Introduction
Machine learning has revolutionized various industries, enabling computers to learn and make decisions without explicit programming. One of the key aspects that drives the success of machine learning algorithms is high-quality and accurately labeled data. Data annotation plays a pivotal role in this process.
Data annotation is the process of labeling and categorizing data to create training datasets for machine learning models. It involves adding relevant metadata, tags, and annotations to raw data, enabling the models to recognize patterns and make accurate predictions. By providing labeled data, data annotation assists the algorithm in understanding and identifying specific features or patterns, which are crucial for accurate predictions and decision-making.
The importance of data annotation cannot be understated. It serves as the building block for training machine learning models and directly impacts their performance and effectiveness. High-quality and well-annotated datasets lead to accurate models, while low-quality or incorrectly labeled data can introduce biases, errors, and inefficiencies into the learning process.
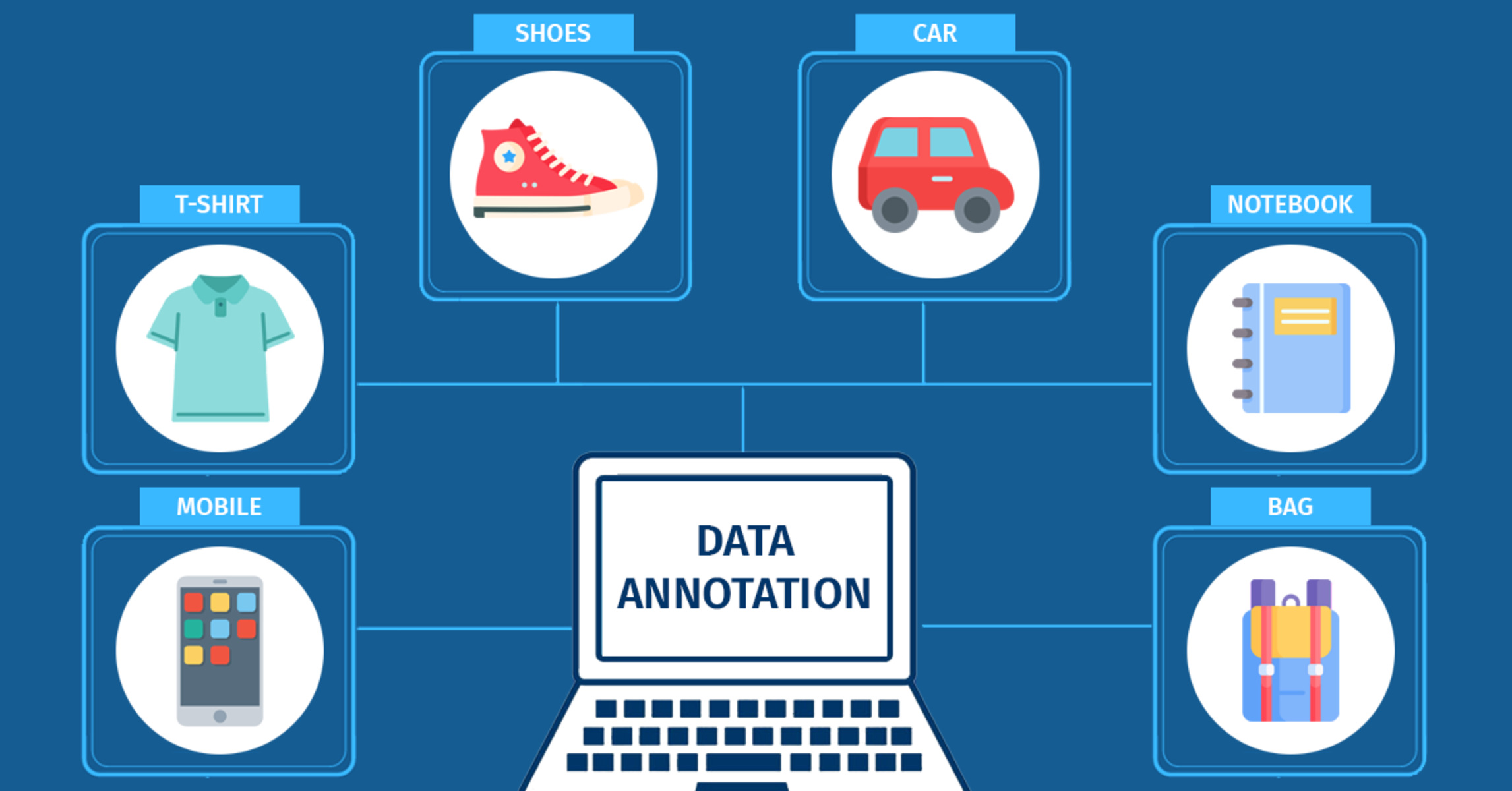
Data annotation is not limited to a specific industry or field. It is utilized in various sectors, such as healthcare, finance, autonomous vehicles, natural language processing, and computer vision, to name a few. With the growing adoption of machine learning across industries, the demand for accurate and reliable data annotation services has skyrocketed.
