Introduction
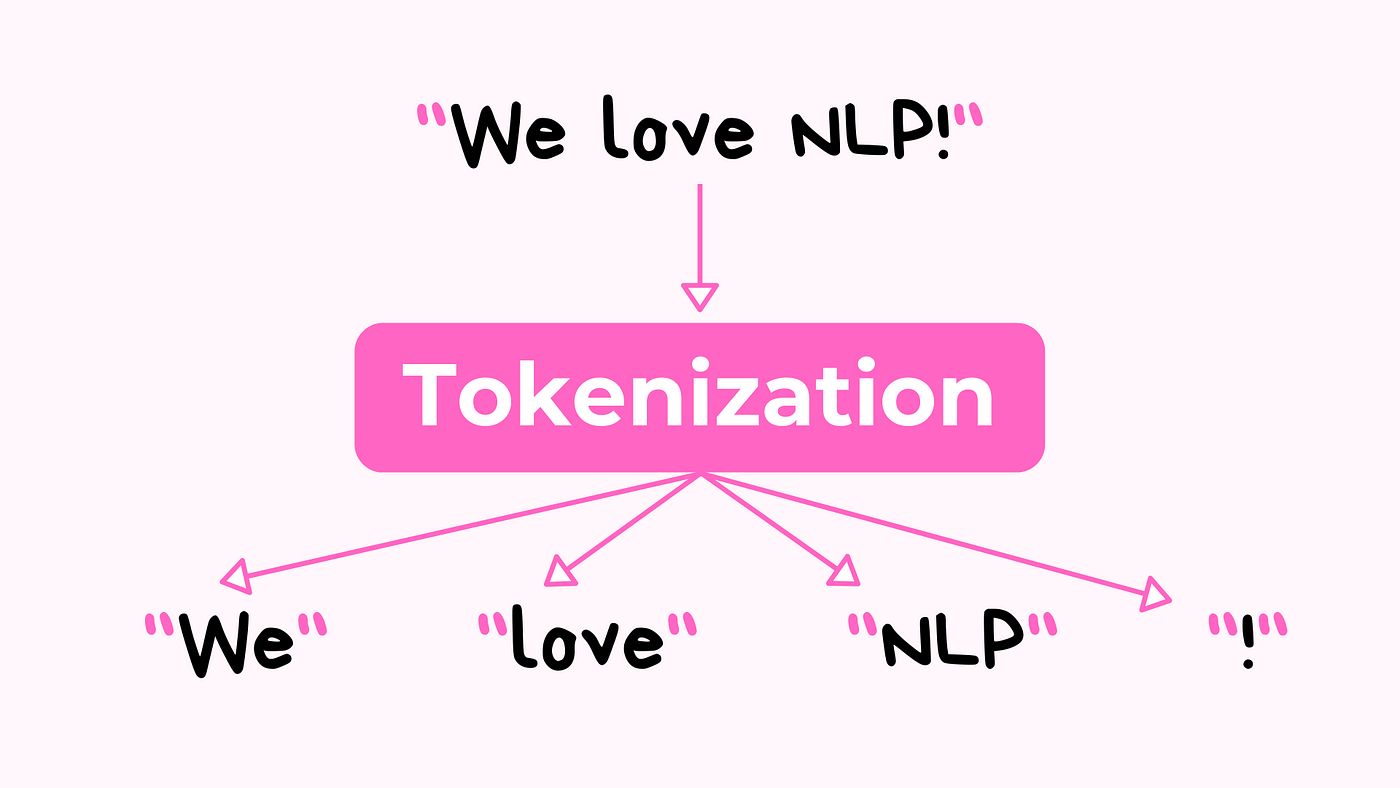
Tokenization is a fundamental concept in Natural Language Processing (NLP), serving as the initial step in processing and analyzing textual data. It involves breaking down a text into individual segments, which could be words, sentences, or even paragraphs. These segments, known as tokens, act as building blocks that enable various NLP tasks such as text preprocessing, word frequency analysis, sentiment analysis, named entity recognition, language modeling, machine translation, and information retrieval.
