Introduction
Welcome to the fascinating world of anomaly detection in machine learning! Machine learning algorithms have revolutionized various industries by enabling us to analyze vast amounts of data and extract valuable insights. However, in any dataset, there may be instances that deviate significantly from the norm, indicating potential anomalies. These anomalies can be indicative of errors, outliers, or even fraudulent activities.
Anomalies, also known as outliers, are data points that significantly differ from the rest of the dataset. They can arise due to various reasons, such as measurement errors, sensor malfunctions, data corruption, or rare events. Detecting anomalies is critical for numerous applications, including fraud detection, network security, predictive maintenance, medical diagnosis, and quality control.
Identifying anomalies is crucial for ensuring the accuracy and reliability of data analysis. By detecting these anomalies, organizations can take proactive measures to rectify issues, prevent losses, and optimize their operations. However, the task of finding anomalies can be challenging due to several factors, including the vast amounts of data, complex patterns, and evolving risks.
In this article, we will explore the different types of anomalies, discuss their importance, and delve into various approaches for detecting them in machine learning models. We will examine supervised, unsupervised, and semi-supervised anomaly detection techniques, along with tips for improving detection performance. Additionally, we will explore real-world applications where anomaly detection plays a vital role.
Whether you are a data scientist, analyst, or business professional, understanding how to find anomalies in machine learning models is essential for making informed decisions and maintaining data integrity. So, let us dive into the world of anomaly detection and unravel its intricacies.
Anomalies in Machine Learning
Anomalies are data points that deviate significantly from the expected behavior or pattern within a dataset. In machine learning, the aim is to build models that can accurately predict or classify data based on patterns observed in the training set. However, anomalies pose a challenge to this process as they do not conform to the established patterns and can introduce errors or biases in the model’s output.
There are various types of anomalies that can occur in machine learning datasets. Some common types include:
- Point Anomalies: These are individual data points that are significantly different from others in the dataset. For example, in a dataset of customer transaction amounts, a very large or very small transaction value could be considered a point anomaly.
- Contextual Anomalies: Contextual anomalies are data points that are abnormal in a particular context but not necessarily abnormal in the overall dataset. For instance, during a holiday season, a sudden surge in online sales can be considered a contextual anomaly if it is significantly higher than the average sales during non-holiday periods.
- Collective Anomalies: Collective anomalies occur when a subset of data points together exhibits anomalous behavior, while individually, they may appear normal. These anomalies are often identified by examining the relationships and interactions between data points. For example, in a network traffic dataset, a distributed denial-of-service (DDoS) attack may result in an abnormal surge in network traffic across multiple IP addresses.
- Temporal Anomalies: Temporal anomalies refer to data points that exhibit abnormal behavior over time. This can include sudden spikes or drops in values, recurring patterns at unexpected intervals, or long-term trends that deviate from the expected pattern. These anomalies are commonly found in time series data, such as stock prices, weather data, or sensor readings.
The presence of anomalies in machine learning datasets can have significant consequences. They can lead to inaccurate predictions, biased insights, and even financial losses. Therefore, it is crucial to detect and handle anomalies effectively to ensure the integrity and reliability of machine learning models.
Next, we will explore the importance of finding anomalies and the challenges associated with their detection in machine learning.
Importance of Finding Anomalies
The task of finding anomalies in machine learning is of utmost importance for several reasons. Let’s explore why detecting anomalies is crucial:
Data Accuracy: Anomalies can significantly affect the accuracy of machine learning models. By identifying and handling these anomalies, we can ensure that the models are trained on high-quality, reliable data. This, in turn, leads to more accurate predictions and reliable insights.
Error Detection: Anomalies often indicate errors or inconsistencies in data. By identifying these anomalies, organizations can identify and rectify these errors, ensuring data integrity and preventing downstream issues caused by incorrect data.
Fraud Detection: Anomaly detection plays a vital role in fraud detection and security-related applications. By analyzing patterns and detecting anomalies in transactional data or user behavior, organizations can identify potential fraud and security breaches. This allows them to implement appropriate measures to mitigate risks and protect sensitive information.
Performance Optimization: Anomalies can provide valuable insights into areas of improvement and optimization. By identifying abnormal patterns or outliers in a process or system, organizations can identify bottlenecks, inefficiencies, or anomalies that indicate opportunities to optimize operations and enhance performance.
Early Warning Systems: Anomaly detection techniques can be used to build early warning systems for various applications. By continuously monitoring data streams or processes and detecting anomalies in real-time, organizations can take proactive measures to address potential issues before they escalate, minimizing the impact on operations and reducing downtime.
Quality Control: Anomaly detection is essential in maintaining product quality and ensuring adherence to standards. By monitoring sensor data, production metrics, or inspection data, organizations can identify abnormalities that may indicate issues in the production process. This allows them to take corrective actions and maintain quality standards.
Healthcare and Medical Diagnosis: Anomalies in healthcare data can be indicative of potential health issues or abnormalities in patient conditions. Anomaly detection techniques can help identify these anomalies, allowing healthcare professionals to diagnose and treat patients more effectively.