In this article, we will explore the importance of data annotation in machine learning and delve into the various types of data annotation methods. We will also discuss the challenges faced in the data annotation process and highlight best practices for ensuring high-quality annotations. By the end, you will have a solid understanding of the crucial role data annotation plays in the success of machine learning algorithms and the steps involved in the annotation process.
What is Data Annotation?
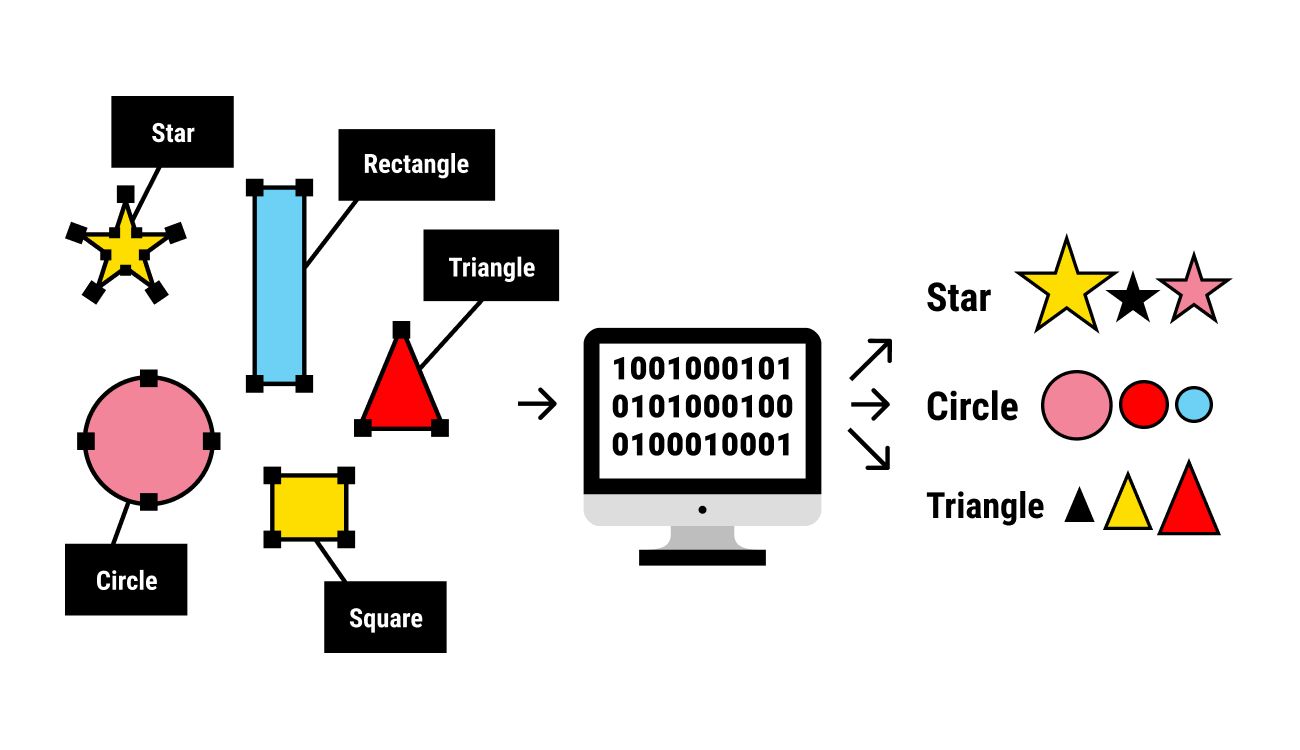
Data annotation, also known as labeling or tagging, is the process of assigning meaningful and relevant information to raw data. This annotation provides context and organizes the data in a structured manner, making it usable for training machine learning models. The labeled data acts as a reference for the algorithm, enabling it to understand patterns and make accurate predictions.