The process of tokenization plays a crucial role in NLP as it helps extract meaningful information and allows us to analyze and understand the text at a granular level. Tokens capture semantic meaning, which aids in further analysis and processing.
Tokenization can be performed using different techniques and algorithms, depending on the specific needs and requirements of the task at hand. Some common tokenization methods include whitespace tokenization, rule-based tokenization, statistical tokenization, and machine learning-based tokenization.
In this article, we will delve into the concept of tokenization and explore its various applications in NLP. From text preprocessing to language modeling, tokenization plays a pivotal role in enabling accurate and efficient analysis of textual data. By breaking down text into smaller units, tokenization allows us to apply advanced techniques and algorithms to extract valuable insights.
In the following sections, we will discuss some of the key applications of tokenization in NLP and demonstrate how it facilitates the execution of these tasks. Each application has unique characteristics and requirements, highlighting the versatility and importance of tokenization in NLP.
Definition of Tokenization
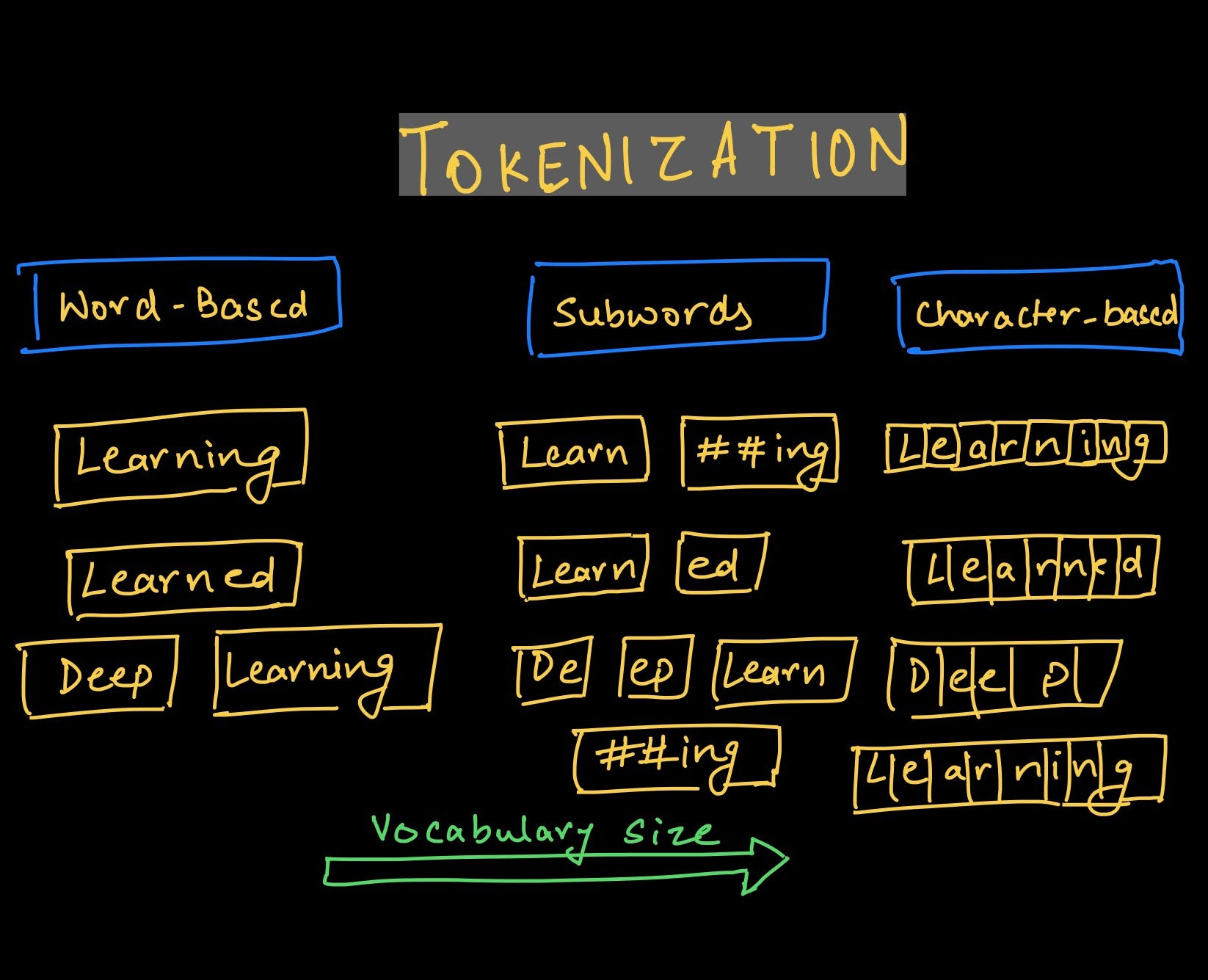
Tokenization in the context of Natural Language Processing (NLP) is the process of breaking down a text into smaller units, known as tokens. These tokens can be words, sentences, or even paragraphs, depending on the specific requirement of the task at hand. Tokenization forms the foundation for various NLP tasks by transforming raw text into a more manageable and structured format.
The main objective of tokenization is to provide a standardized representation of textual data, allowing for easier analysis and manipulation. By breaking text into tokens, NLP algorithms can perform operations at a more granular level, extracting meaning and patterns from the data.
There are different approaches and techniques for tokenization, depending on the specific needs and characteristics of the text. Whitespace tokenization, for example, splits the text based on the presence of whitespace characters such as spaces or tabs. This method is straightforward and commonly used when dealing with well-structured text, such as news articles or blog posts.
Rule-based tokenization, on the other hand, relies on predefined rules or patterns to identify and split the text into tokens. These rules can be based on punctuation marks, capitalization, or specific patterns within the text. This approach allows for more flexibility and customization, especially when dealing with textual data with specific formatting requirements.
