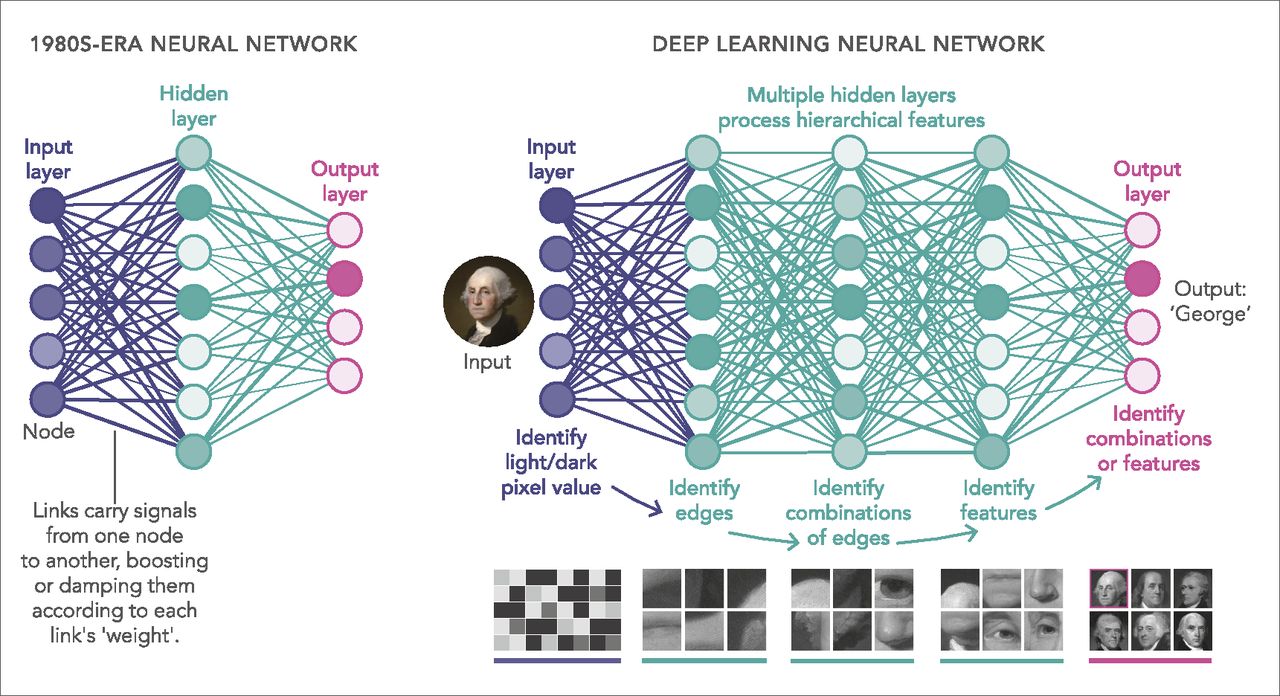
Why Image Processing is Important for Machine Learning
Machine learning algorithms heavily rely on data to make accurate predictions and classifications. When it comes to visual data, such as images, the role of image processing becomes crucial in improving the quality and usefulness of the data. Image processing involves various techniques and operations to enhance images, extract useful features, and prepare them for analysis by machine learning algorithms.
One of the main reasons why image processing is important for machine learning is the need to handle variability in images. Images can vary in terms of size, shape, orientation, lighting conditions, and noise levels. If these variations are not dealt with, it can negatively impact the performance of machine learning models. By applying image processing techniques, we can standardize the images, making them consistent in terms of size, orientation, and lighting, thus reducing the variability.
Another reason for image processing in machine learning is the extraction of meaningful features. Images contain a wealth of information, but not all of it is relevant for the task at hand. Image processing techniques, such as edge detection, filtering, and normalization, can help extract features that are important for the specific machine learning task. These features can be characteristics like edges, textures, colors, or shapes, which can then be used as inputs to the machine learning algorithm.
