Introduction
In the field of machine learning, having access to large amounts of data is crucial for training accurate and effective models. One of the key sources of data used in machine learning is a corpus. A corpus, in the context of machine learning, refers to a structured collection of texts that is used for analysis and training models. It plays a vital role in various natural language processing tasks, such as text classification, sentiment analysis, and language generation.
A corpus can be seen as a representative sample of a language or a specific domain, capturing the diversity and nuances of the text it contains. It provides a rich source of data for machine learning algorithms and allows researchers and developers to extract meaningful patterns and insights from textual data.
Definition of a corpus
A corpus is typically defined as a large and structured collection of texts or documents. These texts can range from written documents, such as books, articles, and websites, to transcribed speech or even social media posts. The corpus is carefully curated to represent a specific language or domain, ensuring that it is diverse and representative of the target population it aims to analyze.
A corpus is not just a random assortment of texts. It requires careful design and planning to ensure its quality and usefulness. This includes selecting appropriate texts, cleaning and preprocessing the data, and annotating the corpus with additional information like part-of-speech tags or sentiment labels.
Types of corpora
There are several types of corpora that serve different purposes in machine learning:
- General corpora: These corpora include a wide range of text genres and cover various topics. They are designed to be representative of the language as a whole and are often used for tasks such as language modeling.
- Domain-specific corpora: These corpora focus on texts from a specific domain or industry. They capture the specialized vocabulary and language patterns of that domain and are valuable for tasks like sentiment analysis in social media or medical text classification.
- Parallel corpora: These corpora contain texts in two or more languages that are aligned at sentence or phrase level. They are used for machine translation and cross-lingual information retrieval.
- Comparable corpora: These corpora consist of texts in different languages or domains that share similar content. They are useful for cross-lingual or cross-domain analysis and can facilitate knowledge transfer between different languages and domains.
Building and utilizing different types of corpora based on the specific task at hand can greatly enhance the effectiveness and accuracy of machine learning models.
Definition of a Corpus
A corpus is a fundamental component in the field of natural language processing and machine learning. It refers to a structured collection or body of texts that is systematically gathered and organized for analysis and research purposes. The texts in a corpus can include written documents, transcriptions of speech, social media posts, or any other form of textual data.
A corpus serves as a representative sample of a language or domain and is carefully curated to ensure its authenticity, diversity, and relevance to the specific task at hand. Corpus linguistics, a branch of linguistics, focuses on the study and analysis of corpora to gain insights into language use, variation, and patterns.
To create a corpus, several steps need to be followed:
- Data Collection: Texts are collected from various sources, such as books, websites, research papers, news articles, or social media platforms. The selection of texts depends on the purpose and domain of the corpus.
- Data Cleaning: Before analysis, the collected texts undergo a process of cleaning and preprocessing. This may involve removing irrelevant or duplicate content, correcting spelling and grammar errors, standardizing formatting, and ensuring textual consistency.
- Data Annotation: Sometimes, additional information is added to the texts to enhance the analysis and modeling process. This can include part-of-speech tagging, named entity recognition, sentiment labeling, or any other relevant annotations.
- Data Organization: The texts are organized and stored in a structured manner, allowing efficient retrieval and analysis. This typically involves indexing the texts, assigning unique identifiers, and categorizing them based on domains or topics.
Corpora play a crucial role in various areas of natural language processing and machine learning. They are used as training data for machine learning models, providing the necessary examples and patterns that enable the system to learn and make predictions.
Moreover, corpora are utilized for linguistic research, allowing linguists to investigate language phenomena, analyze language change over time, study language variations across regions, and explore specific linguistic features.
Corpora are also essential for developing and evaluating language models, text classifiers, sentiment analysis systems, machine translation algorithms, and other language processing applications. By using diverse and representative corpora, developers can build more accurate and effective models that can handle a wide range of real-world texts and reflect the intricacies of language usage.