Statistical tokenization utilizes machine learning algorithms and statistical models to determine the optimal boundaries for tokenization. These models are trained on large datasets and can adapt to the specific characteristics of the text. Statistical tokenization is particularly useful when dealing with texts that have complex structures or languages with unique tokenization rules.
In recent years, machine learning-based tokenization has gained popularity due to its ability to handle diverse and complex textual data. These models are trained on vast amounts of text and can learn patterns and rules automatically, resulting in more accurate and efficient tokenization.
Overall, tokenization is a critical step in NLP as it transforms unstructured text into structured data, facilitating further analysis and processing. It allows NLP algorithms to work with smaller units of text, enabling tasks such as text preprocessing, word frequency analysis, sentiment analysis, named entity recognition, language modeling, machine translation, and information retrieval. By breaking down text into tokens, tokenization provides a foundation for extracting valuable insights and understanding textual data on a deeper level.
Applications of Tokenization in NLP
Tokenization plays a crucial role in various applications of Natural Language Processing (NLP), enabling efficient and accurate analysis of textual data. Here, we will explore some of the key applications where tokenization is essential:
1. Text Preprocessing
Tokenization is an essential step in text preprocessing, which involves cleaning and preparing the raw text for further analysis. By breaking down the text into smaller units like words or sentences, tokenization helps remove unwanted characters, punctuation, or stopwords. It also aids in normalizing text by converting all tokens to a consistent case (lowercase, uppercase, or title case). Text preprocessing ensures that the data is standardized and ready for subsequent NLP tasks.
2. Word Frequency Analysis
Tokenization is fundamental in word frequency analysis, where the frequency of words in a given text is determined. By breaking the text into individual words, tokenization enables the counting and analysis of word occurrences. This analysis provides insights into the most common words in a document, which can be helpful in tasks like keyword extraction, summarization, and topic modeling.
