Introduction
Machine learning has become an integral part of various industries, revolutionizing the way we solve complex problems and make data-driven decisions. With the abundance of data available, it has become increasingly necessary to employ advanced algorithms that can extract meaningful insights and patterns from large datasets. One such algorithm that has gained significant popularity in the field of machine learning is the Random Forest.
The Random Forest algorithm is a powerful and versatile ensemble learning method that combines the predictions of multiple decision trees to generate highly accurate results. Its ability to handle both classification and regression tasks has made it a go-to choice for data scientists and practitioners in a wide range of applications.
In this article, we will delve into the world of Random Forest and explore its inner workings. We will discuss how it operates, the advantages and disadvantages it offers, as well as some practical use cases that highlight its effectiveness.
So, let’s strap in and embark on a journey to discover the intriguing world of Random Forest in machine learning.
Background of Machine Learning
Before diving into Random Forest, it’s essential to have a basic understanding of machine learning. Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn and make predictions or decisions without being explicitly programmed.
Machine learning algorithms can analyze large datasets and identify underlying patterns or trends, enabling them to make accurate predictions or classifications on new or unseen data. This process involves training the machine learning model on historical data, known as the training set, to learn the patterns and relationships within the data. Once trained, the model can make predictions or classifications on new data based on its learned knowledge.
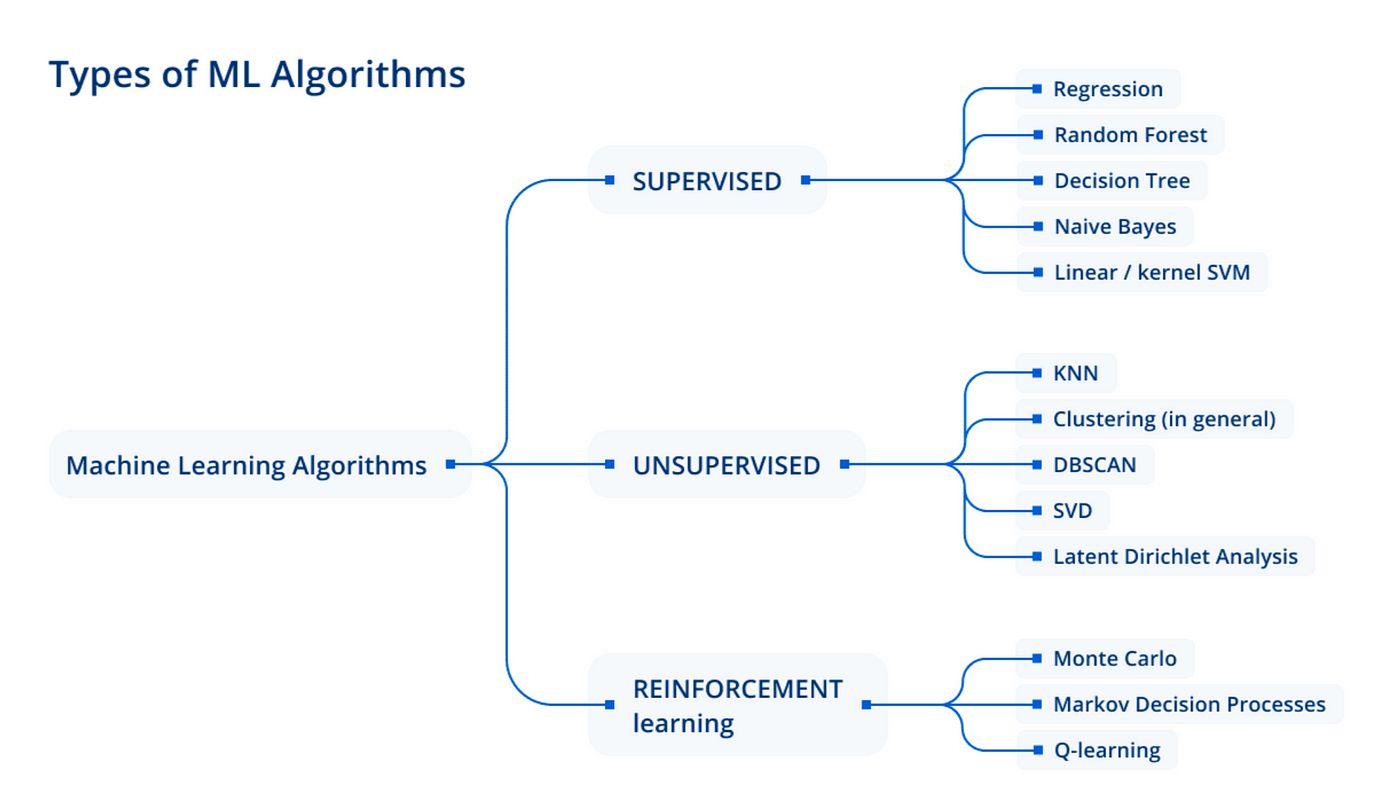
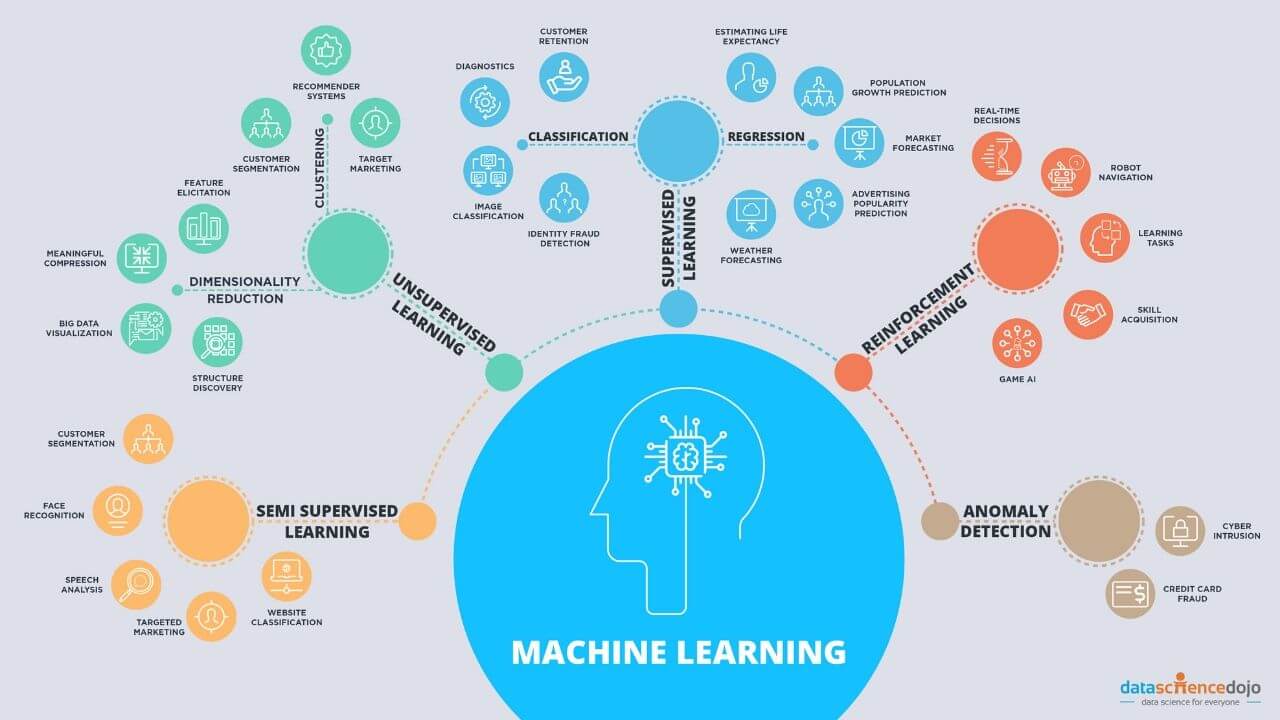
There are several types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves training a model using labeled data, where the desired output is known. Unsupervised learning, on the other hand, deals with unlabeled data, where the algorithm seeks to discover patterns and structures on its own. Reinforcement learning relies on learning through experimentation and feedback from the environment.
Over the years, machine learning algorithms have evolved and become more sophisticated, enabling them to tackle complex problems across various domains. Random Forest is one such algorithm that has gained popularity for both its simplicity and remarkable performance in a wide range of applications.
Now that we have a basic understanding of machine learning, let’s dive into the fascinating world of Random Forest and explore how it can tackle complex tasks with ease.
What is Random Forest?
