success of machine learning models. Without proper labels, the algorithms cannot learn effectively, leading to inaccurate or unreliable results. Whether it is image recognition, speech recognition, sentiment analysis, or any other machine learning task, the quality and accuracy of the labeled data directly impact the performance of the models.
The process of data labeling involves human experts or annotators who carefully review the data and assign appropriate labels. They may need to analyze images, text, audio, or video data, depending on the specific task. Data labeling can be a time-consuming and labor-intensive process, especially when dealing with large datasets.
Accurate data labeling is crucial for training and fine-tuning machine learning models. It helps in creating reliable training datasets that can improve the model’s performance. In addition, labeled data enables the evaluation and validation of the model’s accuracy, ensuring that it performs consistently and reliably in real-world scenarios.
There are various techniques available for data labeling, ranging from manual labeling by human experts to automated methods that leverage algorithms or pre-trained models. The choice of labeling technique depends on factors such as the complexity of the task, the amount of data available, and resource constraints.
In this article, we will explore different data labeling techniques, best practices, and challenges involved in the process. We will also discuss the importance of data labeling in machine learning and the tools and platforms available to facilitate the labeling process. So, let’s dive deeper into the world of data labeling and understand its significance in machine learning.
What is Data Labeling?
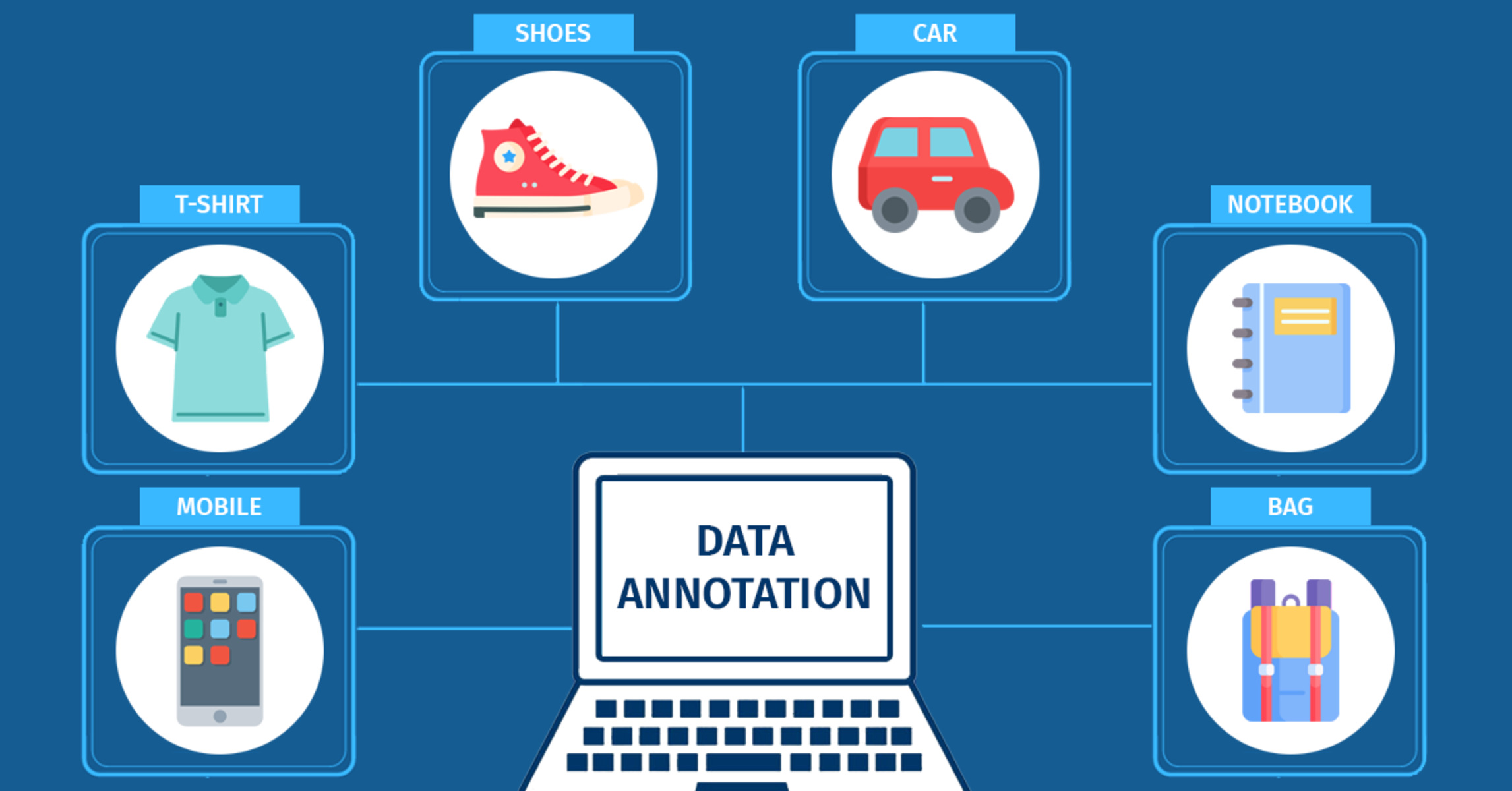
Data labeling is the process of assigning relevant and meaningful tags or labels to raw data, making it understandable for machine learning algorithms. It involves categorizing or annotating data to provide the necessary information for training machine learning models.
In the context of machine learning, raw data can take various forms, such as images, text documents, audio recordings, or video clips. These unstructured datasets need to be labeled with specific tags or categories that represent the desired information or attributes. These labels help the machine learning models understand and recognize patterns, make predictions, or classify new and unseen data.
Data labeling is a form of supervised learning, where human experts review and interpret the data to assign the appropriate labels. The experts may have domain knowledge or expertise in the specific task or dataset, enabling them to make accurate label assignments.