3. Sentiment Analysis
Tokenization is essential in sentiment analysis, which aims to determine the overall sentiment or opinion expressed in a given text. By tokenizing the text into individual words or phrases, sentiment analysis algorithms can assess the polarity of each token and estimate the sentiment of the entire text. This analysis is valuable for understanding customer feedback, social media sentiment, and public opinion on various topics.
4. Named Entity Recognition
Tokenization plays a crucial role in named entity recognition (NER), where the task is to identify and classify named entities in a text, such as people, organizations, locations, or dates. By tokenizing the text into words or phrases, NER algorithms can analyze the context of each token and determine if it represents a named entity. This enables advanced information extraction and helps in tasks like information retrieval, question answering, and text summarization.
5. Language Modeling
Tokenization is essential in language modeling, which involves predicting the next word in a sequence of words. By tokenizing the text into words or subword units, language models can learn the statistical patterns and relationships between tokens. This enables the generation of coherent and contextually relevant text, which is valuable in tasks like auto-completion, machine translation, and text generation.
6. Machine Translation
Tokenization is crucial in machine translation, where the goal is to translate text from one language to another. By breaking the source and target texts into tokens, machine translation algorithms can align the corresponding words or phrases, enabling accurate translation. Tokenization helps preserve the structure and meaning of the text during the translation process, ensuring high-quality translations.
7. Information Retrieval
Tokenization is fundamental in information retrieval, which involves retrieving relevant documents or information based on user queries. By tokenizing the text in both the query and document corpus, information retrieval systems can match the query terms with the tokens in the documents. This allows for efficient searching and retrieval of relevant information, improving search engine performance and user experience.
In summary, tokenization is a vital component of various applications in NLP. From text preprocessing to sentiment analysis, named entity recognition, language modeling, machine translation, and information retrieval, tokenization enables the efficient processing and analysis of textual data. By breaking down text into tokens, tokenization provides the foundation for extracting valuable insights and understanding the nuances of language in NLP tasks.
Text Preprocessing
Text preprocessing is a crucial step in Natural Language Processing (NLP) that involves cleaning and preparing raw text for further analysis. Tokenization plays a fundamental role in this process by breaking down the text into smaller units such as words or sentences. This enables several important tasks in text preprocessing, including the removal of unwanted characters, punctuation, or stopwords, as well as normalizing the text for consistency.
The tokenization process starts by splitting the text into individual tokens based on predetermined boundaries. For word-level tokenization, the text is typically split based on whitespace, punctuation marks, or other language-specific rules. For example, the sentence “The quick brown fox jumps over the lazy dog” would be tokenized into individual words: “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”.
Tokenization also facilitates the removal of unwanted elements, such as special characters or punctuation marks, which are irrelevant for many NLP tasks. Additionally, tokenization enables the removal of stopwords, which are commonly occurring words that do not add much semantic meaning to the text, such as “the”, “and”, “is”, etc. Removing stopwords helps reduce noise in the data and improves the efficiency of subsequent analyses.
Another important aspect of text preprocessing is the normalization of text. This involves converting all tokens to a consistent case, such as lowercase, uppercase, or title case. Normalization ensures that the analysis is not sensitive to variations in capitalization and allows for more accurate comparisons between tokens.
Text preprocessing using tokenization is applicable across various NLP tasks. For example, sentiment analysis benefits from tokenization by breaking the text into words or phrases, allowing sentiment analysis algorithms to determine the sentiment of individual tokens. Similarly, named entity recognition relies on tokenization to identify and classify named entities within a text.
In summary, tokenization plays a vital role in text preprocessing in NLP. By breaking down text into smaller units, it allows for the removal of unwanted elements, the normalization of text, and the preparation of data for further analysis. Text preprocessing using tokenization is crucial for ensuring accurate and efficient analysis in various NLP tasks, paving the way for more insightful and meaningful results.
