Introduction
Creating an image dataset is a crucial step in building robust and accurate machine learning models. Whether you are working on object detection, image classification, or any other computer vision task, a well-curated dataset is essential to train and evaluate your model effectively. By providing the model with a diverse range of images, you enable it to generalize well and make accurate predictions on unseen data. In this article, we will explore the step-by-step process of creating an image dataset for machine learning.
The process of creating an image dataset involves several key steps, including finding and downloading images, cleaning and organizing the data, labeling the images, augmenting the dataset, splitting it into training and testing sets, preprocessing the images, and finally uploading the dataset to a machine learning platform. Each step plays a crucial role in preparing the dataset for training and evaluation.
Effective data collection is the foundation of any successful machine learning project. It begins with finding and downloading relevant images that align with your project’s objectives. This may involve searching for images online, using web scraping techniques, or leveraging existing image databases. The key is to ensure that the downloaded images cover a wide range of scenarios and variations relevant to your task.
Once you have acquired the images, it is important to clean and organize the data. This involves removing duplicates, correcting any labeling errors, and organizing the images into appropriate directories or folders. By maintaining a clean and well-structured dataset, you can avoid potential confusion or inaccuracies during the training process.
Labeling the images is a crucial step in supervised learning tasks. It involves assigning specific tags or categories to each image, enabling the model to learn the relationship between the input data and their corresponding labels. Proper labeling ensures that the model can accurately classify or detect objects within the images. There are various tools and frameworks available that facilitate the labeling process, ranging from manual labeling to utilizing advanced labeling software.
To improve the diversity and robustness of the dataset, augmentation techniques can be applied. Augmentation involves applying various transformations to the images, such as rotations, translations, flips, and changes in color and contrast. This artificially expands the dataset and helps the model generalize better to unseen variations in the real-world scenarios.
Finding and downloading images
The first step in creating an image dataset for machine learning is to find and download relevant images. The goal is to gather a diverse range of images that cover various aspects and scenarios related to your project. Here are some approaches to consider for finding and acquiring images:
- Search engines: Utilize search engines like Google or Bing to search for specific image categories or keywords. You can use advanced search filters to find high-resolution images or specify the usage rights to ensure they are free to use for your project.
- Online image databases: There are numerous online image databases available, such as Unsplash, Pexels, and Flickr, that provide a wide variety of images in different categories. These platforms often have search functionalities that allow you to narrow down your search based on specific criteria.
- Web scraping: If you need a large number of images, you can employ web scraping techniques to extract images from websites. However, it is important to comply with ethical guidelines and respect website terms of service while scraping.
- Specialized image datasets: Depending on your project’s requirements, there may be specialized image datasets available in your domain. These datasets can be sourced from academic research papers, open-source projects, or specific communities related to your field.
Once you have identified the sources, it’s time to download the images. You can either manually download them one by one or use automated web scraping tools to bulk download images from a given source. However, ensure that you have the necessary permissions and rights to download and use the images for your intended purpose.
It is recommended to collect a substantial number of images to create a balanced and representative dataset. The quantity of images required depends on the complexity of your machine learning task and the diversity of the target classes. Aim for a sufficient number of images per category to allow your model to learn the distinguishing features of each class effectively.
During the image collection process, it is essential to consider the quality and diversity of the images. Ensure that the images are of high resolution and clarity, as low-quality images may negatively impact the performance of your machine learning model. Additionally, strive for diversity in terms of lighting conditions, backgrounds, angles, and object variations to ensure that your model generalizes well to unseen data.
In this step, it is advisable to save the images in a well-organized directory or folder structure. This will make it easier to handle and process the images during the subsequent steps of dataset creation. Consider creating separate folders for different classes or categories, and give meaningful names to the images that reflect their content.
By following these steps, you can effectively find and download a diverse set of images to create your image dataset. Remember to respect copyright and usage rights while acquiring the images, and ensure that you have the necessary permissions to use them for your machine learning project.
Cleaning and organizing the images
Once you have gathered a collection of images for your dataset,
the next step is to clean and organize the data. Cleaning the data involves removing duplicate images, correcting labeling errors, and ensuring the dataset is free from any inconsistencies that may impact the performance of your machine learning model.