Regulatory Compliance: Anomaly detection is crucial in industries with strict regulations, such as finance and healthcare. By detecting anomalies in financial transactions or medical records, organizations can ensure compliance with regulatory requirements and uncover potential fraudulent or malicious activities.
Overall, the ability to find anomalies in machine learning datasets is essential for data accuracy, error detection, fraud prevention, performance optimization, early warning systems, quality control, healthcare, regulatory compliance, and many other applications. It empowers businesses to make informed decisions, minimize risks, and achieve optimal results. Next, we will explore the common types of anomalies encountered in machine learning datasets.
Common Types of Anomalies
When it comes to anomalies in machine learning, there are several common types that can be encountered in datasets. Understanding these types can help in better identification and handling of anomalies. Let’s explore some of the common types:
- Point Anomalies: Point anomalies are individual data points that significantly deviate from the rest of the dataset. These anomalies stand out as outliers due to their extreme values or unusual characteristics. For example, in a dataset of credit card transactions, a purchase amount that is much larger or smaller than the average transaction amount can be considered a point anomaly.
- Contextual Anomalies: Contextual anomalies occur when a data point is considered abnormal in a specific context but not necessarily unusual in the overall dataset. For instance, in a dataset of temperature recordings, a sudden spike in temperature during winter months would be considered a contextual anomaly as it deviates from the expected behavior.
- Collective Anomalies: Collective anomalies involve a group or subset of data points that exhibit anomalous behavior together, even though individually they may appear normal. These anomalies can be detected by considering the interactions and relationships between data points. For example, in a network traffic dataset, a group of IP addresses that are simultaneously involved in suspicious activities may indicate a collective anomaly like a coordinated attack.
- Temporal Anomalies: Temporal anomalies refer to abnormalities detected over time. These anomalies are identified by observing patterns and trends in time series data. They can include sudden spikes or drops in values, unexpected recurring patterns, or long-term trends that deviate from the expected behavior. For example, in a stock market dataset, a significant price increase or decrease that deviates from the usual fluctuations can be identified as a temporal anomaly.
- Distributional Anomalies: Distributional anomalies involve data points that do not conform to the expected probability distribution of the dataset. These anomalies occur when the observed data significantly deviates from the expected distributional properties, such as mean, variance, or skewness. For example, in a dataset of exam scores that follows a normal distribution, a score that is far outside the expected range can be considered a distributional anomaly.
By understanding the different types of anomalies, data analysts and machine learning practitioners can adopt appropriate techniques and algorithms specific to each type for effective anomaly detection. However, it is important to note that these types are not mutually exclusive, and there can be overlaps between different types of anomalies in real-world datasets.
Now that we have explored the common types of anomalies, let’s move on to understanding the challenges associated with detecting anomalies in machine learning.
Challenges in Finding Anomalies
The task of finding anomalies in machine learning datasets is not without its challenges. These challenges can arise due to various factors, making the detection and handling of anomalies a complex task. Let’s explore some of the common challenges in finding anomalies:
- Data Imbalance: Anomalies are often rare occurrences compared to normal data points, resulting in data imbalance. This makes it challenging to train machine learning models to accurately detect anomalies as they have limited exposure to such instances.
- Uncertainty in Anomaly Definition: Defining what is considered an anomaly can be subjective and dependent on the specific context and application. Anomalies can vary from dataset to dataset and may require domain knowledge or expert input to define clear boundaries.
- Complex Data Patterns: In real-world datasets, anomalies can exhibit diverse and complex patterns, making them hard to detect using traditional methods. Anomalies may be hidden within high-dimensional datasets or may exhibit subtle changes over time, requiring advanced techniques for detection.
- Data Preprocessing: Preprocessing data for anomaly detection can be challenging. Noisy or incomplete data can impact the accuracy of anomaly detection algorithms. Missing values, outliers, or data errors require careful handling to ensure accurate anomaly detection.
- Labeling Anomalies: In supervised anomaly detection, anomaly labels are necessary for training the model. However, labeling anomalies can be difficult and time-consuming, especially when dealing with large datasets or when anomalies are not clearly defined.
- Real-Time Detection: For applications that require real-time anomaly detection, there is a need for efficient algorithms that can process and analyze data streams in real-time. This presents additional challenges, such as handling high volumes of data and making quick decisions without compromising accuracy.
- Model Interpretability: Understanding and interpreting anomaly detection models can be complex, especially when using sophisticated techniques like deep learning. The interpretability of models is crucial for gaining insights into the detected anomalies and taking appropriate actions.
- Adaptation to Concept Drift: In dynamic environments, data distributions can change over time, leading to concept drift. Anomaly detection models need to adapt to such changes to ensure continual accuracy in detecting anomalies.
Addressing these challenges requires a combination of domain knowledge, advanced algorithms, and meticulous data preprocessing. It is essential to select appropriate techniques and continually evaluate and refine the anomaly detection process to ensure effective identification and handling of anomalies.
