Introduction
Welcome to the world of machine learning! As you embark on your journey to build powerful and intelligent models, one of the most crucial steps is creating a high-quality dataset. A dataset is a collection of data points or examples that serve as the basis for training, validating, and testing your machine learning algorithms.
Machine learning models are only as good as the data they are trained on. Therefore, it is essential to have a well-curated dataset that is representative of the problem you are trying to solve. In this article, we will guide you through the process of creating a dataset for machine learning.
The process of creating a dataset involves several key steps, such as defining the problem, collecting data, preprocessing the data, exploring the data, splitting the dataset, transforming the data, and finalizing the dataset. Each step plays a vital role in ensuring the quality and efficacy of your dataset.
Before diving into the specific steps, it is important to understand the significance of a good dataset. A well-designed dataset provides the necessary inputs and outputs to train your machine learning model effectively. It should contain a sufficient number of diverse and representative examples to enable the model to learn patterns and make accurate predictions.
Creating a dataset can be a time-consuming and iterative process. It involves careful consideration of the problem you are trying to solve, the sources of data available to you, and the preprocessing techniques required to clean and transform the data into a usable format.
In the following sections, we will delve into each step of creating a dataset, providing practical tips and insights along the way. By the end of this article, you will have a solid understanding of how to create a dataset that sets the foundation for successful machine learning endeavors.
What is a Dataset?
In the context of machine learning, a dataset refers to a structured collection of data points or examples that are used to train, validate, and test machine learning algorithms. It serves as the foundation for building intelligent models that can make predictions, classifications, or identify patterns in new, unseen data.
A dataset typically consists of two main components: features and labels. Features are the attributes or characteristics of the data that are used as inputs to the machine learning model. Examples of features could be the age, gender, or income of a person, or the pixel values of an image. Labels, on the other hand, are the desired outputs or target values that the model aims to predict or classify based on the given features.
Datasets come in various forms, depending on the type of machine learning task at hand. They can be categorized into three main types:
- Regression Datasets: These datasets are used when the machine learning task involves predicting a continuous numerical value. For example, predicting the price of a house based on its features such as the number of bedrooms, square footage, and location.
- Classification Datasets: Classification datasets are used when the task involves assigning a label or class to a given set of features. For instance, classifying emails as spam or non-spam based on their content and metadata.
- Clustering Datasets: Clustering datasets are used when the goal is to group similar data points together based on their similarities or distances. This type of dataset does not have predefined labels and is often used for exploratory analysis.
It is important to note that a dataset should be both representative and balanced. Representativeness ensures that the dataset captures the full spectrum of data that the model is likely to encounter in the real world. A balanced dataset ensures that each class or category is adequately represented, preventing the model from being biased towards a particular class.
Creating a dataset requires careful planning and consideration. It involves gathering relevant data from various sources, preprocessing and cleaning the data, and ensuring the appropriate split between training, validation, and testing subsets. By building a high-quality dataset, you set the stage for training accurate and robust machine learning models.
Step 1: Define the Problem
The first and most crucial step in creating a dataset for machine learning is to clearly define the problem you intend to solve. By having a clear problem statement, you can determine the type of data you need to collect and the features and labels that are relevant to the problem.
Defining the problem involves understanding the goal of your machine learning project. Are you trying to build a model for predictive analysis, classification, or clustering? Defining the problem also includes identifying the target audience for your model and the specific requirements and constraints you need to consider.
To define the problem effectively, ask yourself the following questions:
- What is the goal: Clearly articulate the objective of your machine learning project. Are you trying to predict a numerical value, classify data into categories, or group similar data points?
- What data is needed: Determine the types of data you need to collect to solve the problem. Consider both the features (inputs) and labels (outputs). Decide which attributes or characteristics of the data are relevant to the problem and will contribute to the model’s accuracy.
- What are the constraints: Identify any limitations or constraints that might impact your dataset creation process. This could include limited availability of data, privacy concerns, or budget restrictions.
