Introduction
Machine learning has revolutionized numerous industries by enabling computers to learn patterns and make predictions or decisions based on data. However, in the pursuit of accurate models, there is a risk of overfitting, which can undermine the reliability and generalizability of these models. Overfitting is a common challenge in machine learning, and understanding its causes, symptoms, and techniques to overcome it is crucial for building robust and effective models.
Overfitting occurs when a machine learning model becomes too complex and starts to memorize the training data instead of learning the patterns. As a result, the model performs exceptionally well on the training data but fails to generalize well on unseen data. In other words, it “fits” the training data too closely and loses its ability to make accurate predictions in real-world scenarios.
One of the main causes of overfitting is having a model with too many parameters or features compared to the available data. When the number of parameters is high relative to the dataset size, the model can capture noise or random fluctuations in the data as meaningful patterns, leading to overfitting. Additionally, overfitting can occur when the training data is noisy or contains outliers, making the model overly sensitive to these erroneous data points.
Symptoms of overfitting can be observed during model evaluation. If the performance of the model significantly deteriorates when tested on new, unseen data compared to the training data, it is a clear indication of overfitting. High variance between the training and test accuracy scores, as well as a large difference between the model’s performance on the training and validation sets, are also indicative of overfitting.
The impact of overfitting can be detrimental. An overfitted model may produce unreliable predictions or decisions in real-life scenarios, leading to poor outcomes and wasted resources. It can also hinder the model’s ability to adapt and generalize to new data, limiting its usefulness and applicability.
To mitigate the risk of overfitting, several techniques can be employed. Cross-validation is a widely-used approach that involves dividing the data into multiple subsets and training the model on different combinations of these subsets. This helps to assess the model’s performance on unseen data and identify any signs of overfitting.
Regularization is another effective technique that introduces a penalty for complex models, discouraging overfitting. By adding a regularization term to the loss function, the model is encouraged to find a balance between accuracy and complexity, preventing it from over-optimizing on the training data.
Feature selection is another valuable approach that involves identifying and selecting the most relevant features. Removing unnecessary or redundant features can help simplify the model and reduce the risk of overfitting.
Early stopping is a technique that halts the training process when the model’s performance on the validation set starts to deteriorate. This prevents the model from excessively fitting the training data and allows it to generalize better on unseen data.
Overall, overfitting poses a significant challenge in machine learning, but with the right techniques and practices, it can be effectively addressed. By understanding the causes, symptoms, and techniques to combat overfitting, practitioners can build more reliable and robust machine learning models with improved generalization capabilities.
What is Overfitting?
In machine learning, overfitting refers to a phenomenon where a model becomes too closely fit to the training data, resulting in poor generalization to new, unseen data. It occurs when the model captures not just the underlying patterns in the data but also the noise and random fluctuations, leading to overly complex and specific representations of the training data.
When a model overfits, it essentially memorizes the training data rather than learning the underlying patterns that can be used for accurate predictions on unseen data. This leads to a high accuracy on the training set but poor performance on new, unseen data.
Overfitting often occurs when a model becomes too complex or has too many parameters relative to the available data. With a large number of parameters, the model has more degrees of freedom to capture even the smallest details and variations in the training data, including noise and outliers.
As a result, the model may start to attribute importance to random fluctuations or outliers, considering them as critical patterns. This leads to a loss of generalization ability as the model becomes too specific to the training data, unable to make accurate predictions on new instances.
Moreover, overfitting can be exacerbated by having limited or insufficient training data. When the dataset is small, the model has a higher chance of fitting the noise in the data rather than the true underlying patterns.
Another factor that can contribute to overfitting is the complexity of the chosen algorithm. Some algorithms, such as decision trees or neural networks, are inherently prone to overfitting due to their high flexibility and capacity to represent complex functions.
Identifying overfitting is critical in machine learning because it can affect the reliability and applicability of the model. A model that is overfit may perform admirably on the training data but fail miserably in real-life scenarios, resulting in incorrect predictions, decisions, or recommendations.
To tackle overfitting, various techniques and strategies can be employed. These include cross-validation, regularization, feature selection, and early stopping. By applying these techniques, practitioners can strive to strike a balance between model complexity and generalization, ultimately building robust and accurate models in machine learning.