In summary, a corpus is a structured collection of texts that serves as a valuable resource for language analysis, machine learning, and linguistic research. It provides a systematic and representative sample of a language or domain, enabling researchers and developers to extract meaningful insights, patterns, and knowledge from textual data.
Types of Corpora
In the realm of natural language processing and machine learning, there are various types of corpora that are utilized for different purposes. These corpora are designed to capture specific linguistic and contextual features, enabling researchers and practitioners to tackle diverse language processing tasks effectively. Let’s explore some of the most common types of corpora:
- General Corpora: These corpora encompass a wide range of text genres and cover various topics. They are designed to be representative of the entire language and serve as a foundation for language modeling tasks. General corpora often contain diverse sources such as newspapers, books, blog posts, and web pages, providing a comprehensive snapshot of the language in different contexts.
- Domain-Specific Corpora: Domain-specific corpora focus on texts from a particular domain or subject area. These corpora capture the specialized vocabulary, language patterns, and terminologies associated with that domain. For example, a medical corpus may include scientific articles, patient records, and clinical trial data. Domain-specific corpora are instrumental in developing machine learning models customized for specific fields, such as medical or legal text classification.
- Parallel Corpora: Parallel corpora consist of texts in multiple languages that are aligned at a sentence or phrase level. These corpora serve as a valuable resource for machine translation and cross-lingual information retrieval. By aligning texts across languages, parallel corpora enable researchers to study translation patterns and develop machine translation models that can accurately translate between different languages.
- Comparable Corpora: Comparable corpora comprise texts in different languages or domains that are thematically related or share similar content. These corpora facilitate comparative analysis and enable researchers to study language variations, identify cross-lingual dependencies, and explore cross-domain information transfer. Comparable corpora are particularly useful for cross-lingual information retrieval, where the aim is to find relevant information in one language based on a query in another language.
- Specialized Corpora: Specialized corpora focus on a particular type of language or communication medium. These may include corpora of spoken language, social media texts, legal texts, or historical documents. Specialized corpora allow researchers to analyze language usage in specific contexts and develop models tailored to handle the linguistic characteristics of these specialized domains or mediums.
By leveraging different types of corpora, researchers and practitioners can gain insights into language usage, develop accurate machine learning models, and address a wide range of language processing tasks. The choice of corpus type depends on the specific research or application requirements, as each type brings its own unique benefits and challenges.
Building a Corpus
Building a corpus involves several steps to ensure its quality, representativeness, and suitability for the intended language processing tasks. The process of building a corpus can be summarized as follows:
- Data Collection: The first step in building a corpus is to collect text data from various sources. These sources may include books, websites, research papers, social media platforms, or any other relevant textual content. The selection of sources depends on the purpose and scope of the corpus. It is important to ensure that the collected data covers a diverse range of topics and faithfully represents the target language or domain.
- Data Preprocessing: Once the data is collected, it needs to be cleaned and preprocessed. This involves removing any irrelevant or duplicate content, correcting spelling and grammatical errors, and standardizing the formatting. The preprocessing step also includes handling special characters, tokenizing the text into individual words or sentences, and normalizing the text for consistent representation.
- Data Annotation: In some cases, it may be necessary to annotate the corpus with additional information. This can involve the assignment of part-of-speech tags, entity recognition, sentiment labels, or any other relevant linguistic annotations. Annotated corpora provide useful linguistic insights and enable the development of supervised machine learning models.
- Data Organization: The corpus needs to be organized in a structured manner to facilitate efficient retrieval and analysis. This involves indexing the texts, assigning unique identifiers, and categorizing the texts based on domains, topics, or any other relevant criteria. Effective organization ensures easy access and retrieval of specific texts or subsets of the corpus.
- Corpus Size: The size of the corpus is an important consideration. While larger corpora generally provide more representative linguistic patterns, they can also introduce noise and complexity. The corpus size should be determined based on the specific research or application requirements, striking a balance between data volume and manageable computational resources.