- Who is the target audience: Understand who will be using or benefiting from your machine learning model. This will help you tailor your dataset to their specific needs and preferences.
By clarifying the problem statement, you can focus your efforts on collecting the right data and ensuring that it accurately represents the real-world scenarios your model will encounter. Take the time to gather domain knowledge and consult with experts in the field to gain a deeper understanding of the problem and its requirements.
Documenting your problem definition is essential for maintaining clarity and alignment throughout the dataset creation process. It will serve as a reference point when making decisions regarding data collection, preprocessing, and model evaluation.
Once you have a well-defined problem, you are ready to move on to the next step: collecting the necessary data.
Step 2: Collect Data
After defining the problem and understanding the data requirements, the next step in creating a dataset for machine learning is to collect the necessary data. Data collection involves acquiring relevant samples or data points that represent the real-world scenarios your model will encounter.
The process of data collection can vary depending on the nature of your problem and the availability of data sources. Here are some key considerations for collecting data:
- Identify data sources: Determine the potential sources of data that can provide the information you need. This could include public datasets, external websites, APIs, or internal databases. Consider the reliability, accessibility, and legality of the data sources.
- Data acquisition: Once you have identified the data sources, extract or access the data. This may involve web scraping, data downloading, or connecting to APIs. Ensure that you comply with any terms of use or legal requirements associated with the data sources.
- Data diversity: It is essential to collect a diverse range of data to ensure that your model is not biased towards specific patterns or scenarios. Consider collecting data from different regions, time periods, or demographics, depending on the problem at hand.
- Data quality assurance: When collecting data, pay attention to the quality and integrity of the data. Clean the data by removing any duplicates, outliers, or irrelevant information. Validate the data to ensure its accuracy and consistency.
- Data augmentation: In some cases, you may need to augment or generate additional data to supplement your existing dataset. This can be done through techniques such as data synthesis, image transformations, or text augmentation.
It is important to note that data collection can be a time-consuming and iterative process. As you explore and analyze the collected data, you may identify gaps or deficiencies that require additional data collection or refinement. Continuously evaluate the quality and relevance of the collected data to ensure the dataset is representative and comprehensive.
Documenting the data collection process is crucial for transparency and reproducibility. Keep track of the data sources, collection methods, and any preprocessing steps applied to the data. This documentation will help you maintain the integrity of the dataset and facilitate future updates or modifications.
Once you have collected the data, you are ready to move on to the next step: preprocessing the data to prepare it for analysis and modeling.
Step 3: Preprocess the Data
After collecting the raw data, the next step in creating a dataset for machine learning is to preprocess the data. Preprocessing involves transforming and cleaning the data to ensure it is in a suitable format for analysis and modeling.
Here are some key preprocessing steps to consider:
- Data cleaning: Clean the data by handling missing values, outliers, and inconsistencies. Depending on the nature of the data, you may choose to remove incomplete or erroneous samples, impute missing values, or apply outlier detection techniques.
- Data normalization: Normalize the data to ensure that each feature has a similar scale or range. This can prevent certain features from dominating the model’s learning process. Common normalization techniques include standardization (z-score normalization) and min-max scaling.
- Feature selection: Identify the most relevant features that contribute significantly to the problem you are solving. Eliminate irrelevant or redundant features to reduce the dimensionality of the dataset and improve model performance.
- Feature encoding: If your dataset contains categorical or textual features, you may need to encode them into numerical representations. Common encoding techniques include one-hot encoding, label encoding, and word embedding.
- Handling imbalanced data: If your dataset has imbalanced class distributions, where some classes are more prevalent than others, consider balancing techniques such as undersampling, oversampling, or using weighted loss functions to prevent bias in your model.
- Handling noisy data: Noisy data can introduce errors or inconsistencies in the learning process. Apply techniques such as smoothing, denoising, or filtering to reduce noise and improve the quality of the dataset.