The first task in the cleaning process is to identify and remove any duplicate images. Duplicate images can introduce bias and redundancy into your dataset, which can negatively impact the model’s training and evaluation. Various tools and techniques are available to detect and remove duplicates, ranging from simple file comparison methods to more advanced algorithms that analyze image content.
Labeling errors can occur during the initial labeling process or when downloading images from external sources. It’s crucial to review the labels assigned to each image and make corrections if necessary. This ensures that your dataset accurately represents the desired categories or classes that your model will learn from.
Organizing the images is another essential step in creating an effective dataset. A well-structured directory or folder system makes it easier to handle and process the images during training and evaluation. Consider creating separate folders for each class or category and give meaningful names to the image files. This will help maintain clarity and organization throughout the dataset.
Furthermore, it is recommended to remove any irrelevant or unnecessary images from the dataset. Unwanted images may include duplicates, mislabeled images, or images that do not fit the scope of your project. By keeping only the relevant images, you can ensure that your machine learning model focuses on learning the salient features of the target classes.
In addition to cleaning and organizing the images, it is important to check for any inconsistencies or anomalies in the dataset. This can include images that are excessively bright, have extreme color variations, or contain artifacts that may affect the model’s performance. You may need to manually review and adjust such images or apply preprocessing techniques to mitigate these issues.
By dedicating time and effort to clean and organize your image dataset, you set the foundation for training a high-quality machine learning model. Removing duplicates, correcting labeling errors, and maintaining a well-structured dataset will enhance the model’s ability to learn the underlying patterns and make accurate predictions.
Remember that the process of cleaning and organizing the images is an iterative one. It may require several iterations and checks to ensure the dataset is of optimal quality. Regularly reviewing and refining the dataset will lead to better performance and more reliable results when training your machine learning model.
Labeling the images
Labeling the images is a crucial step in creating an image dataset for machine learning. It involves assigning specific tags or categories to each image, allowing the model to learn the relationship between the input data and their corresponding labels. Accurate and comprehensive labeling ensures that the model can effectively classify or detect objects within the images.
There are several approaches and tools available for labeling images. Here are some commonly used methods:
- Manual labeling: This approach involves manually viewing each image and assigning the appropriate label. It is a time-consuming process but allows for fine-grained control over the labeling. Manual labeling is ideal when dealing with a small and specialized dataset or when the images require expert-level judgment.
- External labeling services: There are various online platforms and labeling services available that provide a pool of human annotators who can label the images for you. These services offer faster labeling turnaround times and are particularly useful when dealing with large-scale datasets or tight project deadlines.
- Automated labeling: Automated labeling utilizes machine learning algorithms or pre-trained models to automatically assign labels to images based on certain features or patterns. This approach can be useful when dealing with large datasets and can significantly reduce the manual labeling effort required.
When labeling the images, it is important to maintain consistency in the labeling scheme. Clearly define the categories or classes that your model will learn from and ensure that each image is assigned to the correct label. Consistent labeling allows the model to learn and generalize from the labeled examples, improving its ability to accurately classify or detect objects in real-world scenarios.
Labeling errors can occur, especially when dealing with complex or ambiguous images. Regular quality checks and calibration sessions with annotators, if using external labeling services, can help minimize such errors. It is also important to provide clear guidelines or annotation instructions to ensure uniformity and accuracy in the labeling process.
To enhance the performance of your model, it is beneficial to include multiple annotations or labels for each image. This is known as multi-labeling, where an image can be assigned to more than one category or class. Multi-labeling allows the model to learn the presence of different objects or attributes within the same image, enabling more detailed and nuanced predictions.
Remember to keep track of the labeling process, documenting the label assignments for each image. This documentation can be in the form of a CSV file, JSON file, or any other structured format that can be easily parsed and integrated into your machine learning pipeline.
By accurately and consistently labeling the images, you provide the necessary ground truth information that enables your machine learning model to learn and make predictions efficiently. Proper labeling is crucial to the success of your project and ensures that your model can effectively understand and interpret the visual content of the images.
Augmenting the dataset
Augmenting the dataset is an important step in creating a robust image dataset for machine learning. Augmentation involves applying various transformations and modifications to the images, artificially expanding the dataset size and introducing variations that improve the model’s generalization capabilities.