- Ethical Considerations: Building a corpus involves being mindful of ethical considerations. It is essential to obtain proper permissions for copyrighted texts and respect user privacy when incorporating data from social media or other public platforms. Researchers should also consider the potential biases that may exist in the corpus and strive to create inclusive and representative datasets.
Building a high-quality corpus is a meticulous process that requires careful attention to detail, proper data cleaning and preprocessing, and thoughtful annotation. Well-designed and curated corpora form the foundation for robust language models, accurate text classifiers, and effective natural language processing systems.
The success of any language processing task relies heavily on the availability of a relevant and representative corpus. Therefore, building a corpus is a crucial step in enabling researchers and practitioners to develop cutting-edge language models and advance our understanding of human language.
Pre-processing a Corpus
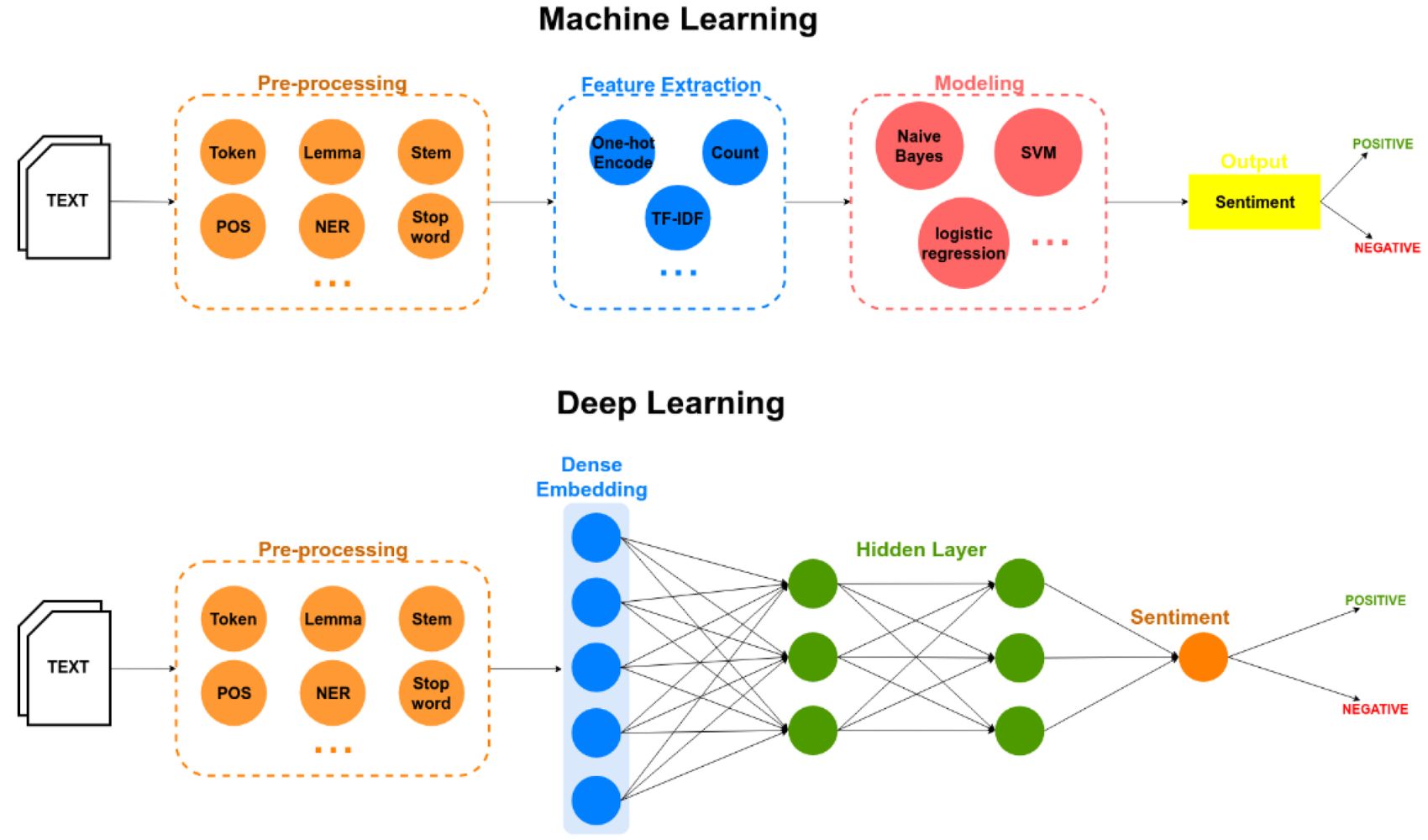
Before a corpus can be utilized effectively for natural language processing and machine learning tasks, it is essential to pre-process the data to ensure its quality and suitability. Pre-processing involves several steps to clean and prepare the corpus for analysis and modeling. The pre-processing of a corpus can be summarized as follows:
- Cleaning: The first step in pre-processing a corpus is to clean the data. This involves removing any irrelevant or redundant content, such as headers, footers, or advertisements. It also includes eliminating any non-textual elements, such as HTML tags or special characters, that may hinder the analysis process.
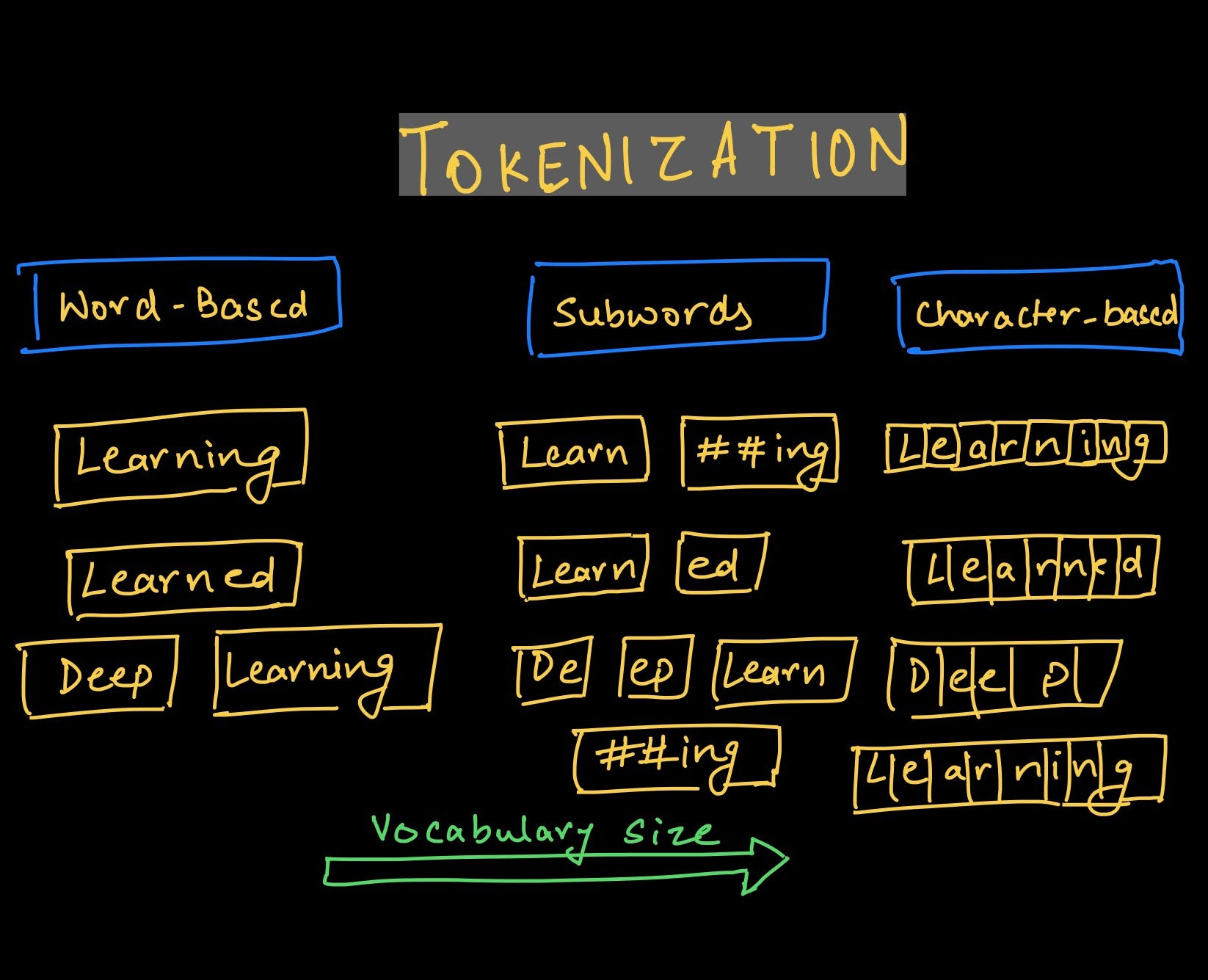