Word Frequency Analysis
Word frequency analysis is a common task in Natural Language Processing (NLP) that involves determining the frequency of words in a given text. This analysis provides insights into the importance and prevalence of different words, which can be valuable for various NLP applications such as keyword extraction, summarization, and topic modeling. Tokenization plays a crucial role in word frequency analysis by breaking down the text into individual words, enabling counting and analysis of word occurrences.
The process of word frequency analysis starts with tokenization, where the text is segmented into individual words or tokens. These tokens act as the units for analysis, allowing for the calculation of word frequencies. By counting the occurrences of each word in the text, it is possible to determine the frequency distribution, ranking the words based on their occurrence count.
Word frequency analysis provides valuable insights into the most common and frequent words in a given text. This information can be helpful in several ways. For example, in keyword extraction, identifying the most frequent words can help identify the key themes and topics in a document or a collection of documents. It can also assist in understanding the overall content and focus of a piece of text.
Summarization is another application where word frequency analysis is useful. By analyzing the frequency of different words, it is possible to identify the most important and central concepts in the text. These key concepts can then be used to create a concise summary that captures the essence of the original text.
Word frequency analysis is also beneficial in topic modeling, where the objective is to discover underlying themes or topics within a collection of documents. By identifying the most frequent words across the documents, topic models can assign words to different topics and uncover the relationships between words and topics.
Furthermore, word frequency analysis can be used for text classification and information retrieval. By comparing the occurrence of words in different categories or classes, it is possible to determine their relevance and importance in distinguishing between different classes or retrieving relevant information.
In summary, word frequency analysis is a valuable task in NLP, providing insights into the importance and prevalence of words in a given text. Tokenization plays a crucial role in this analysis by breaking down the text into individual words, allowing for the calculation of word frequencies. Word frequency analysis has numerous applications, including keyword extraction, summarization, topic modeling, text classification, and information retrieval. By exploring the frequency distribution of words, we can gain a better understanding of the underlying patterns and themes present in textual data.
Sentiment Analysis
Sentiment analysis, also known as opinion mining, is a popular application of Natural Language Processing (NLP) that aims to determine the sentiment or emotion expressed in a given text. It is widely used in various domains, such as customer feedback analysis, social media sentiment analysis, and market research. Tokenization plays a critical role in sentiment analysis by breaking down the text into individual words or phrases, allowing sentiment analysis algorithms to assess the polarity of each token and estimate the overall sentiment of the text.
The tokenization process in sentiment analysis involves segmenting the text into tokens, which can be words, phrases, or even emojis. Each token is then assigned a sentiment polarity, typically positive, negative, or neutral, based on its semantic meaning and context. By analyzing the sentiment of individual tokens and aggregating them, sentiment analysis algorithms provide an overall sentiment score for the text.
Sentiment analysis can be approached in multiple ways. Lexicon-based methods utilize sentiment lexicons or dictionaries containing pre-defined sentiment polarities of words. During tokenization, the sentiment of each token is determined by matching it with entries in the lexicon. Machine learning-based methods, on the other hand, rely on labeled datasets to train models that can automatically classify the sentiment of tokens.
Tokenization enables sentiment analysis to capture the sentiment expressed in the text accurately. By breaking the text into smaller units, sentiment analysis algorithms can analyze the context and semantic meaning of each token. This allows for the recognition of positive or negative sentiments conveyed by specific words or phrases within the text.
Sentiment analysis has various applications across different industries. In market research, it helps gauge customer opinions and reactions towards products or services, providing valuable insights for businesses to make informed decisions. In social media sentiment analysis, sentiment analysis algorithms analyze large volumes of social media posts to understand public sentiment towards specific topics, brands, or events.
Additionally, sentiment analysis is useful in analyzing customer feedback, identifying patterns in product reviews, and monitoring online reputation. It assists in political analysis by determining public sentiment towards political figures or policies. It is also applied in financial sentiment analysis to analyze trends in stock markets based on the sentiment expressed in news articles or social media posts.