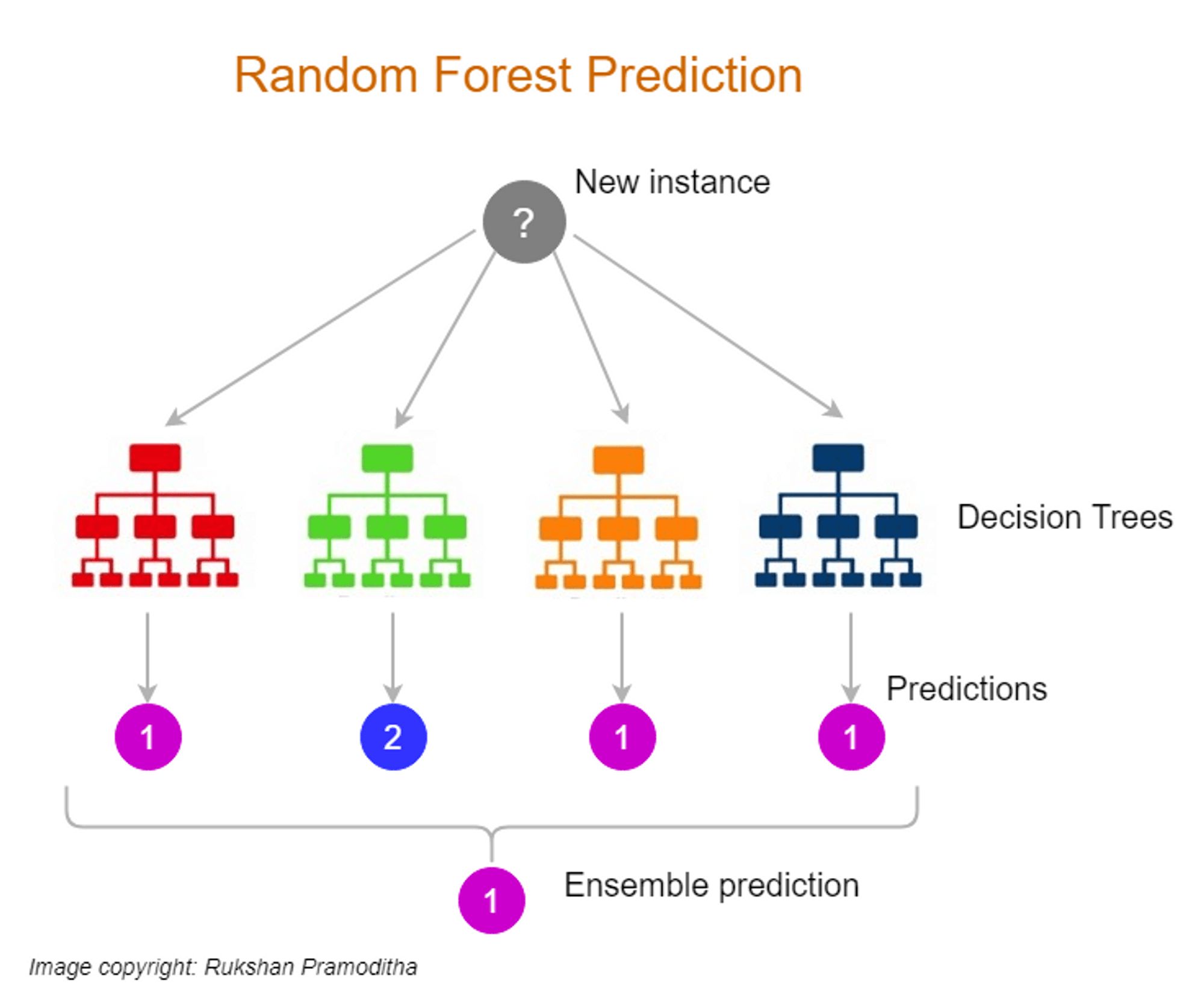
Random Forest is a powerful machine learning algorithm that belongs to the family of ensemble learning methods. It combines the predictions of multiple individual decision trees to generate a final prediction or decision. Each decision tree in the Random Forest algorithm is built using a subset of the available training data and a subset of the features. This randomness injected into the algorithm helps to reduce overfitting and improve the overall accuracy and robustness of the model.
The Random Forest algorithm can handle both classification and regression tasks. In classification problems, Random Forest assigns a class label to each input based on the majority vote of all the decision trees. In regression problems, it predicts a continuous value based on the average prediction of all the decision trees.