- Tokenization: Tokenization involves breaking the text into individual words or tokens. This step is crucial for further analysis and modeling, as it allows for the extraction of meaningful units of language. Tokenization can be as simple as splitting the text by white spaces or using more advanced techniques, like regular expression patterns or language-specific tokenizers.
- Normalization: Normalization aims to transform the text into a consistent and standardized representation. This includes converting all letters to lowercase, removing punctuation marks, and handling common language variations, such as stemming or lemmatization. Normalization ensures that different forms of a word are treated as the same token, reducing redundancy and improving text coherence.
- Stop Word Removal: Stop words are common words that do not contribute much to the overall meaning of a text, such as “the,” “and,” or “is.” Removing stop words can help reduce noise in the corpus and improve the efficiency of language processing tasks. However, it is important to be cautious when removing stop words, as they may contain useful information in certain contexts.
- Encoding: Encoding is an important step to ensure proper representation of the text data. It involves converting the text into a suitable character encoding format, such as UTF-8, to handle different languages and special characters. Encoding ensures that the text is correctly interpreted and can be processed without any character encoding issues.
- Filtering: Depending on the specific task, filtering may be performed to remove unwanted or irrelevant content from the corpus. This can include removing specific types of documents, filtering out low-quality or spam texts, or excluding texts that do not meet certain criteria. Filtering helps ensure that the corpus is focused and aligned with the research or application objectives.
By pre-processing a corpus, researchers and practitioners can obtain cleaner and more manageable data that is better suited for analysis and modeling. Pre-processing steps help reduce noise, standardize the representation of text, and improve the quality of features extracted from the corpus.
It is worth noting that the pre-processing steps may vary depending on the specific task, domain, or language being analyzed. Different natural language processing techniques and algorithms may require specific pre-processing steps to optimize their performance.
Overall, pre-processing a corpus is a critical step in the data preparation phase of natural language processing. It ensures that the corpus is cleaned, standardized, and ready for analysis and modeling, enabling researchers and practitioners to extract meaningful insights from textual data.
Corpus-based Machine Learning Techniques
Corpora play a vital role in training and improving machine learning models for natural language processing tasks. By utilizing corpus-based techniques, researchers and practitioners can leverage the rich source of data provided by corpora to enhance the performance and accuracy of their machine learning models. Here are some prominent corpus-based machine learning techniques:
- Text Classification: Corpora are instrumental in training text classification models. By providing labeled samples, a corpus can help identify patterns and features that distinguish different categories or classes of texts. Machine learning algorithms can learn from these labeled examples to accurately classify new, unseen texts into the appropriate categories, such as sentiment analysis, spam detection, topic categorization, or document classification.