Now that we have explored the challenges in finding anomalies, let’s delve into the various approaches and techniques used for detecting anomalies in machine learning.
Approaches to Finding Anomalies
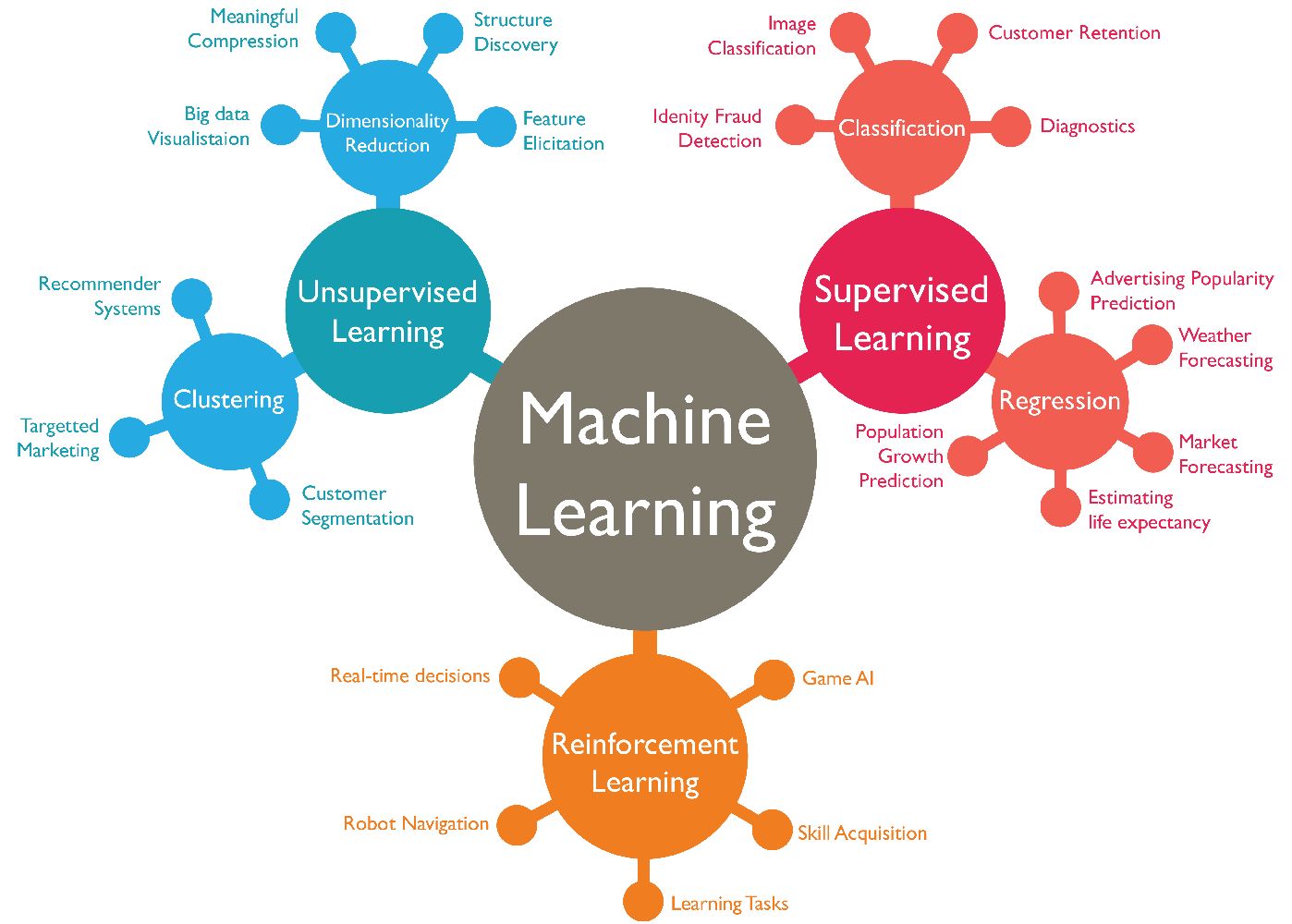
There are various approaches and techniques that can be used to find anomalies in machine learning datasets. These approaches can be broadly categorized into three main types: supervised, unsupervised, and semi-supervised anomaly detection. Let’s explore each of these approaches:
- Supervised Anomaly Detection: In supervised anomaly detection, anomalies are identified by training a model on labeled data, where anomalies are explicitly labeled. The model learns the patterns and characteristics of normal data and then classifies new instances as either normal or anomalous based on the learned patterns. Supervised approaches require a labeled dataset, which can be challenging to obtain in some cases.
