Introduction
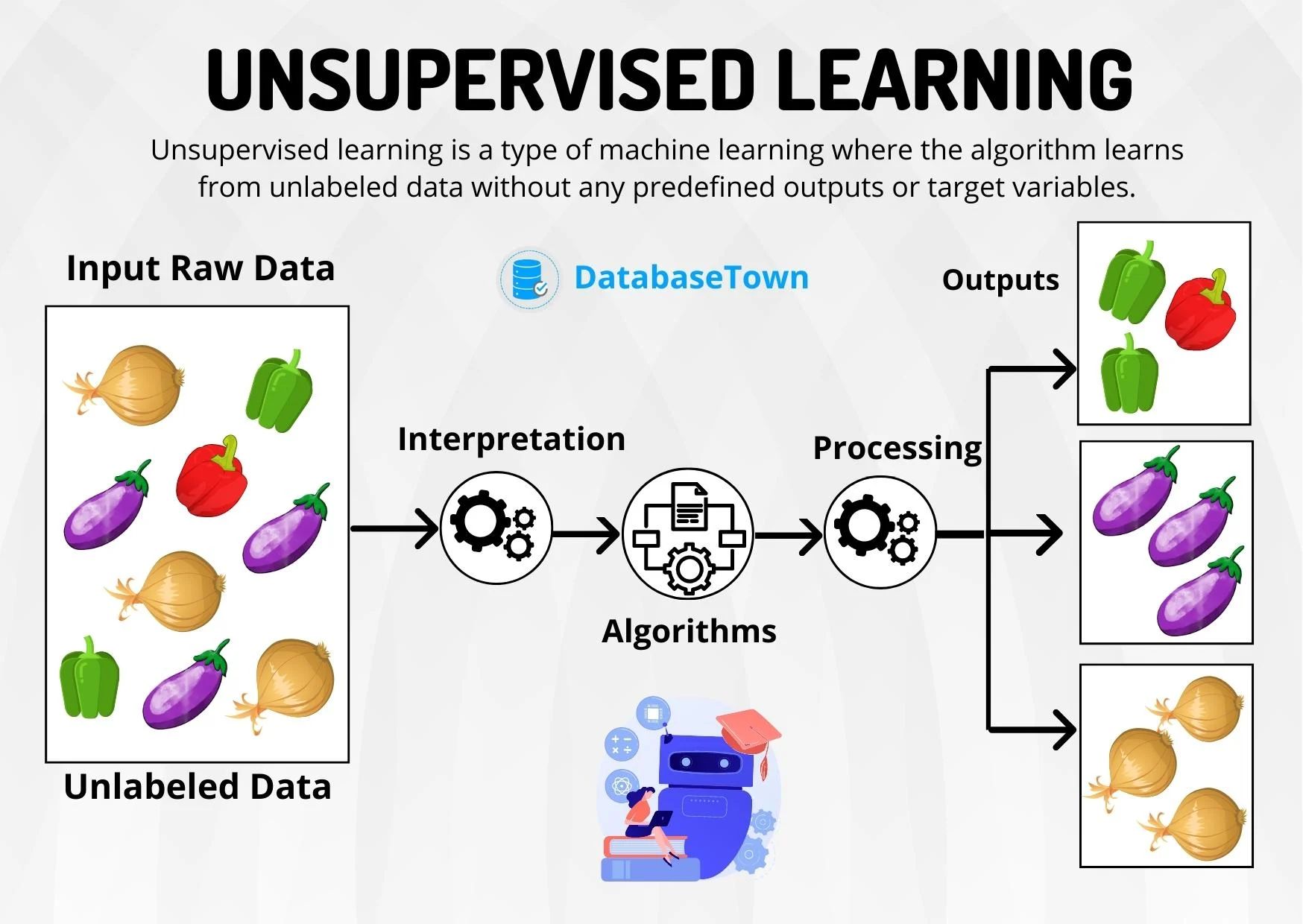
Unsupervised machine learning is a branch of artificial intelligence (AI) that focuses on discovering patterns and relationships in data without the need for labeled examples. Unlike supervised learning, where the algorithm is trained using labeled data to make predictions, unsupervised learning algorithms work on unlabeled data to find meaningful structures or groupings.
