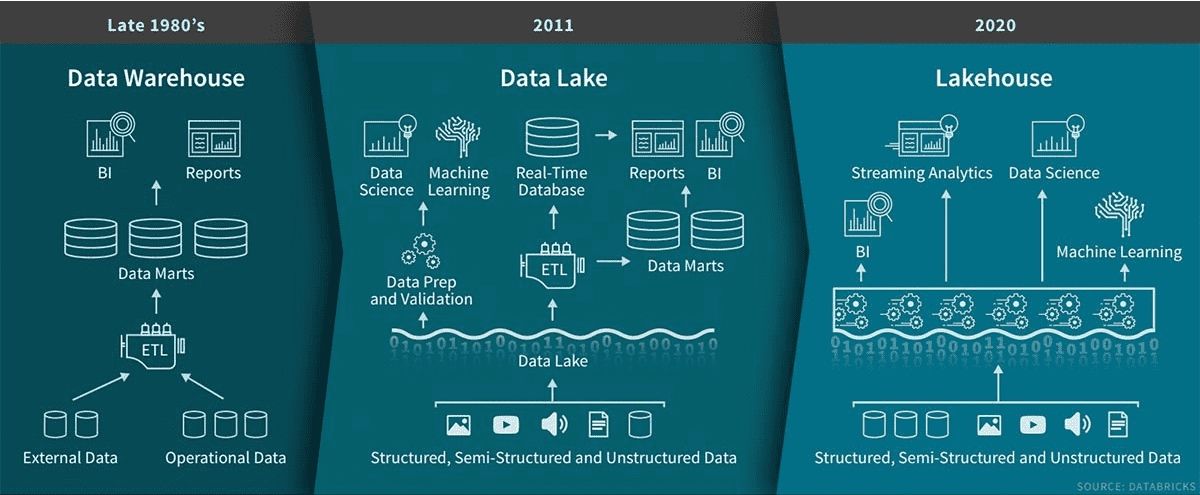
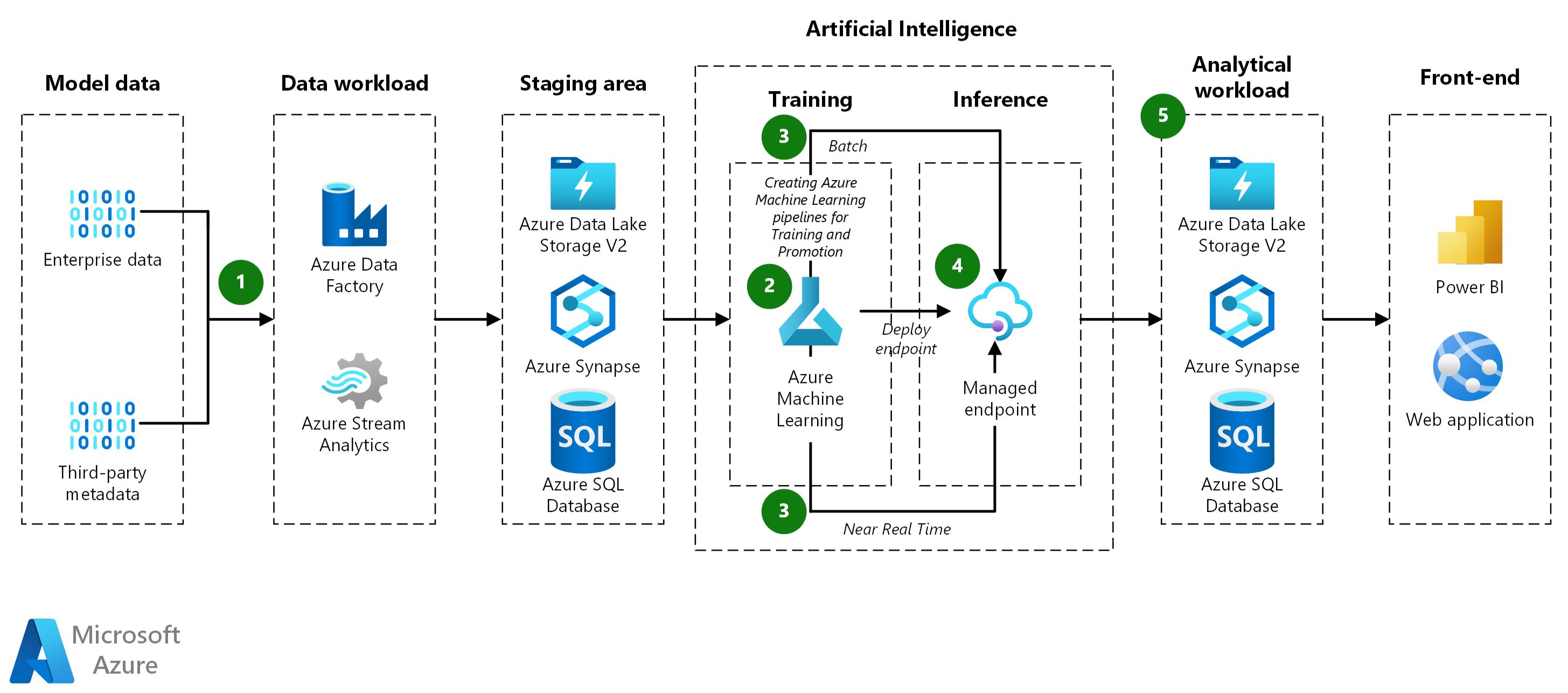
Introduction
Welcome to the exciting world of machine learning! In today’s rapidly evolving technological landscape, machine learning has emerged as a powerful tool for solving complex problems and making predictions based on data. It has become increasingly important in various fields, from finance and healthcare to marketing and entertainment. In this article, we will guide you through the process of creating a machine learning model, step by step.