- Language Modeling: A corpus serves as the basis for language modeling, which is crucial for various language tasks such as speech recognition, machine translation, and language generation. Language models learn the statistical properties of a given corpus, enabling them to predict the probability of the next word or sequence of words in a sentence. By training on a corpus, language models can generate coherent and contextually appropriate text.
- Named Entity Recognition (NER): Corpora are invaluable for training NER models, which aim to identify and classify named entities, such as person names, organizations, locations, or dates, in a given text. Annotated corpora provide examples of named entities, enabling machine learning models to learn the patterns and features that distinguish them from other words in the text.
- Sentiment Analysis: Sentiment analysis models analyze the sentiment or emotion expressed in a piece of text. Corpora with sentiment labels or annotations allow machine learning models to learn the sentiment polarity and sentiment-related features, enabling them to classify new texts as positive, negative, or neutral based on the learned patterns.
- Topic Modeling: Topic modeling algorithms discover latent topics or themes from a collection of documents. Corpora are used to train these models, where the algorithms learn the topic-word distributions and document-topic distributions. By analyzing the frequency and co-occurrence of words across the corpus, machine learning models can automatically group documents into topics, enabling researchers to gain insights into large document collections.
- Information Retrieval: Corpora play a crucial role in information retrieval systems, helping to improve search accuracy and relevance. Machine learning models trained on a corpus learn to rank and retrieve documents or web pages based on their relevance to a given query. By leveraging the patterns and features learned from the corpus, information retrieval systems can provide users with more accurate and relevant search results.
These are just a few examples of how corpora are employed to enhance machine learning techniques in natural language processing. By training models on well-constructed and diverse corpora, researchers and practitioners can develop more accurate, robust, and context-aware machine learning models that deliver superior performance in a range of language-related tasks.
Benefits of Using Corpora in Machine Learning
The use of corpora in machine learning brings numerous benefits that greatly enhance the effectiveness and performance of language processing tasks. Here are some key advantages of utilizing corpora:
- Data Availability: Corpora provide a large and diverse collection of textual data, ensuring that machine learning models have access to a rich and representative sample of the target language or domain. This data availability facilitates more accurate and comprehensive training, enabling models to learn from a wide range of language variations and patterns.
- Improved Accuracy: Training machine learning models on corpora allows them to capture linguistic nuances, context-dependent patterns, and domain-specific features, leading to improved accuracy in language processing tasks. The diverse and representative nature of corpora helps models generalize well to unseen data, enabling them to make more accurate predictions or classifications.
- Enhanced Language Understanding: Corpora provide valuable insights into the usage, structure, and semantics of a language. By training models on corpora, they acquire a deeper understanding of language conventions, idiomatic expressions, and syntactic relationships. This enhances the models’ ability to comprehend and generate language in a more human-like manner.
- Support for Various Language Tasks: Corpora serve as a foundation for a wide range of language processing tasks, including text classification, sentiment analysis, machine translation, named entity recognition, and more. By training models on corpora, researchers and practitioners can develop specialized algorithms for specific language tasks, improving performance and enabling the handling of real-world language data.
- Domain-Specific Adaptability: Corpora can be curated to focus on specific domains or industries, enabling models to be tailored to the language patterns and vocabulary of these domains. By training models on domain-specific corpora, they become more adaptable and accurate in handling specialized content, such as legal documents, medical texts, or technical literature.
- Insights into Language Usage: Corpora provide linguistic researchers with valuable insights into language usage, changes over time, and sociolinguistic variations. Analyzing corpora helps uncover underlying language patterns, study language evolution, and gain a deeper understanding of language behavior in different contexts or regions.
The benefits of using corpora in machine learning extend beyond improving the performance of language processing models. Corpora enable researchers to gain insights into language phenomena, advance linguistic research, and contribute to the development of more sophisticated and realistic language models.