Unsupervised machine learning is particularly useful when dealing with large and complex datasets where it is difficult or impossible to manually label each data point. By analyzing the inherent patterns and similarities within the data, unsupervised algorithms can provide valuable insights and make sense of unstructured information.
One of the main goals of unsupervised learning is to uncover hidden, unknown, or previously unrecognized patterns that may be present in the data. This can be accomplished through various techniques such as clustering, dimensionality reduction, association rule learning, and anomaly detection. Each technique has its own unique approach and can be applied to different types of data analysis problems.
In recent years, unsupervised machine learning has gained significant attention and popularity due to its wide range of applications. From customer segmentation in marketing to anomaly detection in cybersecurity, unsupervised learning algorithms have proven to be powerful tools for data analysis and decision-making.
However, it’s important to note that unsupervised learning also has its limitations. Without labeled data to train and evaluate the algorithm, it can be challenging to measure the performance or interpret the results accurately. Additionally, the quality and relevance of the insights derived from unsupervised learning heavily rely on the quality and relevance of the input data.
In this article, we will explore the different types of unsupervised machine learning algorithms and discuss their advantages, limitations, and various applications. Whether you are a data scientist, a business professional, or simply curious about the field of machine learning, understanding unsupervised learning can open up new possibilities for analyzing and extracting knowledge from data.
What is Unsupervised Machine Learning?
Unsupervised machine learning is a branch of artificial intelligence that involves training algorithms to automatically learn and discover patterns, structures, or relationships in data without any explicit or pre-defined labels. In other words, the algorithm is left on its own to find useful information and meaningful insights from the input data without any guidance.
The main objective of unsupervised learning is to identify hidden patterns or structures within the data that may not be apparent to humans. By analyzing the inherent similarities and differences among data points, unsupervised algorithms can group similar instances together and detect interesting relationships or clusters.
Unsupervised learning algorithms can be used for various purposes, including data exploration, feature extraction, data preprocessing, and anomaly detection. These algorithms are particularly useful when it comes to dealing with large and complex datasets where manual labeling is impractical or infeasible.
There are several fundamental techniques used in unsupervised machine learning, such as clustering, dimensionality reduction, association rule learning, and anomaly detection.
1. Clustering: Clustering algorithms group similar data points together based on their proximity or similarity. The goal is to maximize the similarity within clusters and minimize the similarity between different clusters. Clustering is commonly used for customer segmentation, image recognition, and data compression.
2. Dimensionality Reduction: Dimensionality reduction techniques aim to reduce the number of input variables (or features) while retaining the most relevant information. This is done by transforming the original high-dimensional data into a lower-dimensional representation. Dimensionality reduction helps in visualization, feature selection, and noise removal.
3. Association Rule Learning: Association rule learning algorithms identify interesting relationships or associations among different variables in the data. These algorithms are widely used in market basket analysis, where the goal is to discover patterns in customer purchasing behavior.
4. Anomaly Detection: Anomaly detection algorithms focus on identifying outliers or anomalies in the dataset. These anomalies can represent unusual events, fraud detection, or errors in the data. Anomaly detection is crucial in various domains, including cybersecurity, healthcare, and finance.
While unsupervised machine learning has its advantages, such as the ability to uncover hidden patterns and gain insights from unlabeled data, it also has its limitations. It can be challenging to evaluate the performance of unsupervised algorithms without labeled data and to determine the suitability of the obtained results. Additionally, the quality and relevance of the insights heavily depend on the quality and relevance of the input data.
In the following sections, we will dive deeper into each type of unsupervised learning algorithm, exploring their characteristics, use cases, and benefits.