Machine learning is a subset of artificial intelligence that enables computers to learn from data without being explicitly programmed. It involves training a model to recognize patterns and make predictions based on the data it is fed. This ability to learn and improve from experience is what sets machine learning apart from traditional programming.
Building a machine learning model involves several key steps, each with its own challenges and considerations. Throughout this article, we will provide a comprehensive overview of the entire process, from defining the problem to making predictions with your trained model.
Whether you are a data scientist, a software engineer, or simply someone with a keen interest in machine learning, this article will give you the knowledge and tools to start creating your own models. So, let’s dive in!
Step 1: Define the Problem
The first and most crucial step in creating a machine learning model is to clearly define the problem you want to solve. This step sets the foundation for all the subsequent stages of the process. Without a well-defined problem, your efforts may be misguided, leading to inaccurate or irrelevant results.
When defining the problem, start by clearly articulating the goal you want to achieve. Ask yourself: What do you want your model to accomplish? Is it classification, regression, clustering, or something else? For example, if you’re building a spam email filter, your goal might be to classify incoming emails as either spam or non-spam.
Next, define the scope of the problem. Consider the constraints and limitations of the data, resources, and time available to you. This will help you determine what is feasible and realistic for your project.
It’s also crucial to specify the target audience or end-users of your model. Who will benefit from the model’s predictions or insights? Understanding the needs and expectations of your audience will allow you to tailor your approach and ensure that your model meets their requirements.
Lastly, consider the metrics or evaluation criteria you will use to measure the success of your model. How will you know if your model is performing well? Will you use accuracy, precision, recall, or some other metrics specific to your problem domain? Defining these metrics will help you assess the performance of your model and make necessary improvements.
By clearly defining the problem, scope, target audience, and evaluation metrics, you establish a solid foundation for your machine learning project. This clarity will guide you throughout the rest of the process, enabling you to make better decisions and create a more effective model.
Step 2: Gather Data
Once you have defined the problem, the next step in building a machine learning model is to gather the necessary data. Data is the fuel that powers your model, and the quality and quantity of data you collect will greatly impact the accuracy and effectiveness of your model.
Start by identifying the relevant data sources for your problem. This could include existing datasets, public databases, APIs, or data collected internally within your organization. Consider both structured and unstructured data that may be useful in solving your problem.
After identifying potential data sources, it’s important to assess the quality of the data. Review the data to ensure that it is accurate, complete, and representative of the problem you are trying to solve. Data that is incomplete or contains errors can lead to biased or unreliable results. Clean and preprocess the data as needed to ensure its integrity.
It’s also essential to consider the size of the dataset. In general, larger datasets tend to yield more accurate models. However, collecting and storing large amounts of data can be challenging and expensive. Find the right balance based on the requirements of your problem and the resources available to you.
In addition to the size of the dataset, diversity is also important. A diverse dataset with a wide range of samples can help improve the generalization and robustness of your model. Ensure that your dataset includes a variety of relevant features and covers different scenarios or conditions.
Lastly, consider the ethical and legal implications of the data you collect. Ensure that you have the necessary permissions and comply with privacy regulations when gathering and using personal or sensitive data. Use anonymization techniques when necessary to protect the privacy of individuals.