Corpora serve as a critical resource in the field of machine learning, providing the necessary training data to build accurate and robust models. By harnessing the power of corpora, researchers and practitioners can make significant strides in advancing natural language processing techniques and achieving greater language understanding and processing capabilities.
Limitations of Corpora in Machine Learning
While corpora offer a wealth of data for training machine learning models in natural language processing tasks, they also come with certain limitations that need to be considered. Understanding these limitations is crucial for researchers and practitioners working with corpora in machine learning. Here are some key limitations:
- Data Bias: Corpora can inherently contain biases present in the source data. If the initial data collection process is biased or if the data sources predominantly represent a specific demographic or viewpoint, the resulting corpus may not provide a balanced or representative view of the target population or language. Biased corpora can lead to biased models that perpetuate or amplify existing biases in language processing tasks.
- Data Annotation Challenges: Annotating corpora with additional information, such as part-of-speech tags or sentiment labels, can be time-consuming and subjective. Annotators may vary in their interpretations and labeling criteria, leading to inconsistencies in the annotated corpus. This can impact the reliability and quality of the annotations and subsequently affect the performance of machine learning models trained on them.
- Data Sparsity: Corpora may suffer from data sparsity, particularly in specialized domains or less-represented languages. It can be challenging to find enough labeled examples or an extensive range of texts to cover all possible linguistic variations or topics of interest. The lack of sufficient data can limit the model’s ability to generalize well to unseen or out-of-domain data.
- Dynamic Language Phenomena: Languages are dynamic, with new words, phrases, and linguistic patterns emerging continuously. Corpora, especially older ones, may not capture the most up-to-date language phenomena, which can impact model performance when faced with contemporary text. Regular updates to corpora or continuous data collection efforts are necessary to keep pace with changing language usage.
- Privacy and Ethical Considerations: Corpora often contain sensitive or private information obtained from sources such as social media platforms or personal documents. Privacy concerns arise when working with such data, raising ethical considerations around data usage, storage, and access. Safeguarding user privacy and ensuring ethical data practices become crucial when dealing with corpora.
- Domain Specificity: The usefulness of corpora can be limited when dealing with highly specific or niche domains where data availability is scarce. Domain-specific corpora may require extensive efforts for data collection and careful curation to ensure representative and relevant data. Building effective models in such cases may require combining multiple corpora or employing transfer learning techniques for generalization.
Acknowledging these limitations is essential to mitigate potential biases, address data insufficiencies, and make well-informed decisions when working with corpora. Researchers and practitioners must strive for transparency, ethics, and data diversity to develop fair and robust machine learning models that can handle the challenges posed by corpora.
Despite these limitations, corpora remain a powerful resource that, when used judiciously, can significantly contribute to advancements in natural language processing and enable the development of more accurate and context-aware language models.
Conclusion
Corpora play a crucial role in the field of machine learning for natural language processing. They serve as a rich source of data, enabling researchers and practitioners to build more accurate and effective models for various language tasks. By utilizing corpora, machine learning models can capture language patterns, learn from diverse examples, and make informed predictions or classifications.
Throughout this article, we explored the definition of a corpus and its types, emphasizing the importance of carefully building and preprocessing corpora to ensure their quality and suitability. We delved into the benefits of using corpora in machine learning, such as enhanced accuracy, improved language understanding, and support for various language tasks. However, it is crucial to acknowledge the limitations of corpora, including data biases, annotation challenges, data sparsity, and the dynamic nature of language.
Despite these limitations, corpora remain a valuable resource that drives advancements in natural language processing. Researchers and practitioners must strive for transparent and ethical practices when working with corpora, addressing biases, and ensuring diverse and representative datasets for training models.
In conclusion, corpora provide the foundation for training robust and accurate machine learning models in natural language processing. By harnessing the power of corpora, we can advance our understanding and processing of human language, paving the way for innovative applications and breakthroughs in the field. Continual efforts to improve corpora quality, mitigate biases, and consider ethical considerations will contribute to the development of more reliable and inclusive language models in the future.