During the preprocessing stage, it is crucial to maintain the integrity and representativeness of the data. Avoid introducing bias or distorting the original distribution of the features and labels. Regularly visualize and analyze the preprocessed data to ensure that it aligns with your problem statement.
Document the preprocessing steps you applied to the data, as this information is essential for reproducibility and future updates. It also helps you understand the impact of preprocessing on the model’s performance.
By preprocessing the data, you transform it into a clean and structured format that is ready for analysis and modeling. The next step is to explore the data and gain insights to inform further steps in the dataset creation process.
Step 4: Explore the Data
Once the data has been preprocessed, the next step in creating a dataset for machine learning is to explore the data. Exploring the data involves gaining insights and understanding the patterns, relationships, and distributions within the dataset.
Here are some key steps to consider during data exploration:
- Descriptive statistics: Calculate and analyze descriptive statistics for each feature in your dataset. This includes measures such as mean, median, standard deviation, and quartiles. Descriptive statistics provide a summary of the data and help identify any anomalies or unexpected patterns.
- Data visualization: Visualize the data using various charts, graphs, and plots. This can help you uncover trends, clusters, and relationships between features. Explore different types of visualizations such as histograms, scatter plots, box plots, and heatmaps.
- Feature correlations: Analyze the correlations between different features in your dataset. This can be done using correlation matrices or scatter plots. Understanding the relationships between features can provide insights into the interdependencies within the dataset.
- Data distributions: Examine the distributions of your features to understand their characteristics and potential biases. This can be done through histograms or density plots. Identifying skewed or imbalanced distributions can help you make informed decisions during modeling.
- Data anomalies: Look for any anomalies or outliers in your dataset. Outliers can significantly impact the performance of a machine learning model and should be either removed or treated accordingly. Use techniques such as statistical methods or visualization to detect outliers.
- Feature importance: Assess the importance of different features in your dataset for the problem you are solving. Use techniques such as feature importance ranking, such as correlation-based methods or machine learning algorithms like decision trees, to identify the most influential features.
Data exploration provides valuable insights into the characteristics and peculiarities of your dataset. It helps you understand the data better and make informed decisions during subsequent steps in the dataset creation process.
Document your data exploration findings, including any interesting observations or patterns you discover. This documentation will serve as a reference and can be used to validate the models you build on the dataset.
By exploring the data, you gain a deeper understanding of its properties and uncover insights that can guide you in the next steps of dataset creation, such as feature engineering or model selection.
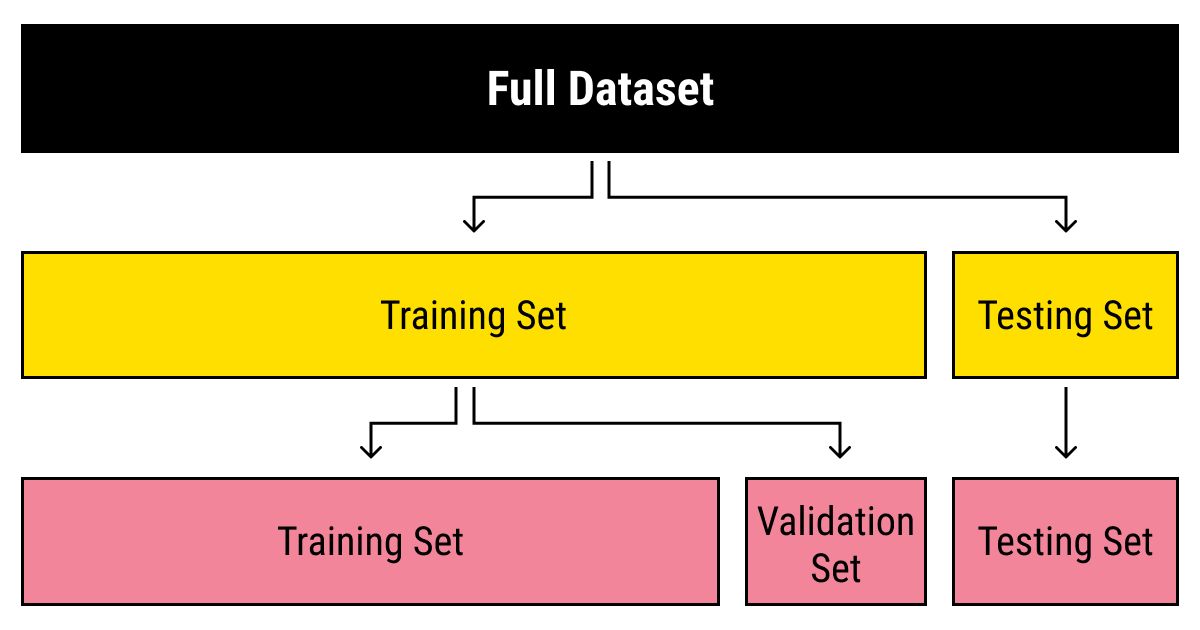
Step 5: Split the Dataset
After exploring the data, the next step in creating a dataset for machine learning is to split the dataset into training, validation, and testing subsets. Splitting the dataset helps evaluate the performance of the model and prevent overfitting.