By carefully gathering and assessing the right data, you set a strong foundation for building a successful machine learning model. Remember that the quality, quantity, and diversity of the data will greatly influence the performance and reliability of your model.
Step 3: Preprocess the Data
Once you have gathered the data, the next step in creating a machine learning model is to preprocess the data. Preprocessing involves cleaning, transforming, and organizing the data to make it suitable for training your model.
The first step in preprocessing is to handle missing data. Missing values can be problematic and can lead to biased or inaccurate results. You can either remove the instances with missing values or impute the missing values using techniques such as mean imputation or regression imputation, depending on the nature of the data.
Next, you need to handle outliers. Outliers are data points that deviate significantly from the rest of the data. Outliers can negatively affect the performance of your model, so it’s important to identify and deal with them appropriately. You can either remove the outliers or transform them using techniques such as winsorization or logarithmic transformation.
After handling missing data and outliers, you may need to normalize or scale the features in your dataset. Different features in your data may have different scales, which can bias the model. Normalization or scaling techniques such as min-max scaling or standardization can help bring all the features to a similar scale, ensuring fair representation.
Furthermore, you may need to encode categorical variables into numerical values. Machine learning algorithms generally require numerical inputs, so categorical variables need to be transformed. This can be done through techniques such as one-hot encoding or ordinal encoding, depending on the nature of the categorical variables.
In addition to these preprocessing steps, you may also need to feature engineer your dataset. Feature engineering involves creating new features from the existing ones to enhance the predictive power of your model. This could include creating interaction terms, polynomial features, or transforming the features to capture nonlinear relationships.
Lastly, split the preprocessed data into training and testing sets. The training set is used to train the model, while the testing set is used to evaluate its performance. This ensures that you have an unbiased assessment of your model’s performance on unseen data.
By carefully preprocessing your data, you ensure that it is clean, organized, and ready for training your machine learning model. Preprocessing is a critical step that can greatly impact the accuracy and efficiency of your model.
Step 4: Split the Data into Training and Testing Sets
Once you have preprocessed your data, the next step in building a machine learning model is to split the data into training and testing sets. This step is essential for evaluating the performance of your model and preventing overfitting.
The training set is used to train your machine learning model. It contains the labeled data that the model will learn from. The more diverse and representative the training set is, the better the model will be able to generalize and make accurate predictions.
The testing set, on the other hand, is used to evaluate the performance of your trained model. It contains data that the model has not seen during training. The testing set simulates real-world scenarios and allows you to assess how well your model generalizes to new, unseen data.
When splitting the data, it is common to use a randomization technique to ensure that the data is shuffled randomly. This helps prevent any biases that may arise from the ordering of the original dataset. The ratio of data to allocate to the training and testing sets can vary depending on the size and complexity of the dataset, but a commonly used ratio is 80:20 or 70:30.
It’s important to note that the testing set should only be used for evaluating the final performance of your model. It should not be used for any training or parameter tuning, as this can lead to overfitting. Overfitting occurs when the model learns to perform well on the training set but fails to generalize to new data.
In addition to training and testing sets, it is also common to create a validation set. The validation set can be used during the training process to fine-tune hyperparameters and optimize the model’s performance. It provides an additional level of evaluation and helps prevent overfitting.
By splitting your data into training, testing, and potentially validation sets, you can effectively evaluate the performance of your model and ensure its ability to generalize to new, unseen data. This step is crucial in building a reliable and accurate machine learning model.
Step 5: Choose a Machine Learning Algorithm
Once you have preprocessed and split your data, the next step in building a machine learning model is to choose the appropriate machine learning algorithm. The choice of algorithm depends on the type of problem you are trying to solve, the nature of your data, and your desired outcome.
There are various types of machine learning algorithms, each with its own strengths and weaknesses. Here are a few common types:
- Supervised Learning: This type of algorithm is used when you have labeled data, where the input features and the corresponding output labels are known. Supervised learning algorithms include classification algorithms for predicting discrete labels and regression algorithms for predicting continuous values.
- Unsupervised Learning: In unsupervised learning, you don’t have labeled data. Instead, the algorithm learns patterns and relationships in the data without explicit guidance. Unsupervised learning algorithms include clustering algorithms for grouping similar instances and dimensionality reduction algorithms for representing the data in a lower-dimensional space.
- Reinforcement Learning: This type of learning involves an agent learning from interaction with an environment to maximize cumulative rewards. The agent learns through trial and error, receiving feedback in the form of rewards or penalties. Reinforcement learning is commonly used in areas such as gaming, robotics, and autonomous vehicles.