In data annotation, humans or automated systems add annotations to various types of data, such as text, images, videos, or audio. These annotations can range from simple labels or tags to more complex data attributes, like bounding boxes, keypoints, segmentation masks, sentiment scores, or named entity recognition.
The process of data annotation involves understanding the specific requirements of the machine learning task and designing a structured annotation schema. This schema defines the categories, classes, or labels that the data will be annotated with. For example, in an image classification task, the schema might include labels such as “cat,” “dog,” or “car.”
Data annotation can be a manual process performed by human annotators or an automated process using machine learning techniques. Manual annotation involves trained annotators carefully reviewing and labeling the data based on the annotation schema. Automated annotation methods leverage pre-existing models or algorithms to automatically assign annotations. However, manual annotation is typically preferred for tasks that require high accuracy and precision.
Data annotation is essential in machine learning as it directly influences the performance and effectiveness of the models. Accurate and high-quality annotations ensure that the models learn from reliable and relevant data. Conversely, incorrect or inconsistent annotations can introduce biases, errors, and hinder the model’s ability to generalize and make accurate predictions.
In the next section, we will explore the importance of data annotation in machine learning and examine how it contributes to the success of machine learning models.
Importance of Data Annotation in Machine Learning
Data annotation plays a crucial role in the success of machine learning models by providing labeled data that helps them learn and make accurate predictions. Here are some key reasons why data annotation is essential in machine learning:
1. Training Machine Learning Models: Machine learning models rely on labeled data to learn patterns and make predictions. Data annotation provides the necessary information for the models to understand the underlying structure and relationships within the data, enabling them to make accurate predictions.
2. Improving Model Performance: High-quality annotations ensure that the models are trained on accurate and relevant data. Well-annotated datasets reduce the risk of introducing biases, errors, and inconsistencies, leading to improved performance and more reliable predictions.
3. Enabling Supervised Learning: Supervised learning, where models learn from labeled examples, is a widely used approach in machine learning. Data annotation provides the labeled examples needed for training the models in a supervised manner.
4. Enhancing Generalization: Data annotation helps models generalize patterns from the labeled data to new, unseen data. By exposing the models to a diverse range of annotated examples, they can learn to recognize and predict patterns in real-world scenarios.
5. Domain-specific Insights: Data annotation allows domain experts to add contextual information and insights to the labeled data. This domain expertise can be crucial in enhancing the accuracy and relevance of the annotations, especially in specialized fields such as healthcare, finance, or natural language processing.
6. Scaling Machine Learning Projects: Data annotation allows for the creation of large-scale annotated datasets, which are essential for training complex machine learning models. By annotating large volumes of data, organizations can build robust models that can handle diverse and real-world scenarios.
7. Continuous Model Improvement: Data annotation is an iterative process. As models make predictions and encounter new data, the feedback loop of data annotation helps refine and improve the models over time. This continuous improvement ensures that the models adapt to changing trends and patterns.
In the next section, we will explore the different types of data annotation methods used in machine learning.
Types of Data Annotation
Data annotation involves various methods and techniques to assign annotations to different types of data. Here are some common types of data annotation used in machine learning:
1. Image Annotation: Image annotation involves labeling objects, regions, or attributes within an image. It can include bounding box annotations, where a rectangular box is drawn around an object of interest, or polygon annotations for more complex shapes. Other types of image annotation include semantic segmentation, where each pixel is labeled with a specific class, and landmark annotation, which marks specific points of interest within an image.