Furthermore, image processing plays a crucial role in preprocessing and cleaning the data for machine learning. Noisy or corrupted images can lead to inaccurate results. By applying filtering and denoising techniques, we can remove unwanted noise and artifacts from the images, ensuring that the machine learning algorithm focuses on the relevant information.
Additionally, image processing techniques can help in data augmentation, which is useful when the dataset is limited. Data augmentation involves creating new samples by applying transformations to the existing images, such as rotations, flips, or zooms. This increases the diversity and size of the dataset, which improves the generalization and performance of the machine learning models.
In summary, image processing plays a vital role in preparing images for machine learning. By standardizing images, extracting meaningful features, cleaning the data, and augmenting the dataset, image processing techniques enable machine learning algorithms to perform more accurately and efficiently. Therefore, incorporating image processing into the machine learning pipeline is essential for achieving better results in tasks involving visual data.
Preparing Your Dataset
Before diving into image processing techniques for machine learning, it is essential to ensure that your dataset is well-prepared. Preparing the dataset involves several steps that help optimize the quality and usability of the images for training machine learning models.
The first step in preparing your dataset is to gather a diverse and representative sample of images. The dataset should contain a wide range of images that cover different variations and scenarios relevant to your machine learning task. Including images with different backgrounds, lighting conditions, angles, and object positions will help the model learn to generalize and perform well on unseen data.
Once you have collected the images, it is crucial to label them appropriately. Labeling involves assigning correct class labels or annotations to each image. This step is essential for supervised learning, as it provides ground truth information that the model can learn from. Accurate and consistent labeling ensures that the machine learning algorithm receives the correct information during training.
Next, it is important to divide the dataset into training, validation, and testing sets. The training set is used to train the machine learning model, while the validation set helps tune the hyperparameters and monitor the model’s performance during training. The testing set is used to evaluate the final performance of the model on unseen data. This separation is crucial for assessing the model’s generalization ability and preventing overfitting.
After data partitioning, it is recommended to perform data preprocessing steps. This includes resizing and cropping the images to a standardized size. Standardizing the image size ensures that the machine learning model receives inputs of consistent dimensions. It also helps improve computational efficiency during training. Additionally, if there are images with irrelevant information or background noise, cropping can be used to remove unwanted regions and focus on the important objects or areas in the image.
Finally, it is essential to check the quality and integrity of the images in your dataset. This involves detecting and handling corrupt or missing images. Removing any incomplete or corrupted images prevents them from affecting the training process and ensures the reliability of the dataset.
In summary, preparing your dataset for image processing and machine learning involves gathering a diverse sample, labeling the images accurately, splitting the dataset into training/validation/testing sets, and performing preprocessing steps like resizing and cropping. Taking these steps ensures that your dataset is of high quality, manageable, and optimized for training machine learning models.
Image Resizing and Cropping
Image resizing and cropping are essential preprocessing steps in image processing for machine learning. These techniques allow us to standardize the size and aspect ratio of images, as well as focus on specific regions of interest within an image.
Resizing an image involves changing its dimensions while maintaining the aspect ratio. When working with a dataset that contains images of varying sizes, resizing them to a consistent size is crucial. This not only ensures compatibility with machine learning algorithms but also aids in reducing the computational complexity of the training process. Resizing is achieved by either scaling the image up or down, using interpolation algorithms to preserve the quality and details of the original image.
Cropping, on the other hand, involves selecting a specific region of interest within an image and discarding the rest. This technique is beneficial when the relevant information is concentrated in a specific area, and the surrounding background or irrelevant elements can be removed. Cropping helps in eliminating distractions and focusing the attention of the machine learning model on the critical features or objects of interest.
When resizing and cropping images, the aspect ratio should be considered to avoid distorting the content. It is important to maintain the original proportions of the image to prevent any unwanted stretching or squeezing. If the aspect ratio needs to be changed, it should be done carefully, taking into account the specific requirements of the machine learning task.
In addition to standardizing the size and aspect ratio, image resizing and cropping can also be used for data augmentation. By applying random crops or selecting different regions within an image, we can create additional training samples, increasing the variability and diversity of the dataset. This approach helps build more robust machine learning models that can generalize well to different scenarios.