The strength of Random Forest lies in its ability to handle high-dimensional data with a large number of features, as well as datasets with missing values. It can maintain high accuracy even when dealing with noisy or unbalanced datasets. Additionally, Random Forest can also provide a measure of feature importance, allowing us to gain insights into the underlying patterns and relationships within the data.
Random Forest is known for its robustness against overfitting, which is a common issue in machine learning. Overfitting occurs when a model is overly complex and captures noise or irrelevant patterns from the training data, resulting in poor generalization to new data. The randomness introduced in Random Forest, such as bootstrapping and random feature selection, helps to mitigate overfitting by creating diverse and independent decision trees.
In summary, Random Forest is a versatile algorithm that leverages the power of ensemble learning to generate accurate predictions or decisions. Its ability to handle high-dimensional data, robustness against overfitting, and capability to handle missing values make it a popular choice among machine learning practitioners.
How does Random Forest Work?
Random Forest harnesses the power of ensemble learning by creating an ensemble, or a collection, of decision trees. Each decision tree in the ensemble is built using a random subset of the training data and a random subset of the features. This randomness introduces diversity among the decision trees, which helps to improve the accuracy and robustness of the model.
The process of building a Random Forest can be summarized in the following steps:
- Random Subsampling: First, the algorithm randomly selects a subset of the training data from the original dataset. This process, known as bootstrap sampling or bagging, allows each decision tree to have a slightly different dataset, reducing the risk of overfitting.
- Feature Randomness: Random Forest also introduces feature randomness. Instead of using all the available features for building each decision tree, a random subset of features is selected. This serves to further diversify the decision trees and reduce their correlation.
- Decision Tree Building: Once the random subsampling and feature selection are done, each decision tree is constructed using the modified dataset. The decision tree is trained to predict the target variable based on the selected features.
- Majority Voting: During the prediction phase, the Random Forest algorithm combines the predictions from all the decision trees in the ensemble. In classification tasks, the class label with the majority vote among the decision trees is chosen as the final prediction. In regression tasks, the average prediction of all the decision trees is taken as the final prediction.
The randomness injected into Random Forest helps to reduce variance and improve generalization. By combining the predictions of multiple decision trees, Random Forest can capture a wide range of patterns and make more accurate predictions than a single decision tree.
Additionally, Random Forest provides a measure of feature importance, which indicates the relative contribution of each feature in the model. This information can help in feature selection and understanding the underlying patterns and relationships within the data.
Overall, Random Forest is a powerful algorithm that leverages the strength of ensemble learning to deliver robust and accurate predictions. Its ability to handle high-dimensional data, reduce overfitting, and provide insights into feature importance makes it a popular choice in the field of machine learning.
Advantages of Random Forest
Random Forest offers several advantages that have contributed to its popularity and widespread use in various machine learning applications:
- High Accuracy: Random Forest generally delivers high accuracy due to the consensus of multiple decision trees. The ensemble approach helps to reduce bias and overfitting, resulting in more reliable and robust predictions.
- Robustness to Noise: Random Forest performs well even when the dataset contains noisy or irrelevant features. The algorithm’s ability to consider a subset of features for each tree reduces the impact of noisy features, enabling it to extract relevant information more effectively.
- Feature Importance: Random Forest provides a measure of feature importance, allowing data scientists to gain insights into which features contribute the most to the model’s predictions. This information can guide feature selection, feature engineering, and overall understanding of the problem domain.
- Handling Missing Values: Random Forest has the ability to handle datasets with missing values. It takes advantage of the fact that decision trees only need a subset of features at each split, so missing values in certain features do not disrupt the entire algorithm.
- Efficiency: Despite the ensemble nature of Random Forest, it can efficiently handle large datasets and high-dimensional feature spaces. The algorithm can be parallelized and distributed across multiple processors, making it suitable for handling big data applications.
- Outlier Robustness: Random Forest is less sensitive to outliers compared to other machine learning algorithms. The ensemble averaging process helps to mitigate the impact of outliers by reducing their influence on the final predictions.
These advantages have made Random Forest a popular and reliable choice for various machine learning tasks. Its ability to deliver accurate results, handle noise and missing values, and provide insights into feature importance makes it a valuable tool for data scientists and practitioners.
Disadvantages of Random Forest
While Random Forest offers numerous advantages, it is important to consider its limitations and potential drawbacks:
- Computationally Intensive: Random Forest can be computationally expensive, especially when dealing with large datasets and a large number of decision trees in the ensemble. Building and training multiple decision trees can require significant computational resources.