2. Text Annotation: Text annotation involves labeling or tagging specific elements within textual data. This can include Named Entity Recognition (NER), where entities such as names, locations, or organizations are identified and labeled within the text. Sentiment analysis annotation involves evaluating the sentiment expressed in the text, such as positive, negative, or neutral. Text classification annotation assigns predefined categories or labels to the text, enabling classification tasks.
3. Audio Annotation: Audio annotation involves labeling or transcribing audio data. This can include speech recognition annotation, where spoken words are transcribed into text, or speaker diarization, which identifies and segments different speakers in the audio. Other audio annotation tasks include emotion recognition, music genre classification, or sound event detection.
4. Video Annotation: Video annotation involves labeling and annotating objects, actions, or events within a video. This can include object tracking, where objects are annotated over time to track their movement. Activity recognition annotation involves labeling specific actions or activities performed in the video. Video annotation is crucial in applications such as surveillance, autonomous vehicles, and video-based analysis.
5. Geospatial Annotation: Geospatial annotation involves labeling or tagging geographic and spatial data. This can include annotating points of interest, land cover types, or routes on maps. Geospatial annotation is pivotal in applications such as mapping, geolocation services, and GIS-based analysis.
6. Sensor Data Annotation: Sensor data annotation involves labeling or annotating data collected from sensors or IoT devices. This can include annotating sensor readings, sensor fusion data, or environmental data. Sensor data annotation is crucial in applications such as smart cities, environmental monitoring, and industrial automation.
These are just a few examples of the types of data annotation used in machine learning. Depending on the specific use case and requirements, different annotation methods can be employed to provide the necessary information for training and modeling purposes.
In the next section, we will explore the processes of manual data annotation and automated data annotation.
Manual Data Annotation
Manual data annotation involves human annotators carefully reviewing and labeling the data based on predefined annotation guidelines or schema. It is a labor-intensive process that requires domain expertise and attention to detail. Here are the key steps involved in manual data annotation:
1. Annotation Guidelines: Before starting the annotation process, clear and detailed annotation guidelines are established. These guidelines define the annotation schema, the specific categories or labels to be assigned, and any specific instructions or guidelines for handling complex cases.
2. Selection of Annotators: Annotators with relevant domain knowledge and expertise are selected for the annotation task. These annotators should be familiar with the annotation guidelines and have a good understanding of the data to ensure accurate and consistent annotations.
3. Annotation Process: Annotators carefully review the data and assign the appropriate labels, annotations, or tags according to the defined guidelines. They follow the annotation schema and consider the context and nuances of the data to ensure accurate and meaningful annotations.
4. Quality Assurance: To maintain accuracy and consistency, a quality assurance process is implemented. This involves regular checks on the annotated data to identify any errors, inconsistencies, or discrepancies. Feedback and clarifications are provided to annotators to ensure high-quality annotations throughout the process.
5. Iterative Refinement: Manual annotation is an iterative process that involves continuous feedback and refinement. As annotators gain more experience and encounter challenging cases, the annotation guidelines may be updated to provide clearer instructions or guidelines. This iterative refinement ensures that the annotations align with the desired quality and accuracy.
6. Annotator Collaboration: Collaboration and communication among annotators are crucial for maintaining consistency and resolving any doubts or ambiguities. Regular meetings or discussions can help address any challenges, share insights, and ensure a common understanding of the annotation guidelines.
7. Time and Resource Management: Manual data annotation can be time-consuming and resource-intensive. Proper management of time, resources, and workloads is essential to maintain productivity and meet project deadlines. This can involve effective task allocation, workload balancing, and careful scheduling.
Manual data annotation allows for human expertise and contextual understanding to be incorporated into the annotation process. It is particularly suitable for tasks that require a high level of accuracy, nuanced interpretation of data, or domain-specific knowledge. However, it can be challenging to scale manual annotation for large-scale datasets or when tight deadlines are present.
In the next section, we will explore automated data annotation methods and their benefits and limitations.
Automated Data Annotation
Automated data annotation techniques leverage machine learning algorithms and pre-existing models to assign annotations to data automatically. These methods aim to reduce the manual effort and time required for data annotation. Here are some common automated data annotation methods:
1. Pre-trained Models: Automated data annotation can utilize pre-trained models that have been trained on large annotated datasets. These models can automatically assign annotations to new, unlabeled data based on the patterns and features they have learned from the training data. Pre-trained models are particularly useful for tasks such as image classification, object detection, or text classification.