It is worth noting that resizing and cropping should be applied consistently across the entire dataset to maintain fairness and prevent bias in the training process. Inconsistently resized or cropped images may affect the model’s ability to generalize effectively.
In summary, image resizing and cropping are important preprocessing techniques in image processing for machine learning. They help standardize the size and aspect ratio of images, focus on specific regions of interest, and create augmented training samples. By carefully applying these techniques, we can ensure compatibility, reduce computational complexity, and improve the model’s performance and generalization abilities.
Image Normalization
Image normalization is a crucial step in image processing for machine learning that aims to standardize the pixel values across images. This technique helps in reducing the influence of lighting conditions and improving the comparability of images within a dataset.
When capturing images, variations in lighting conditions, such as brightness and contrast, can cause significant differences in pixel intensities. Normalization seeks to remove these variations by scaling the pixel values to a common range. Typically, this involves rescaling the pixel values to fall within the range of 0 to 1 or -1 to 1.
Normalization is achieved by calculating the minimum and maximum pixel values in the image and mapping the original values to the desired range. This ensures that the brightest pixel in an image is mapped to 1 (or -1) and the darkest pixel to 0. Other pixel values are linearly scaled between these two extremes.
The normalization process can also involve other transformations, such as mean subtraction and standard deviation scaling. Mean subtraction involves subtracting the mean value of the pixel intensities from each pixel, resulting in a centered distribution around zero. Standard deviation scaling involves dividing the pixel values by the standard deviation of the pixel intensities, which helps in achieving unit variance. These additional transformations are particularly useful when training machine learning models that are sensitive to the scale and distribution of the input data.
Normalization is important for machine learning as it helps in improving the model’s ability to learn and generalize across different lighting conditions. By removing the lighting variations, the model can focus on the content and features of the image that are relevant to the task at hand. Additionally, normalization can also aid in preventing gradient explosion or vanishing during the optimization process, leading to more stable and efficient training.
It is important to note that normalization should be applied consistently across the entire dataset to maintain fairness and prevent bias. Inconsistently normalized images may introduce unwanted artifacts or biases in the training process, affecting the model’s performance.
In summary, image normalization is a critical step in image processing for machine learning. It standardizes the pixel values across images, reducing the influence of lighting conditions and improving comparability. Normalization enhances the model’s ability to learn and generalize across different lighting conditions, leading to more accurate and robust results.
Image Augmentation Techniques
Image augmentation is a powerful technique in image processing for machine learning that involves creating new training samples by applying various transformations to existing images. This technique helps increase the size and diversity of the dataset, which can improve the model’s performance and generalization ability.
One of the most common image augmentation techniques is rotation. By rotating the image at different angles, we can create new training samples that represent different orientations of the same object. Rotations can mimic real-life scenarios where objects may be viewed from different angles.
Flipping is another technique that can be applied horizontally or vertically. This simple transformation can create additional samples by mirroring the image and can be useful when the orientation of the object does not affect its classification or when the training data is limited.
Zooming is another augmentation technique that involves scaling the image either up or down. This can simulate images captured at different distances or magnifications and increases the dataset’s variability. Cropping, either random or centered, can also be considered an augmentation technique that removes unwanted backgrounds or focuses on specific regions of interest, similar to the cropping technique mentioned earlier.
Adding noise to images is another augmentation technique that helps the model learn robustness to noisy real-world data. Common types of noise include Gaussian noise, salt-and-pepper noise, or speckle noise. This technique can help the model generalize better in scenarios where the input images may contain random noise or artifacts.
Color jittering can be applied to introduce variations in hue, saturation, and brightness. By slightly modifying the color attributes of images, we can create new samples that account for differences in lighting conditions or color representations.
These augmentation techniques can be combined to create a more diverse dataset. For example, a rotated and flipped image with added noise can generate numerous new training samples, enhancing the model’s ability to learn robust features and generalize well.