- Lack of Interpretability: Random Forest provides accurate predictions, but it lacks interpretability compared to simpler models like decision trees. Understanding the specific reasoning behind the model’s predictions can be challenging due to the complex ensemble nature of Random Forest.
- Memory Usage: Random Forest requires more memory compared to individual decision trees. The ensemble nature of Random Forest results in a larger memory footprint, especially when dealing with a large number of trees or high-dimensional feature spaces.
- Limited Extrapolation Ability: Random Forest is primarily designed for interpolation, meaning it works well within the range of observed data. However, it may struggle with extrapolation, making predictions outside of the observed data range less reliable.
- Less Effective for Linear Relationships: Random Forest is generally not well-suited for capturing linear relationships between features and the target variable. Linear relationships can be better modeled by algorithms like linear regression or support vector machines.
- Model Complexity and Overfitting: Although Random Forest is known for its robustness against overfitting, building a very large number of decision trees can still result in complex models that may overfit the training data if not properly regularized. The hyperparameters of Random Forest, such as the number of trees and tree depth, need to be carefully tuned to avoid overfitting.
Despite these limitations, Random Forest remains a powerful and versatile algorithm that offers many advantages. It is important to understand these limitations and analyze whether they align with the specific requirements and constraints of the problem at hand.
Use Cases of Random Forest
Random Forest has found applications in diverse domains, showcasing its versatility and effectiveness in various problem-solving scenarios. Let’s explore some of the common use cases where Random Forest excels:
- Classification: Random Forest is commonly used for classification tasks, such as spam detection, sentiment analysis, and disease diagnosis. Its ability to handle high-dimensional data and capture complex decision boundaries makes it a reliable choice for these tasks.
- Regression: Random Forest can also be used for regression tasks, such as predicting housing prices, stock market trends, or customer churn rates. The ensemble approach enables it to handle non-linear relationships and capture intricate patterns in the data.
- Image and Text Analysis: Random Forest can be applied to image and text analysis tasks. In image analysis, it can be used for image recognition, object detection, and image segmentation. In text analysis, it can be used for sentiment analysis, topic modeling, and text categorization.
- Anomaly Detection: Random Forest can be leveraged for identifying anomalies or outliers in datasets. By training the model on normal data and comparing new observations, it can flag instances that deviate significantly from the expected behavior, making it useful in fraud detection, network intrusion detection, and fault diagnosis.
- Feature Selection: Random Forest’s ability to provide feature importance metrics makes it valuable for feature selection tasks. By ranking features based on their contribution to the model’s predictions, it helps identify the most relevant features and eliminates irrelevant or redundant ones.
- Data Imputation: Random Forest can be used for filling missing values in datasets. By using the other features’ information, it can predict the missing values more accurately compared to traditional imputation methods. This makes it useful in handling datasets with missing data.
These are just a few examples of the numerous applications of Random Forest. Its versatility and ability to handle various types of data and tasks make it a go-to algorithm in many real-world scenarios.
Conclusion
Random Forest is a powerful and versatile machine learning algorithm that has gained immense popularity due to its ability to deliver accurate and robust predictions. With its ensemble approach and combination of multiple decision trees, Random Forest can handle complex tasks, including classification, regression, anomaly detection, and feature selection.
One of the key advantages of Random Forest is its high accuracy, thanks to the consensus of multiple decision trees. It is also robust to noisy data and can handle missing values effectively. The feature importance measure provided by Random Forest allows for a deeper understanding of the underlying patterns in the data.
However, Random Forest does have some limitations. It can be computationally intensive, particularly when dealing with large datasets and a large number of decision trees. Additionally, the interpretability of the model may be limited, and linear relationships may not be well-captured by the algorithm.
Despite these limitations, Random Forest remains a valuable tool in the field of machine learning, finding applications in diverse domains such as classification, regression, image and text analysis, anomaly detection, and feature selection.
Understanding the strengths and weaknesses of Random Forest is crucial in selecting the appropriate algorithm for a specific problem. As with any machine learning algorithm, proper parameter tuning and optimization are essential to ensure optimal performance and prevent overfitting.
In summary, Random Forest is a versatile and powerful algorithm that enables data scientists and practitioners to tackle complex tasks with high accuracy. By harnessing the strength of ensemble learning, Random Forest continues to be a reliable and effective tool for a wide range of machine learning problems.