Causes of Overfitting
Overfitting, a common challenge in machine learning, can arise due to several factors that cause the model to become too closely fit to the training data. Understanding these causes is crucial to effectively address and mitigate overfitting.
One of the main causes of overfitting is having a model with a high complexity or a large number of parameters compared to the available data. When the model is too complex, it can capture noise or random fluctuations in the training data as meaningful patterns, leading to overfitting. As a result, the model fails to generalize well on new, unseen data and becomes overly specialized to the training set.
Data quality and characteristics can also contribute to overfitting. If the training data is noisy or contains outliers, the model may give excessive importance to these erroneous data points, resulting in overfitting. Similarly, having insufficient or inadequate training data can increase the risk of overfitting as the model may not capture the true underlying patterns.
The choice of algorithm can also play a role in overfitting. Some algorithms, such as decision trees or neural networks, have high flexibility and capacity to represent complex functions. While this can be advantageous in capturing intricate patterns, it can also make these algorithms more susceptible to overfitting if not appropriately regularized or constrained.
Another cause of overfitting is the presence of irrelevant or redundant features in the dataset. When there are too many irrelevant or redundant features, the model may mistakenly attribute importance to them, leading to overfitting. Feature selection techniques can help mitigate this issue by identifying and selecting the most relevant features for the model.
In addition to these causes, overfitting can also be influenced by the specific sampling of the data used for training. If the training set is not representative of the data distribution in the real world, the model may become overfit and fail to generalize to new instances.
Overall, understanding the causes of overfitting is critical to developing effective strategies to mitigate its impact. By addressing issues related to model complexity, data quality, algorithm selection, feature relevance, and data sampling, practitioners can improve the generalization capabilities and reliability of their machine learning models.
Symptoms of Overfitting
Identifying the symptoms of overfitting is crucial in ensuring the reliability and generalization abilities of machine learning models. By recognizing these symptoms, practitioners can take appropriate measures to address overfitting and improve the performance of their models.
One significant symptom of overfitting is a stark difference in performance between the model on the training set and the validation or test set. If the model achieves a high accuracy or performance on the training set but significantly underperforms on new, unseen data, it is a clear indication of overfitting. This discrepancy suggests that the model has become too closely fit to the training data and is unable to generalize well to new instances.
Furthermore, high variance between the performance metrics of the model on the training set and the validation or test set can be a sign of overfitting. This indicates that the model’s performance is highly sensitive to changes in the training data, leading to poor generalization on unseen data.
Another symptom of overfitting is observing a large difference between the model’s accuracy or performance on the training set and the validation set. If the model performs significantly better on the training set compared to the validation set, it indicates that the model has become overly specific to the training data and may not generalize well to new instances.
It’s also vital to keep an eye on performance metrics such as precision, recall, or F1 score. If there is a significant difference in these performance metrics between the training and validation sets, it suggests that the model is overfitting and may not perform well in real-world scenarios.
Visualizing the learning curve of the model can provide valuable insights into overfitting. If the learning curve shows a decreasing training error but an increasing validation error as the model is trained with more data, it is an indication of overfitting. This signifies that the model is learning to fit the training data too closely, leading to poor generalization.
In summary, the symptoms of overfitting include a significant difference in performance between the training and validation/test sets, high variance between these sets, a large discrepancy in performance metrics, and an observable trend in the learning curve. By recognizing these symptoms, practitioners can take proactive steps to address overfitting and develop more reliable and generalizable machine learning models.
Impact of Overfitting
Overfitting, if not addressed, can have detrimental effects on the reliability and applicability of machine learning models. It can significantly impact the model’s performance and ultimately lead to poor outcomes in real-world scenarios.
One of the key impacts of overfitting is the decreased generalization ability of the model. When a model is overfit, it becomes too specific to the training data and fails to capture the underlying patterns that can be applied to new, unseen data. As a result, the model’s predictions or decisions may not be accurate or reliable when applied to real-life situations.
Overfitting can also lead to biased or skewed results. If the training data contains outliers or misleading patterns, an overfitted model may give excessive importance to these erroneous data points and produce biased predictions. This can have serious consequences in sensitive domains such as healthcare or finance, where accurate and unbiased predictions are crucial.