It is important to note that image augmentation should be applied carefully and in moderation. Augmenting excessively may lead to artificially inflated dataset sizes or introduce unrealistic variations that are not representative of real-world scenarios. Proper validation and testing should be conducted to ensure that the augmented data does not negatively impact the model’s performance.
In summary, image augmentation techniques play a vital role in image processing for machine learning. By applying transformations, such as rotation, flipping, zooming, cropping, noise addition, and color jittering, we can expand the dataset, increase variability, and improve the model’s ability to learn and generalize effectively.
Filtering and Denoising Images
Filtering and denoising are important image processing techniques used to enhance the quality of images by reducing noise and unwanted artifacts. These techniques play a crucial role in preparing images for machine learning tasks, as noise and artifacts can negatively impact the accuracy and performance of the models.
Noise in images can be caused by various factors, such as sensor limitations, compression algorithms, or environmental conditions. Common types of noise include Gaussian noise, salt-and-pepper noise, or speckle noise, which can distort the true content and make it more challenging for machine learning algorithms to extract meaningful features.
When it comes to filtering and denoising, there are several techniques that can be applied. One commonly used technique is the Gaussian filter, which smooths out the image by using a weighted average of neighboring pixels. This can effectively reduce high-frequency noise while preserving important details and edges in the image.
Another technique is the median filter, which replaces each pixel value with the median value of its neighboring pixels. This filter is particularly effective at removing salt-and-pepper noise, which appears as randomly distributed white and black pixels in the image.
In addition, there are more advanced denoising techniques, such as the bilateral filter or the non-local means filter, which aim to preserve important image structures while effectively reducing noise. These filters take into account both the intensity values and spatial distances between pixels to achieve better denoising results.
It is important to note that the choice of filtering or denoising technique depends on the specific characteristics of the noise in the image and the desired trade-offs between noise removal and preservation of image details. Different images or datasets may require different approaches to achieve optimal results.
Applying filtering and denoising techniques improves the quality of images by reducing noise, which in turn benefits the downstream machine learning tasks. Cleaner images with reduced noise enable the machine learning models to focus on the relevant information and extract meaningful features more accurately. This can lead to improved performance and generalization of the models.
However, it is important to strike a balance when applying filtering and denoising techniques. Over-filtering or aggressive noise removal can lead to the loss of important details and distort the image’s true content. It is crucial to evaluate the impact of filtering and denoising on the specific machine learning task and find the optimal level of noise reduction.
In summary, filtering and denoising are essential image processing techniques that improve the quality of images by reducing noise and unwanted artifacts. These techniques help enhance the performance of machine learning models by enabling them to extract meaningful features from cleaner and more reliable images.
Edge Detection
Edge detection is a fundamental image processing technique used to identify and highlight the boundaries or edges between different objects or regions in an image. This technique plays a crucial role in various computer vision applications, including machine learning tasks, as edges provide significant information about the objects’ shapes and structures.
Edges represent areas where there is a significant change in intensity or color, indicating transitions between different regions in an image. Edge detection algorithms aim to locate these transitions by identifying the positions and orientations of edges.
One commonly used edge detection algorithm is the Canny edge detector, which applies a series of steps to accurately detect edges. The Canny edge detector involves smoothing the image to reduce noise, calculating gradients to determine the edges’ strength and orientation, applying non-maximum suppression to thin the edges, and finally, applying hysteresis thresholding to extract the strong edges.
Another popular edge detection algorithm is the Sobel operator, which estimates the gradients of the image to determine the edge strengths. The Sobel operator calculates the gradient in both horizontal and vertical directions and combines them to obtain the edge magnitudes and orientations.
Edge detection is crucial in machine learning tasks as it helps extract important features for object detection, segmentation, and recognition. By identifying the edges in an image, machine learning models can focus on these boundaries to distinguish different objects and understand their shapes and boundaries.
Furthermore, edge detection can be used as a preprocessing step to simplify images and reduce the dimensionality of the data. By extracting the edges, we can represent the image with a reduced set of features, making it more computationally efficient for machine learning algorithms to process.