The process of data labeling requires a clear understanding of the task at hand and the desired output labels. For example, in image recognition, a dataset of images may need to be labeled with different categories, such as “cat,” “dog,” or “bird.” In sentiment analysis, a dataset of customer reviews may need to be labeled as “positive,” “negative,” or “neutral.”
Data labeling can be a manual or automated process, depending on the complexity of the task and the availability of resources. Manual labeling involves human experts meticulously reviewing each data point and assigning the corresponding labels. This approach ensures high accuracy but can be time-consuming and expensive, especially for large datasets.
On the other hand, automated labeling techniques leverage algorithms or pre-trained models to assign labels to the data. These techniques are useful when dealing with massive datasets or when quick labeling is required. However, automated labeling may not always be as accurate as manual labeling, especially in cases where the data is complex or ambiguous.
Overall, data labeling is a critical step in the machine learning pipeline. It not only assists in training accurate models but also enables the evaluation and validation of the model’s performance. By providing labeled data, the machine learning algorithm can learn from the patterns and relationships present in the data, increasing its ability to make accurate predictions or decisions in real-world applications.
Importance of Data Labeling in Machine Learning
Data labeling plays a crucial role in the success and effectiveness of machine learning models. It is the foundation upon which these models learn and make accurate predictions or decisions. Here are some key reasons why data labeling is important in the field of machine learning:
- Improved Model Performance: Accurate data labeling helps in creating high-quality training datasets. When the data is properly labeled, the machine learning model can learn from the labeled examples and identify patterns and correlations. This, in turn, leads to improved model performance and higher accuracy in making predictions or classifications.
- Training Data Consistency: Data labeling ensures that the training data is consistent and aligned with the desired output. Consistency in labeling is crucial to prevent biases or discrepancies in the model’s understanding of the data. Inconsistencies can negatively impact the model’s performance and make it less reliable in real-world scenarios.
- Evaluation and Validation: Labeled data enables the evaluation and validation of machine learning models. By comparing the model’s predictions with the ground truth labels, we can assess its accuracy and measure its performance. This evaluation helps identify areas for improvement and fine-tuning of the model.