Another impact of overfitting is the waste of computational resources and time. When a model is overfit, it may require excessive training iterations, complex architectures, or laborious hyperparameter tuning efforts. These processes can be time-consuming and computationally expensive, leading to inefficiency and an unnecessary drain on resources.
In addition, overfitting can hinder the model’s ability to adapt and generalize to new data. If the model is too closely fit to the training data, it may struggle to make accurate predictions when faced with unseen data instances that differ from the training distribution. This lack of adaptability can limit the practical usefulness and scalability of the model.
Furthermore, overfitting can undermine the interpretability and transparency of the model. An overfitted model may learn intricate and complex representations of the training data, making it difficult to understand and interpret the factors driving its predictions or decision-making process. This can pose challenges in regulated industries or situations where interpretability is crucial for building trust in the model’s outputs.
Overall, the impact of overfitting can be significant and far-reaching. It can lead to decreased generalization, biased results, waste of computational resources, hindered adaptation to new data, and reduced interpretability. To build reliable and robust machine learning models, practitioners must be mindful of the potential impacts of overfitting and take appropriate measures to address this challenge.
Techniques to Avoid Overfitting
To prevent the occurrence of overfitting and improve the generalization capabilities of machine learning models, various techniques and strategies can be employed. These techniques aim to strike a balance between model complexity and performance, ensuring robust and reliable results on unseen data.
Cross-validation: Cross-validation is a widely-used technique to assess model performance and detect signs of overfitting. It involves dividing the data into multiple subsets, training the model on different combinations of these subsets, and evaluating its performance on the remaining subset. By assessing the model’s performance on unseen data, cross-validation helps identify if the model is overfitting the training set and suggests potential adjustments.
Regularization: Regularization is an effective technique for preventing overfitting by introducing a penalty for complex models. It adds a regularization term to the model’s loss function, encouraging the model to find a balance between accuracy and complexity. By imposing a constraint on model parameters, regularization helps prevent over-optimization on the training data and encourages more generalizable representations.
Feature Selection: Feature selection is the process of identifying and selecting the most relevant features for the model. By removing unnecessary or redundant features, this technique helps simplify the model and reduce the risk of overfitting. Feature selection can be based on statistical measures or domain expertise, focusing on the features that contribute the most valuable information for accurate predictions.
Early Stopping: Early stopping involves monitoring the model’s performance on a validation set during the training process and halting training when the performance starts to deteriorate. In other words, training is stopped before the model becomes too closely fit to the training data, preventing overfitting. Early stopping allows the model to generalize better on unseen data by finding a suitable stopping point that balances training accuracy and generalization.
Data Augmentation: Data augmentation is a technique that enhances the training dataset by generating additional synthetic examples. By applying various transformations or perturbations to the existing data, such as rotation, flipping, or adding noise, data augmentation helps increase the diversity and variability of the training set. This can improve the model’s ability to generalize and reduce the risk of overfitting.