Here are the typical splits used in machine learning:
- Training set: The training set is the largest portion of the dataset and is used to train the machine learning model. It should contain a sufficient amount of data to capture the patterns and relationships within the dataset.
- Validation set: The validation set is used to tune the hyperparameters of the model and assess its performance during training. It helps in selecting the best model by providing feedback on its generalization ability and preventing overfitting.
- Testing set: The testing set is used to evaluate the performance of the final trained model. It provides an unbiased estimate of how well the model is expected to perform on new, unseen data.
The split ratio between the subsets can vary depending on the size of the dataset and the specific problem you are tackling. Generally, an 80-20 or 70-30 split between the training and testing subsets is common, with a portion of the training set reserved for validation.
When splitting the dataset, ensure that the distribution of the classes or categories is preserved across all subsets. This prevents bias and ensures that the model is trained and evaluated on a representative sample of the data.
Random sampling is commonly used to split the dataset, but other techniques such as stratified sampling or time-based splitting can be applied depending on the nature of the data.
Document the split process and keep track of the data indices or identifiers used for each subset. This documentation will help you maintain consistency and reproduce the same split in future experiments or model improvements.
By splitting the dataset, you establish a framework for training, validating, and testing your machine learning model. It allows for robust evaluation and performance estimation before deploying the model to make predictions on new, unseen data.
Step 6: Transform the Data
Once the dataset has been split, the next step in creating a dataset for machine learning is to transform the data. Data transformation involves preparing the features and labels in a format that can be effectively used by the machine learning algorithms.
Here are some key considerations for transforming the data:
- Feature scaling: Scale the features to a similar range to avoid any biases that may arise from varying magnitudes. Common techniques include standardization (e.g., z-score normalization) or normalization (e.g., min-max scaling).
- Feature engineering: Create new features from the existing ones that can help the model capture more complex patterns or improve its predictive capabilities. Feature engineering involves applying mathematical transformations, combining existing features, or creating interaction terms.
- Handling categorical variables: Encode categorical variables into numerical representations that can be understood by the machine learning algorithms. This can be done using techniques like one-hot encoding, label encoding, or ordinal encoding.
- Handling temporal or sequential data: If your dataset includes temporal or sequential data, consider transforming it into a format that captures the temporal dependencies. This can be achieved through techniques such as lagging variables or using time-series analysis approaches.
- Dimensionality reduction: Reduce the dimensionality of the dataset by selecting a subset of the most important features, especially if the dataset has high dimensionality. This can be done using techniques like principal component analysis (PCA) or feature selection algorithms.
When transforming the data, it’s important to ensure consistency between the transformation applied during the training phase and how it’s applied during the inference phase when making predictions on new, unseen data.