2. Transfer Learning: Transfer learning involves using a pre-trained model as a starting point and fine-tuning it with a smaller annotated dataset specific to the target task. This approach leverages the knowledge learned from a larger, more diverse dataset to make faster and more accurate annotations on the target data.
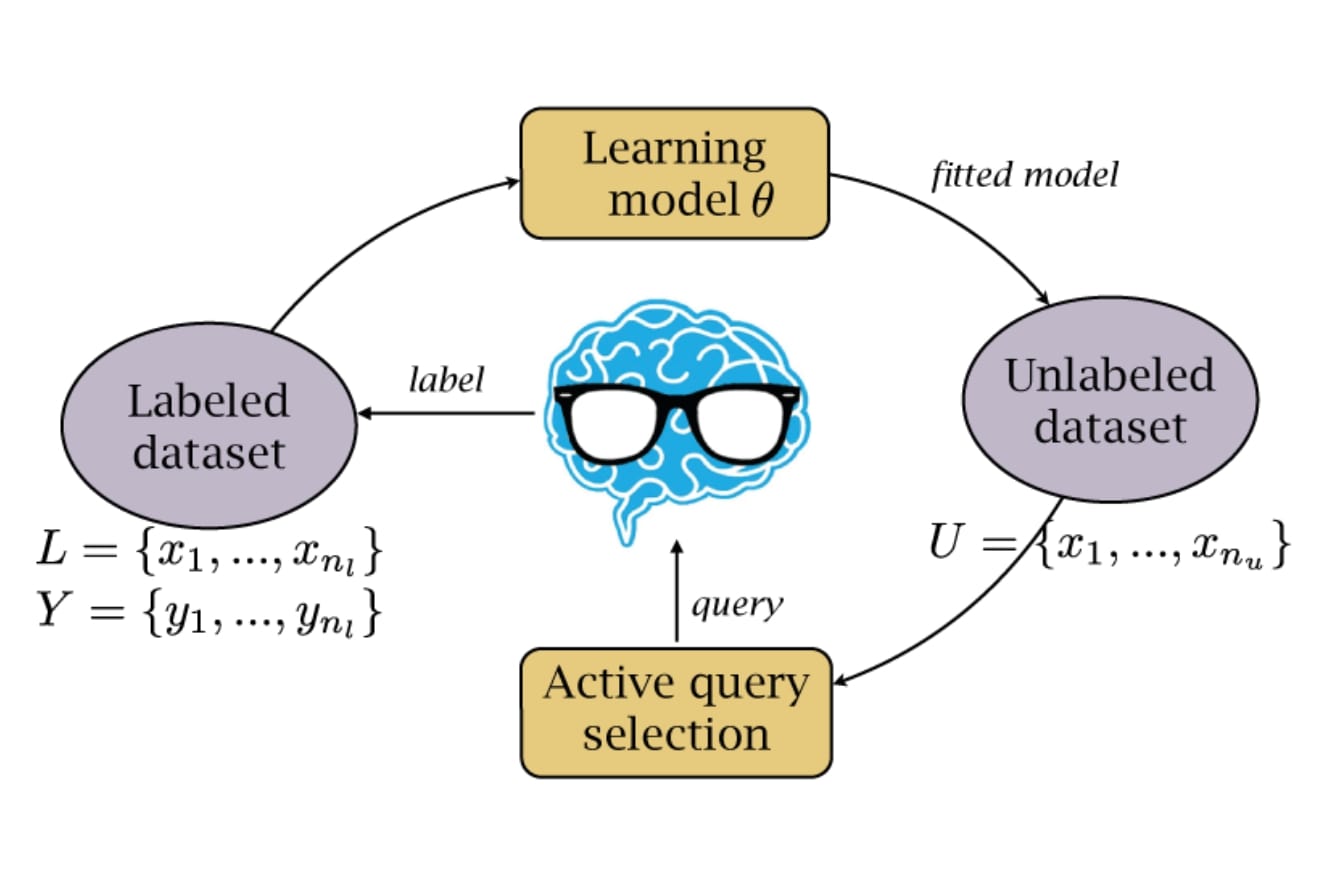
3. Active Learning: Active learning techniques involve an iterative process where the machine learning algorithm selects the most valuable or uncertain instances in the unlabeled data for annotation by human annotators. This minimizes the amount of manual annotation required while maximizing the accuracy and efficiency of the annotation process.