When choosing a machine learning algorithm, it’s important to consider the characteristics of your data and the assumptions of the algorithm. Some algorithms work best with linearly separable data, while others are more suitable for handling nonlinear relationships. It’s also important to consider the computational demands and scalability of the algorithm, especially if you’re dealing with large datasets.
Additionally, consider the interpretability of the algorithm. Some algorithms, such as decision trees and logistic regression, provide transparent and interpretable models, while others, like deep learning models, are more complex and less interpretable. The interpretability of the model may be important depending on the application and the need for explaining the predictions and insights.
It’s worth noting that choosing an algorithm is not a one-size-fits-all approach. It often involves experimentation and iteration to find the best algorithm that fits your problem and data. Don’t be afraid to try different algorithms and compare their performance to make an informed decision.
By carefully selecting the appropriate machine learning algorithm, you set the foundation for building an effective and accurate model. Remember to consider the nature of your data, the desired outcome, and the interpretability requirements to make the best choice for your specific problem.
Step 6: Train the Model
After choosing the machine learning algorithm, the next step in building a model is to train it using the training dataset. Training involves feeding the algorithm with the labeled data and allowing it to learn the patterns and relationships within the data.
The training process consists of iterating through the training dataset multiple times, known as epochs. During each epoch, the algorithm makes predictions based on the current model parameters and compares them with the true labels. It then adjusts the model’s parameters using optimization techniques, such as gradient descent, to minimize the prediction errors.
The training process aims to find the optimal set of model parameters that can accurately predict the labels for unseen instances. The algorithm learns from the training data by updating its internal representations and weights based on the errors and feedback it receives.
The duration of the training process can vary depending on the complexity of the problem, the size of the dataset, and the chosen algorithm. Some models converge quickly, while others may require more computational resources and longer training times.
During the training process, it’s crucial to monitor the performance of the model on both the training data and a separate validation set. This helps you understand if the model is learning effectively or if it is overfitting the training data. Overfitting occurs when the model becomes too complex and starts to memorize the training examples instead of learning the underlying patterns.
To mitigate overfitting, regularization techniques such as dropout or L1 and L2 regularization can be applied. These techniques add a penalty to the loss function, discouraging the model from assigning too much importance to each individual training example.
After the training process is complete, the model’s parameters are fine-tuned, and it is ready to make predictions on unseen data. It’s important to note that during the training phase, the model should not be evaluated or tested on the testing dataset to prevent bias in assessing the model’s performance.
By training the model with the labeled training data, you enable it to learn and make accurate predictions on unseen data. The training step is a vital part of the machine learning process and lays the foundation for the model’s performance.
Step 7: Evaluate the Model
Once the model has been trained, the next step in building a machine learning model is to evaluate its performance. Evaluation is crucial to assess how well the model is performing and to determine if it meets the desired objectives and requirements.
There are various metrics to evaluate a model’s performance, depending on the type of problem. For classification tasks, metrics such as accuracy, precision, recall, F1 score, and area under the ROC curve (AUC-ROC) can be used. These metrics measure how well the model predicts the correct class labels.
For regression tasks, metrics such as mean squared error (MSE), mean absolute error (MAE), and R-squared value can be used. These metrics quantify the quality of the model’s predictions of continuous variables.
In addition to individual metrics, it’s important to analyze the model’s performance through visualizations, such as confusion matrices, precision-recall curves, or ROC curves. These visuals provide insights into the model’s strengths, weaknesses, and its ability to handle different classes or thresholds.
Moreover, it is important to consider the context of the problem and the desired trade-offs. Some applications may prioritize high precision over recall, while others may require a balanced approach. Evaluating the model against specific business or domain requirements is essential to determine its overall effectiveness.
It’s worth noting that the evaluation process should not only focus on the training data but also extend to the testing dataset that the model has not seen during training. This ensures that the model can generalize well to unseen data and perform reliably in real-world scenarios.
If the model does not meet the desired performance criteria, further steps can be taken to improve the performance. This may include revisiting data preprocessing steps, fine-tuning hyperparameters, trying different algorithms, or collecting more labeled data.
Evaluation should be an iterative process, allowing you to continuously refine and improve the model’s performance until it meets the desired standards. By evaluating the model’s performance, you gain valuable insights into its effectiveness and identify areas for improvement.
Step 8: Tune the Model
After evaluating the model’s performance, the next crucial step in building a machine learning model is to tune it. Model tuning involves optimizing various hyperparameters to improve the model’s performance and make it more effective.