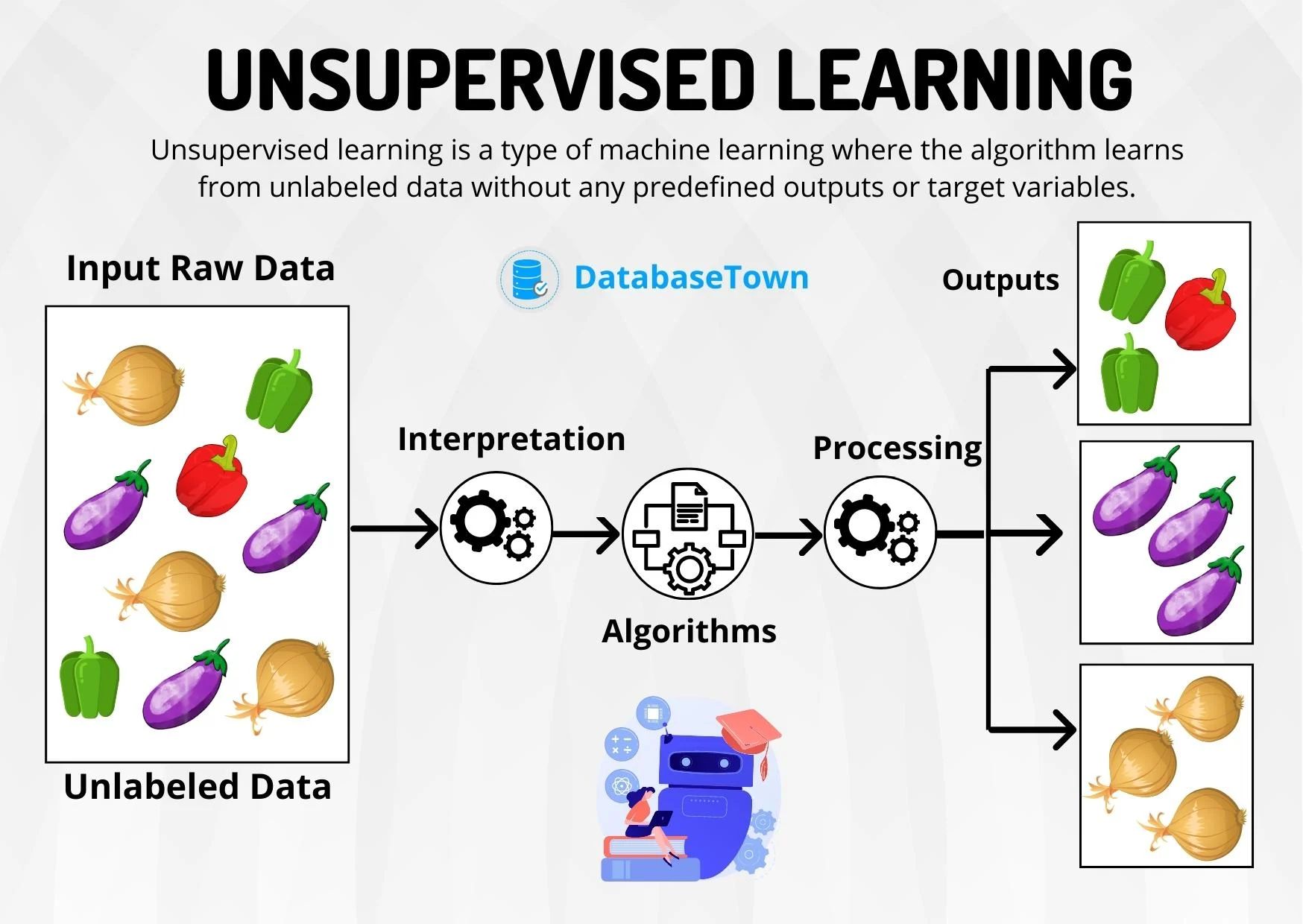
- Unsupervised Anomaly Detection: Unsupervised anomaly detection does not rely on labeled data. Instead, it focuses on identifying anomalies by analyzing the characteristics and structure of the data without any prior knowledge of what constitutes an anomaly. Unsupervised approaches use various statistical techniques, clustering algorithms, or density-based methods to identify anomalies based on deviations from the expected patterns in the data.
- Semi-Supervised Anomaly Detection: Semi-supervised anomaly detection combines elements of both supervised and unsupervised approaches. It uses a small proportion of labeled data and a larger proportion of unlabeled data for training. The model learns the patterns of normal data from labeled examples and then detects anomalies in the unlabeled data based on deviations from the learned patterns. Semi-supervised techniques can provide improved accuracy compared to fully unsupervised methods, especially when labeled data is limited.
The choice of the most suitable approach depends on the availability of labeled data, the nature of the dataset, and the specific requirements of the application. Additionally, various techniques can be employed within each approach, such as statistical methods (e.g., z-scores, percentiles), clustering-based approaches (e.g., k-means, DBSCAN), density estimation techniques (e.g., Gaussian mixture models, kernel density estimation), or advanced machine learning algorithms (e.g., neural networks, support vector machines).
Furthermore, ensemble methods, which combine the predictions of multiple anomaly detection models, can be utilized to enhance the accuracy and robustness of anomaly detection systems. Ensemble methods can leverage the complementary strengths of different models and provide more reliable anomaly detection results.
When selecting an approach and technique for finding anomalies, it is crucial to evaluate their performance and consider factors such as computational efficiency, interpretability, and the specific requirements and constraints of the problem at hand.