Types of Unsupervised Machine Learning Algorithms
Unsupervised machine learning encompasses several distinct types of algorithms that are used to discover patterns, relationships, and structures within data. These algorithms can be broadly categorized into four main types: clustering algorithms, dimensionality reduction algorithms, association rule learning algorithms, and anomaly detection algorithms. Let’s explore each of these types in more detail.
1. Clustering Algorithms: Clustering algorithms aim to group similar data points together based on their inherent similarities or distances from each other. The goal is to create homogeneous clusters where data points within the same cluster are more similar to each other than to those in other clusters. Popular clustering algorithms include K-means clustering, hierarchical clustering, and DBSCAN. Clustering is widely used in various fields, such as customer segmentation, image recognition, and social network analysis.
2. Dimensionality Reduction Algorithms: Dimensionality reduction algorithms are employed to reduce the number of input variables while preserving the most relevant information. These algorithms transform the original high-dimensional data into a lower-dimensional representation, making it easier to analyze, visualize, and comprehend. Principal Component Analysis (PCA) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are commonly used dimensionality reduction techniques. They assist in feature selection, noise reduction, and visualization of complex datasets.
3. Association Rule Learning Algorithms: Association rule learning algorithms identify interesting relationships or associations among different variables in the dataset. They extract patterns and rules that describe how items are often associated or co-occur with each other. Apriori and FP-Growth are popular association rule learning algorithms. These algorithms are widely employed in market basket analysis, where the goal is to discover purchasing patterns or recommendations based on the purchasing behavior of customers.
4. Anomaly Detection Algorithms: Anomaly detection algorithms are designed to identify outliers or anomalies in the dataset, which deviate significantly from the expected patterns. These anomalies can represent rare events, errors, or fraudulent activities. Popular anomaly detection techniques include statistical methods, clustering-based approaches, and autoencoders. Anomaly detection plays a crucial role in various domains, such as cybersecurity, fraud detection, and system diagnostics.
Each type of unsupervised machine learning algorithm has its own strengths, weaknesses, and suitable applications. The choice of algorithm depends on the nature of the data and the specific problem or goal. It’s essential to understand the characteristics and capabilities of each algorithm to select the most appropriate one for a given task.
In the next sections, we will delve deeper into each type of unsupervised learning algorithm, exploring their features, use cases, and advantages. This will provide a comprehensive understanding of the various techniques available for uncovering meaningful insights from unlabeled data.
Clustering Algorithms
Clustering algorithms are an essential component of unsupervised machine learning, aiming to group similar data points into clusters based on their similarities or distances from each other. The objective is to create homogeneous clusters where data points within the same cluster are more similar to each other than to those in other clusters.
One of the most widely used clustering algorithms is K-means. It is an iterative algorithm that assigns each data point to a cluster based on its proximity to the cluster’s centroid. The algorithm aims to minimize the sum of squared distances between data points and their respective cluster centroids. K-means is applicable to a variety of scenarios, such as customer segmentation, image compression, and document clustering.
Hierarchical clustering is another popular clustering algorithm that builds a hierarchical structure of clusters. The algorithm starts with each data point as a separate cluster and gradually merges clusters based on their similarities. Hierarchical clustering provides a visual representation of clusters through dendrograms and allows for different levels of granularity in cluster identification.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a density-based clustering algorithm that groups data points into clusters based on their density. It is effective in discovering clusters of arbitrary shapes and can handle datasets with noise and outliers. DBSCAN defines clusters as dense regions separated by sparser regions, making it suitable for applications such as spatial data analysis and outlier detection.
Clustering algorithms have numerous applications across various domains. In marketing, cluster analysis can help identify different customer segments based on their preferences and behaviors, enabling personalized marketing strategies. In image analysis, clustering can be used for image segmentation and object recognition. In social network analysis, clustering can reveal communities or groups of individuals with similar interests or connections.
However, clustering algorithms also come with certain limitations. One challenge is determining the optimal number of clusters, as it may not always be explicitly defined. Evaluating the quality of the clustering results can also be subjective, as it depends on the specific domain and context. Additionally, clustering algorithms may struggle with high-dimensional data or datasets with imbalanced clusters.