- Generalization: Data labeling contributes to the generalization capability of machine learning models. When the training data is labeled accurately and comprehensively, the model can learn the underlying patterns and generalize them to make predictions on unseen data. This generalization ability is crucial for the model’s effectiveness and reliability in real-world applications.
- Domain Adaptation: Data labeling allows for domain adaptation, where the model can learn from labeled data in one domain and apply that knowledge to a related but different domain. This helps in leveraging existing labeled datasets to train models for new tasks or domains, saving time and resources.
Overall, data labeling is vital for training and fine-tuning machine learning models. It significantly impacts the performance, accuracy, and reliability of these models in various applications. By providing accurate and consistent labels, data labeling enables the models to understand and interpret data effectively, leading to valuable insights and reliable predictions.
Techniques for Data Labeling
Data labeling involves assigning relevant labels to raw data, making it understandable for machine learning algorithms. Several techniques can be used to perform data labeling, each with its own advantages and considerations. Here are some commonly used techniques for data labeling:
- Manual Labeling: Manual labeling is the traditional and most accurate approach to data labeling. Human experts or annotators carefully review each data point and assign the appropriate labels based on their understanding and expertise. This technique ensures high accuracy but can be time-consuming, especially for large datasets.
- Automated Labeling: Automated labeling techniques leverage algorithms or pre-trained models to assign labels to the data automatically. This approach is useful when dealing with massive datasets or when quick labeling is required. However, automated labeling may not always be as accurate as manual labeling, especially when the data is complex or ambiguous.
- Semi-Supervised Labeling: In semi-supervised labeling, a combination of human labeling and automated techniques is used. Initially, a small portion of the data is manually labeled by experts. This labeled data is then used to train a machine learning model, which can then be applied to label the remaining unlabeled data. Semi-supervised labeling helps reduce the manual effort required while maintaining accuracy.
- Active Learning: Active learning is a technique where the machine learning model itself identifies the data points that are the most informative or uncertain, and requests labels for those specific data points. This approach optimizes the use of manual labeling effort by focusing on the data points that contribute the most to improving the model’s performance.
- Transfer Learning: Transfer learning involves leveraging pre-existing labeled datasets from related tasks or domains to label new data. The model is first trained on the existing labeled data, and the knowledge gained from that training is then transferred to label the new data. This technique saves time and resources by reusing labeled data from similar tasks or domains.
The choice of labeling technique depends on various factors such as the complexity of the task, the availability of resources, and the desired level of accuracy. It is common to use a combination of these techniques to optimize the data labeling process and improve efficiency.
It is important to note that regardless of the labeling technique used, continuous evaluation and quality control measures should be in place to ensure the accuracy and reliability of the labeled data. Regular feedback loops and iterative labeling processes can help improve the quality of the labels and enhance the performance of the machine learning models.
Manual Labeling
Manual labeling is a technique for data labeling that relies on human experts or annotators to review and assign labels to raw data. This approach ensures high accuracy and allows for a nuanced understanding of the data. Manual labeling is commonly used when dealing with complex or subjective data that requires human judgment.
In the manual labeling process, human experts carefully analyze each data point and assign the appropriate labels based on their knowledge and expertise. They follow specific guidelines or instructions provided by the project or task manager to ensure consistency and accuracy in labeling. The experts may need to consider various factors and attributes of the data to make informed label assignments.
Manual labeling offers several advantages. Firstly, human annotators can handle ambiguous or nuanced data points that may be challenging for automated techniques. They can understand context, interpret complex patterns, and make subjective judgments when necessary. This level of human understanding is valuable in tasks such as sentiment analysis, where the tone and subtleties of the text need to be captured accurately.
Furthermore, manual labeling allows for domain expertise to be applied to the data. Experts with deep knowledge in the specific domain can provide valuable insights and ensure that the labels capture the relevant information effectively. This expertise enhances the quality of the labeled data, leading to improved model performance.