The goal of data augmentation is to expose the model to a wider range of scenarios and variations that it may encounter during real-world inference. By doing so, the model becomes more robust and less prone to overfitting on the specific examples present in the training dataset.
Here are some common techniques for augmenting the dataset:
- Rotation: Rotating the image by a certain angle (e.g., 90 degrees, 180 degrees) introduces variations in object orientations and perspectives. This helps the model learn to recognize objects from different angles.
- Translation: Shifting the image horizontally or vertically creates additional examples where the objects are located at different positions within the image. This aids the model in learning to recognize objects regardless of their location.
- Scaling: Resizing the image to larger or smaller dimensions introduces variations in object sizes. This teaches the model to handle objects at different scales and improves its ability to detect objects in images of varied resolutions.
- Flip: Flipping the image horizontally or vertically allows the model to learn from both original and mirrored representations of objects. This enhances the model’s robustness to object orientations.
- Color and contrast manipulation: Modifying the color balance, brightness, or contrast of the image introduces variations in lighting conditions. This helps the model adapt to images captured under different lighting environments.
- Noise addition: Adding random noise to the image simulates real-world imperfections and introduces further variations. This encourages the model to be less sensitive to noise and artifacts in the images it encounters during inference.
It is important to apply data augmentation techniques in a manner that preserves the semantic information of the original image. The augmented images should still retain the same class or category as the original image so that the model can learn consistent representations.
While data augmentation can significantly enhance the robustness and generalization capabilities of the model, it is essential to strike a balance. Applying excessive augmentation may introduce unrealistic variations that do not align with real-world scenarios and may degrade the model’s performance. Therefore, it is recommended to experiment with different augmentation techniques and their respective parameters to find the optimal augmentation strategy for your specific dataset and machine learning task.
Data augmentation can be performed using various libraries and frameworks in popular programming languages such as Python. These libraries provide pre-defined functions and pipelines to apply augmentation techniques efficiently. By augmenting your dataset, you create a more diverse and representative set of images that empower your model to perform well on a wide range of real-world scenarios.
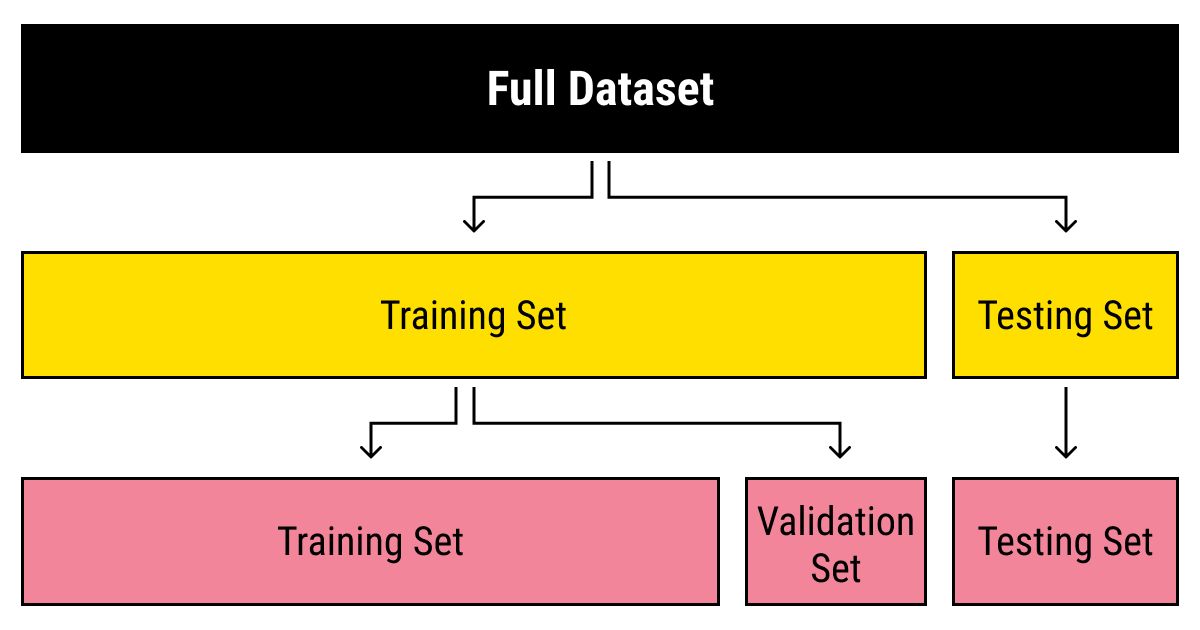
Splitting the dataset into training and testing sets
Splitting the dataset into separate training and testing sets is a crucial step in evaluating the performance and generalization capability of your machine learning model. This division allows you to train the model on a subset of the data and assess its performance on unseen examples.