Document the data transformation steps and any associated parameters or scaling factors applied. This documentation is crucial for reproducibility of the transformations and for applying the same transformations to new data in the future.
By transforming the data, you enhance the representation of the dataset and prepare it for effective modeling. The transformed data can capture complex relationships, reduce noise, and improve the model’s ability to make accurate predictions.
Step 7: Finalize the Dataset
The final step in creating a dataset for machine learning is to finalize the dataset by ensuring its readiness for model training and evaluation. This step involves performing a final check and making any necessary adjustments to ensure the dataset is in its best possible form.
Here are some key tasks to consider when finalizing the dataset:
- Data quality check: Perform a thorough data quality check to ensure the dataset is clean, consistent, and free from errors or inconsistencies. Validate the data against predefined quality criteria and address any anomalies or issues that may impact the model’s performance.
- Balancing class distributions: If your dataset has imbalanced class distributions, consider using techniques such as oversampling or undersampling to balance the number of samples from each class. This ensures that the model is not biased towards the majority class and can accurately learn from the minority class.
- Final feature selection: Revisit the feature selection process and ensure that the final set of features selected is relevant, informative, and aligned with the problem you are solving. Remove any features that may introduce noise or reduce the model’s interpretability.
- Ensure data privacy and security: If your dataset contains sensitive or personal information, ensure that appropriate measures are taken to protect data privacy and comply with relevant regulations. Consider techniques such as anonymization, encryption, or access control.
- Create documentation: Document all the steps performed during dataset creation, including data collection, preprocessing, exploration, and transformation. This documentation provides a clear understanding of the dataset’s characteristics and facilitates reproducibility.
Once you have finalized the dataset, make backups of the dataset files and store them in a secure location. It is important to maintain the integrity and availability of the dataset for future reference or updates.
By finalizing the dataset, you ensure that it is clean, balanced, and ready to be used for training and evaluating machine learning models. A well-prepared and documented dataset sets the foundation for accurate and insightful model development.
Conclusion
Creating a high-quality dataset is a vital step in the process of building successful machine learning models. A well-designed dataset provides the necessary inputs and outputs for training, validating, and testing the models, enabling them to make accurate predictions and classifications. The process of creating a dataset involves several key steps, including defining the problem, collecting data, preprocessing the data, exploring the data, splitting the dataset, transforming the data, and finalizing the dataset.
In Step 1, defining the problem ensures clarity and alignment with the overall objective of the machine learning project. This step helps identify the relevant data attributes and target variables essential for model training and evaluation.
Step 2 revolves around collecting the data from various sources and ensuring its representativeness and availability. Careful data acquisition and quality assurance are vital to producing a reliable dataset.
In Step 3, preprocessing the data involves cleaning, normalizing, and transforming the data into a format suitable for analysis and modeling. Outliers, missing values, and inconsistent data are addressed during this stage to enhance the dataset’s quality.
Step 4 focuses on exploring the data, visualizing its characteristics, and identifying patterns, correlations, and anomalies. Data exploration enables a deeper understanding of the dataset’s properties and guides subsequent steps in the dataset creation process.
Step 5 involves splitting the dataset into training, validation, and testing subsets. This allows for proper model evaluation, generalization assessment, and performance estimation before deploying the model on unseen data.
Step 6 entails transforming the data by scaling features, engineering new ones, encoding categorical variables, and reducing dimensionality. These transformations enhance the dataset’s representation and enable effective modeling.
Lastly, Step 7 involves finalizing the dataset by conducting a final quality check, addressing any imbalances, and documenting the dataset creation process. This ensures the dataset’s readiness for model training and evaluation.
By following these steps and implementing best practices, you can create a high-quality dataset that serves as a reliable foundation for building accurate and robust machine learning models. A well-crafted dataset increases the chances of achieving successful outcomes in various applications, from predictive analysis to classification and clustering tasks.