In summary, sentiment analysis is a valuable application of NLP that aims to determine the sentiment or emotion expressed in a given text. Tokenization serves as a crucial step in sentiment analysis by breaking down the text into smaller units and enabling the assessment of sentiment polarity for each token. Sentiment analysis finds applications in various domains, including customer feedback analysis, social media sentiment analysis, market research, and political analysis. By accurately capturing and analyzing sentiment, businesses and organizations can make data-driven decisions and gain insights into public opinions and emotions.
Named Entity Recognition
Named Entity Recognition (NER) is a vital task in Natural Language Processing (NLP) that involves identifying and classifying named entities within a text. Named entities can be people, organizations, locations, dates, or any other predefined category of proper nouns. Tokenization plays a crucial role in NER by breaking down the text into individual words or phrases, allowing NER algorithms to analyze the context of each token and determine if it represents a named entity.
The tokenization process in named entity recognition involves segmenting the text into tokens, which are typically words or phrases. Each token is then analyzed by NER algorithms, which determine if it represents a named entity and assign it a specific category, such as person, organization, location, date, etc. This analysis takes into account the context and semantic meaning of each token, allowing for more accurate identification and classification of named entities.
Named entity recognition is crucial in various applications of NLP. In information retrieval, NER helps extract key information from documents, enabling more accurate search results and information extraction. NER also plays a significant role in question answering systems, where identifying named entities helps provide precise and relevant answers to user queries.
Additionally, in text summarization, named entity recognition identifies important entities that can be key to understanding the main concepts and themes in the text. By recognizing and categorizing named entities, text summarization algorithms can generate concise summaries that capture the most relevant information.
Named entity recognition also finds application in sentiment analysis, where recognizing named entities can help understand the sentiment associated with specific individuals, organizations, or locations mentioned in the text. It is also utilized in information extraction tasks, where extracting specific information related to named entities from unstructured textual data is crucial.
Tokenization is an essential step in named entity recognition as it allows NER algorithms to analyze the context and semantic meaning of each token. By considering the relationships between tokens and their positions within the text, NER algorithms can accurately identify and classify named entities, providing valuable information for various NLP tasks.
In summary, named entity recognition is an important task in NLP that involves identifying and classifying named entities within a text. Tokenization is a critical component of NER, as it breaks down the text into individual tokens and allows for the analysis of each token’s context and semantics. Named entity recognition has various applications, including information retrieval, question answering, text summarization, sentiment analysis, and information extraction. By accurately recognizing and categorizing named entities, NER enables more efficient analysis and extraction of information from unstructured textual data.
Language Modeling
Language modeling is a fundamental task in Natural Language Processing (NLP) that involves predicting the next word in a sequence of words. It plays a crucial role in various applications such as auto-completion, machine translation, text generation, and speech recognition. Tokenization is a key component in language modeling as it breaks down the text into words or subword units, allowing language models to learn statistical patterns and relationships between tokens.
The tokenization process in language modeling involves segmenting the text into tokens, which can be individual words or subword units. These tokens are then used to build language models that learn the statistical properties of the sequence of tokens. By analyzing the distributions and patterns of tokens, language models can generate coherent and contextually relevant text.
Language modeling can be approached in different ways. N-gram models are a simple yet effective approach that considers the probability of a token given its previous N-1 tokens. These models require tokenization to divide the text into appropriate units for analysis. Neural network-based language models, such as recurrent neural networks (RNNs) or transformers, learn the statistical patterns and relationships between tokens using large amounts of training data. These models also rely on tokenization to feed the text into the network and generate predictions based on the learned patterns.
Tokenization in language modeling aids in capturing the structure and meaning of the text. By breaking the text into meaningful units, language models can learn the dependencies and relationships between tokens. This allows the models to generate contextually coherent text and make accurate predictions about the next word in a sequence.