4. Weak Supervision: Weak supervision techniques leverage noisy or imperfect labels to annotate data automatically. Instead of relying solely on human annotators, weak supervision uses heuristics, expert rules, or other sources of information to generate annotations. While not as accurate as manual annotation, weak supervision can still provide useful annotations at a larger scale.
5. Crowdsourcing: Crowdsourcing platforms allow multiple annotators to collaborate and collectively annotate large datasets. These platforms provide annotation tasks to a crowd of human workers who follow specific guidelines or annotation rules. The collective effort of multiple annotators helps ensure accuracy and diversity in the annotations.
6. Active Learning with Human in the Loop: This approach combines the benefits of active learning with human intervention. The machine learning algorithm initially selects the most valuable instances for annotation, but these instances are then reviewed and corrected by human annotators. This iterative process helps refine the annotations and improve the overall quality of the data.
Automated data annotation methods offer several advantages, including increased annotation efficiency, scalability for large datasets, and reduced cost. However, they also come with limitations, such as the dependency on pre-existing models, the risk of introducing biases, and the challenge of handling complex or ambiguous cases that may require human judgment and expertise.
In the next section, we will discuss the challenges faced in the data annotation process and how to overcome them.
Challenges in Data Annotation
Data annotation is a complex and challenging process that comes with its own set of difficulties. Here are some common challenges faced in the data annotation process:
1. Ambiguity and Subjectivity: Data can often contain ambiguous or subjective elements that make it challenging to assign clear annotations. Annotators may interpret data differently, leading to inconsistencies and variations in the annotations. Clear annotation guidelines and regular communication among annotators can help address these challenges.
2. Domain Expertise: Certain domains require specialized knowledge and expertise to accurately annotate the data. Annotators need to understand the context, nuances, and domain-specific terminology to provide meaningful annotations. Collaborating with domain experts or providing specific training to annotators can help overcome this challenge.
3. Scalability: Scaling the annotation process to handle large volumes of data can be a significant challenge. Manual annotation processes may not be feasible when dealing with massive datasets. In such cases, automated annotation methods or leveraging crowdsourcing platforms can help increase scalability and efficiency.
4. Time and Cost Constraints: Data annotation can be time-consuming and costly, especially when manual annotation is involved. Meeting project deadlines and managing annotation budgets can be challenging. Efficient planning, resource management, and automation can help address these constraints.
5. Quality Control: Ensuring the quality and consistency of annotations is critical for training reliable machine learning models. Inconsistencies, errors, or biases in annotations can negatively impact model performance. Implementing a thorough quality control process, including regular checks, feedback loops, and inter-annotator agreement assessments, helps maintain annotation quality.
6. Bias and Annotation Errors: Bias can be introduced during the annotation process, which can lead to biased models and algorithmic discrimination. Annotators’ subjective judgments, personal biases, or inconsistent annotation guidelines can contribute to bias. Providing explicit guidelines, diverse annotator teams, and regular quality checks can help mitigate bias and minimize annotation errors.
7. Ever-changing Data: Data annotation can be a continuous process, particularly when dealing with dynamic datasets or evolving tasks. As new data becomes available or annotation requirements change, the annotations need to be updated or refined to adapt to the evolving needs. Flexibility and adaptability in the annotation process are crucial to overcome this challenge.
Addressing these challenges requires careful planning, effective communication, thorough annotation guidelines, quality control measures, and leveraging technology and automation where possible. Overcoming these challenges ensures the production of high-quality, reliable annotations that contribute to accurate and effective machine learning models.
In the next section, we will explore best practices for data annotation to ensure high-quality annotations and successful machine learning models.