Hyperparameters are different from the model’s parameters, as they are set manually by the user rather than learned from the data. These hyperparameters control the behavior of the algorithm and can significantly impact the model’s performance.
Common hyperparameters that are often tuned include learning rate, regularization strength, number of hidden layers or units in a neural network, and the type of kernel in a support vector machine (SVM).
One common approach to tune hyperparameters is through a process called grid search. Grid search involves specifying a range of values for each hyperparameter and trying out all possible combinations. The model’s performance is evaluated for each combination, and the combination with the best performance is chosen as the optimal set of hyperparameters.
Another popular method for hyperparameter tuning is random search. Instead of trying all possible combinations, random search selects random hyperparameter values from within specified ranges. This reduces computational costs while still exploring a wide range of hyperparameter combinations.
K-fold cross-validation is often used during the hyperparameter tuning process. This technique involves splitting the training dataset into K equally sized subsets or folds. Each fold is used as a validation set while the model is trained on the remaining folds. The average performance across all validation sets is then used to assess the model’s performance.
It’s important to note that tuning the model should be done carefully to avoid overfitting the hyperparameters to the training data. It’s essential to validate the model’s performance on an independent testing dataset to ensure that the tuned hyperparameters generalize well to unseen data.
The tuning process may require multiple iterations, adjusting and fine-tuning the hyperparameters based on the model’s performance. This iterative approach helps to hone in on the optimal hyperparameters for your specific problem.
By tuning the model’s hyperparameters, you can enhance its performance and make it more effective in solving the problem at hand. Careful consideration and experimentation with hyperparameters are key to achieving the best possible model performance.
Step 9: Make Predictions
After training and fine-tuning your machine learning model, the final step in the process is to use it to make predictions on new, unseen data. Making predictions allows you to apply your model to real-world scenarios and leverage its learned patterns and relationships.
To make predictions, you pass new input data through the trained model. The model applies the learned weights and biases to the input data and produces output predictions based on the patterns it has learned from the training process.
The input data used for prediction should be preprocessed and formatted in the same way as the training data to ensure compatibility. This includes handling missing values, scaling features, and encoding categorical variables, if necessary.
It’s crucial to remember that the predictions are only as good as the data on which the model was trained. If the input data for making predictions differs significantly from the training data distribution, the model’s performance may degrade. Therefore, it’s important to regularly monitor and assess the model’s performance on new data to ensure its accuracy and relevance.
Once the model has made predictions, you can analyze and interpret the results based on the specific problem you are solving. The predictions can provide valuable insights and support decision-making in various domains, such as healthcare, finance, marketing, and more.
Additionally, it’s important to consider the confidence or uncertainty associated with the predictions. Some machine learning algorithms provide confidence scores or probability estimates for each prediction, indicating the model’s level of certainty. Understanding the model’s confidence can help in making informed decisions and assessing the reliability of the predictions.
Furthermore, it’s essential to monitor the performance of the model on an ongoing basis. Analyze the predictions and compare them to the ground truth to understand any patterns of errors or biases. This feedback loop can guide you in identifying any limitations or areas for improvement in the model.
Making predictions with your trained machine learning model enables you to apply the power of data-driven insights to real-world scenarios. By leveraging the model’s learned patterns, you can make informed decisions, gain valuable insights, and drive meaningful results in your chosen field.
Conclusion
Building a machine learning model involves a systematic and iterative process, starting from defining the problem and gathering the necessary data, to preprocessing, training, tuning, and finally making predictions. Each step plays a crucial role in creating an effective and accurate model that can provide valuable insights and predictions.
Throughout this article, we have discussed the key steps involved in creating a machine learning model. We emphasized the importance of clearly defining the problem, assessing and preprocessing the data, and carefully choosing the appropriate machine learning algorithm. We also highlighted the significance of training the model, evaluating its performance, and refining it through hyperparameter tuning.
By following these steps, you can develop a robust and reliable machine learning model that can make accurate predictions and provide valuable insights. It’s crucial to continuously monitor the model’s performance, validate its predictions, and iterate on the process to ensure its effectiveness in real-world scenarios.
Keep in mind that building a machine learning model is not a one-time task. The field of machine learning is continuously evolving, and new algorithms, techniques, and approaches are constantly being developed. It’s important to stay updated with the latest advancements and continue to learn and improve your models.
With the power of machine learning, you can unlock new opportunities, solve complex problems, and gain valuable insights from your data. By applying the steps outlined in this article and maintaining a focus on continuous learning and improvement, you can harness the potential of machine learning to drive significant value in your chosen field.