Despite these limitations, clustering algorithms provide a powerful tool for finding patterns and organizing data in an unsupervised manner. They enable data scientists and researchers to gain valuable insights, discover hidden structures, and make informed decisions based on the identified clusters.
In the next section, we will explore another type of unsupervised machine learning algorithm: dimensionality reduction algorithms.
Dimensionality Reduction Algorithms
Dimensionality reduction algorithms are a crucial aspect of unsupervised machine learning, used to reduce the number of input variables or features while retaining the most relevant information. By transforming high-dimensional data into a lower-dimensional representation, dimensionality reduction algorithms facilitate data analysis, visualization, and understanding.
One of the widely used dimensionality reduction techniques is Principal Component Analysis (PCA). PCA identifies the directions (principal components) in the data that capture the most significant variations. By projecting the data onto these principal components, PCA reduces the dimensionality while preserving the maximum amount of variance. PCA is effective in feature extraction, noise reduction, and data compression.
t-SNE (t-Distributed Stochastic Neighbor Embedding) is another popular dimensionality reduction algorithm that focuses on visualization. It is particularly useful in visualizing high-dimensional data in a lower-dimensional space, maintaining the local structure and preserving the relationships between data points. t-SNE is commonly employed in fields such as image recognition, natural language processing, and genomics.
Dimensionality reduction algorithms offer various benefits. First, they enable the visualization of complex datasets in a simplified and interpretable manner, which aids in gaining insights and identifying patterns. Second, reducing the dimensionality can improve computational efficiency, as working with a smaller feature space requires less computational resources. Third, dimensionality reduction can help address the “curse of dimensionality,” where high-dimensional data can lead to sparse and noisy representations, making analysis and modeling challenging.
However, it’s important to note that dimensionality reduction also comes with its own considerations. One challenge is deciding the appropriate number of dimensions to reduce to. The retained dimensions should strike a balance between preserving important information and avoiding loss of crucial details. Additionally, while dimensionality reduction can be helpful, it may result in some loss of information, especially if the reduced dimensions discard less important but still relevant features.
Dimensionality reduction algorithms find applications in various fields. In image processing, they can assist in feature extraction and image compression. In natural language processing, dimensionality reduction can be used to represent text documents in a more compact and manageable form. In genetics, dimensionality reduction techniques aid in analyzing gene expression data and revealing meaningful gene clusters.
Overall, dimensionality reduction algorithms are invaluable tools for pre-processing data, visualizing complex datasets, and improving computational efficiency. They provide insights into the underlying structure of the data and facilitate downstream analysis tasks.
In the next section, we will delve into another type of unsupervised learning algorithm: association rule learning algorithms.
Association Rule Learning Algorithms
Association rule learning algorithms are an important component of unsupervised machine learning, focused on discovering interesting relationships or associations among different variables in a dataset. These algorithms extract patterns and rules that describe how items are often associated or co-occur with each other.
One of the most widely used association rule learning algorithms is Apriori. Apriori works by identifying frequent itemsets, which are sets of items that frequently occur together in the dataset. It then uses these frequent itemsets to generate association rules that capture the relationships between items. Association rules consist of an antecedent (the items that precede) and a consequent (the items that follow), along with a support and confidence measure.
Another popular association rule learning algorithm is FP-Growth (Frequent Pattern Growth). FP-Growth constructs a compact data structure called an FP-tree to represent the dataset efficiently. It then recursively searches this compressed representation to mine frequent patterns and generate association rules. FP-Growth is known for its efficiency and scalability, making it suitable for large-scale dataset analysis.
Association rule learning algorithms find applications in various domains. In market basket analysis, these algorithms help identify associations between products that are frequently purchased together. This information can be utilized for cross-selling, recommendation systems, or targeted marketing strategies. Association rule learning is also valuable in healthcare for analyzing patient records and identifying co-occurring medical conditions or potential treatments.