Best Practices for Data Annotation
Data annotation is a critical step in developing accurate and reliable machine learning models. Here are some best practices to follow when performing data annotation:
1. Clear Annotation Guidelines: Develop clear and detailed annotation guidelines that define the annotation schema, labeling conventions, and any specific instructions or edge cases. Clear guidelines ensure consistency and accuracy during the annotation process.
2. Training and Calibration: Provide thorough training and calibration sessions to annotators to ensure a common understanding of the annotation guidelines and the desired annotation quality. Regular calibration exercises can help maintain consistency among the annotators.
3. Quality Control Measures: Implement quality control checks throughout the annotation process to identify and rectify any errors, inconsistencies, or biases. Conduct regular checks and feedback sessions with annotators to address any issues and maintain annotation quality.
4. Inter-Annotator Agreement: Assess the agreement levels between different annotators for the same set of data to ensure consistency. Employ techniques such as measuring inter-annotator agreement scores, like Cohen’s kappa, to quantify the degree of agreement between annotators.
5. Continuous Feedback Loop: Establish a feedback loop with annotators to address their questions, challenges, and clarifications promptly. Regular communication and feedback help enhance the annotation process and ensure the accuracy and quality of the annotations.
6. Collaboration and Communication: Foster collaboration and communication among annotators to address any doubts or ambiguities. Encourage annotators to share insights, seek clarification, and discuss challenging cases to ensure a common understanding and consistent annotations
7. Documentation: Maintain comprehensive documentation of the annotation process, including guidelines, feedback, and any updates or modifications made along the way. Detailed documentation ensures transparency, reproducibility, and ease of onboarding for new annotators.
8. Understanding Data Bias: Be aware of potential biases in the data and annotations. Take steps to mitigate biases by ensuring diverse annotator teams, examining potential sources of bias, and implementing measures to address them.
9. Iterative Refinement: Treat data annotation as an iterative process and embrace continuous improvement. As models learn from annotations and encounter new data, refine the annotation guidelines and processes to adapt to changing requirements and improve annotation quality.
10. Use Automation Where Applicable: Leverage automated annotation methods, such as pre-trained models or active learning, to increase annotation efficiency and scalability. Automating repetitive or less subjective annotation tasks can free up time for annotators to focus on more complex cases.
By following these best practices, organizations can achieve high-quality annotations, resulting in more accurate and reliable machine learning models. The process of data annotation requires attention to detail, collaboration, and adherence to best practices to ensure successful outcomes.
In the next section, we will summarize the key points discussed and highlight the importance of data annotation in the machine learning workflow.
Conclusion
Data annotation plays a vital role in the success of machine learning models by providing labeled data that enables the models to learn and make accurate predictions. It involves assigning annotations, labels, or metadata to raw data, creating structured and meaningful datasets for training. Whether performed manually by human annotators or utilizing automated techniques, data annotation is crucial for building accurate and reliable machine learning models.
Throughout this article, we explored the importance of data annotation in machine learning, discussing its role in training models, improving performance, and enabling supervised learning. We also examined the different types of data annotation, including image annotation, text annotation, audio annotation, video annotation, geospatial annotation, and sensor data annotation.
We delved into the challenges faced in the data annotation process, such as ambiguity, scalability, time constraints, quality control, bias, and ever-changing data. It is crucial to address these challenges using best practices, including clear annotation guidelines, training and calibration, quality control measures, continuous feedback, and effective collaboration.
While manual data annotation allows for human expertise and domain understanding, automated data annotation methods provide scalability, efficiency, and cost savings. Employing a combination of manual and automated techniques can yield optimal results, ensuring accurate annotations while managing large-scale datasets.
Data annotation is a continuous and iterative process that requires regular evaluation, refinement, and adaptation. By following best practices and staying attuned to data biases and emerging trends, organizations can produce high-quality annotations and develop robust machine learning models that deliver reliable predictions and insights.
In conclusion, data annotation is a crucial step in the machine learning workflow, enabling models to learn from labeled data and make accurate predictions. It fosters the growth and development of machine learning algorithms, accelerating their deployment and impact across various industries. By investing time, effort, and resources in data annotation, organizations can unlock the full potential of machine learning technology and drive innovation in an increasingly data-driven world.