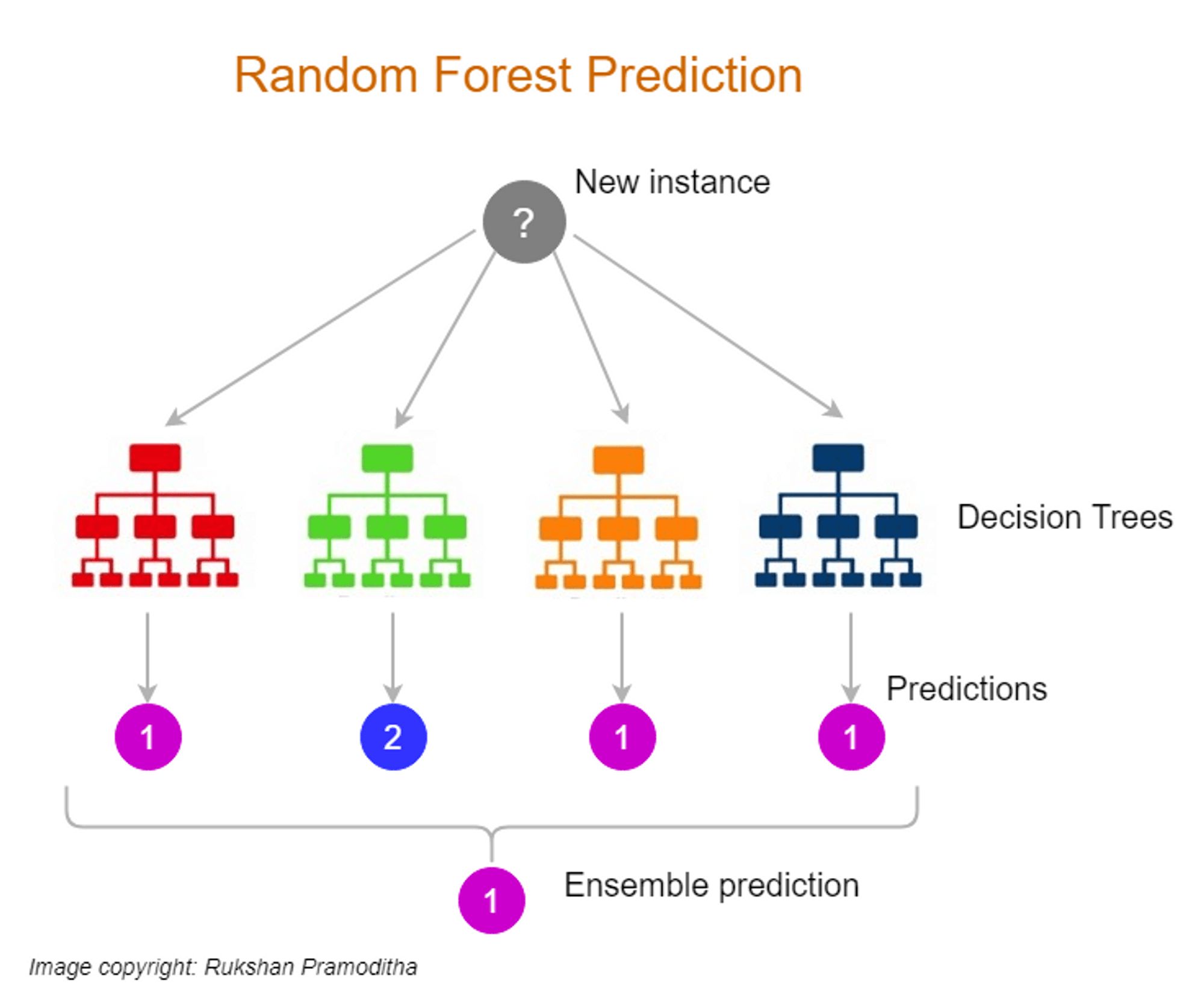
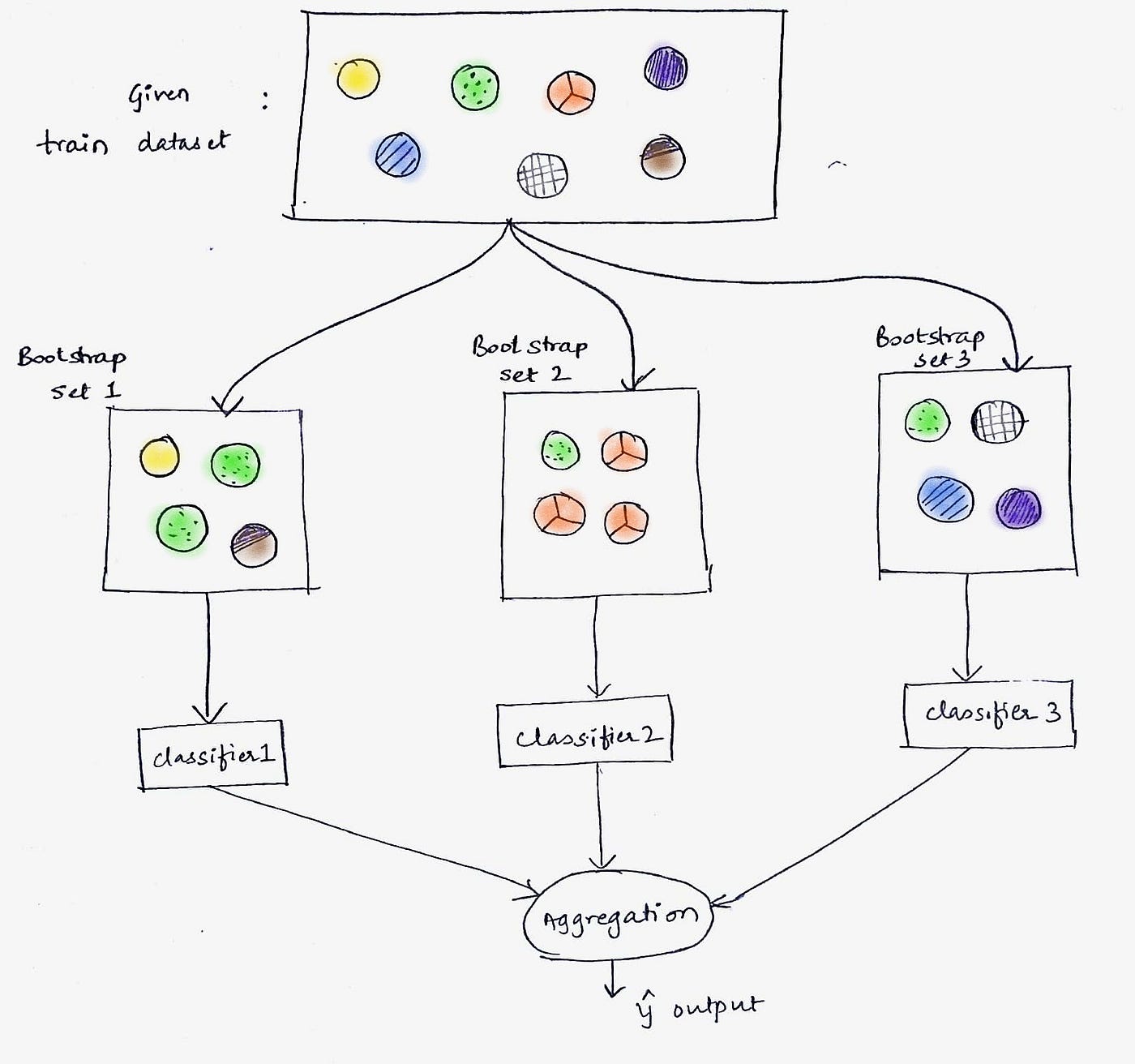
Ensemble Methods: Ensemble methods combine the predictions of multiple models to improve generalization and reduce the risk of overfitting. By training multiple models with different subsets of the data or using different algorithms, ensemble methods can capture different aspects of the underlying patterns and reduce the impact of individual model errors. Popular ensemble methods include bagging, boosting, and stacking.
Model Selection: Choosing the right model architecture and complexity is crucial for avoiding overfitting. It is essential to select a model that is appropriate for the data and problem at hand, considering factors such as dataset size, complexity, and the trade-off between model performance and generalization. Starting with a simpler model and gradually increasing complexity can help identify the appropriate level of model expressiveness without risking overfitting.
By employing these techniques and adopting a cautious approach to model development, practitioners can effectively avoid overfitting and build more reliable and generalizable machine learning models.
Cross-validation
Cross-validation is a widely-used technique in machine learning to assess the performance of a model and detect signs of overfitting. It involves dividing the available dataset into multiple subsets or folds, training the model on a combination of these subsets, and evaluating its performance on the remaining fold. This process is repeated multiple times, ensuring that each subset is utilized both for training and evaluation.
The main objective of cross-validation is to estimate how well the model will generalize to new, unseen data. By evaluating the model performance on different partitions of the data, cross-validation provides a more robust estimate of the model’s accuracy and helps identify any potential issues related to overfitting.
The most common type of cross-validation is k-fold cross-validation, where the dataset is divided into k subsets of approximately equal size. The model is trained k times, each time using k-1 subsets as the training data and the remaining subset as the validation data. The performance is then calculated as the average over the k iterations.