One of the challenges in association rule learning is the generation of high-quality rules. It involves setting appropriate thresholds for support and confidence measures, selecting relevant items or variables, and handling large or sparse datasets effectively. Additionally, the interpretation and evaluation of the generated rules can be subjective, requiring domain knowledge and expertise to derive meaningful insights.
Despite these challenges, association rule learning algorithms provide a powerful method for uncovering hidden relationships and dependencies in data. By discovering frequent itemsets and generating association rules, these algorithms enable businesses and researchers to gain valuable insights, improve decision-making, and optimize processes.
In the next section, we will explore another type of unsupervised learning algorithm: anomaly detection algorithms.
Anomaly Detection Algorithms
Anomaly detection algorithms play a crucial role in unsupervised machine learning, aiming to identify outliers or anomalies in a dataset. Anomalies refer to data points that deviate significantly from the expected patterns or behaviors. These anomalies can represent rare events, errors, fraud, or any other abnormal occurrences in the data.
One commonly used technique for anomaly detection is statistical methods. These methods assess the statistical properties of the data and identify data points that fall outside a certain threshold or distribution. For example, the z-score or modified z-score can be calculated to measure the deviation of a data point from the mean. Data points with high z-scores are considered anomalies. Statistical anomaly detection techniques are effective for detecting simple anomalies in univariate or multivariate data.
Another approach to anomaly detection is clustering-based methods. These methods aim to identify data points that do not belong to any cluster or belong to very small or sparse clusters. Since anomalies often do not conform to the expected patterns of the majority of data points, they are likely to form separate or sparsely populated clusters. Clustering techniques such as DBSCAN or k-means clustering can be adapted to identify such anomalous clusters or data points.
Machine learning techniques, such as isolation forests or one-class support vector machines (SVM), can also be employed for anomaly detection. These techniques build models or decision boundaries based on normal data and classify data points outside these boundaries as anomalies. Machine learning-based anomaly detection approaches are effective when dealing with complex or high-dimensional data where traditional statistical methods may not be sufficient.
Anomaly detection algorithms have diverse applications. In cybersecurity, these algorithms can detect malicious activities, network intrusions, or anomalous login attempts. In finance, anomaly detection can help identify fraudulent transactions or detect unusual market behavior. In healthcare, anomaly detection can be used for identifying rare diseases, abnormal patient conditions, or medical errors.
However, anomaly detection also faces challenges. Determining what constitutes an anomaly and setting appropriate thresholds can be subjective, as anomalies can be context-dependent. Additionally, in large datasets, the presence of noise or outliers in the normal data can make it challenging to distinguish true anomalies.
Despite these challenges, anomaly detection algorithms provide a valuable tool for identifying unusual or unexpected patterns in data. By distinguishing anomalies from normal behavior, these algorithms enable proactive actions, efficient resource allocation, and improved decision-making.
In the next section, we will discuss the advantages of unsupervised machine learning as a whole.
Advantages of Unsupervised Machine Learning
Unsupervised machine learning offers several advantages that make it a valuable approach for data analysis and knowledge discovery. Here are some of the key advantages:
1. Discovery of Hidden Patterns: Unsupervised learning algorithms can uncover hidden patterns, structures, and relationships within data that may not be immediately apparent to humans. By analyzing the inherent similarities and differences in the data, unsupervised algorithms can reveal valuable insights and provide a deeper understanding of the underlying patterns.
2. Handling Unlabeled Data: Unsupervised learning excels at handling unlabeled or unstructured data. In many real-world scenarios, obtaining labeled data can be time-consuming, expensive, or even impossible. Unsupervised algorithms alleviate the need for labeled data, making them suitable for large and complex datasets where manual labeling is not feasible.
3. Scalability: Unsupervised learning algorithms can handle large-scale datasets efficiently. Since they do not rely on labeled data for training, the computational complexity is often reduced, enabling quicker analysis and processing of massive amounts of data. This scalability makes unsupervised learning algorithms well-suited for big data applications.