However, manual labeling can be time-consuming and resource-intensive, especially when dealing with large datasets. The process requires skilled annotators who can consistently assign accurate labels. Quality control measures, such as inter-annotator agreement, regular meetings, or feedback loops, may be implemented to ensure the consistency and reliability of the labeled data.
To streamline the manual labeling process and improve efficiency, it is common to use annotation tools or platforms. These tools provide a user-friendly interface for annotators to review the data and assign labels. They may include features such as data visualization, annotation guidelines, and labeling validation mechanisms to facilitate the labeling process and enhance collaboration among annotators.
In summary, manual labeling is a valuable technique for data labeling that leverages human expertise and judgment to assign accurate and nuanced labels. It is particularly suitable for complex or subjective data that requires human understanding. Although it can be time-consuming, manual labeling ensures high accuracy and the application of domain expertise, resulting in reliable training datasets for machine learning models.
Automated Labeling
Automated labeling is a technique for data labeling that involves using algorithms or pre-trained models to assign labels to raw data automatically. This approach is particularly useful when dealing with large datasets or when quick labeling is required. Automated labeling can save time and resources, but it may not always be as accurate as manual labeling, especially for complex or ambiguous data.
In automated labeling, machine learning algorithms or pre-trained models are utilized to analyze and interpret the data. These models have learned from previously labeled data and can utilize that knowledge to make predictions or classifications on new, unlabeled data. The models apply predefined rules or algorithms to assign labels based on patterns or features present in the data.
Automated labeling techniques can vary depending on the type of data being labeled. For text data, techniques like Natural Language Processing (NLP) can be used to analyze the text and extract relevant information or sentiments. Image data can be labeled using computer vision techniques like object detection or image recognition algorithms. Audio data can be labeled using speech processing algorithms to identify the spoken words or emotions.
One advantage of automated labeling is its efficiency in processing large datasets. With the use of automated algorithms and pre-trained models, thousands or even millions of data points can be labeled quickly, saving significant time and effort compared to manual labeling. It also reduces the dependency on human annotators and associated costs, making it an attractive option for organizations with limited resources.
However, automated labeling may not always achieve the same level of accuracy as manual labeling, especially in cases where the data is complex or ambiguous. The models rely on patterns and previous learning, which may not capture the full context or inherent nuances of the data. The accuracy of the labels is highly dependent on the quality and diversity of the training data used for the models. Therefore, careful validation and evaluation of the labeled data are necessary to ensure its reliability and quality.
To improve the accuracy of automated labeling, a combination of techniques can be employed. For example, a hybrid approach that combines automated labeling with manual review and correction can help achieve higher accuracy and consistency in the labels. This approach allows for the benefits of automation while also leveraging human expertise to handle complex or ambiguous cases effectively.
Overall, automated labeling is a valuable technique for data labeling, particularly in scenarios with large datasets or time constraints. While it offers efficiency and scalability, it should be used with caution and validated against manual or ground truth labels to ensure the accuracy and reliability of the labeled data for training machine learning models.
Semi-Supervised Labeling
Semi-supervised labeling is a data labeling technique that combines manual labeling with automated methods to label datasets more efficiently. It strikes a balance between the accuracy of manual labeling and the scalability of automated labeling. This approach is particularly useful when dealing with large datasets where manual labeling is time-consuming and resource-intensive.
In semi-supervised labeling, the process begins with a small portion of the data being manually labeled by experts. This labeled subset of data is used to train a machine learning model, which can then be applied to label the remaining unlabeled data. The model uses the patterns and insights it has learned from the labeled data to predict and assign labels to the unlabeled data.
The key advantage of semi-supervised labeling is that it reduces the overall manual labeling effort while maintaining a high level of accuracy. By leveraging the efficiency of automated labeling, a larger portion of the dataset can be labeled with minimal human intervention. This approach is particularly beneficial when manual labeling is expensive, time-consuming, or requires domain expertise.
However, it is important to note that the accuracy of the semi-supervised labeling depends on the quality and representativeness of the initially labeled subset used for training the model. Therefore, care should be taken to ensure that the initial labeled data is diverse and fully captures the different aspects and variations present in the complete dataset.