However, it is important to note that edge detection is not always a trivial task, as it is susceptible to noise and variations in lighting conditions. Preprocessing techniques, such as noise reduction and image normalization, can be applied before edge detection to improve the results and reduce false positives or false negatives.
In summary, edge detection is a crucial image processing technique for machine learning tasks. By accurately identifying and highlighting the boundaries between different objects or regions, edge detection helps extract significant features and shapes from images, enabling machine learning models to understand and recognize objects more effectively.
Histogram Equalization
Histogram equalization is a widely used image processing technique that enhances the contrast of an image by redistributing the pixel intensities. This technique aims to improve the visual quality and enhance the details and features of an image, making it more suitable for machine learning tasks.
The histogram of an image represents the distribution of pixel intensities. In many images, the pixel intensities are not evenly distributed, resulting in low contrast and poor visibility of details. Histogram equalization addresses this issue by mapping the intensities in the image to a new distribution that is more uniform.
The process of histogram equalization involves several steps. First, the histogram of the image is computed by counting the frequency of each intensity level. Next, a cumulative distribution function (CDF) is calculated from the histogram, which represents the cumulative probability of each intensity value.
The CDF is then normalized to span the full range of possible intensity values. This normalized CDF is then used to map the original intensity values to new values in the equalized image. The result is an image with a more balanced histogram, leading to improved contrast and enhanced details.
Histogram equalization is particularly useful in situations where the image has low contrast or a narrow range of intensity values. It expands the range of intensities, making the image more visually appealing and improving the visibility of features.
One important consideration when applying histogram equalization is that it can amplify the noise in the image. In some cases, this can lead to undesirable artifacts or make the noise more prominent. Preprocessing steps, such as noise reduction, can be applied before histogram equalization to mitigate this issue.
Histogram equalization is a simple yet effective technique that can be used in image processing for machine learning. By enhancing the contrast and improving the visibility of details, histogram equalization helps the models extract more meaningful features from the images and improves their performance in tasks such as object detection, segmentation, and recognition.
It is worth noting that histogram equalization is a global operation that treats each pixel independently, and it may not always provide the desired results. In such cases, more advanced algorithms, like adaptive histogram equalization, can be used to enhance local contrast and address image-specific variations.
In summary, histogram equalization is an image processing technique that improves contrast by redistributing pixel intensities. By enhancing the visibility of details, histogram equalization helps machine learning models better extract features and improve performance in various tasks involving image analysis.
Color Space Conversions
Color space conversions are essential image processing operations that involve transforming the representation of colors from one color space to another. Different color spaces provide different ways of representing and understanding colors, and converting between them can offer various benefits for image analysis and machine learning tasks.
One commonly used color space is the RGB (Red, Green, Blue) color space, which represents colors as combinations of red, green, and blue components. RGB is widely used in digital imaging devices and computer displays. However, RGB may not always be the most suitable color space for image analysis tasks, as the color information is intertwined with the intensity information.
An alternative color space is the grayscale color space, where each pixel value represents only the intensity of the corresponding area in the image. Converting an image to grayscale can simplify the data representation and reduce computational complexity, making it easier for machine learning models to process the information and focus on important features.
Another popular color space is the HSV (Hue, Saturation, Value) color space, which separates the color information (hue) from the saturation (intensity of the color) and value (brightness) information. The HSV color space is more intuitive for human interpretation and can offer better separation of color-related features, making it beneficial for certain machine learning tasks, such as object recognition based on color.
Color space conversions can also be used to correct for specific image properties or lighting conditions. For example, white balance adjustments, which aim to neutralize color casts caused by varying lighting conditions, involve converting an image from one color space to another to correct the color representation and achieve more realistic and consistent color rendering.
Furthermore, converting images to different color spaces can support the extraction of specific features or enhance the discrimination of certain objects or regions. For instance, skin detection tasks may benefit from converting images to the YCbCr color space, where the Y channel represents luminance and the Cb and Cr channels provide chrominance information. By focusing on specific channels or color components, machine learning models can better identify and discriminate certain elements in an image.