Now that we have explored the different approaches to finding anomalies, let’s dive deeper into each approach and discuss specific techniques and algorithms within them.
Supervised Anomaly Detection Techniques
Supervised anomaly detection techniques rely on labeled data, where anomalies are explicitly labeled. These techniques train a model using the labeled data and learn the patterns and characteristics of normal instances. They then classify new instances as either normal or anomalous based on the learned patterns. Let’s explore some common supervised anomaly detection techniques:
- Classification Algorithms: Supervised classification algorithms, such as Decision Trees, Random Forests, or Support Vector Machines (SVM), can be applied to anomaly detection. These algorithms learn the boundary between normal and anomalous instances and classify new instances accordingly. Ensemble methods, like AdaBoost or Bagging, can also be used to enhance the accuracy of classification-based anomaly detection.
- One-Class SVM: One-Class Support Vector Machines (SVM) is a popular supervised anomaly detection technique. It learns the characteristics of normal instances and creates a boundary that separates normal instances from anomalous ones. New instances falling outside this boundary are classified as anomalies. One-Class SVM is particularly useful when only normal instances are available for training.
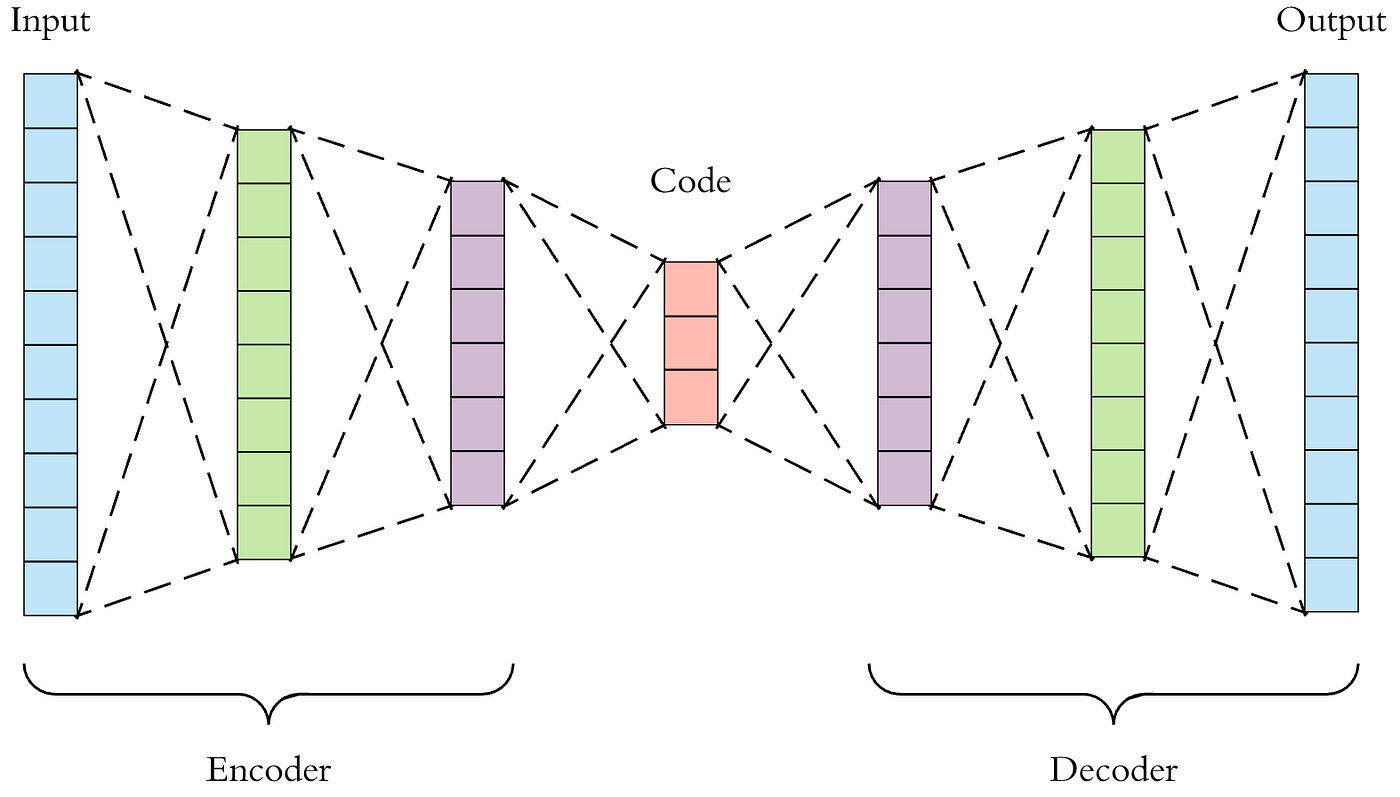
- Neural Networks: Neural networks, such as Autoencoders or Variational Autoencoders (VAE), can also be employed for supervised anomaly detection. These models are trained on normal instances and learn to reconstruct the input data accurately. Anomalies are identified as instances that have a high reconstruction error compared to normal instances.