Language modeling has various applications. Auto-completion, for instance, utilizes language models to suggest the next word or phrase as a user types, improving typing efficiency and ease of use. Machine translation also relies on language models to generate fluent and contextually accurate translations by predicting the next word or phrase in the target language.
Text generation is another application where language modeling is applied. By predicting the next word based on the context provided, language models can generate coherent and contextually relevant text, which finds applications in chatbots, automated content generation, and creative writing assistance.
Speech recognition systems benefit from language modeling to improve the accuracy of transcription by using language models to decode speech and select the most likely sequence of words based on the context.
In summary, language modeling is a crucial task in NLP that involves predicting the next word in a sequence of words. Tokenization plays a vital role in language modeling by breaking down the text into tokens, allowing for the analysis of token distributions and patterns. Language modeling has applications in auto-completion, machine translation, text generation, and speech recognition. By considering the context provided by tokenization, language models can generate coherent and accurate predictions, enabling more natural language processing and improved performance in various applications.
Machine Translation
Machine translation is the task of automatically translating text from one language to another. It plays a crucial role in breaking down language barriers and facilitating communication between people who speak different languages. Tokenization is a fundamental step in machine translation as it breaks down the source and target texts into tokens, allowing translation algorithms to align the corresponding words or phrases accurately.
The tokenization process in machine translation involves segmenting the source and target texts into tokens, which are typically words or subword units. These tokens act as the building blocks for translation algorithms. By breaking the texts into tokens, machine translation models can analyze the structure and meaning of the sentences, and map the source language tokens to their corresponding tokens in the target language.
Tokenization helps preserve the integrity of the source and target texts during the translation process. It ensures that the meaning and structure of the text are maintained, allowing for accurate and high-quality translations. Furthermore, tokenization allows for the handling of complex linguistic phenomena such as idioms, multi-word expressions, or compound words, which are essential for accurate translation.
Machine translation relies on various techniques and algorithms, such as statistical machine translation (SMT) and neural machine translation (NMT). These models utilize tokenization to process the source and target texts, align the tokens, and generate translations based on statistical patterns or neural network-based architectures.
Machine translation has made significant progress in recent years, thanks to advances in deep learning and neural network-based models. These models, such as sequence-to-sequence models using recurrent neural networks (RNNs) or transformers, have improved the translation quality by capturing and modeling the sequential dependencies and linguistic properties of the source and target languages.
Machine translation is crucial in various domains, including international business, tourism, and cross-cultural communication. It enables the translation of documents, websites, and other forms of written or spoken content, facilitating communication between speakers of different languages.
While machine translation has advanced significantly, it still faces challenges related to language ambiguity, cultural nuances, and idiomatic expressions. Nevertheless, tokenization remains a fundamental step in machine translation, providing the foundation for accurate and meaningful translations.
In summary, machine translation is the process of automatically translating text from one language to another. Tokenization is a critical step in machine translation, breaking down the source and target texts into tokens for accurate alignment and translation. Machine translation has a wide range of applications, enabling cross-linguistic communication and breaking down language barriers. By leveraging tokenization and advanced translation models, machine translation continues to improve, making communication more accessible and efficient in our increasingly globalized world.
Information Retrieval
Information retrieval is a vital application in Natural Language Processing (NLP) that involves retrieving relevant documents or information based on user queries. Tokenization plays a significant role in information retrieval by breaking down the query and the document corpus into tokens, matching the query terms with the tokens in the documents, and enabling efficient searching and retrieval of information.
The tokenization process in information retrieval involves segmenting the query and the document corpus into tokens, typically words or phrases. Tokenization allows for the analysis and comparison of individual tokens, enabling information retrieval systems to match the query terms with the tokens in the documents.
Tokenization plays a crucial role in determining the relevance and ranking of documents in information retrieval. By breaking down the text into tokens, it allows for precise matching of query terms with the tokens present in the documents. This matching process forms the basis for retrieval models that assign a relevance score to each document based on the frequency and context of the query terms within the tokens.