In summary, color space conversions are important image processing operations that involve transforming the representation of colors from one color space to another. These conversions can simplify data representation, separate color information from intensity, correct for lighting conditions, and enhance the discrimination of specific features. By appropriately selecting and manipulating color spaces, machine learning models can better make use of color information and improve performance in various image analysis tasks.
Feature Extraction from Images
Feature extraction is a crucial step in image processing for machine learning tasks as it involves identifying and representing the most informative and discriminative aspects of an image. By extracting meaningful features, machine learning models can better understand and classify images for various applications such as object detection, recognition, and segmentation.
There are various techniques used for feature extraction from images, each with its strengths and effectiveness for different tasks. One commonly used technique is to utilize filters or convolutional kernels to detect specific patterns or features, such as edges, corners, or textures, in an image. These filters capture local structures and variations, which are then used as features for classification or analysis.
Another popular approach for feature extraction is using pre-trained deep learning models, such as Convolutional Neural Networks (CNNs). These networks consist of multiple layers that learn progressively abstract and hierarchical features from images. By leveraging these pre-trained models, it is possible to extract high-level features that represent complex visual information present in the images.
In addition to local and deep learning-based approaches, feature extraction can also involve transforming the image into a numerical representation that encapsulates its key characteristics. This could be achieved through techniques such as Principal Component Analysis (PCA) or extracting statistical features such as mean, standard deviation, or histogram of pixel values.
The selected features should be both informative and discriminative for the specific machine learning task at hand. Informative features capture the essential characteristics of an object or region, while discriminative features differentiate between different classes or categories. Choosing the right features is crucial for achieving accurate and robust machine learning models.
Feature extraction can also involve dimensionality reduction techniques to reduce the number of features while preserving most of the relevant information. This helps in reducing computational complexity and mitigates the risk of overfitting when dealing with high-dimensional feature spaces.
It is important to note that different tasks may require different features, and there is no one-size-fits-all approach. The choice of feature extraction technique depends on the specific problem, the available data, and the desired trade-offs between complexity, interpretability, and accuracy.
In summary, feature extraction is a critical step in image processing for machine learning. It involves identifying and representing informative and discriminative aspects of an image to enable accurate classification, recognition, and analysis. From local filters to deep learning models, the selection of appropriate feature extraction techniques is crucial for achieving high-performance machine learning models.
Conclusion
Image processing techniques play a vital role in preparing and enhancing images for machine learning tasks. From image resizing and cropping to histogram equalization and feature extraction, each technique serves a specific purpose in optimizing the quality and usefulness of the data. HTML is a powerful tool for creating visually appealing and well-structured content, allowing readers to easily navigate and consume the information.
By utilizing these techniques, we can standardize image sizes, normalize pixel values, reduce noise, detect edges, and extract meaningful features. These preprocessing steps are crucial for ensuring consistency, improving the performance of machine learning algorithms, and enabling accurate and reliable data analysis.
Moreover, image augmentation techniques offer the ability to expand and diversify the dataset, increasing its variability and enhancing the model’s ability to generalize. Filtering and denoising techniques help enhance the image quality by reducing noise and unwanted artifacts, ensuring that machine learning models focus on the important features.
Converting between different color spaces allows for optimal representation of color information and simplification of data for more efficient processing. Finally, feature extraction helps in identifying and representing the most informative aspects of an image, enabling machine learning models to understand and classify images effectively.
As an SEO writer, it is crucial to create content that provides valuable insights and engages readers. Incorporating markdown formatting, using appropriate keywords naturally, and optimizing the HTML structure are important factors to consider when crafting SEO-friendly articles.
In conclusion, mastering image processing techniques and effectively integrating them into the machine learning pipeline can significantly enhance the accuracy and performance of models. By leveraging the power of HTML and SEO writing principles, you can create informative and engaging content that appeals to both search engines and readers, ensuring that your valuable insights reach a wider audience.