4. Adaptability to New Data: Unsupervised learning algorithms can adapt to new and changing data without the need for re-training or updating the models. As new data is encountered, the algorithms can dynamically adjust their representations or clusters to accommodate the changes. This adaptability is particularly valuable in dynamic environments where the data distribution may evolve over time.
5. Novelty Detection: Unsupervised learning algorithms can identify novel or previously unseen patterns or anomalies in the data. By specifying what is considered “normal” or “expected” behavior, these algorithms can detect deviations from the norm and highlight potential outliers or exceptional instances. Novelty detection is beneficial in applications such as fraud detection, anomaly detection, and outlier analysis.
6. Exploration and Preprocessing: Unsupervised learning algorithms facilitate data exploration and preprocessing. They can provide a visual representation of the data, aid in feature selection, and assist in data cleaning by identifying and handling missing or inconsistent values. Unsupervised algorithms serve as a valuable preliminary step in data analysis, uncovering insights that can guide further investigations.
Overall, unsupervised machine learning techniques offer numerous advantages, including the ability to uncover hidden patterns, handle unlabeled data, scale to large datasets, adapt to new data, detect novelties, and facilitate data exploration and preprocessing. These advantages make unsupervised learning algorithms powerful tools for extracting knowledge and making informed decisions based on the inherent structure of the data.
In the next section, we will discuss the limitations of unsupervised machine learning.
Limitations of Unsupervised Machine Learning
While unsupervised machine learning offers various advantages, it also has its limitations and challenges. Understanding these limitations is crucial for using unsupervised learning algorithms effectively. Here are some of the key limitations:
1. Lack of Ground Truth: Unsupervised learning algorithms do not have access to labeled data for training and evaluation. This makes it challenging to measure the performance or accuracy of the algorithm objectively. Without a ground truth or reference, assessing the quality and reliability of the results becomes subjective and dependent on human interpretation.
2. Subjectivity and Interpretability: Unsupervised learning outcomes often require human interpretation and domain expertise. The clusters, patterns, or relationships discovered by unsupervised algorithms may not always have clear-cut interpretations or actionable insights. Interpretation can be subjective and heavily dependent on the context and understanding of the data.
3. Sensitivity to Input Data: The quality and relevance of the insights generated by unsupervised learning algorithms are heavily reliant on the quality and relevance of the input data. Noisy, missing, or irrelevant data can significantly impact the accuracy and usefulness of the results. Data preprocessing and cleaning are critical steps to ensure the reliability and effectiveness of unsupervised learning algorithms.
4. Difficulty in Evaluating Results: Unlike supervised learning algorithms that have clear evaluation metrics, assessing the performance of unsupervised learning is challenging. Determining the optimal number of clusters or the appropriateness of the obtained patterns or associations can be subjective. Evaluation techniques such as silhouette scores or domain-specific measures are often used, but they may not always capture the true quality of the results.
5. Scalability and Complexity: Some unsupervised learning algorithms may suffer from scalability issues when dealing with high-dimensional or large-scale datasets. The computational complexity and memory requirements of certain algorithms can be prohibitive, making them less practical for big data applications. Optimization techniques and parallel computing are often required to mitigate these challenges.
6. Curse of Dimensionality: High-dimensional data can pose challenges for unsupervised learning algorithms. With an increasing number of dimensions, the sparsity of the data increases, making it difficult to find meaningful structures or patterns. Dimensionality reduction techniques can alleviate this issue, but they may introduce information loss or distort the underlying structure of the data.
Despite these limitations, unsupervised machine learning remains a valuable approach for data analysis and knowledge discovery. Understanding the limitations and addressing them appropriately can help ensure the effective and reliable use of unsupervised learning algorithms.
In the next section, we will explore various applications of unsupervised machine learning across different industries and domains.