To improve the accuracy of the semi-supervised labeling process, active learning techniques can be employed. Active learning involves the machine learning model dynamically selecting uncertain or informative data points for manual labeling. By incorporating human expert feedback on these specific data points, the model can fine-tune its understanding and improve its labeling accuracy. This iterative process can be repeated to further enhance the model’s performance.
Semi-supervised labeling is especially useful in scenarios where there is limited access to experienced annotators or when large-scale labeling is required. It allows organizations to make the most efficient use of their resources while still ensuring high-quality labeled data. Additionally, it enables the application of machine learning techniques to unlabeled data that would otherwise be unusable or expensive to label manually.
In summary, semi-supervised labeling offers a practical and efficient solution for data labeling by combining the benefits of manual and automated labeling methods. It reduces the manual effort required while maintaining high labeling accuracy. By using the initial labeled data to train a model and incorporating active learning techniques, the semi-supervised approach optimizes the data labeling process and facilitates the scalability of machine learning applications.
Active Learning
Active learning is a data labeling technique that involves an iterative process of machine learning models actively selecting specific data points for manual labeling. It aims to optimize the data labeling process by focusing on the most informative or uncertain data points that contribute the most to improving the model’s performance. Active learning is particularly useful when limited resources are available for manual labeling.
In active learning, machine learning models use predefined criteria or algorithms to determine the data points that would benefit the most from manual labeling. These criteria can be based on uncertainty, disagreement among predictions, or representing data points on the decision boundary. The selected data points are then presented to human annotators for manual labeling, incorporating their expertise and judgment.
The key advantage of active learning is its ability to prioritize the labeling of data points that are most valuable in improving the model’s accuracy. By actively selecting data points that are challenging or uncertain for the model, active learning optimizes the allocation of manual labeling resources. This approach reduces the overall labeling effort required while maintaining high model performance.
Active learning can be especially beneficial in scenarios where labeling resources are limited, and labeling a large dataset manually is not feasible. By focusing on the most impactful data points, active learning ensures that the labeled data improves the model’s understanding and generalization capabilities significantly. This technique allows for a more cost-effective and efficient data labeling process.
There are different active learning strategies that can be applied, depending on the specific task or dataset. Some common strategies include uncertainty sampling, query-by-committee, and version space. These strategies aim to maximize the information gain from the labeled data while minimizing the number of queries required for manual labeling.
It is important to note that active learning requires a feedback loop between the machine learning model and the human annotators. The labeled data from the active learning process should be used to retrain or update the model to incorporate the newly acquired knowledge. This iterative process further enhances the model’s performance and its ability to select informative data points.
Although active learning offers significant advantages, it is crucial to monitor and evaluate its effectiveness. Regular validation and assessment of the model’s performance using carefully selected evaluation metrics can ensure that active learning is indeed contributing to improved accuracy and efficiency. Adjustments to the active learning strategy may be necessary based on the specific task and the model’s performance.
In summary, active learning is a powerful technique for data labeling that maximizes the value of manual labeling resources. By prioritizing the labeling of the most informative data points, active learning optimizes the model’s performance while minimizing the overall labeling effort. When combined with an iterative feedback loop, active learning can significantly enhance the efficiency and effectiveness of the data labeling process, leading to improved machine learning models.
Best Practices for Data Labeling
Data labeling is a critical step in the machine learning pipeline, and following best practices ensures accurate and reliable labeled data for training and fine-tuning machine learning models. Here are some key best practices for data labeling:
- Clearly Define the Labeling Task: Clearly outline the objectives and requirements of the labeling task. Provide detailed guidelines and instructions to annotators to ensure consistency and accuracy in the labels assigned.
- Use Multiple Annotators: Employ multiple annotators to label the same data points independently. This allows for inter-annotator agreement and helps identify and resolve any discrepancies or ambiguities in the labeling. Regular meetings and discussions among annotators can enhance consistency and improve the quality of the labels.