- Cluster-Based Approaches: Supervised anomaly detection can also be performed using clustering algorithms. The idea is to first cluster the normal instances, then classify instances outside the clusters as anomalies. This approach can be effective when anomalies do not belong to any existing clusters and exhibit distinct characteristics.
Supervised anomaly detection techniques offer the advantage of being able to accurately identify anomalies with labeled data. However, they can be limited by the availability of labeled instances, as labeling anomalies can be time-consuming and costly. Additionally, supervised approaches may struggle with identifying novel anomalies that differ significantly from the labeled anomalies used for training.
It is important to note that supervised techniques can still be utilized in scenarios where limited labeled anomaly data is available. In these cases, techniques such as active learning or transfer learning can be employed to make the most efficient use of the available labeled data and improve anomaly detection performance.
Now that we have explored the supervised anomaly detection techniques, let’s move on to discussing unsupervised anomaly detection techniques.
Unsupervised Anomaly Detection Techniques
Unsupervised anomaly detection techniques rely on the characteristics and structure of the data itself, without the need for labeled instances. These techniques aim to detect anomalies by identifying patterns that deviate significantly from the expected normal behavior. Let’s explore some common unsupervised anomaly detection techniques:
- Statistical Methods: Statistical methods are commonly used for unsupervised anomaly detection. They involve calculating statistical measures such as z-scores, percentiles, or interquartile ranges to identify instances that deviate significantly from the expected statistical distribution of the data. Outliers, as identified by these measures, can be considered anomalies.
- Clustering-Based Approaches: Unsupervised anomaly detection can also be performed using clustering algorithms. These algorithms group similar instances together based on their distance or density. Instances that do not belong to any cluster or belong to very small or sparse clusters are considered anomalies. Popular clustering algorithms for anomaly detection include k-means, DBSCAN, or Gaussian Mixture Models (GMM).
- Density Estimation: Density estimation techniques estimate the distribution of normal data and identify instances that have very low probability under the estimated distribution. This includes methods like Kernel Density Estimation (KDE), where a density function is built based on the data points, and instances with low density values are classified as anomalies.
- Distance-Based Approaches: Distance-based methods measure the distance between instances in the dataset and use this information to detect anomalies. Instances that are significantly distant from the majority of the data points are considered anomalies. Common distance-based techniques include Local Outlier Factor (LOF), which compares the density of instances to their neighbors, and the Mahalanobis distance, which considers the correlation between features.
- Isolation Forest: The Isolation Forest algorithm is another popular unsupervised anomaly detection technique. It constructs random decision trees and isolates anomalies by locating instances that require fewer splits to be separated from the majority of the data points. Anomalies are considered instances that have a shorter average path length in the trees.
Unsupervised anomaly detection techniques are particularly useful when labeled instances are scarce or unavailable. They can discover anomalies without prior knowledge about the specific characteristics of anomalous instances. However, they may have limitations in correctly identifying complex or subtle anomalies that are not easily detectable based solely on statistical measures or clustering algorithms.
It is worth noting that hybrid approaches combining elements of supervised and unsupervised techniques, or incorporating domain knowledge and expert input, can be used to improve the accuracy of anomaly detection in real-world scenarios.
Having explored unsupervised anomaly detection techniques, let’s now move on to discussing semi-supervised anomaly detection techniques.
Semi-Supervised Anomaly Detection Techniques
Semi-supervised anomaly detection techniques combine elements of supervised and unsupervised approaches. These techniques utilize a limited amount of labeled data and a larger proportion of unlabeled data to train a model that can identify anomalies. Let’s explore some common semi-supervised anomaly detection techniques:
- Self-Training: Self-training is a technique where a model is initially trained on the labeled examples and then used to predict labels for the unlabeled instances. These predictions are then incorporated back into the training set as additional labeled data. This iterative process continues until the model converges or reaches a predefined stopping criterion. Self-training enables the model to learn from both labeled and unlabeled data, improving anomaly detection performance.
- Co-training: Co-training is another semi-supervised technique that uses multiple models or views of the data. Each model is trained on a different subset of features or a different representation of the data. The models then exchange and learn from one another’s predictions on the unlabeled data. Co-training leverages the diversity of the models and the information contained in different feature subsets to enhance the accuracy of anomaly detection.
- Generative Models: Generative models, such as Variational Autoencoders (VAE) or Generative Adversarial Networks (GANs), can be used for semi-supervised anomaly detection. These models learn the underlying distribution of normal instances and generate new instances based on this distribution. Anomalies are identified as instances that have a low likelihood of being generated by the model.
- Active Learning: Active learning is a technique that selects the most informative instances from the unlabeled data and asks an oracle (e.g., domain expert) to label them. The model is then updated using the labeled instances, and the process is iterated. Active learning focuses on intelligently selecting instances that would most benefit the model’s learning process, thereby maximizing the use of limited labeled data for anomaly detection.
Semi-supervised anomaly detection techniques combine the benefits of utilizing labeled data while also making effective use of the larger amount of unlabeled data. They can improve the anomaly detection performance, especially in scenarios where obtaining labeled anomaly data is challenging or expensive.