K-fold cross-validation offers several advantages. Firstly, it makes better use of the available data by using all instances for both training and validation. This helps to mitigate any issues related to limited data and provides a more comprehensive evaluation of the model’s performance. Secondly, it helps to estimate how the model generalizes to different subsets of the data by assessing its performance on multiple combinations of training and validation sets. This can help identify if the model is overfitting the training data or whether it exhibits high variability in performance on different partitions of the data.
Another type of cross-validation is stratified k-fold cross-validation, which ensures that the class distribution is preserved in each fold. This is particularly useful in cases where the dataset is imbalanced or when preserving the class proportions is important.
Cross-validation can also be combined with other techniques to further enhance model evaluation. For example, nested cross-validation is used to perform an additional layer of cross-validation when hyperparameter tuning or model selection is involved. This helps to avoid biased model evaluation and provides a more realistic estimate of the model’s performance.
Overall, cross-validation is a valuable technique in the machine learning workflow. It helps to assess the performance and generalization abilities of the model, detect potential issues related to overfitting, and provide more reliable estimates of the model’s accuracy. By incorporating cross-validation into the model development process, practitioners can build more robust and reliable machine learning models.
Regularization
Regularization is a powerful technique used to combat overfitting in machine learning models. It introduces a penalty or constraint on the model’s parameters, encouraging it to find a balance between accuracy and complexity. By preventing models from over-optimizing on the training data, regularization helps improve generalization and reduces the risk of overfitting.
One commonly used form of regularization is called L1 regularization, also known as Lasso regularization. L1 regularization adds a penalty term to the model’s loss function equal to the absolute value of the model’s coefficients. This encourages sparse parameter values, effectively selecting the most relevant features and forcing the model to focus on the most important predictors.
Another form of regularization is L2 regularization, also known as Ridge regularization. L2 regularization adds a penalty term to the loss function, corresponding to the squared sum of the model’s coefficients. Unlike L1 regularization, L2 regularization does not promote sparsity and instead encourages small, but non-zero parameter values. This can help prevent extreme parameter values and reduce the effects of noise in the data.
Regularization also includes a hyperparameter, often denoted as λ (lambda), that controls the strength of the regularization penalty. The choice of λ determines the trade-off between model complexity and accuracy. A smaller λ value allows the model to be more flexible and potentially fit the training data more closely, while a larger λ value enforces a stronger regularization, leading to simplified models with potentially improved generalization.
Regularization techniques can be applied to a wide range of machine learning models, including linear regression, logistic regression, and neural networks. Regularization is typically accomplished by adding the regularization term to the loss function during training. The model parameters are then updated using optimization algorithms such as gradient descent, taking into account both the data fitting term and the regularization term.
Regularization provides several benefits in addition to mitigating overfitting. It can help reduce complexity and increase model interpretability by encouraging more parsimonious representations. Regularization can also improve the model’s ability to handle noisy or irrelevant features by reducing their impact on the final predictions.
When applying regularization, it is important to tune the hyperparameter λ carefully. This can be accomplished through techniques such as grid search or cross-validation to find the optimal value that balances model complexity and generalization. Regularization should be considered as part of the model development process to ensure robust and reliable machine learning models.
Feature Selection
Feature selection is a technique used to identify and select the most relevant features from a given dataset. It aims to reduce the dimensionality of the data and focus on the subset of features that contribute the most valuable information for building accurate and generalizable machine learning models. By removing unnecessary or redundant features, feature selection can help prevent overfitting and improve the efficiency and interpretability of models.
One common approach to feature selection is filter methods, which assess the relevance of features based on their statistical properties. These methods calculate measures such as correlation, mutual information, or chi-square between each feature and the target variable. Features with low relevance are then discarded, keeping only those with a higher degree of association with the target variable.
Another approach to feature selection is wrapper methods, which utilize the predictive power of a specific machine learning algorithm to evaluate feature subsets. Wrapper methods employ a search strategy to iteratively select, evaluate, and compare combinations of features based on the performance of the model. This process can be computationally expensive but provides more accurate and tailored feature selection.