- Continuous Quality Control: Implement rigorous quality control measures throughout the labeling process. Regularly review and evaluate the labeled data to identify any inconsistencies or errors. Validate the labeled data against ground truth or expert knowledge to ensure accuracy.
- Consider Labeling Ambiguity: Acknowledge and address the potential ambiguity in certain data points. Provide clear instructions to annotators on how to handle ambiguous cases, encouraging them to seek clarification or consult domain experts when necessary.
- Iterative Refinement: Embrace an iterative approach to labeling. Use the labeled data to train and fine-tune the machine learning models, and incorporate the newly acquired knowledge into the labeling process. This iterative feedback loop helps improve the accuracy and consistency of the labeled data.
- Avoid Bias in Labeling: Be mindful of biases that can be introduced during the labeling process. Unintentional biases can impact the model’s performance and fairness. Provide guidelines to annotators to minimize bias and ensure fair representation across different classes or groups.
- Regularly Update Guidelines: Data labeling guidelines should be updated and improved based on feedback and lessons learned from the labeling process. Continuously refine the guidelines to address any challenges or issues encountered during the process to enhance accuracy and consistency.
- Use Data Visualization: Utilize data visualization tools and techniques to aid annotators in the labeling process. Visual representations can enhance the understanding of complex data and facilitate accurate labeling.
- Document Labeling Decisions: Maintain proper documentation of the labeling decisions and the rationale behind them. This documentation helps in auditability, provides clarity, and ensures consistency across annotators and future labeling efforts.
By following these best practices, organizations can ensure high-quality labeled data for training machine learning models. These practices improve the accuracy and reliability of the models, ultimately leading to better predictions and decisions in real-world applications.
Data Labeling Tools and Platforms
Data labeling can be a complex and time-consuming process, especially when dealing with large datasets. Fortunately, there are several data labeling tools and platforms available that can streamline and facilitate the labeling process. These tools offer user-friendly interfaces, automation capabilities, and collaboration features, improving the efficiency and accuracy of data labeling. Here are some popular data labeling tools and platforms:
- Labelbox: Labelbox is a comprehensive data labeling platform that provides a range of annotation tools for various data types, including images, text, and video. It offers features like data management, quality assurance, and collaboration capabilities to ensure efficient and accurate labeling.
- Amazon SageMaker Ground Truth: Amazon SageMaker Ground Truth is a fully managed data labeling service that integrates with other Amazon Web Services (AWS) offerings. It provides built-in workflows, templates, and automated annotation capabilities, making it easier to label data at scale.
- OpenLabeling: OpenLabeling is an open-source data labeling tool that allows users to create custom labeling interfaces and workflows. It provides flexibility and customization options for different labeling tasks and data types.
- Supervisely: Supervisely is an end-to-end data annotation platform that supports various annotation tasks, including image segmentation, object detection, and text classification. It offers powerful collaboration and project management features for teams working on complex labeling projects.
- Labelbox: Labelbox is a popular data labeling platform that supports annotation tasks for images, text, video, and 3D data. It provides an intuitive interface, automation options, and quality control features to ensure accuracy and efficiency in the labeling process.
- Figure Eight: Figure Eight, now Appen, is a data annotation platform that combines human-in-the-loop labeling with machine learning capabilities. It offers a variety of annotation options, including image tagging, sentiment analysis, and entity recognition.
- Google Cloud AutoML: Google Cloud AutoML is a machine learning platform that includes an automated data labeling feature. It leverages machine learning algorithms to label data points automatically based on user-defined rules or criteria.
- Snorkel: Snorkel is a data labeling framework that allows users to programmatically generate training data labels. It leverages weak supervision and noise-aware techniques to handle large-scale data labeling tasks effectively.
These tools and platforms offer a range of features, integrations, and pricing options to cater to different labeling requirements and budgets. Selecting the right tool depends on factors such as the complexity of the task, the type of data, the level of automation desired, and the collaboration needs of the labeling team.