It is important to note that semi-supervised techniques require careful consideration and selection of the labeled data to ensure that it is representative of the anomaly distribution. Inappropriate selection or improper labeling can lead to biased models or inaccurate anomaly detection results.
Now that we have explored semi-supervised anomaly detection techniques, let’s move on to discussing the evaluation of anomaly detection models.
Evaluation of Anomaly Detection Models
Evaluating the performance of anomaly detection models is crucial to assess their effectiveness and determine their suitability for the given task. However, evaluating the performance of anomaly detection models can be challenging as it differs from traditional supervised learning tasks that involve binary classification. Let’s explore some common evaluation techniques for anomaly detection models:
- Confusion Matrix: The confusion matrix is a commonly used evaluation metric for anomaly detection models. It provides a breakdown of true positive (anomalies correctly detected), true negative (normal instances correctly identified), false positive (normal instances classified as anomalies), and false negative (anomalies missed) counts. From the confusion matrix, various metrics such as precision, recall, and F1-score can be calculated.
- Receiver Operating Characteristic (ROC) Curve: The ROC curve is a graphical representation of the performance of an anomaly detection model. It plots the true positive rate against the false positive rate at different threshold settings. The area under the ROC curve (AUC-ROC) is often used as a performance metric for anomaly detection models, with a higher AUC-ROC indicating better performance.
- Precision-Recall Curve: The precision-recall curve is another useful evaluation metric for anomaly detection models. It plots precision (fraction of correctly detected anomalies) against recall (fraction of actual anomalies detected). The area under the precision-recall curve (AUC-PR) provides an overall measure of the model’s performance, with a higher AUC-PR indicating better anomaly detection capability.
- Anomaly Detection Rate: The anomaly detection rate calculates the percentage of anomalies successfully detected by the model. It provides a measure of the model’s effectiveness in identifying anomalies and can be used as a performance metric when the emphasis is on correctly detecting anomalies rather than minimizing false positives.
- Domain-Specific Metrics: Depending on the specific application and domain, additional domain-specific evaluation metrics may be defined. For example, in fraud detection, metrics such as the amount of money saved by detecting fraudulent transactions or the ratio of false positives to true positives may be more relevant than traditional evaluation metrics.
It is important to note that the choice of evaluation metric depends on the specific requirements and priorities of the application. Different metrics may be more appropriate in different contexts, and the selection should align with the desired goals of the anomaly detection task.
Additionally, evaluating anomaly detection models requires appropriate datasets for testing and validation. It is essential to have a representative dataset that includes a sufficient number of anomalies to assess the model’s performance accurately. The dataset should also capture a wide range of normal behaviors to avoid biased evaluations.
By employing appropriate evaluation techniques and metrics, practitioners can assess the performance and efficacy of anomaly detection models, providing insights into their strengths, weaknesses, and areas for improvement.
Now that we have discussed the evaluation of anomaly detection models, let’s move on to explore some tips for improving anomaly detection performance.
Tips for Improving Anomaly Detection Performance
Anomaly detection performance can be improved by considering various factors and adopting specific techniques. Let’s explore some tips to enhance the performance of anomaly detection models:
- Feature Engineering: Selecting and engineering informative features can significantly impact anomaly detection performance. It is essential to carefully analyze the dataset and identify relevant features that capture the characteristics of normal and anomalous instances. Domain knowledge and feature scaling techniques, such as normalization or standardization, can also be applied to improve performance.
- Outlier Removal: Before training the model, it can be beneficial to remove outliers from the dataset. Outliers that do not represent true anomalies can introduce noise to the model and affect its performance. Removing these outliers can enhance the model’s ability to detect meaningful anomalies.
- Ensemble Approaches: Ensemble techniques can be utilized to improve anomaly detection performance. Combining the predictions of multiple models can provide more accurate and reliable results. Ensemble methods can incorporate diverse perspectives, capture different types of anomalies, and reduce the impact of individual model biases or weaknesses.
- Threshold Selection: Setting an appropriate anomaly detection threshold is crucial. The threshold determines the boundary between normal and anomalous instances. It should be chosen carefully to balance between false positives (normal instances classified as anomalies) and false negatives (anomalies missed). Consider the application’s tolerance for different types of errors and adjust the threshold accordingly.
- Model Selection and Tuning: Different anomaly detection algorithms or models have different strengths and weaknesses. It is essential to experiment with multiple models and evaluate their performance on the specific dataset. Fine-tune the selected model by adjusting hyperparameters, such as the number of neighbors in a clustering algorithm or the regularization factor in a neural network, to optimize performance.
- Continuous Monitoring and Updating: Anomaly detection is not a one-time task. Monitoring data continuously is critical to identify and adapt to changing patterns or emerging anomalies. Regularly updating the model based on new data ensures its relevance and effectiveness in detecting anomalies over time.