Embedded methods offer a third approach to feature selection, where the feature selection process is embedded within the model training itself. These methods incorporate feature selection as part of the optimization process. For instance, some machine learning algorithms, such as LASSO (Least Absolute Shrinkage and Selection Operator) and Elastic Net, impose penalties on the model’s coefficients, effectively selecting the most relevant features during the training process.
Feature selection has several advantages in addition to mitigating overfitting. It helps to improve computation and memory efficiency by reducing the dimensionality of the dataset. With fewer features, models require fewer resources and can be trained faster. Feature selection also enhances model interpretability by focusing on a meaningful subset of features, providing insights into the important factors influencing the model’s predictions.
However, it is essential to note that feature selection is a delicate balancing act. Removing too many features can result in information loss and limit the model’s ability to capture important patterns and relationships. It is crucial to avoid excessively relying on automated feature selection algorithms and to consider domain knowledge and intuition in the selection process, as human expertise can provide valuable insights into the relevance and importance of specific features.
Overall, feature selection is a valuable technique in machine learning, allowing practitioners to identify the most informative features and improve model generalization. By focusing on the subset of relevant features, feature selection helps mitigate overfitting, enhance efficiency, and facilitate interpretability in machine learning models.
Early Stopping
Early stopping is a technique used to prevent overfitting in machine learning models by stopping the training process before the model becomes too closely fit to the training data. This technique helps improve generalization by finding the optimal point in training where the model achieves a balance between accuracy on the training data and its ability to generalize to unseen data.
The early stopping technique is typically applied during iterative model training, such as training a neural network with stochastic gradient descent. It involves monitoring the model’s performance on a separate validation set during the training process. The validation set contains data that is not used for training but is representative of the problem domain.
As the model is trained over multiple iterations or epochs, its performance on the validation set is continuously evaluated. If there is a decrease or stagnation in the model’s performance on the validation set, it suggests that the model is starting to overfit the training data. At this point, the training process is halted, and the model with the best performance on the validation set is selected as the final model.
Early stopping prevents the model from continuing to learn from the training data beyond the point where it becomes overly specialized to the training set. By stopping the training process early, before significant overfitting occurs, the model retains its ability to generalize well to unseen data.
A key advantage of early stopping is that it helps to save computational resources and time. By stopping the training process early, unnecessary iterations can be avoided, leading to faster training times and more efficient model development.
It is important to note that early stopping requires the availability of a separate validation dataset. This dataset should be representative of the unseen data for which the model will ultimately be used. Splitting the original dataset into training, validation, and test sets ensures proper evaluation and prevents bias in model evaluation.
When applying early stopping, practitioners may need to tune hyperparameters such as the patience parameter, which determines the number of consecutive epochs with no improvement before the training is stopped. Proper validation set monitoring and hyperparameter tuning are crucial for effective early stopping and optimal model performance.
Overall, early stopping is a valuable technique for preventing overfitting and improving generalization in machine learning models. By monitoring the model’s performance on a separate validation set and stopping the training process at the optimal point, early stopping helps ensure that the model achieves a balance between accuracy and generalization, leading to more robust and reliable models.
Conclusion
Overfitting is a common challenge in machine learning that can undermine the reliability and generalization capabilities of models. It can lead to poor performance on new, unseen data and hinder the model’s ability to make accurate predictions or decisions in real-world scenarios.
To address overfitting, various techniques and strategies can be employed. Cross-validation helps assess model performance and detect signs of overfitting by evaluating the model on different subsets of the data. Regularization introduces a penalty on the model’s complexity, encouraging a balance between accuracy and simplicity. Feature selection helps identify and select the most relevant features, reducing the dimensionality of the data. Early stopping stops the training process before overfitting occurs, improving the model’s ability to generalize. These techniques help mitigate overfitting and promote the development of more reliable and robust machine learning models.
It is crucial to understand the causes, symptoms, and techniques to avoid overfitting in order to build effective machine learning models. Fine-tuning hyperparameters, incorporating domain knowledge, and applying appropriate evaluation methodologies can further enhance the effectiveness of these techniques.
By addressing overfitting, practitioners can improve the generalizability and performance of their machine learning models. This, in turn, enables accurate predictions, informed decision-making, and the development of reliable solutions across various domains and industries.