By utilizing data labeling tools and platforms, organizations can streamline their labeling processes, improve labeling accuracy, and efficiently manage large-scale labeling projects. These tools enable faster turnaround times, maintain consistency, and enhance the overall productivity of data labeling efforts.
Challenges in Data Labeling
Data labeling, although crucial for training machine learning models, presents several challenges that need to be addressed to ensure the accuracy and reliability of labeled data. Here are some common challenges in data labeling:
- Subjectivity and Ambiguity: Some data points may be subjective or contain ambiguous information, making it difficult to assign definitive labels. Annotators may interpret the same data differently, leading to inconsistencies and potential biases in the labeling process.
- Scalability: Labeling large datasets manually can be time-consuming and resource-intensive. Scaling labeling efforts to match the size and complexity of the dataset can present significant challenges, especially when limited resources are available.
- Labeling Bias: Bias can unintentionally be introduced during the labeling process, leading to biased training data and biased machine learning models. Annotators may have their own inherent biases that can impact the labeling decisions, resulting in models that are not representative or fair.
- Lack of Standardization: The lack of standardized guidelines and protocols for labeling can result in inconsistencies across annotators and labeling projects. This inconsistency can introduce noise and undermine the accuracy and reliability of the labeled data.
- Evaluating Labeling Quality: Assessing the quality and accuracy of labeled data can be challenging. Without ground truth labels or expert knowledge available, it can be difficult to determine if the assigned labels are correct. Quality control measures and inter-annotator agreement can help mitigate the risk of labeling errors.
- Cost and Resources: Manual labeling can be labor-intensive and costly, particularly when dealing with intricate or specialized tasks. Finding skilled annotators and allocating sufficient resources for labeling efforts can pose financial and logistical challenges.
- Data Privacy and Security: Labeling often involves handling sensitive or private data that must be protected against unauthorized access or misuse. Adequate measures need to be taken to ensure data privacy and comply with relevant regulations and policies.
- Unbalanced and Incomplete Labels: Data labeling can be prone to label imbalance and incompleteness, where certain classes or aspects of the data may be underrepresented or overlooked. This can lead to a biased understanding of the data and impact the model’s performance.
- Labeling Consistency: Ensuring consistent labeling decisions across annotators is challenging. Different annotators may have varying levels of expertise or interpret the labeling guidelines differently, leading to inconsistencies in the assigned labels.
Addressing these challenges requires robust quality control measures, clear guidelines and instructions, continuous evaluation and feedback, and proactive management of labeling resources. Collaboration and communication among annotators, domain experts, and project managers are crucial to minimize these challenges and achieve accurate and reliable labeled data.
Conclusion
Data labeling is a vital process in the field of machine learning, allowing algorithms to understand and interpret data for accurate predictions and decisions. Whether it’s manual labeling by human experts or automated techniques, the quality and accuracy of labeled data significantly impact the performance of machine learning models.
Manual labeling offers high accuracy and nuanced understanding of the data but can be time-consuming and resource-intensive. On the other hand, automated labeling provides scalability, but may not always match the accuracy of manual labeling, especially for complex or subjective data. Semi-supervised labeling and active learning are hybrid approaches that optimize labeling efficiency while maintaining accuracy.
Best practices such as clear task definition, multiple annotators, continuous quality control, and iterative refinement help ensure accurate and consistent labeled data. Data labeling tools and platforms further streamline the labeling process with features like automation, collaboration, and data visualization.
However, challenges in data labeling like subjectivity, scalability, bias, and lack of standardization need to be carefully addressed to maintain the reliability and quality of the labeled data. Evaluating labeling quality, managing costs and resources, addressing data privacy concerns, and ensuring label consistency are also important considerations in the data labeling process.
In conclusion, data labeling is an indispensable step in training machine learning models effectively. It empowers models to recognize patterns, make accurate predictions, and deliver valuable insights in various applications. By following best practices, leveraging appropriate techniques, and addressing challenges, organizations can harness the power of data labeling to create reliable and high-performing machine learning models.