The general rule of thumb is to allocate the majority of the dataset for training and a smaller portion for testing. The exact ratio may vary depending on factors such as the size of the dataset, the complexity of the task, and the availability of labeled data. A commonly used split is 80% for training and 20% for testing, but you can adjust the ratio based on your specific requirements.
The training set is used to train the model’s parameters by exposing it to labeled examples. This enables the model to learn the underlying patterns and relationships between the input data and the corresponding labels. The training set should be representative and diverse, covering various classes and variations within those classes.
The testing set, on the other hand, is used to evaluate the model’s performance on unseen data. It serves as a benchmark to assess how well the model generalizes from the training set to new examples. The testing set should be independent of the training set, ensuring that the model is evaluated on instances it has not been exposed to during training.
It is important to randomize the data before splitting to avoid any potential biases or order-dependent patterns. Randomization helps in ensuring that the training and testing sets have a fair representation of the overall dataset.
When splitting the dataset, you should ensure that the class distribution is maintained in both the training and testing sets. This prevents any imbalance in the data that may affect the model’s performance. Several techniques, like stratified sampling, can be employed to achieve balanced class distributions in each set.
During the training phase, it is crucial not to evaluate the model’s performance on the testing set. This can lead to overfitting, where the model memorizes the testing set rather than learning generalizable patterns. To monitor the model’s progress during training, it is common to further split the training set into training and validation subsets. The validation set is used to tune the model’s hyperparameters and make decisions regarding model selection and optimization.
By splitting the dataset into training and testing sets, you can evaluate your model’s performance accurately and make informed decisions about its readiness for deployment. This separation helps in highlighting any issues such as overfitting or underfitting, guiding further improvements in the model’s architecture and training process.
Preprocessing the images
Preprocessing the images is a crucial step in preparing the dataset for machine learning. It involves transforming and enhancing the images before feeding them into the model. Preprocessing techniques can improve the model’s performance by reducing noise, standardizing input formats, and extracting important features from the images.
Here are some common preprocessing steps applied to images:
- Resizing: Resizing the images to a consistent size is necessary to ensure uniformity in input dimensions for the model. This helps in avoiding computational complexities and allows the model to process the images efficiently.
- Normalization: Normalizing the pixel values of the images to a standardized range, such as [0, 1] or [-1, 1], helps in reducing the impact of different lighting conditions or color variations. This ensures that the model treats all images consistently regardless of their original pixel value distributions.
- Grayscale conversion: Converting the images to grayscale can be beneficial when the color information is not crucial for the task. Grayscale images reduce the computational burden and simplify the model’s learning process.
- Image enhancement: Applying techniques such as contrast adjustment, histogram equalization, or sharpening can enhance the visual quality and improve the model’s ability to extract important features from the images. These techniques can enhance edges, details, and overall image quality.
- Cropping and centering: Removing irrelevant backgrounds or cropping images to focus on the objects of interest can help reduce noise and distractions. Additionally, centering the objects can help the model learn their relative positions and orientations more effectively.
- Data augmentation: Although data augmentation is typically performed before preprocessing, it can also be considered as a part of the overall preprocessing pipeline. Applying data augmentation techniques, as discussed in section 4, can further enhance the dataset’s diversity and improve the model’s generalization.
The choice of preprocessing techniques depends on the nature of the task, the characteristics of the dataset, and the requirements of the model. It is important to strike a balance between applying necessary preprocessing steps and preserving the essential information within the images. Over-preprocessing or aggressive feature extraction can result in the loss of valuable details and hinder the model’s performance.
It is recommended to experiment with different preprocessing techniques and evaluate their impact on the model’s performance through validation or cross-validation. This iterative process helps in identifying the optimal preprocessing pipeline for your specific machine learning project.
Implementing the preprocessing pipeline efficiently is crucial to ensure fast and scalable training and inference. Utilizing libraries, frameworks, or hardware acceleration can speed up the preprocessing process, especially when dealing with large datasets.