Tokenization helps handle different languages, word forms, and variations in spelling or punctuation. By normalizing the text during tokenization, variations in capitalization, word forms, and punctuation can be reduced, enabling accurate matching and retrieval of relevant information.
Information retrieval systems utilize tokenization to enable efficient searching and retrieval of relevant information. By matching the query terms with the tokens in a large corpus of documents, these systems can quickly identify and retrieve the most relevant documents based on their tokenized contents. This efficiency is critical in scenarios where large volumes of documents need to be searched and relevant information needs to be retrieved rapidly.
Furthermore, tokenization aids in semantic matching and understanding in information retrieval. By analyzing the context and relationships between tokens, information retrieval systems can infer semantic similarities and relevance between query terms and document tokens. This allows for more accurate retrieval of relevant documents even in cases where the exact query terms are not present in the document.
Information retrieval is a vital application in various domains, including search engines, document management systems, digital libraries, and enterprise knowledge bases. By leveraging tokenization, these systems can provide users with quick and accurate access to the desired information from vast collections of documents.
In summary, tokenization is a crucial step in information retrieval, enabling efficient searching and retrieval of relevant information. By breaking down the query and documents into tokens, tokenization facilitates precise matching and semantic understanding. Information retrieval systems leverage tokenization to provide users with quick and accurate access to relevant information, making it an essential component of NLP applications in search engines, document management systems, and other information-centric domains.
Conclusion
Tokenization is a fundamental concept in Natural Language Processing (NLP) that plays a crucial role in various applications. By breaking down text into smaller units such as words or phrases, tokenization enables efficient and accurate analysis of textual data. Throughout this article, we explored the definition of tokenization and its applications in NLP.
In the field of NLP, tokenization serves as the foundation for several tasks. It plays a vital role in text preprocessing, where it facilitates cleaning and preparing raw text for further analysis. Tokenization enables the removal of unwanted characters, punctuation, and stopwords, as well as the normalization of text. This standardized representation of textual data improves the efficiency and quality of subsequent NLP tasks.
Tokenization is also essential in word frequency analysis, where it allows for the counting and analysis of word occurrences. Through tokenization, we can gain insights into the most frequent words in a document or corpus, aiding in keyword extraction, summarization, and topic modeling.
Sentiment analysis benefits from tokenization by breaking down text into individual words or phrases, facilitating the assessment of sentiment polarity. By analyzing the sentiment expressed in the text, sentiment analysis algorithms can understand public opinion, customer feedback, and social media sentiment.
Named Entity Recognition (NER) relies on tokenization to identify and classify named entities within a text. Tokenization enables the analysis of the context and semantic meaning of tokens, assisting in information retrieval, question answering, and text summarization.
Language modeling leverages tokenization to predict the next word in a sequence, enabling tasks such as auto-completion, machine translation, text generation, and speech recognition. Tokenization aids in capturing the structure and meaning of the text, allowing language models to generate coherent and contextually relevant predictions.
Machine translation benefits from tokenization by breaking down the source and target texts into tokens, enabling accurate alignment for translation. Tokenization preserves the structure and meaning of the text, facilitating high-quality translations and breaking down language barriers.
Tokenization is also crucial in information retrieval, allowing for efficient searching and retrieval of relevant documents or information. By matching query terms with tokens in a document corpus, information retrieval systems deliver fast and accurate retrieval results, facilitating access to relevant information.
In conclusion, tokenization is a vital concept in NLP, enabling efficient and accurate analysis of textual data. By breaking text into smaller units, tokenization supports various tasks such as text preprocessing, word frequency analysis, sentiment analysis, named entity recognition, language modeling, machine translation, and information retrieval. By leveraging tokenization techniques and algorithms, we can unlock valuable insights and understanding from unstructured text, contributing to advancements in NLP and improving our ability to analyze and process textual data effectively.