- Validation and Cross-Validation: Validation techniques, such as hold-out validation or k-fold cross-validation, can provide insights into the generalization performance of the anomaly detection model. By validating the model on independent datasets, practitioners can assess its robustness and ensure it performs well on unseen data.
By implementing these tips, practitioners can enhance the performance of their anomaly detection models and improve the accuracy, efficiency, and reliability of identifying anomalies. It is important to adapt and optimize these strategies based on the specific characteristics of the dataset, the requirements of the application, and the available resources.
Now that we have explored tips for improving anomaly detection performance, let’s move on to discussing real-world applications where anomaly detection plays a crucial role.
Real-World Applications of Anomaly Detection
Anomaly detection has widespread applications across various industries and domains. Let’s explore some real-world applications where anomaly detection plays a crucial role:
- Fraud Detection: Anomaly detection is extensively used in financial and banking sectors to detect fraudulent activities, such as credit card fraud, money laundering, or insurance fraud. By analyzing transactional patterns and customer behavior, anomaly detection models can identify suspicious activities and trigger alerts for further investigation.
- Network Security: Anomaly detection is crucial in network security to identify and prevent cyber threats. By monitoring network traffic and analyzing patterns, anomalies, and unusual behaviors can be detected, indicating potential security breaches, malware attacks, or unauthorized access attempts.
- Predictive Maintenance: Anomaly detection is applied in industrial settings to predict and prevent equipment failures or breakdowns. By monitoring sensor data and detecting anomalies in performance metrics, maintenance teams can take proactive measures to fix issues before they result in costly downtime or accidents.
- Healthcare and Medical Diagnosis: Anomaly detection plays a crucial role in healthcare for medical diagnosis, patient monitoring, and identifying abnormal conditions. By analyzing patient data, such as vital signs, lab results, or medical imaging, anomalies can be detected to support accurate diagnosis, early detection of diseases, and improved patient care.
- Quality Control: Anomaly detection is used in manufacturing and production processes to ensure product quality and identify defects or abnormalities on the assembly line. By monitoring sensor data and detecting anomalies in product parameters or quality metrics, organizations can take corrective actions to maintain high-quality standards.
- Cybersecurity: Anomaly detection plays a critical role in cybersecurity to detect and prevent cyber threats and attacks. By monitoring system logs, user behavior, or network traffic, anomalies can indicate malicious activities, such as data breaches, ransomware attacks, or advanced persistent threats.
- Sensor Networks and IoT: Anomaly detection is utilized in sensor networks and Internet of Things (IoT) applications to monitor and control various systems. By analyzing sensor data and identifying anomalies, critical events or abnormal behaviors can be detected, enabling timely actions for safety, energy efficiency, or optimizing system performance.
- Social Media and Online Platforms: Anomaly detection is employed in social media platforms and online systems to detect spam, fake accounts, or abusive behavior. By analyzing user behavior patterns and identifying anomalies, platforms can ensure trusted and secure online experiences.
These are just a few examples of how anomaly detection is utilized in real-world applications. The ability to detect anomalies enables organizations to mitigate risks, improve efficiency, enhance security, and make informed decisions. By leveraging anomaly detection techniques, businesses can gain valuable insights from their data and take proactive measures to address abnormalities and unusual patterns.
Now that we have explored the real-world applications of anomaly detection, let’s conclude our article and summarize the key insights we have discussed.
Conclusion
Anomaly detection is a vital component of machine learning and data analysis. It plays a crucial role in various domains, including fraud detection, network security, predictive maintenance, healthcare, quality control, and many others. By identifying anomalies, organizations can detect errors, prevent losses, optimize operations, and improve decision-making processes.
In this article, we explored different types of anomalies, including point anomalies, contextual anomalies, collective anomalies, temporal anomalies, and distributional anomalies. We discussed the importance of finding anomalies and the challenges associated with their detection in machine learning.
We explored three main approaches to anomaly detection: supervised, unsupervised, and semi-supervised. Supervised techniques utilize labeled data to train models, while unsupervised techniques rely on the characteristics of the data itself. Semi-supervised approaches combine elements of both supervised and unsupervised techniques to leverage limited labeled data effectively.
We also discussed evaluation techniques for assessing the performance of anomaly detection models, such as confusion matrix, ROC curve, precision-recall curve, anomaly detection rate, and domain-specific metrics. To improve performance, we explored tips including feature engineering, outlier removal, ensemble approaches, threshold selection, model selection and tuning, continuous monitoring and updating, and validation techniques.
Finally, we delved into various real-world applications of anomaly detection, including fraud detection, network security, predictive maintenance, healthcare, quality control, cybersecurity, sensor networks, and social media platforms.
Understanding and effectively detecting anomalies is crucial for ensuring data accuracy, error detection, fraud prevention, performance optimization, and compliance with regulations. By leveraging anomaly detection techniques and adopting best practices, organizations can reap the benefits of reliable insights, proactive decision-making, and enhanced operational efficiency.
As the field of anomaly detection continues to evolve, it is important to stay updated with new algorithms, techniques, and emerging practices to tackle the ever-evolving challenges of detecting anomalies in machine learning and data analysis.