By applying appropriate preprocessing techniques, you can enhance the quality of the images and extract important features that facilitate the model’s learning process. Preprocessing plays a vital role in improving the model’s accuracy, reducing noise and bias, and ensuring that the images are represented in a standardized and informative manner.
Uploading the dataset to a machine learning platform
Once you have prepared and preprocessed your image dataset, the next step is to upload it to a machine learning platform or framework. Uploading the dataset to a dedicated platform provides a convenient and efficient way to train, evaluate, and deploy your machine learning models.
There are several machine learning platforms available that offer features for dataset management, training, and model deployment. Here are some steps to consider when uploading your dataset:
- Data format: Ensure that your dataset is in a compatible format supported by the machine learning platform you are using. Commonly used formats for image datasets include JPEG, PNG, or any other format that can be easily read and processed by the platform’s tools and libraries.
- Data ingestion: Some platforms provide specific APIs or tools for uploading datasets. These tools allow you to seamlessly upload your preprocessed dataset to the platform’s storage or file system. Use the provided tools to efficiently upload your dataset.
- Dataset splitting: If you haven’t already split your dataset into training and testing sets, some machine learning platforms offer built-in functionalities to perform this split. Alternatively, you can split the dataset beforehand and upload the separate training and testing sets to the platform.
- Data labeling: If your dataset requires additional labeling or annotation, there are platforms that offer annotation tools and workflows to assist with the labeling process. These tools allow you to label your dataset directly within the platform interface, making it easier to manage and maintain the labeled data.
- Data versioning and management: Machine learning platforms often provide features for versioning and managing your datasets. These features enable you to keep track of dataset updates, access previous versions, and ensure reproducibility in your experiments and model training.
- Data verification: Before initiating the training process, it is crucial to verify that the uploaded dataset is correctly ingested and accessible. Some platforms provide data verification mechanisms to ensure the integrity and consistency of the dataset. Verify the dataset on the platform to confirm that it matches your expectations.
Once your dataset is uploaded and stored in the machine learning platform, you can start leveraging the platform’s tools and resources for training and evaluating your model. The platform will provide APIs, libraries, and pre-configured environments tailored for machine learning tasks, allowing you to efficiently train your models on the uploaded dataset.
Additionally, many platforms offer visualization tools, metrics tracking, and collaboration features to facilitate the model training process. These features enable you to monitor the model’s performance and collaborate with team members or stakeholders throughout the training and evaluation phase.
When uploading sensitive or confidential data, ensure that the machine learning platform you choose maintains high security standards and provides appropriate data protection measures.
By uploading your dataset to a dedicated machine learning platform, you can take advantage of the platform’s resources and tools, simplify the training process, and effectively manage your dataset throughout the machine learning lifecycle.
Conclusion
Creating an image dataset for machine learning is a crucial step in building accurate and robust models. From finding and downloading images to preprocessing and uploading the dataset, each step is essential in preparing the data for effective model training and evaluation.
Finding and downloading relevant images from trusted sources forms the foundation of a high-quality dataset. Cleaning and organizing the images ensure data consistency and eliminate duplicates or labeling errors. Labeling the images accurately provides the ground truth information necessary for the model to learn and make accurate predictions. Augmenting the dataset with various transformations increases diversity and enables the model to handle unseen variations. Splitting the dataset into training and testing sets allows for proper evaluation of the model’s performance.
Preprocessing the images enhances the dataset by normalizing, resizing, and extracting relevant features. Finally, uploading the dataset to a machine learning platform offers convenient dataset management, training, and deployment features to streamline the machine learning process.
It is important to approach each step with care and consideration, ensuring that the dataset is representative, diverse, and accurate. Adhering to best practices and utilizing suitable tools and techniques can significantly impact the performance and reliability of the resulting machine learning models.
Remember, creating an image dataset is an iterative process, and it may require multiple iterations to refine and improve the dataset quality. Regular evaluation, validation, and collaboration with domain experts can help to further enhance the dataset and improve the model’s performance.
By following the steps outlined in this article and continuously refining the dataset, you can create a high-quality image dataset that empowers your machine learning models to make accurate predictions and drive meaningful insights in various computer vision tasks.