Applications of Unsupervised Machine Learning
Unsupervised machine learning has a wide range of applications across various industries and domains. The ability to discover hidden patterns, structures, and relationships in data makes unsupervised learning algorithms invaluable for extracting insights and making informed decisions. Here are some prominent applications of unsupervised machine learning:
1. Customer Segmentation: Unsupervised learning is extensively used in marketing to segment customers based on their preferences, behaviors, or demographic attributes. By clustering customers into distinct groups, businesses can tailor their marketing strategies, personalize recommendations, and improve customer satisfaction.
2. Image and Video Analysis: Unsupervised learning plays a vital role in image and video analysis tasks such as image categorization, object recognition, and video summarization. Clustering algorithms help group similar images or videos together, enabling efficient browsing, search, and content organization.
3. Natural Language Processing (NLP): Unsupervised learning techniques are used in NLP for tasks such as document clustering, topic modeling, and text classification. By applying clustering algorithms or dimensionality reduction methods, large text datasets can be organized, summarized, and analyzed effectively.
4. Anomaly Detection and Fraud Detection: Unsupervised learning algorithms are widely employed in detecting anomalies, fraud, or unusual behaviors in various domains. By modeling what is considered normal or expected, these algorithms can identify deviations from the norm, helping organizations detect fraudulent transactions, network intrusions, or unusual patterns in data.
5. Recommendation Systems: Unsupervised learning algorithms are fundamental to recommendation systems, where the aim is to suggest relevant items or content to users. By analyzing users’ past behaviors or preferences, clustering or association rule learning algorithms can generate personalized recommendations, enhancing user experience and driving engagement.
6. Genomics and Bioinformatics: Unsupervised learning is extensively utilized in genomics and bioinformatics for tasks such as gene expression analysis, protein classification, and disease diagnosis. Clustering algorithms help identify gene clusters or protein families, enabling a deeper understanding of genetic patterns and potential disease markers.
7. Cybersecurity: Unsupervised learning algorithms are crucial in cybersecurity to detect and prevent cyber threats. Anomaly detection techniques can identify unusual network traffic, identify potential malware or intrusion attempts, and proactively safeguard systems and data from malicious activities.
These are just a few examples of the myriad applications of unsupervised machine learning. From healthcare to finance, from social media to manufacturing, unsupervised learning techniques enable organizations to gain valuable insights, optimize processes, and drive data-driven decision-making.
In the final section, we will summarize the key points discussed throughout the article.
Conclusion
Unsupervised machine learning is a powerful branch of artificial intelligence that enables the discovery of hidden patterns, structures, and relationships in data without the need for labeled examples. By analyzing unlabeled data, unsupervised learning algorithms provide valuable insights and make sense of complex and unstructured information.
In this article, we explored the different types of unsupervised machine learning algorithms, including clustering, dimensionality reduction, association rule learning, and anomaly detection. Clustering algorithms group similar data points together, while dimensionality reduction algorithms simplify high-dimensional data. Association rule learning algorithms uncover interesting relationships, and anomaly detection algorithms identify outliers and irregularities in the data.
We discussed the advantages of unsupervised machine learning, such as the discovery of hidden patterns, the ability to handle unlabeled data, scalability, adaptability to new data, novelty detection, and data exploration and preprocessing. However, we also highlighted the limitations, including the lack of ground truth, subjectivity, sensitivity to input data, difficulty in evaluating results, scalability and complexity concerns, and the curse of dimensionality.
Unsupervised machine learning finds applications in numerous fields, including customer segmentation, image and video analysis, natural language processing, anomaly detection, recommendation systems, genomics, bioinformatics, and cybersecurity. These applications reflect the versatility and power of unsupervised learning in extracting knowledge, making data-driven decisions, and optimizing processes.
As unsupervised machine learning continues to evolve, it is essential to understand its strengths, limitations, and appropriate use cases. By leveraging unsupervised learning algorithms effectively, organizations can unlock the hidden value within their data, gain insights, and drive innovation and success across various domains.
Thank you for joining us on this exploration of unsupervised machine learning. We hope this article has provided you with a deeper understanding of the subject and its applications. Embrace the power of unsupervised learning and continue to explore the possibilities it offers in your data-driven journey.